この記事は、ロドニー・ブルックス氏のブログ記事 "[FoR&AI] Steps Toward Super Intelligence III, Hard Things Today" の翻訳です。訳者によるまとめはこちら。
[これは4つあるエッセイの3番目である -パート1はこちら]
もしも我々が人間と同程度の人工知能、たとえばこのエッセイのパート2のECWやSLPのような人工知能を開発し、更には人間を超えていきたいと望むのであれば、今日のAIには何がまったく不可能なのかを知る必要がある。そうすれば、研究の努力をどこに投入する必要があるのか、超知能へと向かう進歩がどこに進んでいくのかを知ることができるだろう。
ここで私が選んだ7つの能力は、具体的な事例から始まっているが、後になるにつれて曖昧でスペキュレーティブになっていく。だから、今日我々がどこまで近づいているか比較的容易に分かるだろうし、また今後も研究を続けていく必要があることは何かも認識できるだろう。これらの問題が解決されるに従って、我々が住む知的世界は現在とは異なる形になっていくだろう。そしてその変化はそれ以前の研究結果に依存する。だから、我々が確信を持って語れるのは、我々が発展を担うであろう短期的な問題のみである。
そして、ここで私が短期的と言っている意味は、我々が既に過去40年余り、一部は60年以上も取り組んできた問題を指している。
また、ここで取り上げたものと同じ程度の難易度の、現在のAIが解決不可能な問題は他にも多数存在している。ここでは7件だけを選択したが、やるべきことは他にもたくさんあることに注意してほしい。
1. 真の画像認識
ディープラーニングは、画像のラベリングについて目覚しい発展を遂げた。多くの人は、コンピュータビジョンは今や解決済みの問題だと考えているようだ。しかし、これはまったく正しくない。
以下の写真は、トム・カーパー上院議員が、環境・公共事業上院委員会 [Senate Committee on Environment and Public Works] のメンバーとして出席したときのものである。委員会の公聴会は、2018年6月13日水曜日の朝に開かれた。アメリカの道路や橋の上に、自動運転技術が出現しつつあることの影響を検討するものである。

彼が示している写真は、今やよく知られるようになった、自動運転車用に訓練されたディープラーニング視覚システム特有の欠陥を表している。左側の一時停止の標識には、黒と白のテープで注意深く印が付けられている。ディープラーニングシステムは、もはやこの標識を一時停止の標識であると認識できず、制限時速45マイルの標識であると考えてしまうのだ。目を細めてこの標識の写真をよく見れば、「S」と「T」の下部が「4」のようにも見え、「O」と「P」の下部が「5」っぽくも見えるかもしれない。
しかし、なぜ自動車を十分に長い時間走行させられるような視覚システムが、これほど酷い間違いを犯すのだろうか。一時停止の標識は赤だ! 制限速度の標識は、赤ではない。ディープラーニングは、標識が赤であるかそうでないかの違いを確実に見分けられるのではないのか?
そうではないのだ。我々が、一時停止標識の赤色が明白で顕著な特徴だと考えるのは、人間の視覚システムが色一貫性 [color constancy] を検出できるよう進化してきたからなのだ。異なる光の条件のもとでは、同一物体も異なる色の光を反射する - もしも、「これは赤色だ」と我々が感じる画像の画素を拡大したとすると、画像上には赤の値はまったく存在しないかもしれない。実際は、我々の視覚システムが、影の検出、特定の物体が何色である「べき」かという知識、「我々の脳が検出した色」同士の局所的な位置関係などを含む、あらゆる種類の手掛かりを使用して色を認識しているのである。これは、カメラ画像中の画素に含まれた赤/緑/青の画素値を単純に取得することとは著しく異なる。
ディープラーニングシステムの訓練用に使われるデータセット内には、画像中の特定領域に対する詳細な色ラベルは存在していない。また、色一貫性検出のための計算は極めて複雑である。そのため、この問題はディープラーニングシステムが簡単に乗り越えられるようなものではないのだ。
以下に示した5x5のチェッカー板の合成画像を見てほしい。これは、MITの教授、テッド・アーデルソンが作成したものだ。我々はこの画像を見て、これはチェッカー板である、なぜなら白と黒の、あるいは少なくとも相対的に暗い色と明るい色の正方形のマス目が交互に置かれているからだ、と言うだろう。しかし、ちょっと待ってほしい。画像中には正方形はまったく存在しない。それらは歪んでいる。我々の脳が二次元の画像から三次元的構造を取り出して、これは本当は平面上の正方形の板であり、正方形の各辺が我々の視線と直交しない角度から見た光景だろうと推測するのである - これにより、我々が目にする一貫したパターンの歪みが説明される。
しかし、ちょっと待ってほしい。もう1件ある。画像中で「同じ[same]」とマークされた2つの潰れた正方形をよく見てほしい。一つは確かに黒で、もう一つは確かに白に見えるだろう。しかし、我々の脳が真実を見ることを妨げているために、この画像は読者の脳を騙しているのだ。
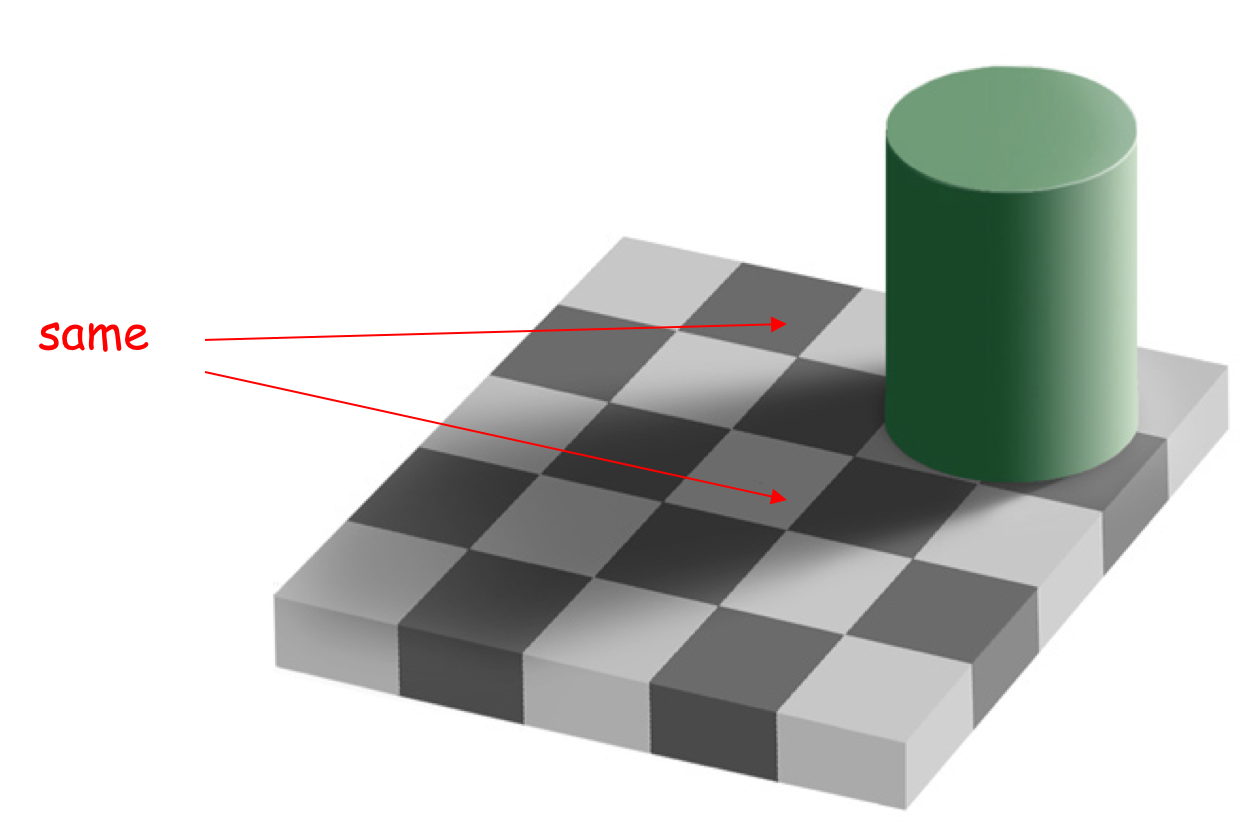
画像の一部を切り出してみよう。左側の画像は、上部の(黒の)正方形から、中央は下部の(白の)正方形から切り出したものである。

個別に見れば、どちらも明確に黒だとも白だとも言えないだろう。我々の視覚システムが、緑の円柱の影を見て、知覚される明るさを補正するために、我々には白い正方形が見えるのだ。また、そこは更に暗い影付きの黒色の正方形に囲まれているために、この効果が増すのである。上記最も右側の画像は、「same」とラベルが付いた領域の間にある、影が落ちた黒の正方形の一部から取ったものである。もしも信じられなければ、画像をプリントアウトして、対象の2つの領域以外全体を覆い隠してみてほしい。まったく同じ灰色であることが分かるだろう。
これと類似の事例としては、私が昨年書いた記事「ロボットであるとはいかなることか?」の中の、青色の(しかし赤色に見える)イチゴを見てほしい。
