この記事は、シアトルコンサルティング株式会社 Advent Calendar 2021の4日目の記事です。
こんにちは、シアトルコンサルティングの松縄です。
現在は、エンジニアとしてWebサービスの開発に携わっています。
はじめに
みなさん、つみたてNISAはやっていますか?
僕は1年くらい前からやり始めていて最近は順調に上がっていて安心しています。
さて、今回とある証券会社のサイトでスクレイピングをしてみようと思ったのは、自動化をしたいなと考えたからです。
僕は最低でも1日1回は口座状況を見るようにしています。chromeでパスワードは保存できるからすぐログインできますが少し面倒でした。それに日毎に見て少し増減があってもよほど変わらない限り気付けないんです。
そこで、今回作ったPython + AWS Lambda + Spreadsheet + LINEのシステムで日毎の損益を残しつつ、週毎だったり月毎だったりの増減も見れるようにしてみました。
シリーズ
- ローカルで証券会社のサイトにログインしてスクレイピング←イマココ
- AWS Lambdaにローカルで作成したファイルをアップロードして実行
- スプレッドシートに保存された値をLINEに通知
使用技術
- Python 3.7
- AWS Lambda
- AWS S3
- AWS CloudWatch
- Google Spreadsheet
- GAS
- LINE Messaging API
ローカルで証券会社のサイトにログインしてスクレイピング
それではこの記事の本題に移ります。
まずはローカルで証券会社のサイトからデータを取ってスプレッドシートに保存するシステムを作りましょう。
今回必要なもの
- Python
- venv(Pythonを実行するための仮想環境)
- ChromeDriver
- スプレッドシート
手順
- ディレクトリ作成、各種インストール
- 証券会社のサイトのトップページを開く
- 証券会社のサイトにログインして必要なデータを取得
- スプレッドシートに保存
1. ディレクトリ作成、各種インストール
まずはローカルで開発する場所とファイルを作ります。(ディレクトリ名、ファイル名はお好きに)
mkdir myapp
cd myapp
touch lambda_function.py
次に仮想環境を作ります。作業ディレクトリにいる状態で以下を実行します。
python3 -m venv venv
右のvenvが環境名になります。
正しく処理されれば、作業ディレクトリ配下にvenvというフォルダが作成されます。
この状態になったら以下のコマンドを実行します。
source venv/bin/activate
こちらが正しく実行されるとターミナルの○○のMacBook-Pro $の部分の左側か上に(venv)と追加されます。これで、仮想環境の有効化ができました。
次に、今回使うライブラリをインストールします。
pip3 install gspread selenium bs4 oauth2client python-dotenv
また、今回はシステムからChromeを開いてログインなどを行うのでChromeDriverというChromeブラウザをプログラムで動かす為のドライバーを使用します。
1.左上のChromeタブから「Google Chrome について」をクリック

2.Chromeのバージョンを確認(今回は96.0.4664.55)

3.ChromeDriverをインストール
こちらのサイトから2で確認したChromeのバージョンに近いものをインストールします。(今回はChromeDriver 96.0.4664.45をインストール)
4.chromedriverを作業ディレクトリ配下に移動
インストールしたzipファイルを開くとchromedriverというUnix実行ファイルになるので作業ディレクトリ配下に移動させておきます。
これでシステムからスクレイピングする準備は整いました。
次からは実装に入ります。
以下のコードのlambda_handlerから呼び出すメソッドごとに解説していきます。
段階毎に動作確認したい場合は、下のメソッドをコメントアウトしてください。
import os
import time
import datetime
import gspread
import json
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from oauth2client.service_account import ServiceAccountCredentials
from dotenv import load_dotenv
def lambda_handler(event, context):
# envファイルの読み込み
load_dotenv()
# 証券会社のサイトのトップページを開く
driver = connect()
# 証券会社のサイトの口座から必要なデータを取得する
result = get_data(driver)
# 取得したデータをスプレッドシートに保存する
save_to_spreadsheet(result)
if __name__ == '__main__':
lambda_handler(event=None, context=None)
2. 証券会社のサイトのトップページを開く
ここでは証券会社のサイトのトップページを開くところまで実装していきます。
まず、作業ディレクトリ配下に.envを作っておいて以下のように環境変数を設定しておきます。
