ホームページ:https://program-board.com
最終目標:Filmarksより年代別で高評価となっている映画一覧の作成を目的としたデータ抽出を行う.
本稿では,特定のページでの複数の項目についての情報を抽出する.抽出する映画はまだ1つです.
ソースコードの確認
前回と同様に,抽出したい情報のソースコードを確認する.
本稿では,以下の情報を抽出します.
・映画タイトル
・上映日
・製作国
・上映時間
・ジャンル(3つまで)
・星(評価)
・監督
・脚本(2人まで)
・出演者(3人まで)
import requests
import bs4
import pandas as pd
# ウェブの情報を取得
url= 'https://filmarks.com/list/trend'
res = requests.get(url)
# HTMLの整形
soup = bs4.BeautifulSoup(res.text) #features='lxml')
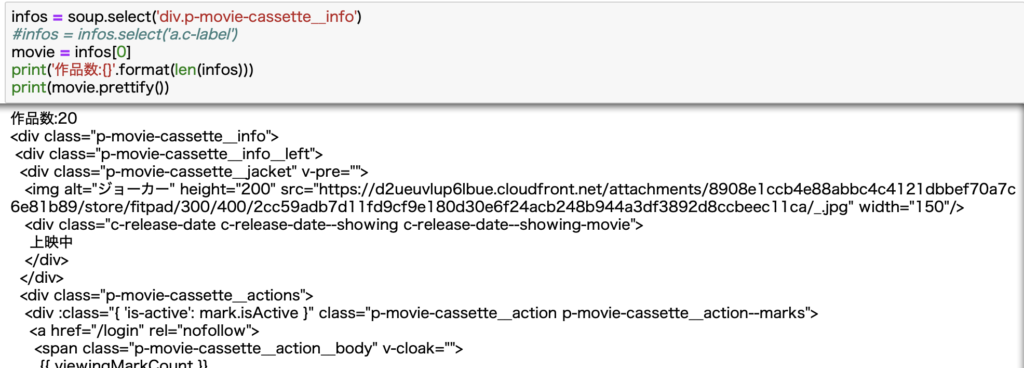
1作品のみの情報を抽出
とりあえず,表示画面の冒頭作品のweb情報を抽出します.
infos = soup.select('div.p-movie-cassette__info')
# infos = infos.select('a.c-label')
movie = infos[0]
print('作品数:{}'.format(len(infos)))
print(movie.prettify())
複数項目の抽出
ここから複数項目の情報抽出を試みます.しかし,エラーが発生したため,エラーに対する試行錯誤も記述します.
エラー発生
前回と同様の方法で,監督の情報を抽出するためにソースコードが'a.c-label'だったので,'a.c-label'で抽出を試みた.しかし,監督だけでなく脚本・キャストも抽出されました.
確認すると,監督・脚本・キャストもソースコード中で'a.c-label'タグをつけられてました.

エラーへの対策
そのため,抽出した情報を整理する時は,リストの要素として格納するなど工夫が必要です.
抽出情報の整理もかねて,複数項目抽出のコードをmovie_info()で定義します.
コードと出力結果は以下の通りです.
def movie_info(info):
#出力用
out_list = []
# タイトル
title = info.select('h3.p-movie-cassette__title')[0].text
out_list.append(title)
# 上映日
release_date = info.select('span')[2].text
release_date = '{}/{}/{}'.format(release_date[0:4],release_date[5:7],release_date[8:10])
out_list.append(release_date)
# 製作国
country = info.select('div.p-movie-cassette__other-info')[0].select('a')[0].text
out_list.append(country)
# 上映時間
time = info.select('span')[3].text.replace('分','')
out_list.append(time)
# ジャンル(3つまで)
genre_list = ['-','-','-']
genre_web = info.select('div.p-movie-cassette__genre')[0].select('a')#ジャンルリスト作成
for i in range(len(genre_web)):
genre_list.insert(i,genre_web[i].text)
out_list.append(genre_list[0])
out_list.append(genre_list[1])
out_list.append(genre_list[2])
# 星(評価)
score = info.select('div.c-rating__score')[0].text
out_list.append(score)
# 監督
director= info.select('div.p-movie-cassette__people-wrap')[0].select('a')[0].text
out_list.append(director)
# 脚本(2人まで)
scenario_list = ['-','-','-']
scenario_web = info.select('div.p-movie-cassette__people-wrap')[1].select('a')
for i in range(len(scenario_web)):
scenario_list.insert(i,scenario_web[i].text)
out_list.append(scenario_list[0])
out_list.append(scenario_list[1])
# 出演者(3人まで)
cast_list = ['-','-','-']
cast_web = info.select('div.p-movie-cassette__people-wrap')[2].select('a')
for i in range(len(cast_web)):
cast_list.insert(i,cast_web[i].text)
out_list.append(cast_list[0])
out_list.append(cast_list[1])
out_list.append(cast_list[2])
return out_list
###################################
['ジョーカー',
'2019/10/04',
'アメリカ',
'122',
'ドラマ',
'クライム',
'スリラー',
'4.4',
'トッド・フィリップス',
'トッド・フィリップス',
'-',
'ホアキン・フェニックス',
'ロバート・デ・ニーロ',
'-']
###################################
次回への修正点
このコードをベースに複数作品の情報抽出しようとしたが,脚本が記載されていない作品もありました.そこで,リストの要素を使うのではなく,直接「脚本」等の項目で判別できるように修正します.