概要
Python でのデータ分析作業に向いたグラフ作成ツールの機能比較です。Python のグラフ作成ツールといえば matplotlib ですが、正直言って煩雑な構文で、こういった作業に向かないと思います。そこで、今回は使えそうな以下の3つ+α1のパッケージについて、大雑把に紹介します。
グラフ作成ツールに求められる要件
サンプルコードと結果だけ見たい場合はここは読み飛ばしても問題ないです。
たとえば pandas-profiling はデータフレーム内の全ての列に対して記述統計量をとり、簡易的なヒストグラムなんかも表示してくれますが、多くの場合それだけでは不十分です。高次元のデータから変数間の関係を読み取ることを意図していました。いわゆる探索的データ解析 (EDA) に近いものだと思います2。変数どうしの関係を様々な視点で視覚化してやっと発見できる事実もあります。そこで、このような作業に活用できるグラフ作成ツールにことに対して次のような要件を考えています。
- 構文が分析の軸の増加に対してスケーラブルであること
- EDAに必要な様々なグラフを描く機能が用意されていること
- 様々なデータ型にも対応できること
- ミニマルなデザインのグラフであること
- グラフを拡大縮小する機能があること
- ある程度の計算・集計機能があること
また、「データ分析」特有でないですが、以下の要件もあればうれしいです。
- 構文の学習コストが少ないこと
- 構文がよく規格化されており、基本を覚えたら類推でいろいろ書けるようになる
- 環境依存しないこと。
- OS、特殊な外部ライブラリなどにあまり依存していないこと。データ分析特有ではないが、あるとうれしい
ここで上げた要件についてもう少し詳しく解説します。
(1) について、 EDAの過程では、変数 X, Y をグループ別に集計して、グラフを重ね合わせ (オーバーレイ) たり、積み上げたり、個別に表示したり (ファセット)、グループ別集計の軸を増やしたり、値のスケールを調整したり...、などの試行錯誤は非常によくあります。よって、こういう工程であまり手間がかからないような構文であると、作業の手間が減ります。私が matplotlib を使いにくいという理由は、ここにあります。変数が増えたらコードもどんどん煩雑になり、使い回しもしづらいパッケージだと思います。
Python のライブラリとして、bokeh や plotly も有名ですが、どちらかというと Tableau とかのダッシュボードを作る「ビジュアリゼーションツール」的な機能を志向しているように見えます。どちらも自由度はありますが、都度細かくレイアウトを設定する必要があり、このような複雑な操作を繰り返すのに適した構文ではないと思います3。
(2) の代表例は、ヒストグラム、 折れ線グラフ (ラインプロット)、散布図、箱ひげ図 (or バイオリンプロット)などです。統計学あるいはデータビジュアライゼーション的に有意義なものが用意されている必要があります。一方で、使われる場面の限定的なグラフは、今回は重視していません。例えばネットワーク図とか、ローソク足 (candlestick) チャートなんかは、必要な場面もありますが、かなり限定されると思うので今回は考慮していません。
(3) 視覚化したいデータには複数の種類があります。int, float, のような数値も、 bool型やカテゴリカル変数もありえます。日付時刻を表す場合もあります。加えて、欠損値がしばしばつきものです。このような多用な型を、面倒な事前処理なしでグラフとして表示できるようなものが求められます。
(4) でいう「ミニマル」とは、データから得られる情報をモレなく・無駄なく視覚化するということです。たとえば、3D円グラフや3D棒グラフのような 「見た目を良くするだけ」のグラフは要求していません。私の意図している使い方では、大勢の人間とグラフを共有するものではなく、個人作業か、ある程度の専門知識を共有したチームメンバーなど限られた範囲でグラフを確認するというものです。データの視覚化で3次元のプロットが使われる場面もありますが、(1) ですでに多数の軸で集計できる機能を要件としているため、3Dプロットなしでも代替的なグラフを描ける場合が多いです。たとえば、x-y軸の散布図に対して、z軸の変数に対応してして点の大きさや色を変えたり、等高線を描いたりすれば同じように機能します。よって、3Dプロット機能も必須でないと考えています。また、色彩を例にすれば、誰でも識別しやすい色分けのグラフを描けることは重要です見やすいカラーユニバーサルデザイン であることが望ましい4です。そして、当然ながら、こういったデザインのグラフがデフォルトで用意されており、デザインの調整のためのコーディングもミニマルであるようなパッケージが望ましいです。
このようなデザインを、なるべくコードを追加せずともデフォルトで描けるようなパッケージが望ましいです。つまり、デフォルトのデザインのミニマルさと、デザイン調整に要するコーディングのミニマルさの2つを要求しています。
(5) データの件数が大きくなるとこの機能が欲しくなってきます。特に昨今は大きなデータを扱う機会が増えており、1万件を超えるものも全く珍しくないと思います。1万件のデータの散布図は、ほとんど塗りつぶされてしまいます。そういうときにデータの一部だけ取り出してグラフを作り直す、という処理は面倒なので、インタラクティブに拡大縮小操作可能であると便利です。
(6) 例えば「グループごとに平均値をとったグラフ」を描きたいときに、入力データをいちいち手動で集計加工しなくとも、そのまま与えてもグラフ作成ライブラリ側で集計処理をしてくれると楽です5。
検証用データ
以下のようなコードで検証用データを作成しました。このデータフレームには、 int/float 型の数値をそれぞれ複数、日付時刻、 bool 型、文字列、日本語を含む文字列が含まれています。昨今は大量のデータを扱える機会が増えているため、およそ5万行のデータフレームにしています。
クリックしてソースコードと結果を表示
import numpy as np
import pandas as pd
# CUD パレット
# http://jfly.iam.u-tokyo.ac.jp/colorset/ 4ed準拠
cud_rgb_dec = [(246, 170, 0), (0, 90, 255), (255, 241, 0), (128, 64, 0), (119, 217, 168), (191, 228, 255)]
cud_rgb_hex = ['#' + ''.join(map(lambda x: hex(x).split('x')[-1].zfill(2), x)) for x in cud_rgb_dec]
# 検証用データフレーム
np.random.seed(42)
df_large = pd.DataFrame({'time': pd.date_range('2018-01-01 00:00', '2018-12-31 23:50', freq='10MIN')})
df_large = df_large.assign(
is_train=np.random.choice([True, False], p=[0.7, .3], size=df_large.shape[0]),
discrete_2=np.random.poisson(lam=100, size=df_large.shape[0]),
cat_1=np.random.choice(['plotnine', 'brunel', 'altair', 'seaborn', np.nan], size=df_large.shape[0]),
cat_2=np.random.choice(['PRML', 'ESL', 'SICP', 'Causality', np.nan], size=df_large.shape[0])
)
df_large['num_1'] = np.random.normal(size=df_large.shape[0]) + (df_large['cat_1'] == 'plotnine') * np.random.normal(scale=2, size=df_large.shape[0])
df_large['num_2'] = np.random.normal(size=df_large.shape[0]) + (df_large['cat_1'] == 'brunel') * np.random.normal(loc=1, scale=.5, size=df_large.shape[0])
df_large['num_3'] = np.random.lognormal(size=df_large.shape[0]) + (df_large['cat_1'] == 'altair') * np.random.lognormal(mean=-1, size=df_large.shape[0])
