はじめに
Deep Variational Network Embedding in Wasserstein Spaceという論文を読んだのでまとめていきます。
1. 対象とするトピック
1.1 キーワード
Network Embedding, Wasserstein Space 論文
1.2 Abstract
Network embedding, aiming to embed a network into a low dimensional vector space while preserving the inherent structural properties of the network, has attracted considerable attentions recently. Most of the existing embedding methods embed nodes as point vectors in a low-dimensional continuous space. In this way, the formation of the edge is deterministic and only determined by the positions of the nodes. However, the formation and evolution of real-world networks are full of uncertainties, which makes these methods not optimal. To address the problem, we
propose a novel Deep Variational Network Embedding in Wasserstein Space (DVNE) in this paper. The proposed method learns a Gaussian distribution in the Wasserstein space as the latent representation of each node, which can simultaneously preserve the network structure and model the uncertainty of nodes. Specifically, we use 2-Wasserstein distance as the similarity measure between the distributions, which can well preserve the transitivity in the network with a linear computational cost. Moreover, our method implies the mathematical relevance of mean and variance by the deep variational model, which can well capture the position of the node by the mean vectors and the uncertainties of nodes by the variance. Additionally, our method captures both the local and global network structure by preserving the first-order and second-order proximity in the network. Our experimental results demonstrate that our method can effectively model the uncertainty of nodes in networks, and show a substantial gain on real-world applications such as link prediction and multi-label classification compared with the state-of-the-art methods.
2. 理論
2.1 概要
自然言語処理と同様に、ガウス分布を用いてネットワークを空間に埋め込むことを考えます。ただし、KL divergenceを用いている既存の手法とは異なり、Wasserstein distanceを空間の距離に用います。これにより、KL divergenceを用いることで失われてしまうtransitivityを保持しようと試みます。
2.2 Notations
記号は以下のように定義されています。
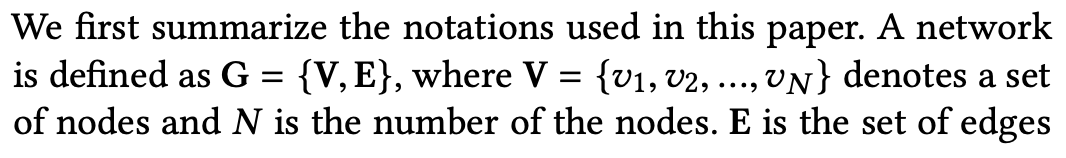

2.3 Problem Definition
3つの問題設定を行なっています。なお、proximityについての記述は以下の通りです。

2.3.1 First-Order Proximity

first-order proximityの解釈は以下の通りです。レコメンデーションと同様に、得られるデータがスパースであることが機能的な制約となっています。

2.3.2 Second-Order Proximity
 友達の友達は友達みたいな関係ですね。`first-order`だとデータがスパースなのでより拡張した範囲までノード間の類似度計算に利用しているようですね。
友達の友達は友達みたいな関係ですね。`first-order`だとデータがスパースなのでより拡張した範囲までノード間の類似度計算に利用しているようですね。
2.3.3 Gaussian-Based Network Embedding

