はじめに
最近、プログラミングスクールで機械学習による画像認識を学び始めたプログラミング初学者です。
もし田舎で動物と遭遇した時、動物を識別できれば便利ではないだろうかと思い、今回、CNNを用いて、アライグマ、ハクビシン、ヒグマ、シカ、イノシシ、イタチの6種類の動物の画像認識できる簡単なアプリを作ってみました。
学習してきた内容の復習にもなっており、こうしておけばよかった等の反省点も少し記載していくので、よろしくお願いします。
目次
- 画像の収集
- 画像の選定
- 画像を訓練データと検証データに分類
- モデルの定義
- モデルの学習と評価
- 実装結果の可視化
- アプリの作成
- まとめ
実行環境
- Google Colaboratory
- Visual Studio Code
1.画像の収集
まずは、必要な量の画像を収集、保存を行います。
画像収集したものを以下に保存されるように、最初にcdコマンドを実行しておきます。
%cd "/content/drive/My Drive/seikabutu"(1).ライブラリのインポート
キーワード検索で画像データを簡単に収集できる「incrawler」をインストールし 必要なライブラリをインポートしました。#incrawlerのインストール !pip install icrawler #pythonライブラリの「incrawler」でBing用クローラーのモジュールをインポート from icrawler.builtin import BingImageCrawler #globをインポート import glob(2).検索した画像をフォルダに保存する
以下のコードは、検索から画像収集する際使えるコードだと教えていただいたものです。詳しいことは分かりませんが、簡単に画像収集する際、便利なコードなようです。
使う人によって変える箇所は、主に3点。
①search_wordsに、通常ネット検索したい時と同じように、検索したいワードを日本語で入力します。
②dir_namesに、検索で得た画像を入れるフォルダ名を任意で入力します。
ここは、ローマ字でフォルダ内に何が入っているか分かるような言葉なら、何を入力してもいいようです。③max_numに、ダウンロードする最大枚数を設定します。ここでは、250と設定しました。
(何度か試しましたが、250で設定すると250弱ダウンロードできました。300にしても同じ結果だったので、250で設定しました。)#動物6種類の検索リストの生成 search_words = ["イタチ","ハクビシン","アライグマ","イノシシ","鹿","ヒグマ"] #検索画像を保存する時のフォルダ名の設定 dir_names = ["itachi","hakubishin","araiguma","inoshishi","shika","higuma"] #検索した画像を名前を設定したフォルダに入れていく for search_word,dir_name in zip(search_words,dir_names): #Bing用クローラーの生成 bing_crawler = BingImageCrawler( downloader_threads=6, # ダウンローダーのスレッド数 storage={'root_dir': dir_name}) # ダウンロード先のディレクトリ名 #クロール(キーワード検索による画像収集)の実行 bing_crawler.crawl( keyword=search_word, # 検索キーワード(日本語もOK) max_num=250) # ダウンロードする画像の最大枚数250枚に設定search_words内のヒグマで検索をかけている箇所、最初は、クマで検索をかけていました。
ヒグマに検索ワードを変更した理由を、次の項目、「画像の選定」で説明しています。参考文献:
>>画像データをキーワード検索で効率的に収集する方法(Python「icrawler」のBing検索)
https://atmarkit.itmedia.co.jp/ait/articles/2010/28/news018.html2.画像の選定
各動物250枚弱の画像が集めましたが、モデルの精度に関わる不要なデータもありましたので、削除を行いました。
<削除した画像>
1.何枚も同じ画像がある
2.動物が複数映っている
3.イラストなど明らかに本物の動物でないこの選定により、ある種類の動物画像だけ、極端にデータが減ってしまいました。
「クマ」です。キャラクター等、デザイン画像が多く、削除データが多くなってしまいました。
クマとつくキャラクターが多いことを考慮し、具体的なクマの種類に絞って検索をかけていたら、検索のかけなおしと画像の選定の二度手間が防げたかなと思います。
検索ワードを一部変えたいとき、以下を実行すれば、他の種類が再ダウンロードされずにすみ、時短になると教えていただきました。注意点として、保存する時のフォルダ名(dir_names)だけ、使ってないフォルダ名に一旦変えておく必要があります。一部変えたい時のコード
#検索リストの生成 search_words = ["ヒグマ"] #検索したい単語 dir_names = ["higuma2"] #保存するときのフォルダ名 for search_word,dir_name in zip(search_words,dir_names): # Bing用クローラーの生成 bing_crawler = BingImageCrawler( downloader_threads=6, # ダウンローダーのスレッド数 storage={'root_dir': dir_name}) # ダウンロード先のディレクトリ名 # クロール(キーワード検索による画像収集)の実行 bing_crawler.crawl( keyword=search_word, # 検索キーワード(日本語もOK) max_num=250) # ダウンロードする画像の最大枚数3.画像を訓練データと検証データに分類
収集、選定した画像をgoogleColaboratoryに読み込み、サイズ変更などの処理をして、訓練データと検証データに分類します。
ライブラリをインポート