df_large['discrete_1'] = ((df_large['cat_1']=='plotnine') & (df_large['cat_2']=='PRML')) * 5 + np.random.poisson(lam=5, size=df_large.shape[0] )
df_large['discrete_2'] = (df_large['cat_2'] == 'SICP') * np.random.binomial(n=5, p=.7, size=df_large.shape[0]) + np.random.binomial(n=2, p=.5, size=df_large.shape[0])
df_large['cat_2_ja'] = df_large['cat_2'].replace(
{'PRML': 'パターン認識と機械学習',
'ESL': '統計的学習の基礎',
'SICP': '計算機プログラムの構造と解釈',
'Causality': '統計的因果推論 -モデル・推論・推測-',
np.nan: np.nan
})
df_large.info()
RangeIndex: 52560 entries, 0 to 52559
Data columns (total 10 columns):
time 52560 non-null datetime64[ns]
is_train 52560 non-null bool
discrete_2 52560 non-null int64
cat_1 52560 non-null object
cat_2 52560 non-null object
num_1 52560 non-null float64
num_2 52560 non-null float64
num_3 52560 non-null float64
discrete_1 52560 non-null int64
cat_2_ja 52560 non-null object
dtypes: bool(1), datetime64[ns](1), float64(3), int64(2), object(3)
memory usage: 3.7+ MB
df_large.head()
| time | is_train | discrete_2 | cat_1 | cat_2 | num_1 | num_2 | num_3 | discrete_1 | cat_2_ja | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-01-01 00:00:00 | True | 2 | plotnine | Causality | -2.062584 | 0.669508 | 3.408795 | 5 | 統計的因果推論 -モデル・推論・推測- |
| 1 | 2018-01-01 00:10:00 | False | 1 | seaborn | Causality | 0.249987 | -0.269146 | 0.548975 | 4 | 統計的因果推論 -モデル・推論・推測- |
| 2 | 2018-01-01 00:20:00 | False | 2 | brunel | ESL | 1.475662 | -0.099113 | 0.296738 | 4 | 統計的学習の基礎 |
| 3 | 2018-01-01 00:30:00 | True | 1 | plotnine | ESL | -0.192918 | 1.594994 | 0.458107 | 7 | 統計的学習の基礎 |
| 4 | 2018-01-01 00:40:00 | True | 4 | brunel | SICP | 0.481949 | 0.238898 | 0.277485 | 3 | 計算機プログラムの構造と解釈 |
比較方法
大量に比較画像を用意するのも大変なので、以下の項目をそれぞれ作図してみました。時系列グラフ以外、すべて bool型の is_train でグループ分けして作図します。2つのグループの傾向の違いを比較しやすくするため、必要に応じて重ねて描画します。これは、機械学習で訓練データと検証データとで分布の傾向に違いがないかを確認することがよくあるからです。
また、カラーユニバーサルなデザインも重視するため、不適切な色分けであれば変更するようにします。
- 複数変数のヒストグラム。
- 複数変数の箱ひげ図・バイオリンプロット。
- 散布図行列。
- 疑似3次元プロット。2次元プロットで擬似的に3次元の情報を表す機能があるか確認します)
- 時系列のグラフ。3つの列をそれぞれ時系列で並べます。このとき、各列の値を絶対値に変換し、さらに累積値に変換して描画します。
なお、結構な量になったため、こちらには結果の一部だけ掲載しています。
以下の gist に完全版があります。何が原因か gist 上では表示されませんが、 Python のバージョンは 3.6 で、ここで紹介しているパッケージはすべて pip でインストールできるため、追試は簡単にできると思います。
https://gist.github.com/36a30a245bec916d3057adbbf336d123
実演
plotnine
- https://github.com/has2k1/plotnine
- マニュアル: https://plotnine.readthedocs.io/en/stable/#
- 作者は「Pythonにおける grammar of graphics の実装である」と主張していますが実質的に R の ggplot2 のクローンです.。
- だいたい ggplot2 と同じ構文になっています
- ggplot2 の公式関数リファレンス https://ggplot2.tidyverse.org/reference/index.html
- ちなみに yhat も
ggplotという ggplot2 クローンを開発していますが、あまり更新されていません。再現度はplotnineのほうが上だと思います。
- 本家
ggplot2の日本語解説ページは多いので、参考になることもあります。たとえば:- 岩嵜 航 (heavy_watal) 氏による ggplot2 の初心者向け解説: 『ggplot2 — きれいなグラフを簡単に合理的に
』、 『Rにやらせて楽ラクしよう — データの可視化と下ごしらえ』 - 前田 和寛 (@kazutan) 氏による 『ggplot2に関する資料まとめ』
- 岩嵜 航 (heavy_watal) 氏による ggplot2 の初心者向け解説: 『ggplot2 — きれいなグラフを簡単に合理的に
長所
-
ggplot()関数で入力データを指定、geom_*()でデータを元に各種グラフを描画、stat_*()でデータを要約した値を可視化できます。これらの関数にはaes()で使用する列を指定します。 - これらの関数を
+演算子で足すことで色々なグラフを作成できます。 - 補助的な情報を与えるのが簡単。
- 垂直線、水平線などの補助線を引いたり、回帰直線を引いたり、散布図の点の位置にテキストを描画したりといったことも、関数を足すことで簡単に実現できます。
- 値のスケール変更が容易です。たとえば
scale_y_log10()を足せばy軸を対数スケールにできます。 -
ggplot2を知っていれば学習コストはほとんどありません。ggplot2の作例を参考にできます。- 一部の引数名や、R のベクトル
c(...)を Python のリスト[...]に置き換えればだいたい再現できます。
- 一部の引数名や、R のベクトル
- 入力データ、使用する軸の指定、グラフの種類、色や線の太さといった属性、を指定するコンポネントごとに分かれた構文になっており、作り直しや使い回しがききます。
- 様々なグラフとグループ別集計に対応しています。入力データの集計値をグラフにするのも簡単です。
短所
- ユニバーサルカラーな色スキームが用意されていません。
- むしろデフォルトで赤緑の組み合わせが発生しやすいです。
- 本家では
ggthmesの pander を使うことができましたが、こちらにはありません。
- 公式ドキュメントがやや不親切です。
-
ggplot2と同様の欠点があります。- 複数の変数を同時にグラフに表すのが難しいです。
- ヒートマップなど行列的な配置のグラフも苦手です。
- 文字や点のサイズの自動調整ができません。点が大きすぎたり文字がはみ出したり。日付のフォーマット設定も外部ライブラリ
mizaniが必要です。
- インタラクティブに拡大縮小ができません6
- 本家の
ggthemes,gridExtraなどに対応するものがないので、あまり凝ったレイアウトにはできません7。 -
from plotnine import *は大量のメソッドがグローバル空間にばらまかれるので名前の衝突が少し不安です。一方で毎回
plotnine.ggplot(..., plotnine.aes(...)) + plotnine.geom_line(...) + plotnine.theme(...)
