TL;DR
Kaggleの"Hello world!"的位置付けのコンペである "Titanic: Machine Learning from Disaster" に、Python機械学習で定番のpandasやscikit-learnといったライブラリを使わず、PySparkのみでSubmissionまでしてみようというもの。
実行環境
- macOS X Catalina 10.15.6
- Jupyter Lab : 2.2.8
- Spark : 2.4.4
ライブラリの読み込み
import os, sys
import datetime
import numpy as np
import warnings
warnings.simplefilter('ignore')
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import IntegerType
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer, VectorIndexer
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.tuning import ParamGridBuilder, TrainValidationSplit
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
SparkSessionインスタンスの生成
SparkSessionインスタンスを生成する。環境変数SPARK_HOMEは事前に設定しておく。
Py4jのバージョンは環境に合わせて適宜読み替える。
spark_home = os.environ.get('SPARK_HOME', None)
sys.path.insert(0, spark_home + '/python')
sys.path.insert(0, os.path.join(spark_home, 'python/lib/py4j-<version>-src.zip'))
spark = SparkSession.builder.appName('Titanic').getOrCreate()
データの読み込み・前処理
Kaggle のページからダウンロードしたデータを PySpark の DataFrameに読み込む。
header=Trueで先頭行をヘッダーとして読み込む。inferSchema=Trueでデータ型をよしなに推定してくれる。
train = spark.read.csv('data/train.csv', header=True, inferSchema=True)
test = spark.read.csv('data/test.csv', header=True, inferSchema=True)
trainの各フィールドのデータ型を確認する。数値データがintやdoubleとして認識されている。
train.dtypes
[('PassengerId', 'int'),
('Survived', 'int'),
('Pclass', 'int'),
('Name', 'string'),
('Sex', 'string'),
('Age', 'double'),
('SibSp', 'int'),
('Parch', 'int'),
('Ticket', 'string'),
('Fare', 'double'),
('Cabin', 'string'),
('Embarked', 'string')]
train, testそれぞれのデータサイズを確認する。(pandasの.shapeのようなものは用意されていない。多分)
print(train.count(), len(train.columns))
print(test.count(), len(test.columns))
891 12
418 11
pandasの.describe()にあたる関数がPySparkにも用意されている。データ型がString型のフィールドも平均や標準偏差はnullとなって表示される。(pandasでは省略される)
train.describe().show()
+-------+-----------------+-------------------+------------------+--------------------+------+------------------+------------------+-------------------+------------------+-----------------+-----+--------+
|summary| PassengerId| Survived| Pclass| Name| Sex| Age| SibSp| Parch| Ticket| Fare|Cabin|Embarked|
+-------+-----------------+-------------------+------------------+--------------------+------+------------------+------------------+-------------------+------------------+-----------------+-----+--------+
| count| 891| 891| 891| 891| 891| 714| 891| 891| 891| 891| 204| 889|
| mean| 446.0| 0.3838383838383838| 2.308641975308642| null| null| 29.69911764705882|0.5230078563411896|0.38159371492704824|260318.54916792738| 32.2042079685746| null| null|
| stddev|257.3538420152301|0.48659245426485753|0.8360712409770491| null| null|14.526497332334035|1.1027434322934315| 0.8060572211299488|471609.26868834975|49.69342859718089| null| null|
| min| 1| 0| 1|"Andersson, Mr. A...|female| 0.42| 0| 0| 110152| 0.0| A10| C|
| max| 891| 1| 3|van Melkebeke, Mr...| male| 80.0| 8| 6| WE/P 5735| 512.3292| T| S|
+-------+-----------------+-------------------+------------------+--------------------+------+------------------+------------------+-------------------+------------------+-----------------+-----+--------+
