※ 本記事は筆者の個人ブログに掲載した中国語記事を日本語に翻訳・再構成したものです。
原文:https://moyerock-qmzpu.wordpress.com/2026/01/22/context-engineering/
はじめに
最近は、AI 関連の就職用プロジェクトを開発しており、OpenAI API、LangGraph、そして MCP を利用した実装に携わってきました。そこで得たコンテキストエンジニアリングの実践経験について、共有したいと思います。
システム構成の概観
下図のように、本システムはユーザーの音声意図を認識し、対応する機能に振り分ける形で動作しています。
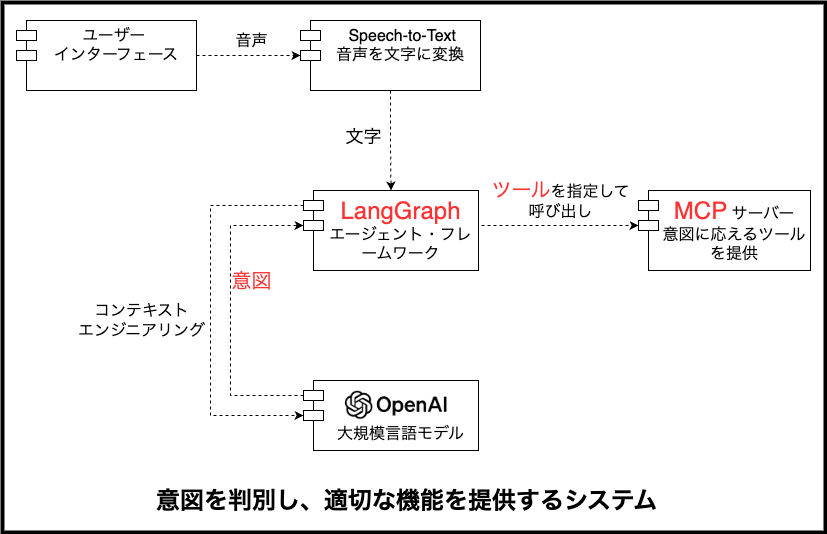
フロントエンド(UI)の詳細は置いておき、バックエンド側は大きく以下の三つの部分に分かれています:
- メインサービス(FastAPI 上で動作する LangGraph ワークフロー)
- MCP サーバー(FastMCP ベースで実装)
- エージェント(ここでは OpenAI の gpt-4o-mini を採用しています)
プロジェクトの課題
単純な例:コンテキストが無いケース
対話コンテキストの関連性を考慮しないのであれば、OpenAI の Responses API を例にすると、本システムは コンテキストエンジニアリング を導入しなくても実現可能です。
その場合、自然言語でワークフロー全体を記述した巨大なプロンプトを用意することになり、見た目としては次のような形になります:
あなたは意図認識の専門家です。あなたのタスクは、ユーザーの入力内容に基づいて応答タイプを判定し、以下の重要なルールを厳守することです:
- 出力は必ず JSON Schema に厳密に従うこと
- JSON 以外のテキストを一切追加しないこと(説明・補足・余計な文言は禁止)
- JSON のみを返却し、Markdown・説明文・コードブロックは出力しないこと
- 対応すべきタスクの種類は以下のとおりです:
- 通常会話 → type="talk"
ロジック:……(※ここでは約200字省略)- 音楽推薦 → type="music.recommend"
ロジック:……(※ここでは約200字省略)- 課題リマインド → type="kadai.reminder"
ロジック:……(※ここでは約200字省略)- 企業評価 → type="company.rating"
ロジック:……(※ここでは約200字省略)
さらに、対話コンテキストの関連性を考慮しないため、呼び出し時に対話履歴を返却する必要もありません。見た目としては次のようになります:
def get_openai_reply(user_text, system_prompt):
response = _openai_client.responses.create(
model="gpt-4o-mini",
input=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_text}
],
tools=[
{
"type": "mcp",
"server_label": "jp_speaking_assistant_mcp",
"server_url": Config.get("MCP_SERVER_URL"), # 設定ファイルから MCP Server のアドレスを読み込む
"require_approval": "never",
"authorization": Config.get(Constants.API_INVOKE_TOKEN), # MCPサーバーは Bearer トークン認証が必要
}
]
)
return response.output_text.strip()
もし追加要件が出たら?
