当たり前の話だったら超恥ずかしいのですが、初めて知って驚愕したのでご紹介。
タイトルのとおり、pandas-profilingが探索的データ解析(EDA)にめちゃめちゃ便利だったのでご紹介するだけの記事です。
pandas-profilingの詳細はこちらからご確認を。
pandas-profiling
準備
pipやAnacondaを使うなどして、適宜ご自身の環境にインストール。
pip install pandas-profiling
あとはインポートするだけ。
import pandas as pd
import pandas_profiling as pdp
実行
みんな大好きTitanicのtrainデータを使用。
なんの前処理もかけずに実行してみる。
df = pd.read_csv('train.csv')
pdp.ProfileReport(df)
Output
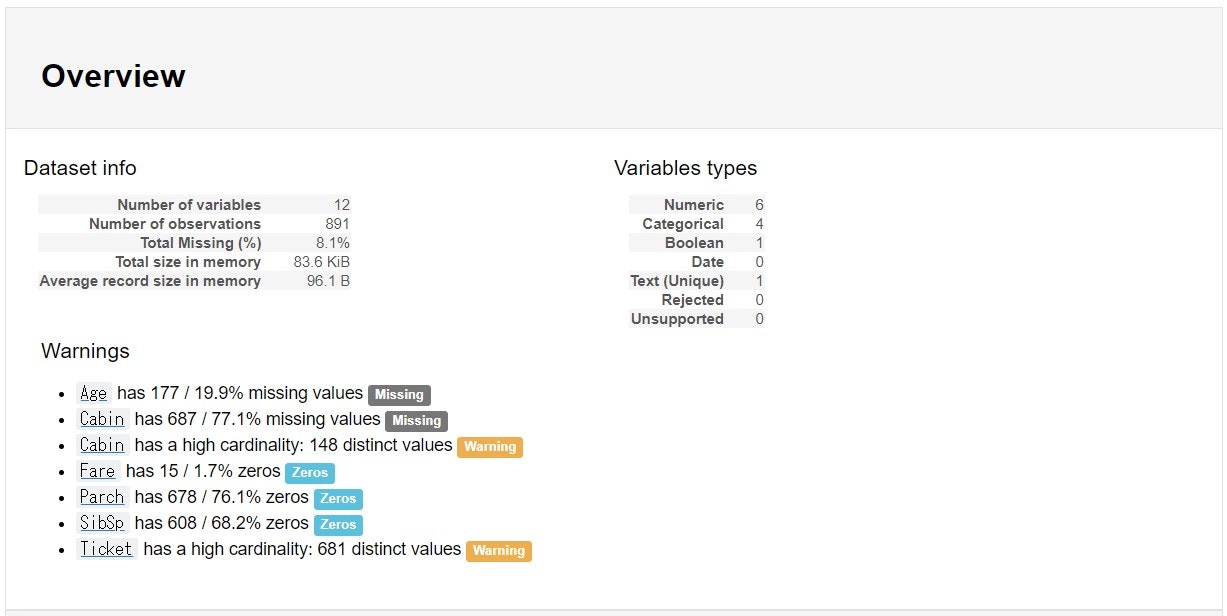
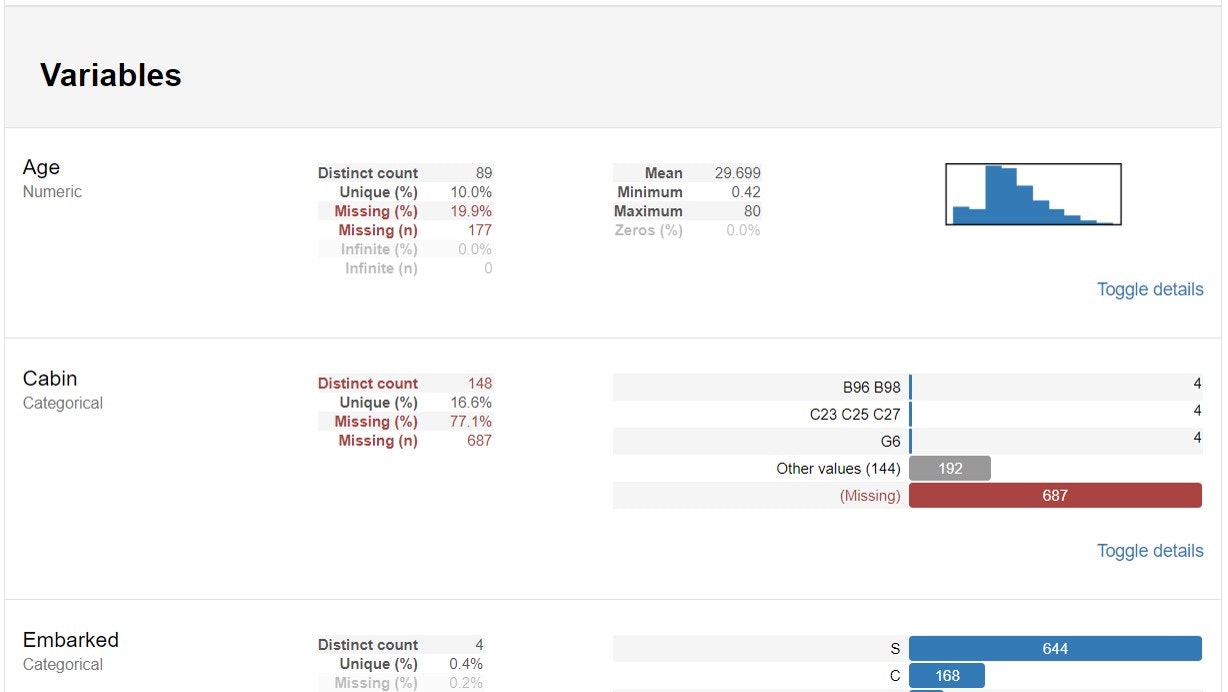
こんな感じでデータの全体像をHTMLで出力してくれます。便利。
画像
gif
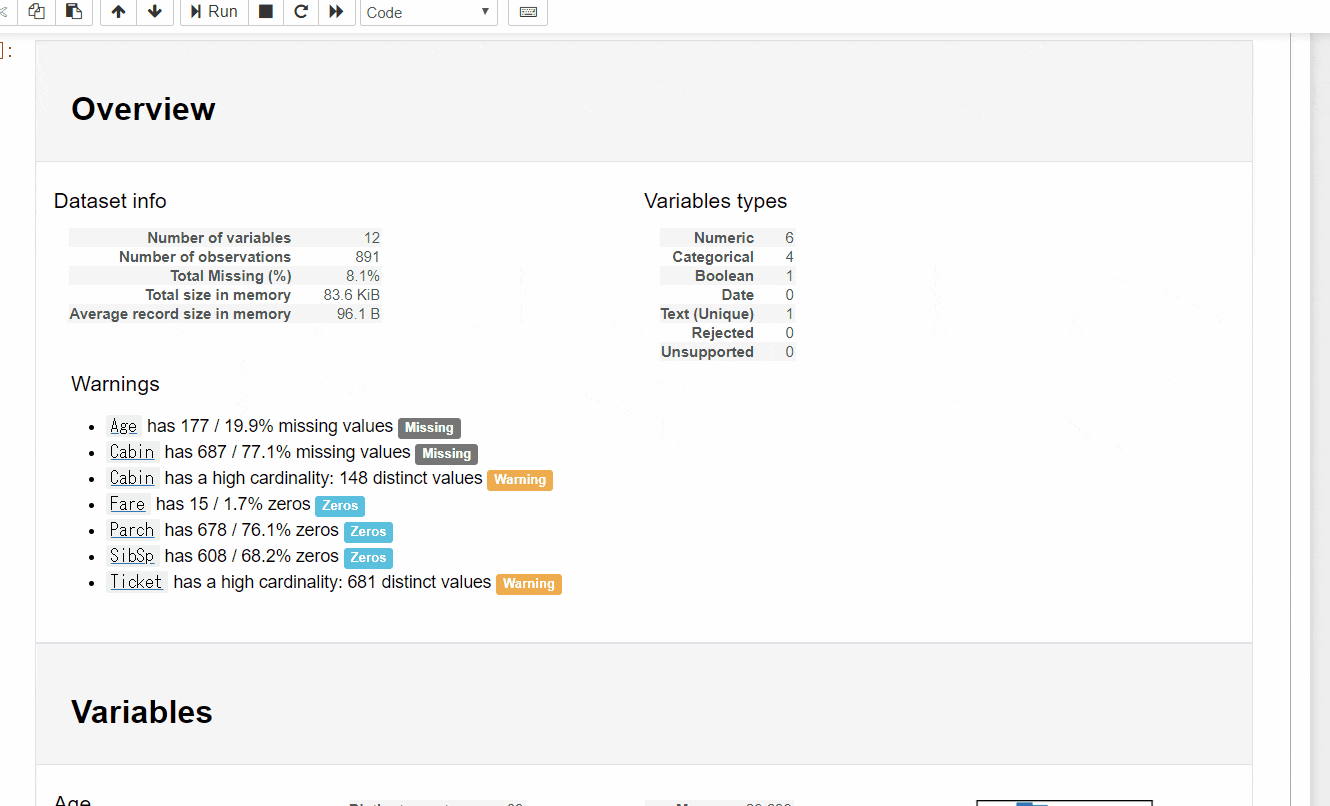