はじめに
- GitHubでは100MB以上のファイルをプッシュすると拒否され、50MB以上のファイルをプッシュすると警告される仕組みとなっています。
- 今回はGitHubに100MB以上のファイルをプッシュする方法を考えてみたいと思います。
Githubに100MB以上のファイルをプッシュする方法
- 100MB以上のファイルをそのままプッシュするとGithubに拒否されてしまうため、ファイルを分割してプッシュしようと思います。
- また、50 MBより大きいファイルを追加または更新しようとすると、Githubから警告が表示されるので、49MBでファイル分割しようと思います。
- 具体的には、ZIPファイルをbase64にエンコードして、49MBのテキストファイルに分割してプッシュします。
- 元のファイルに戻すときは、分割したテキストファイルのテキストを結合して、デコードすればZIPファイルに戻ります。
実装
Pythonで実装したコードが以下です。
フォルダ構成
ディレクトリ
├─main.py
├─setting.json
├─input
└─output
コード
main.py
import base64
import json
import glob
def split_text(text, split_byte_size, charcode='utf-8'):
bytes_text = text.encode(charcode)
head = bytes_text[:split_byte_size].decode(charcode, errors='ignore')
tail = text[len(head):]
if tail == text:
return []
split_tail = split_text(tail, split_byte_size)
result = []
result.append(head)
result.extend(split_tail)
return result
if __name__ == "__main__":
# 設定取得
setting = json.load(open('./setting.json', "r", encoding="utf-8"))
if setting["setting"] == "z2t":
input_path = str(setting["input"]) + "in.zip"
with open(input_path, "rb") as f:
s = base64.b64encode(f.read())
split_text = split_text(s.decode(), int(setting["byte"]))
for index, text in enumerate(split_text):
f = open(str(setting["output"]) + "file" + str(index) + ".txt", 'w', encoding=setting["encoding"])
f.write(text)
f.close()
elif setting["setting"] == "t2z":
file_txt = ""
for index, filepath in enumerate(glob.glob(str(setting["input"]) + "*")):
