1.はじめに
みなさんはじめまして!未経験からWebエンジニア就職を目指している文系大学4年生です!
エンジニア就職、転職を考えている方は必ず目にするであろう、企業様の募集要項「実務経験 ~以上の方」という一文。未経験とプロのエンジニアの間に途方もない差があるのは承知ですが、プロのエンジニアの方にはどんな世界が見えているのだろかそしてエンジニアとしてお給料をいただくというのはどういうことなのか。そんな疑問から実務案件をこなしたいと考えていました。
そんなある日、ご縁があり実務案件に携わらせていただく機会がありましたので、未経験が初の実務案件をこなしてみての実務の活動内容や未経験とプロのエンジニアはここがちがうんだな〜と感じた部分を書き残しておきたいと思います。
実務案件をとおしてエンジニアとして働くということの「価値観が180度」良い意味で変わった体験でしたので一読していただけると幸いです。
また同じような疑問を頂いている方の参考に少しでもなれると幸いでございます。
2022/01/04 追記:新たな実務案件記事
別の実務案件も記事にしましたのでよろしければ覗いてみてください!
( PHP, Laravel, Chart.js, Dokcer, Circle CI AWS(EC2, RDS, Cloud Formation)などを使ってます )
2.4行で自己紹介
- Webエンジニア就職を目指す文系大学4年生(休学中)
- プログラミングを使って母の職場の課題解決をきっかけにWebエンジニアを目指す
- 趣味はIotディバイスを部屋に導入して生活を豊かにしたり読書したりすること
- 案件前のAWSの知識はほぼゼロ(S3ってなに?ってレベル)
3.こんな人に読んでほしい
- 未経験からエンジニアを目指している方
- 実務案件てどんなことするんだろ?と疑問をお持ちの方
- 未経験とプロのエンジニアの違いってなんだろ?と疑問をお持ちの方
- 企業のデータ分析ってどんなことをどのようにやっているの?と疑問をお持ちの方
- 駆け出しエンジニアが成長する物語が読んでみたい方
4.使用した技術
- AWS(Athena, CLI, CloudWatch, EC2, Glue, IAM, KMS, QuickSight, RDS, S3)
- cron
- シェルスクリプト
- SQL
5.最終的なインフラ構成図と作業内容
最終的なインフラ構成図

最終的な作業内容の一連の流れ
①MasterRDSのスナップショットからマスキング用RDSの作成
②マスキングRDSでマスキング処理
③スナップショットを取得