import cv2 import numpy as np import os from tensorflow.keras.utils import to_categorical(1).画像の読み込み
各動物の画像をos.listdirを用い、リスト式でgoogleColaboratoryに読み込みます。
その中に必要のないデータがあったため、removeを使って取り除きました。print(len(path_~))のコードは、本来必要ありませんが、画像が何枚あるのか知るために、書いています。
path_araiguma = os.listdir("/content/drive/My Drive/seikabutu/araiguma") path_hakubishin = os.listdir("/content/drive/My Drive/seikabutu/hakubishin") path_inoshishi = os.listdir("/content/drive/My Drive/seikabutu/inoshishi") path_itachi = os.listdir("/content/drive/My Drive/seikabutu/itachi") path_higuma = os.listdir("/content/drive/My Drive/seikabutu/higuma") path_shika = os.listdir("/content/drive/My Drive/seikabutu/shika") path_araiguma.remove(".ipynb_checkpoints") path_hakubishin.remove(".ipynb_checkpoints") path_inoshishi.remove(".ipynb_checkpoints") path_itachi.remove(".ipynb_checkpoints") path_shika.remove(".ipynb_checkpoints") #画像の枚数 print(len(path_araiguma)) print(len(path_hakubishin)) print(len(path_inoshishi)) print(len(path_itachi)) print(len(path_higuma)) print(len(path_shika))(2).画像の処理
画像の処理を行い、各動物のデータを150ずつに揃えます。
150枚ずつにした理由は、2つあります。
①データはなるべく多い方がよく、最低でも100ずつはデータがあった方がよいため
②画像認証の結果に偏りが出ないためにデータ数を揃える必要があるため#動物ごとのリスト作成 img_araiguma = [] img_hakubishin = [] img_inoshishi = [] img_itachi = [] img_higuma = [] img_shika = [] img_num = 150 #画像データの数 img_size = 150 #画像のサイズ # rgb型(150,150)サイズに変えて、1つずつ取り出し、リストに入れている for i in range(img_num): img = cv2.imread("/content/drive/My Drive/seikabutu/araiguma/"+ path_araiguma[i]) b,g,r = cv2.split(img) img = cv2.merge([r,g,b]) img = cv2.resize(img, (img_size,img_size)) img_araiguma.append(img) for i in range(img_num): img = cv2.imread("/content/drive/My Drive/seikabutu/hakubishin/"+ path_hakubishin[i]) b,g,r = cv2.split(img) img = cv2.merge([r,g,b]) img = cv2.resize(img, (img_size,img_size)) img_hakubishin.append(img) for i in range(img_num): img = cv2.imread("/content/drive/My Drive/seikabutu/inoshishi/"+ path_inoshishi[i]) b,g,r = cv2.split(img) img = cv2.merge([r,g,b]) img = cv2.resize(img, (img_size,img_size)) img_inoshishi.append(img) for i in range(img_num): img = cv2.imread("/content/drive/My Drive/seikabutu/itachi/"+ path_itachi[i]) b,g,r = cv2.split(img) img = cv2.merge([r,g,b]) img = cv2.resize(img, (img_size,img_size)) img_itachi.append(img) for i in range(img_num): img = cv2.imread("/content/drive/My Drive/seikabutu/higuma/"+ path_higuma[i]) b,g,r = cv2.split(img) img = cv2.merge([r,g,b]) img = cv2.resize(img, (img_size,img_size)) img_higuma.append(img) for i in range(img_num): img = cv2.imread("/content/drive/My Drive/seikabutu/shika/"+ path_shika[i]) b,g,r = cv2.split(img) img = cv2.merge([r,g,b]) img = cv2.resize(img, (img_size,img_size)) img_shika.append(img)以下、画像処理について、アライグマの部分だけ取り出して細かく説明していきます。
