PDFは扱いにくい
PDFファイルをPythonで扱うのは大変です。
表がPDFの中に埋め込まれているケースも割とあります。
例えば
平成30年 全衛連ストレスチェックサービス実施結果報告書の中にはたくさんの表データが埋め込まれています。
例えばファイルの40ページの【表14 業種別高ストレス者の割合】を抜き出したいと思ったとします。
この表を選択して、Excelにコピペしてみましょう。
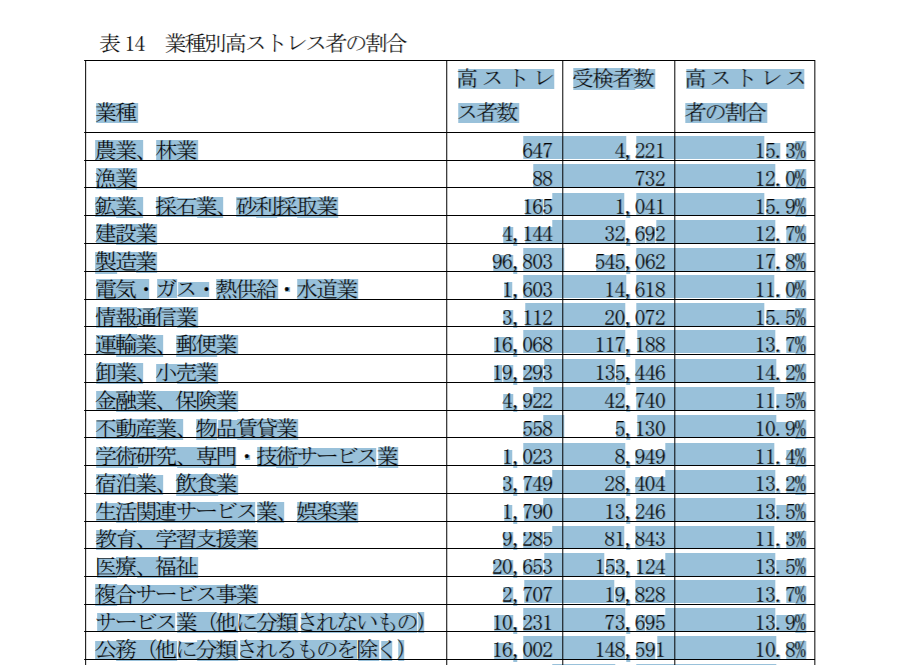
コピーして、Excelに貼り付けます。

おや?うまくいかないですね。
1つのセルの中に、全部のデータが羅列されてしまっています。
実はPythonを使ってこのPDF中の表を比較的簡単にcsvやExcelに変換することができます。
PythonでPDFの表をcsvに
PythonでPDF内の表(テーブル)をcsvやexcelに変換する手順は2ステップです。
ステップ1. PDFから表をpandasのDataFrameとして抜き出す
ステップ2. DataFrameをcsvやexcelとして書き込む
順に見ていきましょう。
ステップ1. PDFから表をpandasのDataFrameとして抜き出す
pdfの表をDataFrameとして抜き出すために、tabulaというモジュールを使います。
tabulaはインストールされていない方も多いと思いますので
pip install tabula-py
でインストールします。
さらにこのtabulaはJavaで動きますので、Javaのインストールも必要です。
tabulaの準備ができたところで、pandasとtabulaをimportしておきます。
import pandas as pd
import tabula
PDFから表を抜き出すには、
tabula.read_pdf("xxx.pdf", lattice=True, pages='xxxx')
という関数を使います。
※補足:tabula.read_pdf("xxx.pdf", lattice=True, pages='xxxx')でエラーになる場合もあるようです。その場合は、tabula.io.read_pdf("xxx.pdf", lattice=True, pages='xxxx')としてみてください。
-
"xxx.pdf"には、読み込みたいPDFファイルのパスを書きます。 -
lattice=Trueはテーブルの罫線でセルを判定するためのオプションです。
抜き出したい表が罫線で区切られているならlattice=Trueを指定しましょう。 -
pagesは読み込みたいページを指定します。 -
40ページ目だけを読み込むなら
pages='40'のように指定します。 -
40~45ページを読み込むなら
pages='40-45'のように指定します。 -
すべてのページを読み込むなら
pages='all'でOKです。 -
関数の戻りとして
pandas.DataFrameのリストが返ります。複数の表があった場合には、このリストをfor文で順に取り出せばよいです。
では、先ほどの『平成30年 全衛連ストレスチェックサービス実施結果報告書』の40ページの表を読み込んでみましょう。
# lattice=Trueでテーブルの軸線でセルを判定
dfs = tabula.read_pdf("平成30年 全衛連ストレスチェックサービス実施結果報告書.pdf", lattice=True, pages = '40')
for df in dfs:
display(df)
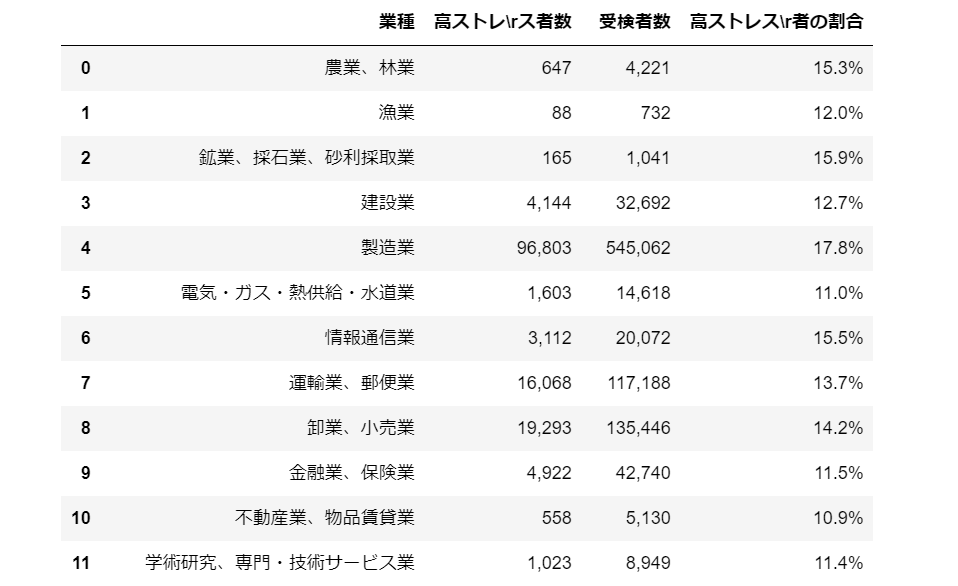