この事例は、生物の知覚システムが進化的タイムスケールを掛けて発展させてきた、おそらく100個とある小さな (あるいは大きな) トリックの一例である。他には、人々の声から韻律 [prosody] を引き出すこと、環境中の雑音を自動的に補正すること、ある人の話し方に対する個別的な知識、更に一般的には、声から性別、年齢、母語やあるいはその人の出身地までもを推測できる能力が挙げられるだろう。我々はこれらを行うことに何の努力も必要としないが、しかし、こういった能力のおかげで、我々は他の人々と世界の中で協調でき、またバカげた社会的非礼が防がれているのだ。別の例としては、音声から空間を推定する能力がある。モノラルの電話回線越しでさえ - 相手が大きな空間がある建物の中にいるのか、屋外にいるのか、運転しているのか、風が吹いているのかを、単に話し声の質からだけでも理解できる。更に別の事例としては、絵から人間の顔を容易に認識できる能力もある。32ピクセル四方以下の、過去に一度も会ったことがなく写真を見たこともない人物の若い頃の似顔絵だけからでも人の顔を識別できる。人間は、信じがたいまでに顔の認識に優れている。最近の進歩にもかかわらず、我々は未だ我々自身が作ったプログラムよりも顔認識に優れている。リストはまだ続けられる。
ECWとSLPがこれと同種の100個もの隠れたトリックを習得できない限り、AGIエージェントたちが我々と同じように世界を理解することも、任されたタスクを遂行することもできないだろう。彼らはずうずうしい無能にしかなるまい。年老いたロドニーおじさんが物の名前を思い出せず、ECWに対して「そこの赤いもの!」と言ったとする。画素の値からはまったく赤に見えない物体を「赤色」とマッピングできなかったら、ECWはうまく働くことはできないだろう。
2. 真の物体操作
私は、何も見ないままで、苦もなくズボンのポケットに手を入れて中にある車の鍵を取り出せる。けれども、近い将来には、私は自分のズボンのポケットの近くへとロボットハンドを接近させることさえできないだろう。
器用な物体操作は、途方もなく難しい。そして、器用な手を作ることはまったく簡単ではない。何をすればロボットハンドに大きな進歩を起こせるのですか、といつも私は質問を受ける。もしも私がその方法を知っていたら、とうの昔に試していただろう。
1977年、スタンフォード大学の人工知能研究所に参加した直後、私はロボットアームのプログラミングに着手した。下に載せた「ゴールドアーム」の写真は、私がプログラムを組んだ2台のロボットアームのうちの1台である。スタンフォード大学コンピュータサイエンス学科の建物の入口で、ケースの中に飾られている。ロボットの「手」、スライドして近づいたり離れたりする平行の指が分かるだろうか。これが当時存在した「手」のすべてだったのだ。

そして、以下の写真は、40年後の2017年に私の会社が販売しているロボットアームであるが、根本的に同一の機械的設計を踏襲している。(ボールねじが平行な2本の指をスライドさせ、物を挟んだり離したりする。指先端の内側には、柔らかいクッションが取り付けられている (上記の1977年のロボットハンドでは、片方の指からクッションが脱落してしまっている)) これが我々が持っている「手」のすべてなのだ。過去40年間、ロボットアームは実質的にほぼ変化していない。

けれども、このようなロボットハンドを超えたところでは、人間に可能なタスクを行えるロボットハンドの製造には近付いてすらいない。発送センター、つまりオンラインショッピングサイトの注文をパッキングする施設では、注文に対して梱包が必要な商品すべてを一ヶ所に集約する作業は、ほとんど解決済みである。ロボットが異なる商品の詰まった棚を持ち運んでいる。しかしその後、個々の棚から正しい商品を取り出すのは人間であり、個別の注文に対して適切な梱包材を選び、発送用の箱へ商品を梱包するのも人間である。商品のピッキングとパッキングは、自動化によって解決されていない。鉛を金に変えるのと同じような経済的モチベーションがあり、この分野で多くの研究がなされているにもかかわらずそうなのだ。
更に大きな問題は、やわらかい物体を操作することである。たとえば、アパレル工場で使われる布地、薄くスライスされた肉、あるいは人間をベッドの上に寝かせることなどについては、わずかな進歩しか見られない。我々のロボットはこういった物を扱えないのだ。これはSLPにとっては問題にならないが、ECWには大問題である。
ところで、私がいつも苦々しく感じることがある。他の研究者が新しいロボットハンドのデモを見せるとき、ロボットハンドがロボットアームの先端に設置されているのではなく、人間の研究者がロボットハンドの「手首」を持って移動させているのを見るときだ。読者も、リーチグラバー [いわゆるマジックハンド、手の届かない高所にある物を取るために使う] を使ったことがあるか、または誰かが使っているのを見たことがあるだろうと思う。 これは、オンラインショッピングサイトから適当に (マウスを使って!) 持ってきた画像である。

そこで、もしも読者がこのようなリーチグラバーで遊んだ経験があるのならば、シンプルなプラスティック製の2本の指とただ1通りの挟み動作だけで、あなたはロボティクス研究史上のいかなるロボットよりも器用な操作が可能となる。つまり、シンプルな「はさみ」、その後ろにある人間の脳、そして触覚のない遠く離れた「指」だけを使うだけで、ロボットが物を掴み、操作することがいかに難しいか理解できるだろう。
3. 本を読むこと
人間は、書籍を通して、最近では「ハウツーもの」のビデオを通して、スキルと知識を伝達する。最近、さまざまな「ロボット」あるいはAIシステムが、ビデオ視聴や読書を通して学習可能であるという主張を多数目にしたかもしれないが、これらのデモンストレーションは、人間の子供の能力水準にはまったく達しておらず、人々がうたうアプローチが人間レベルのコンピタンスへと一般化できる可能性は低いだろう。このポイントは後でもう一度触れる。
しかしその前に、ここではAIシステムが一般的な読書についての人間レベルのコンピタンスを獲得したいと考えた場合、あるいは、ビデオの視聴を通して本当にスキルを学ぶためには、何をする必要があるのかを説明しよう。
普通の本は、数学の証明のようにすべての推論のステップを含めて書かれているわけではない。実際のところ、数学の証明もそんなふうに書かれているわけではないのだが。我々人間が本を読むときには、我々の背景知識と理解のプロセスを協調させ、数え切れないステップを埋めるのである。
なぜこれが上手くいくのだろうか? それは、人間が本を執筆するとき、著者はあらゆる人間の読者が保持している背景知識を暗黙のうちに知っているからである。そこで、著者は本を読む人間の読者が、保持している背景知識を理解しているという前提で執筆するのである。そこで、読書するAIシステムも同等の前提知識を持っていなければならない。
