はじめに
こんな人におすすめ
- Claude Code を日常的に使っているが、セッションをまたぐと前回の文脈が消えてしまうことに困っている人
- Claude Code のセッション間でプロジェクトの文脈を自動で引き継ぎたい人
- Claude Code のプラグイン・フック機能に興味がある人
Claude Code はとても便利なツールですが、セッションをまたぐと前回の会話内容がリセットされます。
「あの話どこまで進んでたっけ?」を毎回説明し直すのが地味にしんどい...と感じていたところ、claude-mem というツールを見つけました。
この記事では、claude-mem の概要・導入手順・実際にハマったポイントをまとめます。
claude-mem とは
claude-mem は、Claude Code 向けの 永続メモリ圧縮システムです。
セッションをまたいで文脈を保持するために、以下のことを自動でやってくれます:
- ツール実行の観察結果(ファイル読み書きなど)をキャプチャ
- セッション終了時にセマンティックなサマリーを生成
- 次回セッション開始時に過去セッション分のコンテキストを自動注入
処理の流れはこんな感じです:
セッション開始 → 過去コンテキストを注入
↓
ユーザープロンプト → セッション作成・保存
↓
ツール実行 → 観察結果をキャプチャ(Read, Write など)
↓
ワーカープロセス → Claude Agent SDK で学習内容を抽出
↓
セッション終了 → サマリー生成 → 次回セッションへ
主な機能:
- セッションをまたいだ記憶の永続化
- MCP ツールによるプロジェクト履歴の自然言語検索
-
<private>タグによるプライバシー制御 - Web ビューア UI(http://localhost:37777)でリアルタイム確認
インストール
必要な環境
- Node.js 18.0.0 以上
- Claude Code(最新版)
- Bun(不足している場合は自動インストール)
- uv(ベクトル検索用 Python パッケージマネージャー。不足している場合は自動インストール)
- SQLite 3(バンドル済み)
インストール方法
推奨:npx 経由
npx claude-mem install
これだけで以下が自動実行されます:
- IDE の検出
- プラグインファイルのコピー
- 依存関係のインストール(Bun・uv を含む)
- ワーカーサービスの起動
注意:
npm install -g claude-memではプラグインフックとワーカーサービスが起動しません。必ずnpx claude-mem installを使ってください。
