本記事の目的
Azure Machine Learning(以下 Azure ML)を触り始めて約1年立つ。ちょうど関連試験 DP-100(データサイエンス)の更新期限もあったので、整理がてら記事を書いてみることにした。
Azure MLとはMicrosoftが提供する機械学習用プラットフォームで、モデルの開発からデプロイ、運用まで一通りのことが実現できる。Azure MLでは機械学習モデルの開発方法が3パターン提供されているが、本記事ではこのうち「Notebook」のみに絞って記載する。
<Azure MLで提供されている開発方法>
開発方法1. Notebook : Jupyter Notebookベース(Python) ← 本記事のスコープ
開発方法2. 自動ML : いわゆるAutoML(ノーコード)
開発方法3. デザイナー : グラフィカルな開発ツール(ローコード)
想定する読者像は、以下のような人。
- ローカル(Anaconda環境とか)やGoogle Colaboratoryでちょっと機械学習したことがある
- Azure Machine Learningをこれから使っていきたいが、まだあまり触ったことがない
- mlflowなど機械学習のライフサイクル管理(MLOps)にもまだ馴染みが薄い
Azure ML上では機能が豊富に用意されているが、始めから色々手を出しても混乱する。まずはPythonのコードをAzure上でそのまま動かすところからはじめて、以下のように段階的にAzure MLの機能を取り入れていくのが良い。
<Azure Machine Learningの始め方>
◇ステップ1. ローカルのコードをとりあえずAzure上で動かす
◇ステップ2. 実行ログとモデルを履歴管理する
◇ステップ3. 利用するデータを履歴管理する
◇ステップ4. コンピューティングクラスタを利用する
◇ステップ5. モデルをデプロイする
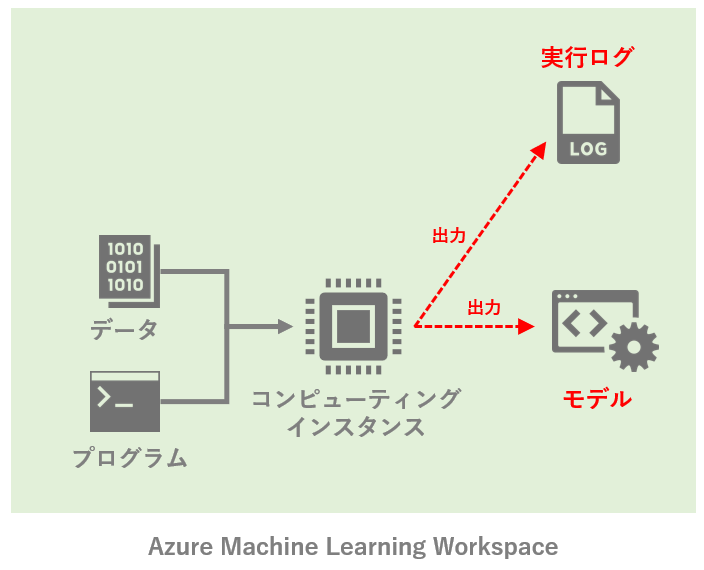
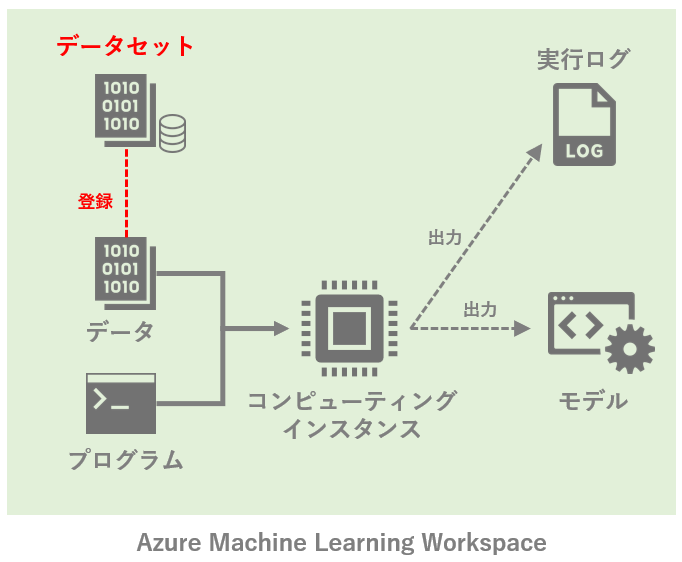
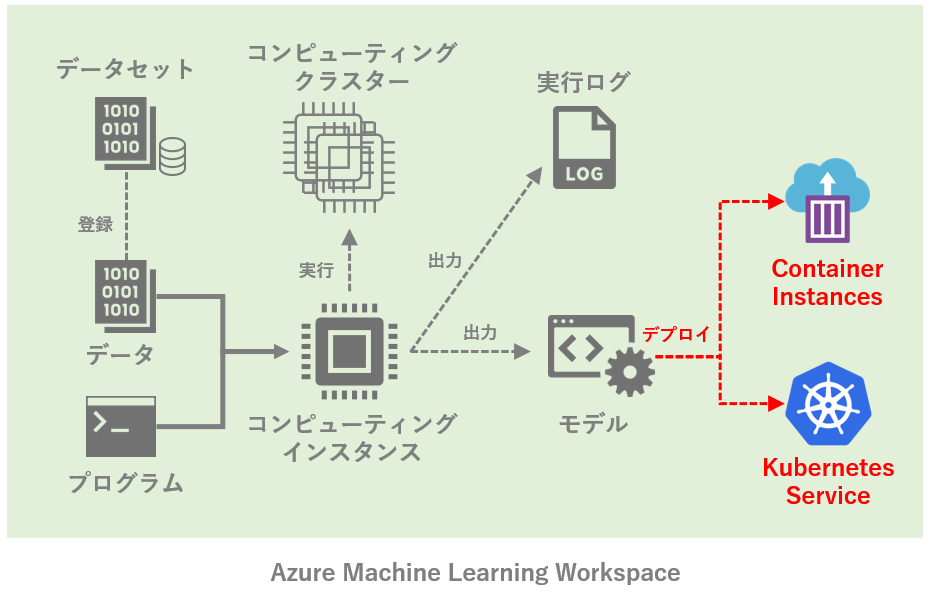
最終的に目指すのは以下のようなイメージ。ローカルで機械学習を動かしている状態から、Azure ML上でいくつかの主要な機能を使いながら動かす状態に持っていきたい。
※ 筆者が作成したイメージなので、不正確な部分などがもしありましたら是非ご指摘下さい。
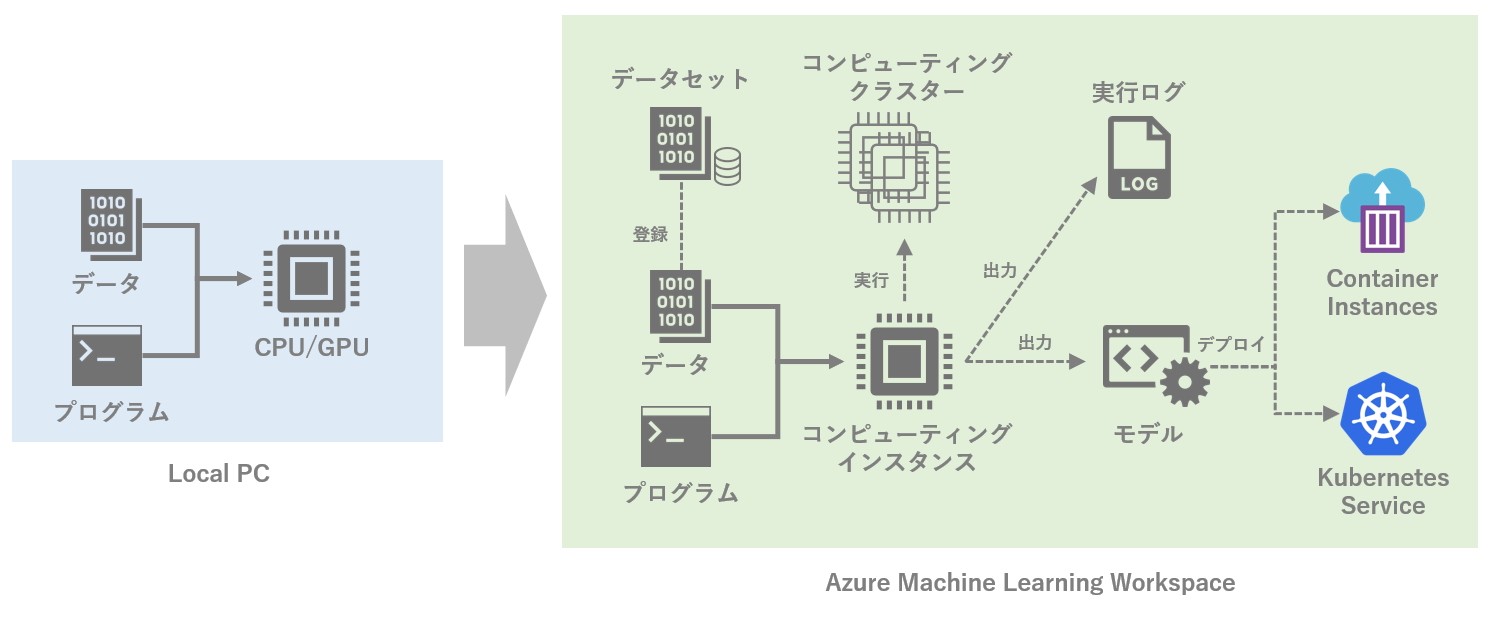
図中のAzure Machine Learning Workspaceにある機能をそれぞれ紹介するが、コンポーネントやパイプラインなど、本記事で触れていないAzure MLの機能は他にも多々ある。今後気が向けば追記するかも。
