はじめに
今回はk近傍法をsckit-learnで実装していきます。
よろしければ前回の記事も確認してください。
Pythonでscikit-learnとtensorflowとkeras用いて重回帰分析をしてみる
pythonのsckit-learnとtensorflowでロジスティック回帰を実装する
k-近傍法について
k-近傍法(k-nearest neighbor)は分類と回帰の両方に用いられるアルゴリズムです。
似たものにk-平均法(k-means)などがありますが、別物なので注意してください。
以下はwikipediaの引用です。
k近傍法(ケイきんぼうほう、英: k-nearest neighbor algorithm, k-NN)は、特徴空間における最も近い訓練例に基づいた分類の手法であり、パターン認識でよく使われる。最近傍探索問題の一つ。k近傍法は、インスタンスに基づく学習の一種であり、怠惰学習 (lazy learning) の一種である。その関数は局所的な近似に過ぎず、全ての計算は分類時まで後回しにされる。また、回帰分析にも使われる。
この説明でもなんとなく理解できると思いますが、解説します。
n次元数ベクトルの特殊空間があり、あるデータの特殊空間の位置はn個の説明変数で決定され、そのデータが属するクラスは目的変数により決定されます。
n次元数ベクトルの特殊空間には当然、データ間の距離が存在します。基本的にk-近傍法ではユークリッド距離を用います。
分類において、ある目的変数が未知のデータが与えられた時、そのデータの目的変数を特殊空間上に近い他のデータの目的変数の多数決で決定するのが、k-近傍法です。
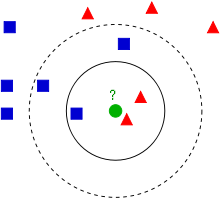
多数決を行うとき、どれくらいの距離を近傍とするのかで分類が異なります。上記の画像の例だと、小さい円を近傍としたときこの緑のデータは赤い三角だと予想されます。しかし、大きい円を近傍としたとき、この緑のデータは青い四角だと予想されますよね。
このように、k-近傍法で分類を行うときはどれくらいを近傍とするのかを決めなければいけません。
また、回帰のときは未知のデータが与えられた時、特殊空間における近傍のデータの目的変数の平均をそのデータの目的変数とします。
分類問題の実装
それでは分類モデルをk-近傍法で実装してみましょう。
今回用いるデータはiris(アヤメ)データセットです。
iris(アヤメ)データセットについて
irisデータは、アヤメという花の品種のデータです。
アヤメの品種であるSetosa、Virginica、Virginicaの3品種に関するデータが50個ずつ、全部で150個のデータです。
実際に中身を見ていきましょう。
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
print(iris_df.head())
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
iris.feature_namesに各々のカラム名が格納されているので、それをpandasのDataframeの引数に渡すことで上のようなデータを出力できます。
Sepal Lengthはがく弁の長さが、Sepal Widthにはがく弁の幅が、Petal lengthには花びらの長さが、Petal Widthには花びらの幅のデータが格納されています。
以下のようにすれ正解ラベルを表示できます。
print(iris.target)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
データセットの準備
以下のコードでデータセットを準備しましょう。
from sklearn.datasets import load_iris
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
iris_target_data = pd.DataFrame(iris.target, columns=['Species'])
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
X_train, X_test, Y_train, Y_test = train_test_split(iris_df, iris_target_data)
print(iris_df)
print(iris_target_data)
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
.. ... ... ... ...
145 6.7 3.0 5.2 2.3
146 6.3 2.5 5.0 1.9
147 6.5 3.0 5.2 2.0
148 6.2 3.4 5.4 2.3
149 5.9 3.0 5.1 1.8
[150 rows x 4 columns]
Species
0 0
1 0
2 0
3 0
4 0
.. ...
145 2
146 2
147 2
148 2
149 2
[150 rows x 1 columns]
train_test_splitを用いて、訓練用とテスト用にデータを分けました。
以下のコードでk-近傍法のモデルを作成しましょう。
knn = KNeighborsClassifier(n_neighbors=6)
knn.fit(X_train, Y_train)
n_neighborsにより、近傍として取り扱うデータの数を指定しています。今回は、近傍の6個のデータに対して多数決をとることにします。
次のコードで精度を評価しましょう。
Y_pred = knn.predict(X_test)
print(metrics.accuracy_score(Y_test, Y_pred))
0.9210526315789473
predictにより、引数に渡したデータをもとに目的変数を予測します。また、metrics.accuracy_scoreによりY_testとY_pred)の一致率を算出しています。
92.1パーセントとなかなかの精度で予測することができました。
次のコードで、近傍とするデータの数を変更していき、精度がどれくらいに変化するかを図示していきます。
