画像から表を抜き出したい
画像ファイルの中の表をテーブルデータとして抜き出したいことがあります。
例えば、「紙の書籍や文書をスキャンして、画像ファイルやPDFファイルとして電子化」した場合です。
(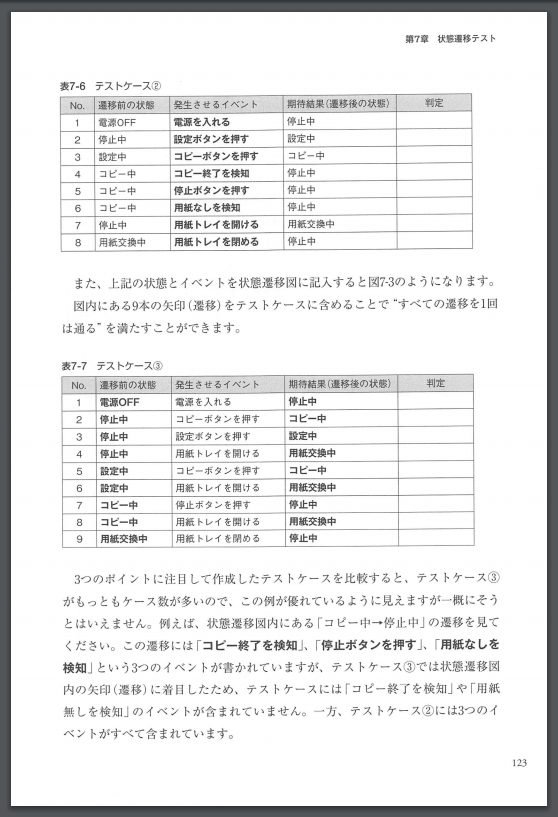
この中の表はOCR処理されていない単なる画像なので、表どころか文字としても認識されていません。
ですので、当然、このままでは表データとして扱うことはできません。
では、潔く諦めて地道に手打ちでデータを表にしていくしかないのでしょうか…?
いいえ、諦める必要はありません!
画像から表データを抜き出す方法
実は、このような画像(jpg, png, pdfなど)からでも、次のステップで表をデータとして抜き出すことができます。
事前準備. Microsoft OneDriveにアカウント登録する(無料)