と書いていたらコードが冗長になりすぎます。
- Python の言語仕様上、
ggplot2と微妙に異なるところがあります。-
theme()関数の引数がaxis.text.y->axis_text_yなどドットが置き換わっています。 -
aes()で列名を指定するには必ず文字列で渡す必要があります (関数の評価はされます)。
-
- 言語仕様の差異を考慮しても、まだところどころ ggplot2 の再現が不完全なところがあります
-
stat_summary_hex(),geom_contour()など便利な関数が未実装です。 - smooth_* シリーズの平滑機の実装がおかしいです。
- linetype で4種類を超えるカテゴリを指定するとエラーになります (matplotlib に依存しているため)。
- 日本語表示する場合は予め対応フォントを指定する必要があります8 (matplotlib に依存しているため)。
- 他にも、凡例の順序の決定方法が本家と違う、一部の引数のデフォルト設定が本家と違う、など細かい差異があります。
-
plotnine の作例
以下のように初期化処理をしておきます。
ソースコードを表示
# 初期化
from plotnine import *
import plotnine
# 日本語表示できるフォントに設定
plotnine.options.current_theme = theme(text=element_text(family='IPAGothic'))
# 横長のグラフ設定
thm_wide = theme(
figure_size=(16, 5)
)
# 正方形のグラフ設定
thm_sq = theme(
figure_size=(15, 10),
legend_position='bottom',
legend_title=element_text(size=15),
legend_text=element_text(size=15),
legend_box_margin=30
)
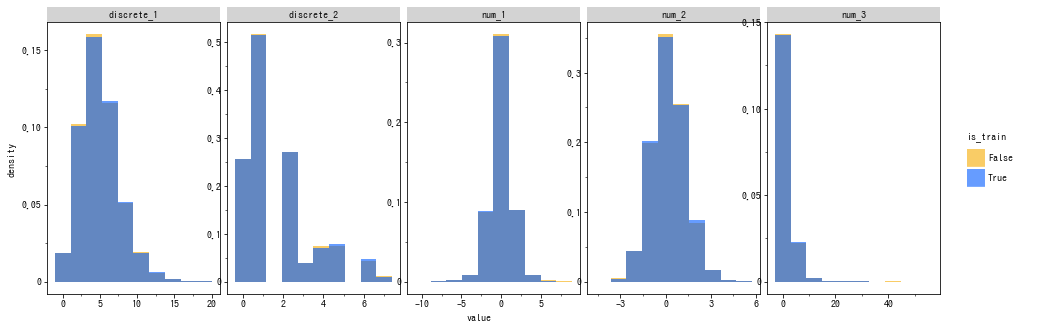
複数のヒストグラム
-
geom_histogram()がヒストグラムを描画する関数です。group=,fill=を設定することで簡単にグループ別に集計できます。 - グループ別にヒストグラムを作る場合、デフォルトでは積み上げになるため
position='identity'を設定しています9。 -
facet_wrap()で個別にグラフ描画できます。 -
y='..density..'は y軸を相対頻度で表す構文ですが、列全体で計算するため、pd.melt()を使って描いた場合は値が不適切になります。 -
plotnineは自動調整できないため、今回の例では軸ラベルの値が重なってしまっています (手動で調整することはできます)。 - カテゴリカル変数の場合は
geom_bar()を使いますが、相対頻度の計算をする機能がないため、見づらくなってしまいます。
ソースコードを表示
ggplot(
pd.melt(df_large.select_dtypes(include=[float, int, bool]), id_vars=['is_train']),
aes(x='value', y='..density..', group='is_train', fill='is_train')
) + geom_histogram(
position='identity', alpha=.6, bins=10,
) + facet_wrap(
'variable', scales='free', nrow=1
) + scale_fill_manual(
values=cud_rgb_hex
) + thm_wide
ソースコードを表示
# カテゴリカル変数
ggplot(
pd.melt(df_large[df_large.select_dtypes(include=['object']).columns.tolist() + ['is_train']],
id_vars=['is_train']),
aes(x='value', y='..count..', group='is_train', fill='is_train')
) + geom_bar(
position='identity', alpha=.5
) + facet_wrap('variable', scales='free') + scale_fill_manual(
values=cud_rgb_hex
) + thm_wide
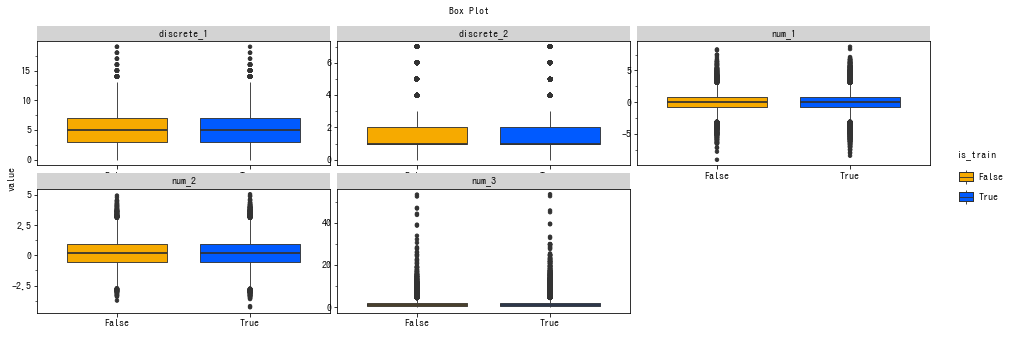
複数の箱ひげ図・バイオリンプロット
-
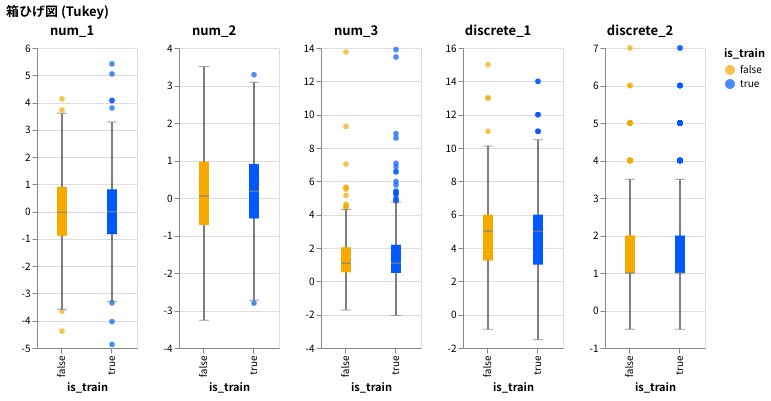
geom_boxplot()かgeom_violin()を使うだけで箱ひげ図/バイオリンプロットを簡単に切り替えられるため、ここでは前者のみ掲載します。 - 箱ひげ図は、1.5 IQR のヒゲ + 外れ値を表示するいわゆる Tukey 流10です。
- ヒストグラムの場合と同様、y軸のスケールの調整ができません。
ソースコードを表示
g_box = ggplot(
pd.melt(df_large.select_dtypes(include=[float, int, bool]), id_vars=['is_train']),
aes(x='is_train', y='value', group='is_train', fill='is_train')
) + scale_fill_manual(
values=cud_rgb_hex
)
g_box + geom_boxplot() + facet_wrap(
'variable', scales='free'
) + labs(x=' ', title='Box Plot') + thm_wide
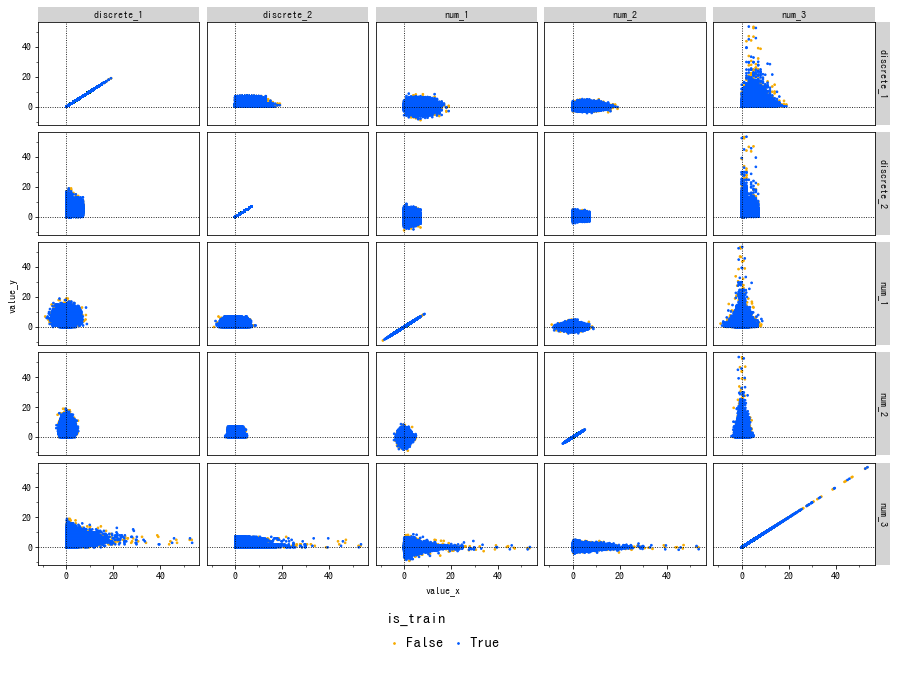
散布図行列
-
facet_grid()をつかい、2元配置の散布図として描画できます。 - しかし、ロング形式で与える必要があるので、元データの 行数 x 列数 倍の行数のデータフレームを作ることになり、計算量的に難しい場合もあります。
- スケールもグラフごとに調整することができません。
-
smooth_*()やgeom_vline()などで補助線を引くことが容易です。 - この方法では数値変数とカテゴリカル変数の混合した散布図行列は描けません。個別に散布図を書くことはできます。
- カテゴリカル変数の散布図には、軸をランダムにずらすことで擬似的に数値変数の散布図のように表現する
geom_jitter()も役に立ちます。
- カテゴリカル変数の散布図には、軸をランダムにずらすことで擬似的に数値変数の散布図のように表現する
ソースコードを表示
tmp = pd.melt(
df_large[['is_train', 'num_1', 'num_2', 'num_3', 'discrete_1', 'discrete_2']].reset_index(),
id_vars=['index', 'is_train']
)
tmp = pd.merge(tmp, tmp, on=['index', 'is_train'])
g = ggplot(
tmp, aes(x='value_x', y='value_y', color='is_train')
) + geom_point(size=0.5) + facet_grid(
['variable_x', 'variable_y'], scales='free'