2.4 DEEP VARIATIONAL NETWORK EMBEDDING
2.4.1 Framework
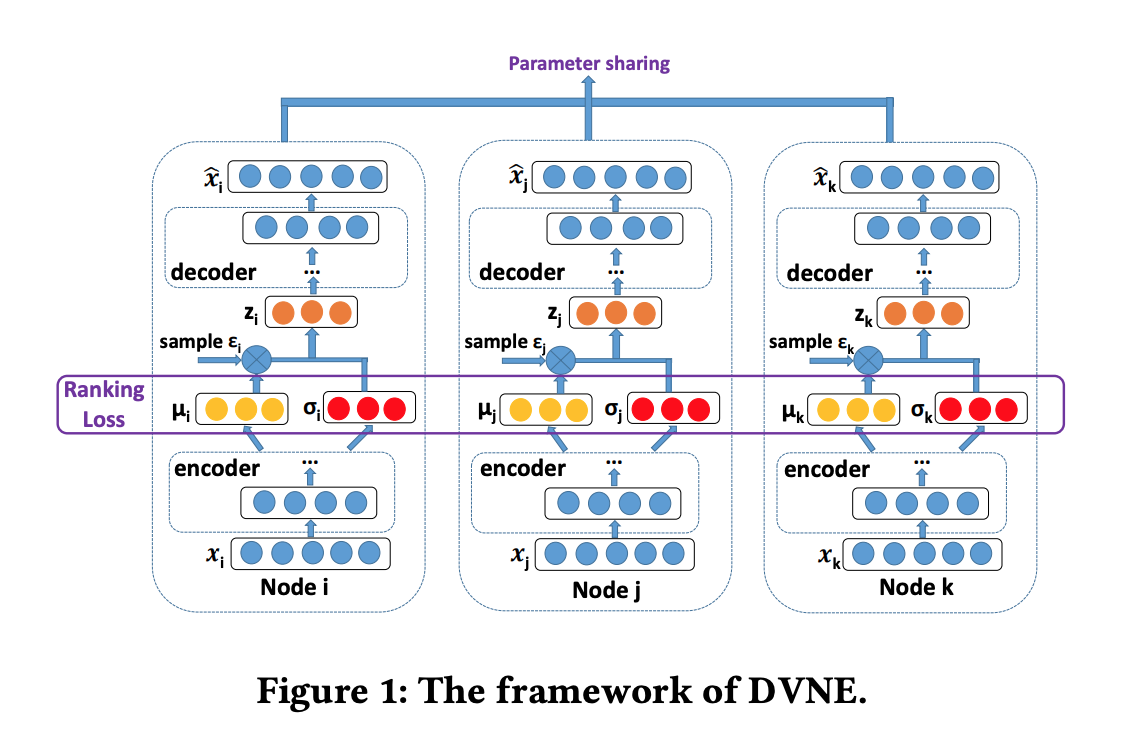
2.4.2 Similarity Measure
transitivityを保持した状態で分布間の距離を計算するためにWasserstein distanceを利用します。一般式(p-Wasserstein distance)は以下の通りです。
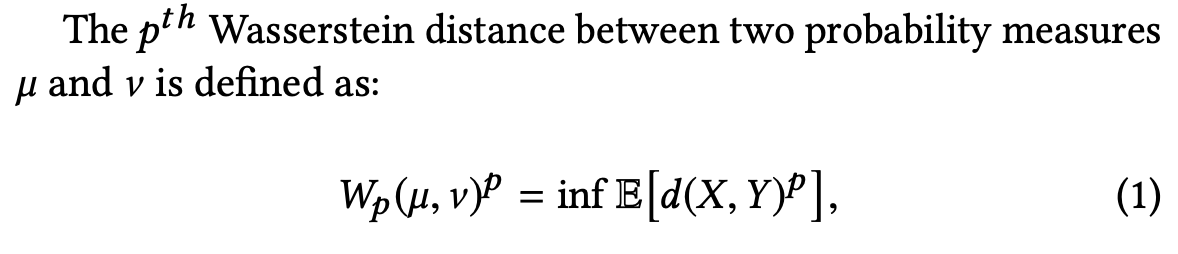
この値を直接計算すると計算時間が大きく実用的でないので回避します。そこで今回は計算時間を短縮可能だと既に判明している2-th Wasserstein distance($W_2$)を用います。すると、以下のようにガウス分布間の距離を計算できます。
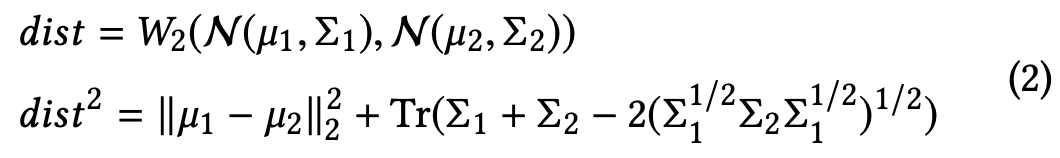
更に、今回対象とする対角共分散を用いた場合は式(2)が以下のように簡略化されます。
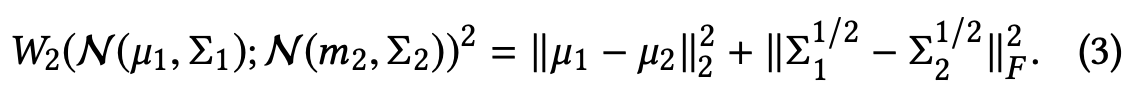
2.4.3 Loss Function
first-order proximityとsecond-order proximityを保持するように損失関数を設計します。
first-order proximityについての記述は以下の通りです。入力の組の近さが$W_2$の大小として表現されています。その後エネルギー関数を用いて損失を定義しています。最終的にはfirst-order proximityを有する組の類似度が大きくなります。

second-order proximityについての記述は以下の通りです。序盤はWasserstein Auto-Encoders (WAE)について記述しています。

