やりたいこと
データ分析実務で、groupby関数を使ってあるカラムに対して複数の集約(mean,maxなど)を行っていると、マルチカラムとなってしまい、データが扱いにくくなることがあります。
たとえばこんなコード
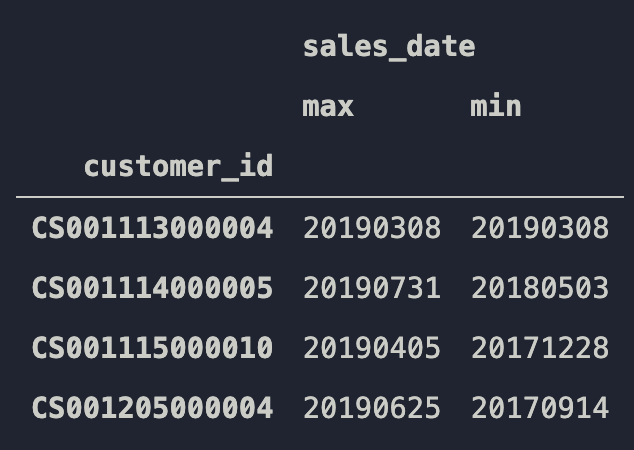
df_receipt.groupby("customer_id").agg({"sales_date":["max", "min"]})
こんなの嫌だ・・・![]()
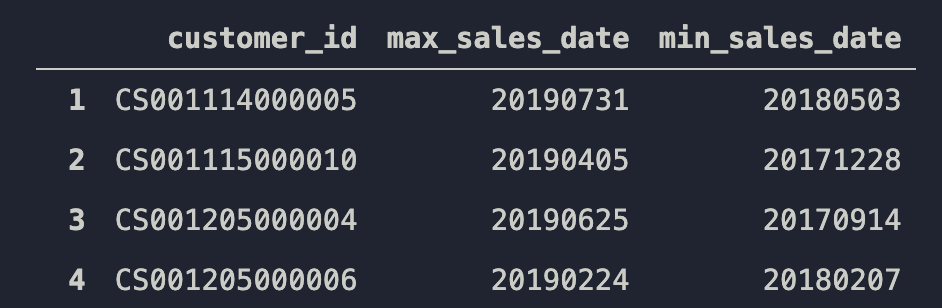
こんな感じにしたい…!![]()
やり方
やり方は以下の4ステップ。
- マルチカラムとなっているカラム以外は、indexに退避(
set_index関数) - マルチカラム→シングルカラムにする(
droplevel関数) - 集約化されたカラムに、いい感じのprefix or suffix をつける(
add_prefixoradd_suffix関数) - indexに退避していたカラムを元に戻す(
reset_index関数)
※ groupby関数を使っていると、groupby対象カラムはindexとなるので、1.は要らない場合あり
コードサンプル
# 同じカラムで複数の集約を行うときはlistで表現
tmp = df_receipt.groupby("customer_id").agg({"sales_ymd":["max", "min"]})
# マルチカラムとなっているので削除
# droplevelの対象にしたくないカラムは、indexに退避させておくのがミソ
tmp.columns = tmp.columns.droplevel(0)
# カラム名を修正して、indexを戻してあげる
tmp = tmp.add_suffix("_sales_date").reset_index()
まとめ
groupby関数はデータ分析でよく使うので、どんどん仲良くなっていきたいですね![]()