web漫画の更新を掲載をまとめているサイトはあるものの通知などを行っている所がなかったため作ってみました。(自分の読んでいる漫画のみ)
作るにあたって苦労した点を中心に書いていこうと思います。
全体構成

Cloud Functions | Pub/Sub
公式ドキュメントを参考に設定していきます。
料金プランをBlazeプランにアップグレードし、プロジェクトで Google Cloud Pub/Sub と Cloud Scheduler API を有効にします。
設定ができたら実行したい関数に、1時間毎の場合下記のように記述します。
exports.scrapeWebComic = functions.pubsub
.schedule("every 1 hours")
.timeZone("Asia/Tokyo")
.onRun(async (context) => {
console.log('This will be run every 1 hours!');
return null;
}
スクレイピング
※各web漫画のページのデータを取得するコードを書くのはかなり骨が折れるので、web漫画の更新をまとめている某サイト様に条件付きで許可をいただきデータ取得を行わせていただいてます。
スクレイピングはpuppeteerで行います。
puppeteerをCloud Functionsで使う際に2つほどエラーと遭遇したのでその内容と解決方法を説明していきます。
puppeteer ver3.0.0以降で起こるエラー
puppeteer 3.0.0以上ではlibgbm1をインストールする必要があります。
こちらのissueで話されているように、今はver3未満を使うことで解決できます。
{
"dependencies": {
"puppeteer": "^2.1.1"
}
}
Error: memory limit exceeded. Function invocation was interrupted.
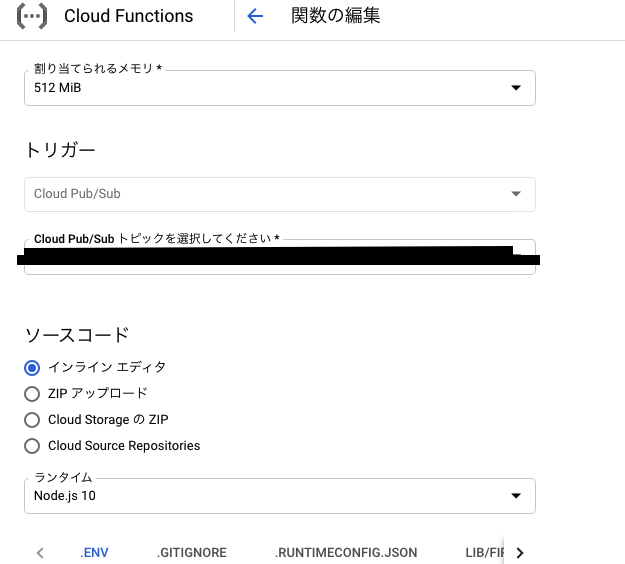
メモリ制限を超えたため、関数の呼び出しを停止した。というエラーなのでCloud Funcstionsから使用メモリを変更することで解決します。
GCPのCloud Functionsから対象の関数を選び編集から割り当てられるメモリを256Mibから512Mibに設定します。
Firestore
データモデルの構成
| ドキュメント | 場所 | 管理するコレクション |
|---|---|---|
| comics | データベースのルート | comicsコレクション |
| episodes | comicsドキュメントの配下 | episodesコレクション |
実際にはこのような構成なります。

データモデルが決まったので、データ追加時の処理について説明していきます。
スクレイピングで取得した配列データを、mapで処理しています。
await Promise.all(data.map(async (d) => await setFirestore(d)));
const setFirestore = async (data: ComicData) => {
const episodeRef = fireStore
.collection("comics")
.doc(data.titleData.name)
.collection("episodes")
.doc(data.nameNonSlash.episode);