たとえば次のような需要があったとします:
- 会社比較 → 出力 type="company.comparison"
ロジック:
あなたは企業分析の専門家です。複数の企業情報を基に、横断的な比較分析を行ってください。比較に使用するデータ:
これまでの 直近10ターンの会話 に登場した企業情報を使用してください。タスク:
- 複数の観点から企業を比較する(総合評価、職場環境、給与・福利厚生、将来性など)
- 各企業の強みと弱みを明確にする
- 選択のためのアドバイスを提供する(それぞれの企業がどのようなタイプの求職者に向いているか)
- 客観的かつ専門的で、親しみやすいトーンを保つこと
返却する JSON データ形式:...
この場合、過去の対話履歴も参照した上で出力する必要があります:
def get_openai_reply(user_text, system_prompt, recent_messages):
# ......
input=[
{"role": "system", "content": system_prompt},
*recent_messages, # 対話履歴メッセージを再送
{"role": "user", "content": user_text}
],
# .....
ここまでは順調です。
しかし、デバッグが必要な状況になるとやや厄介です。
というのも、recent_messages の中から関連データとなり得る履歴を調査し、さらに各種ログを突き合わせて原因を特定する必要があるためです。
タスクの種類が常に一桁程度に収まっているのであれば、こうした運用もまだ許容範囲でしょう。
しかし、タスクの種類や遡って確認すべき対話数が少しでも増えてくると、開発体験はあまり快適とは言えなくなります。
そこで有力な選択肢となるのが、コンテキストエンジニアリング(Context Engineering)の導入です。
タスクをワークフローとして整理し、それぞれのタスクに対して専用のデータ構造を持たせることで、可読性や保守性を大きく向上させることができます。
そのため、本システムでは、コンテキストエンジニアリングを実現するためのツールとして LangGraph を導入しました。
LangGraph
LangGraph が対応している主なユースケース:
- ループや分岐:線形な実行に限らず、複雑な制御フローを表現できる
- 状態管理:複数のステップ間でコンテキストを保持できる
- 長時間実行:タスクの一時停止・再開・永続化が可能
- 人とAIの協調:人による介入、レビュー、修正を組み込める
簡単に言えば、LangGraph は次の課題を解決するために登場しました:
「Agent の思考プロセスを、prompt からコードへ移す」
これは、まさに私が求めていたものでした。
解決策
ワークフロー
上図の通り、本システムではユーザーの意図に基づき、最適なツールへ振り分けるルーティング・ワークフローを採用しています。
状態
このワークフローを実現するため、各ノードで読み書きが可能な、専用のデータ構造を定義する必要があります。そこで、これらの要件を満たす状態管理用のコンテナを導入しました。
# src/agents/langgraph/conversation_state.py
from typing import TypedDict, Annotated, Literal, Optional, List, Dict, Any
from langgraph.graph.message import add_messages
from langchain_core.messages import BaseMessage
class ConversationState(TypedDict):
"""会話のステータス"""
# メッセージの履歴(自動的合併)
messages: Annotated[List[BaseMessage], add_messages]
# ユーザーからの入力
user_input: str
# インテントのカテゴリ
intent: Literal[
"talk",
"music.recommend",
"company.rating",
"company.comparison",
"kadai.reminder",
"unknown"
]
# コンテクストの情報(数回の会話用)
contextvars: Dict[str, Any] # 例:{"last_emotion": "sad", "asked_for_music": True}
# intent: "talk"
reply: Optional[str]
reply_translation: Optional[Dict[str, str]]
suggestion: Optional[str]
suggestion_translation: Optional[Dict[str, str]]
# intent: "music.recommend"
artist: Optional[str]
song: Optional[str]
music_description: Optional[str]
track: Optional[Dict[str, Any]]
recommended_tracks: List[Dict[str, Any]] # お勧めの履歴
# intent: "company.rating"
company_name: Optional[str]
company_description: Optional[str]
company_rating: Optional[Dict[str, Any]]
companies_discussed: List[Dict[str, Any]] # 会社リスト
# intent: "company.comparison"
companies_to_compare: List[str] # 会社リスト(比較用)
comparison_report: Optional[str] # 比較の結果のレポート
comparison_data: Optional[Dict[str, Any]] # 比較のデータ
# intent: "kadai.reminder"
kadai_list: List[Dict[str, Any]]
# 最終の出力結果
output: Dict[str, Any]
# エラー
error: Optional[str]
状態図
状態コンテナを用意したら、ワークフローを表現する StateGraph を構築します:
# src/agents/langgraph/conversation_agent.py
from langgraph.graph import StateGraph, START, END
from langgraph.graph.state import CompiledStateGraph
from langchain_openai import ChatOpenAI
from .conversation_state import ConversationState
from .mcp_client import MCPClient
from .nodes.talk_node import TalkNode
from .nodes.music_node import MusicNode
from .nodes.company_rating_node import CompanyRatingNode
from .nodes.company_comparison_node import CompanyComparisonNode
from .nodes.kadai_node import KadaiNode
