この記事は、ロドニー・ブルックス氏のブログ記事 "[FoR&AI] Steps Toward Super Intelligence I, How We Got Here" の翻訳です。訳者によるまとめはこちら。
神は自身の姿に似せて男を作った。
男は自身の姿に似せてAIを作った。
(…) 少なくとも、そのように始まった。けれども、我々自身の姿を機械として創り出すことは、極めて難しいタスクなのだ。
我々は、ゲーデル的不完全性の奇妙な世界に閉じ込められているのかもしれない - もしかすると、我々の知能はある閾値を下回っているために、我々と同等の人工知能を理解したり構築したりは決してできないのかもしれない。地球上の人間以外のあらゆる生物については、多くの人がこれは正しいと同意してくれると思う - 生きたイルカたちがすべてを設計し作り上げたロボットイルカが海から現れたとしたら、我々はとんでもなく驚愕するだろう。イルカやゴリラやボノボと同じように、我々人間は、知能を構築するために必要な知能を下回っているのかもしれない。私が「傲慢と謙遜」で議論した通りである。
あるいは、もしかすると、私が信じている通り、人工知能の構築は単に本当に難しくて、何百年もの、あるいはもっと長い期間の集中した努力を要するのかもしれない。数千年間にわたって、化学の分野では未だ新たな発見がなされており、人々はそれを理解し、サイエンスからエンジニアリングへと変化させようと試みている。人間レベルの知能はこれと同じくらいの、あるいはもっと難しい挑戦であるのかもしれない。
直近の私のブログ記事、「人工知能の起源」では、AI分野の創始者の全員が、加えてその後のほとんどの研究者が、人間レベルの知能を実現するというモチベーションを持っていたと述べた。最近では、いくつかの異なる小集団が、自らの研究を差別化するために、ただ自分たちだけが (それぞれ別々のグループが…) 人間レベルの知能実現に興味を抱いていると主張している。そのうえ、各々が汎用人工知能 [Artificial General Intelligence] (AGI)を名乗り、主流派のAI研究から自分たちを区別しようと試みている。けれども、彼らが語ることのほとんどは、ひとたびAGIが実現されると、それがどれほど素晴しいものになるか、あるいはどれほど悲惨なことになるかという話だけだ。この2つのメッセージが同じ人物の口から同時に発せられることも非常に頻繁にある。彼らは、AGIについて考察する高揚感をあまりに楽しんでいるために、実際にそれを作成することにかけては時間を無駄にしている。
また別の人たちは、必ずしもAI研究者になるつもりはないようだが、AIについてはすべて分かっており、またそれをどう進めるかも知っていると主張し (フーム…)、彼らが呼ぶところの超知能、人間のレベルを超えたAIの切迫した危険性について語っている。
彼らは、超知能はすぐにでも出現すると主張している。特に、我々がAGI、人間レベルの知能を手に入れると、即座に膨大なクラウドコンピュータの計算力を用いて更に優れたAIの開発が加速されるのだという。そのために、自律的な超知能の開発が起こるとされている。このような誇大広告/催眠術師的 [hype-notists] なロジックのもとでは、超知能は当然に我々の能力を超えているとされている。けれども、彼らがこれを神に取って代わるものだと信じているのかは分からないが… いずれにせよ、彼らは当然のごとく超知能には危険性があると主張しており、我々 (人類) と我々の生き方は考慮されず、我々全員が殲滅されるかもしれないと主張している。彼らは、超知能を一種の移民であると捉えているのではなかろうか。けれども、未来を見通す千里眼的能力を無償サービスしてくれるこれら予言者たちも、AGIや超知能がどのようにして構築されるのかは理解していない。彼らは単に、すぐにそれが起きると知っているのみである。もしも、既に起こっているのでなければだが。また彼らは、心から、これが悪いものになると分かっている。本当に悪いものになるのだ。
人工知能を使ったシステムを保有していると主張する企業が、ユーザに通知しないまま、実際には人間の労働者を使って難しい問題への対応に当たらせている場合があるという事実も、まったく彼らの認識を変える助けにならないようである。これは今日の人工知能の到達点に対する世間の認識を深刻に混乱させるものであり、また言うまでもなく本質的なプライバシー欠如にからむ問題をはらんでいる。私が思うに、どうやら我々人間は他の人々よりも機械に対しては、喜んでプライベートな考えや行動をシェアしてくれるようだから。
これらすべての関心のもとで、我々はどんな研究を必要としているのか、どんな問題を解く必要があるのか、汎用人工知能あるいは人間の知能レベルのエンティティの実現に対して我々はどれほど近付いているのか、を私は考察してきた。我々は既に62年間も活発に挑戦を続けてきたが、見たところ、必要なすべてのブレイクスルーを即座に実現できそうにはない。それがこの記事の目的である。つまり、我々が未だに理解していないことと、AGIエージェントを構築するために知る必要があるすべてのこと、そして更には、いかなる方法で超知能へと至るのかについての、私自身のベストな考察である。そしてこれがこの記事のタイトルだ: 『超知能へ向けたステップ』
イエス。このタイトルは、マーヴィン・ミンスキーの1961年の論文『人工知能へ向けたステップ [Steps Toward Artificial Intelligence]』へのオマージュである。この論文については、1991年の私の論文『推論なき知能 [Intelligence Without Reason]』の中で簡単に取り上げた。その論文で私が指摘したこととしては、ミンスキーが示した5つの人工知能の研究分野、すなわち、探索、3つの制御探索 [control search] (パターン認識、学習と計画) そして5つめのトピックである帰納[induction]が挙げられる。今日では、パターン認識と学習は明白に「探索」の分野を超えて発展している。おそらく、私自身の超知能に向けた研究の方針も、それほど遠くない将来間違いであると判明するだろう。それでも、私の予測を古びさせる事象は未だほとんどの研究者に知られていないと思うし、確実に今日のホットな研究トピックではないことにはいくらか自信を持っている。
この文章は1つの長いエッセイになるはずだったが、どんどん長くなっていった。そこで、エッセイを4つの部分に分割した。それでもすべてが長い記事である。いずれにせよ、これは連載記事「ロボティクスと人工知能の未来」の最後から2番目の記事となる。
それでも、我々は (我々人類は) すぐに必ずそれを実現できる!