img_araiguma = []#1枚ずつ取り出し画像処理を行う for i in range(img_num): img = cv2.imread("/content/drive/My Drive/seikabutu/araiguma/"+ path_araiguma[i]) b,g,r = cv2.split(img) img = cv2.merge([r,g,b]) img = cv2.resize(img, (img_size,img_size)) img_araiguma.append(img)まず、cv2.imreadでアライグマの画像処理ができるように読み込みます。
cv2.split(img)で「b,g,r」型になっているのを切り離し、
cv2.merge([r,g,b])で「r,g,b」型に結合する。
cv2.resizeで(150x150)にサイズ変更を行い、
append(img)でimg_araiguma=[ ]のアライグマの空リストに追加していく
これを、for i in range(img_num)で150枚目の画像データまで1枚ずつ取り出し繰り返します。
同じことを他の動物の画像データでも行っています。画像データを「r,g,b]型に変える理由は、CNNを用いる場合、「r,g,b」型である必要があるためです。
また、サイズを変更を行う理由は、サイズがバラバラだと実装したモデルできちんとした学習が行えないからです。
(3).データの分類
動物の種類ごとに分けていた画像データを、Numpy形式に変えて一つにまとめます。
画像データをコンピューターが認識できるように、動物ごとに0~5の数字を振って、to_categoricalでカテゴリー分けし、np.random.permutationで、ランダムに並び替えます。
並び替えたデータの内、80%をtrainとして訓練データに、残りの20%を検証データに分類します。
#NumPy形式に変換 X = np.array(img_araiguma + img_hakubishin + img_inoshishi + img_itachi + img_higuma + img_shika) #種類ごとに番号を付ける y = np.array([0]*len(img_araiguma) + [1]*len(img_hakubishin) + [2]*len(img_inoshishi) + [3]*len(img_itachi) + [4]*len(img_higuma) +[5]*len(img_shika)) y = to_categorical(y) #ランダムにデータを入れ替え rand_index = np.random.permutation(np.arange(len(X))) X = X[rand_index] y = y[rand_index] # データの分割 train80%,test20% X_train = X[:int(len(X)*0.8)] y_train = y[:int(len(y)*0.8)] X_test = X[int(len(X)*0.8):] y_test = y[int(len(y)*0.8):]参考文献:
>>numpy.random.permutation – 配列の要素をランダムに並べ替えた新しい配列を生成
https://www.headboost.jp/numpy-random-permutation/4.モデルの定義
CNNを用いてモデルを実装し、VGG16の転移学習を行います。
CNNとは、「Convolutional Neural Network」の略であり、日本では、「畳み込みニューラルネットワーク」とも呼ばれています。いくつもの深い層が重なったニューラルネットワークであり、主に画像認識でよく使われているネットワークです。
VGG16とは、ImageNetという大量の画像セットで1000カテゴリの分類を学習したモデルです。
転移学習とは、機械学習の手法の一つであり、「別のタスクで学習された知識を別の領域の学習に適用させる技術」のことを指します。
つまり、画像認識でよく使われるネットワークを用いて、学習済みのモデルに独自モデルを結合し、学習の精度、効率をあげるモデルを実装していきます。
ライブラリをインポート
from tensorflow.keras.layers import Dense,Dropout,Flatten,Input from tensorflow.keras.applications.vgg16 import VGG16 from tensorflow.keras.models import Model,Sequential from tensorflow.keras import optimizers import tensorflow as tf import matplotlib.pyplot as pltモデルの実装コードを細かく分けて説明していきます。 初学者のため、ふんわりした説明になっているかもしれません。モデル定義の全体像
# 出力結果の固定 tf.random.set_seed(0) # VGGモデルを作る input_tensor = Input(shape=(img_size,img_size,3)) vgg16 =VGG16(include_top=False,weights="imagenet",input_tensor=input_tensor) # 全結合層モデルを構築 top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(256,activation="sigmoid")) top_model.add(Dropout(0.5)) top_model.add(Dense(128,activation="sigmoid")) top_model.add(Dropout(0.5)) top_model.add(Dense(6,activation="softmax")) # 