0. 画像ファイル(jpg,pngなど)の場合は、pdfファイルに変換する(最初からPDFの場合はこの手順は不要)
- PDFファイルをOneDriveに保存し、Wordに変換してOCR処理をかける
- OCR処理済のWordをPDFとして保存する
- PDF内の表をPythonで抜き出す
途中でWordを使いますが、無料のOfficeオンラインを使うので、PCにMicrosoft Wordがインストールされてなくても大丈夫です。
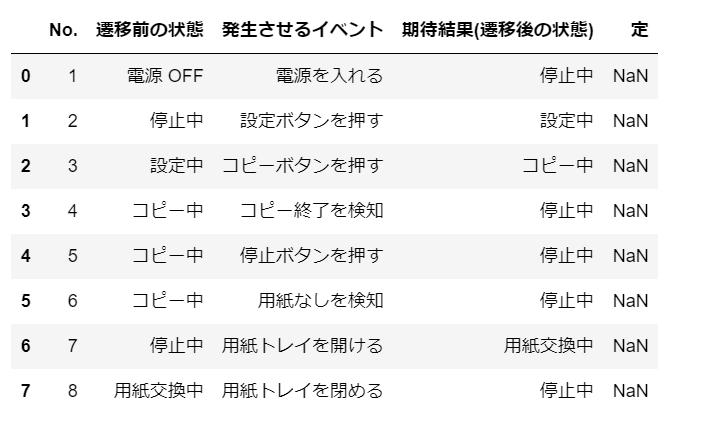
では、今回は↓のPDFファイルを使って説明していきます。
(
画像ファイル(jpg,pngなど)から表を抜き出したい場合は、まずPDFファイルに変換しておきましょう。
画像ファイルをPDFに変換する無料Webサービスもありますが、簡単なのは【画像ファイルを右クリック→印刷→プリンターで「Microcoft Print to PDF」を選択して印刷】でOKです。