④取得したスナップショットをS3にエクスポート
⑤S3データをCrawlerを使用しデータ整形化しDataCatalogにメタデータとして保存
⑥Athenaでクエリ実行、クエリ結果テーブル作成
⑦QuickSightにて可視化
クエリを打たずに単純な可視化であれば、Athenaを介さずDataCatalogをQuickSight直接参照もできます。
一連の流れを自動化とその方法
①〜④まではcronにて定期実行
⑤はCrawlerの定期実行処理設定にて定期実行
⑦は一度作成したしたら自動でダッシュボードを開いた際に自動で最新のものに更新される
**最終的にこの形で実務案件を終えました!**今はこのツールは何なんだ?的なものがたくさんあるかもしれませんが、「活動内容」のセクションではじめて見る方でもわかるように1つ1つ説明していくので安心して読みすすめていっていただければと思います。
6.案件の経緯
そろそろこう思われる方がいるかも知れません「結局君はなにをしたの?」
はい、おまたせしました。いえおまたせしすぎたのかもしれません!ってことでここから具体的に実務案件の内容を細かく記して行きます。
クライアントからの要望
クライアントが運用している自社サービスのデータのモニタリング体制が構築できておらず、気軽にデータ分析ができないためデータ分析体制を構築してほしいとのことでした。

(クライアントから実際にいただいた画像)
当初のサービスのモニタリング体制図
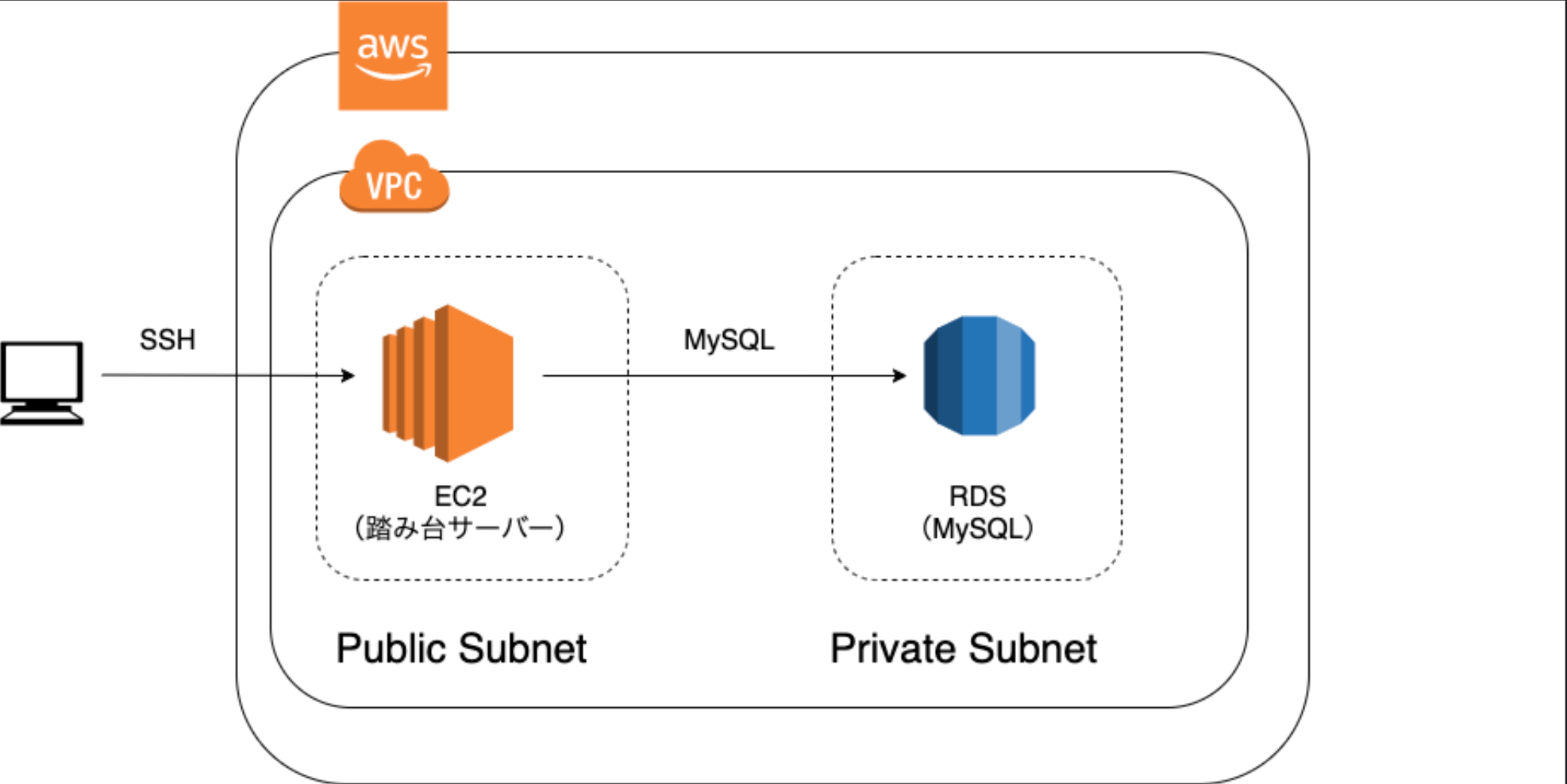
EC2を踏み台サーバーとしてMySQLにログインし、MySQL内でSQLコマンドを用いてデータの確認をしている状況。EC2へSSH接続をしてからMySQLへログインという段階を踏む必要があるため手軽にデータを確認できない。また、ユーザーに関わる情報を数値化して定期的にモニタリングすることができないという課題がありました。
私はこの段階でこう思いました。クライアントが求めていることがざっくりすぎる、、、
そうなんです。ポートフォリオ作成では間違いなく意識しないポイントですがクライアントの要望というのはざっくりしている場合が多いとのこと。そのために「要件定義」という作業をおこなっていきます。
7.活動内容
ここまでの振り返り
ここまでで自己紹介、最終結果、案件内容の解説がおわりました。ここからが実際の活動内容になりますのでこれまでの情報と答え合わせをするような形でお楽しみくださいませ。
7-1.要件定義編
7-2.技術選定編
7-3.タスクばらし編