from .nodes.intent_router_node import IntentRouterNode
class ConversationAgent:
def __init__(self, openai_api_key: str, mcp_client: MCPClient):
self.llm = ChatOpenAI(
model="gpt-4o-mini",
api_key=openai_api_key,
temperature=0.7
)
self.mcp_client = mcp_client
self.app: CompiledStateGraph = self._build_graph()
def _build_graph(self) -> CompiledStateGraph:
"""LangGraphのワークフロー"""
workflow = StateGraph(ConversationState)
# ノードの導入
self.intent_router_node = IntentRouterNode(self.llm, self.mcp_client)
self.talk_node = TalkNode(self.llm, self.mcp_client)
self.music_node = MusicNode(self.llm, self.mcp_client)
self.company_rating_node = CompanyRatingNode(self.llm, self.mcp_client)
self.company_comparison_node = CompanyComparisonNode(self.llm, self.mcp_client)
self.kadai_node = KadaiNode(self.llm, self.mcp_client)
# ノードの追加
workflow.add_node("router", self.intent_router_node)
workflow.add_node("talk", self.talk_node)
workflow.add_node("music", self.music_node)
workflow.add_node("company", self.company_rating_node)
workflow.add_node("comparison", self.company_comparison_node)
workflow.add_node("kadai", self.kadai_node)
# 入り口
workflow.add_edge(START, "router")
# ルータにより意思決定
workflow.add_conditional_edges(
"router",
self._route_by_intent,
{
"talk": "talk",
"music": "music",
"company": "company",
"comparison": "comparison",
"kadai": "kadai"
}
)
# すべてのブランチが終るべきだ
workflow.add_edge("talk", END)
workflow.add_edge("music", END)
workflow.add_edge("company", END)
workflow.add_edge("comparison", END)
workflow.add_edge("kadai", END)
return workflow.compile()
def _route_by_intent(self, state: ConversationState) -> Literal["talk", "music", "company", "comparison", "kadai"]:
"""インテントとノードのマッピング"""
intent = state.get("intent", "talk")
route_map = {
"music.recommend": "music",
"company.rating": "company",
"company.comparison": "comparison",
"kadai.reminder": "kadai"
}
route = route_map.get(intent, "talk")
logger.debug(f"[DEBUG] Routing to: {route}")
return route
コードそのものが状態マシン(ステートマシン) として機能しており、非常に直感的です 。
次に、各ノードの実装を見ていきます。
ノード
まず、使用する依存関係を注入するためのノードの基底クラスを定義します:
# src/agents/langgraph/nodes/base.py
from langchain_openai import ChatOpenAI
from ..mcp_client import MCPClient
class BaseNode:
def __init__(self, llm: ChatOpenAI, mcp_client: MCPClient):
self.llm = llm
self.mcp_client = mcp_client
そして、BaseNode を基盤として、ワークフローの入り口となるノードを実装します:
# src/agents/langgraph/nodes/intent_router_node.py
import json
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from src.app.logger import logger
from .base import BaseNode
from ..conversation_state import ConversationState
class IntentRouterNode(BaseNode):
async def __call__(self, state: ConversationState) -> ConversationState:
"""ユーザーの意図を解析し、適切な処理ノードに振り分ける"""
user_input = state["user_input"]
messages = state.get("messages", [])
context = state.get("context", {})
companies_discussed = state.get("companies_discussed", [])
# 意図認識プロンプト
system_prompt = """あなたは意図認識の専門家です。ユーザーの入力と文脈を分析し、ユーザーの意図を判断してください。
想定される意図タイプ:
1. talk - 通常の会話
2. music.recommend - 音楽推薦(感情表現、音楽の明確なリクエスト、曲を変えたい等)
3. company.rating - 企業評価(具体的な会社名、面接、説明会などに言及)
4. company.comparison - 企業の横断的比較(複数社の比較を明確に求める、または2社以上を議論した上で助言を求める場合)
5. kadai.reminder - 課題リマインダー(課題、宿題などに言及)
**重要ルール:company.comparison と判断する条件**
- ユーザーが「比較・対比・どちらが良い・選んでほしい」などの表現を明確に使っている
- または、すでに2社以上の企業について話しており、「どう思う?・アドバイスは?・どれを選ぶべき?」と尋ねている
- これまでに議論された企業数:{companies_count}
- これまでに議論された企業:{companies_list}