事前準備. OneDriveにアカウント登録
Microsoft OneDriveにアカウントを登録しておきます。無料です。
[Microsoft アカウントを取得しよう]
(https://www.microsoft.com/ja-jp/office/homeuse/onedrive-guide.aspx)
1. PDFファイルをOneDriveに保存
対象のPDFファイルをOneDriveにアップロードします。
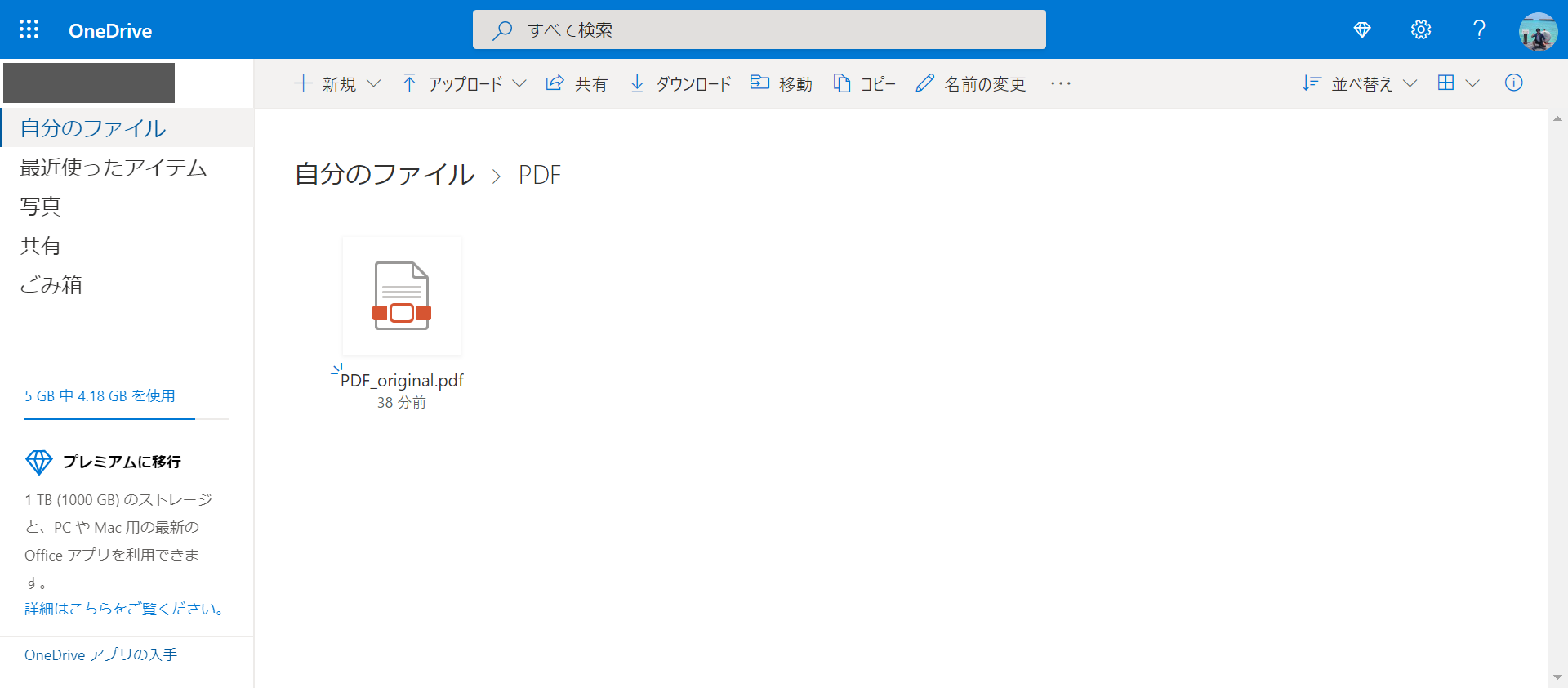
ファイルを右クリックして、「開く」を選択します。
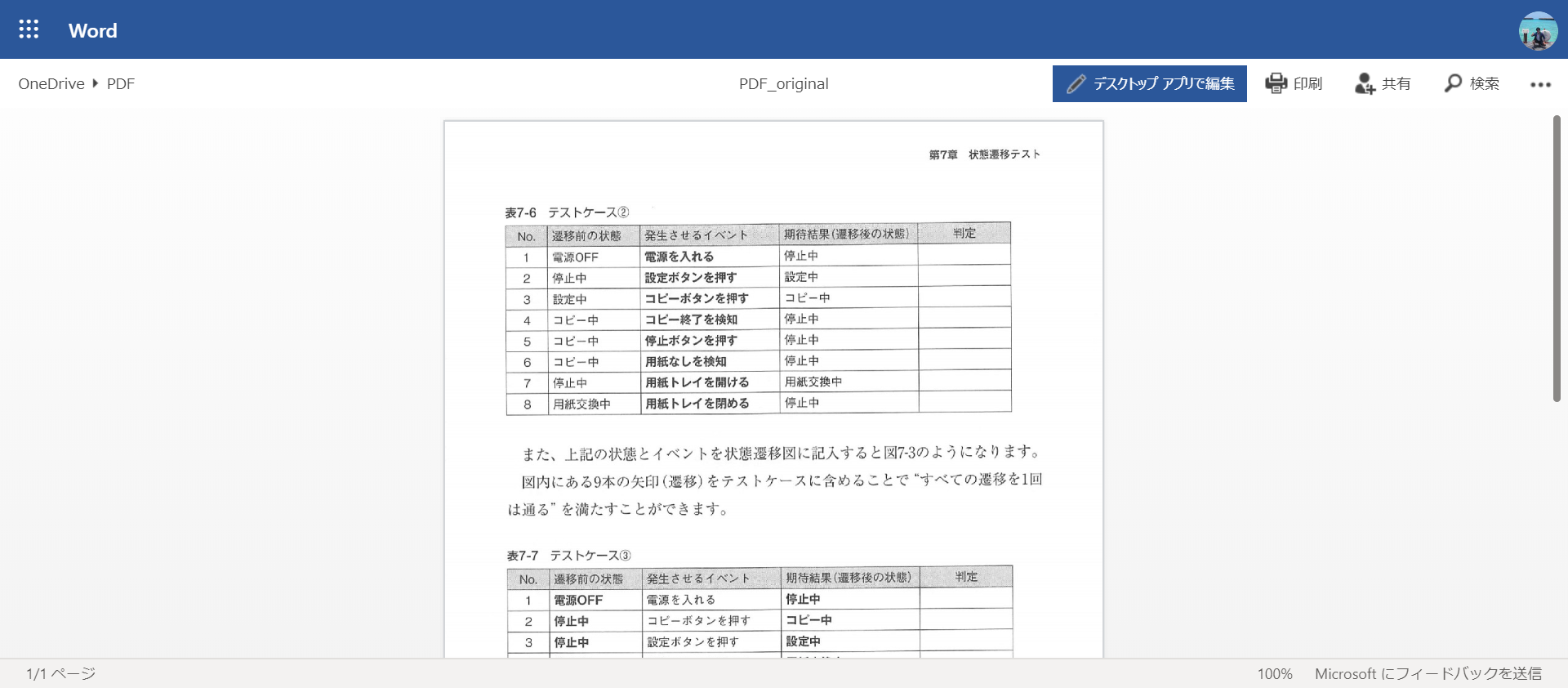
この時点で、表のあたりを選択してみると、文字をテキストとして選択できるようになっています。表構造も認識されています。
「デスクトップ アプリで編集」ボタンを押します。すると、ファイル変換するかどうか聞かれるので「変換」ボタンを押します。