7-4.データモニタリング体制の構築編
7-5.定期実行編
7-6.マスキング処理編
7-1 ~ 7-6で全ての活動内容が分かる形にしております。
7-1.要件定義編
クライアントから課題があたえられたらまずは課題を解決するためにクライアントと要件定義(要求を考慮し、システムとして必要な要件をまとめること)のすり合わせをおこないます。
要件定義の前に要求分析(相手の要望を抽出し分析すること)を行ったが今回は割愛します。
要件定義は以下のようになりました。
- 要件定義:機能要件
- データベースに直接アクセスできる
- SQLを自由に叩ける
- モニタリング指標の各項目が数字として表示される
- モニタリング指標の各項目がグラフ化して見ることができる
- モニタリング指標の各項目を自由に変更できる
- ユーザー管理機能(アクセス権限の設定)
- 要件定義:非機能要件
- 個人情報は閲覧できない
- 読み込み専用にする
- 本番DBに負荷がかからない
- インターフェイスはデザイン崩れしない
- 画面は3秒以内に表示できるようにする
- 指定されたユーザーのみ、ユーザー管理を自由に行えるようにする
- 死活監視:モニタリングサービスが落ちたら検知できる
- エラー監視:エラーが発生したら検知できる
- 運用コストの上限は5000円/月
7-2.技術選定編
この段階ではどうやってモニタリング体制を整えるのか一寸の光も差し込まないほど見通しが立っていませんでした。
自分で調べたり、知り合いのエンジニアの方に企業では通常どのようにモニタリング体制を整えるのかきいてみるとBIツールというものを使うとクライアントの課題を解決できそうという結論に至りました。
BIツール
BIツールとは「ビジネスインテリジェンスツール」の略で、企業に蓄積された大量のデータを集めて分析し、可視化して、迅速な意思決定を助けるのためのツールのことです。
ものすごーく簡単に言うとデータ分析に特化したWebアプリケーションで有料から無料のものまでさまざまで、使える機能もそれぞれで異なります。
BIツール検討比較表
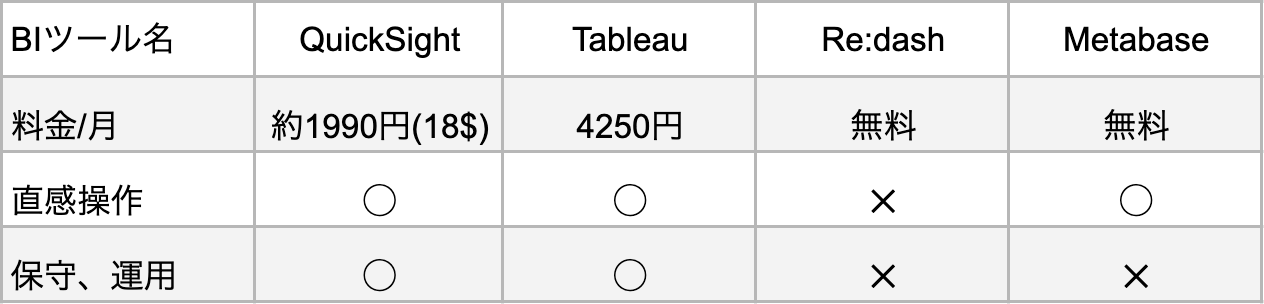
- 比較要素
- 運用コスト(全体のコストが月に5000円前後なのでBIツールは2000円以内が望ましい)
- 直感的な操作(外部委託予定があるので直感的な操作ができること)
- 保守、運用(手間が減らせるようクラウドで完結するBIツールが望ましい)
検討した結果今回は**「Amazon QuickSight」**を使用することにしました。
他ツールの不採用の理由
