この投稿は、某秘密結社の幹部が、世を忍ぶ仮の一般人としてお送りします。
**【2015/01/16】**戦いを挑んだ結果はこちら!(→結果にワープ)
**【2015/01/14改訂】**Straming APIのオマケ話を追加しました。(→オマケへワープ!)
明後日、金曜ロードSHOW!に、アイツがまた来る!
今週(2016/01/15)、金曜ロードSHOW!であの「天空の城ラピュタ」が放送されるってご存知でしたか?
そうです。あの、伝説のクジラを呼び覚ます禁断の呪文「バルス」をTwitter民に唱えさせる、それはそれは恐ろしい映画です。
この呪文が唱えられる予想時刻は、**日本時間で2016年1月15日23時21分頃**と言われています。
シェルスクリプトで戦いを挑みたい!
あの「バルス」に、無謀にもシェルスクリプトで戦いを挑もうと目下準備中であります。
戦いとは何か……、**上映中にTwitter民が唱える「バルス」を含むツイートを全部集める。**というそれはそれは恐ろしい計画です。もしそれができたら……、(AWKやsedやgrepやらで)データマイニングして、Twitter民の何か面白い習性を見つけることができるかもしれません。
ということでこの投稿では、そのために開発したシェルスクリプトを紹介します。
進化を遂げたTwitterクライアント「恐怖!小鳥男」
昨年のクリスマスイブ、POSIX原理主義に基づくシェルスクリプト製Twitterクライアント「恐怖!小鳥男」の正体が明らかになりました。