欠損値の処理
各フィールドの欠損値の個数を確認する。pandasに比べるとやや煩雑。
train.select([F.count(F.when(F.isnull(col), col)).alias(col) for col in train.columns]).show()
+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+
|PassengerId|Survived|Pclass|Name|Sex|Age|SibSp|Parch|Ticket|Fare|Cabin|Embarked|
+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+
| 0| 0| 0| 0| 0|177| 0| 0| 0| 0| 687| 2|
+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+
数値型のフィールドとしては年齢(Age)にnullが存在するので、これをとりあえず平均年齢に置き換える。
stats = train.agg(F.avg('Age').alias('Age'))
age_avg = stats.first()[0]
train = train.na.fill({'Age': age_avg})
その他の欠損値はすべてString型のフィールドに存在しているので、データと被らない適当な文字列で置き換える。
train = train.na.fill('nodata')
DataFrameの中身と欠損値の数を確認する。
train.show(5)
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+------+--------+
|PassengerId|Survived|Pclass| Name| Sex| Age|SibSp|Parch| Ticket| Fare| Cabin|Embarked|
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+------+--------+
| 1| 0| 3|Braund, Mr. Owen ...| male|22.0| 1| 0| A/5 21171| 7.25|nodata| S|
| 2| 1| 1|Cumings, Mrs. Joh...|female|38.0| 1| 0| PC 17599|71.2833| C85| C|
| 3| 1| 3|Heikkinen, Miss. ...|female|26.0| 0| 0|STON/O2. 3101282| 7.925|nodata| S|
| 4| 1| 1|Futrelle, Mrs. Ja...|female|35.0| 1| 0| 113803| 53.1| C123| S|
| 5| 0| 3|Allen, Mr. Willia...| male|35.0| 0| 0| 373450| 8.05|nodata| S|
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+------+--------+
only showing top 5 rows
train.select([F.count(F.when(F.isnull(col), col)).alias(col) for col in train.columns]).show()
+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+
|PassengerId|Survived|Pclass|Name|Sex|Age|SibSp|Parch|Ticket|Fare|Cabin|Embarked|
+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+
| 0| 0| 0| 0| 0| 0| 0| 0| 0| 0| 0| 0|
+-----------+--------+------+----+---+---+-----+-----+------+----+-----+--------+
このあたりで、今回の分析に利用しない特徴量をDataFrameからdropしておく。
train = train.drop('Name')
train = train.drop('Ticket')
train = train.drop('Cabin')
train.show(5)
+-----------+--------+------+------+----+-----+-----+-------+--------+
|PassengerId|Survived|Pclass| Sex| Age|SibSp|Parch| Fare|Embarked|
+-----------+--------+------+------+----+-----+-----+-------+--------+
| 1| 0| 3| male|22.0| 1| 0| 7.25| S|
| 2| 1| 1|female|38.0| 1| 0|71.2833| C|
| 3| 1| 3|female|26.0| 0| 0| 7.925| S|
| 4| 1| 1|female|35.0| 1| 0| 53.1| S|
| 5| 0| 3| male|35.0| 0| 0| 8.05| S|
+-----------+--------+------+------+----+-----+-----+-------+--------+
only showing top 5 rows
カテゴリカル変数の変換
予測に使用する説明変数の中で性別(Sex)と乗船港(Embarked)がカテゴリカル変数になっているので、これらを数値データに変換していく。scikit-learnではLabelEncoderを使用すれば良いが、PySparkではStringIndexerを用いて同様の処理を実現できる。
# Sex Indexing
SexIndexer = StringIndexer(inputCol='Sex', outputCol='IndexSex')
SexIndexer = SexIndexer.fit(train)
train = SexIndexer.transform(train)
train = train.drop('Sex')
# Embarked Indexing
EmbarkedIndexer = StringIndexer(inputCol='Embarked', outputCol='IndexEmbarked')
EmbarkedIndexer = EmbarkedIndexer.fit(train)