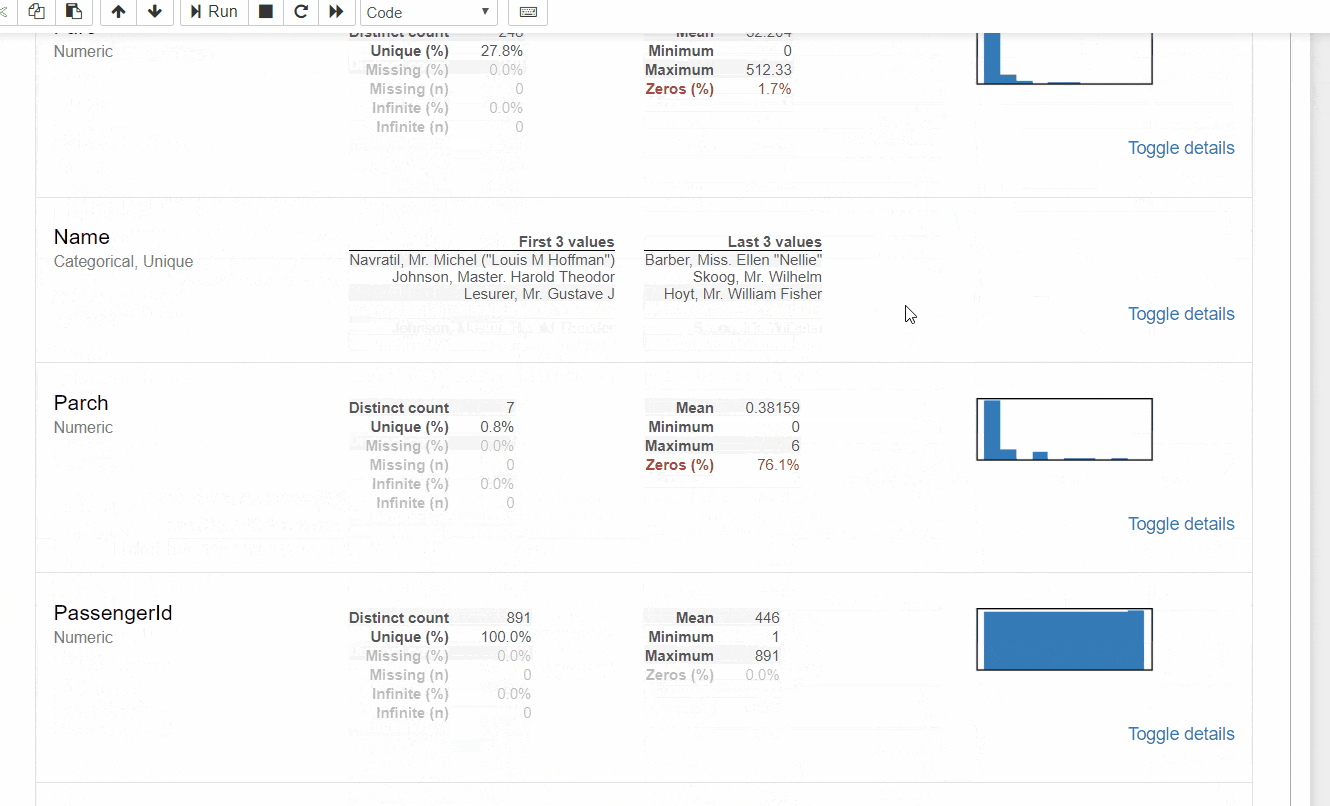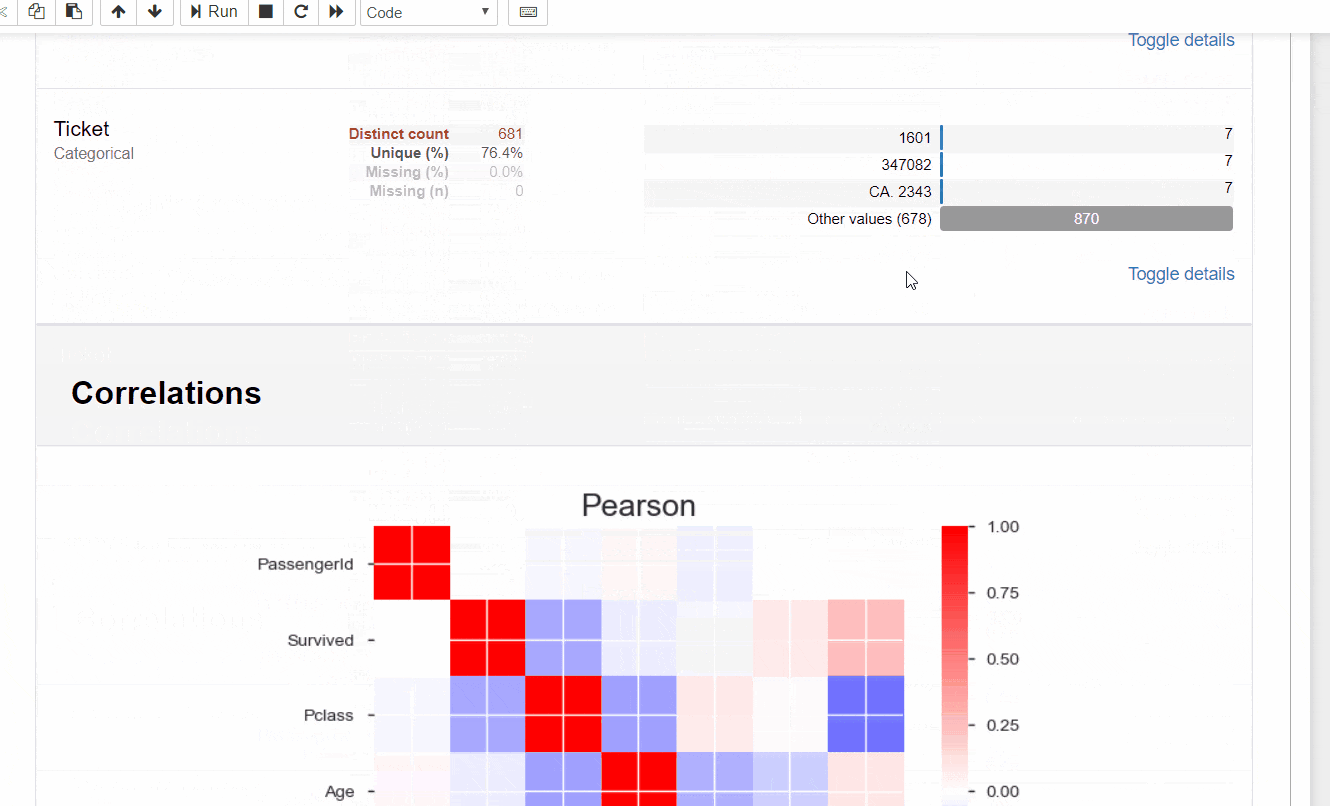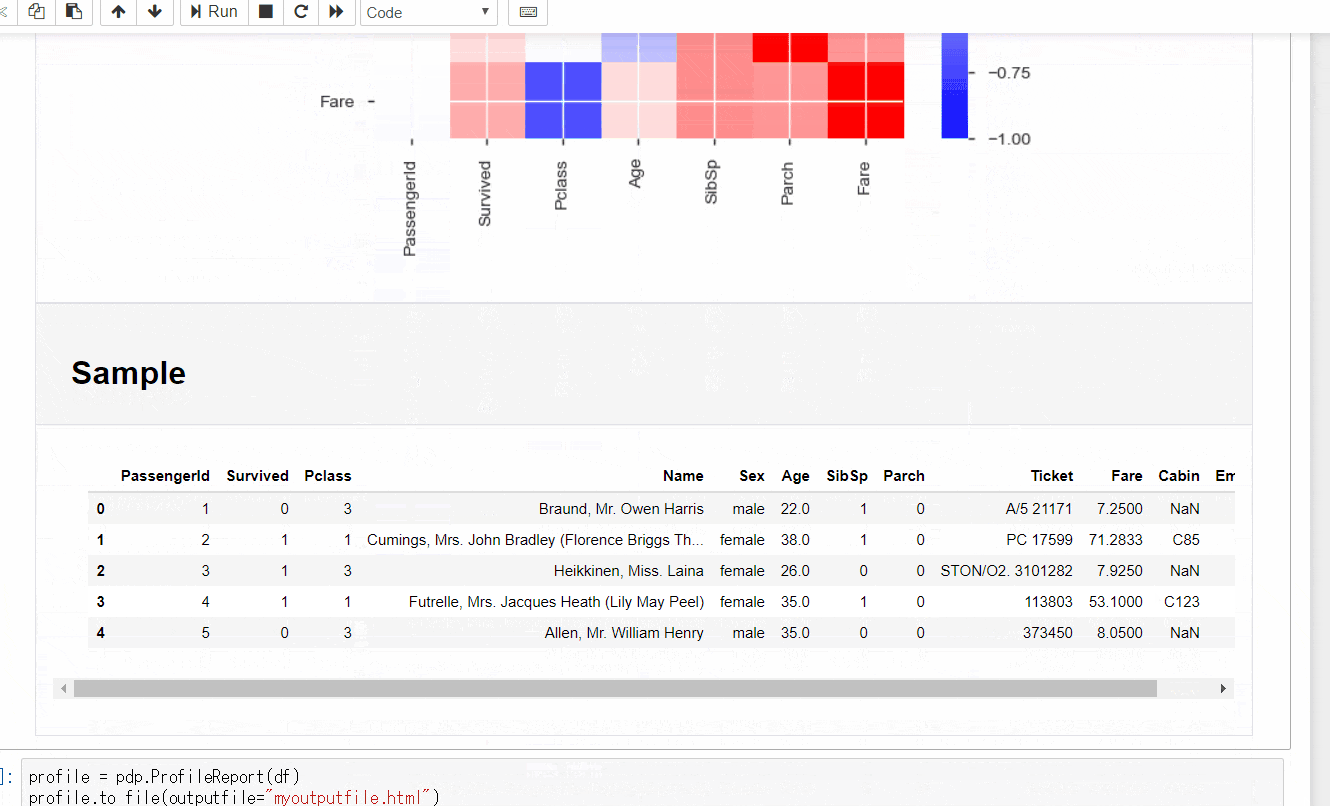
データフレームの構造に、データ型別の基本統計量とグラフ、
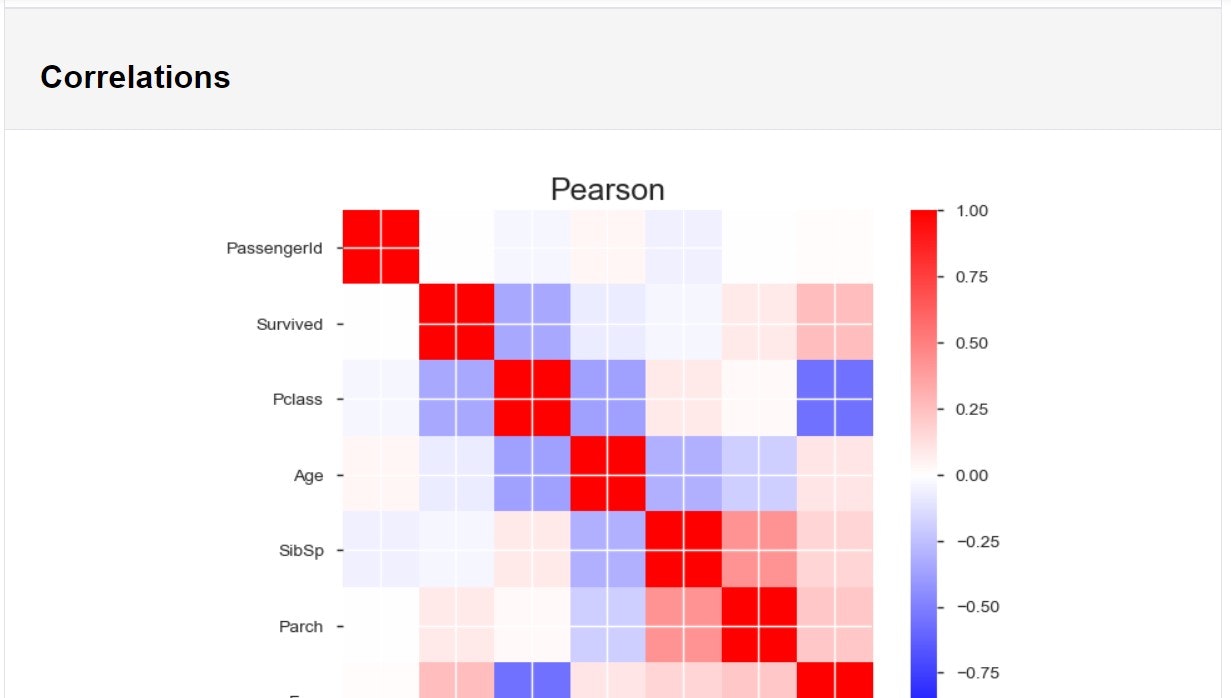
数値データはピアソンの積率相関とスピアマンの順位相関といったところでしょうか。
膨大な説明変数があると大変そうですが、
1行のコードでここまで出してくれるのはEDAが捗りそうですねぇ。
また、以下でHTMLファイルの作成も可能。
profile = pdp.ProfileReport(df)
profile.to_file(outputfile="myoutputfile.html")
注意
Colaboratoryでやると表示、挙動が不安定でした。
Kaggle KernelはOK。
Colaboratoryでは何か方法があるかもしれません。
IT詳しい方、ご存知でしたら教えてください。
補足(2018/05/06追記)
プロフェッショナルの方がcolaboratory挙動の解決策記事を書いてくれています!
HTMLファイルを生成して、埋め込む感じでうまくいくようです!