これはUNIXコマンドプロンプト上から操作できるTwitterクライアントで、最大の特徴はインストールがgit clone一発で超簡単、他言語のインストール不要、依存ソフトウェアはcURL(またはWget)とOpenSSL(またはLibreSSL)だけ、という導入までの敷居の低さ、即ち、動作可能な環境の多さ、にあります。
実はその小鳥男は、年末のコミケに向けて密かに進化していたのです。
コミケに、シェルスクリプトで戦いを挑む!
「コミケに戦いを挑む」とは、コミケ期間中にコミケ会場(東京ビッグサイト)とその周辺から発信されたツイートを全部かき集めるというという挑戦でした。
最終的には無事成功し、手元には収集したたくさんのツイートデータが貯まりました。分析してみると面白いです。例えばこれ、
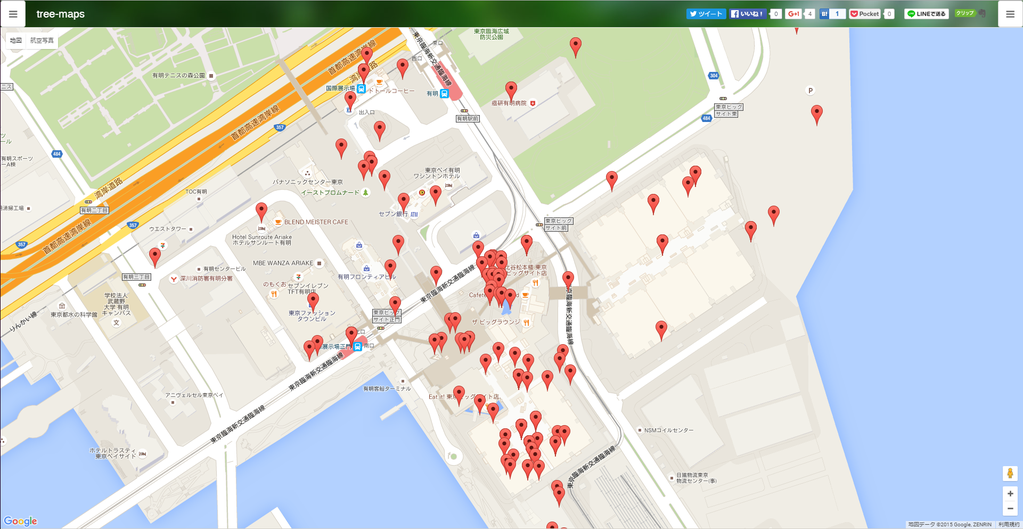
これはコミケ初日の朝10時台に発せられたツイートの座標をAWKやgrepで抜き出し、tree-mapsにコピペしてプロットしたものです。
東ホールのツイートはまばらですが西ホールのツイートは比較的多めです。やっぱり皆、企業スペースから攻めていたのではないでしょうか。
認証方法によるアクセス制限違い
で、このようなツイートをかき集めるためのシェルスクリプトを作ったわけですが、最初は小鳥男のツイート検索コマンドを、Twitterの検索アクセス制限である2秒間隔(厳密には15分で450回)でぶん回せばいいと思っていました。ところが、2秒に1回の頻度でイケると思っていたのに、何度やっても15分後にアクセス頻度に引っかかってしまいました。