列名がセル内で改行されていたために\rが入ってしまっていて変ですが、表の中身はうまく取り出せていますね。
一応、列名もきちんと直しておきましょう。
df.rename(columns={'元の列名': '変更後の列名'})で列名を変更できます。
複数の列名を変更するときは'元の列名': '変更後の列名'をコンマで区切ってつなげていけばOKです。
df = df.rename(columns={'高ストレ\rス者数': '高ストレス者数', '高ストレス\r者の割合': '高ストレス者の割合'})
ステップ2. DataFrameをcsvやexcelとして書き込む
pandasには元々DataFrameをcsvやExcelとして書き込む機能がついています。
csvとして保存:df.to_csv("ファイル名.csv", index=None)
Excelとして保存:df.to_excel("ファイル名.xlsx", index=None)
※index=NoneはDataFrameのindexを書き込まないようにするためのオプション
まとめ
最後に今回のコードをまとめて記載しておきます。
import pandas as pd
import tabula
# lattice=Trueでテーブルの軸線でセルを判定
dfs = tabula.read_pdf("平成30年 全衛連ストレスチェックサービス実施結果報告書.pdf", lattice=True, pages = '40')
# PDFの表をちゃんと取得できているか確認
for df in dfs:
display(df)
# csv/Excelとして保存(今回はdfs[0]のみ)
df = dfs[0].rename(columns={'高ストレ\rス者数': '高ストレス者数', '高ストレス\r者の割合': '高ストレス者の割合'})
df.to_csv("PDFの表.csv", index=None) # csv
df.to_excel("PDFの表.xlsx", index=None) # Excel
画像扱いのPDFファイルから表を抜き出すには
紙の文書や書籍をスキャンして電子化したPDFの場合、テキストがOCR化されておらず、PDFファイル内の表が画像扱いのままのものもあると思います。
その場合は、下記の記事で紹介した方法をお試しください。
参考
私の書いた他の自動化シリーズはこちらです。ご興味があればどうぞ!
【自動化】PythonでWordの文書を読み取る
https://qiita.com/konitech913/items/c30236bdf47775535e2f
【自動化】Pythonコードをexeファイル化する
https://qiita.com/konitech913/items/6259f13e057bc25ebc23
【自動化】PythonでOutlookメールを送信する
https://qiita.com/konitech913/items/51867dbe24a2a4272bb6
【自動化】PythonでOutlookのメールを読み込む
https://qiita.com/konitech913/items/8a285522b0c118d5f905
【自動化】Pythonでメール(msgファイル)を読み込む
https://qiita.com/konitech913/items/fa0cf66aad27d16258c0
【自動化】Pythonでクリップボードを操作してExcelに表を貼り付ける
https://qiita.com/konitech913/items/83975332e395a387eace