Word文書をPythonで読み取る
契約書や報告書などオフィスでは様々な文書がありますが、主流は【Word文書】かと思います。
業務を自動化するにあたっては、Word文書の作成や読み取りを自動化したいというケースも多そうです。
実際、私も3ヶ月ごとに作成する委託契約書の作成をPythonで自動化しています。
本記事では、python-docxというライブラリを使ってPythonでWord文書を読み取る方法を解説します。
(次回はWord文書の作成や置換についてご紹介します。)
Word文書の読み取り
python-docxは標準ライブラリではありません。Anacondaでもデフォルトでは入っていないのでまずインストールしましょう。
pip install python-docx
インストールが終わったらライブラリをimportします。
importのときはpython-docxではなくdocxなので注意してください。
import docx
次にWord文書を読み込んでオブジェクトを作成します。
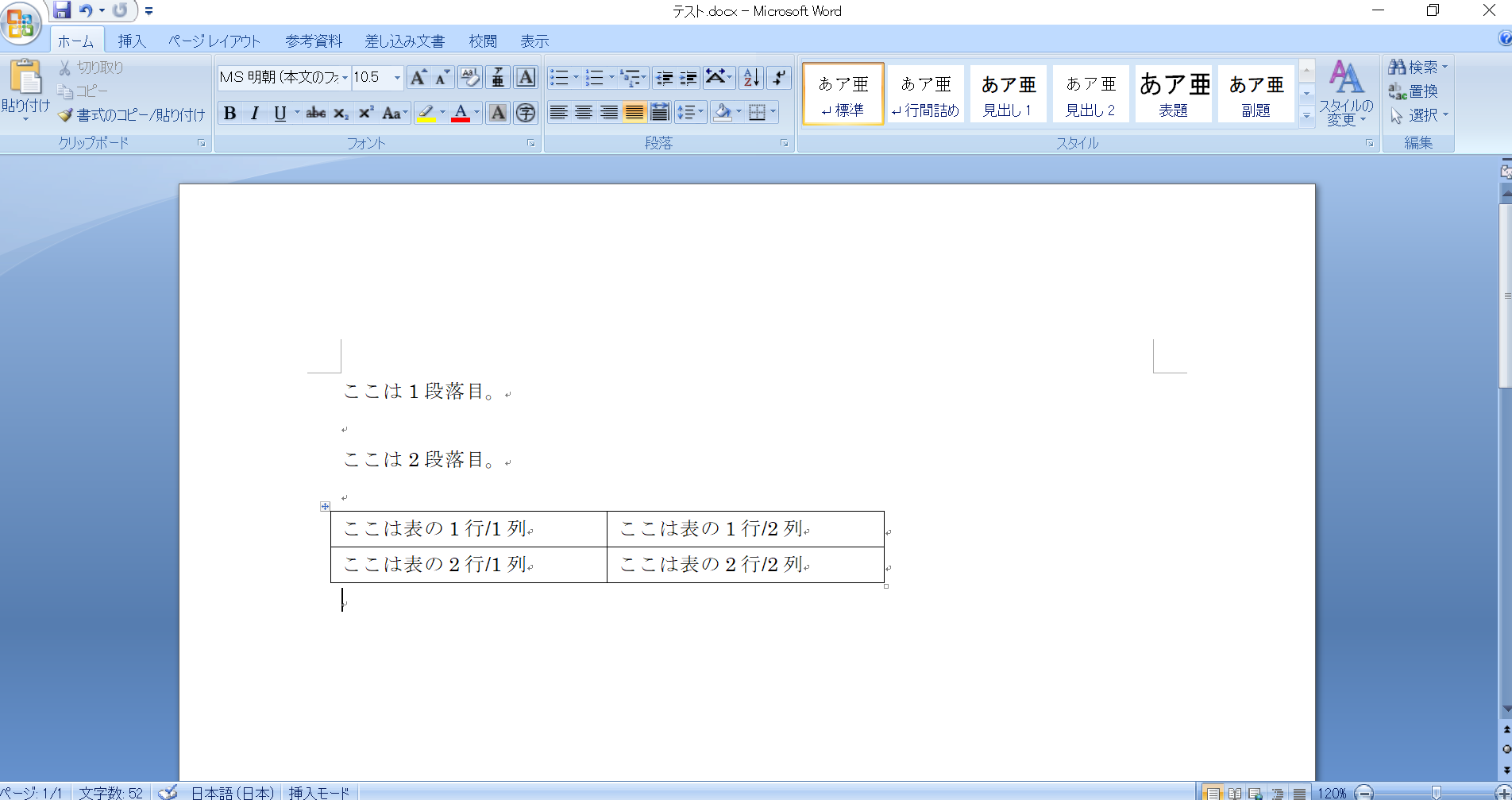
ここでは「テスト.docx」という下記のような文書を読み込みます。
document = docx.Document("テスト.docx")
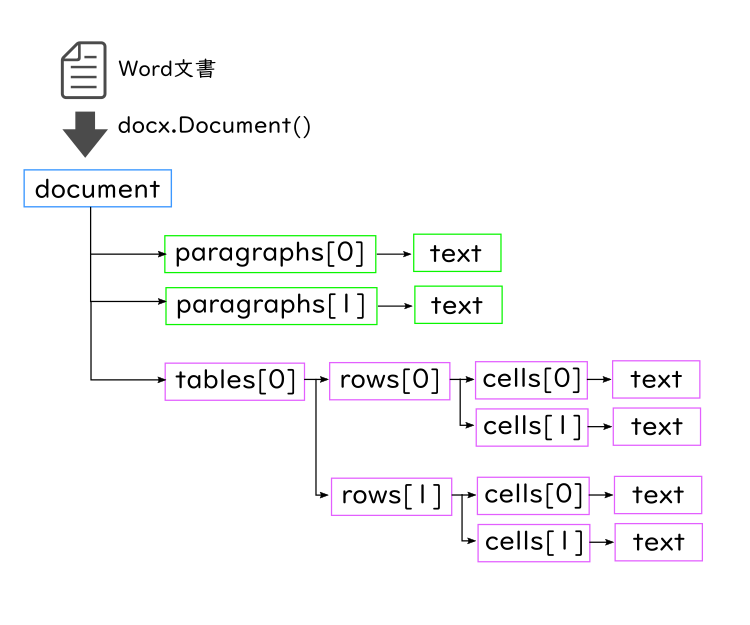
このdocumentオブジェクトはparagraphsというリストと、tablesというリストを持ちます。
paragraphsは本文中の段落のことで、tablesは表のことです。
tablesは行をrowsのリストとして持ち、さらにrowsは列(セル)をcellsというリストとして持っています。
テキストを取得したい場合は、textという属性を参照します。
つまり、このような構造になります。
for paragraph in word.paragraphs:
print(paragraph.text)
ここは1段落目。
ここは2段落目。
for table in document.tables:
for row in table.rows:
for cell in row.cells:
print(cell.text)
ここは表の1行/1列
ここは表の1行/2列
ここは表の2行/1列
ここは表の2行/2列
注意点
残念ながら、python-docxでは脚注を読み取ることはできません。
※少なくとも、私はいくら調べても脚注を操作する方法がわかりませんでした。もし、何か情報をお持ちならコメントいただけると幸いです。
脚注も含めて操作したい場合には、別の方法を検討する必要がありそうです。