検索APIドキュメントをよく見ると、アクセス頻度制限には“user auth”と“app auth”という2種類があることがわかります。ここで両者の認証方式の特徴を次にまとめます。
| 特徴\認証方式 | ユーザー認証 | アプリケーション認証 |
|---|---|---|
| 可能な操作 | 投稿(POST)系 & 閲覧(GET)系 | 閲覧(GET)系のみ |
| 閲覧可能範囲 | 非公開ツイートも閲覧可(要権限) | 公開ツイートのみ閲覧化 |
| アクセス頻度制限 | 厳しい | 比較的緩い |
| 認証の複雑さ | 複雑(OAuth1.0a) | 簡単(OAuth2.0) |
ユーザー認証は、投稿操作にも使えて、非公開ツイートも見られるのでこちらにさえ対応していればいいと思い込んでいたのですが、実は高いアクセス頻度で使いたい場合は向かないということに、私は後から気付きました。
ユーザー認証とアプリケーション認証の具体的な処理内容
コミケ本番が差し迫る中、小鳥男のアプリケーション認証への対応に急いで着手しましたが、ユーザー認証(OAuth1.0a)に比べるとアプリケーション認証(OAuth2.0)は驚くほど単純でした。両認証のデータフロー図を掲載します。
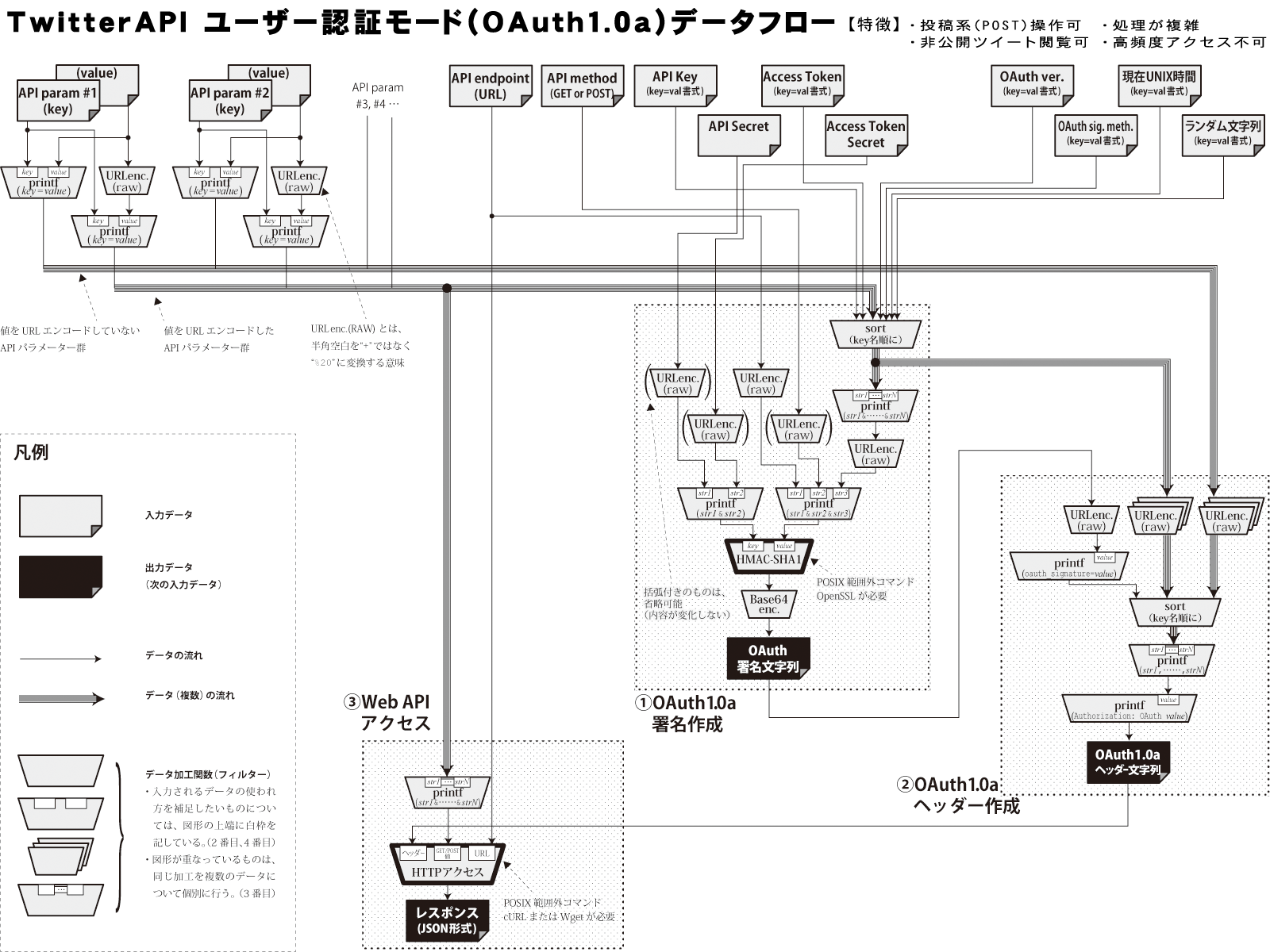
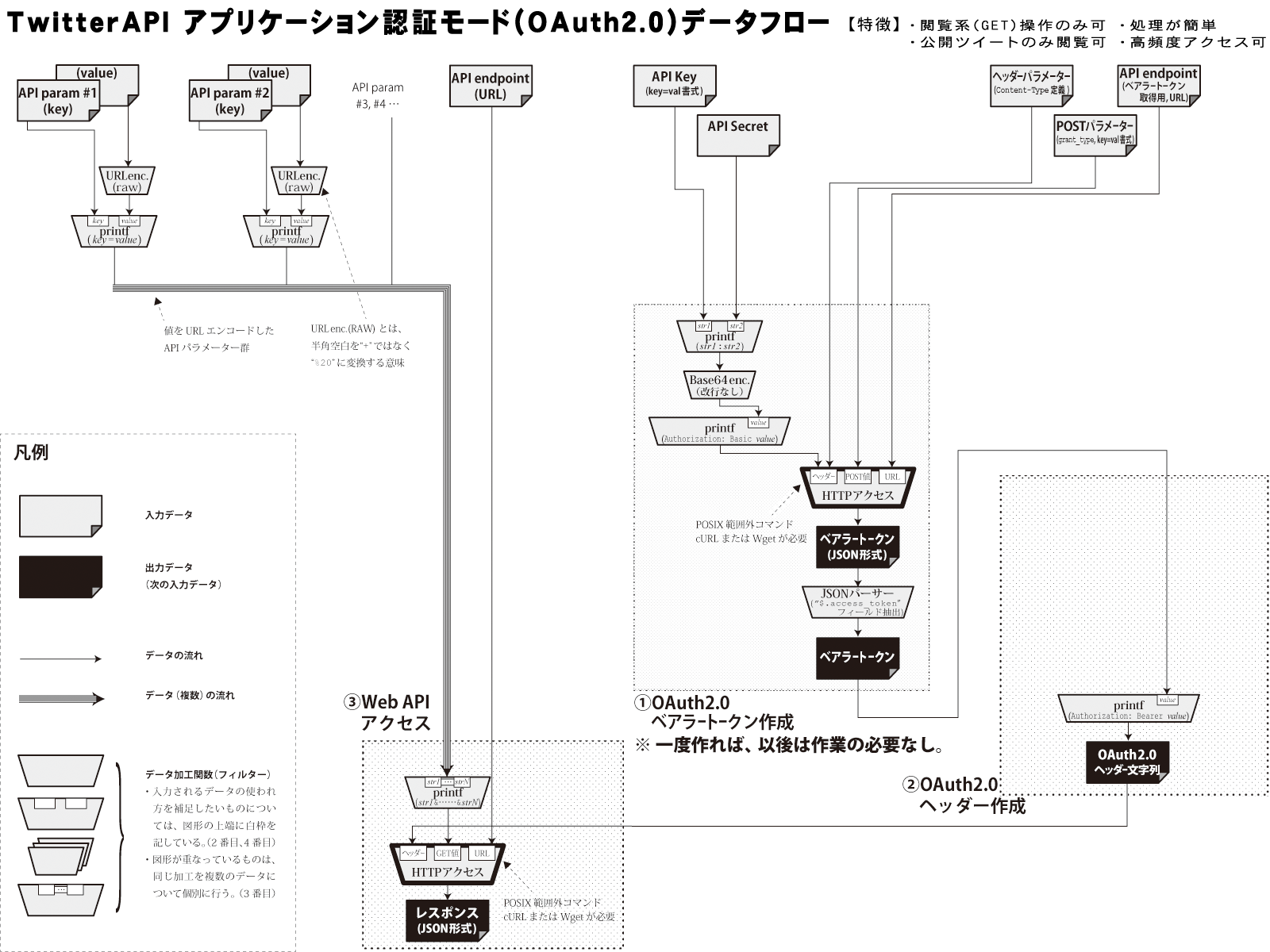
図を比較すると、アプリケーション認証は矢印線(データの流れ)と台形(処理手順)がだいぶ少ないです。しかも、①の部分は最初に一度だけやっておけばいいので、通常時は①を省略できます。なんと簡単なことか。