) + scale_color_manual(
values=cud_rgb_hex
)+ thm_sq
# x=0, y=0 の補助線を引く
g + geom_vline(xintercept=0, linetype=':') + geom_hline(yintercept=0, linetype=':')
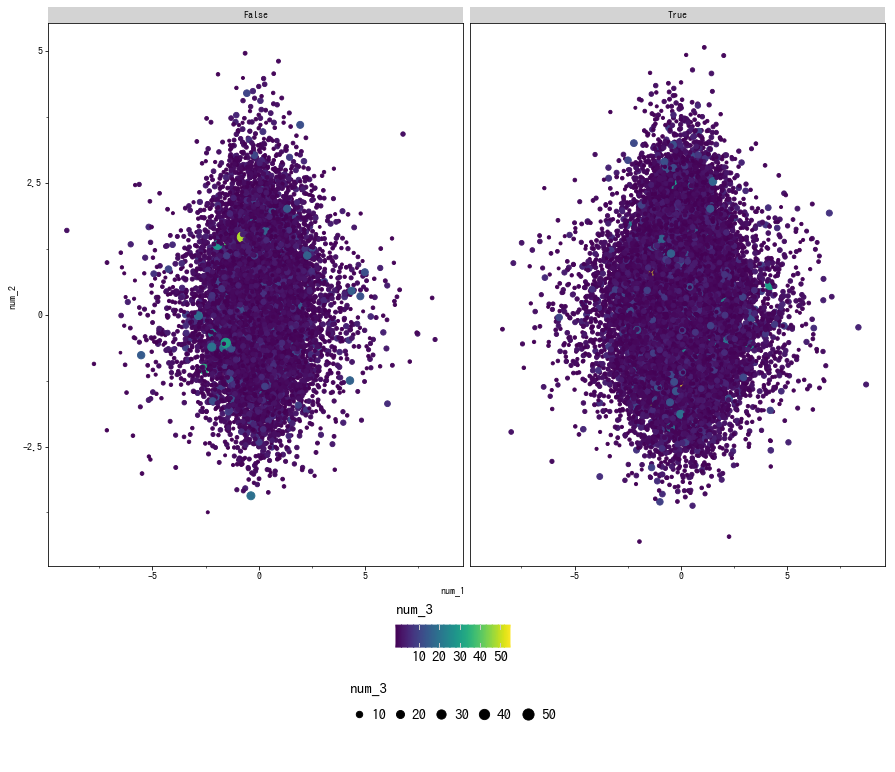
疑似三次元プロット
- 散布図行列同様、
geom_point()で簡単に描けます。 - 本家
ggplot2にある等高線を描くgeom_contour()は 0.4.0 時点では未実装です。 - 一方、x, y の2次元分布の推定線やヒストグラムの等高線を描く
geom_density_2d(),geom_bin2d()はあります (notebook に掲載)。
ggplot(df_large, aes(x='num_1', y='num_2', color='num_3', size='num_3')) + geom_point() + facet_wrap('is_train') + thm_sq
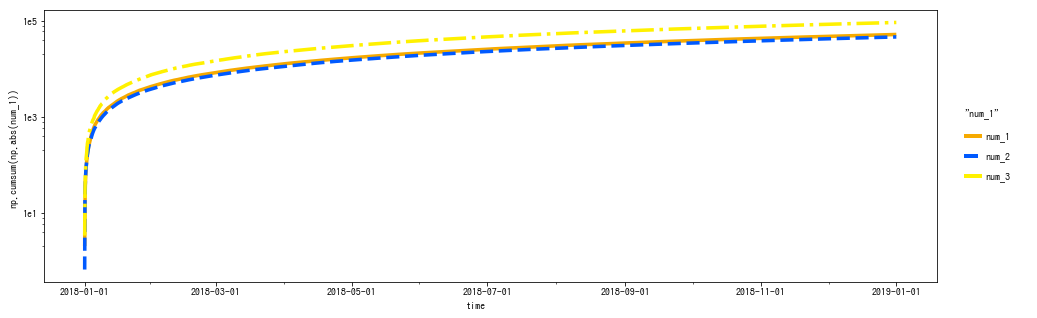
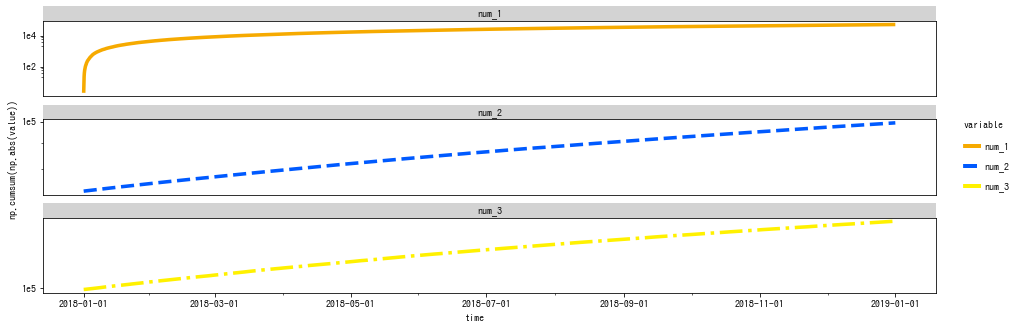
時系列グラフ
- 上図のように個別に線を引くことも、下図のように
pd.melt()を使い、facet_wrap()でスケールの違う個別のグラフにすることもできます。 - 多数の系列がある、いわゆるスパゲティ・プロットの場合は後者のやり方のほうが楽だと思います。
- ただし、
pd.melt()を使った場合は、cumsum の計算がおかしくなります。 - また、折れ線グラフを積み上げエリアプロットに簡単に変更できます (notebook参照)。
- 日付の表示を調整したい場合は、
mizaniを併用する必要があります。- 詳しくは 公式を参照してください。
ソースコードを表示
# 別々の系列として作成
g = ggplot(df_large, aes(x='time')) + scale_color_manual(values=cud_rgb_hex)
cols = ['num_1', 'num_2', 'num_3']
for col in cols:
g = g + geom_line(aes(y='np.cumsum(np.abs({}))'.format(col),
color='"{}"'.format(col), linetype='"{}"'.format(col)), size=2)
print(g + scale_y_log10() + thm_wide)
# facet
g = ggplot(pd.melt(df_large[['time'] + cols], id_vars='time'),
aes(x='time', group='variable', y='np.cumsum(np.abs(value))')
) + scale_y_log10() + scale_color_manual(values=cud_rgb_hex)
g + geom_line(aes(color='variable', linetype='variable'), size=2) + facet_wrap('variable', ncol=1, scales='free_y') + thm_wide
altair
- https://github.com/altair-viz/altair
- チュートリアル https://github.com/altair-viz/altair_notebooks/blob/master/notebooks/Index.ipynb
- マニュアル: https://altair-viz.github.io/
- 作例: https://altair-viz.github.io/gallery/index.html?highlight=time%20series
-
Vega-Liteを元にしたライブラリです。分析作業向けに構文をシンプルにしたバインディングです。-
Vegaは json 形式でグラフを記述する必要がありましたが、altairは Python のコードとして書けます。 - と言っても、構文の長さはあまり変わらず、補完機能が使えるくらいの違いしかありません。
-
- python 3.5.3 以上が必要です。
- jupyter notebook で使う場合は
vegaもインストールする必要があります。
- jupyter notebook で使う場合は
長所
-
vegaと同様に洗練されたデザインのグラフです。- グラフをインタラクティブを拡大縮小できるオプションあり。
- デザインをある程度自動調整してくれます。
- 比較的シンプルな構文です。オブジェクトの使い回しもできます。
- 複雑なグラフの組み合わせ、オーバーレイ操作は配列をパースしたり、
brunelのように二項演算子で簡単に結合できます。 - vega-editor と連携可能です。細かいデザイン変更が必要場合に役立ちます。
- svg, png. html 形式で保存できます。
短所
- 5000 件より多いデータを一度に表示できません。
MaxRowErrorが返されます。- ただしこれは、(1) 膨大なデータをグラフにしても人間には理解できない、(2) notebook のサイズが大きくなりすぎる、という理由からくる制約です。
- 入力データを外部から読めばこのエラーは出ません。
-
altair.data_transformers.enable()で外部ファイルを読み込めます。 -
altair.data_transformers.enable('default', max_rows=None)を一度実行すればセッション中は上限エラーを切ることもできます。 - notebook のサイズ削減のため、以下ではデータを減らして実行しています。
-
- 少し軸が増えるとコードが複雑になります。
- 散布図行列とか、全変数のヒストグラムとか、複数列のグラフを同時に組み合わせる場合のコードが複雑です。
- そのため、場合によっては
matplotlibとあまり変わらない煩雑さになってしまいます。
altair の簡単な使い方
-
altair.Chart(<入力データ>)で Chart オブジェクトを作成し、各種メソッドでグラフを記述します。 -
Chart オブジェクトの様々なメソッドを呼び出してグラフの設定を追加します。
-
.mark_*()で描画するものの種類を指定します。抜粋すると以下のようなメソッドがあります。-
mark_point()中空の点。丸を描きたい場合はmark_circle()。 -
mark_line()折れ線グラフ。 -
mark_bar()バーチャート/ヒストグラム。
-
-
.transform_*で始まる各メソッドは入力データの値を変換したり集計したり、フィルタリングしたりできます。 -
.encode()グラフの軸などに使う列を設定します。 -
.interactive()を追加するとインタラクティブに拡大縮小ができます。 -
.properties()でグラフの大きさなど全般的な属性を設定できます。 -
.repeat()で複数の列に対して同じ処理を繰り返します。 -
altair.hconcat(),altair.vconcat()で複数グラフを縦/横に並べて表示できます。
これらのメソッドの多くは呼び出す順番が自由で、またメソッドチェーンになっているため、直感的に書きやすいです。
altair の作例
# 初期化
import altair as alt