accuracy_list = []
sns.set()
k_range = range(1, 100)
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
accuracy_list.append(metrics.accuracy_score(Y_test, Y_pred))
figure = plt.figure()
ax = figure.add_subplot(111)
ax.plot(k_range, accuracy_list)
ax.set_xlabel('k-nn')
ax.set_ylabel('accuracy')
plt.show()
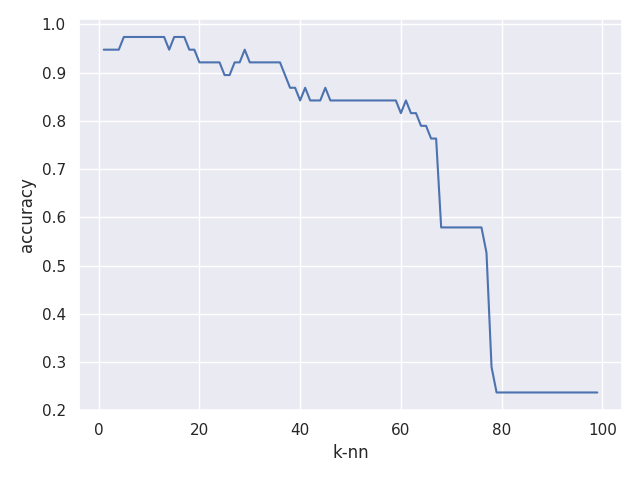
上図をみると、kが60を超えたあたりで急激に精度が落ちています。これは、もともとアヤメのデータセットには一つの種類のデータが50個しかないためであり、一定以上のn_neighborsにおいては精度が落ちるのは当然といえます。
ここまでで分類問題は終了です。
回帰問題の実装
次は回帰問題を実装していきます。使用するデータセットはボストンデータセットです。
13個の説明変数をもとに住宅価格を予測していきます。
以下のモジュールをインポートしましょう。
import pandas as pd
import seaborn as sns
from pandas import DataFrame
from sklearn.model_selection import train_test_split
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
次はデータセットの準備です。
以下のコードでデータセットを準備しましょう。
また、学習に使うデータを確認しましょう。
boston = load_boston()
boston_df = DataFrame(boston.data)
boston_df.columns = boston.feature_names
print(boston_df)
X_train, X_test, Y_train, Y_test = train_test_split(boston_df, boston.target)
CRIM ZN INDUS CHAS NOX ... RAD TAX PTRATIO B LSTAT
0 0.00632 18.0 2.31 0.0 0.538 ... 1.0 296.0 15.3 396.90 4.98
1 0.02731 0.0 7.07 0.0 0.469 ... 2.0 242.0 17.8 396.90 9.14
2 0.02729 0.0 7.07 0.0 0.469 ... 2.0 242.0 17.8 392.83 4.03
3 0.03237 0.0 2.18 0.0 0.458 ... 3.0 222.0 18.7 394.63 2.94
4 0.06905 0.0 2.18 0.0 0.458 ... 3.0 222.0 18.7 396.90 5.33
.. ... ... ... ... ... ... ... ... ... ... ...
501 0.06263 0.0 11.93 0.0 0.573 ... 1.0 273.0 21.0 391.99 9.67
502 0.04527 0.0 11.93 0.0 0.573 ... 1.0 273.0 21.0 396.90 9.08
503 0.06076 0.0 11.93 0.0 0.573 ... 1.0 273.0 21.0 396.90 5.64
504 0.10959 0.0 11.93 0.0 0.573 ... 1.0 273.0 21.0 393.45 6.48
505 0.04741 0.0 11.93 0.0 0.573 ... 1.0 273.0 21.0 396.90 7.88
このように、13個の説明変数を持つデータが506個格納されています。
次のコードで学習モデルを作成します。
knr = KNeighborsRegressor()
knr.fit(X_train, Y_train)
Y_pred = knr.predict(X_test)
mae = mean_absolute_error(Y_test, Y_pred)
rmse = np.sqrt(mean_squared_error(Y_test, Y_pred))
print('平均絶対誤差: ', mae)
print('二乗平均平方根誤差:', rmse)
平均絶対誤差: 4.206456692913386
二乗平均平方根誤差: 5.715249114513284
このようにしてモデルを評価することができました。今回、n_neighborsに値を設定していないのでデフォルトの5となっています。
平均絶対誤差は誤差の絶対値を平均したものであり、二乗平均平方根誤差は誤差の二乗を平均して平方根をとったものとなっています。
次のコードで、平均絶対誤差をn_neighborsに対してプロットしていきましょう。
mae_list = []
sns.set()
k_range = range(1, 100)
for k in k_range:
knn = KNeighborsRegressor(n_neighbors=k)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
mae_list.append(mean_squared_error(Y_test, Y_pred))
figure = plt.figure()
ax = figure.add_subplot(111)
ax.plot(k_range, mae_list)
ax.set_xlabel('k-nn')
ax.set_ylabel('mae')
plt.show()
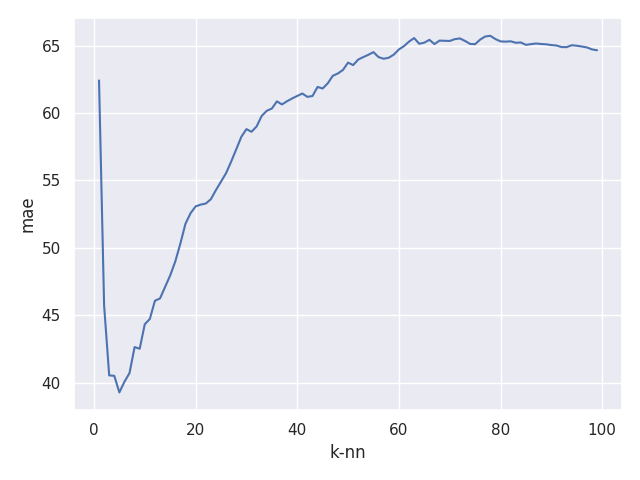
以上の結果より、k-nn=6ぐらいのデータが比較的よく回帰できていることが分かりますね。
ここまでで回帰問題は終了です。
終わりに
今回の記事はここまでとなります。
ここまでお付き合いいただきありがとうございました。
お疲れさまでした。