- ユーザー入力が中国語でも日本語でも、agent 内部ではすべて日本語を使用すること
コンテキスト情報:
- 前のターンで AI が音楽の要望を尋ねたか:{asked_for_music}
- 前のターンで AI が会社情報を尋ねたか:{asked_for_company}
- ユーザーが前のターンで表した感情:{last_emotion}
返却は JSON 形式のみ:
{{
"intent": "タイプ",
"reason": "簡潔な理由",
"extracted_info": {{}},
"companies_to_compare": []
}}
extracted_info には以下を含めてもよい:company_name, emotion, music_preference など
"""
discussed_company_names = [c.get("name") for c in companies_discussed if isinstance(c, dict)]
prompt = system_prompt.format(
companies_count=len(discussed_company_names),
companies_list=", ".join(discussed_company_names) if discussed_company_names else "なし",
asked_for_music=context.get("asked_for_music", False),
asked_for_company=context.get("asked_for_company", False),
last_emotion=context.get("last_emotion", "neutral")
)
result = await self.llm.ainvoke([
SystemMessage(content=prompt),
*messages[-10:], # コンテキストウィンドウ (Context Window)
HumanMessage(content=user_input)
])
try:
intent_data = json.loads(result.content)
intent = intent_data.get("intent", "talk")
extracted_info = intent_data.get("extracted_info", {})
companies_to_compare = intent_data.get("companies_to_compare", [])
# コンテクストを更新
new_context = context.copy()
if "emotion" in extracted_info:
new_context["last_emotion"] = extracted_info["emotion"]
# インテントは comparison に推定され、かつ会社を指名されないなら、既存の会社らを使う
if intent == "company.comparison" and not companies_to_compare:
companies_to_compare = discussed_company_names
return {
"intent": intent,
"context": new_context,
"company_name": extracted_info.get("company_name"),
"companies_to_compare": companies_to_compare,
"messages": [AIMessage(content=f"[Intent: {intent}]")]
}
except Exception as e:
logger.exception(e)
return {"intent": "talk", "error": str(e)}
IntentRouterNode 内のプロンプトや、前述の ConversationAgent コンテナ内の状態は、ステートマシンの規模拡大に伴い複雑化する傾向があります。これはソフトウェア工学の観点から見れば、一種の 『コードの不吉な臭い(Code Smell)』 であり、将来的に解決すべき重要な設計上の課題と言えます。
MCP との連携
ここでは、MCP呼び出しを伴うノードの例として、音楽推薦ノードを見ていきます:
# src/agents/langgraph/nodes/music_node.py
import json
from langchain_core.messages import SystemMessage, HumanMessage
from src.app.logger import logger
from .base import BaseNode
from ..conversation_state import ConversationState
class MusicNode(BaseNode):
async def __call__(self, state: ConversationState) -> ConversationState:
"""音楽のおすすめ"""
user_input = state["user_input"]
context = state.get("context", {})
recommended_tracks = state.get("recommended_tracks", [])
messages = state.get("messages", [])
# 型安全な処理
if not isinstance(recommended_tracks, list):
recommended_tracks = []
valid_tracks = []
for track in recommended_tracks:
if isinstance(track, dict):
valid_tracks.append(track)
elif isinstance(track, str):
try:
parsed = json.loads(track)
if isinstance(parsed, dict):
valid_tracks.append(parsed)
except:
pass
# おすすめ履歴の曲名一覧
history_songs = []
for t in valid_tracks[-10:]:
song_name = t.get("song") or t.get("name") or "Unknown"
history_songs.append(song_name)
system_prompt = """あなたは音楽レコメンドの専門家です。
タスク:ユーザーの感情/リクエスト/過去の推薦履歴に基づき、最適な1曲を推薦してください。
[厳格なルール]:
1. 以下のリストにすでに含まれている楽曲を推薦することは**絶対に禁止**です:{history}
2. 感情が同じであっても、できる限り異なるアーティストや異なる音楽ジャンルの楽曲を推薦してください。
3. 推薦理由は、ユーザーの現在の状況に合わせて微調整してください。
コンテキスト:
- ユーザーの感情:{emotion}
- これまでに推薦した楽曲:{history}
JSON のみを返してください:
{{
"artist": "アーティスト名",
"song": "楽曲名",
"description": "推薦理由(日本語)"
}}
"""
prompt = system_prompt.format(
emotion=context.get("last_emotion", "neutral"),