少し前、私はこの努力には何百年も要するかもしれないと言わなかったか? テクノ愛好家にとっては、私自身もその一員だと思うのだけれど、長い時間のように聞こえるだろう。本当にそんなに長い時間がかかるのだろうか? まぁ、そうではないかもしれないし、200年、あるいは500年、あるいはもっと必要かもしれない。
アインシュタインは、1916年に重力波の存在を予測した。2015年に初めて観測されるまでには、99年の研究を要した。重力波の観測でノーベル賞を受賞したライナー・ウェイスが観測手法を考案したのは51年後、1967年である。そしてその後、必要となるキーテクノロジー、レーザーとコンピュータ、が商業的に広く普及するまで待たなければならなかった。単にそれは長い時間を要したのだ。
制御核融合の実現は、実に60年以上もの間、40年先の未来に留まり続けている。
経済的なインセンティブにも関わらず、化学が鉛を金に変換するまでには1000年が必要であった。(そして我々は未だ有意味な方法で核種変換を実現できていない)
P=NP問題が現在の形で定式化されたのは47年前であり、それを解決した者は誰であれ、少なくとも、当代最高の計算機科学者としての名声を得るだろう。理論計算機科学分野の研究者は、誰もこの問題がいつ解決されるかの予想を述べようとはしていない。そして、この問題の解決にはいかなるエンジニアリングや生産を必要としないのだ。単に思考だけが必要なのにもかかわらずである。
いくつかのものごとには長い時間を要し、多くの新しいテクノロジーと新しいアイデアが発酵するまでの時間が必要とされる。解決に至る道程では、多人数のアインシュタインやウェイスのレベルの貢献者が必要になる。
私は、人間レベルのAIもこの種の問題なのではないかと考えている。それどころか、重力波の観測、制御核融合、あるいは化学よりもはるかに複雑なものであり、何百年もの時間を要する可能性さえある。
心で想像できるものは何でも実現できる、というテクノロジーに対する (シリコンバレー的な) 傲慢さを抱くだけでは、単にまったく十分ではないのだ。
汎用AI実現への過去4つの試み
再び、私の4月のブログ記事「人工知能の起源」で取り上げた通り、1956年の夏、この分野が明示的に「人工知能」と呼ばれるようになって以来、活発な研究が続けられている。それ以前の20年間にも先駆的な試みは存在していたが、当時まだその名前は考案、あるいは割り当てられていなかった。- 私の1991年の論文『推論なき知能』を更にもう一度、人工知能の先行研究および最初の35年の歴史として挙げておこう。
過去62年以上にわたる人工知能への主要アプローチとして、少なくとも4つ挙げられると思う。他の分野も含めたいと考える人も、もちろんいるかもしれない。
以下に4つのアプローチを示す。だいたいの始まりの年を付記している。
- シンボリック (1956)
- ニューラルネットワーク (1954, 1960, 1969, 1986, 2006, ..)
- 伝統的なロボティクス (1968)
- 振る舞いに基づくロボティクス (1985)
これら4つの主要アプローチの利点と欠点を説明する前に、上記の年を選んだ理由を説明しておこう。
シンボリックについては、人工知能に関する著名なダートマスワークショップの年を使用している。
ニューラルネットワークは、過去何度も何度も研究され、放棄され、再び注目されている。マーヴィン・ミンスキーは、1954年にプリンストン大学に博士論文を提出した。題名は「ニューラルアナログ強化システムの理論およびその脳モデル問題への応用 [Theory of Neural-Analog Reinforcement Systems and its Application to the Brain-Model Problem]」であった。2年後、ミンスキーはこのアプローチを放棄し、ダートマスではシンボリックアプローチのリーダーとなった。死亡。1960年、フランク・ローゼンブラットは、自身が作成したハードウェア、マークIパーセプトロンから得た結果を発表した。これは、1つのニューロンのシンプルなモデルであり、それが何を学習できるかを定式化しようと試みたものだ。1969年、マーヴィン・ミンスキーとシーモア・パパートは「パーセプトン[Perceptron]」という題名の書籍を出版し、単一のパーセプトロンが学習可能なことと学習不可能なことを分析した。本書は、実質的にこの分野を何年もの間殺してしまったのだ。再び、死亡。多数の異なる分野の研究者による、何年にもわたる予備的な研究の後、1986年にはデヴィド・ルーメルハート、ジェフリー・ヒントン、およびロナルド・ウィリアムズは『誤差逆伝播による学習表現 [Learning Representations by Back-Propagating Errors]』という論文を公表した。これは、数個の積層ニューロンのモデルで、それぞれの層ではパーセプトロンによく似たモデルを使うものであり、この分野を再建したのである。続く10年間ほどの間巨大な活動が巻き起こったが、ほとんどの研究者はその後ニューラルネットワークを放棄した。またもや死亡。研究者はそこかしこで仕事を続け、更に多数の層を使って実験を行い、このような多数の層が重ねられたネットワークに対して「ディープ」という語を生み出したのだ。それらは扱いづらく、また学習させることが難しいものではあったが、2006年、ジェフリー・ヒントン(再び!)とラスラン・サラクディノフは『ニューラルネットワークによるデータ次元性削減 [Reducing the Dimensionality of Data with Neural Networks]』という論文を発表した。論文中の「クランピング」と呼ばれるアイデアによって、これら複数の層で段階的な学習が可能となったのだ。これによってニューラルネットワークは再び蘇った。そして、過去数年の間「ディープラーニング」のアプローチは、実用的な機械学習へと爆発的に普及した。今日、多くの人々が人工知能を認識したのは、このただ一つの技術的なイノベーションによってのみのようである。
人工知能へのアプローチとしての伝統的なロボティクスには、スタンフォード人工知能研究所 (SAIL) のドナルド・パイパーによる1968年の「コンピュータ制御下のマニピュレータの動力学 [The Kinematics of Manipulators Under Computer Control]」を挙げた。1977年、私はその当時「ハンド・アイ [Hand-Eye]」と呼ばれていたSAILのグループに参加し、博士課程の研究として「眼」部分の問題に取り組んだのだ。
振る舞いに基づくロボティクスとしては、私自身の論文「モバイルロボットのためのロバスト階層制御システム [A Robust Layered Control System for a Mobile Robot]」の年を挙げた。これは1985年に書かれたものであるが、論文誌に掲載されたのは1986年である。当時は、「包摂アーキテクチャ [Subsumption Architecture]」と呼ばれていた。これはその後、振る舞いに基づくロボティクスのアプローチとなり、やがて他の人による技術的なイノベーションを通して、「振る舞い木[behavior trees; ビヘイビア・ツリー]」へと変貌した。自分自身の研究が人工知能の4つのアプローチのうちの1つであると主張することは、いささか謙虚さを欠いているかもしれない。その一方で、このアプローチを通して作られたロボット[ロボット掃除機のルンバ]は人々の家庭に2000万台以上存在しており、これはかつて製造されたいかなるロボットの数をも上回っている。また、振る舞い木は現在では全世界のビデオゲームの約3分の2の基盤となっており、UAVから工業用ロボットに至るまでの多数の物理的ロボットで使用されている。それゆえ、少なくとも商業的成功を収めていると言えるだろう。