すると、変換が行われます。変換が終わると確認画面になるので、「編集」を押しましょう。
すると、ブラウザ上でWordが開きます。きちんと表データとして変換されていますね。
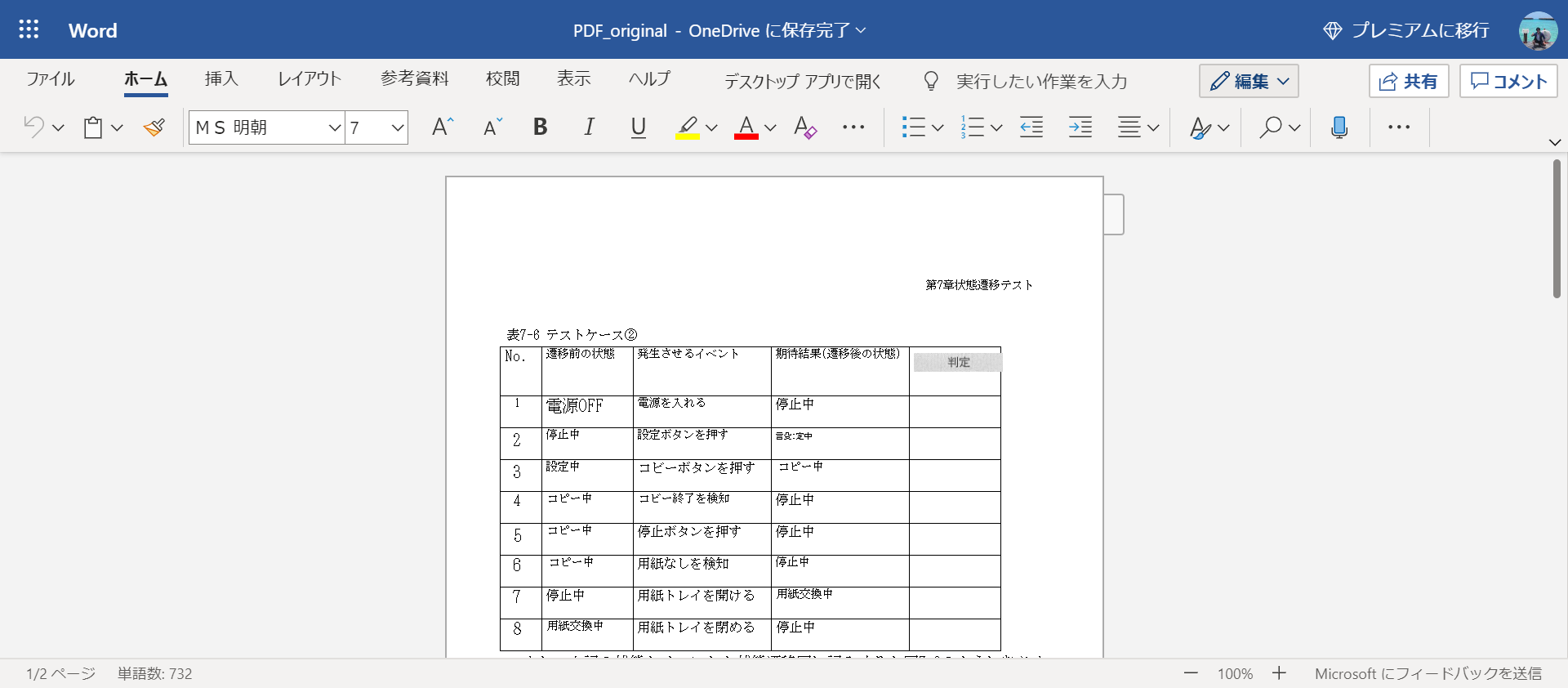
文字が正しく認識されていないところも多少あるかもしれないので、この時点で直せるところは手作業で直してしまいましょう。
この場合、「コピー」が「コビー」になっていたりしますが、ほぼ正しく変換できています。なかなかの認識精度です!
2.OCR処理済のWordをPDFとして保存する
WordファイルよりもPDFファイルの方が表をPythonで扱いやすいので、PDFに変換してダウンロードします。
左上の「ファイル」を選択し、名前を付けて保存→PDFとしてダウンロードを選択します。
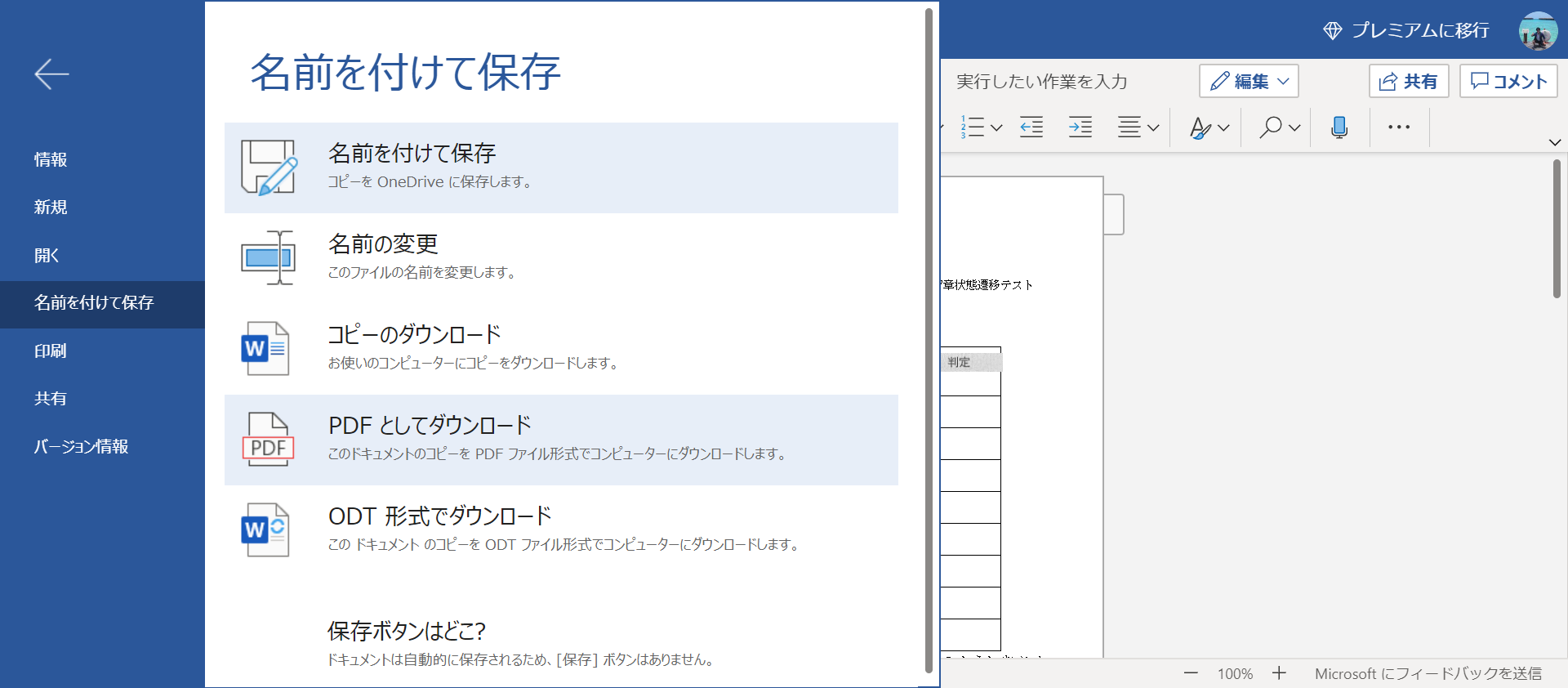
