
TL;DR
Python環境でpip install pixiedustでインストール後、Jupyter起動してこの3行書くだけで
import pixiedust
df = pixiedust.sampleData(Data-URL) # pandas or Spark Dataframe
display(df)
こんなウイジェットができて対話式にデータを分析できます。簡単すぎ!

PixieDustって何?
PixieDustは簡単ですけど結構機能が広いライブラリーなので、ざっくり概要=What isは「Jupyter/Pythonでデータ分析する人にお勧めしたい!便利なライブラリー 「PixieDust」をザクッと紹介します」の記事に書きました。ご興味あればそちらをご参照ください。当記事はインタラクティブなチャート・ウィジェット周りの使い方(How-To)にフォーカスします。
まずはAPIを2つ知ってれば十分
Pixiedustで主に知っている必要があるAPIは基本、2つだけです.
- データをインポートするためのsampleData(URL) - 利用は任意
- データを可視化するためのdisplay(df) - 必須
しかありません。ややこしいパラメータも殆どありません。
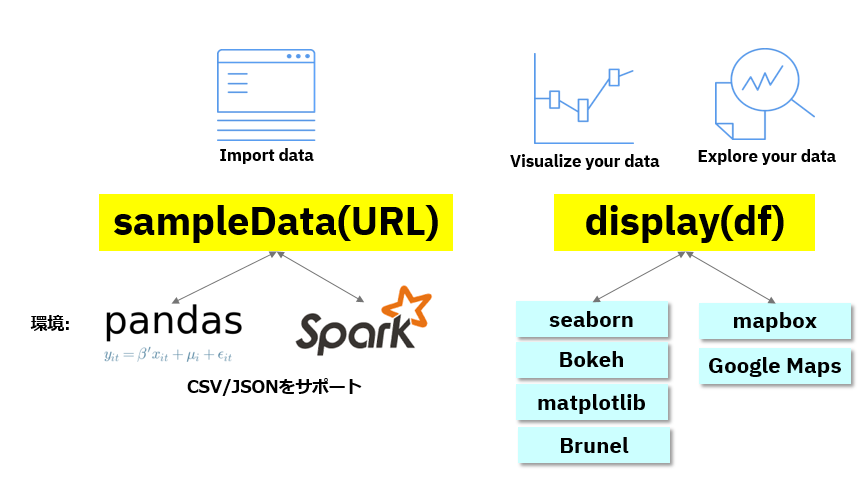
-
PixieDustはpandasとSparkのDataFrameを両方サポートしています
-
入力データについて言うと、通常はCSVやJSONを読んでDataFrameにする場合、pandasかSparkかでコードの書き方は違いますよね。PixieDustは両者の違いを**sampleData(URL)**で隠蔽してくれます
-
同様にチャートや地図を用いた可視化を行う際もmatplotlib/Bokehなど著名なライブラリーの書き方は微妙に違いますが、PixieDustではdisplay(df)だけです。ウイジェットが起動したらあとは対話式に描画エンジンを切り替えることができますので、色々なライブラリーの文法を知らなくてもOK=エンドユーザー様でも分析が行えます。