なお、全体の損失関数は以下の通りです。

3. 実験
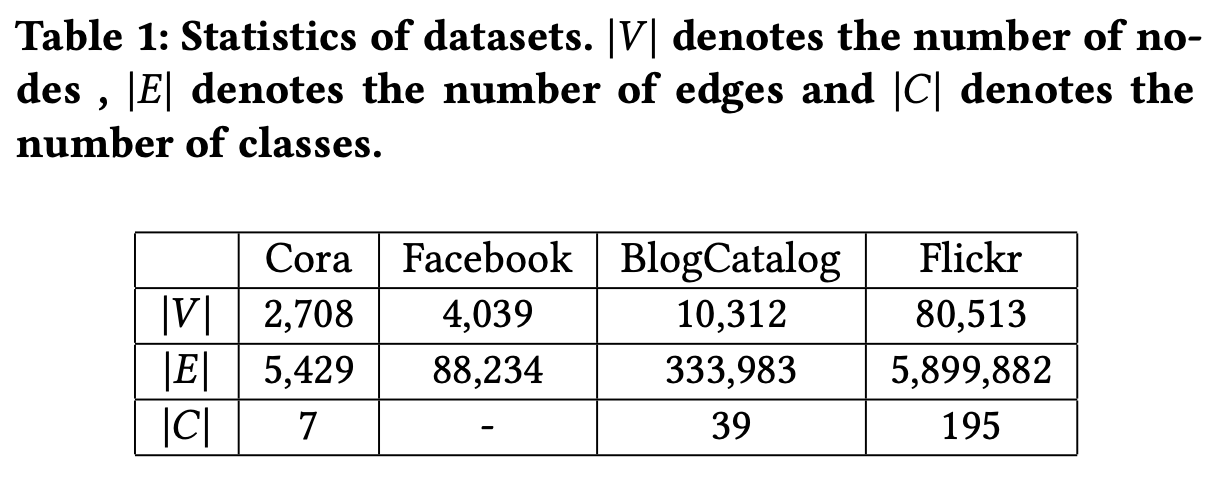
3.1 Dataset
- Cora
- BlogCatalog
- Flicker
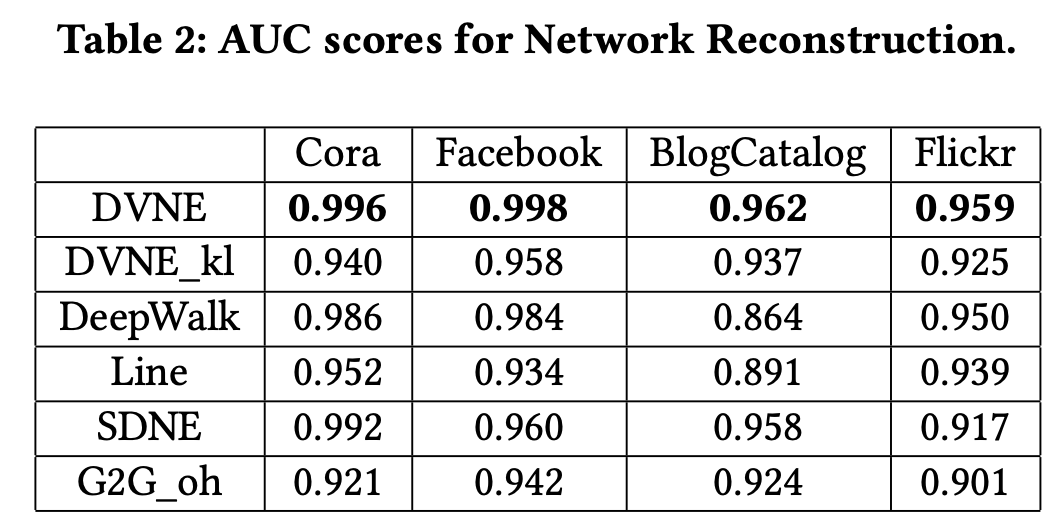
3.2 Network Reconstruction
AUCでの評価結果は以下の通りです。
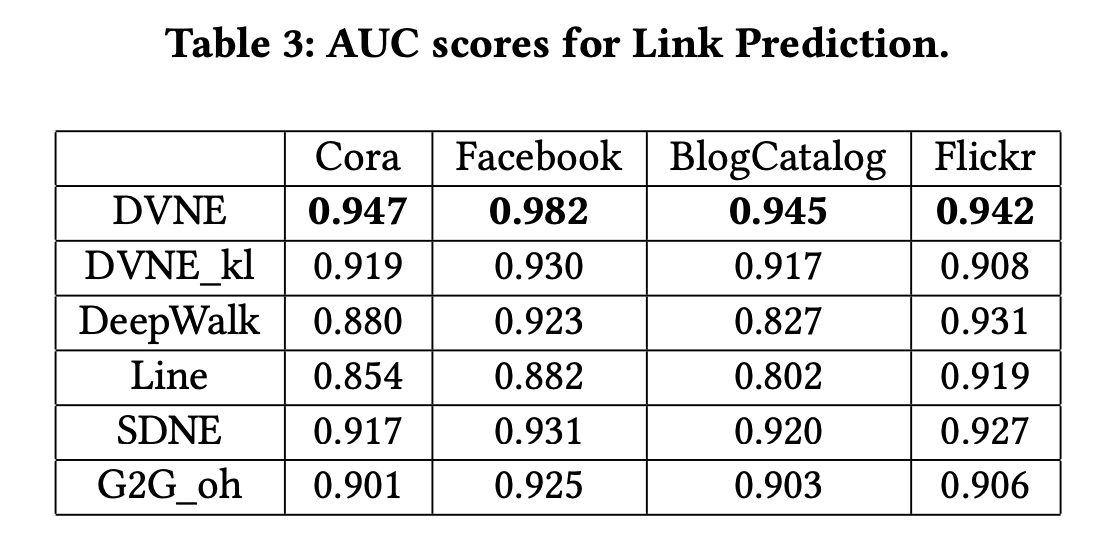
3.3 Link Prediction
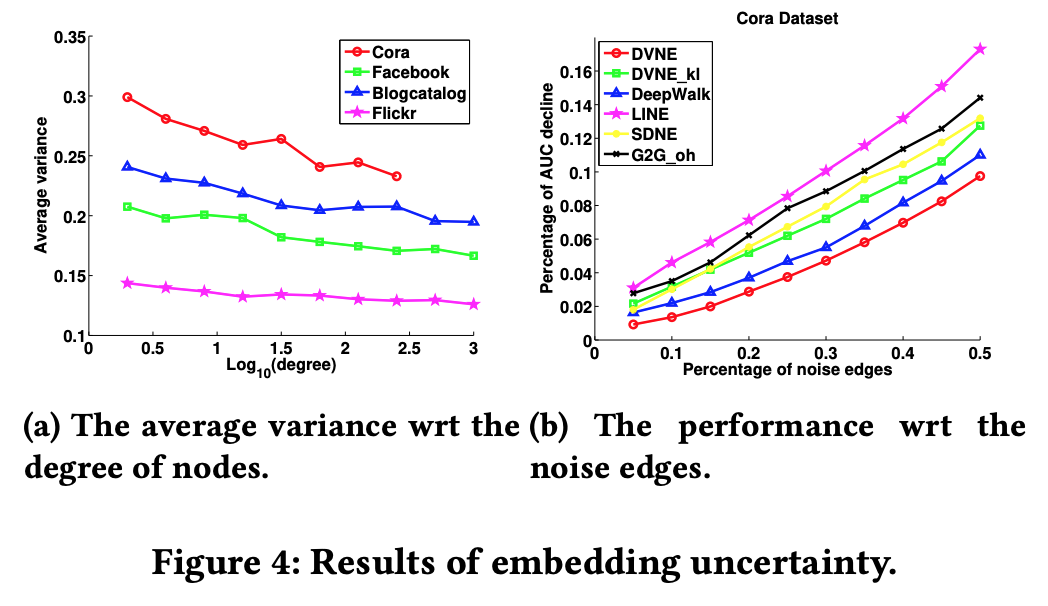
3.4 Embedding Uncertainty
分布での埋め込みによってノードの不確実性を捉えられているか評価します。まずスパースなネットワークほど分散が大きくなるという直感を検証します。手順は以下の通りです。

図4(a)から、学習した分散がネットワークの密度を反映していることがわかりました。更に追加の実験として、ノイズへの対処に分散が有用であるか検証します。手順は以下の通りです。

提案手法(DVNE)が最もAUCの減衰を低く抑えていることが分かります。
参考文献
- Dingyuan Zhu, Peng Cui, Daixin Wang, Wenwu Zhu (2018). Deep Variational Network Embedding in Wasserstein Space, http://pengcui.thumedialab.com/papers/NE-DeepVariational.pdf