train = EmbarkedIndexer.transform(train)
train = train.drop('Embarked')
モデル訓練時に、ラベルに対してlabelというフィールド名が必要なので、目的変数であるSurvivedに対してもIndexingする。
LabelIndexer = StringIndexer(inputCol='Survived', outputCol='label')
LabelIndexer = LabelIndexer.fit(train)
train = LabelIndexer.transform(train)
train = train.drop('Survived')
説明変数ベクトルの作成
scikit-learnではモデル訓練に際してDataFrameごと説明変数として入力するが、PySparkではデータフィールドの中から説明変数を指定する形で入力する。そのため、説明変数を一つのデータフィールドにベクトルとして格納する。
ベクトル化にはPySparkの提供するVectorAssemblerを使用する。ラベル込みのデータフレームなので、ここでは変数名をXyとしておく。
featureCols = train.columns
featureCols.remove('PassengerId')
featureCols.remove('label')
print(featureCols)
['Pclass', 'Age', 'SibSp', 'Parch', 'Fare', 'IndexSex', 'IndexEmbarked']
assembled_feature = VectorAssembler(inputCols=featureCols, outputCol='features')
pipline = Pipeline(stages=[assembled_feature])
pipline = pipline.fit(train)
Xy = pipline.transform(train)
Xy.select('features').show(5)
+--------------------+
| features|
+--------------------+
|[3.0,22.0,1.0,0.0...|
|[1.0,38.0,1.0,0.0...|
|[3.0,26.0,0.0,0.0...|
|[1.0,35.0,1.0,0.0...|
|(7,[0,1,4],[3.0,3...|
+--------------------+
only showing top 5 rows
データ分割
モデルの訓練用と検証用にデータを分割する。(scikit-learnでいうところのtrain_test_split)
Xy_train, Xy_valid = Xy.randomSplit([0.8, 0.2])
それぞれのデータサイズを確認する。
print(Xy_train.count(), len(Xy_train.columns))
print(Xy_valid.count(), len(Xy_valid.columns))
716 10
175 10
モデルの定義・訓練
ここではRandomForestで訓練・予測を行うので、PySparkの提供するものを使用する。
ParamGridBuilder, TrainValidationSplitを使用することでハイパーパラメータのグリッドサーチを行うことができる。(scikit-learnでいうところのGridSearchCV)
rfc = RandomForestClassifier(
labelCol='label',
featuresCol='features',
seed=42)
paramGrid = ParamGridBuilder()\
.addGrid(rfc.numTrees, [20, 50, 100])\
.addGrid(rfc.maxDepth, range(3, 10))\
.build()
tvs = TrainValidationSplit(estimator=rfc,
estimatorParamMaps=paramGrid,
evaluator=BinaryClassificationEvaluator(),
trainRatio=0.8)
scikit-learn同様、.fit()で定義したモデルの訓練を行う。
model = tvs.fit(Xy_train)
モデルの評価
検証用に作成したXy_validを用いてモデルの精度(Accuracy)を算出していく。
results = model.transform(Xy_valid)
results.show(5)
+-----------+------+-----------------+-----+-----+----+--------+-------------+-----+--------------------+--------------------+--------------------+----------+
|PassengerId|Pclass| Age|SibSp|Parch|Fare|IndexSex|IndexEmbarked|label| features| rawPrediction| probability|prediction|
+-----------+------+-----------------+-----+-----+----+--------+-------------+-----+--------------------+--------------------+--------------------+----------+
| 4| 1| 35.0| 1| 0|53.1| 1.0| 0.0| 1.0|[1.0,35.0,1.0,0.0...|[0.23165745048233...|[0.00231657450482...| 1.0|
| 18| 2|29.69911764705882| 0| 0|13.0| 0.0| 0.0| 1.0|(7,[0,1,4],[2.0,2...|[90.7208293296858...|[0.90720829329685...| 0.0|
| 21| 2| 35.0| 0| 0|26.0| 0.0| 0.0| 0.0|(7,[0,1,4],[2.0,3...|[91.7482262785935...|[0.91748226278593...| 0.0|
| 24| 1| 28.0| 0| 0|35.5| 0.0| 0.0| 1.0|(7,[0,1,4],[1.0,2...|[54.9648092296785...|[0.54964809229678...| 0.0|
| 33| 3|29.69911764705882| 0| 0|7.75| 1.0| 2.0| 1.0|[3.0,29.699117647...|[19.2563286505712...|[0.19256328650571...| 1.0|