プラグインマーケットプレイス経由
Claude Code の /plugin コマンドからも導入できます:
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem
プラグインマーケットプレイス経由でインストールした場合の注意
Bun・uv の自動インストールが走らないことがあります。
MCP 検索ツールを使おうとしたときに uvx not found エラーが出た場合は、別途 uv をインストールしてください:
curl -LsSf https://astral.sh/uv/install.sh | sh
インストール後、Claude Code を再起動するとワーカーが uv を認識します。
インストール後
Claude Code を再起動すると、次のセッションから自動でコンテキスト注入が始まります。
データは ~/.claude-mem/ に保存されます。ワーカーのログを確認したい場合は:
tail -f ~/.claude-mem/logs/claude-mem-$(date +%Y-%m-%d).log
仕組みの概要
claude-mem は 5 つのライフサイクルフック を使って動作します:
| フック | タイミング | やること |
|---|---|---|
SessionStart |
セッション開始時 | 過去のコンテキストを注入 |
UserPromptSubmit |
プロンプト送信時 | セッション作成・プロンプト保存 |
PostToolUse |
ツール実行後 | 観察結果のキャプチャ |
Stop |
セッション終了時 | サマリーの生成 |
SessionEnd |
セッション終了時 | 後処理 |
バックエンドは Bun で管理されるワーカーサービス(HTTP API)と SQLite(FTS5 全文検索付き)で構成されています。検索はデフォルトで SQLite FTS が使われ、オプションで Chroma によるベクトル検索も利用できます。
動作確認
セッションをまたいで記憶が引き継がれるか確認する
Claude Code で何か作業したあと、一度セッションを終了して新しいセッションを開始してみてください。
セッション開始時に、前回の作業内容がこのような形で自動注入されます:
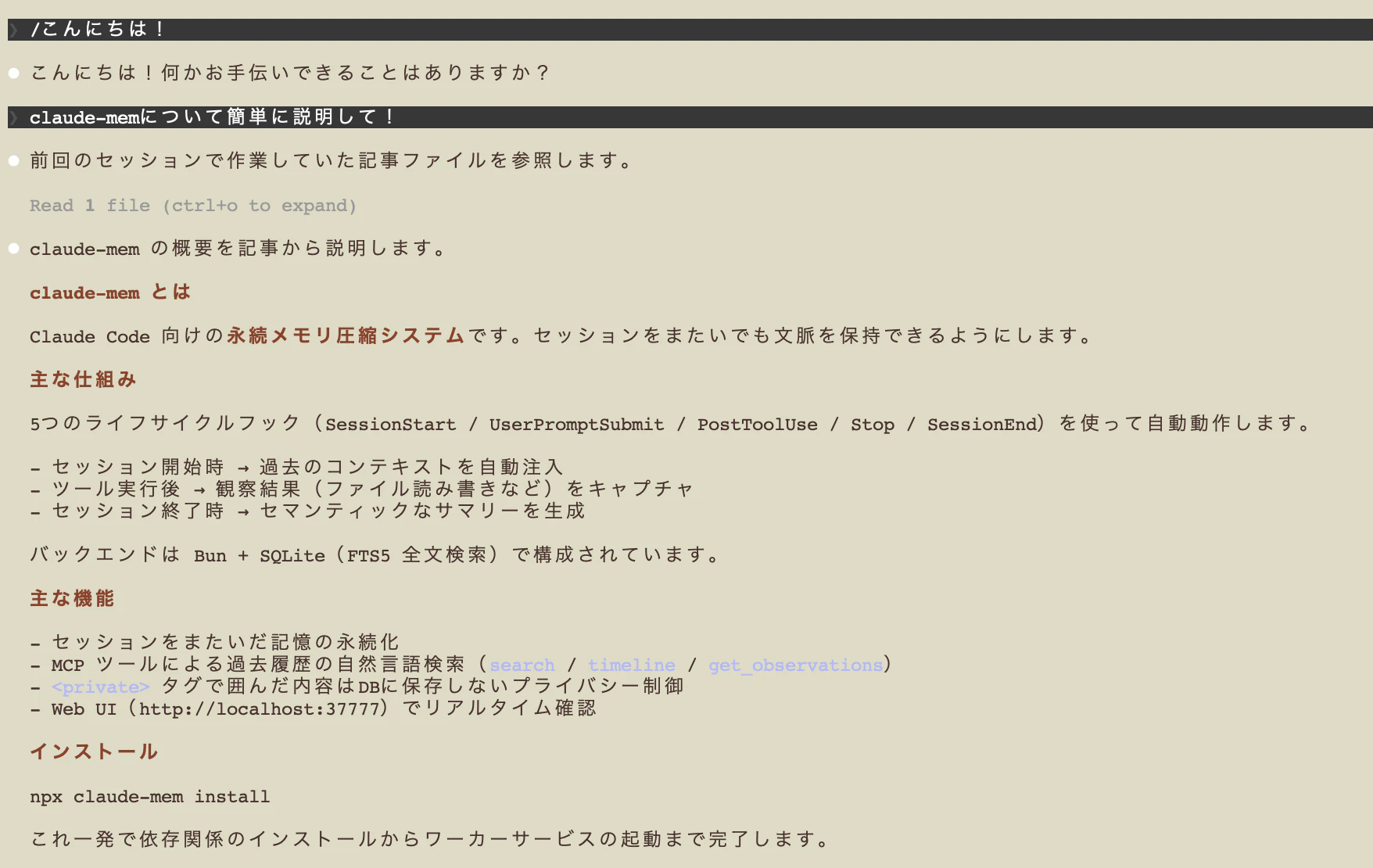
「前回何やってたっけ?」と聞くだけで、Claude が前のセッションの文脈を把握した状態で答えてくれるようになります。
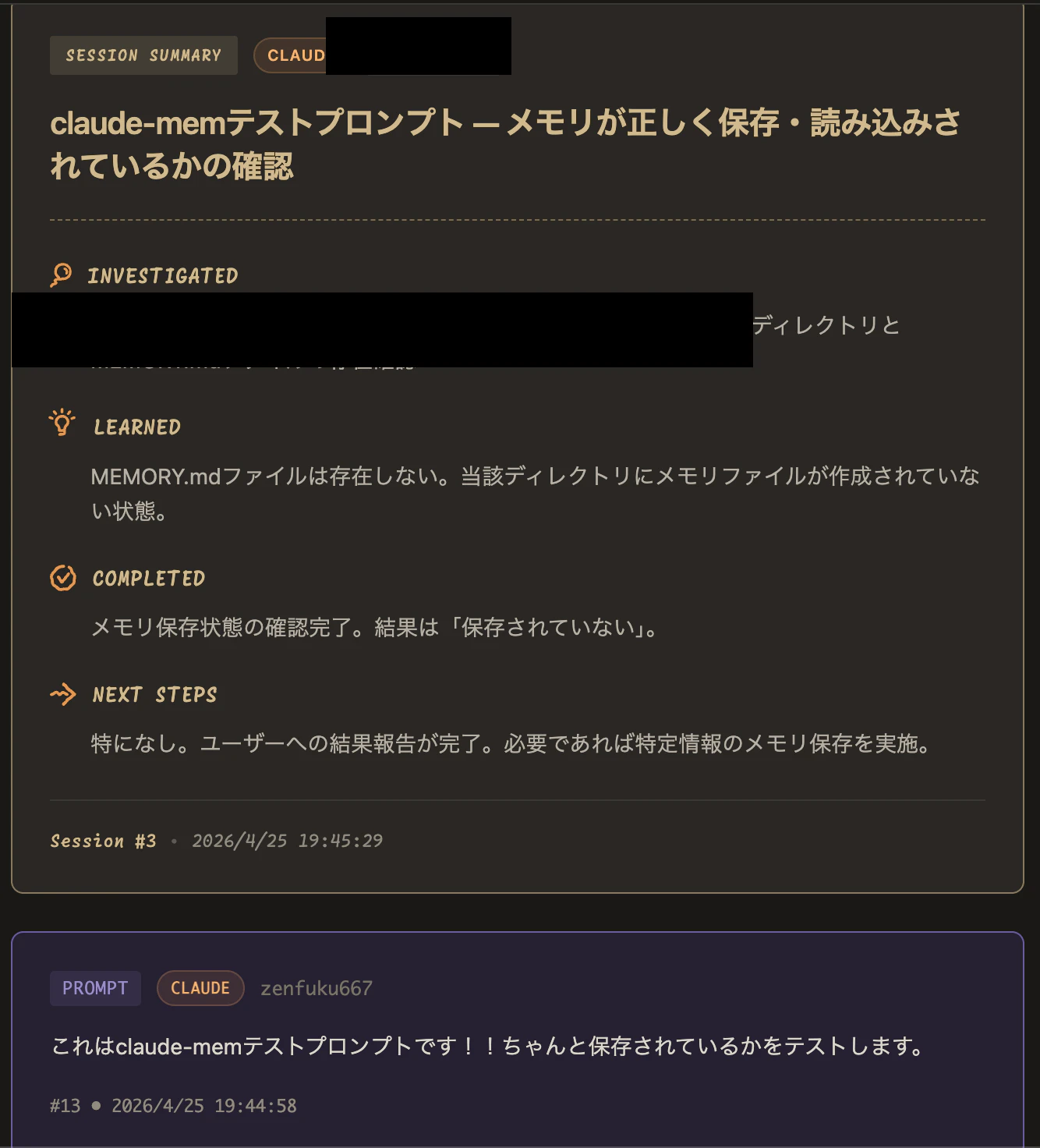