分析対象データの作り方(Load Data)について、もうすこし細かく
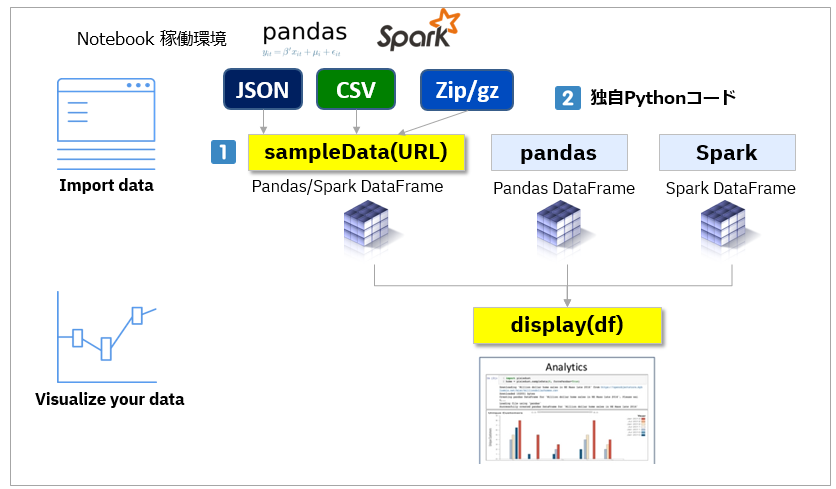
- (1)のsampleData()というAPIを使うと楽ですが、必須ではありません。(2)のように自分で好きな方法でpandasかSparkのDataFrameを組み立て、それをdisplay(df)に渡すこともできます。sampleData()とdisplay()をペアで必ず使う必要があるわけではありません
- (1) sampleData(URL)は引数のURLでファイルの所在を指定します
- http://~/hoge.csvやfile://~/hoge.json等
- ファイルはCSVとJSONをサポート
- ファイルが圧縮されzip/gzの拡張子の場合は自動的に解凍
- ZIPで複数ファイルの場合は先頭のファイルを利用
- sampleData()の出力のDataFrameがpandasのDataFrameになるか、SparkのDataFrameになるかはNotebook環境のSpark有無で決まります。pysparkで起動した場合などSpark環境下の場合はDataFrameもSparkになります。(引数でforcePandas=Trueを指定すれば強制的にpandasのDataFrameにできます)
- 例:
dataframe = pixiedust.sampleData(data_url, forcePandas=True)
- 例:
![]() ここまでの説明でご推察のとおり、PixieDust自身はレンダリング(描画)エンジンを持っていません。グラフやチャートの描画自体はmatplotlibやbokehなどのライブラリーに「ヨロシク!」ってことで委任しています。データの読み込みについても同様。要は**PixieDustは様々な著名オープンソースの違いを隠蔽し、誰でも簡単に使えるようにしてくれる「便利なブローカー」**だとご理解いただくのがいいと思います。
