タイトルの通り、Datastoreに入れていたデータをCloudSQL(MySQL)に持っていくためにやったことです。
結論
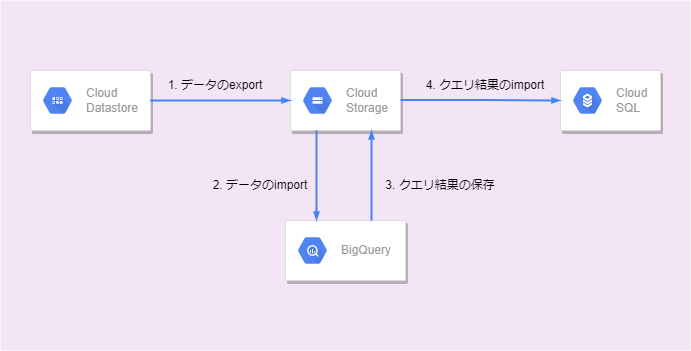
Datastore ---(export)---> GCS ---(import)---> BQ ---(クエリ結果取得)---(import)----> CloudSQL
概要
Datastoreからのエクスポート
サポートされているエクスポート方法はGCSへの出力のみです。LevelDBというkey-value形式でエクスポートされます
DatastoreからBQへ
この手順については公式ドキュメントにもあり、GCSへのエクスポート、BQでGCSからのインポートによるテーブル作成という流れになります。