Tableau -> 予算オーバーの為
Re:dash -> GUIでの直感操作ができない為
Metabase -> 環境構築、サーバー運用が必要なので運用保守の必要がある為
Amazon QuickSight(以下QuickSight)についてご紹介
イメージしやすいようにQuickSightの魅力について記載します。
1.さまざまなデータソースに対応している
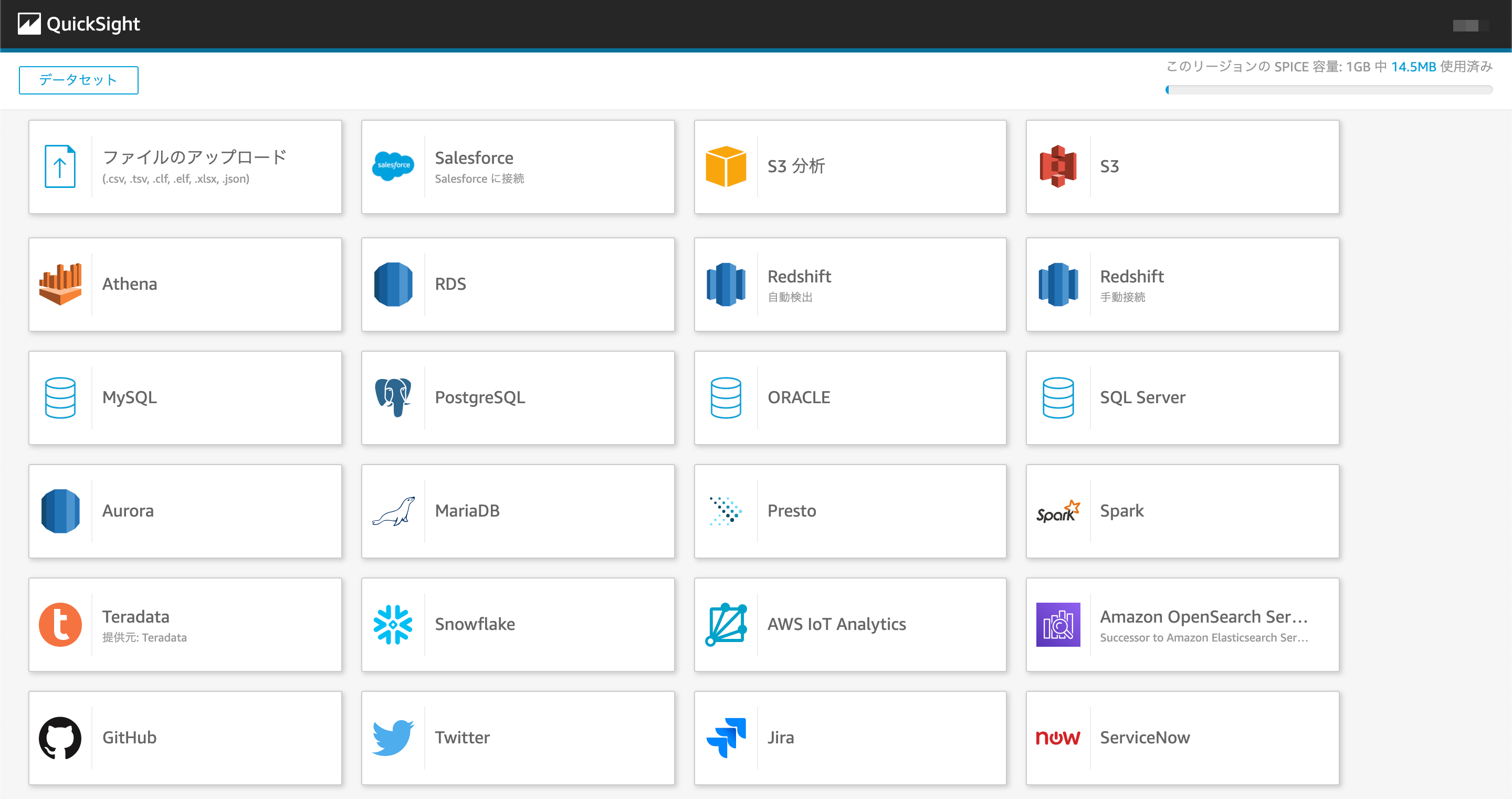
QuickSightはAWSのサービスなのでRDS,S3,Athena等の様々なデータソースにアクセス可能
2.多彩なグラフ作成とドラック&ドロップで直感的な操作が可能
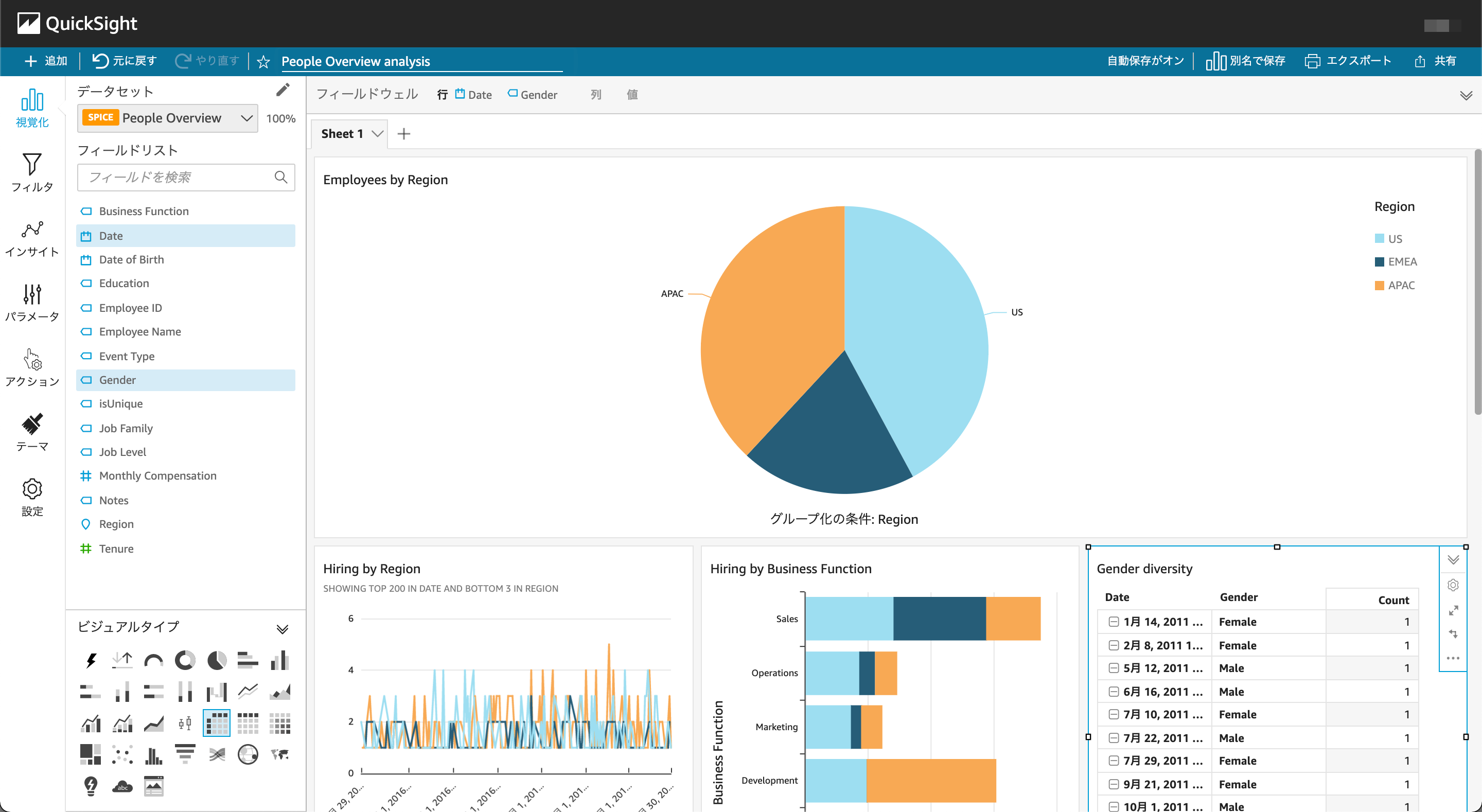
多彩なグラフ作成をすることができる上に作成したグラフはドラック&ドロップで操作することもできるので直感的に操作ができます。外部委託も考えると直感的に操作ができるという点がとてもよかったです。
3.複数アカウントの管理が容易
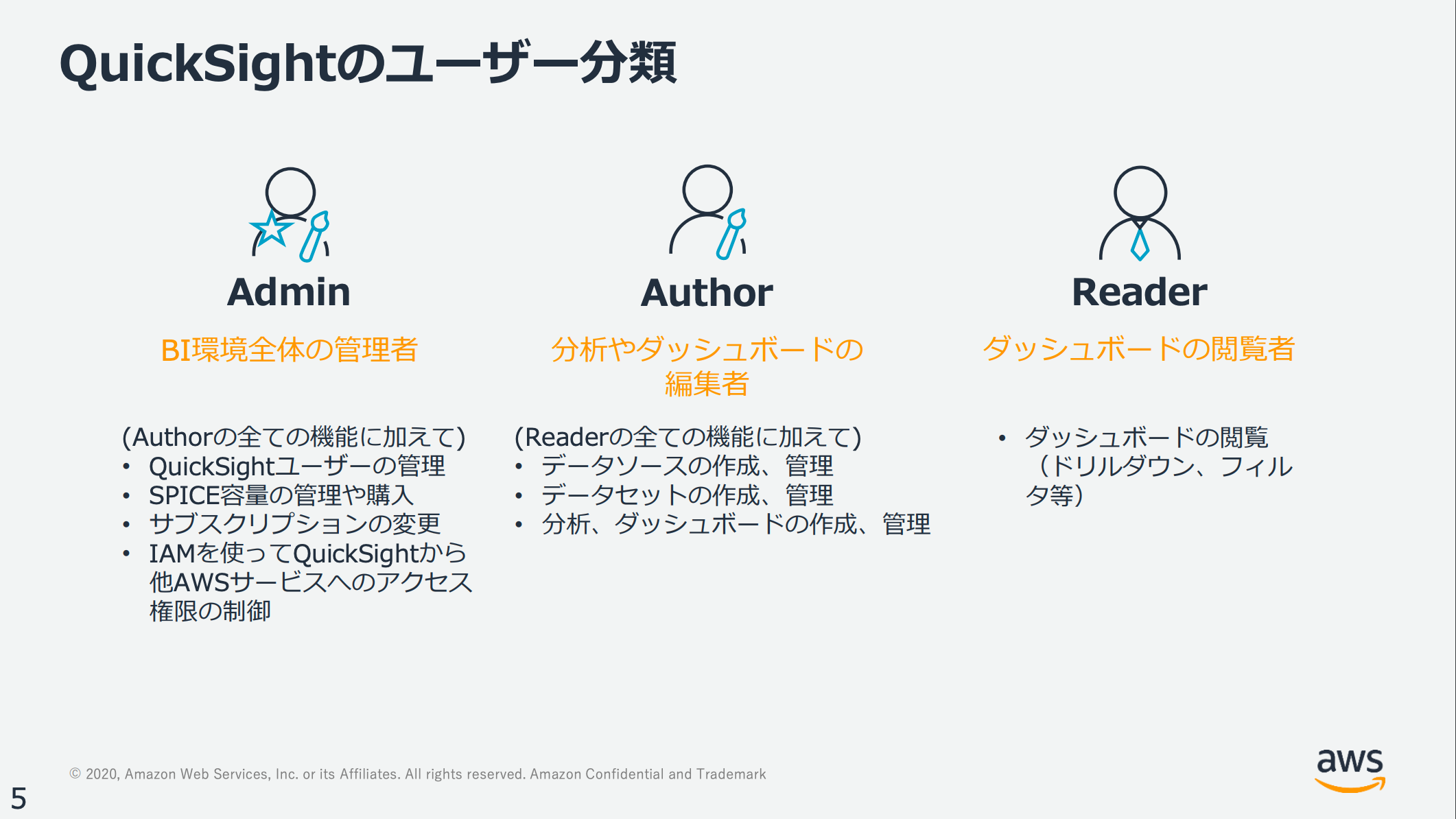
https://aws.amazon.com/jp/blogs/news/quicksight-matome-20201014/ より
Admin, Author, Readerの3種類でサービスが用意されておりIAMユーザーで管理することができるので、招待するときもG-mail等を使えばすぐに招待できるのでアカウントの管理が容易でセキュリティ面も安心です。
7-3.タスクばらし
タスクばらしでは全体の作業量と進め方を確認するために実装でやるべきタスクを全て洗い出す作業です。達成すべきゴールまでの道のりをしっかりと1つ1つのタスクに落とし込むことで迷わずにゴールまで進むことができます。また進んでいる実感も湧くのでモチベーション維持にも繋がります。
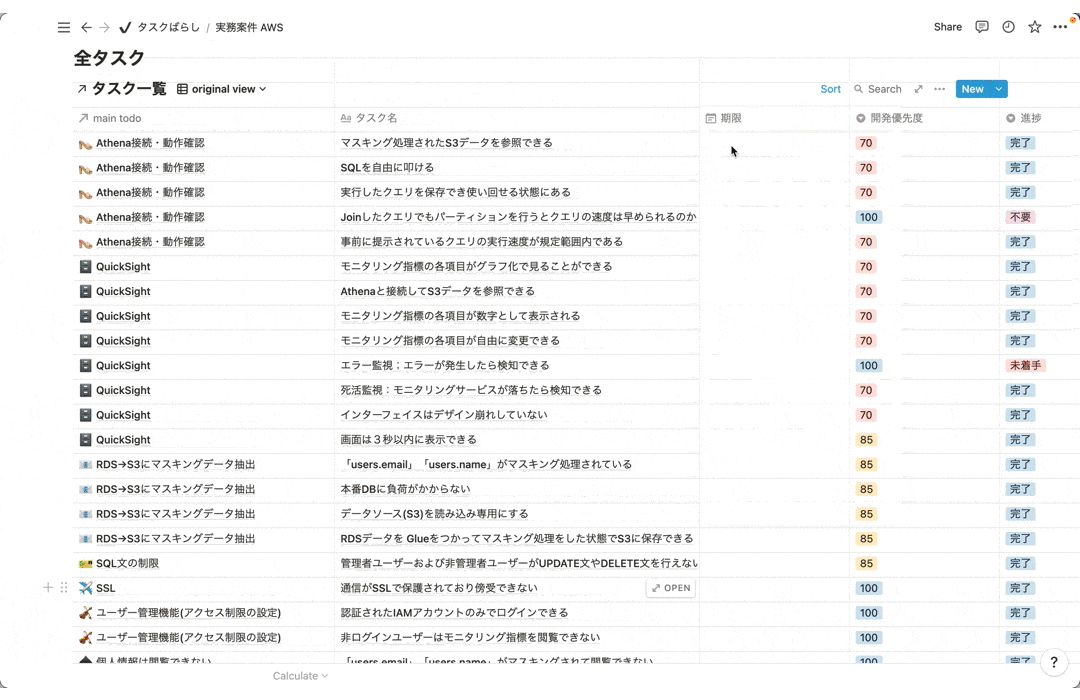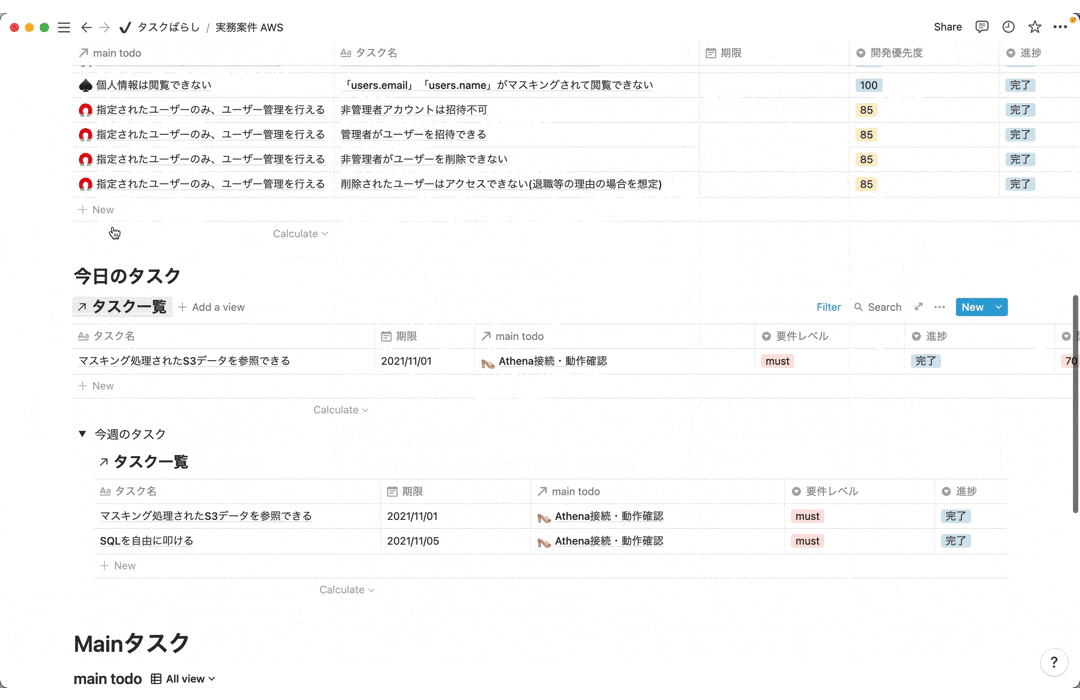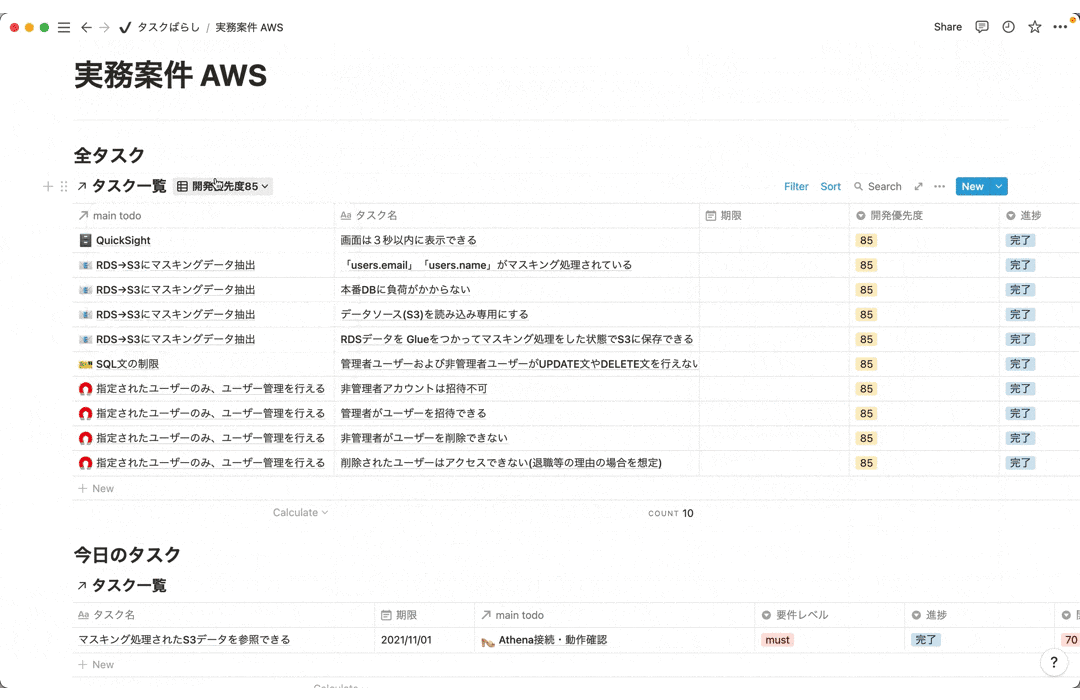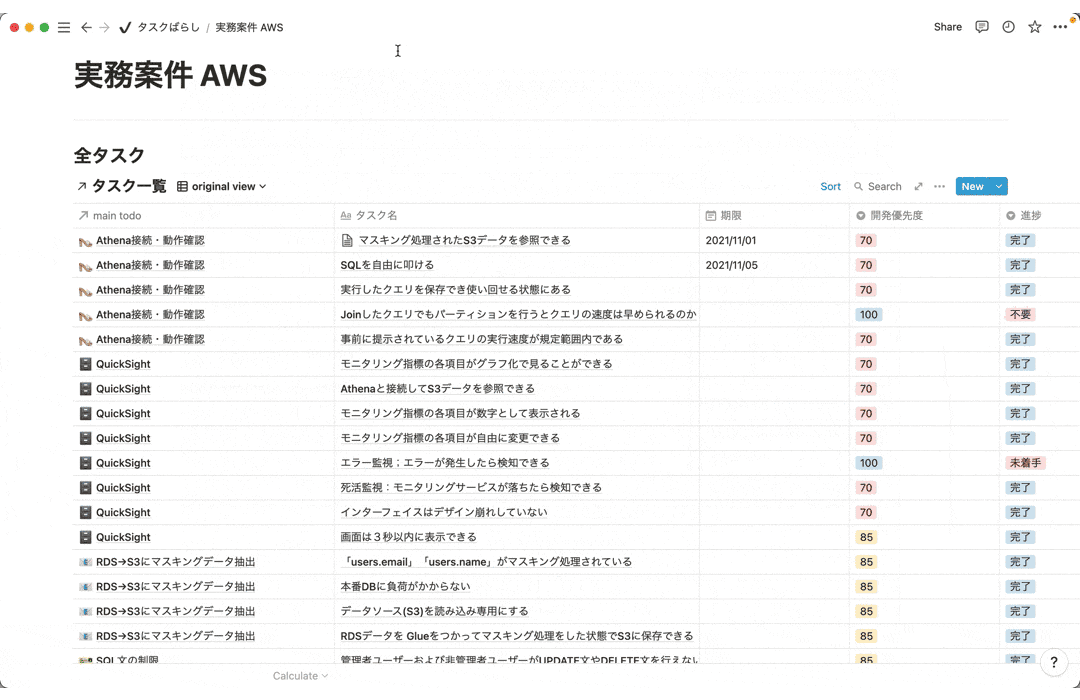
見やすいように一部抜粋、内容削除してます。
意識したこと
1.タスクをとことん細分化する
・ゴールまのでプロセスをしっかりとタスクに落とし込む。
・1タスクは1時間で終わる目安で作っていった。
2.テンプレートの自作
・全体のタスクが確認できるように上段に配置。