ここで、これら4つの人工知能へ向けたアプローチを、ポンチ絵レベルで説明してみたいと思う。人工知能について本当に知識がある人であれば、これらの説明は著しく不十分であると感じるかもしれない。その通りだ。ポイントは、単にそれぞれのアプローチの雰囲気を示すことにある。ここでの説明の目的は、すべての下位アプローチについて網羅的に解説することではないし、個々のアプローチに対する何千人もの貢献者によるすべての主要マイルストーンと成果を解説するつもりもない。そのためには1冊の本の長さが必要になるかもしれない。そしてとても厚い本になるだろう。これらの説明は、単なる概略である。
それでは4タイプのAIに移ろう。最初の2つのアプローチでは、ふつうは利用パターン全体のどこかで人間が関与することに注意せよ。これにより第二の知的エージェントがシステムに加えられ、このエージェントが曖昧性への対処やエラー復旧を担う場合がある。そのため、しばしば、この種のAIシステムの信頼性は、将来の自律システムが求めるよりも低い場合がある。
1. シンボリック人工知能
このアプローチのキーコンセプトは、シンボルである。素直な (あらゆるアプローチは、ふつうの場合何十年か経つうちに複雑化していくものである) シンボリックアプローチによる人工知能では、シンボルは原子的 [atomic] アイテムであり、他の意味に対する関係によってのみ意味を持つ。理解しやすいように、このシンボルは文字列で表現されることが多く、単語に対応している (英語かもしれない)、 たとえば、猫 や 動物 のように。そして、世界に関する知識は関係の中にエンコードできる。たとえば、「~の個体」[instance of] や「~である」[is] など。
通常、このシステム全体はうまく機能し、また単語を、たとえば g0537 や g0028 などに置き換えても一貫した動作ができる。この点については後でもう一度触れよう。
それでは、これがエンコードされた知識である。
- すべての猫の個体は、哺乳類の個体である
- フラッフィーは、猫の個体である。
- ここで我々はフラッフィーは哺乳類の個体であると推論できる
- すべての哺乳類の個体は、動物の個体である
- ここで我々は、すべての猫の個体は動物の個体であると推論できる
- すべての動物の個体は、歩行の動作を実行できる
- ただし、その動物の個体が死亡の状態にない限りは
- すべての動物の個体は、生存の状態にあるか死亡の状態にあるかのどちらかである
ただし、現在の時刻が (その動物の個体が、誕生の動作を実行する) 時刻以前でない限りは
ここで見た文章の意味はよく理解できるだろうが、ここではこのような推論を使用するAIプログラムについて考えていることを思い出そう。すると次のようになるだろう。
- すべてのg0537の個体は、g0083の個体である
- g2536は、g0537の個体である
- ここで我々はg2536はg0083の個体であると推論できる
- すべてのg0083の個体は、g0028の個体である
- ここで我々はg0537の個体はg0028の個体であると推論できる
- すべてのg0028の個体は、g0154の動作を実行できる
- ただし、そのg0028の個体がg0253の状態にない限りは
- すべてのg0028の個体は、g0252の状態にあるかg0253の状態にあるかのどちらかである
ただし、value(the-computer-clock) < (g0028の個体がg0161の動作を実行する) 時刻でない限りは
実際はこれよりも悪い。上記の例では、まだ言葉で関係が説明されている。この種の推論を行うAIプログラムを考えれば、こんなふうになるだろう。
- r0002(x, g0537) であるあらゆるxについて、r0002(x, g0083)
- r0002(g2536, g0537)
- ここで我々はr0002(g2536, g0083)であると推論できる。
- r0002(x, g0083)であるあらゆるxについてr0002(x, g0028)
- ここで我々は、r0002(x, g0537)であるあらゆるxについてr0002(x, g0028)と推論できる
- r0002(x, g0028)であるあらゆるxについてr0005(x, g0154)
- r0007(x, g0253)でない限りは
-
r0002(x, g0028)であるあらゆるxについてr0007(x, g0252)またはr0007(x, g2053)
- ただし、value(the-computer-clock) < p0043(a0027(g0028, g0161)) でない限りは
ここでは、「~の個体である」といった関係は r0002といった匿名のシンボルに、またシンボル 「以前」は 「<」に置き換えられている。AIプログラムの内部はこのように見えるだろう。しかし、そうであったとしても、AIプログラムはシンボルの名前を読むことはない。実際には、ある演繹[inference]または文[statement]中のシンボルと、別の演繹または文中の同一のシンボルを比較するのみである。名前は、単に人間が解釈するためだけのものである。ここでg0537やg0083が猫や哺乳類であるとすれば、人間がプログラムやプログラムの入出力を見て、そのシンボルが何を「意味」しているかを解釈するのだ。
そして、これこそがシンボリック人工知能における重大問題である。つまり、いかにしてシステムが使用するシンボルを現実の世界に接地 [grounding; グラウンディング] するかである。これには、現実世界に対する何らかの知覚が必要であり、シンボルと現実世界の物や出来事を結び付ける何らかの方法が必要である。
多くのアプリケーションでは、システムを使う人間が接地を行なう。検索エンジンに検索語をタイプするとき、AIシステムが世界について知っていることをもとに、意味を成すようなシンボルを選択するのは我々である。検索エンジンは何らかの推論と演繹を行ない、そして我々のために、探しているものとマッチすると考えられるウェブページの一覧を生成する。 (データベース内部のシンボルである「人」に対応するものが我々であるということを何も理解していないままで)
そして、検索エンジンが生成したページの要約を読み、最も見込みの高そうなページを1つか2つクリックするのも我々である。その後、もしも検索結果が我々の目的に適うものでなかった場合、我々は新しい語を加えたり、あるいは別の検索語に取り替えたりして検索を続ける。我々、人間がAIシステムのシンボルグラウンディング担当なのだ。こうも主張する人もいるかもしれない。あらゆる知能は我々の頭の中にあり、AI検索エンジンが本当に提供しているものは、洗練されたインデックスとそれを使うための洗練された方法だけだ、と。
