やること
どうやらAWSのsagemaker jump startで今流行りの stable diffusion のファインチューニングができるようなので、うちの猫(テトちゃん)の画像を10枚程度使って,"a photo of a Teto cat with a hat"のようなプロンプトで現実では絶対できない(テトちゃんは帽子嫌いなので)画像を作ってみる。
今日の目標はとりあえずファインチューニングが目標なので、出来栄えはあまり気にしてないです。
参考資料
たった数枚の画像で Stable Diffusion をファインチューニングできる効率的な Amazon SageMaker JumpStart の使い方
記事の対象者
・stable diffusionをawsで簡単に試してみたい人
・stable diffusionの学習をsagemakerの学習インスタンスを使ってコストを抑えたい人
・sagemakerの勉強したい人
・非エンジニアの方にはあまりおすすめしない。(インスタンスのことなどAWSのことを何も知らずになんとなくで使ってるとエンドポイントの止め忘れとかでクラウド破産するかもしれないので。)
sagemaker jumpstartのstable diffusionのファインチューニングの要点
・Stable Diffusion モデルを使用する場合、CreativeML Open RAIL++-M ライセンスに同意する必要がある
・baseとなるモデルは Stable Diffusion 2.1 ベースモデル。
・sagemaker jumpstartではDreamBoothの手法に沿った学習スクリプトを提供している
・5枚程度~の画像でファインチューニング可能。
・複数の被写体でのファインチューニングはできない。(例:"Teto Cat"と"Taro Cat" 二匹のファインチューニングを同時に実行できない。)
・上記の二匹の猫を順次学習させた場合でも、被写体が類似している場合、モデルが最初の被写体を忘れてしまうという問題がある。
・jumpstartなので、学習用スクリプト、docker image,事前学習済みモデルは用意されていて、必要なのは学習用画像だけ。
・Prior preservationと言う手法も使える。
・ファインチューニングはsagemaker のtrainingjobで学習を行うので、使った分だけ課金されるから無駄がない
・モデルを使う時はエンドポイントにデプロイして使うようになっているので、使ってなくても時間で課金されるので注意が必要。エンドポイントのデフォルトのインスタンスがml.p3.2xlarge(1時間あたり5.242USD(2023年5月東京リージョンの価格)となっているので、1つのエンドポイントを1ヶ月消し忘れただけで約3774ドルほどぶっ飛ぶことになる( ◠‿◠ )。もし10個のエンドポイントを消し忘れていたら( ◠‿◠ )
・sagemaker studioのノートブックインスタンスも高くはないが時間で課金されるので、使い終わったら止めるのを忘れないようにする(良く忘れる)
用語
sagemaker jumpstartとは
機械学習 (ML) のハブとして、基盤モデル、組み込みアルゴリズム、および数回のクリックでデプロイできる事前構築済みの機械学習ソリューション
つまり、数クリックで、機械学習のトレーニングからデプロイまでできてしまうとのこと
DreamBoothとは
3~5枚程度の同じ対象(同じ犬や人)の画像で、テキストから画像を生成するモデルをファインチューニングすることができるフレームワーク
参考
dreambooth
Prior preservation
Prior preservation とは、学習しようとするクラスと同じ画像を追加で使用する手法。例えば、学習データが特定の犬の画像で構成されている場合、Prior preservation では、一般的な犬のクラス画像を取り込む。
ファインチューニングの手順
実際にsagemaker jumpstartを使ってstable diffusionのファインチューニングをやってみる
AWS sagemaker jumpstartからstable diffusionを開く
sagemaker studioを開いて右のホームタブからsagemakerjumpstart > Models,notebooks,solutions > stable Diffusion 2.1baseを選択。
ノートブックを開く
open notebookという右上の方にあると思うので、押下する。
そうすると、model-txt2img-stabilityai-stable-diffusion-v2-1-base-SDK.ipynbというnotebookがDemoNotebooksに保存される。
ノートブックのset upコードを実行する
1章のpip installやimportを行っている、set upコードを実行する
!pip install ipywidgets==7.0.0 --quiet