+-----------+------+-----------------+-----+-----+----+--------+-------------+-----+--------------------+--------------------+--------------------+----------+
only showing top 5 rows
予測結果のデータフレームを確認すると、rawPrediction, probability, predictionといったデータフィールドが追加されている。labelとpredictionを並べると、それなりに予測できていることが確認できる。
results.select('label', 'prediction').show()
+-----+----------+
|label|prediction|
+-----+----------+
| 1.0| 1.0|
| 1.0| 0.0|
| 0.0| 0.0|
| 1.0| 0.0|
| 1.0| 1.0|
| 0.0| 1.0|
| 1.0| 0.0|
| 1.0| 1.0|
| 1.0| 1.0|
| 1.0| 1.0|
| 0.0| 0.0|
| 1.0| 1.0|
| 0.0| 0.0|
| 0.0| 0.0|
| 0.0| 0.0|
| 0.0| 0.0|
| 0.0| 0.0|
| 0.0| 0.0|
| 1.0| 0.0|
| 0.0| 0.0|
+-----+----------+
only showing top 20 rows
MulticlassClassificationEvaluatorでAccuracyの計算を行う。(BinaryClassificationEvaluatorではmetricNameに'accuracy'を指定できないっぽい)
MultiEvaluator = MulticlassClassificationEvaluator(
labelCol = 'label',
predictionCol = 'prediction',
metricName = 'accuracy',
)
acc = MultiEvaluator.evaluate(results)
print(acc)
0.8114285714285714
まずまずの精度なのでテストデータで予測を行っていく。
テストデータによる予測
特徴量ベクトルの作成
訓練用データと同じ要領で特徴量ベクトルX_testを作成していく。
test.select([F.count(F.when(F.isnull(col), col)).alias(col) for col in test.columns]).show()
+-----------+------+----+---+---+-----+-----+------+----+-----+--------+
|PassengerId|Pclass|Name|Sex|Age|SibSp|Parch|Ticket|Fare|Cabin|Embarked|
+-----------+------+----+---+---+-----+-----+------+----+-----+--------+
| 0| 0| 0| 0| 86| 0| 0| 0| 1| 327| 0|
+-----------+------+----+---+---+-----+-----+------+----+-----+--------+
テストデータでは運賃(Fare)にも欠損値が存在するので、年齢(Age)と合わせて平均値と置き換える。
stats = test.agg(F.avg('Age').alias('Age'))
age_avg = stats.first()[0]
test = test.na.fill({'Age': age_avg})
stats = test.agg(F.avg('Fare').alias('Fare'))
fare_avg = stats.first()[0]
test = test.na.fill({'Fare': fare_avg})
利用しないデータフィールドをdropする。
test = test.drop('Name')
test = test.drop('Ticket')
test = test.drop('Cabin')
訓練データで生成したIndexerを用いて、カテゴリカル変数を数値化する。
# Sex Indexing
test = SexIndexer.transform(test)
test = test.drop('Sex')
# Embarked Indexing
test = EmbarkedIndexer.transform(test)
test = test.drop('Embarked')
訓練データで生成したPipelineで特徴量ベクトルを作成する。
X_test = pipline.transform(test)
X_test.select('features').show(5)
+--------------------+
| features|
+--------------------+
|[3.0,34.5,0.0,0.0...|
|[3.0,47.0,1.0,0.0...|
|[2.0,62.0,0.0,0.0...|
|(7,[0,1,4],[3.0,2...|
|[3.0,22.0,1.0,1.0...|
+--------------------+
only showing top 5 rows
予測、ファイル書き出し
提出ファイルの様式に合わせて、予測値をint型にキャストした上でデータフィールド名をSurvivedとする。
submission = model.transform(X_test)
submission = submission.withColumn('Survived', submission['prediction'].cast('int'))
submission = submission.select('PassengerId', 'Survived')
submission.show(5)
+-----------+--------+
|PassengerId|Survived|
+-----------+--------+
| 892| 0|
| 893| 0|
| 894| 0|
| 895| 0|
| 896| 0|
+-----------+--------+
only showing top 5 rows
csv形式でファイルに書き出す。
now = datetime.datetime.now()
timestamp = now.strftime('%Y%m%d-%H%M%S')
submission.write.option('header', 'true').csv('output/pyspark-rfc_{}.csv'.format(timestamp))
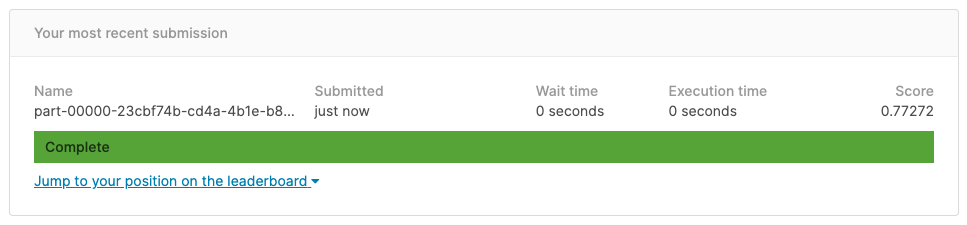
提出👏