ここまでの説明でご推察のとおり、PixieDust自身はレンダリング(描画)エンジンを持っていません。グラフやチャートの描画自体はmatplotlibやbokehなどのライブラリーに「ヨロシク!」ってことで委任しています。データの読み込みについても同様。要は**PixieDustは様々な著名オープンソースの違いを隠蔽し、誰でも簡単に使えるようにしてくれる「便利なブローカー」**だとご理解いただくのがいいと思います。
やってみる
以下、インストールと基本的な操作を流してみましょう。
前提環境
以下をインストールしてある環境。最近流行ってる Jupyter Notebook/Pythonでデータ分析するなら普通の環境ですので説明は割愛します(condaで楽勝かと)
- Jupyter Notebook
- Python(2.7 or 3.5)
- Pandas and/or Spark
- (必須) matplotlib / (オプション) Bokeh/Seaborn/Brunel
![]() 前提は「全部を導入せねばならない」わけではありません。扱うデータがPandasだけで足りるならSparkは不要ですし、グラフ・チャートのレンダラーもmatplotlibさえあれば残りはオプション(無ければメニューで選べないだけ)です。
前提は「全部を導入せねばならない」わけではありません。扱うデータがPandasだけで足りるならSparkは不要ですし、グラフ・チャートのレンダラーもmatplotlibさえあれば残りはオプション(無ければメニューで選べないだけ)です。
インストール
ドキュメント 「Install PixieDust」に書いてありますが1、要はpip install pixiedustでインストールするだけ、でいいと思います。(特にSparkなし=Jupyter/Python/Pandasの典型的なパターンなら)