・上段で期日を入力すれば、下段の「今日のタスク」「今週のタスク」に自動で表示されるようにしており期日遅れを防ぐ仕組みづくり。
・開発の際の優先度を考えて「開発優先度レベル」ごとに確認できるように工夫。
・作業期間がある程度長いのでタスクごとにメモできるようにしてすぐに見返せるように工夫。
株式会社ソニックガーデン様の記事に感銘を受けてに「タスクばらし」をおこなって作業をしていきました。作業の進み具合がしっかりと把握でき1つ1つ達成していく感覚が楽しくてしかたなくなり、かつゴールを見失わずに進むことができました!。このときから作業をするときは必ず「タスクばらし」をおこなうようにしています。
7-4.データのモニタリング体制の構築編
ここから実際にAWSのマネジメントコンソールを使ってモニタリング体制を構築していきました。現状で作り上げたものが下の図のようなものです。

ここで作ったものは至ってシンプルで簡単に説明すると
①RDSからスナップショットを作成
②RDSからS3にスナップショットをエクスポート
③Glueを使ってデータカタログを作成
④Athenaでクエリを実行
⑤QuickSightでデータの可視化
もうすこし粒度を細かくして①~⑤について、1つ1つ説明します。
現状ではかなり致命傷な問題があるのでどこに問題があるのかを探す気持ちで読んでいただけると次の7-5.定期実行編で謎が解明されるので探してみてください!(IAM, KMSなど作業に直接的に関わらないものは割愛します。)
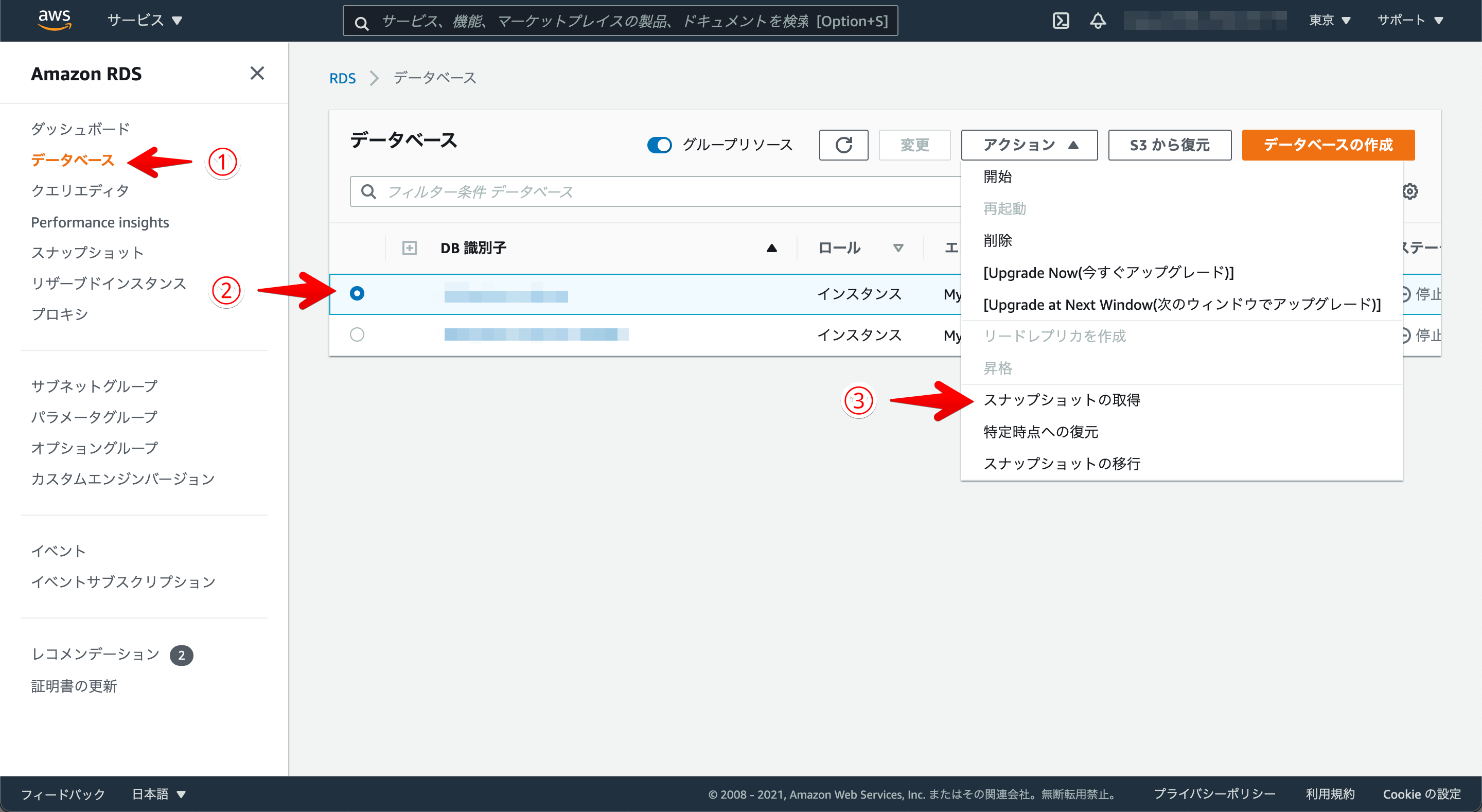
①RDSからスナップショットを作成
AWSを使ったことがある人なら必ず一度は見たことがあるであろうRDSのマネジメントコンソールから、①②③の3stepでスナップショットが作成されます。
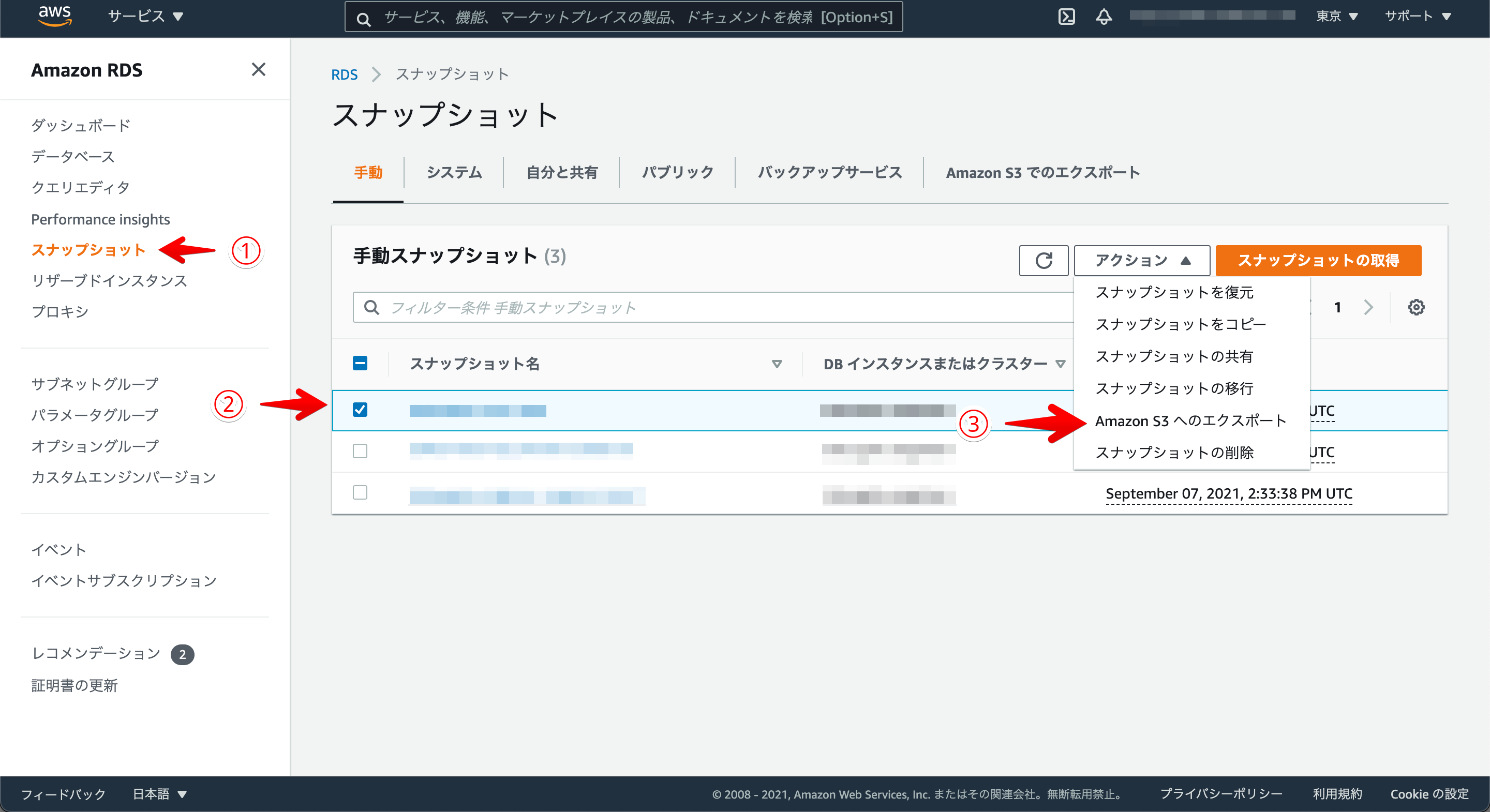
②RDSからS3にスナップショットをエクスポート
こちらも同じくRDSのマネジメントコンソールからS3におくりたいスナップショットを決めたら①②③の3stepでRDSのスナップショットがS3にエクスポートされます。なおエクスポートはスナップショットのデータ量にもよるが私の場合はだいたい40分くらいかかりました。
③Glueを使ってデータカタログを作成
Glueを使うとAthenaでクエリを打つのが大変容易になります。まずはGlueっ言ってるけどなんのこと?となると思うのでGlueの説明をします。これから説明する箇所は下記画像の工程のところです!