CHROMEDRIVER=chromedriver
lambda_handlerの中で最初に呼び出されるload_dotenvでenvファイルの読み込みをします。
次に呼ばれるconnectの中身はこちらです。
def connect():
# 環境変数の取得
chromedriver = os.getenv('CHROMEDRIVER', '')
# Optionの設定
options = Options()
# 画面上にChromeを表示させない
options.add_argument('--headless')
# webdriverの準備
driver = webdriver.Chrome(chromedriver, chrome_options=options)
# 証券会社のサイトのトップ画面を開く
driver.get('証券会社のサイトのURL')
return driver
それでは順番に解説します。
# 環境変数の取得
chromedriver = os.getenv('CHROMEDRIVER', '')
getenvをすることでenvファイルの中から必要な環境変数だけ取得できます。
次に、chromedriverを使うためのoptionの設定です。
options = Options()
options.add_argument('--headless')
options.add_argument('--headless')を使うとヘッドレスモードでChromeを開くことになり、ブラウザを裏側で開くようにすることができます。画面がしっかりと遷移できていることを確認できるまではここはコメントアウトしておいた方が良いかと思います。
次にdriverの設定です。
driver = webdriver.Chrome(chromedriver, chrome_options=options)
driver.get('証券会社のサイトのURL')
第一引数にはchromedriverのパスが入ります。この記事通りに書いている方はこのままで大丈夫ですが、移動させていない方はenvファイルのCHROMEDRIVERを正しいパスに書き換えてください。
driver.get()で指定したリンクを開きます。
これで、プログラムから証券会社のサイトのトップ画面を表示するところまで完了です。
ここまでを動作確認したい場合は、returnする前に以下をコードを加えましょう。
driverが立ちっぱなしになってしまうのでcloseとquitで終了させます。
driver.close()
driver.quit()
3. 証券会社のサイトにログインして必要なデータを取得
ここでのソースコードは以下の通りです。
def get_data(driver):
# 環境変数の取得
user_name = os.getenv('USERNAME', '')
password = os.getenv('PASSWORD', '')
# 途中で処理が失敗した時にブラウザが開きっぱなしになるので必ず終了させるようにする
try:
# 遷移するまで待つ
time.sleep(4)
# ユーザーIDとパスワードを入力
input_user_id = driver.find_element_by_name('user_id')
input_user_id.send_keys(user_name)
input_user_password = driver.find_element_by_name('user_password')
input_user_password.send_keys(password)
# ログインボタンをクリック
driver.find_element_by_name('ACT_login').click()
# 遷移するまで待つ
time.sleep(4)
# ポートフォリオの画面に遷移
driver.find_element_by_link_text('口座管理').click()
# 遷移するまで待つ
time.sleep(4)
# 文字コードをUTF-8に変換
html = driver.page_source.encode('utf-8')
# BeautifulSoupでパース
soup = BeautifulSoup(html, "html.parser")
# 株式
table_data = soup.find('table', border="0", cellspacing="1", cellpadding="1", width="400")
valuation_gains = table_data.find_all('tr', align="right", bgcolor="#eaf4e8")
result = []
today = datetime.date.today().strftime('%Y年%m月%d日')
result.append(today)
for element in valuation_gains:
text = element.find('font', color="red").text
text = text.replace('+', '')
result.append(text)
except Exception as e:
print(e)
finally:
driver.close()
driver.quit()
return result
まず、envファイルにUSERNAMEとPASSWORDは追加しておきましょう。