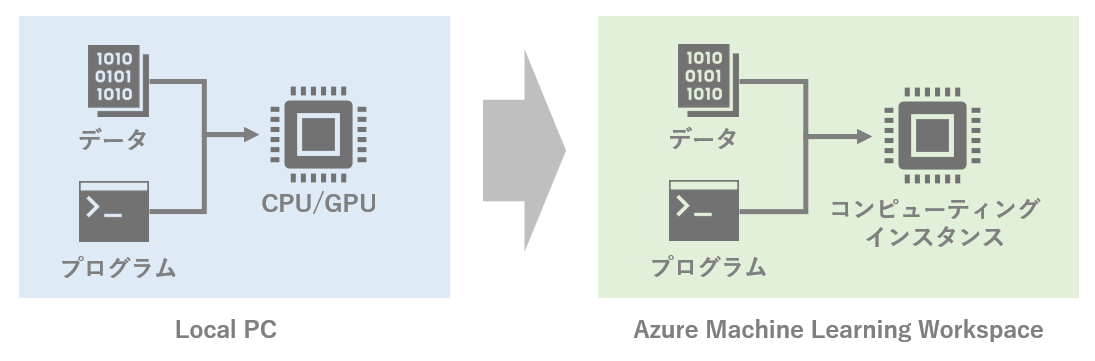
ステップ1. ローカルのコードをとりあえずAzure上で動かす
まずは、ローカルやGoogle Colaboratoryで作成済のプログラムコードをそのまま実行する。例えばローカルのPCのスペックが貧弱なので、もう少し強いコンピューティングを使う、といったシナリオ。ローカルマシンのCPU/GPUの代わりに、Azure上で作成した「コンピューティングインスタンス」を使う。
Azure側で実施しておく事前準備として、最低限必要となるのは次の3点。
<必要な事前準備>
準備 1. Azureのアカウントを作成
準備 2. Azure MLのワークスペースを作成
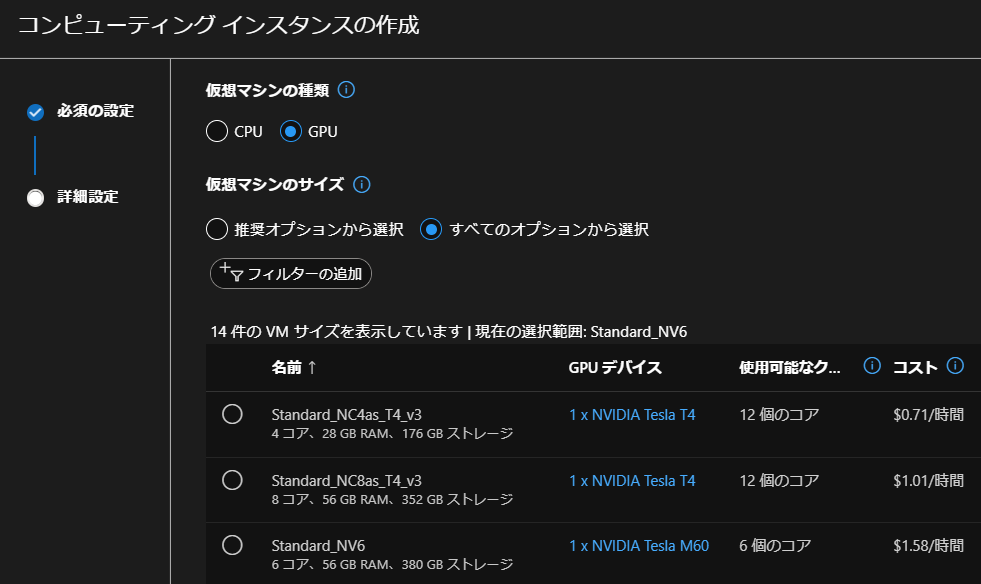
準備 3. ワークスペースでコンピューティングインスタンスを作成
それぞれの具体的な方法は、既に多くの記事が出ているので割愛。なお3のコンピューティングインスタンスの作成は、Azure MLのワークスペース上で行う。GPUのマシンでも安いものだと1時間1ドル以下から利用できるので便利。
コンピューティングインスタンスについては、私がハマった次の2点を注意事項として挙げておく。
- コンピューティングインタンスは複数ユーザで共有できないため、個々の開発者向けにそれぞれ作成する必要があり、開発者が増えると必然的にコンピューティングインスタンスの数が増える
- コンピューティングの課金はインスタンス停止をすれば止まる一方で、コンピューティングインスタンスの裏側で自動生成されるManaged DiskやLoad Balancerの課金はインスタンスを削除するまで停止できない。1台あたり月額数千円程度だが、数を増やすときは注意。

ここまでの準備ができれば、手元の「.ipynb」ファイルをアップロードして、作成したコンピューティングインスタンスで実行すれば動く。基本的なライブラリはデフォルトでインストールされているが、必要に応じて追加する。ここまでで、とりあえずAzureのコンピューティングを利用して機械学習することはできるはず。
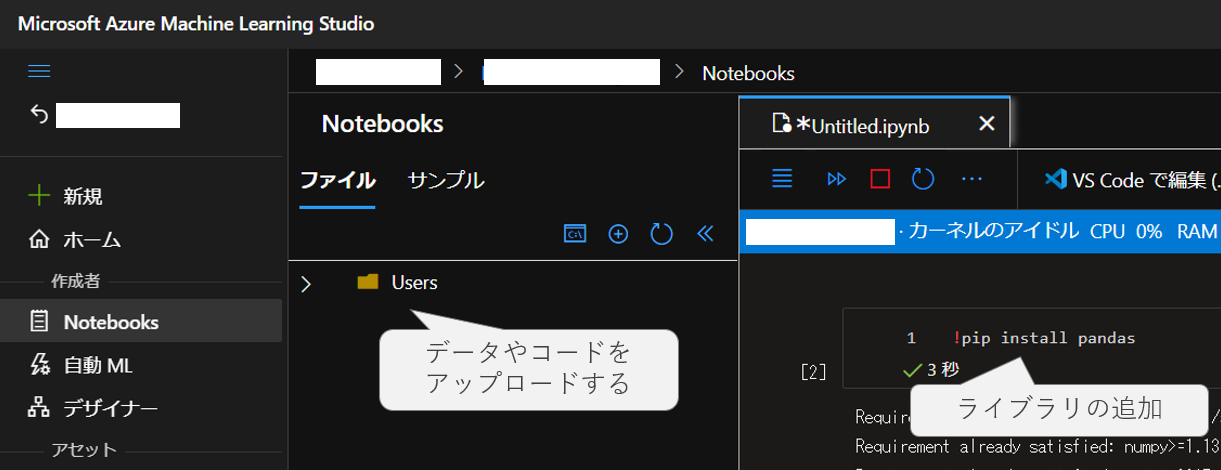
なお開発をする際は、ブラウザでJupyterNotebookやJupyberLabを使っても良いし、VSCodeからワークスペースにつなげて開発することも可能。
ステップ2. 実行ログとモデルを履歴管理する
ステップ2から先は、Azure Machine Learning SDK for Pythonの作法に従い、.ipynbにコードを追記することで機能を拡張していくことになる。Azure MLを使いこなすためには、このSDKの理解が必須となる。mlflowの利用経験があれば比較的すぐに慣れるようだが、私は全く経験がなかったこともあり理解に時間がかかった。