3.PDF内の表をPythonで抜き出す
ダウンロードしたPDFファイルを開いてみましょう。
元のPDFとは違って、きちんと表が表として認識されていますね。
フォントが大きかったり小さかったりして見てくれは悪いですが、pandasのDataFrameとして抜き出してしまうので気にしなくていいです。
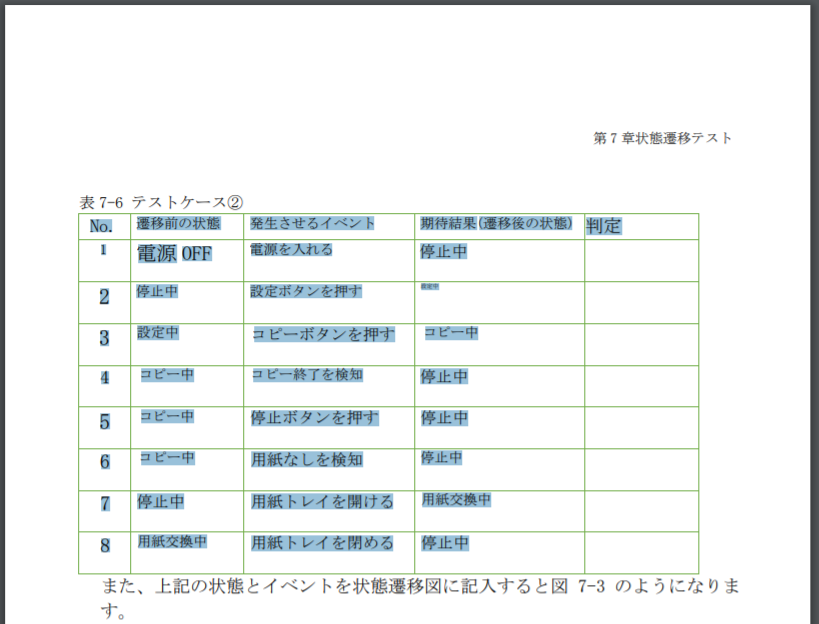
さて、ここまで来たら、あとは『PDF内の表をPythonで抜き出す』の記事で紹介した方法でPythonを使って簡単に表を抜き出せます。
import pandas as pd
import tabula
# lattice=Trueでテーブルの軸線でセルを判定
dfs = tabula.read_pdf("PDF_ocr.pdf", lattice=True, pages='1')
for df in dfs:
display(df)
実行結果