alt.renderers.enable('notebook') # jupyter notebook の場合のみ初期化に必要
# ユニバーサルカラースキーマ作成
scale_color_cud = alt.Scale(range=cud_rgb_hex)
# 上限エラー無効化
alt.data_transformers.enable('default', max_rows=None)
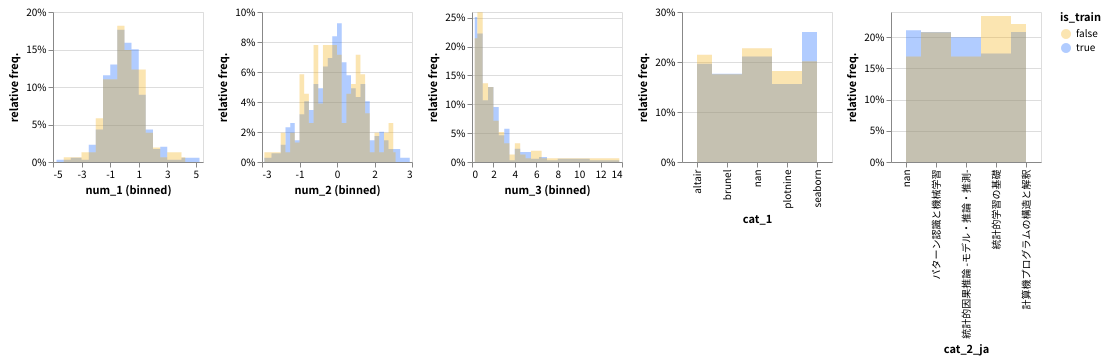
複数のヒストグラム
- 初っ端から複雑なコードになってしまいました。
-
altair.hconcat()で複数の altair グラフを横に連結11できます。 -
altairでヒストグラムを描くとのは少々面倒です。- y軸を相対度数で表す処理を追加すると、さらに複雑になります。
- さらに複雑になるものの、カテゴリカル変数も同時に作図できます
- (参考)
ソースコードを表示
hists = []
chart = alt.Chart(df_large.iloc[:500]).mark_area(opacity=0.3, interpolate='step')
for col in ['num_1', 'num_2', 'num_3', 'cat_1', 'cat_2_ja']:
hist = chart.copy().encode(
alt.X(col, bin=alt.Bin(maxbins=50)),
alt.Y('sum(freq):Q', stack=None, axis=alt.Axis(format='.0%'), title='relative freq.'),
alt.Color('is_train:O', scale=scale_color_cud)
).transform_window(
total='count({})'.format(col),
frame=[None, None],
groupby=['is_train']
).transform_calculate(
freq='1/datum.total'
).properties(width=150, height=150).interactive()
if df_large[col].dtype in [int, float]:
hists.append(hist)
elif df_large[col].dtype == 'O':
hists.append(hist.encode(alt.X(col)))
alt.hconcat(*hists)
散布図行列
-
これも結構複雑ですが、デザインはほとんど調整せずともこうなるので、
matplotlibより良いと思います。 -
.repeatで2元配置しています。 -
ただし、カテゴリ変数も含めて表示させようとするとうまくいかないです。
-
参考: https://altair-viz.github.io/gallery/scatter_matrix.html
-
かなり手間がかかりますが、散布図にヒストグラムを並べることも可能です。
https://altair-viz.github.io/gallery/scatter_marginal_hist.html
ソースコードを表示
# 数値列名のリスト
cols = [x for x in df_large.select_dtypes(include=[int, float]).columns]
alt.Chart(df_large.iloc[:500]).mark_circle(size=2.5).encode(
alt.X(alt.repeat('column'), type='quantitative'),
alt.Y(alt.repeat('row'), type='quantitative'),
alt.Color('is_train', scale=scale_color_cud)
).properties(
width=100,
height=100
).repeat(
row=cols,
column=cols
).properties(title='散布図行列')

複数の箱ひげ図・バイオリンプロット
- 箱ひげ図を描くためののメソッドがないため、
transform_*系のメソッドをいくつも活用する必要があります。複数のグラフを組み合わせないと難しいですが、スニペットを作っておくと便利です。 - 参考例ではヒゲが最大・最小値を表していますが、ここまでの流れ通り Tukey 流にします。
- 分位数や中央値といった集計が必要で、かつ生データの一部を表示する、という処理のためかなり複雑になっており、データが多いと描画に時間がかかります。
- (参考1、参考2)
ただし、 vega-lite の 3.0 では箱ひげ図が簡単に作れるようになっているので、 json 形式でそのまま書いたほうが楽かもしれません。そのうち altair でも mark_boxplot() みたいなメソッドが実装されるかも知れません。
(https://github.com/altair-viz/altair/issues/664)。
- バイオリンプロットについては、現状では vega の制約のため難しそうです。 (https://github.com/vega/vega-lite/issues/3442)。
箱ひげ図を描画する関数の定義のソースコード
def make_altair_grouped_boxplot(data, column, group):
box = alt.Chart(data).encode(x='{}:O'.format(group))
whiskers = box.encode(
x='{}:O'.format(group)
).transform_window(
# 外れ値の選別のため transform_aggregate は使えない
lower_box='q1({})'.format(column),
upper_box='q3({})'.format(column),
med='median({})'.format(column),
frame=[None, None], groupby=[group]
).transform_calculate(
IQR='datum.upper_box - datum.lower_box'
).transform_calculate(
lower_whisker='datum.lower_box - 1.5 * datum.IQR',
upper_whisker='datum.upper_box + 1.5 * datum.IQR'
)
# 外れ値の選別
outliers = whiskers.encode(
alt.X('{}:O'.format(group)),
alt.Y(column, title=None), # y軸名を上に移動させるため
alt.Color(group, scale=scale_color_cud)
).mark_circle().transform_filter(
'(datum.{0} < datum.lower_whisker) | (datum.upper_whisker < datum.{0})'.format(column)
)
# 1件のみ残す
whiskers = whiskers.transform_window(
rank='rank()', frame=[None, None], groupby=[group]
).transform_filter('datum.rank ==1')
return alt.layer(
# 外れ値
outliers,