(py36) root@ubuntu:~# pip install pixiedust
Collecting pixiedust
Downloading https://files.pythonhosted.org/packages/a8/d1/e3df504005abd892fc5ddfabcb23f5d1fc4d74290f0efe4767e23293d9f5/pixiedust-1.1.11.tar.gz (190kB)
100% |████████████████████████████████| 194kB 959kB/s
Collecting mpld3 (from pixiedust)
Downloading https://files.pythonhosted.org/packages/91/95/a52d3a83d0a29ba0d6898f6727e9858fe7a43f6c2ce81a5fe7e05f0f4912/mpld3-0.3.tar.gz (788kB)
100% |████████████████████████████████| 798kB 302kB/s
<<途中省略>>
Running setup.py bdist_wheel for mpld3 ... done
Stored in directory: /root/.cache/pip/wheels/c0/47/fb/8a64f89aecfe0059830479308ad42d62e898a3e3cefdf6ba28
Successfully built pixiedust mpld3
Installing collected packages: mpld3, lxml, geojson, astunparse, markdown, colour, pixiedust
Successfully installed astunparse-1.5.0 colour-0.1.5 geojson-2.4.0 lxml-4.2.4 markdown-2.6.11 mpld3-0.3 pixiedust-1.1.11
(py36) root@ubuntu:~#
データのロード
![]() ドキュメント:Load Data
ドキュメント:Load Data
Jupyterを起動して以下を実行します
import pixiedust
df = pixiedust.sampleData()
引数なしのsampleData()ではサンプルデータの一覧が表示されます
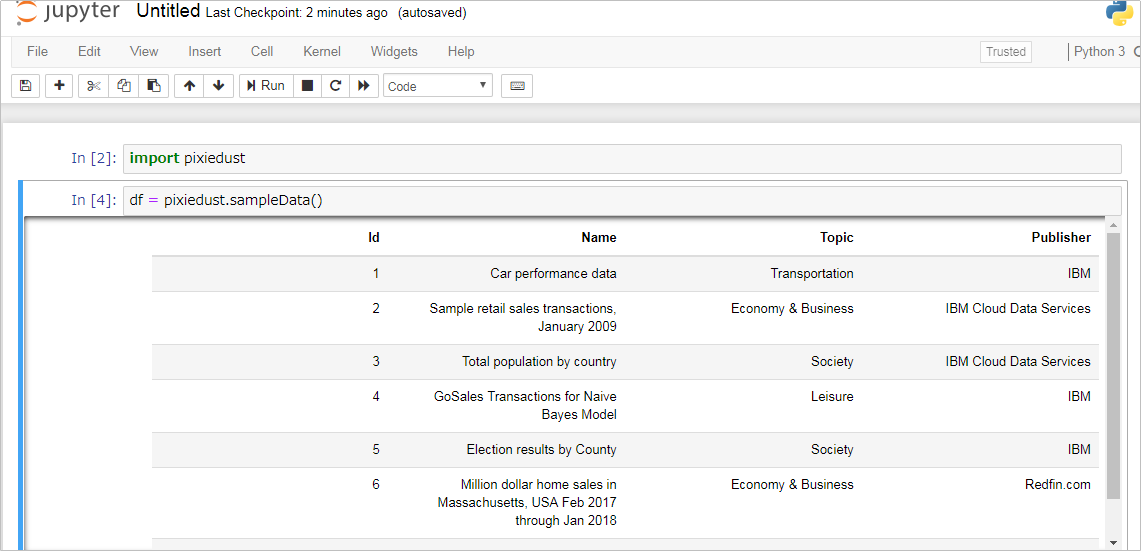
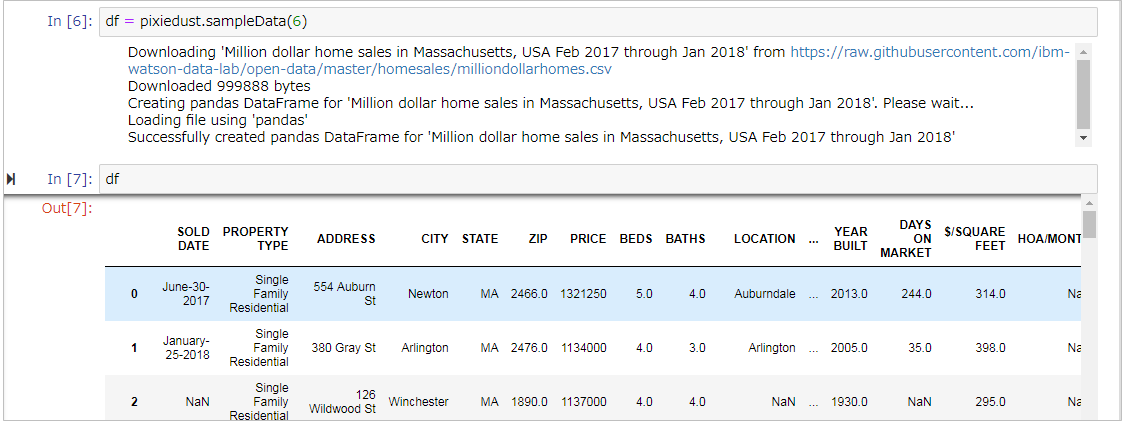
6番目の住宅価格(Million dollar home sales in Massachusetts, USA Feb 2017 through Jan 2018)のデータを使いましょう。引数に6を設定します。
df = pixiedust.sampleData(6)
データがダウンロードされ、PandasのDataFrameになります

![]() 上記はサンプルデータを使いましたが、実際はURLにファイルの所在を書きます。以下のような感じです。
上記はサンプルデータを使いましたが、実際はURLにファイルの所在を書きます。以下のような感じです。
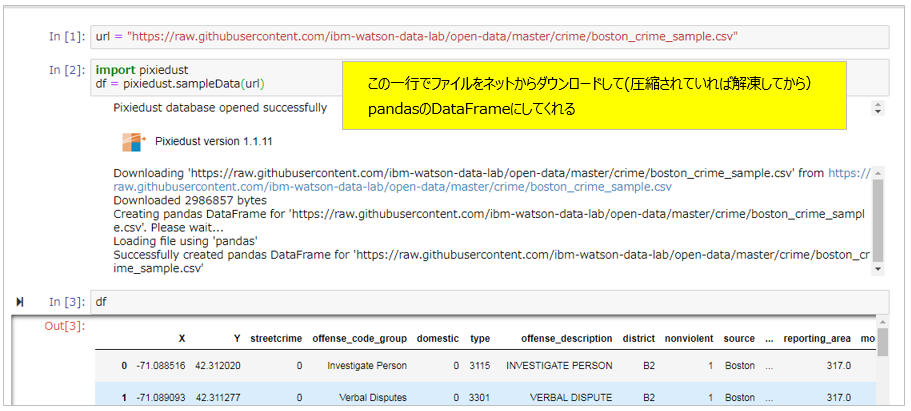
データの表示
![]() ドキュメント:Display Data
ドキュメント:Display Data
display(df)でPandasのDataFrameを渡すとウイジェットが表示されます。
display(df)
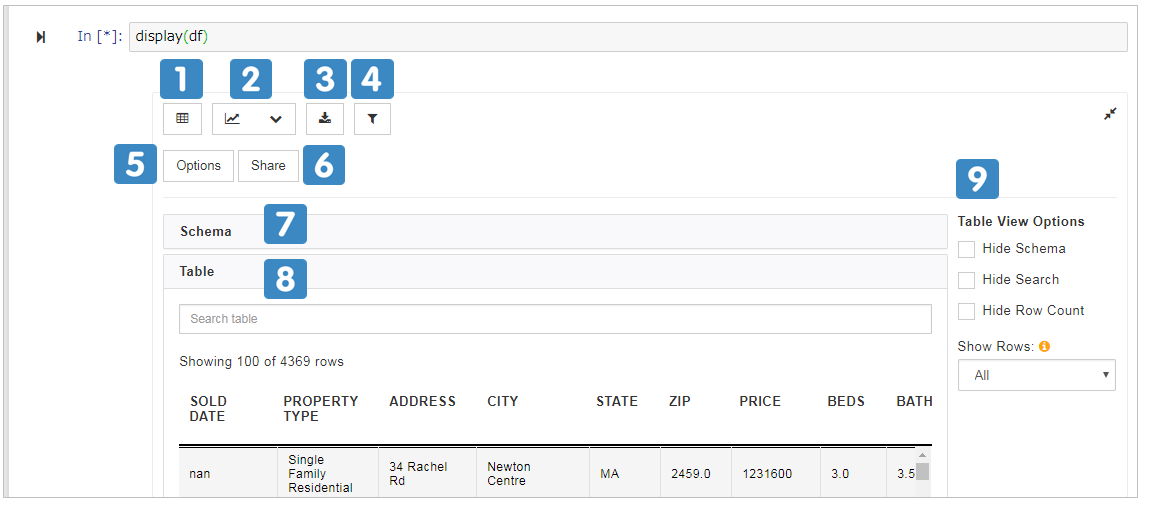
| # | 説明 |
|---|---|
| 1 | 表形式でデータフレームを表示します |
| 2 | チャートの種類を選択します |