ステップ2では、以下のように実行ログとモデルを出力して履歴管理する。
Azure MLでは「Experiment(実験)」という概念があり、過去の実行に対して「機械学習の実行ログ」や「生成モデル」などを紐づけて保持することができる。これによって過去の実行結果を遡って確認でき、例えばアルゴリズムの変更前後でのモデル精度が容易に比較できる。また学習したモデルも併せて履歴管理することで、任意の時点のモデルをすぐに呼び出すことも可能になる。
実際の使い方としては、以下のようにWorkspaceクラスを使ってワークスペースに接続した上で、Experimentクラスで実験を作成し、実行ログの記録を開始する。
# 現在のワークスペースを取得
from azureml.core import Workspace
ws = Workspace.from_config()
# Experiment(実験)を作成
from azureml.core import Experiment
experiment = Experiment(ws, 'ExperimentTest')
# ログを記録
run = experiment.start_logging()
run.log("accuracy", 0.95) # 数値や文字列を記録
run.log_list("accuracies", [0.6, 0.7, 0.87]) # リストを記録
run.complete()
ここでは取得するログ対象として、単一の値(run.log)とリスト(run.log_list)だけを紹介したが、他にも画像やテーブルなどをログとして保存できる。
なお保存されたログはノートブック上で表示することも可能だが、可読性が低いためAzure MLのUI上で確認した方が分かりやすい。下に示した通り、リスト形式で保存したログが、自動でグラフ化されて表示されていることが分かる。
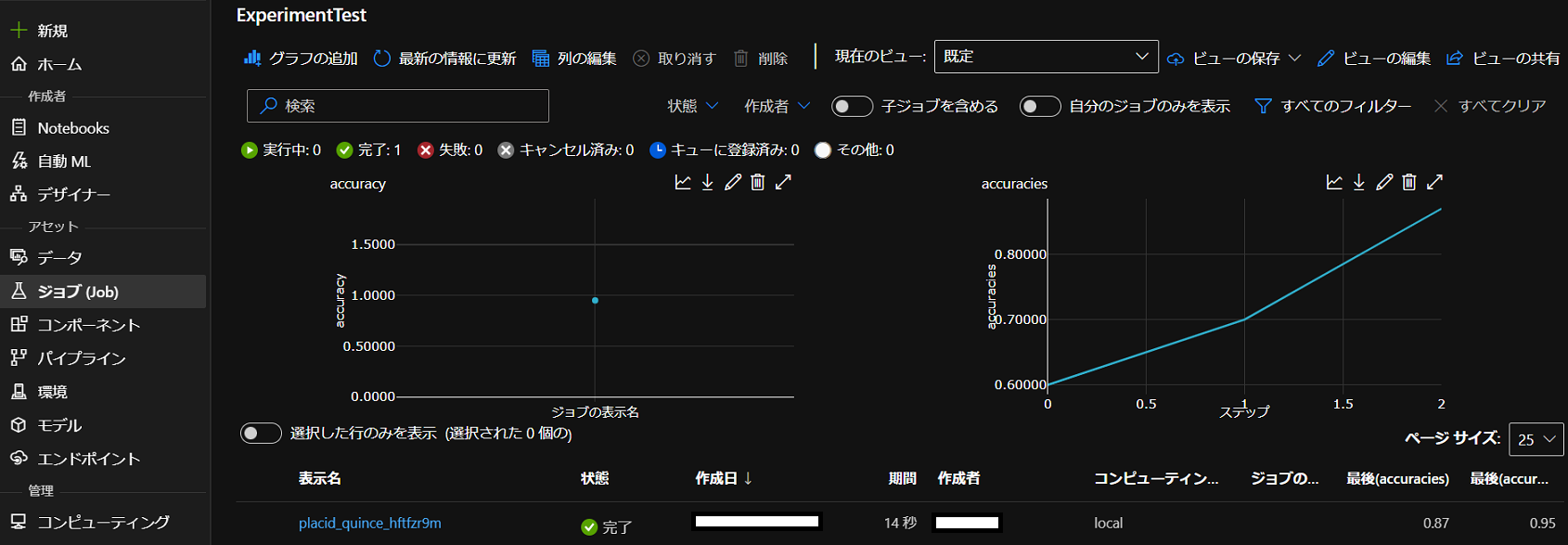
モデルの登録についても同様。run.register_model()を用いることで、生成したモデルをExperiment(実験)に紐づけて保存し、登録することができる。
# モデルの登録
run.register_model(model_name='sample_model', model_path='outputs/model.pkl')
登録されたモデルは、Azure MLの「ジョブ(Job)」というメニュー(Experimentに相当)から実験ログを辿って確認できる。また登録されたモデルは、「モデル」メニューからも同様に確認できる。下の図の通り、モデルファイルが指定した名前でバージョン管理されていることが分かる。モデルはUI操作でダウンロードすることもできる。