# 下ヒゲ
whiskers.mark_rule().encode(y='lower_whisker:Q'),
whiskers.mark_tick(size=10, color='grey').encode(y='lower_whisker:Q'),
# 上ヒゲ
whiskers.mark_rule().encode(y='upper_whisker:Q'),
whiskers.mark_tick(size=10, color='grey').encode(y='upper_whisker:Q'),
# 箱
box.mark_bar(size=10).encode(y='q1({}):Q'.format(column),
y2='q3({}):Q'.format(column),
color=group),
whiskers.mark_tick(size=10.0, thickness=1.5, color='grey').encode(y='med:Q'),
).properties(width=100, title=column)
cols = ['num_1', 'num_2', 'num_3', 'discrete_1', 'discrete_2']
alt.hconcat(*[make_altair_grouped_boxplot(df_large.iloc[:500], col, 'is_train') for col in cols]).properties(title='箱ひげ図 (Tukey)')
疑似三次元プロット
- 散布図行列と同様に、
mark_circle()で描画できます。 -
.facet()で分割も簡単に可能です。 - コードは xy軸指定、色・大きさ指定、ファセットの軸指定、と
plotnineに似ています。 -
vega-liteには等高線をプロットする機能がありますが、altairではまだ対応していないようです。
alt.Chart(df_large.iloc[:500]).mark_circle().encode(
alt.Color('num_3', scale=alt.Scale(type='log')),
alt.Size('num_3', scale=alt.Scale(type='log')),
x='num_1', y='num_2'
).facet(column='is_train').properties(title='疑似三次元プロット').interactive()

時系列グラフ
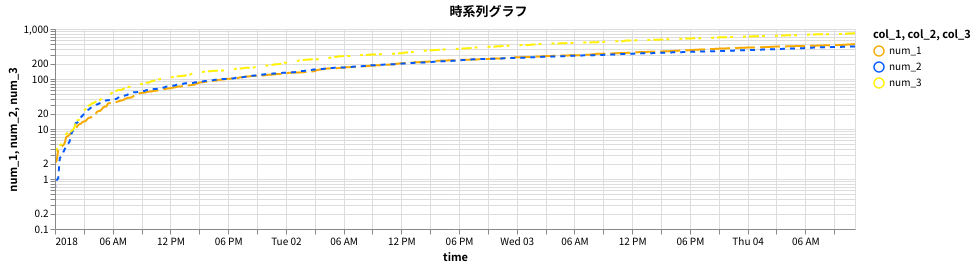
-
.data_transform()で原系列に様々な変換処理をかけられます。累積値もこれを利用して計算できるます。- ただし、列名も変わってしまうので手動で戻す必要があります (気にしなければ放置すれば可)。
-
.vconcat()でChartを垂直方向に連結できます。 - 色分けは
.mark_line()か、ダミーの列を作成して色選択する必要があります。- (参考)
- 色のパターン一覧: https://vega.github.io/vega/docs/schemes/
- 実用上は
pd.meltなどで入力データを加工したほうが楽でしょう。 - 現時点では、グループごとに線を変える機能はないようです。
- しかし、積み上げグラフの場合、対数スケールを指定すると正しく表示されないようです。
ソースコードを表示
c = alt.Chart(df_large.iloc[:500]).transform_calculate(
**{'abs_{}'.format(i): 'abs(datum.num_{})'.format(i) for i in range(1, 4)}
).transform_window(
# 累積値に変換
**{'cumsum_{}'.format(i): 'sum(abs_{})'.format(i) for i in range(1, 4)},
frame=[None, 0]
).transform_calculate(
# 色分け用のダミー列
**{'col_{}'.format(i): '"num_{}"'.format(i) for i in range(1, 4)}
).encode(
x='time:T',
)
alt.layer(
c.mark_line(strokeDash=[20,5]).encode(alt.Y('cumsum_1:Q', title='num_1', scale=alt.Scale(type='log')),
alt.Color('col_1:O', scale=scale_color_cud)),
c.mark_line(strokeDash=[5, 5]).encode(alt.Y('cumsum_2:Q', title='num_2'), color='col_2:O'),
c.mark_line(strokeDash=[10, 3, 3]).encode(alt.Y('cumsum_3:Q', title='num_3'), color='col_3:O')
).properties(width=800, height=200, title='時系列グラフ').interactive()
ソースコードを表示
alt.vconcat(
c.mark_line(strokeDash=[20, 5], color=cud_rgb_hex[0]).encode(alt.Y('cumsum_1:Q', scale=alt.Scale(type='log'))).properties(width=800, height=100).interactive(),
c.mark_line(strokeDash=[5, 5], color=cud_rgb_hex[1]).encode(alt.Y('cumsum_2:Q', scale=alt.Scale(type='log'))).properties(width=800, height=100).interactive(),
c.mark_line(strokeDash=[10, 3, 3], color=cud_rgb_hex[2]).encode(alt.Y('cumsum_3:Q', scale=alt.Scale(type='log'))).properties(width=800, height=100).interactive()
).properties(title='時系列グラフ')

seaborn
- https://seaborn.pydata.org/index.html
- チュートリアル: https://seaborn.pydata.org/tutorial/relational.html
- 詳しい日本語の解説です。これも岩嵜 航 (heavy_watal) 氏によるものです: 『
matplotlib + seaborn — Pythonでグラフ描画
』
長所
-
seaborn.heatmap()とかseaborn.violinplot()とか、統計学によく使われるグラフをそのままな名前のメソッド1つだけで描画できることが多いです。 - デフォルトのデザインの色彩や縮尺が見やすく、洗練されています。
- ここで紹介したパッケージの中では (比較的) 日本語情報もあります。
短所
-
matplotlibの代わりというより、matplotlibの機能拡張というべき存在です。- よく使うグラフを描くのは楽ですが融通がききません。グループ別集計やデザインの調整のために結局
matplotlibを使わなければならない場面が多いので、matplotlibに習熟する必要があります。 - 画像の大きさを変更するような簡単な調整も