// 取得したデータをgetで取得しに行きます
episodeRef
.get()
.then(async (doc: any) => {
// Firestoreにデータがなかった場合(新規データ)だった場合の処理
if (!doc.exists) {
// firestoreに保存
await episodeRef.set(data.episodeData);
}
})
.catch((err: any) => {
console.log("Error getting document", err);
});
};
ここで注意点ですが、Firestoreのドキュメントにはスラッシュ(/)を含むことができないので、取得したデータのスラッシュを置換する必要があります。
今回はスラッシュをハイフンにすることにします。
comicEpisodeNonSlash = comicEpisodeEn.replace(/\//g, "-");
余談ですがスラッシュを含む文字列をFirestoreの関数の引数に渡すこともできますが以下のような動作なります。
//以下2つは同義
let alovelaceDocumentRef = db.collection('users').doc('alovelace');
let alovelaceDocumentRef = db.doc('users/alovelace');
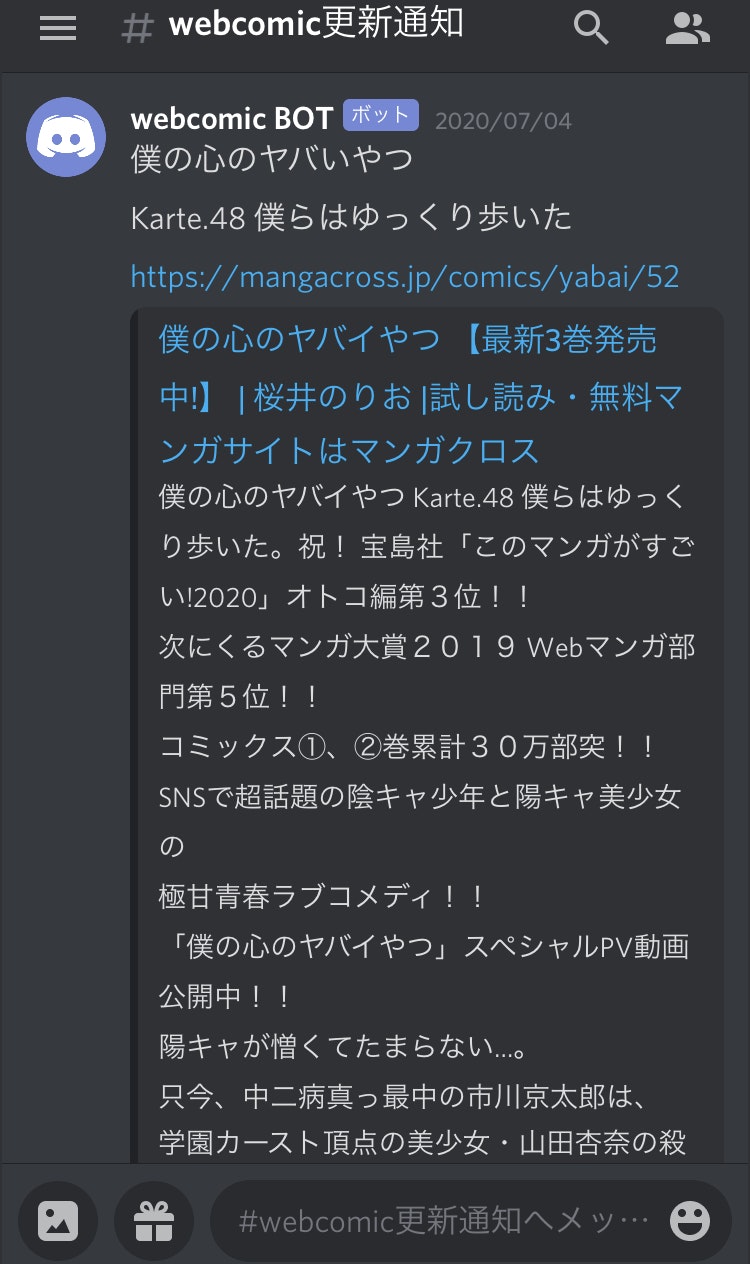
webhookでDiscordに通知
Discordのチャンネル設定からwebhookを作成しwebhookURLを取得します。
後は新規データ追加時に、通知したいデータを入れてaxiosでPOSTするだけです。
const discord_url = functions.config().discord.webhook;
const config = {
headers: {
Accept: "application/json",
"Content-type": "application/json",
},
};
episodeRef
.get()
.then(async (doc: any) => {
if (!doc.exists) {
//送信するデータ
const postData = {
username: "webcomic BOT",
content: `${data.titleData.name}\n${data.episodeData.name}\n${data.episodeData.url}`,
};
// web hookでdiscordに通知
await axios.post(discord_url, postData, config);
// firestoreに保存
await episodeRef.set(data.episodeData);
}
})
Discord BOT等で検索しても対話型のBOTばかりヒットするのでwebhookにたどり着くまでが大変でした。
 ## 終わりに
## 終わりに
ざっくりと説明しましたがコードはこちらになります。
私の読んでいる漫画のみの通知ですがもし入りたい方がいればdiscord
参考リンク
https://qiita.com/kboy/items/47393940a9c8b16278dc
https://github.com/puppeteer/puppeteer/issues/5674
https://github.com/yamam00s/scraping-baseball-data/issues/4