この点を理解するために、次のような思考実験を考えてみてほしい。
あなたは朝鮮語を知らないものとして、すべての入出力が朝鮮語であるようなAIプログラムを利用しているとする。AIプログラムのシンボルはさしたる助けにならないだろう。けれども、朝鮮語辞書、つまり朝鮮語の言葉の意味が朝鮮語で書かれている辞書を持っていたとする。ありがたいことに、現代朝鮮語は有限個の表音文字を使用し、単語と単語の間を分かち書きする (ただし、その規則は英語の文とは若干異なる) ため、プログラムの出力を見て「シンボル」を見つけ出すことはおそらく可能だろう。そこで、単語を辞書を調べることができ、しばらくすれば朝鮮語の文法を推測できるだろう。
ここで、あなたの人間世界に関する大量の知識を活用することで、どのエントリが多数の辞書項目を参照しているかなどから、シンボルの意味をいくらか言い当てることもできるだろう。しかし、もしもあなたが映画『メッセージ』のヘプタポッドであり、ヘプタポッドが地球を訪れる以前だった場合、このような方法では完全なるエイリアンのシンボルをグラウンディングすることは不可能だろう。
つまり、多くの場合において、本当にグラウンディングを行なっているのは、人々の頭の中にある知識なのだ。AIプログラムに対して知識を当てはめるには、内的に首尾一貫した[self-consisntent]辞書(たとえば) の外部にある何かとシンボルを関連付けられなければならない。汎用人工知能の王位僭称者のうちの一人、ニューラルネットワークがこの問題に対して何らかの役割を果たすかもしれないが、次の章で検討する。もちろん、人々はこれまで何十年にわたって研究を続けてきた。我々は未だ遠く離れたところにいる。
60年余りのシンボリック人工知能研究の豊かさを知るためには、AIマガジン を薦めたい。これはアメリカ人工知能学会 [the Association for the Advancement of Artificial Intelligence] による季刊の論文誌である。有料ではあるが、学会に参加しなくてもすべての記事の目次を見ることができるため、シンボリックAI分野で行なわれている研究のバラエティについて雰囲気が分かるだろう。また、時々はニューラルネットワークその他の関連した種類の機械学習の記事が掲載されることもある。
2.0, 2.1, 2.2, 2.3, 2.4, … ニューラルネットワーク
これは大ざっぱに、非常に大ざっぱに、1948年頃の脳内のニューロンについての理解にもとづいている。つまりは、脳に関する現在の知識とはまったく似ているところがないということだ。それでも、メディアはこのアプローチが生物学から着想されたと語ることをやめないだろう。いずれにせよそういうものだ。
ここで私はただ一つの典型的な人工ニューラルネットワークを取り上げ、それがどう訓練されるかを説明したいと思う。すなわち、フィードフォワード階層化ネットワークによる教師付き学習である。他にも多数のバリエーションがあるが、それでもこの例からは基本的な雰囲気を知ることができるだろう。
キーになる要素は、n個の入力を持つ人工ニューロンであり、nまでの番号が与えられている。すべての入力は0から1の間にあり、入力にはx_1,x_2, ..., x_nである。それぞれの入力は重みw1, w2, ...,w3と乗算され、結果は加算される。Wikimedia Commons から引用した下図に示されている通りである。
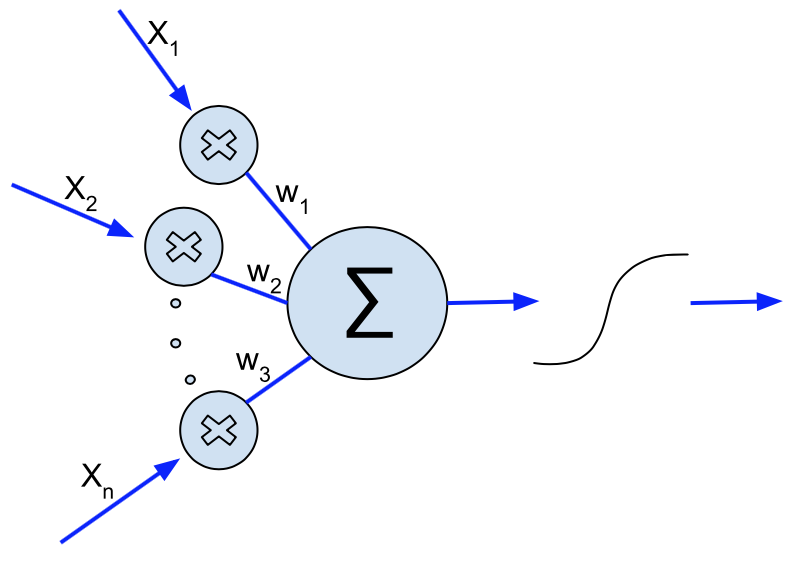
(イエス、図中のw3は本当はwnであるべきだ) これらの重みは、任意の値を取りうる (しかし、実際上はシステムがプログラムされるプログラミング言語によって表現可能な数値の上限は決まっているが)。また、これらの重みがシステムが何を学習できるかを決めるのだ。(ただし、この「学習」という言葉は、私の「7つの大罪」記事で説明した通り、スーツケース語であることを思い出してほしい。) 後のパラグラフで再度戻ろう。
合計も任意の値を取りうるが、しかし2つ目のステップのロジスティック関数またはシグモイド関数を使用して、この数値は再度0から1の間に圧縮される。典型的な1つの例は、
f(x) = \frac{1}{1+e^{-x}}
すなわち、合計は関数の引数として与えられ、右辺の式は厳密に0から1の間の値を生成するよう評価される。極端に大きな値または極端に大きな負の値を取るに従って、1または0に近付いていく。ここで、この関数は可能な入力xの間の大小関係を保存することに注意せよ。すなわち、もし y < z ならば f(y) < f(z) である。さらに、この関数は0の入力に対して対称であり、その時0.5の値を取る。
この関数は非常に頻繁に使用される。この関数が、いかなる出力に対しても微分を計算することが容易であり、入力値を逆転させる関数を求める必要がないからだ。
特に、通常の微分と代数的な簡約化の規則を用いると、この関数の微分は以下の通りに書ける。
\frac{d}{dx} f(x) = \frac{e^x}{(1+e^x)^2} = f(x) (1-f(x))
この性質は、1980年代のニューラルネット復活の際、非常に有用であることが判明した。これらは、下図のような規則的な大規模ネットワークで組み合わされている。ここでそれぞれの大きな円は上記の人工ニューロンの1つに対応する。右側の出力は、普通シンボルでラベル付けされている。たとえば、猫 cat や 車 car などである。左側の小さな円は、何らかのデータソースから来るネットワークへの入力に対応している。
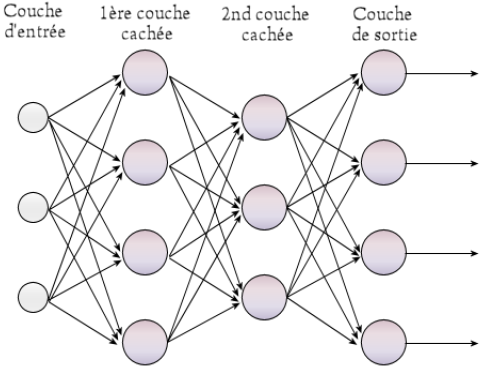
たとえば、データソースは画像であるかもしれず、左側の入力としてサンプリングされた画像の小さな小片が数千個もあるかもしれない。おそらく、画像の中の局所的な特徴、たとえば、角(コーナー)や明点などを取り出すためにピクセルが少しばかり処理されているかもしれない。ひとたびネットワークが訓練されると、catとラベル付けされた出力は、画像に猫が写っている場合に1に近づき、そうでない場合は0に近づくような値を出力する。また、carとラベル付けされた出力も類似の出力を持ち、画像に車が写っているかを判定する。これらの数値は、ネットワークが、猫や車が写っている確率に対して割り当てたものであるとみなすことができる。つまり、この種のネットワークは、入力値を有限個の出力クラスへと分類するものである。
しかし、どのようにしてこのネットワークネットワークは訓練されるのだろうか? 典型的には、何100万枚もの (イエス、何100万だ) 画像を見せるのである。それぞれの画像には何のオブジェクトが含まれているかが明示されている。シンボル付きの出力ラインが正しい結果を得られなかった場合、違反している出力ニューロンに対する入力の重みは、次回はより良い結果を得られるように調整される。これらの重みの更新量は、重みの変更がどれほど出力に影響を与えるのかに依存する。
そのため、シグモイド関数上のどこから出力が来ているかの変化量を知ることは、重要な問題となる。[Knowing the derivative of where on the sigmoid function the output is coming from is thus critical.]