「ちょっと待ってくれ」、機械学習の「飛行機は鳥にあらず」説の信奉者は言う! 超知能は、超知能に向けて書かれた本を読むと考えるべきであり、単なる人間のために書かれた本を読む必要はないのだ、と。しかしこの主張には、当然、2つの問題がある。1つ目に、もしも本当の超知能であれば、単なる人間が理解できることは当然理解可能でなければならないだろう。2つ目は、我々は現在いる場所から超知能へと進まなければならないのだから、何らかの方法により我々の超知能の子孫らをブートストラップしなければならない。そこでは、真に超知能に向けた本を執筆するより前に、単なる人間に向けて書かれた本から学ぶ必要があるだろう。
しかしここで背景知識の話題に戻ろう。背景知識とは、我々全員が世界について知っていることであり、また他の人々も知っていると予期しうる世界についての知識である。たとえば私は、今現在あなたに、読者諸君に対して、今この瞬間、地球上の知的な読者と議論参加者の全体は、すべて生物学的にはホモ・サピエンス種のメンバーであると説明する必要はないと考えている。読者は既に十分にそれを知っているはずだから。
これは「常識」的な知識とも呼べるだろう。我々(我々人間)が世界を理解するための必須要素であり、人間同士のあらゆるコミュニケーションにて想定される背景である。それだけではなく、常識は我々が行動計画を立てるためにも必要となる。
2人のNYU教授、アーネスト・デイヴィス (コンピュータ科学) とゲイリー・マーカス (心理学・神経科学)による最近の記事は、人間が世界を理解するためにどれほどの常識に頼っているか、また何がコンピュータには欠けているのかを解説している。最近ニューヨークタイムズ紙に掲載されたGoogle Duplexに関するオピニオンの他にも、著者らはコンピュータサイエンスの著名な学術誌上で、常識に関する長い記事1を発表している。これは要約である。
背が高いのは、ウィリアム王子と彼の息子のジョージのどちらだろうか? ポリエステルのシャツからサラダを作れるだろうか? 人参に針を刺すと、穴ができるのは人参と針のどちらだろうか? こんな質問は馬鹿げたものに聞こえるかもしれないが、しかし、多数の知的なタスク、たとえば文章理解、コンピュータビジョン、プランニング、また科学的推論などには、これと同じ種類の実世界に対する知識と推論能力が要求される。たとえば、身長180cmの人間が身長60cmの人間を腕に抱いているとする。そして、2人は父と子なのだと言われたとしたら、どちらがどちらなのかを質問する必要はないだろう。夕飯にサラダを作ろうと思ったらレタスを切らしていた場合、間に合わせにクローゼットからシャツを取り出して切り刻むことに時間を費す必要はない。「私は人参に針を刺した。針を抜くと、そこに穴があった。 [I stuck a pin in a carrot; when I pulled the pin out, it had a hole,] 」という文を読んだとき、「そこ[it]」が針を意味している可能性を考える必要はない。
彼らが指摘した通り、いわゆる「常識」は、我々がAIシステムにやってほしいと望むような、最も瑣末なタスクにおいてさえ重要となる。常識によって、GoogleとBingの両方が以下の文章を翻訳できる。「電話がはたらいている。電気技師がはたらいている。 [The telephone is working. The electrician is working.]」という英語の文は、ドイツ語で「電話が機能する。電気技師が労働する。[Das Telefon funktioniert. Der Elektriker arbeitet]」と翻訳される。英語の「はたらく [working]」という語の2つの意味は、ドイツ語では異なる形で扱わなければならず、ある意味において電気技師がはたらき、電話は別の意味ではたらくのである。このような常識が、何らかの形でAIシステムに埋め込まれていなければ、AIが真に書物を理解できるようにはならないだろう。しかし、この例は常識のたった1つのごくわずかな面である。
20から30語程度の文を正しく翻訳することでさえ、常識という小さな原子の複雑な化合物が要求される。ダグラス・ホフスタッターは、最近のアトランティック誌の記事で、近年のディープラーニングの発展にもかかわらず、あまりに複雑すぎるためにGoogle翻訳が扱えない短期的なコンテキストの存在を指摘している。
ホフスタッターの事例では、多数のセンテンスにわたる文脈を扱う際システムが問題を起こすのだ。人間はこれらの事例を苦もなく扱う。4歳児でさえそうだ。 (本記事パート4を参照のこと)
ホフスタッターは、自分の翻訳方法とGoogleの翻訳方法を比較してこう述べている。
Google翻訳は、言語理解の行為をバイパスし、迂回している。
...
私は、端的に言えば、言語Aの語やフレーズから言語Bの語やフレーズへ直接移動するわけではない。実際には、私は無意識のうちに映像、光景、概念を呼び起こし、私自身が経験した (あるいは、読んだり、映像で見たり、友人から聞いた) ことを掘り起こし、そしてこのような非言語的、イメージ的、経験的、精神的な「ぼんやりした光」が具現化した後 -私の脳の中にぼんやりとした意味の泡が浮んできた後- で、はじめて翻訳対象の言語で単語やフレーズを構成するプロセスを開始するのである。その後、何度も、何度も、何度も校正を繰り返すのだ。
2つ目のパラグラフで、ホフスタッターは頭の中でシーンのシミュレーションを走らせることから意味を得るというアイデアに触れている。次の項目でこの点についてもう1度考えよう。また、記事内のさまざまな場所で、彼は翻訳中にGoogle検索を使用する方法、Google翻訳がアクセスできない情報にアクセスするため手法を組み合せる方法についても指摘している。
常識によって、プログラムは、あるいは人間は、非合理な検討項目を枝刈りして取り除くことができるのである。プログラムは、あるフレーズや状況がいかなる意味を持つのか、非常に多くの選択肢を、可能性 [possibility] の領域のすべてを徹底的に洗い出すことができるかもしれない。
常識を使えば、膨大な集合をかなり小さな妥当性 [plausibility; ありそうなこと] の集合へと減少させられる。そこを超えたところで、それらの事例を狭い範囲の重要な蓋然性 [probability; 起こりそうなこと] へと削減できるのだ。可能性から妥当性から蓋然性へと。(...)