history=json.dumps(history_songs, ensure_ascii=False) if history_songs else "なし"
)
try:
result = await self.llm.ainvoke([
SystemMessage(content=prompt),
*messages[-4:],
HumanMessage(content=user_input)
])
data = json.loads(result.content)
artist = data["artist"]
song = data["song"]
# インヴォーク: search_spotify_track(MCPサーバーにて)
track_result = await self.mcp_client.call_tool(
"search_spotify_track",
{"artist": artist, "song": song}
)
if isinstance(track_result, str):
try:
track_result = json.loads(track_result)
except:
track_result = {"raw": track_result}
# 推薦履歴の更新
new_recommended = valid_tracks + [track_result]
return {
"artist": artist,
"song": song,
"music_description": data["description"],
"track": track_result,
"recommended_tracks": new_recommended,
"output": {
"type": "music.recommend",
"artist": artist,
"song": song,
"description": data["description"],
"track": track_result
}
}
except Exception as e:
import traceback
error_msg = f"Music handler error: {str(e)}\n{traceback.format_exc()}"
logger.exception(error_msg)
return {"error": error_msg}
ご覧の通り、このノード内では MCP Server 上の search_spotify_track というツール(Tool)を呼び出し、楽曲のメタデータを取得しています。呼び出しに使用している依存先である mcp_client は、プロトコル層に近いユーティリティクラスであり、その実装は以下の通りです:
# src/agents/langgraph/mcp_client.py
import httpx
from typing import List, Dict, Any, Optional
from src.app.logger import logger
class MCPClient:
def __init__(self, base_url: str, token: str | None = None):
self.base_url = base_url
self.session_id: Optional[str] = None
headers = {
"Content-Type": "application/json",
"Accept": "application/json, text/event-stream", # 重要:FastMCP の動作に必要です
}
if token:
headers["Authorization"] = f"Bearer {token}"
self.client = httpx.AsyncClient(
base_url=base_url,
headers=headers,
timeout=30.0,
follow_redirects=True,
)
async def initialize(self):
"""initialize MCP session,get session_id from the response header"""
payload = {
"jsonrpc": "2.0",
"id": 0, # 0から開始
"method": "initialize",
"params": {
"protocolVersion": "2025-06-18", # 注意:FastMCPはこのバージョン番号が必要です
"capabilities": {
"tools": {} # ツールをサポートすることを宣言
},
"clientInfo": {
"name": "langgraph-client",
"version": "1.0"
}
}
}
# 初期化リクエストを送信
resp = await self.client.post("", json=payload)
if resp.status_code != 200:
raise RuntimeError(
f"Initialize failed: {resp.status_code}, body={resp.text}"
)
# レスポンスヘッダーからセッションIDを取得(注意:大文字小文字を区別しないように取得)
session_id = (
resp.headers.get("mcp-session-id") or
resp.headers.get("Mcp-Session-Id") or
resp.headers.get("MCP-Session-Id")
)
if not session_id:
raise RuntimeError(
f"No session ID in response headers. Headers: {dict(resp.headers)}"
)
self.session_id = session_id
logger.debug(f"✓ MCP session initialized: {self.session_id}")
# 初期化完了通知を送信(重要なステップ)
await self._send_initialized_notification()
async def _send_initialized_notification(self):
"""サーバーへ初期化完了通知(notification)を送信する"""
payload = {
"jsonrpc": "2.0",
"method": "notifications/initialized"
# 注意:これは通知(notification)であるため、IDフィールドは不要
}
# セッションIDをヘッダーに含めて送信
resp = await self.client.post(
"",
json=payload,
headers={"Mcp-Session-Id": self.session_id}
)
if resp.status_code != 200:
logger.debug(f"Warning: initialized notification failed: {resp.status_code}")
else:
logger.debug("✓ Sent initialized notification")
async def _post(self, payload: dict):
"""セッションIDを含めてリクエストを送信する"""
if not self.session_id:
raise RuntimeError("MCP session not initialized. Call initialize() first.")