訓練中にどれほどの量で重みが変更されるか、を表す比例量 [proportional amount]または利得は、時間が経つにつれて減少する。
1980年代の発明によって、出力中に検出された誤差をネットワークの複数の層で、当時ふつう2個か3個程度の層で逆向きに伝播させることで、1件の誤った分類出力からシステム全体が何らかの情報を学習できるようになった。この技法は逆伝播 [back propagation] と呼ばれている。
直近の入力画像が、重みに対して大きな影響を与えることは直ちに理解できるだろう。そこで、ネットワークに他のすべての画像を見せることが必要となる。そして、時間が経つにつれて重みの変化量は次第に減少する。典型的には、それぞれの画像はネットワークに何千回、あるいは何十万回も示され、他の何百万枚もの画像と合わせネットワークへ何千回も入力されるのである。
訓練はこのようになされるが、実際にはもう少し複雑である。しかし、多くの場合うまく機能する。ただし、ネットワークの層の数を定めたり、個々の層から次の層への接続の方法を調節したり、入力や出力が何であるかを決定するのは人間であることに注意せよ。
その後、ネットワークの訓練、何をいつ入力するかというスケジュールを定め、ネットワークの学習における利得を調整する方法は、人間の設計者の選択によっている。
そして、ネットワークが大量に訓練されたあとも学習がうまく進まない場合は、人間がネットワークの構成を調整し、再度訓練を行なうこともある。
このプロセスは、科学としての化学と対比して錬金術にたとえられることもある。呪文をうまく唱えられる現代の錬金術師は、6桁か7桁の給料を受け取る場合もある。
1980年代に逆伝播が初めて開発され多層ネットワークが最初に使用され始めたとき、計算力とアルゴリズム上の制約から、実用的なネットワークはせいぜい2層か3層であった。30年後の2006年のディープラーニング革命の立役者には、アルゴリズムの改良、新しいインクリメンタルな訓練技法、そして当然多大な計算力と、15歳を迎えたワールドワイドウェブから収穫された膨大な量の訓練データセットが含まれている。すぐに12層程度のネットワークも実用的に使われるようになった-これが「ディープ」という名前の由来である-これはネットワークの多数の層の重なりを指しており、決して「深い洞察」を意味しているのではない…
2006年以来の10数年の間に、多くの実用システムが構築されてきている。
最近、そして今後数十年にわたって、ほとんどの人に対して最大の実用的インパクトを与えるであろうシステムは、話し言葉の書き起こしシステム [音声認識システム] だろう。過去5年間の間に、電話越しに「お困りの方は、"2"と言うかボタンを押してください」というレベルのスピーチシステムから、ボイスメッセージの連続的な音声認識システムまでの発展が見られた。そして、家電ではAmazon EchoからGoogle Homeに始まり、今や音声認識はTVのリモコンにまで拡大し、さらに多くの製品が巨大企業の音声認識クラウドサービスの上に作られるようになっている。
人間の発話から正しい単語を得るためには、2つの能力が必要となる。1つ目は、音素の検出である。音素とは、単語を構成する下位部分であり、個々の言語で音素は非常に異なっている。これらの連続した音素を分割して、中には検出エラーもあるかもしれないが、対象言語の単語の連なりへと変換するのである。ニューラルネットワーク以前の特徴検出器、つまり、素の音声信号の入力を受けて音素への低レベルの鍵を提供するプログラムは、エンジニアが手作業で作るものだった。ディープラーニングにより、それら最初の特徴量も含めて、対象言語の様々な話者が話した膨大な量の会話データを聞くことだけで、学習が可能となる技法が開発されたのだ。これが、今日我々が機械に話しかけることは自然だと考えるようになった理由である。ちょうど、スタートレック4のスコッティーがしていたように。
新しい能力は、2014年11月17日のニューヨークタイムズの記事で世界に公開された。記事では以下の写真とともに、Google社のプログラムが自動生成した説明文 「若者のグループがフリスビーのゲームで遊んでいる [A group of young people playing a game of Frisbee]」が添えられていた。
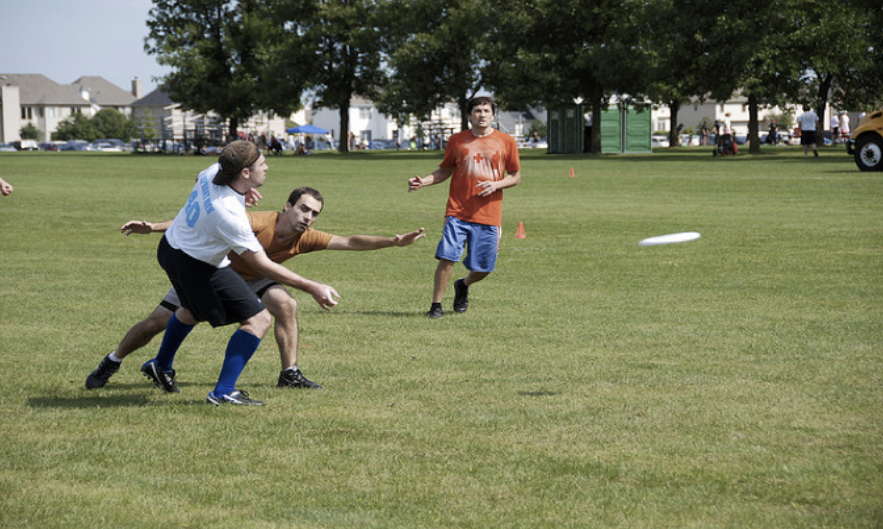
人々が本当にディープラーニングに気付き始めたのはこの頃ではないかと思う。これは魔法のように見えるだろう。AI研究者にとってもそうだ。おそらく、特にシンボリックAI分野の研究者にとっては。シンボリックAIのプログラムはこれを上手く実現できなかったのだ。けれども、人々はパフォーマンス[performance; 目に見える成績、実績]とコンピタンス[competence; 潜在的な能力や技能]を混同しているのではないかと思う (再び私の「7つの大罪」記事を参照のこと)。もしも人間がこのレベルのパフォーマンスを上げられたとしたら、写真についてこの程度の説明ができるとしたら、当然この人物は世界を理解するのに十分なコンピタンスがあると期待できる。そして、この人物はおそらく以下の質問に答えられるだろう。
- フリスビーはどんな形をしていますか?
- 人間はだいたいどれくらい遠くまでフリスビーを投げられますか?
- 人間はフリスビーを食べられますか?
- だいたい何人くらいの人が1度にフリスビーで遊べますか?
- 生後3ヶ月の赤子はフリスビーで遊べますか?
- 今日の天気はフリスビーで遊ぶのに適していますか?