matplotlibに依存しています。 - デフォルトでは日本語表示できないのも
matplotlibと同じです。
- よく使うグラフを描くのは楽ですが融通がききません。グループ別集計やデザインの調整のために結局
- インタラクティブな拡大縮小ができません12
- 構文が統一的ではないです。pandas データフレームを受け付ける場合もあれば、1次元配列しか受け付けない場合もあります。
- メソッド名が少し紛らわしい (
pointplotとscatterplotなど) です。 - (単に静止画を出力するだけというにもかかわらず) 入力データが大きいとクラッシュすることが気持ち多いです。
ソースコードを表示
import matplotlib.pyplot as plt
import seaborn as sns
# デフォルトで colorblind パレットを使用するように
sns.set(palette='colorblind')
# 日本語表示設定
plt.rc('font', family='IPAGothic')
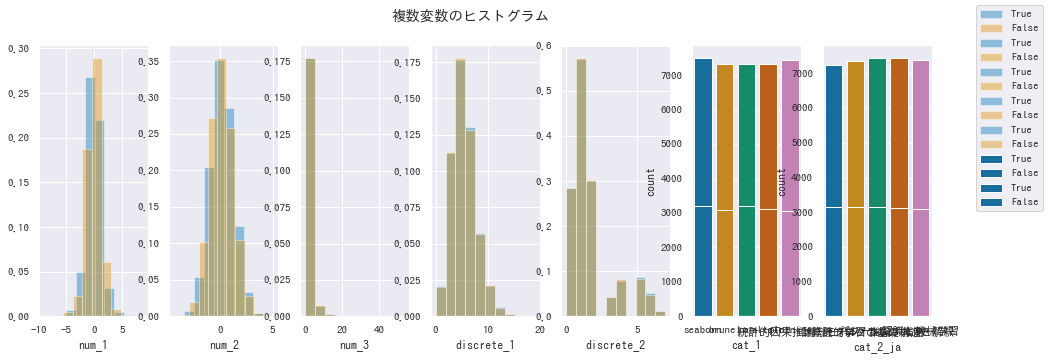
複数変数のヒストグラム
-
seabornでは、グラフのグループ別集計機能が充実していません。-
FacetGrid()は入力データの件数が多いと失敗することが多く、実用的ではありません (原因未特定)。そのため、早くもmatplotlibに頼ることになります。
-
-
norm_histでy軸をカウントか相対頻度かを指定できるのでその点は楽です。 - しかし、カテゴリカル変数のヒストグラムが非常に見づらいです。 これを見やすく調整するには
matplotlibに習熟している必要があります。
ソースコードを表示
cols = ['num_1', 'num_2', 'num_3', 'discrete_1', 'discrete_2', 'cat_1', 'cat_2_ja']
fig, axes = plt.subplots(ncols=len(cols), nrows=1, figsize=(16, 5))
for col, ax in zip(cols, axes):
if df_large[col].dtype in [int, float]:
sns.distplot(df_large.query('is_train')[col], bins=10, kde=False, norm_hist=True, label='True', ax=ax)
sns.distplot(df_large.query('~is_train')[col], bins=10, kde=False, norm_hist=True, label='False', ax=ax)
elif df_large[col].dtype == 'O':
sns.countplot(x=col, data=df_large.query('is_train'),label='True', ax=ax)
sns.countplot(x=col, data=df_large.query('~is_train'), label='False', ax=ax)
plt.suptitle('複数変数のヒストグラム')
fig.legend()
plt.show()
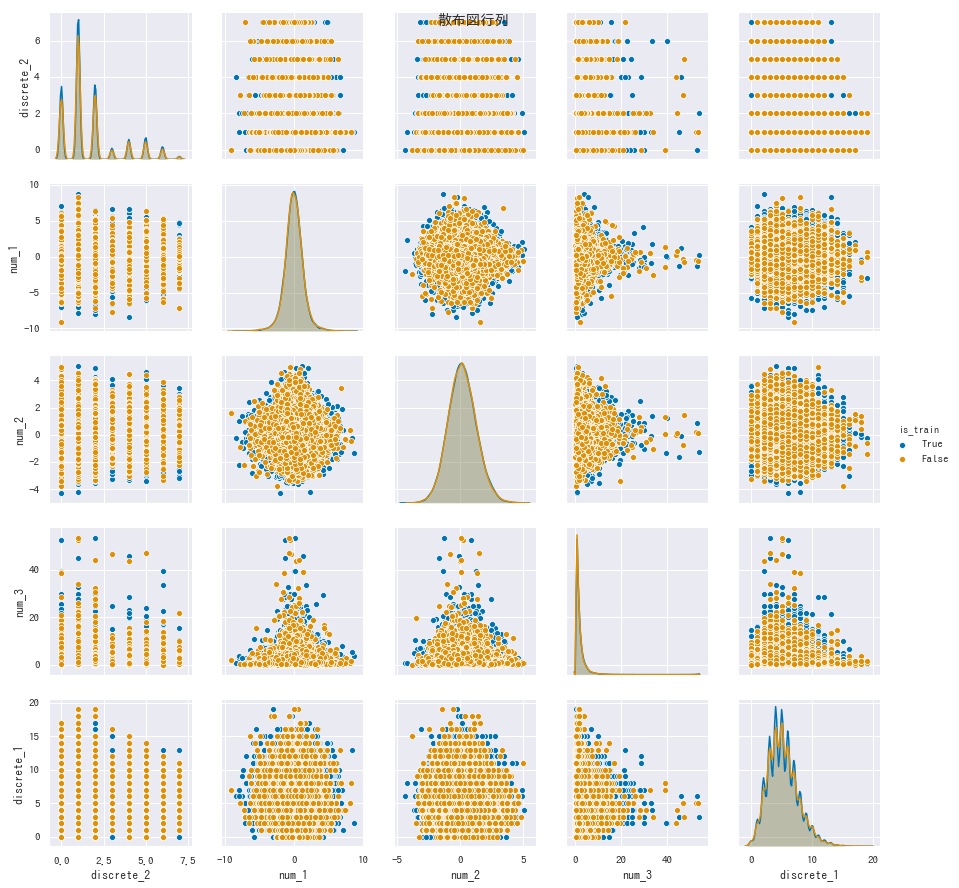
散布図行列
- seaborn ver. 0.9 の
.pairplot()では入力データの全ての int, float, bool 型のみで作成します。 - しかし、
hue=で指定してある変数も対象に入れてしまいます。
sns.pairplot(data=df_large.iloc[:1000], hue='is_train)
はエラーが出ます。そこで、以下のように str に変換しています。
- カテゴリカル変数の散布図は、
.catplot()などを使います (notebook 掲載)。
sns.pairplot(df_large.assign(is_train=df_large['is_train'].astype(str)),
hue='is_train')
plt.suptitle('散布図行列')
plt.show()
複数の箱ひげ図・バイオリンプロット
- 以前は
matplotlibと併用すると箱ひげ図の外れ値が表示されなくなるという問題がありましたが、 現在 (ver. 0.8 以降) は修正されました。 - コードがほぼ同じなのでバイオリンプロットは notebook にのみ掲載します。
ソースコードを表示
cols = ['num_1', 'num_2', 'num_3', 'discrete_1']
fig, axes = plt.subplots(ncols=len(cols), nrows=1, figsize=(16, 5))
for col, ax in zip(cols, axes):
sns.boxplot(data=df_large, x='is_train', y=col, ax=ax)
ax.set_title(col)
ax.set_ylabel('')
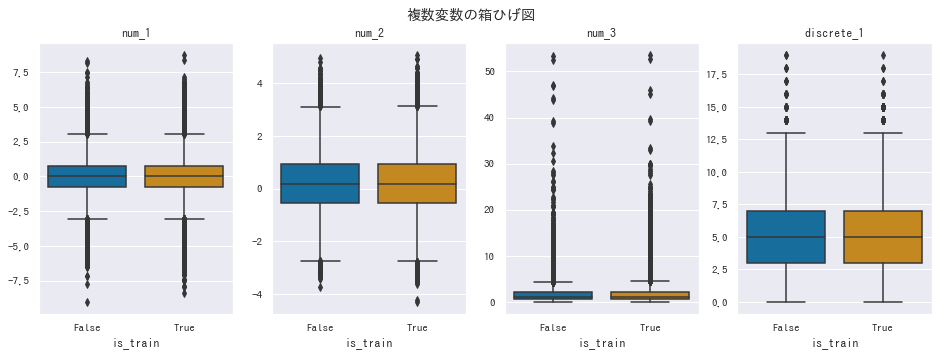
plt.suptitle('複数変数の箱ひげ図')
plt.show()
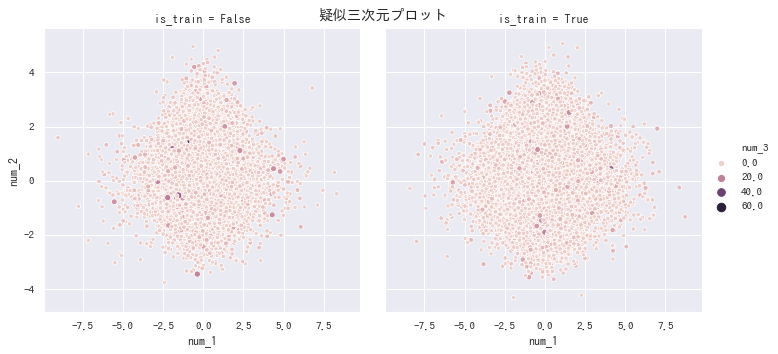
疑似三次元プロット
-
scatterplot()とFacetGrid()を使ってグループ別に書く場合、データが大きいとだいたい失敗します。しかし、2変数の関係をプロットする,relplot()なら安定して動作します。 -
seabornで色やサイズのグラデーションのスケール変換する方法はなさそうです。 -
seabornには等高線をプロットするメソッドがありません。 -
kdeplot()で2次元分布の密度を推定し、等高線を描けます。
plt.figure(figsize=(16, 5))
sns.relplot(data=df_large, x='num_1', y='num_2', hue='num_3', size='num_3', col='is_train')
plt.suptitle('疑似三次元プロット')
plt.show()
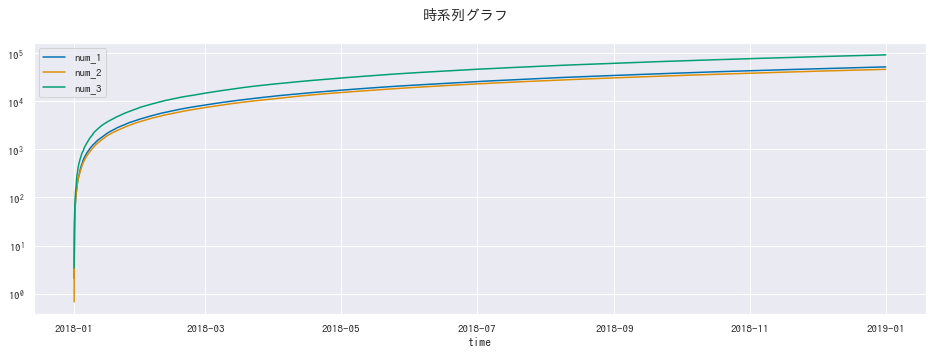
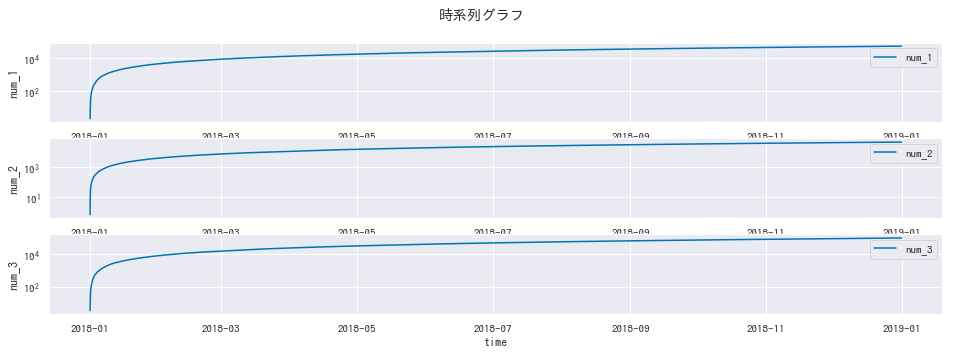
時系列グラフ
- ver. 0.8 までは
tsplot()は日付のプロットができませんでしたが、 0.9 以降はlineplot()で時系列データに対応しました。 - ただし、日付の表示フォーマットを変更はできません。
- エポック秒に変換し、
matplotlibの locator で、 ... という面倒な手順を踏むことになると思います (面倒なので検証していません)。
- エポック秒に変換し、
-
seabornには数値を集計加工する機能がないため、入力の時点で累積値を計算しておく必要があります。 - 対数スケールへの変換も、
matplotlibのメソッドを利用します。 -
seabornにはエリアプロット機能がないため、積み上げグラフを作ることはできません。
ソースコードを表示
# overray
cols = ['num_1', 'num_2', 'num_3']
fig, ax = plt.subplots(figsize=(16, 5))
for col in cols:
sns.lineplot(x=df_large['time'], y=np.cumsum(df_large[col].abs()), label=col, ax=ax)