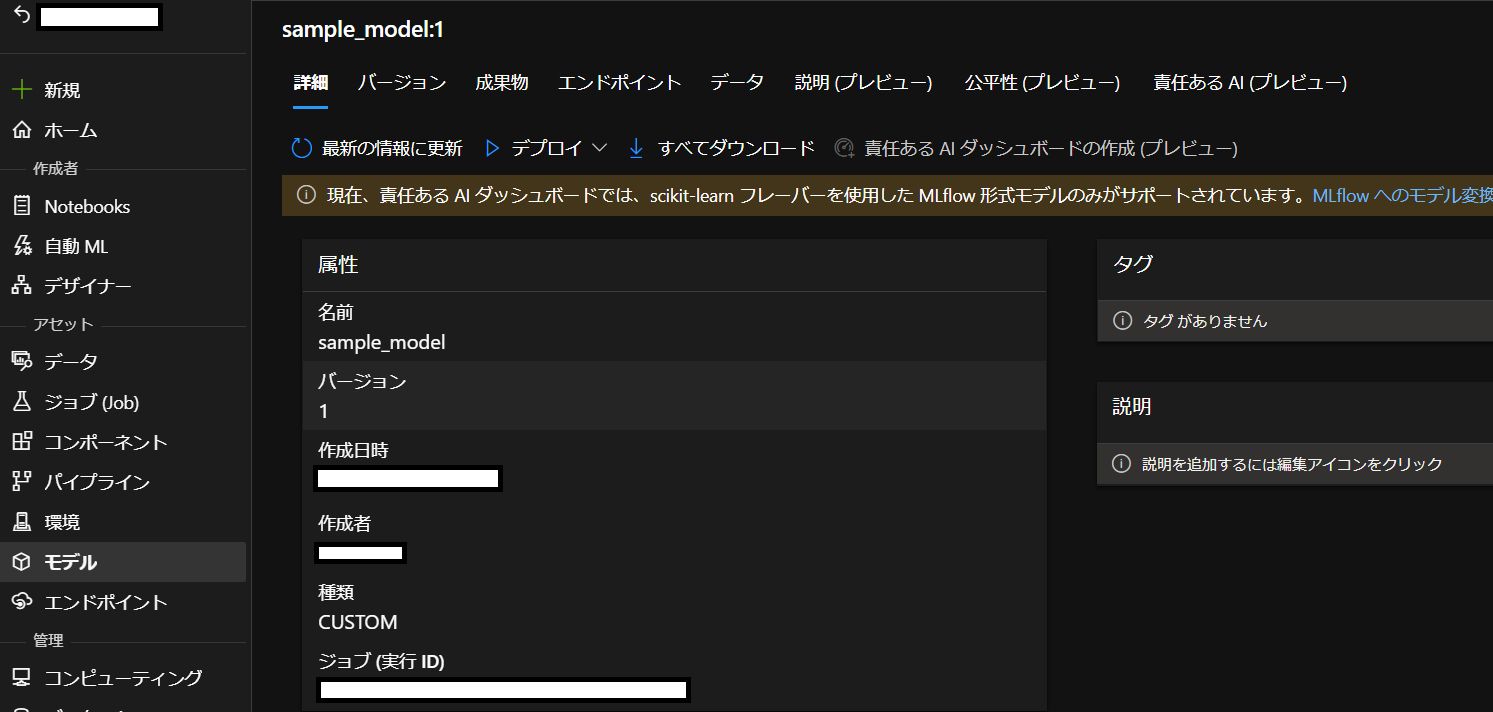
ステップ3. 利用するデータを履歴管理する
次に、機械学習で使うデータを履歴管理することを考える。これまでのようにNotebookと同じ並びにdataフォルダを作成し、データを格納するだけでも問題はない。ただ同一のデータに対して複数の開発者がアクセスしたり、データが頻繁に追加更新されたりする場合には、きちんと登録して管理しておきたい。
そこで学習や検証に使うデータを「データセット」として登録し、Azure ML上で管理することにする。
ここでデータに関わる2つの概念を紹介する。正確な説明ではないかもしれないが、次のようなイメージ。
- データストア : AzureのBLOBやDBにアクセスするためのコネクタ(みたいなもの)
- データセット : Azure ML上でファイルの実体を参照するもの
設定の流れとしては、まずデータが格納されているデータソースを「データストア」として登録し、次にデータストアにあるデータを「データセット」として登録する。データをAzure MLのデータセットに登録しておくことにより、データの履歴(バージョン)管理などが可能となる。
登録するデータストアとしては、BLOBやSQL DBなどが利用できる。
データストアとして登録できるサポート対象の Azure Storage サービスの例
・Azure BLOB コンテナー
・Azure ファイル共有
・Azure Data Lake
・Azure Data Lake Gen2
・Azure SQL データベース
・Azure Database for PostgreSQL
・Databricks ファイル システム
・Azure Database for MySQL
https://docs.microsoft.com/ja-jp/python/api/azureml-core/azureml.core.datastore.datastore?view=azure-ml-py
これらの中で任意の場所にデータを置いてデータストアとして登録すれば良いのだが、実は初めからデフォルトで登録されているものがある。Azure MLのワークスペースを作成した時に自動的に裏側で作成されたストレージアカウントである。今回はこのデフォルトのデータストアを使うことにする。
# デフォルトのデータストアの確認
from azureml.core import Workspace
ws = Workspace.from_config()
default_ds = ws.get_default_datastore()