けれども、上記のような説明文を生成できるディープラーニングのニューラルネットワークでも、これらの質問には答えられない。ディープラーニングは、確実に質問とは何であるかを理解しておらず、単に単語を出力できるのみである。学習結果に埋め込まれている、これらの質問に答えるために必要な知識はまったく持っていないのだ。
そのシステムが学んだのは、色のピクセル、その一部分の局所的配置から単語列へのマッピングである。それがすべてだ。それらの単語は、伝統的シンボリックAI研究における匿名のシンボルをごくわずかに超えているに過ぎず、ある種のグラウンディング、つまり近傍ピクセルの見た目に対してグラウンディングされているのみである。けれども、それを超えたところでは、これらの言葉やシンボルや世界のいかなるものとも関係を持っていない。
ここでの学習は、何万個、あるいは何百万個もの重みを選択することによって行なわれている。入力データに対するネットワークの接続方法は人間によって設計されており、ネットワークのレイアウトも人間によって設計されている。出力としてのラベル、またはシンボルも人間が選択しており、訓練データセットも事前に一人の(または多数の)人間によって、同一のシンボルでラベル付けされているのである。
3. 伝統的ロボティクス
人工知能の最初期の数十年の間、シンボルAI分野の研究者は、ロボットの作成を通してAIをグラウンディングしようと試みた。移動可能なモバイルロボット、おそらく体を使って物を押すこともできるロボットや、ある場所に据え付けられたロボットアームなどがあった。当時は、その両方を持たせること、連結式アームを備えたモバイルロボット、はとても難しかったのだ。
最初期のコンピュータビジョンの試みは、その後これらのロボットと組み合わせられた。当初の目標は、実世界に存在する物体の配置を推測することであり、そして次に幾何学的な位置上で何らかのシンプルなシンボルへとマッピングを行うことであった。
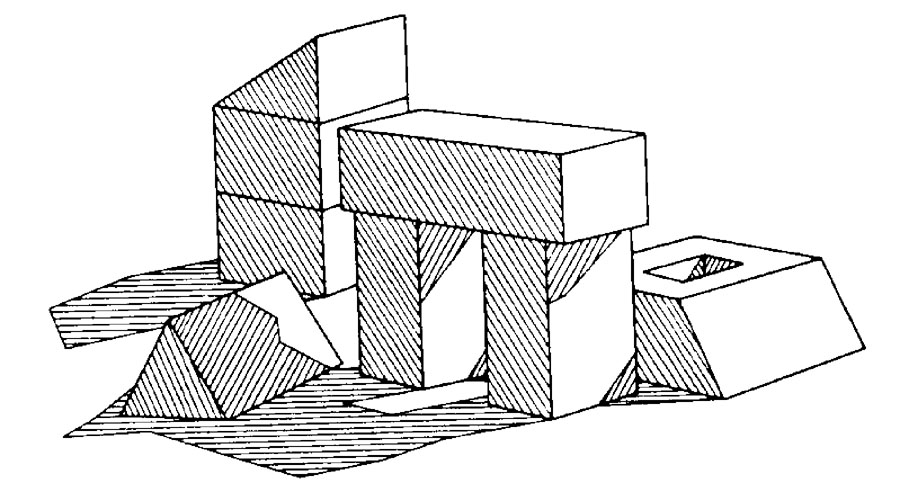
私の人工知能の起源に関する記事の中で、私はいくつかの例を挙げた。たとえば、画像のエッジを探すことによって知覚を構築する方法、世界に存在する物体の幾何学的なモデルを生成するために、どのようなエッジの組み合わせが可能であるかというルールの検討などが挙げられる。私は、以下の影付きの複雑な光景を例として取り挙げた。
カメラとコンピュータを接続して世界を見るとき、視野の中で許容される光線と物体は、コンピュータビジョン、シンボルグラウンディングの実現のために制約を受けることも多かった。下のぼやけた写真は、MIT人工知能研究所で1970年代に実施された「コピーデモ」の写真である。ここでは、視覚システムロボットは、お手本として積み上げられたブロックを見て、ロボットはそれと同じように見えるようブロックを積み上げようとしている。

同じ頃、カリフォルニア州メンローパークにあるSRIインターナショナルのチームは、シャーキーというロボットを構築した。そのロボットは、それぞれの面が別の色に塗られた、立方体やくさび形の大きなブロックを備えた部屋の中で動作するものだった。また、室内の照明装置は綿密に制御されていた。


1979年、スタンフォード人工知能ラボのハンス・モラヴェックは、屋外でも活動できるロボット、「ザ・カート」を作成した。下の写真の中央に写っている。(この写真は私が撮ったものだ) ロボットは、多面体のオブジェクトの周囲を移動するのだが、他の物体も散らかっている。このロボットは1メートルの移動に約15分を要したため、濃い残像が写っている。若干混乱するかもしれない。

そしてこれは1970年代半ば、エジンバラ大学人工知能学科のフレディIIロボットである。四角形や円形のブロックを積み上げ、それらを柱に刺している。

これらの初期の実験では、画像とシンボルマッピングを組み合わせ、そこからロボットが操作できるように3次元座標を計算していた。シンボリックなAIプランニングをエンドツーエンドで使用しているのだ。
それらエンドツーエンドの目標は、時間が経つにつれて次第に失われていったと言っても過言ではないと思う。実際の物体を扱う場合には、不確実性に起因する現実の複雑さが認識され、AIロボティクス研究者が注力するタスクは、大部分が自己定義された研究アジェンダによって進められるようになり、概念実証[proof of concept]それ自体が目的となっていった。
そして、ここで明確に言っておきたい。これらAIベースのロボティクスシステムは、産業界ではまったく利用されていない。工場で眼にするすべてのロボットは (ただし、私の会社 Rethink Roboticsを除く)、定められた動作を正確に何度も何度も何度も繰り返すよう、詳細に、入念にプログラムされている。低レベルのロボット力学モデリングとロボットアームの経路計画の手法は、AIロボティクスコミュニティと産業界で共有しているけれども、それ以上のレベルでは完全かつ精密な台本に従っている。過去40年間のAI研究の工業用ロボットに対する応用は、実際上ほとんど影響を及ぼしていない。
一方で、AI分野の伝統的ロボティクスから巨大な影響を受けた領域が1つ存在している。前述のザ・カートのようなロボティクスを嚆矢として、研究者は、ある場所から別の場所へロボットシステムの移動経路を計画するために、周囲の環境の地図を作成することを試みたのである。その経路は、障害物や不整地などを避けつつ、同時に移動時間が短くなるようなものである。そこで、研究者は、ロボットの移動に従い外界を観察して、周辺の地図作成を目指すプログラムを組み始めた。ロボットの実際の移動距離に対する不確実性と、更に重大な問題としては、ロボットが指令を受けた際の回転角度の不確実性により、ロボットによる観察をシンプルな座標系へと正確に入力することは不可能であるとすぐに理解された。更には、ロボットがより遠くまで移動するにつれて、スタート地点からの相対的な不正確さもより拡大していくのである。
1984年末、トゥールーズのラジャ・シャティラ[Raja Chatila]と当時MITの新任教授であった私は、もしもロボットがしばらくウロウロ移動した後で同じ目標物を再度見たと認識できたとすると、その間の連続した観察を後ろ向きに辿ることができ、それらの観察に含まれる不確実性を低減させられるだろうと気付いたのである。以前に見たものと完全に同じ光景である必要はない。必要なのは、以前にとあるシンボルでラベル付けされた物体の位置を検出し、それと同一のシンボルでラベル付けされた新しい物体が、事実として外界の同一物体であると確認することだけだ。現在ではこれは「ループクロージング[loop closing]」と呼ばれている。我々2人はこのアイデアを論文として、1985年5月にセントルイスで開催されたロボティクス会議 (IEEE ICRA) で独立に発表した。しかし、我々のどちらもあまり優れた統計的モデルを作成できておらず、私のモデルは確実にラジャのものより劣っていた。
