本記事の目的
先日、Azure Machine Learningで開発した機械学習モデルを初めてデプロイした。
Azure Machine Learning自体使い慣れていなかったので苦労したが、最終的にはこちらの記事で書いたように、ACIにデプロイしてPowerAppsからPowerAutomate経由でAPIを叩く形で利用できるようになった。
今回モデルのデプロイするにあたって勉強したところや躓いたところを残しておく。
デプロイ先の選択肢
Azure Machine Learningではデプロイ先として次の3つの選択肢がある。
基本的に下に行くほど機能はリッチだが高価。
- Local
- Azure Container Instance(ACI)
- Azure Kubernetes Services(AKS)
Local
基本的にテスト目的での利用。
Notebookを実行しているコンピューティングインスタンスから、同じVM上にモデルをデプロイする。他のリソースを利用するわけではないので、特に追加のコストは発生しない。
モデルができたらとりあえずローカルにデプロイして、API応答がうまくいくかのテストにのみ利用していた。
from azureml.core.webservice import LocalWebservice
# This is optional, if not provided Docker will choose a random unused port.
deployment_config = LocalWebservice.deploy_configuration(port=6789)
local_service = Model.deploy(ws, "test", [model], inference_config, deployment_config)
local_service.wait_for_deployment()
Azure Container Instance
簡易的なデプロイで問題ない場合に利用。
今回の開発ではモデルが比較的軽量で冗長構成も必要なかったため、最終的にACIでデプロイした。
開発途中、ACIにデプロイしたエンドポイントにrequests.post()で問合せをした際に、なぜか502 Bad Gatewayのエラーが返ってくるという事象があった。どうやらACI側の負荷が問題となっていたようで、ACIのメモリサイズを上げることで解消できたが、もし解決できなければAKSを利用していた。(AKSでは全く問題なく動いていた)
負荷と費用の観点から見ると、まずはACIのメモリサイズを上げることで対応、それでも対応ができない場合はAKSに変更する、という流れになりそう。なお公式ドキュメントによるとACIでのモデルのサイズは1GB未満が推奨されているので、基本的にこれ以上であればAKSを利用することになる。
またACIにデプロイした時のコンテナインスタンスの課金で、分かりづらい点がある。
- コンテナインスタンスの費用はメモリとvCPUのサイズによって決まる
- メモリは小数点第二位で切り上げされるのに対し、vCPUは小数点第一位で切り上げされる
- ACI上には明示的に作成したコンテナの他に、「azureml-fe-aci」というコンテナが自動生成される
- 「azureml-fe-aci」のコンテナサイズはメモリ0.5GB、vCPU 0.1である
「azureml-fe-aci」は推論実行要求を受け付けるフロントエンドポイントで、自動的に生成される。
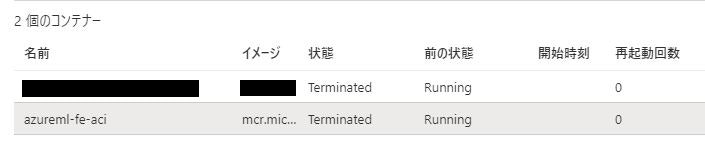
つまり、自身が明示的に作成したコンテナサイズが例えばメモリ1GB、vCPUが1.0だとすると、「azureml-fe-aci」と合計でメモリ1.5GB、vCPU 1.1となる。この時、vCPUは小数点第一位の切り上げなので、vCPU 2.0分の課金となってしまう。作成するコンテナサイズは0.9 vCPUとか1.9 vCPUとかにした方が良い。
from azureml.core.webservice import AciWebservice, Webservice
from azureml.core.model import Model
deployment_config = AciWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "aciservice", [model], inference_config, deployment_config)
service.wait_for_deployment(show_output = True)
print(service.state)
Azure Kubernetes Services(AKS)
スケール可能な本番環境向けの利用。
高速な応答時間、負荷に応じた自動スケーリング、認証機能など高性能。さらにIPアドレスの範囲によるアクセス制限やロールベースのアクセス制御も行える。ただしACIと比較してコストは高くなる。
自動スケーリングや認証機能は本番リリースする場合には必要だと感じたが、今回はPoC目的のモデル開発&リリースということでコスト面を重視してACIを選択した。なお、利用しない時間帯はAzure Automationを使ってAKSを停止するといったこともできるらしい。
AKSで利用する推論クラスタはGUIで作成することができる。
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
おわりに
Azure MLでは機械学習のワークフローはAzure Machine Learning SDKを使って実行しますが、公式ドキュメント以外の「やってみた」系の情報がWeb上であまり見つからず、また私自身コーディング自体にも不慣れなところが多かったため、わりと苦労しました。(Microsoft社のサポートの方々に相当助けられました...感謝です!)
AKSやコンテナといった知識もなかったためモデルのデプロイまで実装できるか不安でしたが、Azure Machine Learningの機能を活用を利用することでなんとか実現できました。特にデプロイ先について、Local/ACI/AKSとコードを少し変更するだけで簡単に切り替えることもできたのは、とても便利で感動しました。
機械学習モデルの開発からデプロイまで、Azure MLのNotebookで全て完結できるのは便利だと思うので、引き続き勉強しながら利用していきたいと思います。