default_ds
以下の例では「sell_prices.csv」というデータを使うため、事前にデータストア(default_dsで登録されているBLOB)にアップロードしておく。なおBLOBへのアクセスには無償のツール「Microsoft Azure Storage Explorer」を使うのが便利。
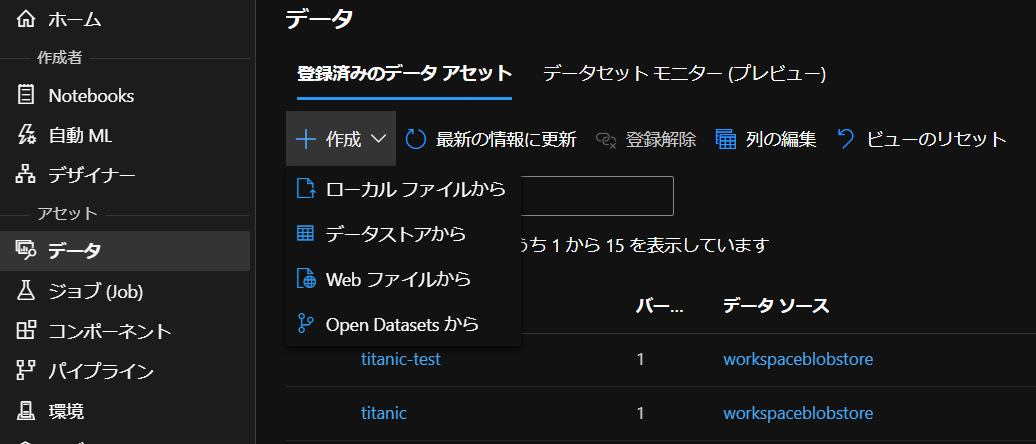
次に、データストアに置いたデータをデータセットとして登録する。登録はPython SDKからも実行できるし、Azure MLの画面からGUIで実行しても良い。Azure MLの画面から実行する場合はメニューの「データ」から作成ボタンで行う。
# データセットを登録する
from azureml.core import Dataset
default_ds = ws.get_default_datastore()
dataset = Dataset.Tabular.from_delimited_files(path=(default_ds, 'path/sell_prices.csv')) # dataset作成
dataset = dataset.register(workspace=ws, name='sell prices dataset', create_new_version=True) # dataset登録
# 登録済のデータセットを利用する
df = dataset.to_pandas_dataframe()
今回は利用データがテーブル形式(.csv)のためデータセットとしてTabular型を利用した(Tabular.from_delimited_files)。一方で画像形式などのデータセットの場合はTabular型ではなくFile型を使う。詳細は公式ドキュメント参照。登録されたデータセットは、容易に読み込みして再利用できる。
ステップ4. コンピューティングクラスタを利用する
ここまではステップ1で作成したコンピューティングインスタンス上で全ての処理を完結させていた。一方で高負荷な機械学習を実行する際、一時的に複数のCPUやGPUを並列で利用したい場面も考えられる。こういった場合には、コンピューティングインスタンスから「コンピューティングクラスタ」を呼び出して使う。
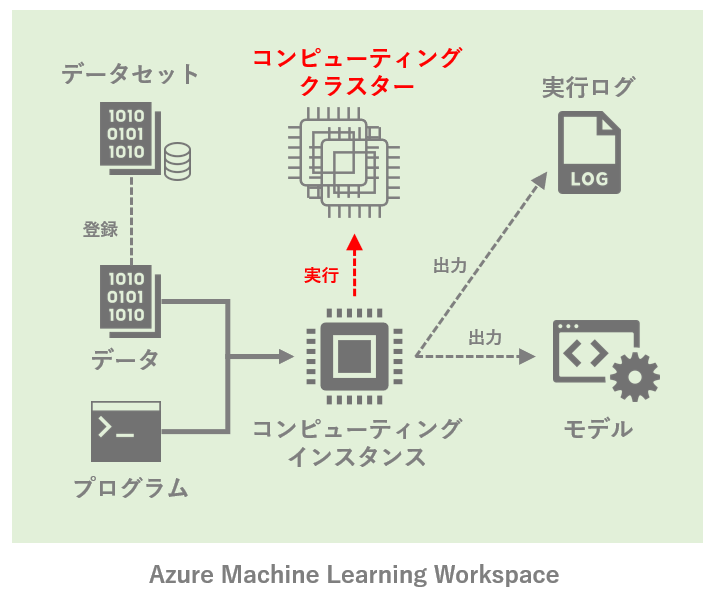
コンピューティングクラスタの作成時には、マシンサイズに加えて「最大ノード数」および「最小ノード数」を指定する。コンピューティングクラスタ内では、計算の負荷に応じて適切な起動ノード数が、指定された範囲内で調整される。例えば最小ノード数を0(デフォルト)にしておけば、処理が発生していないときはノードが起動せず、コンピューティング料金が不要となる。なおコンピューティングクラスタはコンピューティングインスタンスと異なり、同じワークスペース内で他のユーザと共有して利用できる。