さて、本題ですAWS Glueとは?
AWS Glueはデータの抽出や変換、ロードを簡単に行えるフルマネージド型サービスのこと。サーバーレスのため自分で管理、運用する事必要がありません。AWS Glueの機能はたくさんあるが今回使ったのは次の2つです。
- Glue Crawler
- データストア(S3等)のデータ構造を推測して、DataCatalogに表構造を登録するサービス
- Glue Data Catalog
- メタデータ(テーブル構造等)を管理するリポジトリ機能。Glue Crawlerを使用しData Catalogを作成することによっってデータを分析しやすいように整形する
ものすごーく簡単にいうとAthenaをつかってS3にクエリを打つためにS3にある単純なデータを解析してメタデータ(テーブル構造をもつ)に自動で整形してくれるというものです。
ここでのポイントはAthenaはS3にあるデータに対してクエリを実行しているということです。なにをいっているかと言うとS3はただのデータの保存場所なので保存の際にテーブルやカラムなどは考慮されていません。そこでAWS Glueの機能を使ってデータ解析をおこない、単純なデータをメタデータ(テーブル構造をもつ)にすることでクエリが実行できるようになるということです。
この工程を挟むことでAthenaですんなりSQLクエリを実行できるようになるというわけです!
④Athenaでクエリを実行
実際にAthenaを使ってSQLクエリを実行してみます。こちらもGlueのおかげでとても簡単でこれまで通り①②③の3stepで実行結果が表示されます。③の箇所でSQL文を書き込めば普段使っているSQLとなんら変わりなくクエリを実行できます。
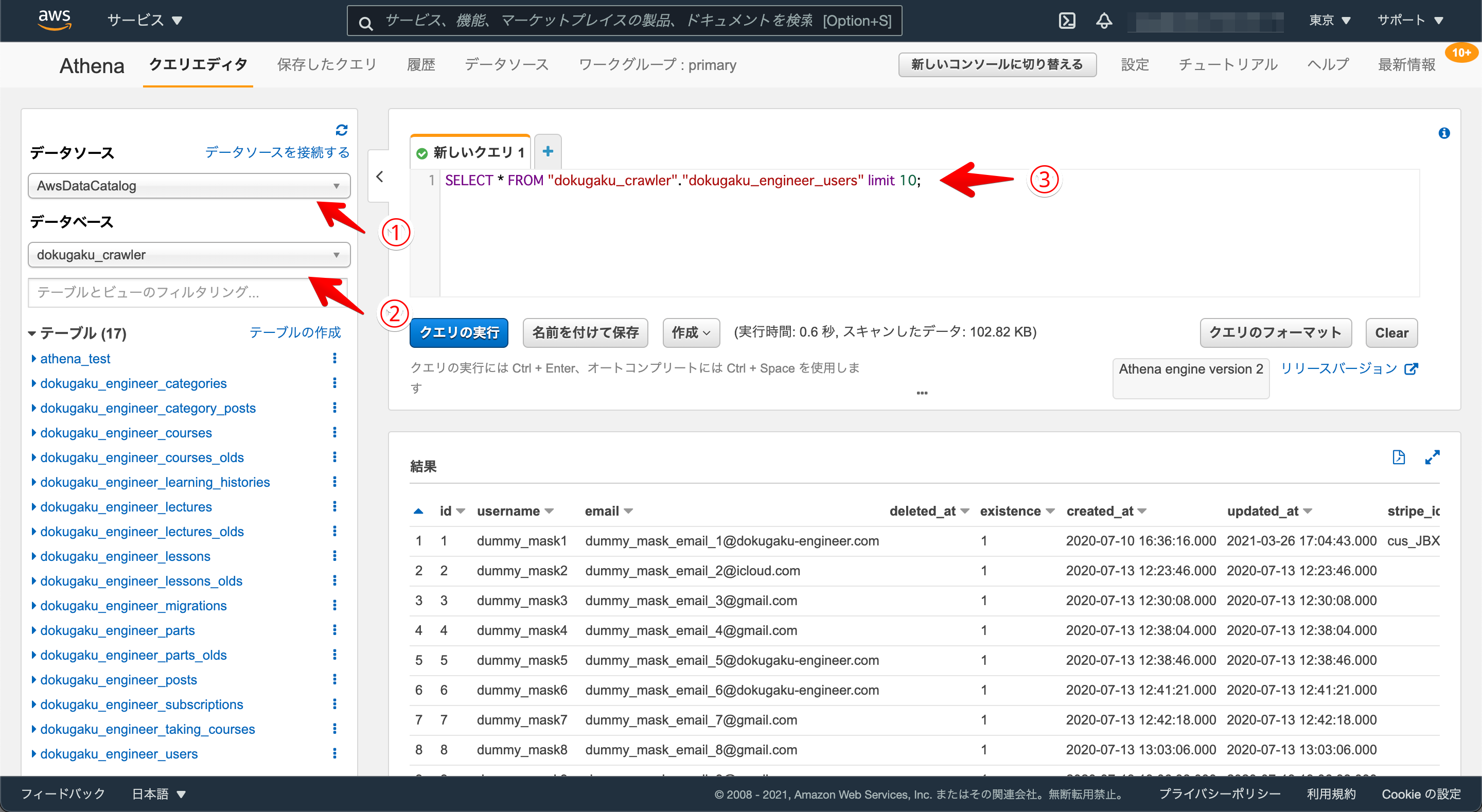
(表示されているデータはマスキング済みのものを使用しています)
⑤QuickSightでデータの可視化
いよいよ7-4.データのモニタリング体制の構築編もおおずめ。QuickSightでデータの可視化をおこないます。こちらも操作はいたってシンプルで
①表示したいビジュアルタイプを選ぶ
②フィールドウェルの欄にフィールドリストのところからカラム名をドラック&ドロップ
こうしてやっとの思い出でデータ可視化を実現することができました。
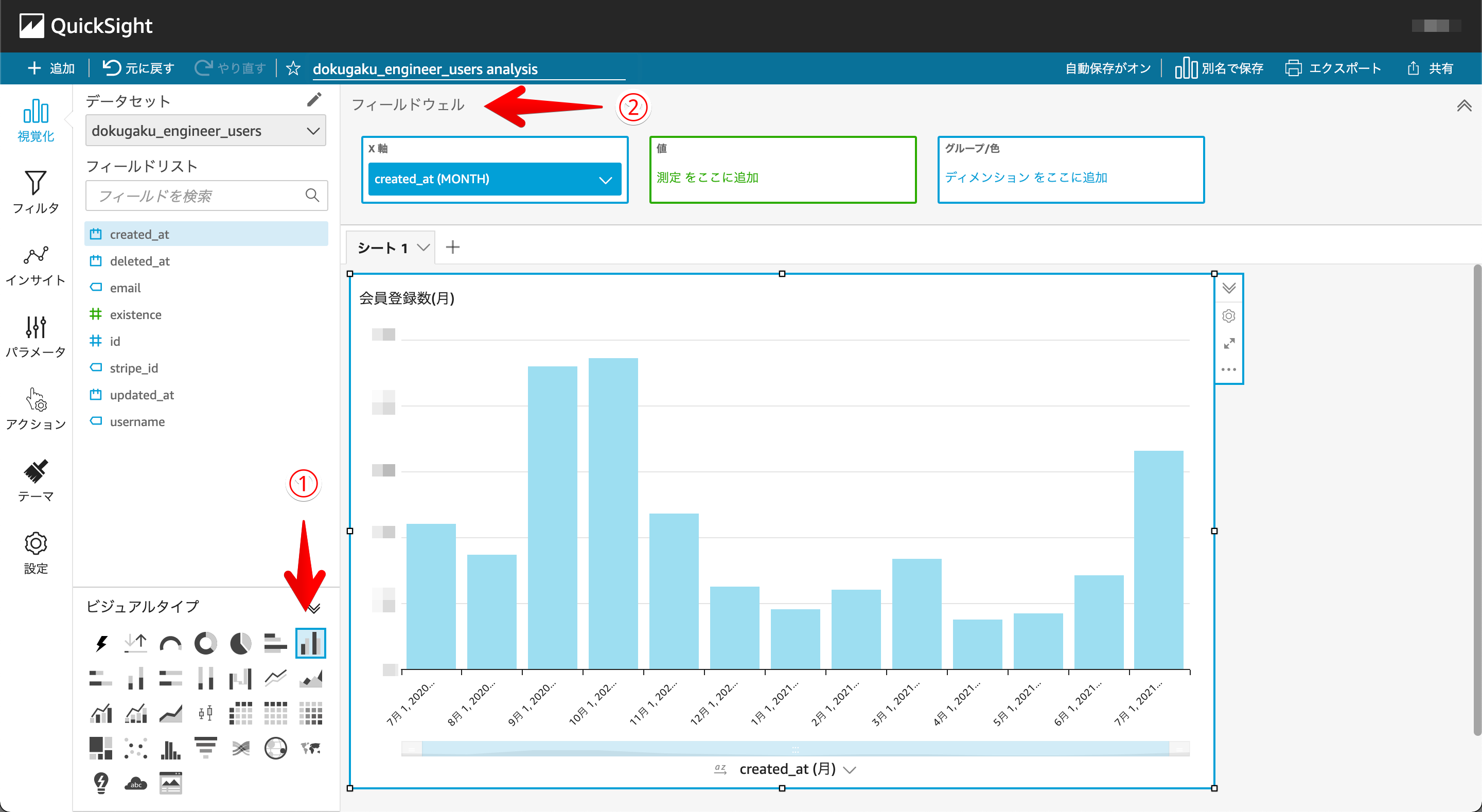
(月別会員登録数を表示)
ここでのポイントは2つあって
1つ目がQucikSightではAthenaに登録されているテーブルを簡単に可視化できることです。
2つ目がAthenaでSQLクエリを実行した結果も可視化できる。例えばSQLのWhere句やGroupBy句などを使った複数のテーブルを参照したデータの可視化をすることができるということです。
さて、ここまでで7-4.データのモニタリング体制の構築編は終わりになります!この時点での私は「おおお!データ分析できた!と満面の笑み」でやりきったぜと思っていました。一見しっかりデータの可視化ができていてモニタリング体制が整っているかのように見えますが、しかし最初に申し上げた通り現状では致命的な問題があります。読者のみなさまは気づくことができましたでしょうか??答え合わせは次の章になります。
7-5.定期実行編
7-4.データのモニタリング体制の構築編では全ての操作をGUI操作(画面をマウスでポチポチ)でおこなっていたが、ここでクライアントからこんなフィードバックをいただきました。
![]() 「最新のデータをみるのに毎回画面をポチポチして更新しないといけないのかい?」
「最新のデータをみるのに毎回画面をポチポチして更新しないといけないのかい?」
いわれてみればそのとおりで、データのモニタリングにしか注意がいっておらず最新のデータに更新されること、日々の使いやすさにフォーカスできていませんでした。現状のソリューションでは最新のデータにするのに毎回7-4.データのモニタリング体制の構築編でおこなった操作を行わなければ最新のデータにはなりません。操作時間+待ち時間で1時間以上はかかってしまいます。
読者の皆様も考えてみてください。自分が彼女や彼氏とデートのために本気でダイエットをしようと決意しました。アプリを使ってダイエット記録をとろうとしたが、記録の操作と反映に毎日1時間以上もかかってしまう。そのダイエットは成功するでしょうか...
言うまでもないですよね。しかし私のこの時点でのソリューションは「最新の記録にするのに操作してから待ち時間を含めて1時間以上かかってしまう」そんな状態でした。
ここでのポイントは「最新の記録にするのに操作してから待ち時間を含めて1時間以上かかってしまう」ということ。これが致命的な問題点です。ここを解決していくのがこのセクションになります!
私がこの問題を解決するためにとった方法はGUI(画面をマウスでポチポチ)で操作していたものをCUI(コード化)にしていく方法です。