この「常識」の獲得は、シンボリックAI分野で長年の目標だった。最近、勢い盛んなディープラーニング屋たちが、自身のシステムは常識の一側面を学ぶことができたのだと主張している。その主張にはいくらかの真実が含まれているかもしれない。けれども、不幸なことに、それらのシステムは複合的であるため、実際には正しくない。- 研究者が、これこそが常識なのだとデモンストレーションするためには、通常の場合、ネットワークが生成した画像や短い動画の結果を解釈する人間が必要とされる。マイナスポイントは、ここでもまた人間の解釈者である。この機械と人間の複合体が存在しなければ、小さな子供さえ持つような人間の能力ほどに有用あるいはロバストにならないだろう。
ここでのポイントは、単に本を読むだけでも極めて難しく、多くの人々が「常識」と呼んできた何かがたくさん必要とされるということだ。このような常識をどうやってAIシステムに獲得させるかという問題は複雑なものであるため、パート4で再度検討することにしよう。
それでは、本を読めるAIシステムは既に存在するという主張に戻ろう。
以前、AIプログラムは、MITの1年生向け微積分学の試験で学部生の成績を追い抜いた。そこで、こう考える人もいるかもしれない。すぐにAIプログラムはもっと多数のMITの試験を上手くこなすようになるだろうし、MITの学位授与基準を満たすAIが現れるのもさほど遠くはないだろう、と。そうなるまでには50年以上かかるだろうと私は確信している。きわめて強く確信しているのだ。単に、MITが学部生の卒業条件として、すべての学生に水泳試験への合格を課しているからだけではない。そうではない。私がこのタイムスケールをきわめて強く確信している理由は、このプログラムが、ジム・スレイグルによってマーヴィン・ミンスキーのもとで博士論文のために書かれたプログラム2が、MITの学生を追い抜いたのは1961年だったからだ。1961年! 既に57年経っている。当時のメインフレームコンピュータの性能は、現在のプログラミング可能な電灯スイッチや自動車のリモコンキーにも劣るだろう。それでも、当時でさえAIプログラムは微積分学のテストでMITの学部生を負かすことができたのだ。
AIプログラムが、日本の大学入試試験で好成績を残した、あるいは8年生 [中学2年生] の理科の試験に合格したともてはやされているのを見たとしても、AIがすぐに人間レベルに近づき、次の新たな試験にも合格していくだろうと考えないでほしい。もう一度、これは7つの大罪の1つであり、試験という狭いタスクに対するパフォーマンスを、汎用的なコンピタンスと混同するという誤りなのだ。これらの試験に人間の方法で合格できる人間は、試験で問われるトピックにまつわる汎用的なコンピタンスを持っていると意味する。試験は人間に向けてデザインされたものであり、本質的にその試験を受ける人間のコンピタンスに関する情報を引き出すようにデザインされている。そして、試験の作成者は、人間以外の受験者について考える必要さえなかっただろう。彼らが知っているのは、人間向けの試験を作成する方法だけである。(けれども、人間の試験の場合でさえ「試験対策講座」によって試験の信頼性が落ちるという実例を眼にしたことがあるだろう。これが、あらゆる試験制度は、いずれ変更または完全刷新しなければならない理由である。) しかし、この"テスト"はAIシステムに対する"テスト"と同じものではない。ちょうど、自動車を運転するべきディープラーニングシステムにとっては、一時停止の標識に何枚かのテープが貼られると、一時停止の標識であるとは認識できなくなるのと同じである。
同時に、研究者は、また彼らの所属組織の広報部門は、7つの大罪の別の罪を犯している。彼らは、AIシステムが「読む」、「理解する」ことができると実証するために、人間用の試験に対するパフォーマンスを提示しているのだ。(先程私が主張した通り、これらの試験は機械のテストとしては有効ではないにもかかわらず)。そしてその後、研究者たちは勝利宣言をして、メディアが結果を過剰なまでに一般化することを放置しているのである。
4. 診断と修繕
ECWが自宅用高齢者介護ロボットとして有用であるためには、ECWは家の中で何かが故障した際、故障を検知できなければならない。少なくとも、修理のためにはどんな専門家を呼ぶべきかを判断しなければならないだろう。もしも、ECWが単に「何かがおかしい、何かがおかしい、でも何なのか分からない!」と言うだけだったら、そんなものはとても超知能とは考えられないだろう。最低でも、ECWはトイレの水が流れないと気付いてトイレ修理業者を呼ぶことができなければならない。また、電球が切れている場合は器用な人を呼び、あるいは家の電気がまったく使用できない場合には電力会社へ連絡する必要がある。
これほど単純な診断タスクを開始できるロボットは、現在まったく存在しない。実際のところ、自分がいる家の屋根が吹き飛ばされたと認識し、その事実を報告できるロボットが存在するのかすら私には分からない。現状のロボットに期待できることは、良くても環境に異常事態が生じたことを検知し、動作を停止する程度だろう。けれども、現実的にもっとありえそうな状況は、ロボットは動作を継続しようと試み (ルンバが高速でブラシを回転させながら犬のフンの上を通ったときのように…最悪だ)、破滅的に失敗することだろう。
しかし、人間が診断を行うときには、1つ前のセクションで私が「常識」と呼んだ何かが働いているだけではない。単純な問題であったとしても、ある種の世界のシミュレーションを実行し、可能性、妥当性と蓋然性を見ているように思える。 そのシミュレーションは、伝統的ロボティクスで使われていたような、ロボットアームが特定の軌道に沿って動作した場合の (また予期せず何かに衝突した場合に、センサからの入力と予測が矛盾していると気付けるような) 三次元的に精緻なシミュレーションではない。人間のシミュレーションはこれよりもいい加減ではあるが、時として位置関係も含むことがある。また、これは最近のディープラーニングの論文でキーとして提案されているような、二次元的な動画でもない。実際は、複数の領域にまたがる非常に複合的なシミュレーションである。加えて、メタファーを用いる場合もある。ECWが、高齢者に対して自宅環境内で信頼できる介護者として完全なサービスを提供できるためには、この種のシミュレーション能力が必要不可欠である。また、SLPにとっても、人工透析病棟の設計時、人間の移動フロー設計がどう機能するかをチェックするために、このような汎用的なシミュレーション能力が求められるだろう。
もう一度言っておくと、AIシステムとロボットは完全に人間と同じようにものごとを行う必要はないかもしれない。けれども、AIたちが人間と同じ程度に賢いとみなされるためには、彼らは人間と同等の、あるいはそれ以上の汎用的なコンピタンスを保持していなければならない。
今現在のところ、いかなるシステムであれ、常識や汎用的シミュレーション能力を備えているものは本当にまったく存在しない。これは人々がこの課題に長期間取り組んでいないと意味するのではない。私が初めて出席したAIのカンファレンス、1977年8月にMITで開催されたIJCA 77で、このテーマに関する論文から私は強い感銘を受けた。論文は、ブライアン・ファントによるもので、そのタイトルは 『ウィスパー: ダイアグラム及び並列処理網膜を用いた問題解決システム WHISPER: A Problem-Solving System Utilizing Diagrams and a Parallel Processing Retina』 であった。ファントは、当時スタンフォード大学で、「人工知能」の名付け親でありダートマス会議の主催者であるジョン・マッカーシーのもとでポスドクを勤めていた。また、マッカーシーによる「常識を備えたプログラム」に関する最初の論文が書かれたのは1958年である。人工知能研究者は、これらの問題が重要であることを長い長い間認識していたのである。過去数十年あまりの間に、これらの問題に対して研究者たちは多くの意義深い進歩を成し遂げてきた。これらの問題は困難であり未解決に留まっており、本当のプロダクトに組込めるほどには成熟していない。
「しかし、待ってくれ」と、あなたは言う。あなたはIKEAの家具を組み立てるロボットについてのニュースリリースを眼にしたことがあるのだ。確実にこの問題には常識と汎用的シミュレーションが求められるだろう。確実にこの問題は既に解決済みで、超知能はすぐそこに迫っているのだ。もう一度言っておこう。息を止めないように- 50年という期間は、人間が酸素なしで生きるには長すぎるからね。読者がこの種のデモを見る時、ロボットとプログラムの構築のために、多人数の大学院生が何ヶ月にも渡って働いているのである。家具の部品は大学院生によって (何ヶ月も前に) 箱から取り出されている。また彼らはプログラムを何度も、何度も、何度も走らせ、そしてようやく1回の動作で家具の部品を組み立てられるようになるのである。すべては学生が行なっており、すべてが完璧に行くように準備しているのである。これは、我々がECWに望むこととは完全にかけ離れている。つまり、ドアのところに届いたIKEAからの何かの荷物を受け取り、それを家の中へと運び (大学院生の手助けなしに)、箱を開けて、あの有名なIKEAの説明書を取り出してそれを読む。そしてその後、家具を組み立てるのである。