| 3 | データをエクスポートします |
| 4 | データをフィルターで絞り込みます |
| 5 | X軸・Y軸、件数などの設定 |
| 6 | PixieAppとしてセルの内容をWeb公開/シェアします |
| 7 | データのスキーマ |
| 8 | データの表示領域 |
| 9 | 表示に即したサブメニュー |
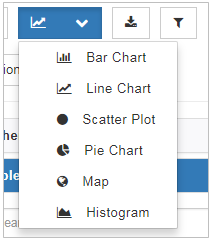
(2) チャートの種類
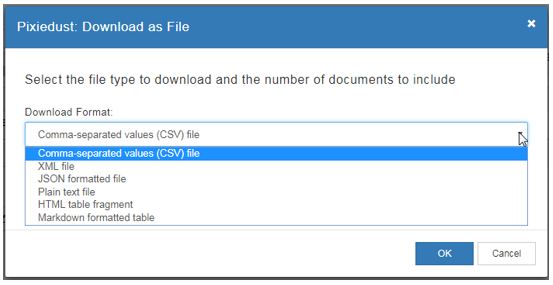
(3) データのエクスポート
(4) データをフィルタ~表示対象データを絞込み/統計値も見られます
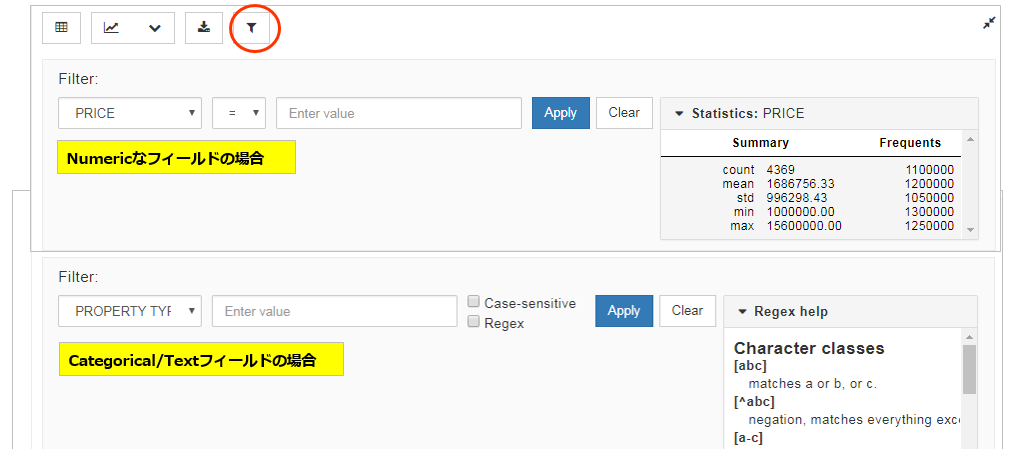
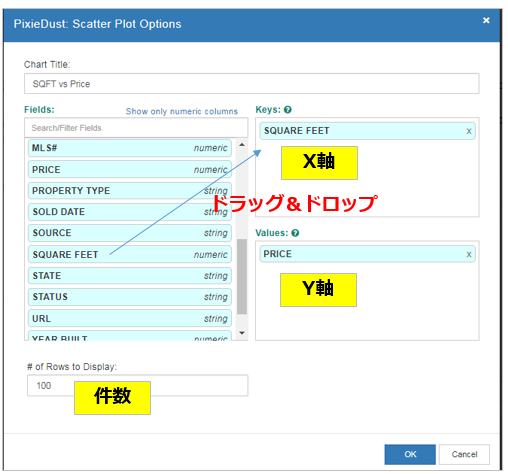
(5) オプションの指定
グラフ
「Scatter Plot」を選び、「オプション」で上記のようにX軸=SQUARE FEET(広さ) Y軸=PRICE(価格)を設定します。
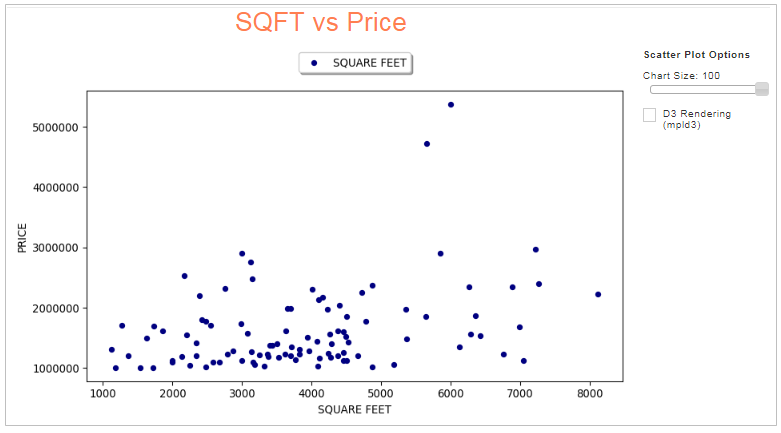
matplotlibのチャートが表示されました。
レンダラーをbokehに切り替えると、点の色やチャートの移動・拡大・縮小などができるようになります。
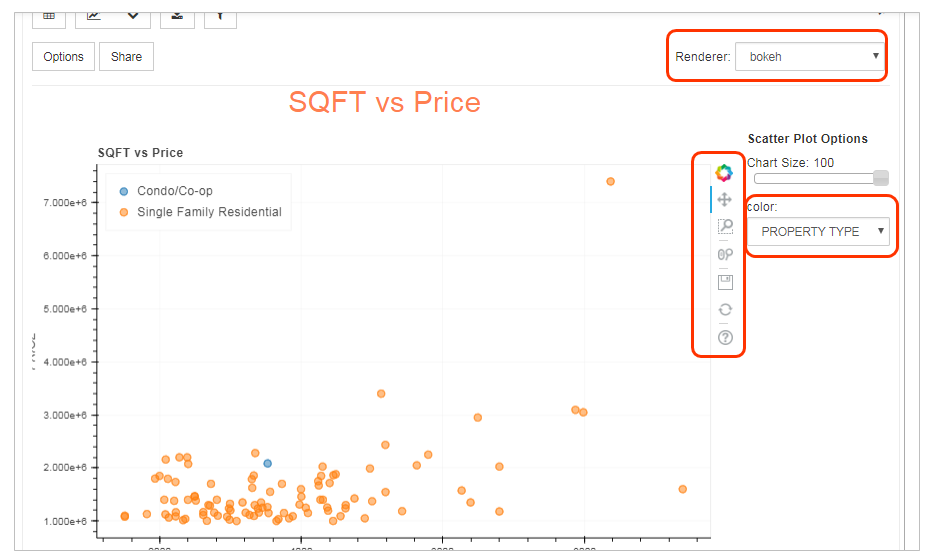
レンダラーをseabornに切り替えると、kindで色々な表示形式を選べます。
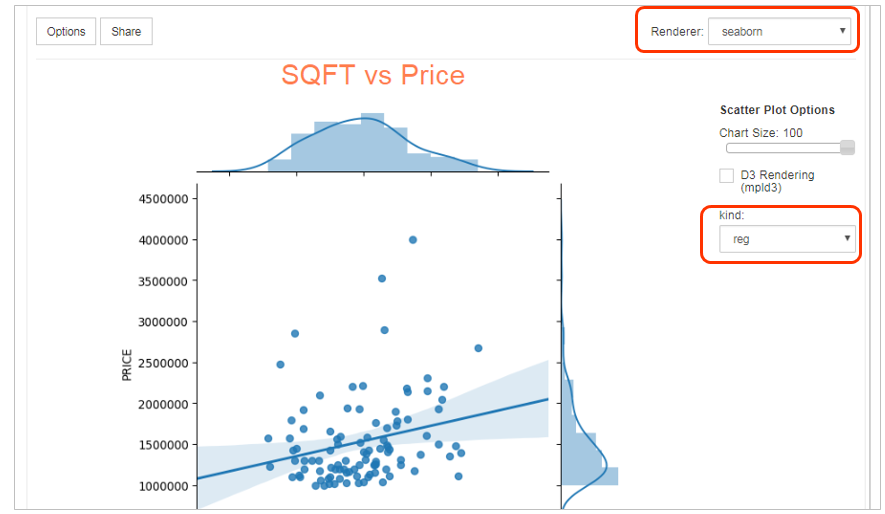
![]() matplotlib以外のレンダラーはオプションです。導入されていなければメニューに表示されません。
matplotlib以外のレンダラーはオプションです。導入されていなければメニューに表示されません。
チャートやデータを変えて、色々触ってみてください。
マップ