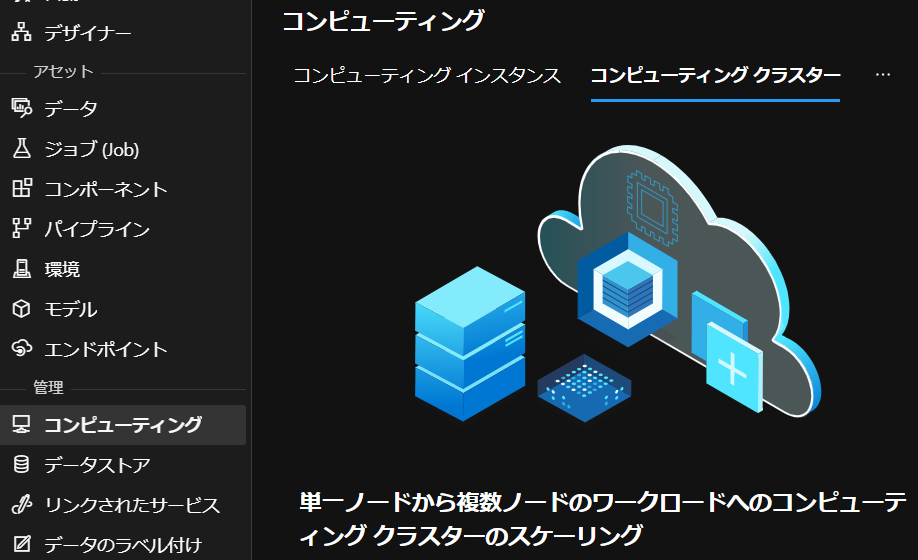
コンピューティングクラスタの作成は、Azure MLのGUI上でもPython SDKでも簡単に行うことができる。
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# コンピューティングクラスタの作成
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=4)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name='cpucluster', compute_config)
cpu_cluster.wait_for_completion(show_output=True)
作成したコンピューティングクラスタを利用する際は、実行の仕方を少し工夫する必要がある。具体的には、一連の処理をPythonスクリプトとして用意しておき、それをScriptRunConfig()で呼び出して実行する形をとる。以前はEstimator()というものもあったが、現在は非推奨なので注意。
<コンピューティングクラスタを使って学習を行う手順>
手順1. 学習用のPythonスクリプトを保存する
手順2. ScriptRunConfig()でスクリプトやクラスタを指定して実行
学習用のPythonスクリプトについては、学習用のコードを.py形式で保存しておけばよい。ただしステップ2で説明したように、履歴やモデルの保存のためにrun.log()やrun.register_model()などを入れておく。ここではスクリプトを「training.py」として保存する。またExperiment(実験)はスクリプトの呼び出し元で定義されるため、スクリプト内では新しい実験は定義せず、実験コンテクストを取得して用いる点に注意する。
from azureml.core import Run
from azureml.core import Model
# 実験コンテクストの取得
run = Run.get_context()
'''
メインの学習処理(必要なログは保存しておく)
'''
# 各種ログの保存
run.log('batch_size', batch_size)
run.register_model(model_name='model_name', model_path='model.pkl')
# Experimentの記録の終了
run.complete()