もしECWがこれらのことをできるとしたら、とても便利だろう。今日のいかなるロボットであれ、この状況下では下記各々のステップで悲惨なまでに失敗するだろう (そして思い出してほしい、これは研究者が一度も眼にしたことのない家の中にいるロボットなのだ)
- 家に配達がされたことを認識する
- 荷物を持ち運び、家の中へ運ぶ
- 何が中に入っているか正確には分からないままで、部品を傷付けないように実際に箱を開く
- 説明書を見付けて、紙を手にとって各々のページの表裏を見る
- 説明書を理解する
- 部品を正しい順番で使えるように、どこに部品を置くかを計画する
- 組み立て時に必要な場合は、2つか3つの部品を一度に扱う
- 適切な工具を発見し、手に取る (ネジ回し、木製の合わせくぎを叩くためのハンマーなど)
- 細かく熟練した動作を行い組み立てる
今日、見知らぬ家で、IKEAの家具を一度も見たことがないロボットは、上記のサブタスクのうちのただ1つでさえうまく遂行できないだろう。大学院生のチームが、特定環境下で特定のサブタスクのただ1つに対して何ヶ月も準備をしなければ、実現は不可能である。
アカデミアの研究者が、ある問題を解決した、あるいはロボットの能力を実証したと述べたとしても、我々がECWに望むパフォーマンスのレベルからは遠く遠く離れているのである。
これは、最近AAAI (Association for the Advancement of Artificial Intelligence) のAIマガジン夏号に掲載された短い記事3からの引用である。アレクサンダー・クレイナーが、AIの教授から、現実世界で毎日毎時働くAIシステムの構築に転身した経験について語ったものである。
2014年にアカデミアを去った後、私はiRobot社の技術組織に参加した。何百万という個人の家に置かれるロボティックシステムの構築がどれほどチャレンジングであるのかをすぐに私は学んだ。対照的に、論文で発表される研究成果 (私自身も含む)は、せいぜい数件の環境に限られた概念実証だったのだ。
アカデミックなデモンストレーションは、これらの問題を解決するために重要なステップである。けれども、それらはデモンストレーションでしかない。ブライアン・ファントは、数秒先の未来を想像できるプログラムのデモンストレーションを41年前に提示している。当時、コンピュータグラフィックスは未だ存在しなかった (1977年の論文では、ラインプリンターの固定幅文字の出力が図を描写するために利用されている)。最初のステップとしては優れている。それでも、数十年にもわたるハードワークにも関わらず、我々は未だそこに辿りついていないのだ。
5. 人間とロボットの行動の地図上での関連付け
「ロボットであるとはいかなることか?」 という記事で指摘した通り、将来の家庭用ロボットは我々自身よりも豊かなセンサ入力を取得できるようになるだろう。たとえば、ロボットにはGPSが組み込まれ、ブルートゥースとWifiで通信し、空間内を伝播するWifi信号のわずかな変動の観察を通して、隣の部屋にいる人の呼吸や心拍を測定できるかもしれない4。
自動運転車 (未だ真の意味で自動の運転ではないけれども) は、ナビゲーションのためGPSに大きく依存している。けれども、現在、GPSは攻撃手法としてなりすましされることもあり、更に悪いことに、国家支援のテロ行為において何者かがGPS衛星の撃墜を決断するかもしれない。
GPSが使用不能となった場合、しばらくの間本当に悪い状況に陥るだろう。一つの問題として、電力ネットワークを小さな地域への供給網に分離する必要があるだろう。現在の電力ネットワークは、遠く離れた地域同士での交流電流の位相同期にGPSを使用しているからである。また、紙の地図があらゆる種類のアプリケーションに向けて再び印刷されるまでは、人間も非常に困ったことになる。とりわけ、オンラインショッピングの配送業者はしばらくの間大打撃を受けるだろう。航空機や船舶の航行も同様である。(初期のボーイング747のコクピットには、大西洋横断中に天測航法を行うための天窓があった; アメリカ海軍学校も、2016年に天測航法をカリキュラムに復活させた)
なりすましであれ、衛星への攻撃であれ、あるいは単なる通信障害であれ、高齢者介護ロボットECWは、GPSが使えない状態でもオフラインになってほしくないだろう。けれども、GPSからのヒントにまったく頼ることなく、視覚その他を用いたローカルなナビゲーション能力が改善しない限りその状況は避けられない。しかし、もしもローカルなナビゲーション能力が向上すれば、災害現場や建築現場といった、地図が必ずしも利用可能ではない場所や、地形が急速に変化するために地図が毎日一貫性を保てないような場所でも活動できるようにもなるだろう。
けれども、これは始まりに過ぎない。地形および3次元的な詳細図を含む地図は、ECWが、高齢者が歩行する道、車椅子で移動する経路、トイレへ入る場所などを判断するために必要不可欠である。この能力は、現状の伝統的ロボティクスアプローチにとってもさほど困難ではない。しかし、SLP、サービスロジスティクスプランナーには、更に汎用的な能力が要求される。SLP自身が考案した人工透析病棟の計画と、仮説上の人間の患者あるいは仮説上の患者およびスタッフの集団とを三次元の地図へと関連付けて、計画された環境での人間の行動を検討しなければならないだろう。これには、人間のグループの行動方法についての人間からのインプットなしで、独力でのシミュレーション構築が必要とされる。
この能力、つまり想像上の物理空間に人間の行動を投影することは、現在のビデオゲーム内で発生している状況とそれほど隔たっていない。この記事中の他の項目と比較すれば、それほど難しくないように見えるだろう。それでも、こういったシステムがロバストで、人間からの事前知識を必要せず動作するためには、何年かのハードワークを要するだろう。- 後者のポイントは、現状のアカデミアのデモンストレーションの力点からは遠く隔たっている。
更には、この種のシミュレーションを走らせる能力は、おそらく「常識」の側面にも貢献するだろう。しかし、そのためには現状のビデオゲームのグラフィックスよりも更に複合的でなければならない。また、単に可能性の領域だけではなく、妥当性と蓋然性の双方でのシミュレーションを実行する必要がある。
これは、1つ前のセクションの「診断と修繕」と似ていなくもない。実際のところ、この2件には多くの共通点がある。しかし、現実の世界とシミュレーションの三次元的な側面の関連付けについて、ここでは更に掘り下げてみた。ECWにとっては、あるがままの現実世界であるだろう。SLPにとっては、設計した世界、将来の人工透析病棟だろう。そして、シミュレーション実行後に、要求仕様の実現失敗や望ましい結果がシステムへとフィードバックされるように、制約は実世界と仮想世界で双方向に流れる必要がある。
6. コンピュータプログラムを書き、デバッグすること
オーケイ、私はこのセクションを楽しみながら書いたことを認めよう。確かにこれは人間の能力と知能のあり方を説明するのには良い事例ではあるのだが。けれども、長い上にややテクニカルであるため、どうぞここは飛ばしてもらっても構わない。
超知能の警告者の中には、こんな心配をしている人もいる。我々が超知能を作り出すと、超知能は自分自身のソースコードを書き換えて成長できるようになる、そして、超知能は指数関数的に成長し我々よりも賢くなり、当然のごとく我々を皆殺しにするだろう。最後の主張は奇妙であることは確かだが、ともかくそう主張されている。
読者は、「学習ソフトウェアが学習ソフトウェアを書く方法を学習した」などというニュースのヘッドラインを見たことがあるかもしれない。実際はそうではないのだ。この事例においては、人間によって書かれた固定のアルゴリズムが存在し、特定の形状のディープラーニングネットワークに対して構築プロセスを実行したというものである。そして、その学習ネットワークが学んだのは、そのアルゴリズムのパラメーター、サイズ、接続方法、レイヤー数などのパラメーターを調整する方法である。ただの1行たりともプログラムのコードを書いてはいない。
では、このような誇大広告に溢れた環境のもとで、一体どのようにすれば、AIシステムがコードを読み、デバッグし、改修し、また新たなプログラムコードを書くまでにどれほど離れているかを分かるのだろうか。ネタバレ注意! 可能な限りの遠い距離である。同じ銀河にすらいないかもしれないし、仮に同じ恒星系に存在したとしても何百万マイルも離れた軌道を周回しているのかもしれない。
今日のAIシステムはそれぞれ何百万行ものコードから作られており、共有ライブラリを通してたくさんの、たくさんの人々の手によって書かれている。それに加えて、AIをベースにしたシステムを提供する企業には、おそらく数百万行ものカスタマイズされたプライベートなコードベースが存在している。