DatastoreからCloudSQLへ
残念ながら、それを一発でやるような方法やドキュメントはありません。そもそもNoSQLのDatastoreからCloudSQLに入れるということが必要になるケースが少ないかもしれませんね。
仕方ないので、BQでクエリ実行して取得した結果をCSVとして保存し、それをMySQLにインポートするという手順を採りました。
全体の流れ
手順
前提
- Datastoreは、Datastoreモードで使用しています。
- エクスポートそれ自体において必須なわけではないですが、CloudSQLにアクセスするための踏み台GCEを経由するするようにしています。
0. 事前準備
- GCSバケットの作成(リージョンに注意: インポート先BQとリージョンを合わせる必要があります)
- BQデータセットの作成(リージョンに注意: GCSバケットとリージョンを合わせる必要があります)
- CloudSQLインスタンスおよびDBの作成
- CloudSQLにアクセスできる環境準備(ここではGCEインスタンスを用意しますが、ローカルマシンでも問題ありません)
1. DatastoreからGCS
ちなみにこのようなサンプルデータを用意しています。
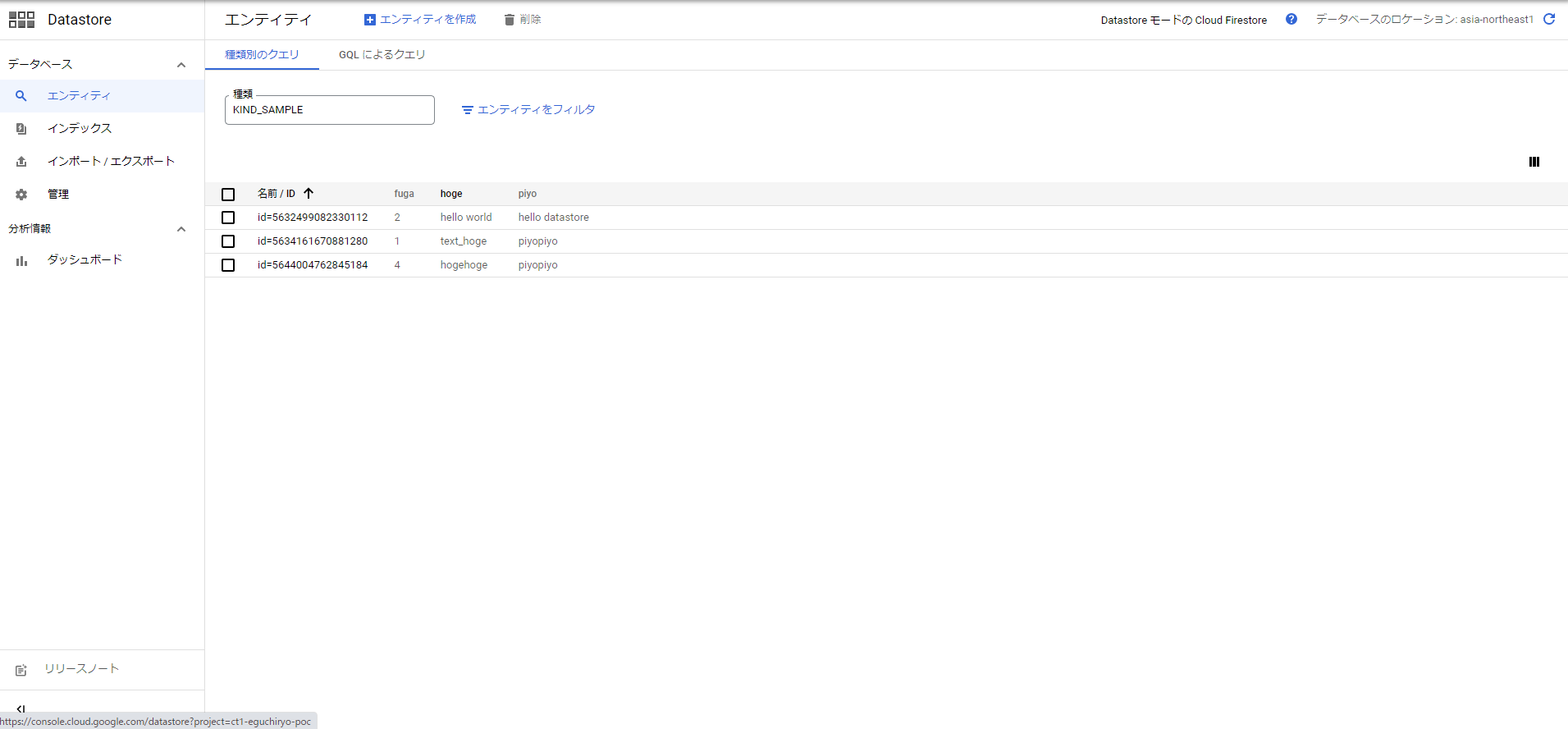
Datastore > インポート/エクスポートで「エクスポート」を選択します。
エクスポートするKindおよびエクスポート先のGCSバケットを選択して、エクスポートを実行します。