学習済みのvgg16と構築した別のモデルを連結する model = Model(inputs=vgg16.input,outputs=top_model(vgg16.output)) # vgg16の重みの固定 for layer in model.layers[:19]: layer.trainable =False # モデルのコンパイル model.compile(loss="categorical_crossentropy",optimizer="adam", metrics=["accuracy"]) model.summary()(1).VGG16モデル
# VGGモデルを作る input_tensor = Input(shape=(img_size,img_size,3)) vgg16 =VGG16(include_top=False,weights="imagenet",input_tensor=input_tensor)VGG16を今回の画像データに合わせて実装します。
Input_tensorをVGG16にデータを読み込む時の形(150x150x3)に設定します。(150x150)は画像のサイズ、(x3)は「r,g,b」型のカラー画像という事です。include_top=Falseは、VGG16の全結合層を使わないという意味です。全結合層部分は、この後で実装します。
weights="imagenet"は、重みはImageNetで学習したものを使いますという意味です。
(2).全結合層のモデルを構築
# 全結合層のモデルを構築 top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(256,activation="sigmoid")) top_model.add(Dropout(0.5)) top_model.add(Dense(128,activation="sigmoid")) top_model.add(Dropout(0.5)) top_model.add(Dense(6,activation="softmax"))vGG16で4次元化されたものを、全結合層では3次元で読み込むために、Flatten(input_shape=vgg16.output_shape[1:])で平滑化します。
top_model.addを使って、モデルを1層ずつ定義していきます。
top_model.add(Dense(256,activation="sigmoid"))のコードは、基本的にお決まりのコードであり、数値やsigmoidの部分を場合によって変えていきます。
数値の部分は、2の何乗かの数字、activation=は最初"leru"とするのが、ベーシックなやり方だと教わりました。sigmoidやreluは活性化関数です。top_model.add(Dropout(0.5))は、過学習を防ぐためのコードで、学習したものを50%削除しています。
top_model.add(Dense(6,activation="softmax"))は、今回6種類の動物の画像認識を行うため、数値を6と設定し、activation(活性化関数)は、画像が6種類の内どれかというのを、確率での表示に変換してくれるsoftmaxに設定します。
(3).VGG16モデルと構築した全結合層モデルの連結
# 学習済みのvgg16と構築した別のモデルを連結する model = Model(inputs=vgg16.input,outputs=top_model(vgg16.output))(1),(2)でVGG16と全結合層のモデル定義が完了したので、2つを連結します。
データをインプットする部分をinputs=vgg16.inputとし、データを出力する部分をoutputs=top_model(vgg16.output)とします。(4).重みの固定
# vgg16の重みの固定 for layer in model.layers[:19]: layer.trainable =False連結した2つのモデルを実行する際、VGG16で学習済みだった「重み」が変わらないように、上記のコードで19層目まで固定します。
(5).モデルのコンパイル
# モデルのコンパイル model.compile(loss="categorical_crossentropy",optimizer="adam", metrics=["accuracy"]) model.summary()最後にモデルをコンパイル(モデルの学習方法を決定)し、モデルの生成が終了します。
loss(損失関数)を、分類向きのcategorical_crossentropyに設定、
optimizer(最適化関数)を、adamに設定します。最適化関数は、様々な種類があるが、今回はadamが良さそうだと講師の方に教えていただきました。今後、色々試していきたいです。
metrics(評価関数)は、accuracy(正解率)と設定します。他の評価関数も存在しますが、今回のような分類の場合、accuracyと設定することが多いそうです。モデルのsummary
Model: "model_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_3 (InputLayer) [(None, 150, 150, 3)] 0 block1_conv1 (Conv2D) (None, 150, 150, 64) 1792 block1_conv2 (Conv2D) (None, 150, 150, 64) 36928 block1_pool (MaxPooling2D) (None, 75, 75, 64) 0 block2_conv1 (Conv2D) (None, 75, 75, 128) 73856 block2_conv2 (Conv2D) (None, 75, 75, 128) 147584 block2_pool (MaxPooling2D) (None, 37, 37, 128) 0 block3_conv1 (Conv2D) (None, 37, 37, 256) 295168 block3_conv2 (Conv2D) (None, 37, 37, 256) 590080 block3_conv3 (Conv2D) (None, 37, 37, 256) 590080 block3_pool (MaxPooling2D) (None, 18, 18, 256) 0 block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160 block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808 block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808 block4_pool (MaxPooling2D) (None, 9, 9, 512) 0 block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808 block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808 block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808 block5_pool (MaxPooling2D) (None, 4, 4, 512) 0 sequential_2 (Sequential) (None, 6) 2131078 ================================================================= Total params: 16,845,766 Trainable params: 2,131,078 Non-trainable params: 14,714,688参考文献:
>>画像認識でよく聞く「CNN」とは?仕組みや特徴を1から解説
https://aismiley.co.jp/ai_news/cnn/
>>【転移学習】学習済みVGG16 による転移学習を行う方法【PyTorch】
https://www.think-self.com/machine-learning/pytorch-tranfer-learning/
>>転移学習とは?AI実装でよく聞くファインチューニングとの違いも紹介
https://aismiley.co.jp/ai_news/transfer-learning/5.モデルの学習と評価
訓練データを利用してモデルの学習を行い、その後、検証データを利用してモデルの評価を行います。(1).モデルの学習
# モデルの学習 history = model.fit(X_train,y_train,batch_size=32,epochs=30,verbose=1,validation_data=(X_test,y_test))model.fitで、モデルの学習が行えます。
batch_sizeは、モデルに一度に入力するデータの数を設定します。2の何乗かで設定するのが、基本的に良いそうです。今回は、32と設定します。訓練データが720(150x6x0.8)あるので、23回目ですべてのデータの学習が完了します。
設定する値は、訓練データの数を考慮して適切に決める必要があります。値が大きすぎると、学習が早くなるが、精度は下がります。反対に、値が小さすぎると、学習時間が長くなりすぎてしまいます。epochsは、モデルの学習回数を設定します。多く設定すれば、学習率は上がりそうですが、多くしすぎると過学習を引き起こしてしまいます。逆に少なすぎると、きちんとした学習が行われないので、適切な回数を設定する必要があります。
validation_dataは、検証データの設定です。
verboseは、モデルの学習過程の表示方法を設定できます。(0:表示しない、1:表示、2:結果のみ表示)となります。
今回は、1の表示にしているので、表示内容を以下に添付しています。学習の実行結果
Epoch 1/30 23/23 [==============================] - 3s 113ms/step - loss: 1.8727 - accuracy: 0.2319 - val_loss: 1.6177 - val_accuracy: 0.4444 Epoch 2/30 23/23 [==============================] - 2s 104ms/step - loss: 1.6788 - accuracy: 0.3139 - val_loss: 1.4415 - val_accuracy: 0.6278 Epoch 3/30 23/23 [==============================] - 2s 105ms/step - loss: 1.5564 - accuracy: 0.3583 - val_loss: 1.3313 - val_accuracy: 0.6556 Epoch 4/30 23/23 [==============================] - 2s 105ms/step - loss: 1.3524 - accuracy: 0.5083 - val_loss: 1.1913 - val_accuracy: 0.7222 Epoch 5/30 23/23 [==============================] - 2s 106ms/step - loss: 1.2233 - accuracy: 0.5875 - val_loss: 1.0327 - val_accuracy: 0.7667 Epoch 6/30 23/23 [==============================] - 2s 108ms/step - loss: 1.1178 - accuracy: 0.6153 - val_loss: 0.9511 - val_accuracy: 0.7556 Epoch 7/30 23/23 [==============================] - 2s 109ms/step - loss: 0.9954 - accuracy: 0.6889 - val_loss: 0.8394 - val_accuracy: 0.8056 Epoch 8/30 23/23 [==============================] - 3s 111ms/step - loss: 0.8801 - accuracy: 0.7139 - val_loss: 0.7639 - val_accuracy: 0.8111 Epoch 9/30 23/23 [==============================] - 3s 111ms/step - loss: 0.8022 - accuracy: 0.7528 - val_loss: 0.6887 - val_accuracy: 0.8389 Epoch 10/30 23/23 [==============================] - 3s 113ms/step - loss: 0.7615 - accuracy: 0.7472 - val_loss: 0.6416 - val_accuracy: 0.8389 Epoch 11/30 23/23 [==============================] - 3s 114ms/step - loss: 0.7250 - accuracy: 0.7667 - val_loss: 0.6418 - val_accuracy: 0.8278 Epoch 12/30 23/23 [==============================] - 3s 114ms/step - loss: 0.7243 - accuracy: 0.7500 - val_loss: 0.5813 - val_accuracy: 0.8833 Epoch 13/30 23/23 [==============================] - 3s 114ms/step - loss: 0.6610 - accuracy: 0.7833 - val_loss: 0.5444 - val_accuracy: 0.8556 Epoch 14/30 23/23 [==============================] - 3s 113ms/step - loss: 0.6150 - accuracy: 0.7972 - val_loss: 0.5274 - val_accuracy: 0.8611 Epoch 15/30 23/23 [==============================] - 3s 117ms/step - loss: 0.5517 - accuracy: 0.8444 - val_loss: 0.4976 - val_accuracy: 0.8667 Epoch 16/30 23/23 [==============================] - 3s 112ms/step - loss: 0.5249 - accuracy: 0.8375 - val_loss: 0.5025 - val_accuracy: 0.8500 Epoch 17/30 23/23 [==============================] - 3s 110ms/step - loss: 0.5425 - accuracy: 0.8250 - val_loss: 0.4753 - val_accuracy: 0.8944 Epoch 18/30 23/23 [==============================] - 2s 109ms/step - loss: 0.5339 - accuracy: 0.8222 - val_loss: 0.4728 - val_accuracy: 0.8667 Epoch 19/30 23/23 [==============================] - 2s 109ms/step - loss: 0.4664 - accuracy: 0.8583 - val_loss: 0.4336 - val_accuracy: 0.8889 Epoch 20/30 23/23 [==============================] - 2s 108ms/step - loss: 0.4309 - accuracy: 0.8681 - val_loss: 0.4086 - val_accuracy: 0.8833 Epoch 21/30 23/23 [==============================] - 2s 109ms/step - loss: 0.4287 - accuracy: 0.8778 - val_loss: 0.4191 - val_accuracy: 0.8833 Epoch 22/30 23/23 [==============================] - 2s 108ms/step - loss: 0.4156 - accuracy: 0.8750 - val_loss: 0.4113 - val_accuracy: 0.8889 Epoch 23/30 23/23 [==============================] - 2s 106ms/step - loss: 0.3824 - accuracy: 0.8778 - val_loss: 0.4067 - val_accuracy: 0.8889 Epoch 24/30 23/23 [==============================] - 2s 107ms/step - loss: 0.3618 - accuracy: 0.8819 - val_loss: 0.3826 - val_accuracy: 0.8889 Epoch 25/30 23/23 [==============================] - 3s 112ms/step - loss: 0.4010 - accuracy: 0.8639 - val_loss: 0.3938 - val_accuracy: 0.9056 Epoch 26/30 23/23 [==============================] - 2s 