Web UI で確認する
http://localhost:37777 にアクセスすると、メモリストリームをリアルタイムで確認できます。

セッションごとのサマリーが一覧表示されます:
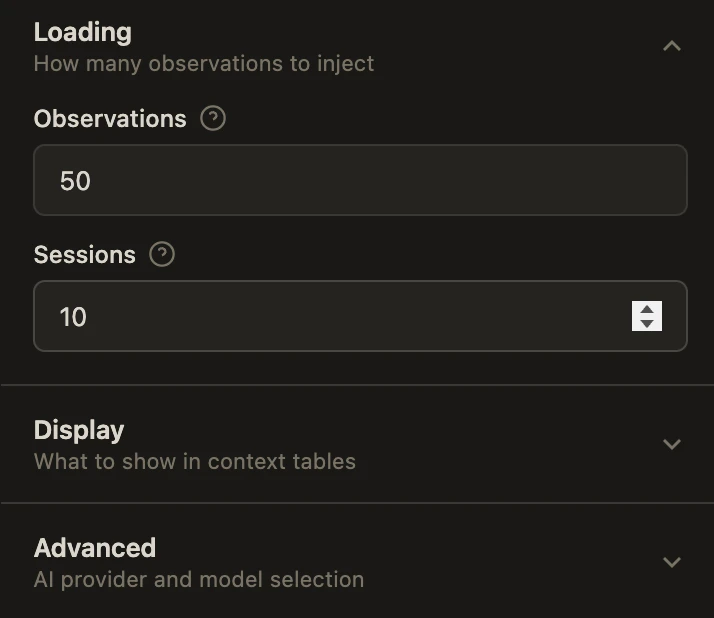
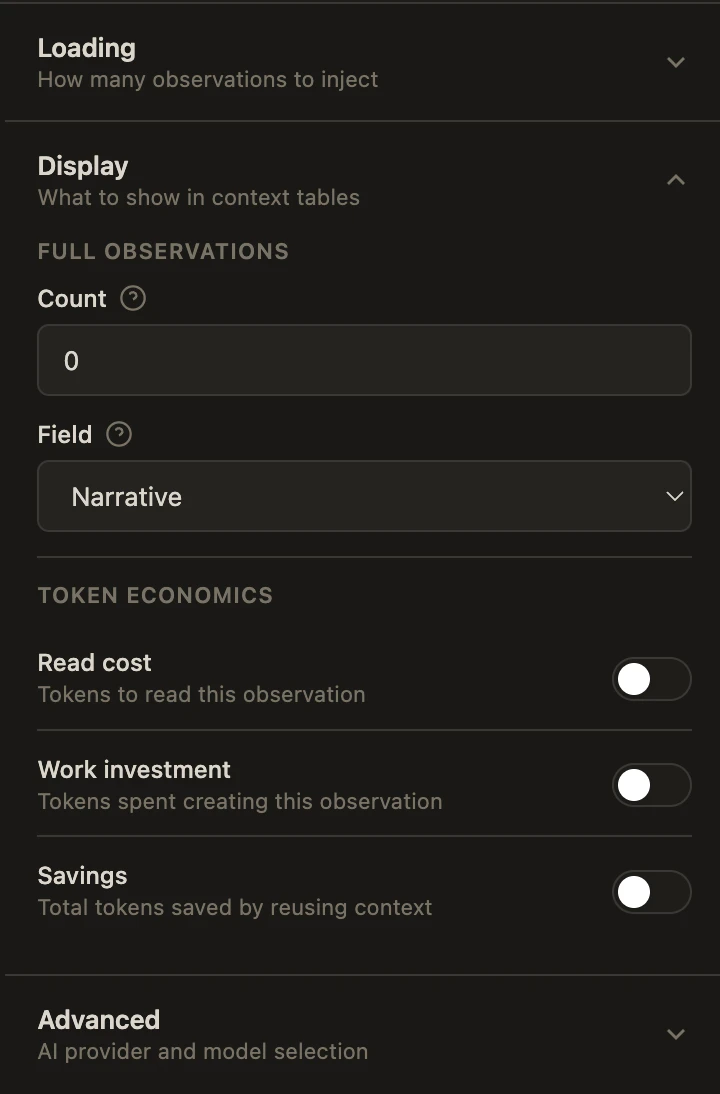
設定画面では動作のカスタマイズが可能です:
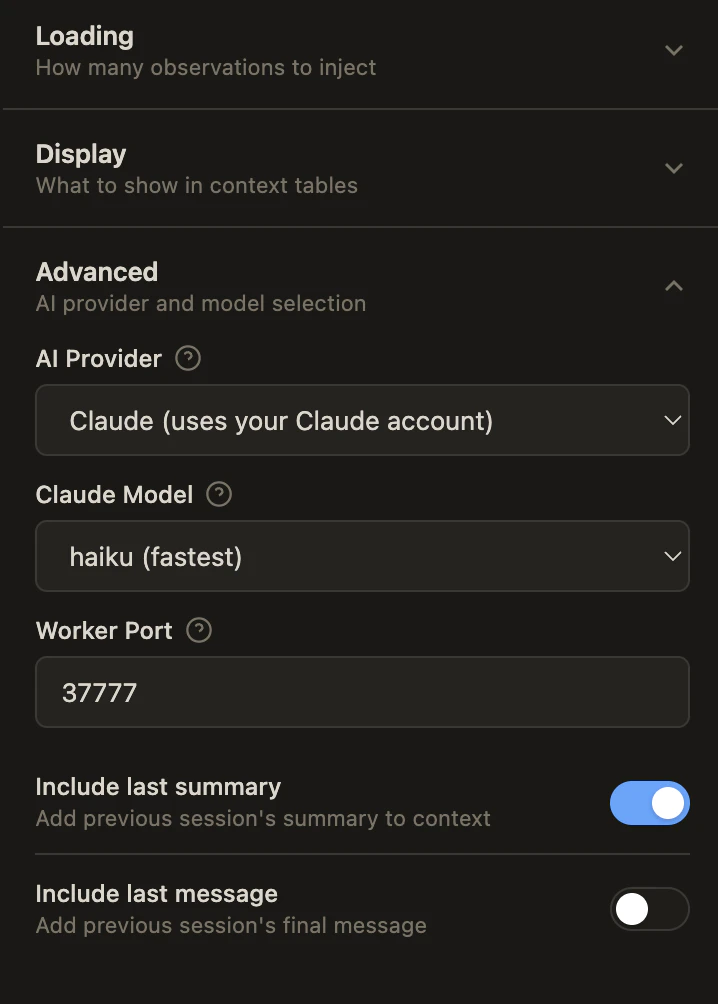
プライベートタグで記憶から除外する
<private> タグで囲んだ内容は、claude-mem のデータベースに保存されません。セッション中は Claude が参照できますが、観察データとして記録されない仕組みです。
基本的な書き方
<private>
ここに書いた内容はメモリに保存されない
</private>
活用場面
API キーや接続情報(シークレット)
<private>
API_KEY=sk-proj-abc123xyz789
HOST=internal-db-prod.company.com
</private>
このAPIに接続してみて
一時的なデバッグログ
<private>
[500行のログ...]