私も驚いたのですが今まで画面でポチポチしていた作業は、コードに置き換えてまとめて実行することができ、更にそのコードを定期実行することもできるんです!そこで活躍するのがAWS CLIとcronです。
AWS CLIとは
AWSコマンドラインインターフェイスの略でコマンド操作によってAWSのサービスを構築できます。今までAWSのマネジメントコンソールからGUI(画面ぽちぽち)で行っていた操作をCUI(コマンドで実行)で同じことができます。
例えばこんな感じ
$ aws s3 mb s3://bucket-name
EC2のLinux上で記載して実行するだけでS3バケットが作成できます。
AWSマネジメントコンソール上でS3を表示してバケット作成を押してバケット名を入力してなどの工程がなくなります。
cronとは
cronはあらかじめ作成した実行ファイルを決められた時間、頻度で定期実行してくれる機能のことです。
例えばこんな感じ
* 1 * * * bash /home/ec2-user/periodic-execution-export.sh
こう書くと毎日1時(UTC時間)にperiodic-execution-export.shという実行ファイルを定期実行してくれます。
ここでのポイントは2つ
- AWS CLIを使ってGUIでおこなっていた作業をCUI(コード化)してシェルスクリプトとしてまとめる
- cronはAWS CLIでまとめたコードを定期実行してくれる
使用したツールの説明が終わったので実際に問題を解決していきます。
これからコード化していくのは赤枠の部分!
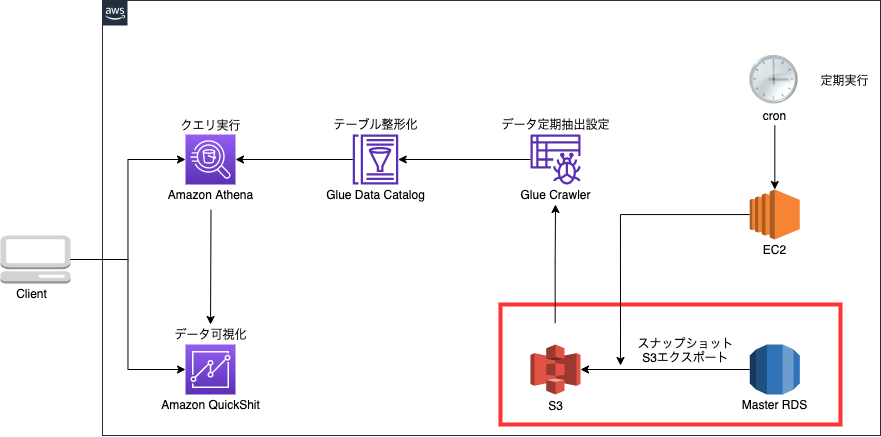
これらを踏まえてコード化、シェルスクリプトにしたのが以下になります。
※S3バケット、RDSのサブネットグループ、パラメーターグループ、KMSkey、IAMロール等都度作り直す必要がない物に関しては予めGUI操作にて作成しています。
#!/bin/bash
#awsコマンドが格納されているファイルまでの絶対パスを変数に格納
SCRIPT_DIR=~/.local/bin/aws
echo ${SCRIPT_DIR}
#スナップショットのエクスポートの際にオブジェクト名が重複するとエラーが起きるため、既存のS3バケット内のオブジェクト削除
${SCRIPT_DIR} s3 rm s3://S3バケット名/S3ファイル名
#RDS識別子を変数に格納
db_instance=dokugaku-engineer
#RDSからスナップショットを作成
${SCRIPT_DIR} rds create-db-snapshot \
--db-instance-identifier ${db_instance} \
--db-snapshot-identifier 作成したいスナップショット識別名
#スナップショット取得開始に5分ほどかかるため待機
sleep 5m
#RDSの情報から最新のスナップショット名取得
SNAPSHOT_NAME=$(aws rds describe-db-snapshots \
--db-snapshot-identifier ${db_instance} \
--query 'reverse(sort_by(DBSnapshots,&SnapshotCreateTime))[0].DBSnapshotArn' --output text)
echo ${SNAPSHOT_NAME};
#S3のバケットオブジェクト名が重複するとエラーが起きるので日時でバケットオブジェクト名が変化する識別子名の作成
NOW_TIME=$(date "+%Y%m%d%H")
EXPORT_NAME="myexport-${NOW_TIME}"
echo ${NOW_TIME};
echo ${EXPORT_NAME};
#エクスポートに必要な情報を変数に格納
S3_BUKET_NAME=S3バケット名
KMS_KEY_ID=作成したKMSキーのID
IAM_ROLE_ARN=使用したいIAMロールのArn
# RDSのスナップショットをS3にエクスポート
${SCRIPT_DIR} rds start-export-task \
--export-task-identifier ${EXPORT_NAME} \
--source-arn ${SNAPSHOT_NAME} \
--s3-bucket-name ${S3_BUKET_NAME} \
--kms-key-id ${KMS_KEY_ID}
--iam-role-arn ${IAM_ROLE_ARN}
#エクスポートに40分程度かかるため待機
sleep 1h
#Glue Crawlarを使った定期クロールのためにS3ファイル名変更
${SCRIPT_DIR} s3 mv s3://${S3_BUKET_NAME}/${EXPORT_NAME} s3://${S3_BUKET_NAME}/s3-export --recursive
#エクスポートが完了したスナップショット削除