次はマップを見ます。マップはチャートと違って、MapboxとGoogle Mapsではできることが異なります。
- GoogleMapsでは国名、都市名などのデータを軸に設定したGeoChartを作れます。(がそれ以外のマップやチャートは作れません)
- MapBoxでは緯度/経度データを用いて細かい地図情報を操作できます
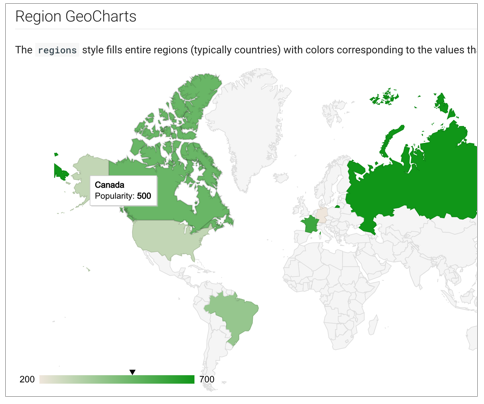
Google MapsのGeoChart
すいません、API Keyがうまく認識されないので「こんなの」という絵だけ貼って終わりにします。「オプション」で地名や国名をX軸に設定します。
MapBox
チャートの種類からMapを選び、「オプション」のX軸に緯度/経度(Latitube/Longitude)を選定します。MapboxのAccess Tokenは今はデフォルトで設定されているものでもかまいません。
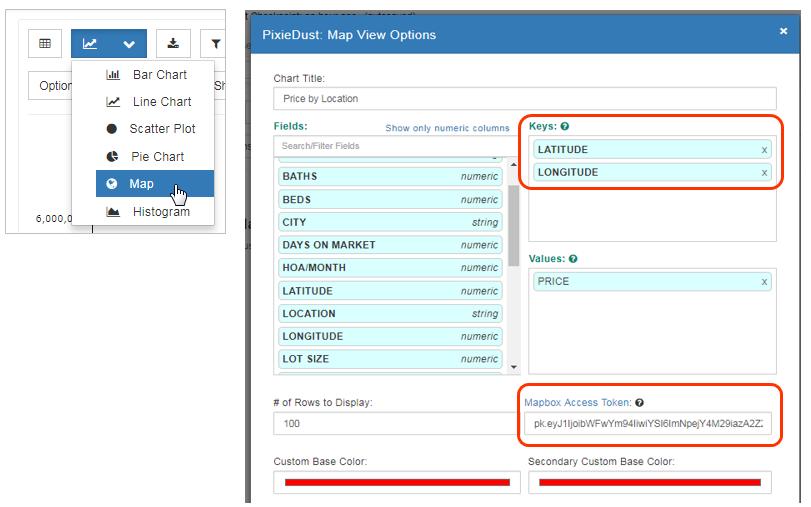
右側のペインで見映えや縮尺を変更できます。

![]() ブログ「 Mapping for Data Science with PixieDust and Mapbox」に紹介あります。
ブログ「 Mapping for Data Science with PixieDust and Mapbox」に紹介あります。
以上、2-3行で簡単にインタラクティブなチャートウィジェットがつくれました。あとはあれこれ触ってみてください。「これだけで探索的データ分析(EDA)ができる!」とまでは申しませんが、チャートの描画がすごく楽なので、pandasの本体の機能やpandas_profilingなどど併用すればいいのかなと思います。
Tips
チャートの設定を毎回一からやるの面倒..
Pixiedustではチャートの設定はJupyter Notebookのセルのメタデータとして保管していますので、再起動してもチャートは残っています。セルを再実行すれば描画は再現されます。(毎回一から設定し直し、というわけではありません)