!pip install --upgrade sagemaker
import sagemaker, boto3, json
from sagemaker import get_execution_role
aws_role = get_execution_role()
aws_region = boto3.Session().region_name
sess = sagemaker.Session()
notebookの2章 Run inference on the pre-trained modelは既に学習済みのモデルのデプロイなのでスキップして、3章のFine-tune the pre-trained model on a custom datasetまでスクロールする
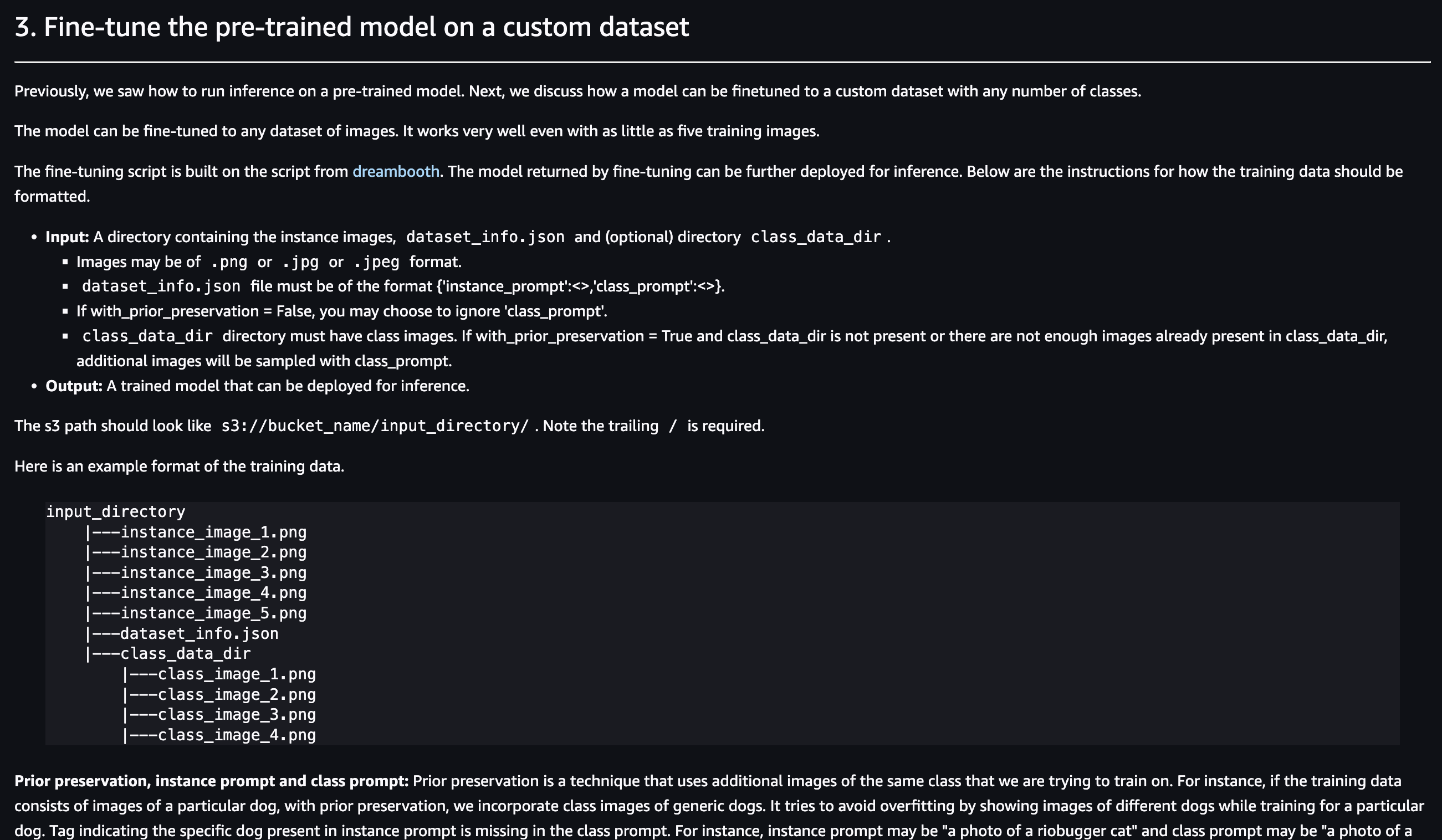
学習用データを用意する。
notebookに書いてるように、s3://bucket_name/input_directory/下に
input_directory
|---instance_image_1.png
|---instance_image_2.png
|---instance_image_3.png
|---instance_image_4.png
|---instance_image_5.png
|---dataset_info.json
の形式で画像とjsonファイルをs3に保存する。
今回はPrior preservationしないので、class_data_dirは作成しない。
instance_imageとしてうちの猫ちゃんを10枚ほど保存した。
画像の形式はjpeg,jpg,pngは使用可能。

dataset_info.jsonは
{'instance_prompt':<>} という形式にする必要があるそうなので
{"instance_prompt":"A photo of a Teto cat"}
とした。
注意 画像のサイズについて
stable diffusionは画像のサイズは512 * 512にリサイズされるので 画像サイズは512以上あればなんでも良さそうだが、学習画像の画像は全て同じ画像サイズに揃える必要があった。
画像サイズがばらばらの画像で学習させてみると、学習の実行完了まではうまくいくが、upload処理時に下記エラーが発生。
RuntimeError: stack expects each tensor to be equal size, but got [3, 4032, 3024] at entry 0 and [3, 3024, 4032] at entry 3
これはawsが用意しているtrainスクリプトの問題。
学習データを保存したs3パスを指定する
import sagemaker.metric_definitions
# Sample training data is available in this bucket
#training_data_bucket = f"jumpstart-cache-prod-{aws_region}"
#training_data_prefix = "training-datasets/dogs_sd_finetuning/"
#うちの猫ちゃん
training_data_bucket = {my_bucket}
training_data_prefix = {my_prefix}
training_dataset_s3_path = f"s3://{training_data_bucket}/{training_data_prefix}"
output_bucket = sess.default_bucket()
output_prefix = "jumpstart-example-sd-training"
# Retrieve the default metric definitions to emit to CloudWatch Logs\n",
metric_definitions = sagemaker.metric_definitions.retrieve_default(
model_id=train_model_id, model_version=train_model_version,
)
s3_output_location = f"s3://{output_bucket}/{output_prefix}/output"
print("output_bucket",output_bucket)
print("s3_output_location",s3_output_location)
spotインスタンスの設定をする
from sagemaker.estimator import Estimator
from sagemaker.utils import name_from_base
from sagemaker.tuner import HyperparameterTuner