これらのコードは通常、C、C++、Python、Javascript、Javaその他など多くの言語にまたがっている。使用されている言語には非形式的な仕様しかないことも多く、過去数年間にも恐るべき頻度で新しい言語が導入されており、ある1つの言語でもバージョンが違えばセマンティクスが異なる場合もある。これらのディテールに頼って生計を立てるプログラマ以外のあらゆる人にとっては、これはやや混乱した状況であると言えよう。
これに加えて、チューリングが1936年に停止問題を導入して以来、すべての可能な入力に対してプログラムがどう実行されるか、ある程度簡単なことでさえ確実に知ることは不可能であると理解している。
1967年、ミンスキーは、比較的少量のメモリ (今日の自動車のリモコンキーに期待される程度の量) 上のプログラムでさえ、そのプログラムについて何らかのことを理解するためには、すべての宇宙で並列計算を行なったとしてさえなお宇宙の寿命と同じ時間を要すると警告していた。
人間は、プログラムが何を実行するのか分析するヒューリスティクスを使って、ある程度自信を持ってプログラムを書くことができる。プログラマは、書いたプログラムが望み通りの動作をすることを自分自身に向けて証明するために、さまざまなモデルと精神的なシミュレーションを使用する。これは厳密な意味での証明とは異なる。
コンピュータが最初に開発されたとき、まずはコンピュータソフトウェアが必要であった。当初は、マシンの各々のオペレーション数値コードをプログラマが手入力しなければならなかったが、すぐにアセンブラ、つまりプログラマが書いたコードと数値コードを1対1で対応させる方法へと行きついた。そこで、少なくとも人間が読めるテキストで、たとえば "ADD" のように操作コードを書けるようになったのだ。その後すぐにコンパイラが開発された。計算を表現する言語は、より抽象的なマシンの高水準モデルを用い、そしてコンパイラは言語を特定マシン用のアセンブラ言語へと変換する。
1960年代からAIシステムを構築する試みが数多くなされており、更に高水準の表現、たとえば英語からコンピュータ言語のコードを生成することも可能になった。
実際のところ、これらのシステムが生成できるコードはきわめて一般的なものであり、複雑なロジックが必要である場合には困難な場合もある。これらシステムの提唱者はシステムがいかに有用であるかを主張するだろうが、けれども、実際には、人間のプログラマは、複雑なコンピュータコードを書くことから、更に複雑な数学的関係を書くことへと移動しなければならない。
本当のプログラマは、空間的モデルと自身の「世界をシミュレートする」能力を使い、どのようなコードを書くべきか、どのようなケースをどのように扱うべきかを判断する傾向がある。しばしば、プログラマは物事をトラッキングできるように疑似英語でケースの長いリストを書くこともあるし、また (コードを維持することになる後の人間が幸運であれば) コードの周りにコメントが入っていることもあるだろう。そして、変数名と関数名は、たとえそれがコンパイラにとって何の意味も持たないとしても、何が計算されるのかを記述している。たとえば、プログラマは文字列ポインタとして変数 StringPtr を使うかもしれないが、コンパイラにとっては、たとえば変数 M が使われていても十分である。人間は、名前を使って何が何であるかを覚えておくのである。
人々は、プログラムをデバッグするAIシステムを作成しようとも試みてきた。しかし、変数名をAIデバッガに理解させようとすることはめったにない。コンパイラと同じく、単なる匿名のシンボルとして扱うのだ。これは、人間がコードについてのアサーションを書くことを要求する「形式手法」のプログラミングであり、自動化システムはそれを理解できる可能性がある。けれども、これは普通のコンピュータコードを書くことよりも更に苦痛が大きく、また通常のコンピュータコードよりも更にバグが多くなるために、ほとんど実行されていない。
そこで、我々の超知能も既存のコードベースに対処しなければならない。そして、その中には極めて汚ないコードもあるだろう。
ちょっとした楽しみのため、私はC言語で小さなライブラリルーチンを書いてみた。- 私が普段使っている別の言語で、まったく同等の意味を持つライブラリルーチンを作り、そしてその後、変数名、関数名と型名からすべての意味を取り去ったのだ。これがそのコードだ。本当は一行である。また、このコードはGCCコンパイラを使ってコンパイルでき、完全に正しく動作する。
a*b(a*c) {a*d; a*e;
for(d=NULL;c!=NULL;e=(a*)*c,*c=(a)d,d=c,c=e);return d;}
私は、2人の同僚にこのコードを送った。彼らはどちらもシステム開発とライブラリのオープンソースコード開発の豊富な経験がある。そして、私はこのコードが何をするものであるか理解できるかと質問した。"a" の定義を与えなかったため、これは少し難しい問題になっている。
2人は即座に "a" は定義された型でなければならないと理解した。1人目は、いくつかの手掛かりがあると答え、データ構造の絵を描き、コードのシミュレーションを開始した。しかしその後、("a"の定義を推測した後で) コンパイラを使った実験に移り、このコード片をコンパイルして呼び出すプログラムを作成したのだ。彼は多くのセグメント違反エラーを発生させた (つまり、プログラムはクラッシュし続けた) が、これは連結リストをすべて辿るプログラムではないかと推測した。2人目は、コードを見つめて、"e"が一時変数であり、その変数の使用場所は他2つの値の代入操作の前後に存在するため、ここでは値の交換が行なわれ続けているのではないかと推測した。また、「変数cがNULLになった時」というループの終了条件から、リストcを"舐めて"いるのだろうと推測したが、しかしその時オリジナルのリストそのものは破壊されている。そこで、彼はこれはインプレースのリスト逆転処理ではないかと推測したのである。そして、彼は頭の中と紙の上でシミュレーションを設定し、それが正しいことを確かめたのだ。
私は2人に、意味を持った名前を用いた、同等の処理を行うオリジナルのコードを復元して伝え (しかし、私はやや古くさい等価な定義型を使用していることは認めよう) 、同時に"a"の型定義はここでは"address"であることを伝えた。2人とも、このコードを紙の上でシミューレションして何が行なわれているかを確認することは容易であると述べた。
# define address unsigned long long int
address *reverse(address *list) {
address *rev;
address *temp;
for(rev=NULL;list!=NULL;temp=(address *)*list,
*list=(address)rev,
rev=list,list=temp);
return rev;}
実際、変数名やコメントは、実際のコードの動作には何も関係ないけれども、何の処理が行なわれるかについて、大量のセマンティックな説明が含まれているのである。単純にコードを眺めているだけでは、その使用方法について十分な情報を得られないだろう。また、システム全体を見た場合には、あらゆる種類の推論プロセスはすぐに対処不能になる。
もしも、上記2バージョンの関数を理解可能なAIシステムを誰かが既に構築していたとしたら、今日のあらゆるプログラマにとって信じがたいほど有用なツールとなりうるだろう。それに近いものは一切存在しないと確信を持っている。- そんなAIはあらゆるIDE (統合開発環境) に搭載されるだろうし、プログラマの生産性は天井を突き抜けるだろう。
しかし、私の小さな実験は、我々の貧弱な超知能 (その提唱者たちが、数年以内に我々を皆殺しにすることを望むだろうと考えている人) にとってはちょっと難しすぎると考える人もいるかもしれない。しかし、我々が日常生活を依存している定められた方法で処理を実行するコードベースが、実際にはどれほど汚い書き方をされているかを過小評価するべきではない。
そこで私は別の2番目の実験を行なった。今度は私一人だけが被験者だ。
これは、自分のマッキントッシュ上で見つけたコード片である。TextEditという名前のディレクトリの下にあり、ファイル名は EncodingManager.m だ。私はファイル拡張子".m" がプログラム言語として何を意味するのかは分からなかったが5 、私にはC言語のコードのように見えた。私は、ファイル内のこの単一のプロシージャだけを見て、それ以外には何も見ていない。それでも、私はプログラムについて、そしてそのプログラムが含まれるシステム一般についていくつかのことが判っている。
ここで登場する語のうちで、C言語の予約語は static, int, const, void, ifとreturn のみである。それ以外のすべての語はプログラムのどこかで定義されていなければならないが、私は定義を探さず、このコード片のみを単独で確認した。コードの下にあるイタリック体のテキストには、ほんの数分の間に私がこのコードから推測した情報を記載している。このような推論ができるAIプログラムは今日存在しないと私が保証する!