106ms/step - loss: 0.3620 - accuracy: 0.8903 - val_loss: 0.3890 - val_accuracy: 0.8889 Epoch 27/30 23/23 [==============================] - 2s 105ms/step - loss: 0.3453 - accuracy: 0.8958 - val_loss: 0.4198 - val_accuracy: 0.8944 Epoch 28/30 23/23 [==============================] - 2s 105ms/step - loss: 0.3697 - accuracy: 0.8792 - val_loss: 0.4055 - val_accuracy: 0.8889 Epoch 29/30 23/23 [==============================] - 2s 106ms/step - loss: 0.3885 - accuracy: 0.8736 - val_loss: 0.4064 - val_accuracy: 0.8778 Epoch 30/30 23/23 [==============================] - 2s 105ms/step - loss: 0.3892 - accuracy: 0.8764 - val_loss: 0.3601 - val_accuracy: 0.8833(2).モデルの評価
検証用データを使って、モデルの評価を行っていきます。
# モデルの検証 scores = model.evaluate(X_test,y_test,verbose=1)model.evaluate(X_test,y_test)で、モデルの評価が行えます。
参考文献:
>>ニューラルネットワークのトレーニングに最適なバッチサイズについて
https://wandb.ai/wandb_fc/japanese/reports/---Vmlldzo1NTkzOTg6.実装結果の可視化
モデルの実装結果をvalやval_lossを用いてグラフで分かりやすく表示します。#lossやval_lossを可視化 loss=history.history["loss"] val_loss=history.history["val_loss"] #pochs値の設定 epochs=len(loss) #横軸epochs値、縦軸loss,val_loss値のグラフの設定、可視化 plt.plot(range(epochs),loss,marker="o",label="loss") plt.plot(range(epochs),val_loss,marker="o",label="val_loss") plt.legend(loc="best") plt.grid() plt.xlabel("epochs") plt.ylabel("loss") plt.show()上記のように、NumPy.matplotlib.pyplotを用いてグラフの表示を行います。
epochs値(学習回数)に対するval(損失)やval_lossの変動を表したグラフです。
loss(損失)とは、損失関数が出力する値の事です。損失関数とは、モデルが算出した結果の予測値と、実際の正解値のズレを計算するための関数であり、その結果出力される損失は、実際の正解値と予測値の距離や差等を指します。そのため、モデルの学習過程で、loss値が小さくなっていっているとズレが減っているという事になり、学習がうまくいっています。
val_lossは、予測に検証データを用いた場合のlossの値になります。こちらも小さくなっていくのが理想です。
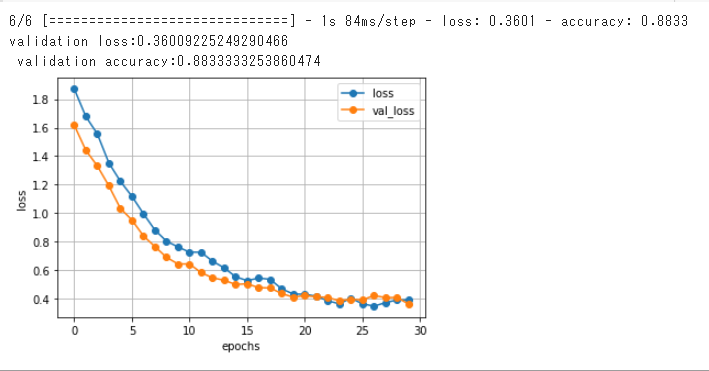
グラフの結果から、loss値やval_loss値が段々と減っており学習が上手くいっている事が分かります。
もし、val_loss値が下がらずloss値を上回るようになってしまうと、過学習が起こっているサインなので、そこで学習を止める必要があります。モデルの評価結果
#モデルの評価の可視化 print("validation loss:{0[0]}\n validation accuracy:{0[1]}".format(scores))以下、検証データを用いたモデルの実装結果です。
validation loss:0.36009225249290466 validation accuracy:0.8833333253860474validation accuracy(検証データを用いた時のモデルの予測に対する正解率)が約88%になりました。
10回やって、1.2回外れる計算なので、ある程度良い結果ではないでしょうか。参考文献:
>>モデルの可視化
https://keras.io/ja/visualization/
>>機械学習のlossが下がらない原因は?精度低下を抑える工夫を解説
https://www.tryeting.jp/column/6037/6.アプリの作成
Flaskを用いて、アプリの作成を行いました。
7.まとめ
田舎で動物に遭遇した時や、動物に畑を荒らされた時、何の動物か分かれば対応や対策ができるかと思い、田舎によく居そうな動物6種類の画像認識アプリを作成しました。画像認識の精度はある程度良くなりましたが、6種類以外の動物を読み込んだ時も、6種類の内のどれかに分類されてしまうので、6種類とそれ以外で分類させるか、分類する動物の種類を増やすという改善が必要だと感じました。
そのためには、更にデータを収集、選定する必要があるので、その知識も深めていく必要があると実感しました。今後も学習を進め、今回作ったアプリの改善をしつつ、より分類が難しいものにも挑戦していきたいです。
参考文献:
>>CNN画像認識で 野菜識別
https://qiita.com/a_tonbo/items/0696fd3fcbdeed4e64cf
>>Niziuのメンバーを機械学習で分類してみた
https://qiita.com/nkbk2525/items/9b6b254eedd311c1f932