training_job_name = name_from_base(f"jumpstart-example-{train_model_id}-transfer-learning")
# Create SageMaker Estimator instance
sd_estimator = Estimator(
role=aws_role,
image_uri=train_image_uri,
source_dir=train_source_uri,
model_uri=train_model_uri,
entry_point="transfer_learning.py", # Entry-point file in source_dir and present in train_source_uri.
instance_count=1,
instance_type=training_instance_type,
max_run=360000,
use_spot_instances=True, # スポットインスタンスを使う、という宣言
max_wait=360000,#max_runと同じか大きな値にしなければならない
metric_definitions=metric_definitions,
hyperparameters=hyperparameters,
output_path=s3_output_location,
base_job_name=training_job_name,
)
if use_amt:
# Let estimator emit fid_score metric to AMT
sd_estimator.set_hyperparameters(compute_fid="True")
tuner_parameters = {
"estimator": sd_estimator,
"metric_definitions": [{"Name": "fid_score", "Regex": "fid_score=([-+]?\\d\\.?\\d*)"}],
"objective_metric_name": "fid_score",
"objective_type": "Minimize",
"hyperparameter_ranges": hyperparameter_ranges,
#"max_jobs": 3,
"max_jobs": 1,
#"max_parallel_jobs": 3,
"max_parallel_jobs": 1,
"strategy": "Bayesian",
"base_tuning_job_name": training_job_name,
}
tuner = HyperparameterTuner(**tuner_parameters)
tuner.fit({"training": training_dataset_s3_path}, logs=True)
else:
# Launch a SageMaker Training job by passing s3 path of the training data
sd_estimator.fit({"training": training_dataset_s3_path}, logs=True)
コストを抑えたかったので、spotインスタンスの設定をした。
Spotインスタンスを使用することで最大70%の学習インスタンスのコスト削減ができる。
Estimatorクラスの引数に、下記を追加する
use_spot_instances=True
max_wait=360000
また、今回はとりあえずファインチューニングを動かすことが目的なので、tuner_parametersの
"max_jobs"と"maz_parallel_jobs"を1に変更しておく。
インスタンスの上限緩和申請を行う。
学習用のgpuインスタンスはawsサポートにて上限緩和申請を行わないと使えない。
今回のstable diffusionでは、デフォルトではml.g4dn.8xlargeを使用するようになってるので、このインスタンスの上限緩和申請を行う。
申請内容は下記のようにした。
'''''''''''''''
サービス: SageMaker Training Jobs
リージョン: US East (Northern Virginia)
リソースタイプ: SageMaker Managed Spot Training
制限の名前: ml.g4dn.8xlarge
上限値: 1
'''''''''''''''
注意点はspotインスタンスを使うため、リソースタイプをSageMaker Managed Spot Trainingを選択する必要があること。逆にspotインスタンスを使わない場合はリソースタイプをSagemaker Trainingにする
また、デフォルトのノートブックのではちゃんとhyperparametersチューニングを行なっていて、"max_jobs"と"maz_parallel_jobs"は3となっているので、そのまま動かしたい場合は上限値を3にする必要がある。