こうして小鳥男のコマンドとして新たに作ったのが、①の部分を担うgetbtwid.shと、アプリケーション認証版の検索コマンドbtwsrch.shでした。
実際に2秒間隔でぶん回してもアクセス頻度制限に引っかかることはなくなりました。
10並列でぶん回す!
しかしまだ完璧ではありません。Twitterサーバー、あるいはプロバイダーを含めた途中の回線が混雑していると1回の検索に2秒以上かかる恐れがあります。そこで、検索コマンドを10並列にし、各々20秒に1回の割合で2秒ずつずらしながら検索APIを叩く作戦にしました。これなら1つのコマンドの猶予は20秒まで延びます。仮に20秒以内に終わりそうになければcURLやWgetのタイムアウト機能を使って強制切断し、他のプロセスに任せます。
最終ツイートIDを共有
Twitterの検索APIには、ある時刻(ツイートIDで指定)以降のツイートだけ取得するための検索条件設定項目がありますので、各プロセスは自分が取得した最後のツイートIDを報告しあうことにより、極力重複なしでツイートを取得できるようになります。これはデータサイズを無駄に増やさないのみならず、検索プロセスの所要時間短縮のためにも重要です。
IDの共有にはファイルで十分です。特定のファイルを直接読み書きするだけ。プロセス間通信など大げさなことは全く必要ありません。ツイートIDなどたかだか十数バイトのテキストデータですので、読み書きは実質的にアトミックに行われます。つまり事実上排他制御はカーネルがやってくれているといえます。そのうえ、サイズも小さいのでオンメモリ。カーネルの機能をしゃぶり尽くすのもシェルスクリプトの醍醐味です。
.