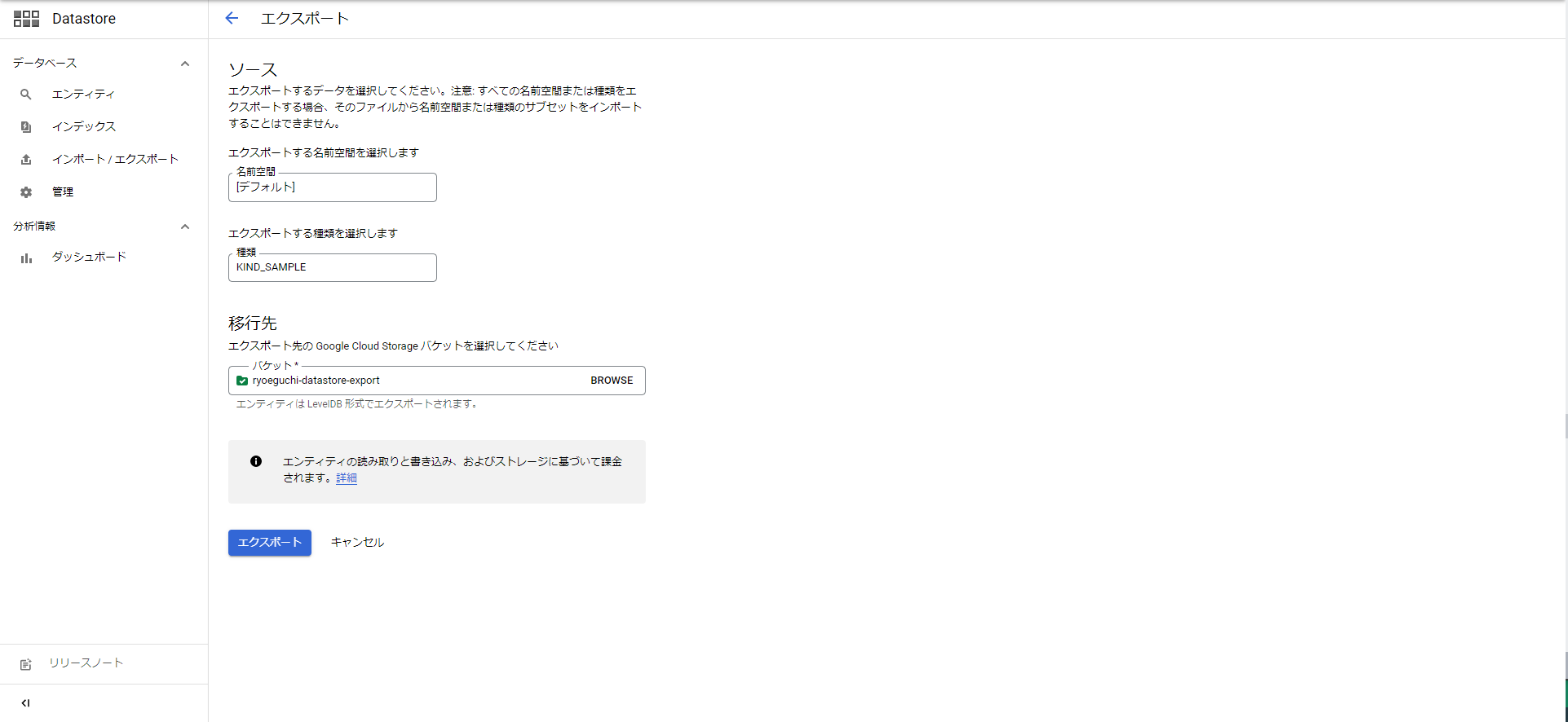
エクスポートが完了すると、GCSには「${YYYY-MM-DDTHH:MM:SS}_${自動採番num}」のフォルダが作成されます。
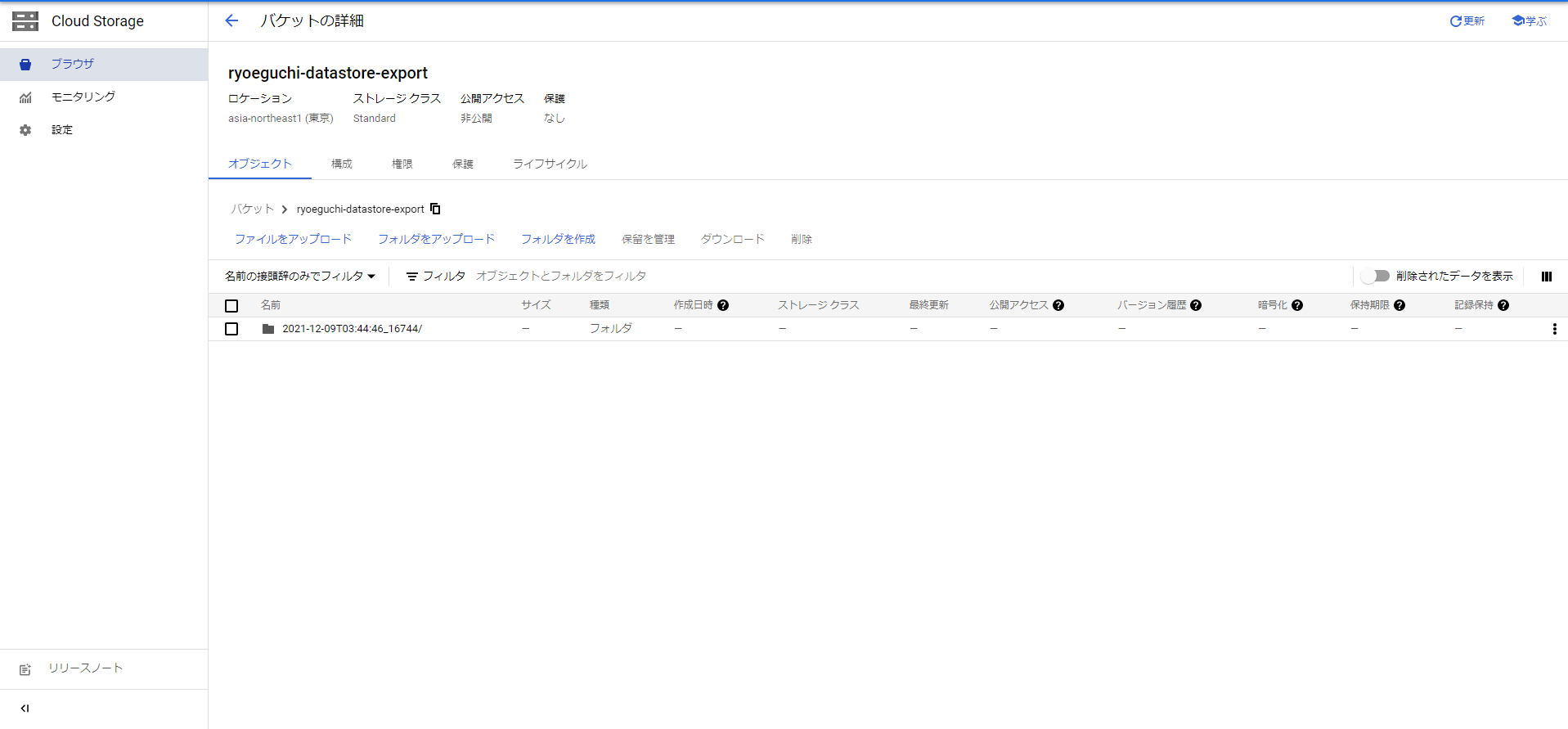
2. GCSからBQ
Big Query > SQLワークスペースで、データセットを開き、[テーブルを作成]をクリックします。
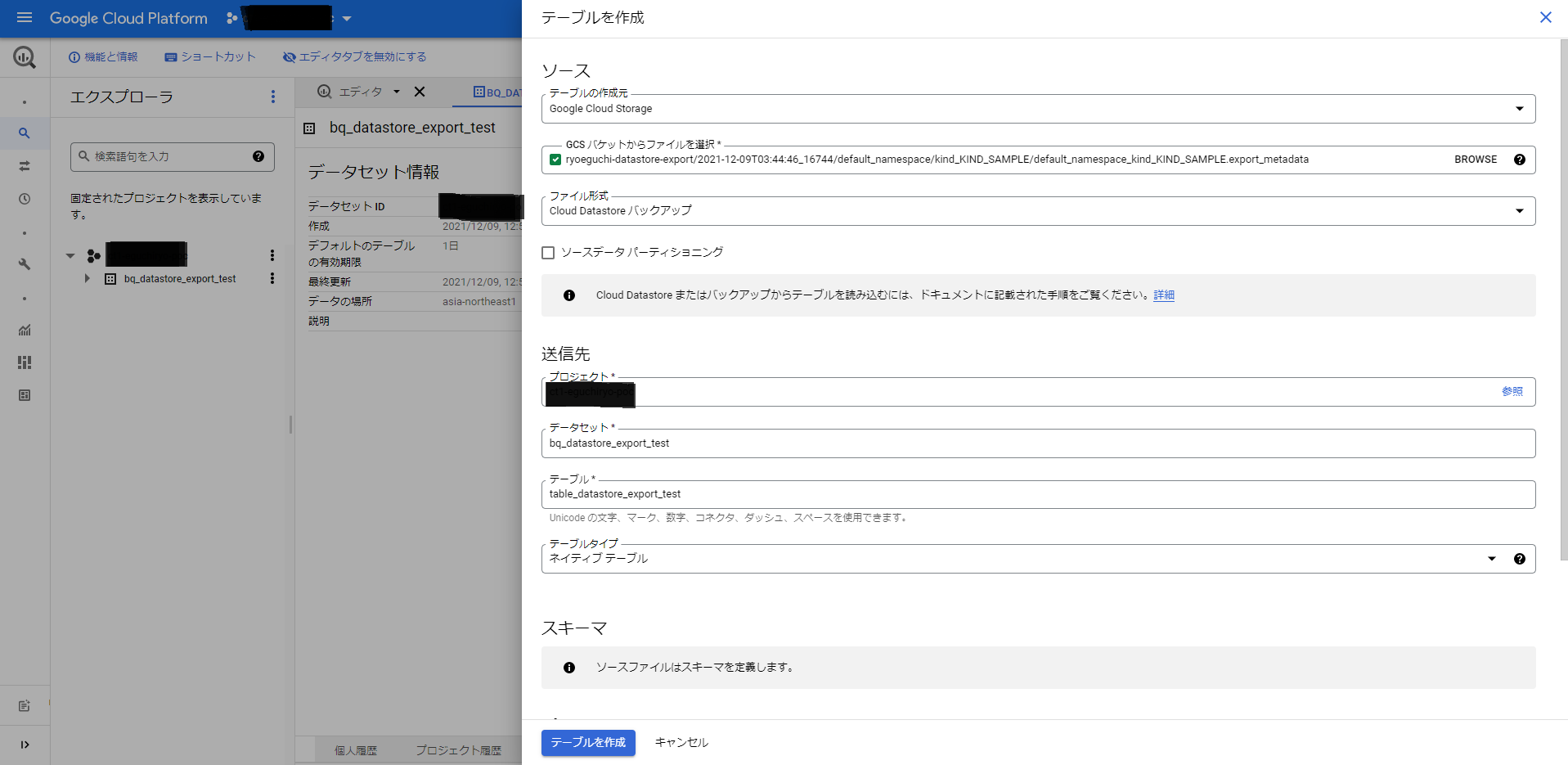
テーブルの作成ページでの選択は以下の通りです(記載のないものはデフォルト)
[ソース]
テーブルの作成元 : Cloud Storage