# セッションIDをヘッダーに渡す(ボディではなくヘッダーで管理)
resp = await self.client.post(
"",
json=payload,
headers={"Mcp-Session-Id": self.session_id}
)
if resp.status_code != 200:
raise RuntimeError(
f"MCP request failed: {resp.status_code}, body={resp.text}"
)
return resp.json()
async def list_tools(self) -> List[Dict[str, Any]]:
"""ツール一覧の配列を返す"""
response = await self._post({
"jsonrpc": "2.0",
"id": 1,
"method": "tools/list",
"params": {},
})
# ツール配列を抽出
if "result" in response and "tools" in response["result"]:
return response["result"]["tools"]
logger.debug(f"Warning: No tools found in response: {response}")
return []
async def call_tool(self, name: str, arguments: dict) -> Any:
"""ツールを実行し、結果を返す"""
response = await self._post({
"jsonrpc: "2.0",
"id": 2,
"method": "tools/call",
"params": {
"name": name,
"arguments": arguments,
},
})
# 実行結果を抽出
if "result" in response:
# FastMCPの返却値は通常 result.content 内に格納される
result = response["result"]
if isinstance(result, dict) and "content" in result:
# extract the first text in the content array
content = result.get("content", [])
if content and isinstance(content, list):
return content[0].get("text", content)
return result
elif "error" in response:
raise RuntimeError(f"MCP tool error: {response['error']}")
return response
async def close(self):
await self.client.aclose()
呼び出し先となる MCP Server 上の Tool がどのように実装されているかについては、本稿ではこれ以上踏み込みません。FastMCP を用いて必要な Tool を備えた Server を構築している、という点だけ押さえておけば十分です。
また、ステートマシン内の他のノードの実装についても、前述の MusicNode と大きな違いはなく、基本的には同様の構成となっているため、詳細な説明は割愛します。
それでは次に、セッション(Session) を用いてどのように対話を管理するかを見ていきましょう。
セッション管理
みなさんが使ったことのある ChatGPT では、画面左側にこれまでのすべての会話が一覧表示されており、それぞれの会話は互いに独立しています。これがいわゆる セッション(Session)の考え方です。
本システムにおける対話も、同様に Session 単位で管理しています。
現在は メモリ上で セッション(Session)を保持する方式 を採用しており、そのためサービスを再起動すると、すべてのセッションは消失します。もちろん、データベースによる永続化を行うこともそれほど難しくありませんが、現時点では強い要件がないため、そこまでは対応していません。
それでは、実装を見ていきましょう:
# src/agents/langgraph/session_manager.py
from typing import Dict, Any
from datetime import datetime, timedelta
import asyncio
class SessionManager:
"""session_id に基づくセッション管理"""
def __init__(self, ttl_minutes: int = 30):
self.sessions: Dict[str, Dict[str, Any]] = {}
self.ttl = timedelta(minutes=ttl_minutes)
self._cleanup_task = None
def get_session(self, session_id: str) -> Dict[str, Any]:
if session_id not in self.sessions:
self.sessions[session_id] = {
"context": {},
"messages": [],
"recommended_tracks": [], # 确保是列表
"companies_discussed": [], # 确保是列表
"created_at": datetime.now(),
"last_access": datetime.now()
}
session = self.sessions[session_id]
session["last_access"] = datetime.now()
session.setdefault("recommended_tracks", [])
session.setdefault("companies_discussed", [])
return session
def update_session(self, session_id: str, updates: Dict[str, Any]):
session = self.get_session(session_id)
for key, value in updates.items():
if isinstance(value, (list, dict)):
import copy
session[key] = copy.deepcopy(value)
else:
session[key] = value
session["last_access"] = datetime.now()
def clear_session(self, session_id: str):
if session_id in self.sessions:
del self.sessions[session_id]
async def cleanup_expired_sessions(self):
"""期限切れセッションのクリーンアップ"""
while True:
await asyncio.sleep(300) # 5分ごとにチェックする
now = datetime.now()
expired = [
sid for sid, session in self.sessions.items()
if now - session["last_access"] > self.ttl