/* Sort using the equivalent Mac encoding as the major key.
Secondary key is the actual encoding value, which works well enough.
We treat Unicode encodings as special case, putting them at top of the list.
同等のMacエンコーディングを主キーとして用いるソート。
副キーは実際のエンコーディング値であり、これは十分うまく機能する。
我々は、ユニコードのエンコーディングは特別ケースとして扱い、リストのトップに置く。
*/
static int encodingCompare(const void *firstPtr, const void *secondPtr) {
CFStringEncoding first = *(CFStringEncoding *)firstPtr;
CFStringEncoding second = *(CFStringEncoding *)secondPtr;
CFStringEncoding macEncodingForFirst = CFStringGetMostCompatibleMacStringEncoding(first);
CFStringEncoding macEncodingForSecond = CFStringGetMostCompatibleMacStringEncoding(second);
if (first == second) return 0; // Should really never happen
if (macEncodingForFirst == kCFStringEncodingUnicode || macEncodingForSecond == kCFStringEncodingUnicode) {
if (macEncodingForSecond == macEncodingForFirst)
return (first > second) ? 1 : -1; // Both Unicode; compare second order
return (macEncodingForFirst == kCFStringEncodingUnicode) ? -1 : 1; // First is Unicode
}
if ((macEncodingForFirst > macEncodingForSecond) || ((macEncodingForFirst == macEncodingForSecond) && (first > second))) return 1;
return -1;
}
まず、冒頭のコメントはやや誤解を招くものだ。これはソートの関数ではないからだ。実際は、何らかのソート処理の中で使用される、2つの要素が正しい順序で整列しているかを判定する述語である。この述語は2つの引数を取り、1か-1のいずれかを返す。それはまだ我々が確認していないソート処理からの出力が、どちらの順序 [昇順か降順か] になるべきかに依存する。これらの2つの可能性が意味することを確かめておく必要があるだろう。TextEditは、マッキントッシュ上で動作するシンプルなテキストファイルのエディタだということは分かっている。これを見ると、TextEditの内部では、文字列要素に対して可能なエンコーディングが複数あるように見える。そして、マッキントッシュ上には、可能なエンコーディングの同一ではない集合が存在している。たぶん、TextEditは他のOS上でも動作する必要があるのではないかと思う。この述語は、汎用エンコーディングとしてエンコーディング値を受け取り、マッキントッシュ上でそれぞれに最も似ているエンコーディングを判定し、どちらを使うべきかを述べるものだ。また、これは1文字に1バイトのみを使用するエンコーディングを好むようだ。エンコーディング自体は、一般的な場合でも、マッキントッシュの場合でも、数値によって表現されている。最初のコメントの3番目の文と、戻り値のところにあるコメントの「// First is Unicode」によれば、この述語の返り値 -1が意味することは、1つ目の引数が2つ目の引数に先行することであり、(つまり、「リストのトップ」に近い場所に表れるということだ。ここで「トップ」と言ったのは、コメントで、リスト内の他のあらゆる要素よりも先行するリストの末端を指してこの言葉が使われていたためである。上記のコード例の中で、これが本当に古典的な連結リストとしてどこかで実装されているのか、あるいは無形のソート済み配列なのかは分からない。しかし、いずれにせよこのコード片の挙動はリストの実装には依存しない) そうでない場合は、1を返すと考えられる。マッキントッシュ用エンコーディングの数値が小さいものが先に来るべきであり、もしもマッキントッシュ用の値が等しい場合は、一般的なエンコーディング値の大小によって順序が決定される。このすべての対象のうちでは、シングルバイト表現が常に勝つ [先行する]
こんな短いコード片からでも、これだけ多くの情報が推測できるのだ。けれども、この種の推論によって複雑なシステムの構築が可能になるのであり、あらゆる現在のソフトウェアはこのようにして作られている。
人間が雑に作製したソースコードを理解し、コードレベルのイントロスペクションを通して超知能が自己改善を進めようとする場合、このような推論ができなければならない。自分自身のソースコードを理解できなければ、自分自身のソースコードを書き換えての自己改善は不可能である。
シンプルなテキストエディタのこれほど小さな小さなコード断片でさえ、今日のいかなるAIシステムでも理解できないのだ。
7. 人間との絆
ここで我々は本当にスペキュレーティブな場所に至る。この種のテーマについては、AIとロボティクス分野でせいぜい25年程度の研究しか行なわれていないのだから。人間は、ロボットと互いに本当の共感を抱くような形でインタラクトできるのだろうか?