次にScriptRunConfig()から「training.py」を呼び出し、先ほど定義したコンピューティングクラスタ「cpu_cluster」上で実行する。
from azureml.core import ScriptRunConfig, Experiment
# 実行するスクリプトやコンピューティングクラスタ、環境を指定する
config = ScriptRunConfig(source_directory='.', script='training.py', compute_target=cpu_cluster)
# Experiment(実験)を定義して記録を開始して処理を実行
experiment = Experiment(ws, "PipingPicture")
run = experiment.submit(config=config)
ここでの注意事項として、デフォルトではDockerイメージ「azureml.core.runconfig.DEFAULT_CPU_IMAGE」がコンピューティングクラスタに適用される。
ここで提供されていないライブラリを利用する必要がある場合には、Environment(環境)をユーザ側で定義して渡す必要がある。Environmentについてはここでは説明を割愛するが、pipやcondaを用いて必要なライブラリを指定できる。詳細は公式ドキュメント参照。
ステップ5. モデルをデプロイする
最後に、Azure MLに登録されたモデルをデプロイし、Web APIで利用できる形でサービス化する。デプロイ先としては基本的にAzure Container Instances(ACI)またはAzure Kubernetes Service(AKS)のいずれか。AKSの方はどうしても管理上の手間がかかるため、とりあえずはACIの利用で良さそう。
モデルをデプロイする際は、学習済モデルに加えて、一連の実行処理を「エントリスクリプト」としてpython形式で保存しておく必要がある。エントリスクリプトの中では、以下の2つを記述する。
1. init() : サービスが初期化されたときに実行する処理を記述
2. run() : APIが呼び出されるたびに実行する処理を記述
import json, joblib
import numpy as np
from azureml.core.model import Model
# サービスが初期化されたときに実行
def init():
global model
# モデルの読み込み
model_path = Model.get_model_path('registerd_model')
model = joblib.load(model_path)
# APIが呼び出されるたびに実行
def run(input_data):