with open(str(setting["input"]) + "file" + str(index) + ".txt", "r", encoding=setting["encoding"]) as f:
file_txt += f.read()
output_path = str(setting["output"]) + "out.zip"
with open(output_path, "wb") as f:
f.write(base64.b64decode(file_txt))
setting.json
{
"setting": "z2t",
"encoding": "shift_jis",
"input": "./input/",
"output": "./output/",
"byte": "51380224",
"コメント": "setting:zipファイルをテキストファイルに変換する際は「z2t」、テキストファイルをzipファイルに変換する際は「t2z」、encoding:文字コード、inputは入力対象ディレクトリのパス、outputは出力対象ディレクトリのパス、byte:テキストファイル出力時の分割サイズ、ファイル名:「in.zip」または「in.txt」"
}
使い方
- 使い方は
setting.jsonの中身を書き換えて使用します。-
setting:zipファイルをテキストファイルに変換する際は「z2t」、テキストファイルをzipファイルに変換する際は「t2z」 -
encoding:文字コード -
input:入力ディレクトリパス -
output:出力ディレクトリパス -
byte:分割するバイト数
-
- ZIPファイルをテキストファイル分割する場合は、
inputのディレクトリパスに「in.zip」という名前で保存する。 - 分割されたテキストファイルをZIPファイルに戻す場合は、
inputのディレクトリパスに全てのテキストファイルを配置する。
ZIPファイル ⇒ テキストファイル
- ZIPファイルを「
in.zip」という名前でinputのディレクトリパスに配置する。

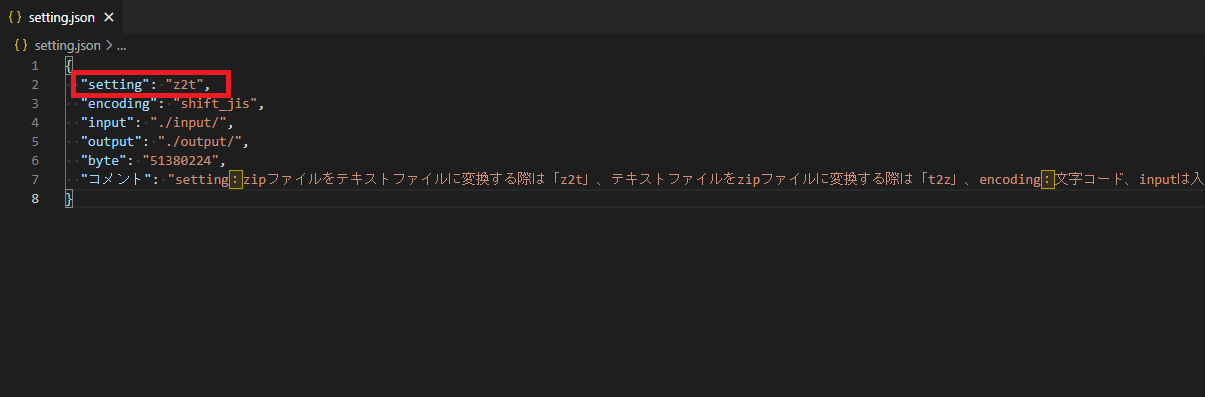
-
setting.jsonのsettingの値をz2tにする。
-
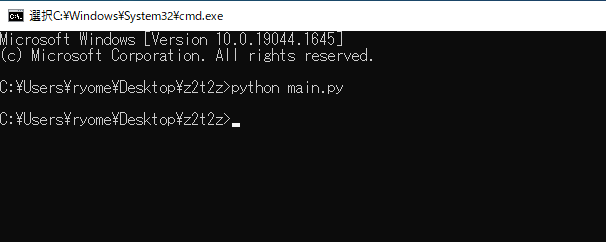
main.pyを実行する。
-
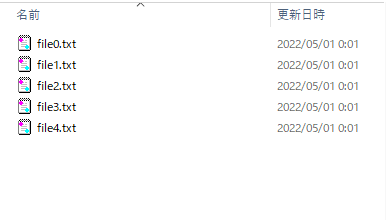
outputのディレクトリパスにテキストファイルができていれば成功。
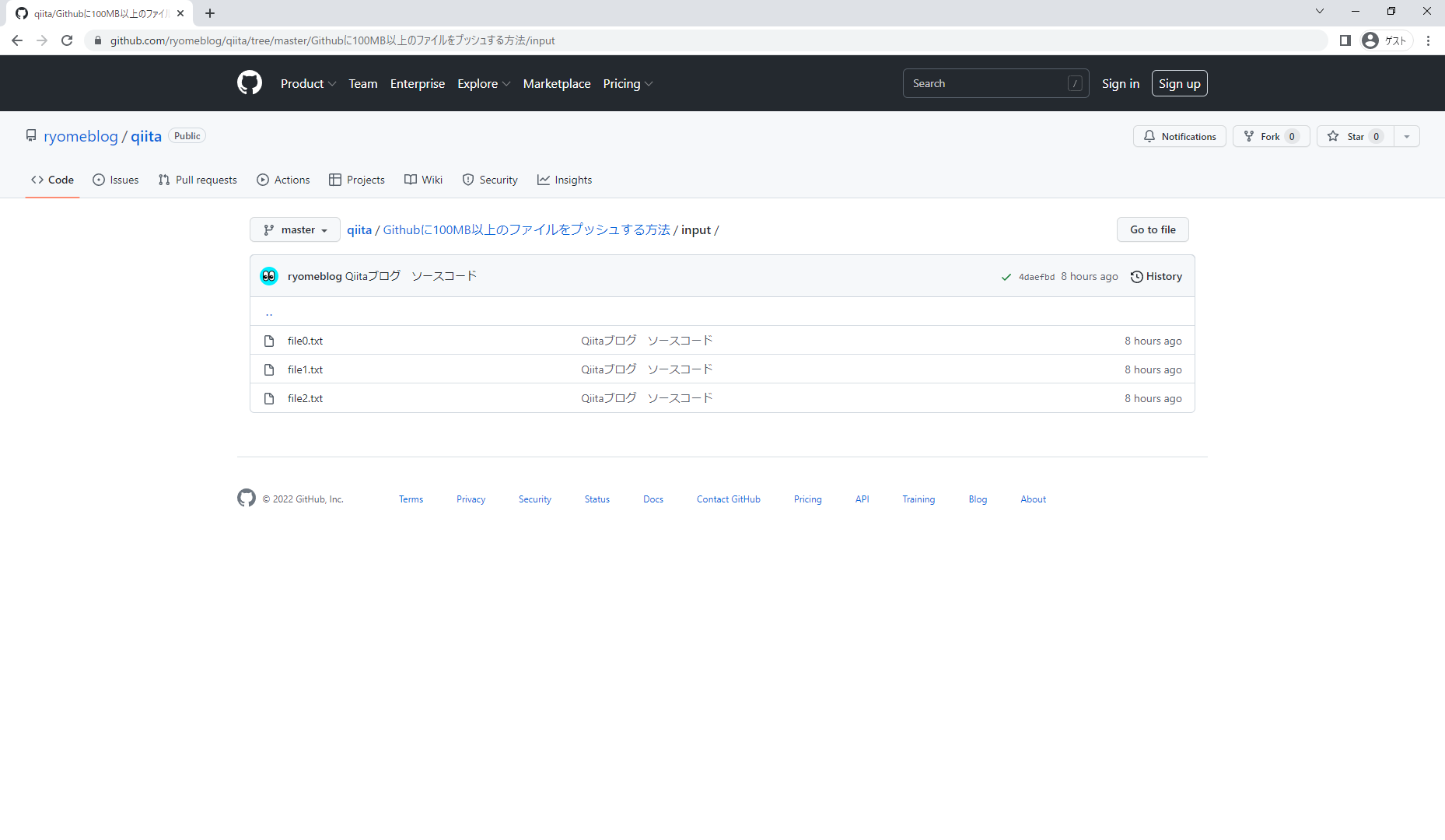
- 作成されたテキストファイルをGitHubにプッシュする。
テキストファイル ⇒ ZIPファイル
- GitHubからテキストファイルを落としてくる。
- テキストファイルを
inputのディレクトリパスに配置する。
-
setting.jsonのsettingの値をt2zにする。
-
main.pyを実行する。
-
outputのディレクトリパスに「out.zip」ができていれば成功。

GitHub
GitHubにソースコードを公開しています。