リージョンはUS East (Northern Virginia)の方が東京より,ml.g4dn.8xlargeのコストが安いので、US Eastを選択。
東京リージョン:5.242USD(2023/05)
アメリカ・ノースバージニアリージョン:3.673USD(2023/05)
上限緩和申請の方法はこちらを参照してください。
【EC2】GPUインスタンスの上限緩和リクエスト
実際にファインチューニングのノートブックを実行していく。
3.4. Start Trainingのセルまで順番に実行していく。
Start Trainingのセルを実行したら、学習が実行されたかを確認する。
AWSコンソールのsagemakerの画面からトレーニング > トレーニングジョブで学習の実行状況を確認できます。
今回は10枚の画像を使って学習させたところ、学習にかかった時間は約2000秒。
spotインスタンスを使っていたので、1248秒が請求対象の時間となっていました。(38%しか節約できてない・・)
エンドポイントにモデルをデプロイする。
3.5. Deploy and run inference on the fine-tuned modelのセルを実行します。
だいたい、エンドポイントの作成に5分 ~ 10分くらいかかります。
inference_instance_type = instance_types.retrieve_default(
region=None,
model_id=train_model_id,
model_version=train_model_version,
scope="inference"
)
# Retrieve the inference docker container uri
deploy_image_uri = image_uris.retrieve(
region=None,
framework=None, # automatically inferred from model_id
image_scope="inference",
model_id=train_model_id,
model_version=train_model_version,
instance_type=inference_instance_type,
)
endpoint_name = name_from_base(f"jumpstart-example-FT-{train_model_id}-")
# Use the estimator from the previous step to deploy to a SageMaker endpoint
finetuned_predictor = (tuner if use_amt else sd_estimator).deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
image_uri=deploy_image_uri,
endpoint_name=endpoint_name,
)
実際にpromptを書いて画像を生成してみる。
お楽しみの画像生成タイム。
うまくできているのか試していきます。
下記のコードのtext引数を好きに変えて色々試していきます。
text = "a photo of a Teto cat with a hat"
query_response = query(finetuned_predictor, text)
img, prmpt = parse_response(query_response)
display_img_and_prompt(img, prmpt)
a photo of a Teto cat with a hat

うちの子じゃない・・
うまく学習行ってませんね。。
a photo of a Teto cat

同じ猫の種類だけど、同じ猫とは言えない感じ。。
a photo of a Hoge cat

全く関係ない名前でも試してみた。
うん、知らない方ですね。
お片付け
# Delete the SageMaker endpoint
finetuned_predictor.delete_model()
finetuned_predictor.delete_endpoint()
エンドポイントとモデルを削除する。
忘れるとクラウド破産しがち。
まとめ
とりあえずsagemaker jumpstartを使ってのstbale diffusionのファインチューニングを一通りやってみました。
jump startの名の通り、コードをガリガリ書かずにデータを集めるだけで簡単に使えるのはいいですね。
けど、簡単な猫の学習もhyperparametersチューニングなしでは難しかったので、精度を求めるなら細かいチューニングは必要そう。(個人で遊ぶには安くはない出費になりそう。。)
もっと aws sagemaker jumpstartで遊んでいきたいと思います。