GCSバケット府からファイルを選択: [作成されたバケット]/[namespace名]/[kind名]/[namespace名]_[kind名].export_metadata
ファイル形式 Cloud Datastore バックアップ
[送信先]
テーブル: 任意のテーブル名
エクスポートが成功すると、BigQueryのプレビュー等で、実際にデータが確認できます。
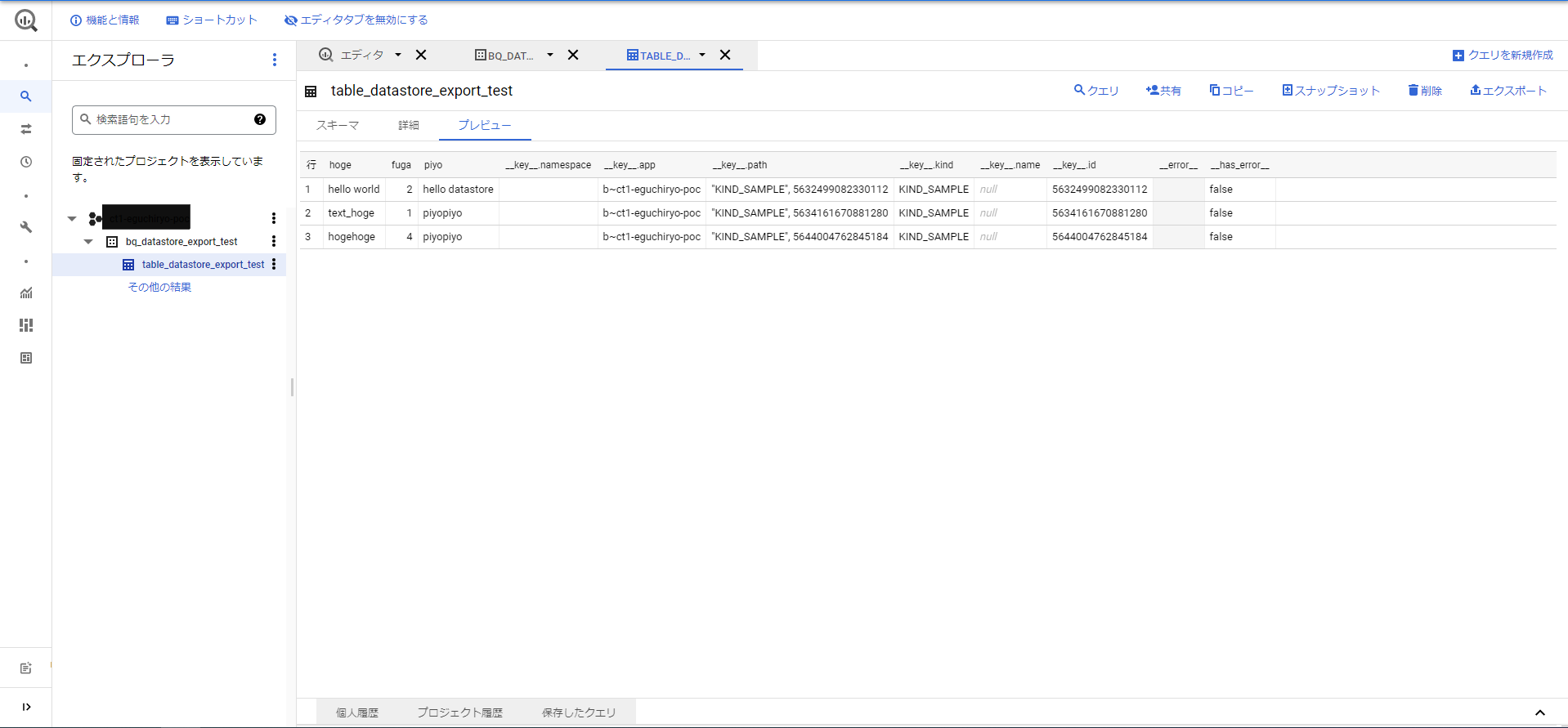
3.BQでクエリ結果取得
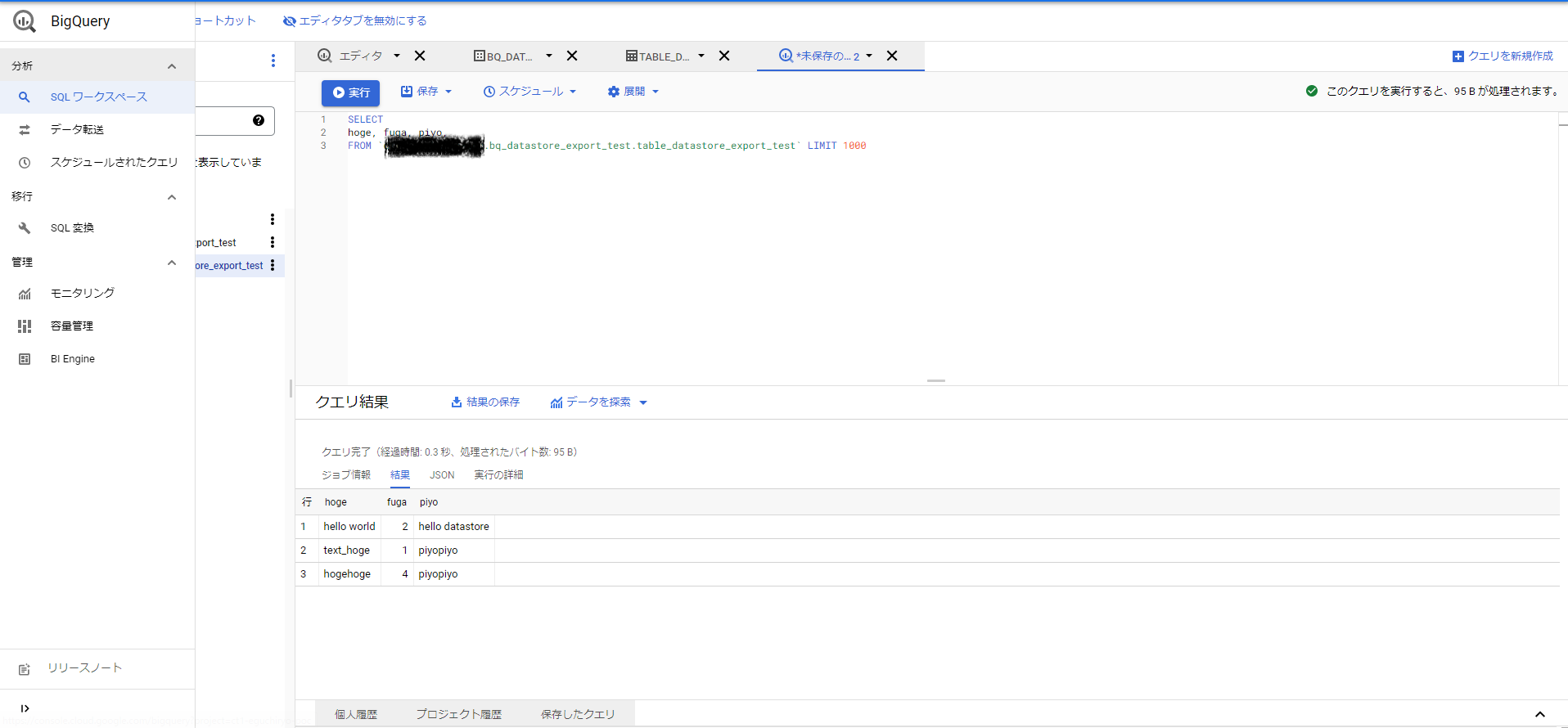
この結果を取得するためにクエリを実行します。
Datastoreにより用意されたカラムもあるので、実際にCloudSQLに入れるのに必要なデータのみ抽出します。
ここでは以下のようになりました