]
for sid in expired:
del self.sessions[sid]
print(f"Cleaned up expired session: {sid}")
def start_cleanup(self):
if self._cleanup_task is None:
self._cleanup_task = asyncio.create_task(self.cleanup_expired_sessions())
# Singletonパターン
_session_manager = None
def get_session_manager() -> SessionManager:
global _session_manager
if _session_manager is None:
_session_manager = SessionManager(ttl_minutes=30)
_session_manager.start_cleanup()
return _session_manager
チャット用インターフェース
一通り準備が整ったので、API 層から呼び出すためのチャットインターフェースを追加します。
こちらも ConversationAgent 内に実装していきます:
from .session_manager import get_session_manager
class ConversationAgent:
async def chat(self, user_input: str, session_id: str, session_manager=None) -> dict:
"""ユーザー入力を処理します(マルチターン対話に対応)"""
if session_manager is None:
session_manager = get_session_manager()
# 1. 過去のセッション状態を取得
session = session_manager.get_session(session_id)
# 2. 参照の影響を防ぐため、セッションデータをディープコピー
initial_state = {
"user_input": user_input,
"messages": copy.deepcopy(session.get("messages", [])),
"context": copy.deepcopy(session.get("context", {})),
"recommended_tracks": copy.deepcopy(session.get("recommended_tracks", [])),
"companies_discussed": copy.deepcopy(session.get("companies_discussed", []))
}
# 3. 処理フローを実行
result = await self.app.ainvoke(initial_state)
if result.get("error"):
return {"error": result["error"], "session_id": session_id}
# 4. 最新データのみを保持するようセッション状態を更新
session_manager.update_session(session_id, {
"messages": result.get("messages", [])[-20:], # 最近の20件
"context": result.get("context", {}),
"recommended_tracks": result.get("recommended_tracks", [])[-10:], # 最近の10曲
"companies_discussed": result.get("companies_discussed", [])[-10:], # 最近の10社
})
# 5. 処理結果を返却
output = result.get("output", {})
output["session_id"] = session_id
return output
統合の呼び出し
ここまでで各機能が出揃い、API 層からチャット API を直接呼び出すことで、ワークフロー全体を駆動できる構成となっています:
from fastapi import APIRouter, HTTPException
from pydantic import BaseModel
from typing import Optional, Dict, Any
from src.app.utils import Utils
from src.app.logger import logger
from src.services.langgraph.conversation_service import get_conversation_agent
conversation_router = APIRouter(prefix="/api/langgraph", tags=["langgraph"])
class ChatRequest(BaseModel):
user_input: str
session_id: Optional[str] = None
class ChatResponse(BaseModel):
type: str
data: Dict[str, Any]
session_id: str
@conversation_router.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest):
try:
agent = get_conversation_agent()
# session_id が指定されていない場合は、新しく生成する
session_id = request.session_id or Utils.new_session_id()
result = await agent.chat(
user_input=request.user_input,
session_id=session_id
)
if "error" in result:
raise HTTPException(status_code=500, detail=result["error"])
return ChatResponse(
type=result.get("type", "unknown"),
data=result,
session_id=session_id
)
except Exception as e:
logger.exception(e)
raise HTTPException(status_code=500, detail=str(e))
ここでの session_id は、原則として一意であれば十分であり、例えば str(uuid.uuid4()) を用いる方法でも問題ありません。
以上で、このコンテキストエンジニアリングに基づく実践は、ひとまず初期的な成功を収めたと言えるでしょう。
あとがき
AIの世界は進化が驚くほど速く、このプロジェクトを書き終える頃には、SNS上はすでに Vibe Coding や Skills の話題で持ちきりでした。せっかく完成させたものが、実戦投入される前に時代遅れになってしまう……そんな可能性も否定できません(まあ、少なくとも MCP Server 内の Tool はそのまま使えますけどね!)。
それでも私にとっては、「書き切った」こと自体に意味があります。
一つの区切りとして、長らく心に引っかかっていたものを片付けられた、そんな感覚です。