USERNAME=ユーザー名
PASSWORD=パスワード
次に、ユーザー名とパスワードを入力してログインします。
# ユーザーIDとパスワードを入力
input_user_id = driver.find_element_by_name('user_id')
input_user_id.send_keys('ユーザー名')
input_user_password = driver.find_element_by_name('user_password')
input_user_password.send_keys('パスワード')
# ログインボタンをクリック
driver.find_element_by_name('ACT_login').click()
find_element_by_nameの引数にユーザー名を入力するinputタグのname属性を入れることでその要素を取得できます。
取得したらsend_keysを使ってユーザー名を入力します。
パスワードも同様です。
ユーザー名とパスワードを入力したらログインボタンの要素を取得して、clickメソッドを使ってログインします。
これで、証券会社のサイトにログインができたので次は欲しいデータを取得します。
今回取得したいのは右下の評価損益です。表示されている部分は買っている数によって異なります。
ここでは以下の形でスクレイピングの結果を出力するところまでをゴールとします。
['今日の日付' , '株式1の評価損益', '株式2の評価損益', '株式3の評価損益']
まずは、ログインをした後の画面の口座管理のリンクに遷移します。
driver.find_element_by_link_text('口座管理').click()
次に、BeautifulSoupを使う準備をします。ここは詳しく説明できるほど理解できていないのでおまじないのつもりです。
# 文字コードをUTF-8に変換
html = driver.page_source.encode('utf-8')
# BeautifulSoupでパース
soup = BeautifulSoup(html, "html.parser")
準備をしたら、今回取得したいデータが書かれている要素を取得します。
今回取得したい要素をコピーすると以下のようになります。(リンクや数字は適当に変えてます)
<table border="0" cellspacing="1" cellpadding="1" width="400">
<tbody>
<tr>
<td class="mtext" colspan="4">
<font color="#336600">
<b>投資信託(金額/つみたてNISA預り)</b>
</font>
</td>
</tr>
<tr bgcolor="#79b26b" align="center">
<td width="93" class="mtext">
<font color="#ffffff">保有口数</font>
</td>
<td width="93" class="mtext">
<font color="#ffffff">取得単価</font>
</td>
<td width="93" class="mtext">
<font color="#ffffff">基準価額</font>
</td>
<td width="108" class="mtext">
<font color="#ffffff">評価損益</font>
</td>
</tr>
<tr bgcolor="#b9e8ae">
<td class="mbody" colspan="3">
<a href="省略">株式1</a>
<a href="省略">
<img src="省略" title="メールアラート画面へ">
</a>
</td>
<td class="stext" align="right">
<a href="省略">積立</a>
<a href="省略">売却</a>
</td>
</tr>
<tr bgcolor="#eaf4e8" align="right">
<td class="mtext">10,000</td>
<td class="mtext">10,000</td>
<td class="mtext">10,000</td>
<td class="mtext">
<b><font color="red">+10,000</font></b>
</td>
</tr>
</tbody>
</table>
このtableタグの中の+10,000という文字列が欲しいのでそれを取れるように書いています。(書き方は色々あると思うのでご自由に)
# 株式
table_data = soup.find('table', border="0", cellspacing="1", cellpadding="1", width="400")
valuation_gains = table_data.find_all('tr', align="right", bgcolor="#eaf4e8")
今回は、まずfindで上のtableタグ全体を取得します。
次にfind_allでtableタグの中からbgcolor="#eaf4e8" align="rightのtrタグを全て取得します。(上のHTMLでは消していますが実際は同じようなtrタグがあと2つあります)
僕は3つの株式を買っているので以下のような配列ができています。
[
<b><font color="red">+10,000</font></b>,