SELECT hoge, fuga, piyo FROM `MY-GCP-PROJECT.bq_datastore_export_test.table_datastore_export_test`
4.クエリ結果の出力
ここではCloudShellを用いてクエリ実行とGCSへのエクスポートを行います
出力先GCSバケットは、datastoreのexport先と同じにしています。クエリは、3の手順のものと同一です。
bq query --nouse_legacy_sql 'EXPORT DATA OPTIONS(
uri="gs://ryoeguchi-datastore-export/query_export_*.csv",format="CSV",overwrite=true,header=true,field_delimiter=",")
AS SELECT hoge, fuga, piyo FROM `MY-GCP-PROJECT.bq_datastore_export_test.table_datastore_export_test` '
GCSバケットにcsvファイルが出力されいるのが確認できます。
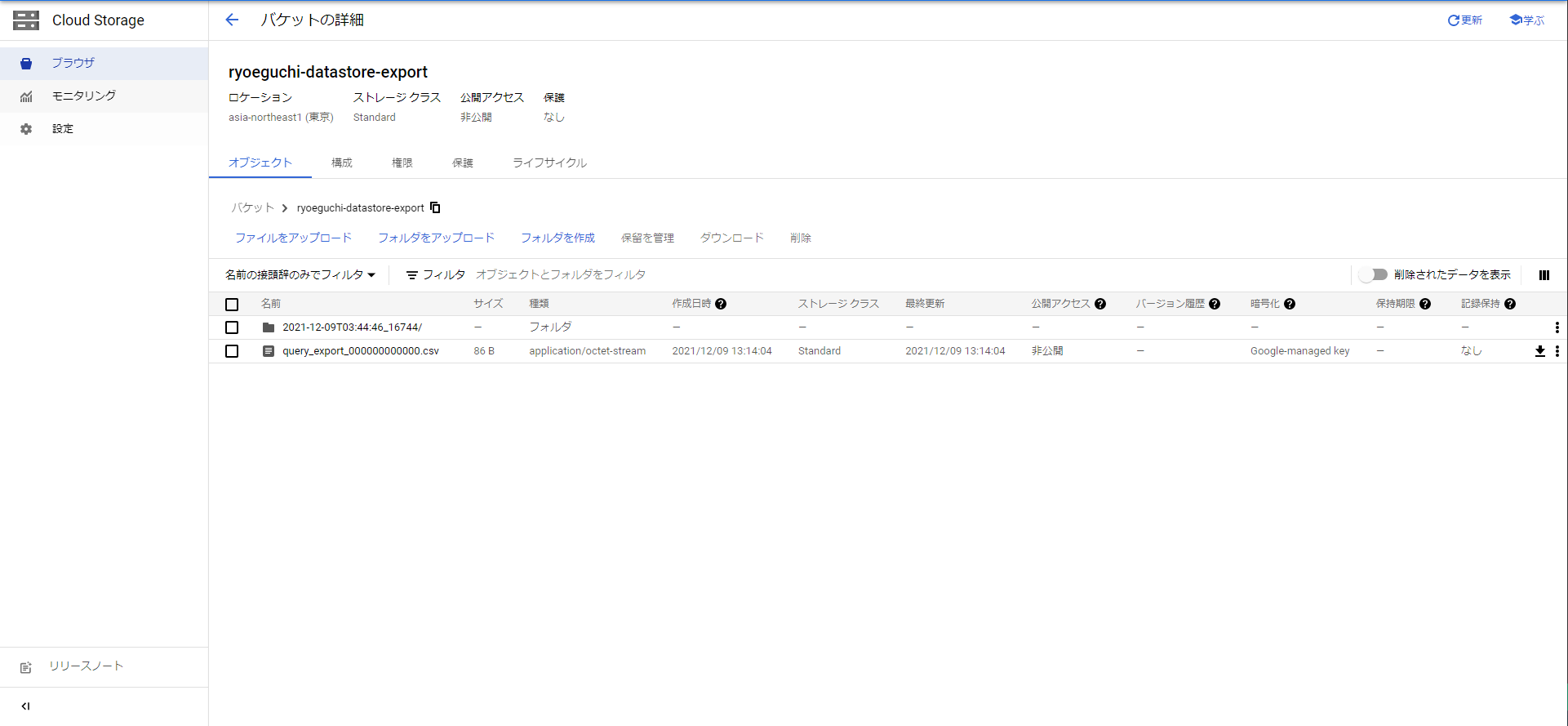
5.クエリ結果をCloudSQLへ投入
gsutilコマンドで、CloudSQLに接続するマシン(GCEインスタンスまたはローカルマシン)に、クエリ結果をコピーします。
gsutil cp gs://ryoeguchi-datastore-export/query_export_*.csv .