とはいえ別のシートやセルに設定をコピーしたい場合もあるかと思います。その場合は以下の手順で設定をメタデータとして表示・編集できます。(別途ご紹介予定のPixieAppsではメタデータを使います)
Jupyter Notebookメニューの「View」-「Cell Toolbar」-「Edit Metadata」
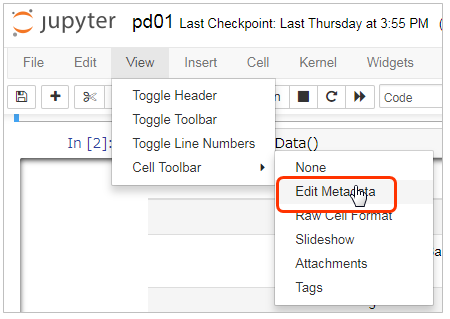
すると各セルの右上にボタンが表示されます
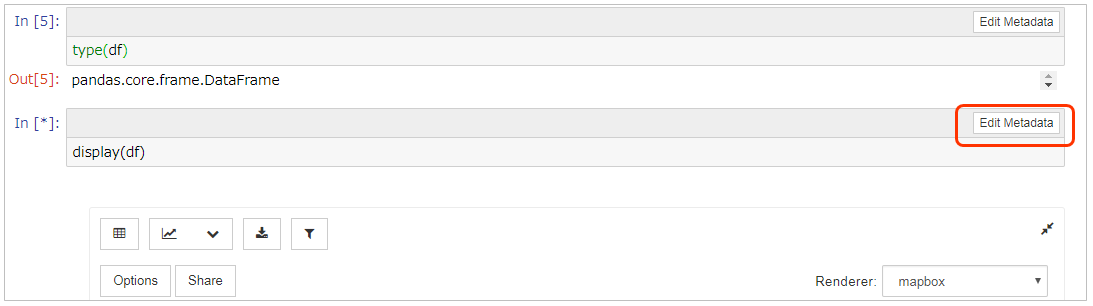
ボタンを押すと現在の設定がjsonで保存されているのが見られます
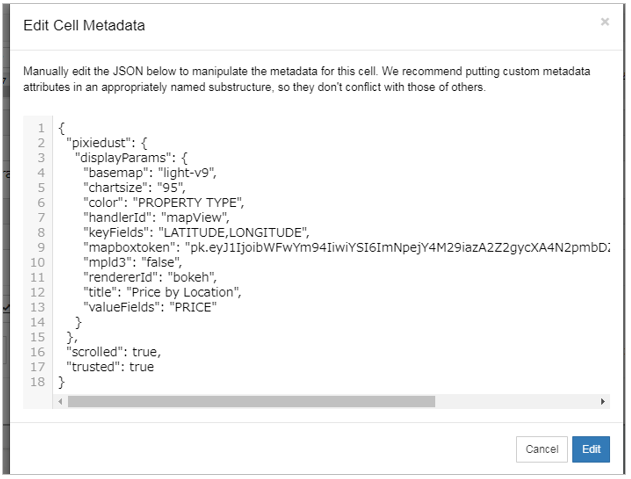
このテキストを別のセルのメタデータにコピペするとチャートが再現します
ログ
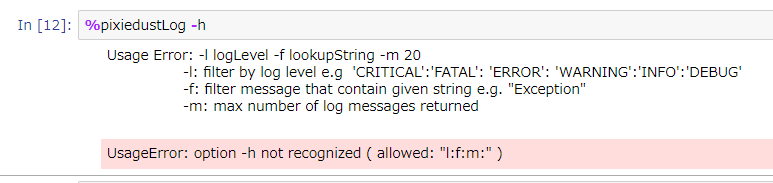
たまにエラーで描画が失敗したりするケースがあります。その場合は以下のセルマジックでログを表示できます。問題判別に便利です。
%pixiedustLog -l debug
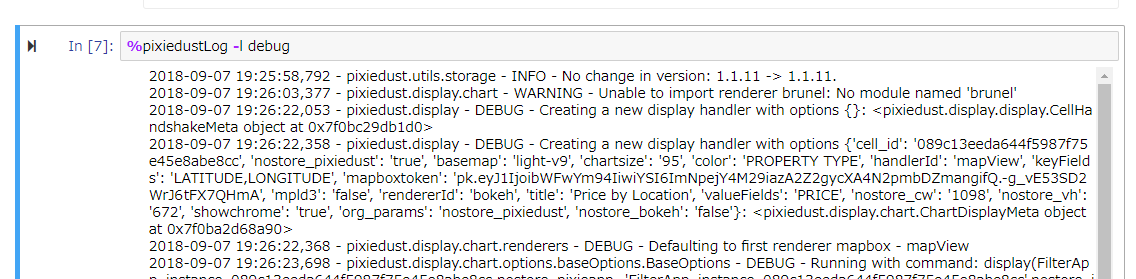
パラメータは下記
以上です。PixieDustは実はウィジェット以外にも豊富な機能を持ったライブラリーです。その全容を知りたい方は記事「Jupyter/Pythonでデータ分析する人にお勧めしたい!便利なライブラリー 「PixieDust」をザクッと紹介します」もご参照ください。
-
ドキュメントにはmac前提とかJava入れろとかJupyter_Kernel入れろとか書いてあるんですが、ubuntu16.04ではやらなくても特に問題なし、でした。ネタ本「Thoughtful_DataScience」にも特に書いてなかったです。Java入れろとか、Spark/Scalaを意識したもの? ↩