<b><font color="red">+20,000</font></b>,
<b><font color="red">+30,000</font></b>
]
これで、評価損益が含まれている要素の配列ができました。
次に、出力する用の配列を用意して、先頭に今日の日付を入れておきます。
result = []
today = datetime.date.today().strftime('%Y年%m月%d日')
result.append(today)
上で用意した配列に、find_allで取得した評価損益の部分を入れていきます。
スプレッドシートに入れるときに+があると数値として見てくれないので+は消しておきます。
for element in valuation_gains:
text = element.find('font', color="red").text
text = text.replace('+', '')
result.append(text)
これで以下の形の配列を作ることができました。
['今日の日付' , '株式1の評価損益', '株式2の評価損益', '株式3の評価損益']
4. スプレッドシートに保存
証券会社のサイトから評価損益を取得できたのでこの結果をスプレッドシートに登録します。
今回はシンプルに以下のようにレコードを追加していきます。
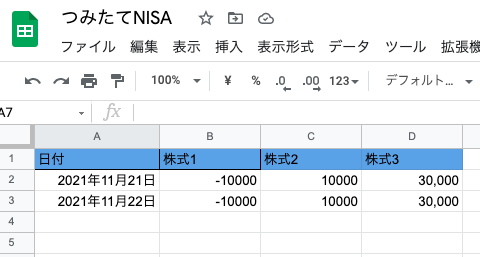
まずはソースコードです。
def save_to_spreadsheet(result):
# 環境変数の取得
spreadsheet_json = os.getenv('SPREADSHEET_JSON', '')
spreadsheet_id = os.getenv('SPREADSHEET_ID', '')
#2つのAPIを記述しないとリフレッシュトークンを3600秒毎に発行し続けなければならない
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
#認証情報設定
#ダウンロードしたjsonファイル名をクレデンシャル変数に設定(秘密鍵、Pythonファイルから読み込みしやすい位置に置く)
credentials = ServiceAccountCredentials.from_json_keyfile_name(spreadsheet_json, scope)
#OAuth2の資格情報を使用してGoogle APIにログインします。
gc = gspread.authorize(credentials)
#共有設定したスプレッドシートのシート1を開く
worksheet = gc.open_by_key(spreadsheet_id).sheet1
# 受け取った配列をスプレッドシートに追加する
worksheet.append_row(result, value_input_option='USER_ENTERED')
return { 'status': 204 }
envファイルに追加する前に、スプレッドシートの準備をします。
こちらのサイトの2.スプレッドシートの設定まで行います。
必要なものは以下の2つです。
- サービスアカウントキーのjsonファイル(spreadsheet-xxxxx-xxxxxxxxx.json)
- 作成したスプレッドシートのスプレッドシートキー(例:
https://docs.google.com/spreadsheets/d/××××/edit#gid=0のxxxxの部分)
まず、サービスアカウントキーのjsonファイルを作業ディレクトリ配下に置きます。
次に、envファイルに以下を追加します。
SPREADSHEET_JSON=spreadsheet-xxxxx-xxxxxxxxx.json
SPREADSHEET_ID=作成したスプレッドシートのスプレッドシートキー
これで準備はできたのでソースコードの説明に移ります。
といってもここは先ほどのサイトをほぼ真似しているので、最後の部分だけ解説します。
worksheet.append_row(result, value_input_option='USER_ENTERED')
ここではappend_rowを使って配列を行としてスプレッドシートに追加することができます。また、value_input_option='USER_ENTERED'を入れることで、スプレッドシートに配列を入れた際に文字列になってしまうのを防ぐことができます。
これで、証券会社のサイトから評価損益を取得してスプレッドシートに保存することができました。
最終的なディレクトリ構成は以下の通りです。
myapp
├─ lambda_function.py
├─ venv
├─ .env
├─ spreadsheet-xxxxx-xxxxxxxxx.json
└─ chromedriver
さいごに
いかがでしたか?
つみたてNISAの損益をスプレッドシートに保存するプログラムの解説でした。
今回作ったプログラムはローカルで直接動かさないといけないので、
AWS lambdaに入れて定期的に実行できるようにしたいと考えています。
その辺りの記事は別で書く予定です。
参考になれば幸いです。
参考
seleniumを使用しようとしたら、「"chromedriver"は開発元を検証できないため開けません。」と言われた
ポートフォリオ情報をPythonでスクレイピング
【もう迷わない】Pythonでスプレッドシートに読み書きする初期設定まとめ