plt.suptitle('時系列グラフ')
ax.set_ylabel('')
ax.set(yscale='log')
plt.show()
# facet
cols = ['num_1', 'num_2', 'num_3']
fig, axes = plt.subplots(nrows=len(cols), figsize=(16, 5))
for col, ax in zip(cols, axes):
sns.lineplot(x=df_large['time'], y=np.cumsum(df_large[col].abs()), label=col, ax=ax)
ax.set(yscale='log')
plt.suptitle('時系列グラフ')
plt.show()
まとめ
冒頭に挙げた要件の結果を表にまとめてみます。
- 構文が分析の軸の増加に対してスケーラブルであること。
- EDAに必要な様々なグラフを描く機能が用意されていること。
- 様々なデータ型にも対応できること
- ミニマルなデザインのグラフであること
- グラフを拡大縮小する機能があること
- ある程度の計算・集計機能があること
| name | (1) スケーラブル | (2) グラフの種類 | (3) データ型 | (4) デザイン | (5) 拡大縮小 | (6) 集計機能 |
|---|---|---|---|---|---|---|
plotnine |
△ | ◯ | ◯ | △ | x | △ |
altair |
△ | △ | ◯ | ◯ | ◯ | ◯ |
seaborn |
x | △ | ◯ | △ | x | x |
各パッケージ一長一短です。構文が楽なものほど融通が効かず、自由度の高いものほど細かい設定を必要とする傾向があります。seaborn は時系列データ関連の機能が充実しておらず、また matplotlib 依存も強いので使いづらいです。同じ matplotlib 依存なら、seaborn よりも pandas データフレームのプロット機能のほうが手軽かもしれません。しかし、plotnine と altair も万全かというとそうでもありません。
個人的には、
-
plotnineが本家ggplot2に近づき、 かつgridExtraやpatchworkと同等の機能を持ち、 かつ色彩や配置バランスの自動調整機能がつく -
altairが箱ひげ図、バイオリンプロット、等高線などvega-liteの機能を全てサポートし、複雑なコードを書く場面が減る
のいずれかが達成されればだいぶ不自由がなくなると思います。plotnine にはいくつか修正困難な問題があるようなので、実現の見込みがより大きいのは後者のような気がします。
実は、seaborn 風な構文の vega-lite の APIを提供する seaborn_altair というパッケージもあります。しかしながら、まだまだ開発途上で、サポートしているグラフの種類は少ないです。
しかし、 seaborn は、仮に matplotlib で書こうとすると細かいデザインの調整が面倒になるようなグラフの描画コードを簡単に書けます。そのため、既に matplotlib に習熟していて書くことに抵抗がないのなら、結局 matplotlib を使ったほうが手っ取り早いとも考えられます。一方で、軸がいくつもある複雑なグラフを作成する場合は、altair や plotnine のほうが簡単になってくると思います。
補足: pixiedust について
- https://github.com/pixiedust/pixiedust
- @ishida330 氏による日本語での紹介: 『Jupyter/Python上でたった3行でインタラクティブなチャート・ウィジェットを作れる!PixieDustを触ってみた』、『Jupyter/Pythonでデータ分析する人にお勧めしたい!便利なライブラリー「PixieDust」をザクッと紹介します』
- IBM が開発したパッケージです。
- 利用には JRE が必要です。
- なぜ補足として紹介したかと言うと、これはここまで紹介したパッケージをインタラクティブな GUI で作図するツールだからです。
-
bokeh,brunel,seaborn,matplotlibなどは、このpixiedustを介して操作できます。 - ただし各パッケージのあらゆる機能を使えるわけではありません。
-
bokehは比較的サポートしている機能が多く、かつ素の構文が面倒なので、bokehで描画すると良さそうです。
-
- 今回想定しているような複雑な設定はしづらいですが、もう少しシンプルなグラフでよいならかなり楽に作成できます。
import pixiedust
display(df_large)
-
当初はこの3つに加えて
brunelというパッケージも調査していましたが、他と比べて制約が多いため、この記事からは割愛することにしました。後述の gist にはbrunelの作例も掲載しています。また、これ以外だとbokehというものが比較的有名ですが、構文が煩雑で後述する要件を全く満たしていないため、紹介しません。 ↩ -
やや古いですが、林 知己夫 (1989) 『データ解析の考え方』でははじめ Tukey が提唱した EDA に対してそのように位置づけています。ただし、今回私が意図した使い方は、厳密な意味での EDA と完全一致するわけではありません。 ↩
-
データ分析をやらないエンジニアでも、ふだんモニタリングしてない数値データを手早く加工して視覚化したい、営業なら KPI をダッシュボードと違う切り口で確認したい、というときに役に立つかも知れません。 ↩
-
今回は、Chromatic Vision Simulator などを利用してグラフの見え方を確認しました。しかしながら、色盲にも個人差があり、印刷やディスプレイなど、媒体ごとにも発色に差があると言われているため、万全なものは保証できませんが、カラーユニバーサルデザイン推奨配色セット を参考にしています。 ↩
-
しかしながら、 Python に限って言えば
pandasがあるので、この機能はあまり重要でないかもしれません。実際、今回あげたパッケージにはこの機能のないものも多いですが、pandasで代替できたり、機能があってもpandasのほうが便利だったりします。 ↩ -
matplotlib に依存しているため、 jupyter 上であれば
%matplotlib notebookが使えます。しかし、あまり操作感覚は良くないです。 ↩ -
一方で、 yhat の
ggplotはmatplotlibのsubplots()と組み合わせられるようです。 ↩ -
Google Colaboratory の場合は、 Colaboratoryでmatplotlibの日本語表示 の方法でフォントを利用できます。 ↩
-
ggplot2のデフォルトはposition='identity'ですが、こちらはなぜかデフォルトの設定が'stacked'になっています。 ↩ -
箱ひげ図のヒゲ (whisker) の書き方には、(1) 最大・最小値、(2) +-1.5 IQR, (3) 5%, 95%点、 (4) 平均+-標準偏差、などいくつかバリエーションがあります。 ↩
-
|演算子や|=演算子も、Chartオブジェクトの水平方向の連結として定義されています。同様に、&,&=は垂直方向の連結、+,+=はオーバーレイとして定義されています(参考)。 ↩ -
plotnineと同様、matplotlib依存なので%matplotlib notebookを使うことはできますが、使い勝手は良くないです。 ↩