1991年までに、当時2人ともオクスフォード大学所属のヒュー・デュラン=ワイトとジョン・レオナードは、この問題のより優れた定式化を行なった。元々の名前では“Simultaneous Map Building and Localisation”(オクスフォード式英語綴り) と呼ばれていたが、後にその問題は “Simultaneous Localisation and Mapping” [同時位置推定地図作成] またはSLAMとなった。その後15年以上にわたって、数百人もの、数千人でなければだが、研究者たちが初期の研究を洗練させていった。それを可能としたのは、新しい低コストの多数のモバイルボロット (私の会社 iRobot社も1990年代はこれらのロボットの供給が主要事業だった) によるものである。厳密に定義された問題、低コストのロボット、豊富な計算力および世界中の研究者の協力、性能への競争により、高速の発展が起こった。しばらくすると、研究者は世界のシンボリックな記述を取り除き、不確実性の統計的モデルを用いた座標系ですべてが実現されるようになった。
SLAMアルゴリズムは自動運転車の基礎の一部となり、SLAMから発展したサブシステムはこれらのシステムのすべてで利用されている。同様に、クアッドコプタードローンの誘導と情報収集にもSLAMが使われている (同時にGPSからの入力も使用されている)。
4. 振る舞いに基づくロボティクス
1985年までに、私は10年ばかりコンピュータビジョンの研究、画像をもとに実世界のシンボリックな記述を引き出すことを目指した研究を行なっていた。また、伝統的ロボティクスの分野では、ロボットがシミュレーションまたは実際の世界で動作するためのプランニングシステムを開発していた。
私は非常に不満を感じるようになっていた。
それ以前の数年間、私は純粋なシミュレーションのデモから実世界で機能する実際のロボットへと進もうと試行していた。自身のプログラム内の実世界に関する知識の中に含まれた不確実性を推定するため、私は数式の中へと埋もれていった。プログラムに、現実世界と世界から得た知覚の間の誤差を測定させようとしていたのである。その当時までには、知覚は難しい問題であることが分かっており、知覚からの完璧なマッピング情報取得は確実に不可能であると判明していた。私は不確実性に順応しようと考えて、伝統的なロボティクスとシンボリック人工知能の組合せを使うことで、不確実性を私のプランニングプログラムへと導入しようと試みていた。希望は、現実の物理世界におけるあらゆる可能性に対して、プランナーがどれほど広範囲の不確実性に適応できるのかを知ることであった。
この連載の過去記事の中で私が取っている、暗黙的な基礎を成す哲学的立場については再度取り上げるつもりだ。記事は今年後半に公開予定である。
しかしその当時、昆虫がいかに上手に実世界を動き回れるか、それがどれほど少ないニューロンで実現されているか (確実に、今日のディープラーニングネットワークの人工ニューロンよりも少ないだろう) について、真剣な考察を始めたのだ。これがどのように実現されているかを考えるうちに、生物の進化の過程において、単純な生物は世界のシンボルや三次元モデルの構築から着手することはおそらくなかっただろうと気付いたのである。実際には、非常に単純な知覚と行動のコネクションから開始されたはずである、と。
このような考え方によって導かれた振る舞いに基づくアプローチでは、複数の並列した振る舞いが同時に行なわれ、わずかな知覚入力を得て、それを用いて世界の中でシンプルな行動を起こすのだ。時として、振る舞いはロボットのアクチュエーターに対して競合した命令を提示することもあり、何らかの競合した解決策[resolution]が必要となることもある。しかし、世界の完全なモデルの必要性に立ち戻り留まって待機しているのではなく、競合の解決メカニズムは、本質的にヒューリスティックである必要がある。お気付きの通り、進化が生み出すであろう種類の行動である。
振る舞いに基づくシステムが機能する理由は、世界に埋め込まれた身体の物理学的な要求が、振る舞いとその相互作用との間で発生する競合に対し、究極的な解決を強制するからである。更には、世界の中に埋め込まれていることにより、システムが移動するに従って新たな物理的制約あるいは世界の中の他のエージェントからの制約が検出される。振る舞い木の制御下にあるビデオゲームの人工キャラクターの場合、物理的な要求は、レンダリングエンジンによって求められるシミュレーション世界の物理的要求に置き換えられる。現実世界の他のエージェントにおいては、人間のプレイヤーまたは別の振る舞いに基づく人工キャラクターである。
つい数週間前、これを示す好例が大きく報道されている。MITのサンベ・キム教授の「チーター3ロボット」についての独自記事である。報道では、ブラインドの[カメラを使わない]ロボットが階段を登ることに大きな注目が集まっている。しかし、記事を読めば、研究のポイントはブラインドロボットを開発することそれ自体ではないと理解できるだろう。コンピュータビジョンは、3Dビジョンでさえ、完全に正確ではない。そのため、触覚ではなく視覚を用いて不整地を登ろうとするロボットは、どんなものであれ、ゆっくりと動作し、一度に一本の脚を注意深く移動させなければならない。ロボットは、世界の中のどこに堅い地面があるかを正確には知らないためである。新しい研究において、キム教授と彼のチームは、間違いが発生したとき、それを感知し素早く個々の脚の動きを修正するような、低レベルの振る舞いの集合を構築したのである。その有効性の証明として、完全にブラインドなロボットを作ったのだ。視覚を通した高レベルのディレクションによって脚をどこに向けるべきかが分かれば、彼らのロボットの性能は更に向上するだろう。しかし、そうであっても、最低レベルの振る舞いに対する反応のみによって、高速で足取りの確かなロボットが構築できるのだ。
振る舞いに基づくアプローチ、つまり世界のモデルをエージェント内部に組込むのではなく、外界をそのままモデルとすることによって、数的にロボットは増殖できたのだ。残念なことに、私は専門外の人々から非難を受けることもある。実質的に、彼らが言うには、私たちは超知能ロボットを約束されていたのにあなたが私たちにくれたものは掃除機だけではないですか、と。申し訳ない。超知能ロボットは開発中なのだ。少なくとも、私は実用品を提供した…
AIへの4つのアプローチの比較
私の1990年の論文『象はチェスをしない [Elephants Don’t Play Chess]』の2ページ目最初のパラグラフで、古典的なシンボリックAI研究と私自身の研究双方の「聖杯」は、「汎用的な人間レベルの知能」であると述べた。今日の若人たちがAGIまたは汎用人工知能の目標は新しいものだと言うのは、端的に間違いなのだ。私がアウトラインを示した上記すべての4つのアプローチは、最終的には人間レベルの知能、あるいはそれを超えた知能を実現するというモチベーションを持っていた。