</private>
このログから原因を教えて
セッション限りの背景情報
<private>
明日が締め切り。本番の hotfix。
</private>
このバグを素早く直して
動作の仕組み
- フィルタリングはフック層(
UserPromptSubmit/PostToolUse)で行われ、ワーカーやDBに届く前に除去される - Claude の画面上の会話には残る(セッション中は参照可能)が、
user_promptsテーブルやobservationsテーブルには一切保存されない
動作確認方法
sqlite3 ~/.claude-mem/claude-mem.db \
"SELECT prompt_text FROM user_prompts ORDER BY created_at_epoch DESC LIMIT 1;"
プライベートタグの内容が含まれていなければ正常です。
注意
<private> タグはあくまで claude-mem への保存を防ぐものです。機密情報は別途シークレット管理ツールを使ってください。
MCP ツールによる記憶検索
claude-mem には、過去の作業ログを Claude 自身が検索できる MCP ツール が組み込まれています。
「先月直したあのバグ、どう解決したっけ?」「このプロジェクト久しぶりだけど今どういう状態だっけ?」——そんなとき、過去のセッションを Claude が自分で調べて答えてくれるようになります。
/claude-mem:mem-search スキルから使えます。
なぜ段階的に検索するのか
全履歴を一度に読み込むと、関係ないデータを大量に処理する羽目になります。そのため claude-mem は 3 ステップで絞り込む設計になっています。
| アプローチ | 消費トークン | 関連度 |
|---|---|---|
| 全件取得(従来) | 〜20,000 | 約 10% |
| 3 ステップ絞り込み | 〜3,000 | ほぼ 100% |
イメージとしては「まず検索して件名一覧を出す → 気になるものの前後を確認 → 必要なものだけ全文を開く」というメールの読み方に近いです。
ステップ 1:search — まず目次を出す
search(query="database connection error", type="bugfix", limit=10)
ID・タイトル・日付の一覧が返ってくるだけなので軽量(1 件あたり 50〜100 トークン)。「どんな記録があるか」を確認するステップです。
主なパラメータ:
-
query— キーワード(AND/OR/NOTも使えます) -
type— 種別フィルタ(bugfix/feature/decision/refactorなど) -
dateStart/dateEnd— 日付範囲(YYYY-MM-DD) -
orderBy— 並び順(date_desc/date_asc/relevance)
ステップ 2:timeline — 前後の流れを把握する
timeline(anchor=312, depth_before=3, depth_after=3)
「このバグを直したとき、前後に何が起きていたか?」を時系列で確認できます。query を渡すと ID なしでも動作します。
ステップ 3:get_observations — 詳細を取得する
get_observations(ids=[312, 489])
ここで初めて詳細データを取得します。複数 ID をまとめて渡すのがポイント(1 件ずつ呼ぶとトークンの無駄遣いになります)。
実際の使い方
「このバグ、前に似たの直したことあったっけ?」
# まず検索して一覧を出す
search(query="database connection error", type="bugfix", limit=10)
# 気になる ID の前後の流れを確認
timeline(anchor=312, depth_before=3, depth_after=3)
# 関連しそうなものだけ詳細を取得
get_observations(ids=[312, 489])
「久しぶりにプロジェクトを再開したい」
# 最近の作業を確認
search(query="project-name", limit=10, orderBy="date_desc")
# 最新作業の前後の流れを確認
timeline(anchor=<最新ID>, depth_before=10)
# 重要そうなものだけ詳細取得
get_observations(ids=[<重要なID>])
まとめ
-
npx claude-mem install一発で導入完了(依存関係の自動インストールもあり) - プラグインマーケットプレイス経由の場合は uv の手動インストールが必要なことがある
- Claude Code のセッションをまたいで文脈が自動で引き継がれるようになる
-
<private>タグで囲んだ内容はメモリに保存されない(API キー・ログなどに便利) - MCP ツール(
search/timeline/get_observations)で過去の作業履歴を検索できる - 3 ステップの絞り込みワークフローでトークン消費を約 1/10 に抑えられる
- Web UI(localhost:37777)でメモリストリームをリアルタイム確認できる