|--- LASTID.txt (最後に取得したツイートIDを伝え合うためのファイル)
|
|--- RAW/yyyymmdd/hh/hhmmss.pid.json(取得したデータ置き場、JSON生データ)
`--- RES/yyyymmdd/hh/hhmmss.pid.txt (取得したデータ置き場、ある程度整理したデータ)
このようなアイデアに基づいて作ったのが、小鳥男のAPPSディレクトリーに収録したcomike_search.shコマンドです。
並列化はシェルで一発
comike_search.shコマンド自体は並列動作に対応しているだけで、それ自身が並列動作をしかけるようには作っていません。並列動作は次のようにしてシェルに任せれば十分だからです。
$ ./comike_search.sh 20 2 0 & ./comike_search.sh 20 2 1 & ./comike_search.sh 20 2 2 & ./comike_search.sh 20 2 3 & ./comike_search.sh 20 2 4 & ./comike_search.sh 20 2 5 & ./comike_search.sh 20 2 6 & ./comike_search.sh 20 2 7 & ./comike_search.sh 20 2 8 & ./comike_search.sh 20 2 9 &
第1引数は「検索実行間隔=20秒」、第2引数は「プロセス間の起動時間差の単位=2秒」、第3引数は「自分は何単位目で検索を実行させるか」を表しています。各々第3引数が1ずつ異なるので2秒(第2引数)の時間差で検索しにいくというわけです。
ちなみに、停止させたい場合も、次のようにしてやはりシェルで一発です。
$ jobs -l | awk '{print $2}' | xargs kill
簡単ですね。
準備は整った。あとは待つのみ。
このようにして、「バルス」に戦いを挑む準備ができました。具体的にはcomike_search.shの冒頭に書いてある検索条件を「バルス」に直したbarusu_search.shを作り、時が来たら上記の並列実行ワンライナーを実行するだけです。
果たして勝利をおさめられるのか?
ちなみに、全然関係ありませんが、私はスバルが好きです。
【オマケ】Streaming API版検索コマンドを作ってみた
コメントによりますとTwitter APIには、ツイートをリアルタイムに垂れ流すStreaming APIというものがあるそうです。しかも調べてみれば、アクセス頻度制限関係なし(繋ぎっぱなしにしておけば永遠に流れてくるので)という究極の仕様!これこそまさにバルスに勝つための最終兵器じゃないですか!
ということで、Streaming APIの一つであるPOST statuses/filterを叩くように改造したコマンドstwsrch.shを作りました。小鳥男リポジトリの2016/01/14以降のリビジョンに加えておきましたのでgit cloneして使ってみてください。(前のリビジョンから移行する人は、UTLディレクトリーの中のunescj.shも更新する必要あり)ちなみにこのAPIはアプリケーション認証かと思いきや、ユーザー認証でした。
さてそれでは、今まさに話題沸騰中の“SMAP”で検索してみましょう。
$ ./stwsrch.sh SMAP
$ ./stwsrch.sh --rawout=hoge.json SMAP # APIが吐く生のJSONも欲しい場合
$ ./stwsrch.sh --rawonly SMAP # むしろ生JSONだけ欲しい場合
するとほら、スゴい勢いでツイートが表示されますよね。
※ 画面はイメージです
まるで何かのファイルをcatしているような物凄い勢い!**Webブラウザー版のライブ検索とは何だったのか。**生JSONデータも取得していたらその尋常で無いサイズの膨れ方に驚くはずです。
「これなら絶対バルスに勝てる」
そう思っていたのですが……、どうやら日本語キーワードはダメっぽいです。全く取得できないというわけでもないみたいですが、ほとんど取得できず使いものになりません。あぁ、バルスが全角文字でなかったらなぁ……。
ということで明日の本番では当初の予定通り、アプリケーション認証モードの検索コマンドを並列実行する方法で挑みます。