data = np.array(json.loads(input_data)['data'])
output_data = model.predict(data)
return json.dumps(output_data)
あとは定義したエントリスクリプトを用いて、サービスをデプロイできる。今回は以下の通り、cpuコア0.9, メモリ1GBのACIにデプロイした。ちなみに小ネタだが、cpuは課金体系の関係で0.9や1.9にすることで少しだけ節約になる。理由はこちらで記載した通り。
from azureml.core.model import Model, InferenceConfig
from azureml.core.webservice import AciWebservice
service = Model.deploy(workspace = ws,
name = 'my_api',
models = [ws.models['classification_model']], # モデルは複数のリスト
inference_config = InferenceConfig(runtime="python", entry_script="score.py"),
deployment_config = AciWebservice.deploy_configuration(cpu_cores=0.9, memory_gb=1))
service.wait_for_deployment(show_output=True)
最後に、デプロイされたサービスをサンプルデータを用いてテストする。
import json
x_test = [ 0.1, 0.3, 0.4 ] # テストデータ
input_json = json.dumps({"data": x_test}) # JSON形式に変換を行う
predictions = service.run(input_data=input_json) # サービスの呼び出し
以上でAzure MLのNotebookを用いた開発からデプロイまでを一通り学んだ。
おわりに
冒頭に紹介した「目指す最終形」を改めて再掲します。
様々な機能がAzure MLでは提供されていますが、段階を踏んで少しずつ利用を進めていけることが伝わっていれば幸いです。
MLOpsの観点からも、今回紹介した各機能+αを使いこなせるとメリットは大きいと思います。また個人だけでなく、チーム全員で使うことでより価値が発揮されると思います。まだまだ少ないAzure MLの「やってみた」系の記事が今後もっと増えてくると良いと思いました。
最後に、公式ドキュメント等を確認しながら間違いがないように気を付けていますが、もしお気づきの点があればご指摘下さい。