個々の4つのアプローチのどれも目標に近づいておらず、あるいはその何らかの組合せも、見たところ目標に近づいていないようである。けれども、各々の4つのアプローチには、それぞれ何かしら特別な強みがあり、同時にすべてのアプローチにおいて容易に認識可能な弱みがある。
AI研究でシンボルを使用するアプローチでは、知能の異なる側面を合成するための共通通貨としてシンボルを使用できる。ある推論用コンポーネントから別のコンポーネントへと、シンボルを受け渡せばよいのだ。ニューラルネットワークでは、かなり控え目なシンボルが出力としてのみ現れ、シンボルを戻したり、本当に他のネットワークへと与える方法はない。伝統的なロボティクスでは、幾何学的な関係と座標をもとに協調される。これは合成が容易な方法ではあるが、しかし意味的[semantic]な内容の扱いには弱点がある。また、振る舞いに基づくシステムは、シンボルより下位レベルのものである。ただし、ある種の原始的なシンボルを扱う方法も登場し始めている。
ニューラルネットワークは、知覚入力から意味のあるシンボルを得ることに対して最も成功したアプローチである。他のアプローチでは、それに挑戦してもいない(伝統的ロボティクス)か、もしくはあまり成功しているとは言い難い。
座標間の堅固な統計的関連性を備えたハードなローカル座標システムは、現代的なアプローチから伝統的ロボティクスへと発展した。
シンボリックAIと振る舞いに基づくシステムの両方とも、異なるパーツを共有することについては弱点がある。よく理解された関係性、座標システムでさえそうなのだ。そして、ニューラルネットワークは、単純に空間理解がへたくそ(イエス、へたくそ[suck])である。
ここで議論した4つのアプローチのうちでは、ただ振る舞いに基づくアプローチだけが、システムの継続的存在にコミットしている。それ以外は、とりわけニューラルネットワークは、本質的にかなり一時的[transactional]である。また、振る舞いに基づくアプローチは、世界の変化に対してミリ秒のタイムスケールで反応できる。システムが世界に埋め込まれており、「生きて」いるからだ。あるいは、ビデオゲームのキャラクターの場合、その基盤にしっかりと埋め込まれているからである。世界の一部となるこの能力、あるいは世界の中での動作主体性 [agency] を持つ能力は、何らかのレベルの人工的な自己認識 [artificial sentience] である。乱雑な哲学的用語であることは確かだ。それでも、私が思うに、汎用人工知能というフレーズを発したことのある人、あるいは超知能という語を発したか、呟いた人は皆、何らかの種類の自己認識を期待しているのではないかと思う。振る舞いに基づくシステムを通して意識を実現するまでどれほど遠いとしても、それが我々が知る最良の方法なのだ。遠大な目標である。
私は、3つのアプローチのどこに利点と欠点があるのか点数付けをしてみた。点数の範囲は1点から3点までであり、3点はそのアプローチに本当に強みがあることを示す。4つの異なる特徴の他に、そのアプローチがどれだけ曖昧性 [ambiguity] をうまく扱えるかを示す列を加えたことに注意せよ。
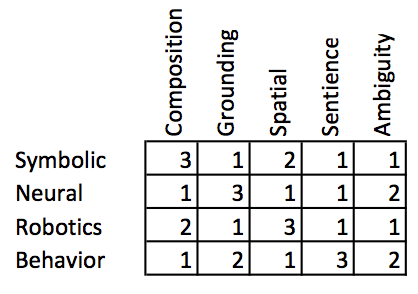
個々の4つのアプローチが得意とする分野はそれぞれ異なっている。けれども、汎用知能実現のためには、認知[cognition]についても話さなければならないと考えている。認知の定義は数多く見つけられるだろうが、しなければならないことのすべては思考 [thinking] に関わっている。そして、思考について語っている定義は、注意[attention]、記憶、言語理解、知覚[perception]、問題解決その他など文脈によりさまざまである。そのため、私の点数はやや主観的であることは認めよう。
もしも我々が超知能的AIのエンティティについて考えるとするならば、超知能AIは世界の中で何らかの目的を持って行動してほしいと思うのではなかろうか。シンボリックAIと伝統的ロボティクス分野では、プランナー[planner]についてたくさんの研究がある。世界の状態を知るプログラムと、一連の行動を通して世界 (および、世界に埋め込まれたAIシステムまたはロボット) をより望ましい状態へと変化させるものである。これらのプランナーは、大部分がシンボリックで、ロボットに対する空間的コンポーネントを持つかもしれず、世界の状態に対する完全な知識を備えて開始されるのである。過去数十年において、世界の詳細な状態をすべて知ることは不可能であるという現実に対処する研究が注力されている。しかし、このようなプランナーは、今後何を起こすかについて極めて意図的 [deliberative] なものである。対照的に、振る舞いに基づくアプローチは、世界の変化に対して純粋に反応的 [reactive] なものとして始まった。これによって、振る舞いに基づくアプローチは現実世界で極めてロバストな手法となっており、実用されているロボットの大部分が振る舞いに基づくアプローチを取っている理由だ。20年来の振る舞い木のイノベーションにより、これらのシステムはかなり意図的に見えるようにもなった。それでも、シンボリックシステムが持つような動的リプランニングの完全な能力を欠いている。
以上を表にまとめた。

ニューラルネットは、このどちらでもないことに注意せよ。ニューラルネットを用いてロボットを制御する研究は、比較的少量の非主流派の研究に限られ、また非常に単純なロボットであり、大部分がシミュレーションに限定される。ニューラルネットワークに関する研究の大部分は、何らかの方法によってデータを分類する手法である。ニューラルネットは完全なシステムにはならず、また実際のところ、最近のニューラルネットの成功事例は、シンボリックAIシステムまたは振る舞いに基づくシステムの部品として埋め込まれたものである。
超知能へ向けたステップ、パート1の終わりに、人工知能の4つのアプローチの比較表にもう一度戻ろう。我々のAIシステムが本当にどれほどうまくできるか(私の意見で)を、人間の子供と比較してみよう。
点数の範囲は1点から3点であることを思い出してほしい。私は右端に「認知」の得点を付け加えている。また、最下段には4つのAIアプローチと比較した人間の子供の得点を記載している。
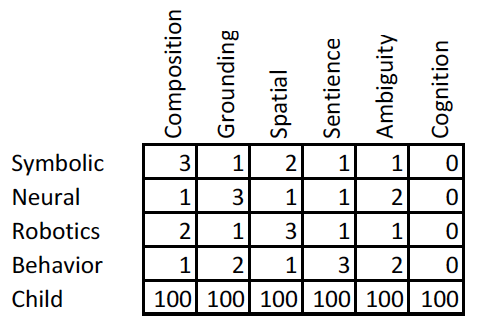
この評価のもとでは、人間の子供は600点の得点を挙げている一方、4つのAIアプローチの合計点は、それぞれ8点か9点である。いつも通り、私は現在のAIシステムの能力をあまりにも過大評価しているかもしれない。
次のパート2「チューリングテストを超えて」