1990年代、私の博士課程の学生であったシンシア・ブリジール6は、我々は、将来の家庭用ロボットを「家電製品か友人か」のどちらにしたいと望むのだろうかという疑問を抱いていた。これまでのところ、彼らは家電製品でしかない。シンシアは、博士論文 (2000年に審査された) のためKismetというロボットを構築した。それは、物理的な頭部であり、人間とやりとりできるロボットであった。彼女は、ロボットに精通した研究室のメンバーと、ロボットに対する事前経験のない (確実にKismetのようなソーシャルロボットに触れたことのない) 一般の人々に対して実験した。
彼女の博士論文のオンライン審査から、2件のビデオ (当時、カメラの解像度は今より低かったのだ) を掲載した。
1つ目のビデオでは、シンシアは、我々の研究室グループのメンバー6人に対して、ロボットをいろいろな方法で賞賛したり、注意を引いたり、何かを禁じたり、あるいはなだめるよう依頼した。ビデオを見ればお分かりの通り、このロボットはシンプルな顔の表情と頭の動作を備えている。シンシアは、ロボット用の感情空間をマッピングし、頭、耳と瞼の動作方法を制御するこれらパラメータにより感情状態を表現したのである。ほとんど独立したシステムが視線方向を制御していたが、その眼は人間の眼のように見えるようデザインされており、それぞれの網膜の後ろにカメラが据えられている。- つまり、その目線の向きは、感情的な機能も持ち、何が見えるかを定めるという機能的な意味も持っている。また、相手の眼を見て、適切な状況ではアイコンタクトをする。Kismetは、視野内で動くものを一般的に検出し、また時々はそれら動作に追従するが、それは人間が無意識のレベルで取るであろう行動のモデルに基いている。ビデオで、Kismetが人間の声に含まれるやや誇張された韻律 [prosody] を容易に検出し、適切に応答していることが示されている。
2つ目のビデオでは、素朴な被験者、つまりロボットに関する事前知識を持たない人に対して、「ロボットに話しかけるように」と依頼した。被験者は、ロボットが英語を理解しておらず、実際には被験者の発話と声の韻律を検出しているに過ぎないということを知らされていなかった。(実際には、Kismetは女性の声に対して強く調整されていた - 先のビデオで人間の被験者全員が女性だったことに気付いただろうか)
また彼は、Kismetが英語の実際の単語ではなく、英語の音素から構成された無意味な単語を発しているだけだということも知らされていなかった。それにもかかわらず、彼はロボットとある程度一貫性のある会話ができたのだ。 (あらゆる話題について、彼はKismetが必要とするタイミングに合うよう待ち時間を調節したので、2者が同時に話し出してしまうことはなかった) そして、彼はKismetに腕時計を見せることにも成功した。「あなたに私の腕時計を見せたい」と彼が言うとき、Kismetは確かに時計を直視している。これが可能なのは、彼が本能的に腕を相手の視界の中へ動かし、時計の文字盤を人差し指で叩いたからだ。Kismetは時計については何も知らないが、しかしシンプルな動作への追従ができる。また、Kismetは相手とアイコンタクトし、顔を追いかけ、また相手の顔を見失なった場合には、被験者は手の動きによって注意を引き、再度関わり合いを始める。そして、被験者があまりにKismetの顔に近付いた場合、Kismetは後ろへ仰け反るのだが、その時彼は「私は近すぎますか?」と言う。
この研究が行われたとき、ほとんどのコンピュータのクロック周波数は200MHz程度でしかなく今日稼動しているコンピュータと比べればごく低速であり、また、RAM [メモリ] の容量は、今日のラップトップに期待されるサイズの1000分の1程度でしかなかったことを思い出してほしい。
シンシアの研究から分かったこととしては、ごく少数のシンプルな振る舞いにより、ロボットは人間らしいインタラクションをして人間と関わり合えると示した点が挙げられるだろう。当時、この研究はシンボリック人工知能へのアンチテーゼであった。シンボリックAIでは、人間同士の会話を「発話行為」として、つまり、ある話者から別の話者への意味の伝達の試みであるとする見方を採っていたからだ。これは Amazon Echo や Google Home が今日使っているモデルでもある。この研究では、会話についての低レベルの手掛かりの上に、会話を含む社会的な相互作用が構築されているように見えるだろう。また更には、ロボットが与えるシンプルで一貫性のある手掛かりが存在すれば、人間も物理的なロボットと関わり合いができるであろう。
これは間違いなく、人間の会話に対する振る舞いベースのアプローチである。
しかし、これを越えて進むことは可能だろうか? 身体を持たないグラフィックスイメージや部屋の隅にあるリスニング/スピーキング用の円柱よりも、物理的なロボットのほうがより上手に人間と関わり合えると示す研究は正しかったのだろうか?
人間が他の何よりも多数行なっている異種間の対話の事例を見てみよう。

この写真は、2015年に Nagasawaらによって公表された論文のScience誌の解説記事7に掲載されたものである。著者たちが示した結果によれば、イヌまたはその飼い主の血中オキシトシン濃度が何らかの理由によって上昇すると、その者はより多くのアイコンタクトを取るようになる。すると、相手の個体 (イヌまたはヒト) のオキシトシン濃度も向上するのである。2者は、持続的なアイコンタクトという外部の振る舞いによって触発された、ポジティブなフィードバックループへと入るのだ。
シンシア・ブリジールは、Kismetと持続的なアイコンタクトをした被験者のオキシトシン濃度を測定していなかったが、けれども測定されていなくともロボットのオキシトシン濃度が向上していないことに私は確信を抱いている。イヌに関する論文の著者らは、進化における家畜化の過程で、人間の乳幼児の育成にとって重要なインタラクションのパターンをイヌが乗っ取る方法を偶然に発見したのではないかと示唆している。
そこで、ロボットとKismetは良いスタート地点だった。確かに何らかの経路をハイジャックすることができた。かわいくも見えないし、人間に似ているわけでもなく、Kismetは極めて明白に非人間的であるものの、我々人間の基盤に対して彼らの行動をマップするのは容易であった。
ここで、奇妙な考えに至る。過去20年間の間に、我々の腸内細菌 (ミクロなバイオーム)、あるいは我々の肌や口に存在するバクテリアがどれほど多いか知られるようになった。近年の研究では、それらバクテリア種が我々の性的魅力、また非性的な社会的相性にさえ影響を与え、あるいは影響を受けたりすることが示されている。そして、バクテリアが人々の間で移動することを示す証拠もある。イヌに対する我々の愛着が、ヒトとイヌの間でのバクテリア移動から部分的に影響を受けているとしたらどうだろうか? 今のところ、それは確証されていない。けれども、もしもそれが正しければ、我々とロボットとの間の関係性は、イヌと、あるいは他のヒトと同じ程度には決して強くなれないことが定められていると言えるかもしれない。その場合は、少なくとも、我々がヒトの生物学的なレプリカントを生産できるようになるまでは。そしてそのようなレプリカントを作れるようになるまでには、対処する必要のある倫理的問題が多数存在している。
ここで議論したことをもとに、超知能を構築するためのクエストの次のパートへと移ろう。
-
原注2:Commonsense Reasoning and Commonsense Knowledge in Artificial Intelligence”, Ernest Davis and Gary Marcus, Communications of the ACM, (58)9, September 2015, 92–103. ↩
-
原注1:“A Heuristic Program that Solves Symbolic Integration Problems in Freshman Calculus”, James R. Slagle, in Computers and Thought, Edward A. Feigenbaum and Julian Feldman, McGraw-Hill , New York, NY, 1963, 191–206, adapted from his 1961 PhD thesis in mathematics at MIT. ↩
-
原注3:“The Low-Cost Evolution of AI in Domestic Floor Cleaning Robots”, Alexander Kleiner, AI Magazine, Summer 2018, 89–90. ↩
-
訳注:拡張子.mはObjective-Cのファイルを表す ↩
-
訳注:シンシア・ブリジールは、コミュニケーションロボット「Jibo」を開発したJibo社の創業者としても知られる。 ↩
-
原注5:“Oxytocin-gaze positive loop and the coevolution of human-dog bonds”, Miho Nagasawa, Shouhei Mitsui, Shiori En, Nobuyo Ohtani, Mitsuaki Ohta,Yasuo Sakuma, Tatsushi Onaka, Kazutaka Mogi, and Takefumi Kikusui, Science, volume 343, 17th April, 2015, 333–336. ↩