CloudSQLに接続し、importを実施します。
sudo mysql -h IP.OF.CLOUD.SQL -u root -p -D datastore_imported
CloudSQLのインポート先テーブルはこのように作りました(bqクエリ結果とカラムの順序の整合を取る必要あり)。
create table table_datastore_import(hoge varchar(255), fuga int, piyo varchar(255));
データが登録されていないテーブルが作成されています。
select * from table_datastore_import;
Empty set (0.002 sec)
load data機能を用いて、CSVファイルを取り込みます。bqの出力時に、区切り文字はカンマ',', ヘッダ出力はtrueにしたので、それに合わせてオプションは設定しています。
load data local infile 'query_export_000000000000.csv' into table table_datastore_import fields terminated by ',' enclosed by '"' ignore 1 lines;
Query OK, 3 rows affected (0.008 sec)
Records: 3 Deleted: 0 Skipped: 0 Warnings: 0
データが投入されていることが確認できました。
select * from table_datastore_import;
+-------------+------+-----------------+
| hoge | fuga | piyo |
+-------------+------+-----------------+
| hello world | 2 | hello datastore |
| text_hoge | 1 | piyopiyo |
| hogehoge | 4 | piyopiyo |
+-------------+------+-----------------+
3 rows in set (0.002 sec)
以上で、DatastoreからCloudSQLへデータをインポートすることができました。
余談
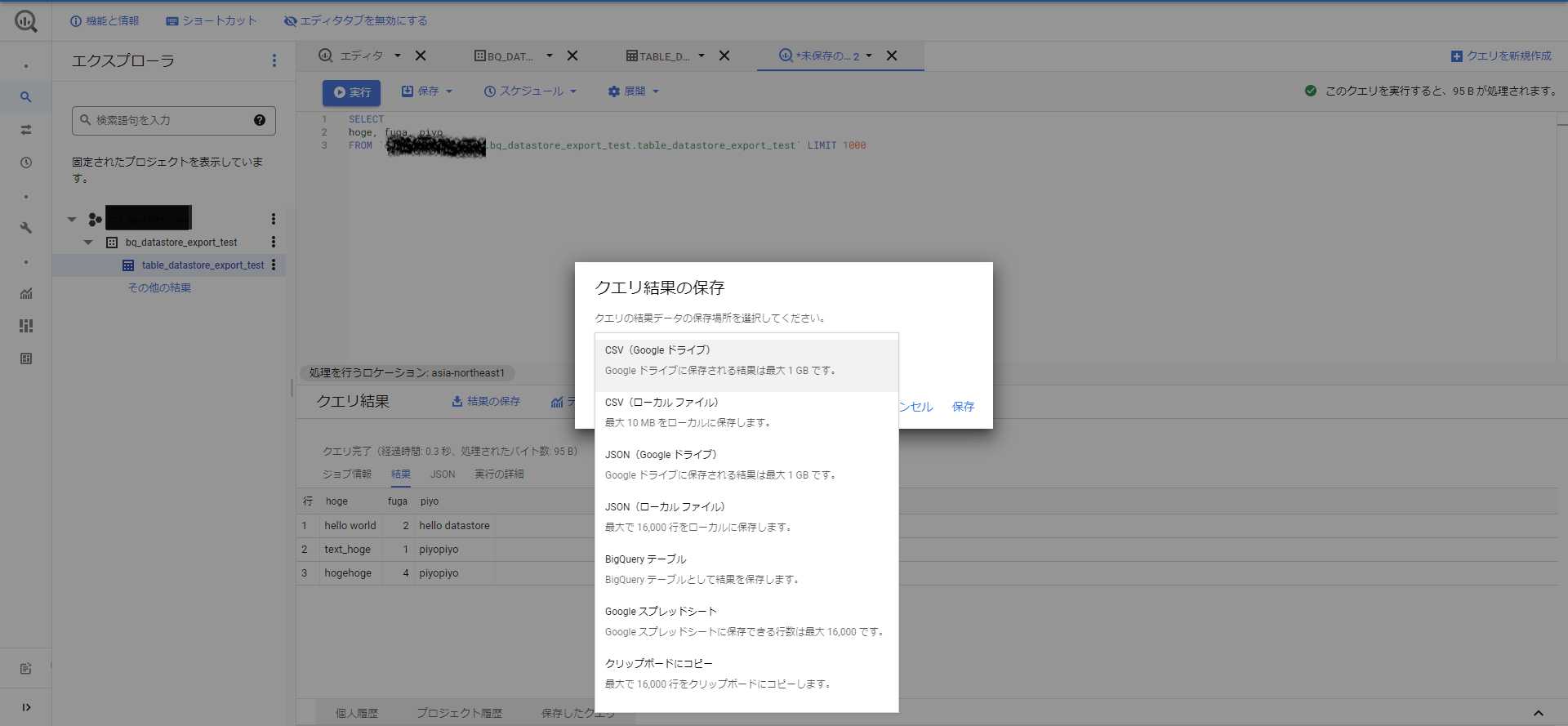
私が過去にこの操作を行った際、コンソール上でクエリ実行結果をローカルに保存してそれを踏み台サーバに送るようにしていました。bqコマンドによりGCSに実行結果を保存するようにすれば、Datastoreに入っている情報をGCPの外(ローカルマシン)に出さずにも出来るようになるため、より安全ですね。
コンソール上でのクエリ結果保存先指定は、クエリ結果の[結果の保存]から実施可能です。