${SCRIPT_DIR} rds delete-db-snapshot \
--db-snapshot-identifier 作成したいスナップショット識別子名
この作業はひたすらaws公式リファレンスとにらめっこで、try&errorの繰り返し。一気に全てを実行するのではなく1つ1つのツールごとにコード化していって成功するかを確認してから別々に成功したコードを最後にまとめる形でなんとか定期実行の仕組みを作ることができた。
ここで大変だったポイントは2つ。
- 最新のスナップショットデータを取ってくるコマンド作成
- RDSスナップショットをS3エクスポートする際の識別子名を都度変更
特に2.に躓いたのでもう少し細かく記載したい。
何が大変だったかと言うと「RDSからS3へエクスポートする識別子を削除するコマンドが用意されていなかったこと」です。S3へエクスポートとするときに識別子が重複するとエラーになってしまう。どういうことかというと、単に定期実行を繰り返しているとエクスポート識別子は固定になりエラーになってしまう。そこでこの課題を解決するために2.の方法をとった。
2.の結果がこんな感じ
myexport-2021103101
myexport(固定)-年/月/日/時間
エクスポート時の日時を含める関数を用意して識別子の重複を防ぎエラーを回避できるようにしました。
なんとかtry&errorを繰り返しながら定期実行の仕組みを作ることができました。最初は定期実行に関して右も左もわからなかった状態でしたが自分なりにかなり意識したポイントがあってそれは「むやみやたらに調べない」です。具体的には自分が何を実現したくてそれを実現するために何が必要なのかをはっきりさせてから調べるようにしていました。さらに調べるだけでなくメモをとってしっかりと言語化、構造化したことでやりきることができたと思います。
(実際のメモ)
こうして無事にGUI操作をCUI操作にして定期実行の仕組みを作ることができました。
そしてこのときは思ってもいませんでした。この後さらなる試練がまっているなんて...(次回、活動編最終章)
7-6.マスキング処理編
7-5.定期実行編での作業で完全におわったと思っていた私ですが、クライアントにこんなフィードバックをいただきました。
![]() 「可視化されているデータが個人情報漏洩しちゃってるよね?」
「可視化されているデータが個人情報漏洩しちゃってるよね?」
完全に想像外のフィードバックでした。これは例えるなら「織姫と彦星が七夕の日!以外に偶然であったときのような衝撃」を受けました。本人たちは1年に一回しか会えないと思っているのに衝撃ですよね。私も実務案件に関わらなければ間違いなく意識することができなかったであろう出会いでした。
ここでのポイントは、将来的に外部委託を考えるとサービスを利用しているユーザーの個人情報が見えてはならないということです。
いよいよ「活動内容」最終章で、最後の怒涛の追い込みがはじまります。
これからマスキング処理していくのは赤枠の部分!
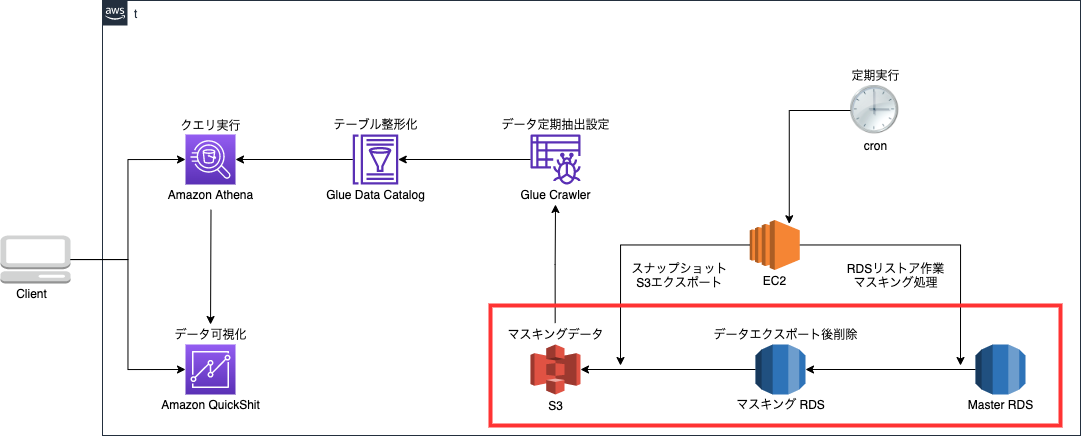
まずは耳馴染みのない「マスキング処理」について解説させてください。
マスキング処理
言葉で説明するより画像で説明したほうがわかりやすいと思ったので下記画像を見てください!
ものすごーく簡単に言うと、登録しているユーザーの個人情報が誰にでも見れると問題だから個人情報を変換して別の形に変換する処理のことです。
たとえばこんな感じ
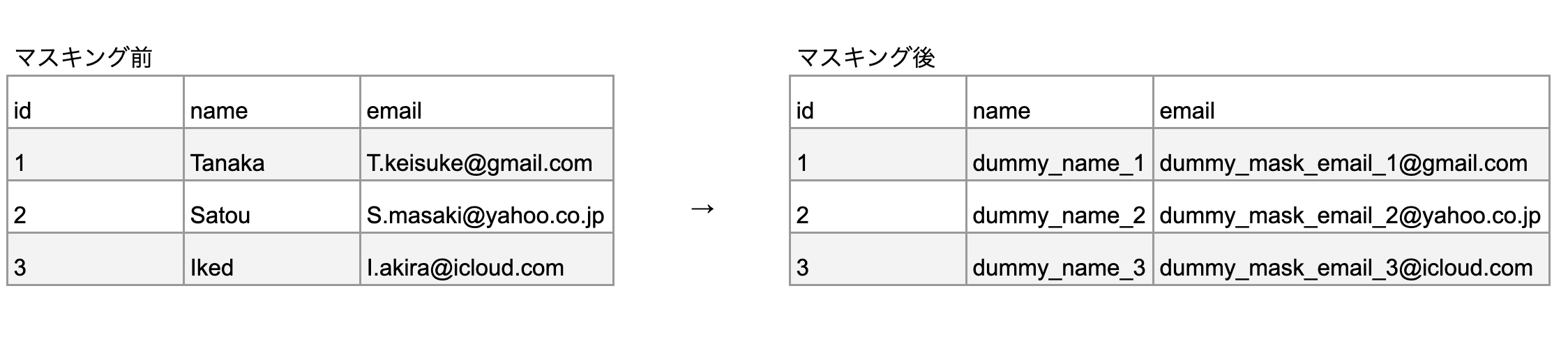
左から右にすることで個人情報を閲覧をできないようにします。
今回のマスキング処理で重要なポイントはこの2つ
・本番環境のデータベース(MasterRDS)に負荷をかけずにデータのマスキング処理を行うためにマスキングRDSをMasterRDSのスナップショットから作成してSQLを使ってマスキング処理をおこなう。
・マスキング前の元データを分析者含め閲覧できないようにマスキングRDSはS3にエクスポート後、削除する。
マスキング処理のSQLはこんな感じ
#!/bin/sh
use [マスキングするテーブル名];
#usernameのマスキング処理 `new_dummy_id`で記載
update users set username= replace(username, username, concat('dummy_mask_',id));
#emailのマスキング処理 `new_dummy_email_id`で記載
update users set email= replace(email, left(email,instr(email,'@')- 1), concat('dummy_mask_email_',id));
マスキング処理の正体はものすごーく簡単にいうとSQLで置換処理してるってことです(他にもやり方はあるので今回の場合)
実際にマスキング処理されたデータはこんな感じ
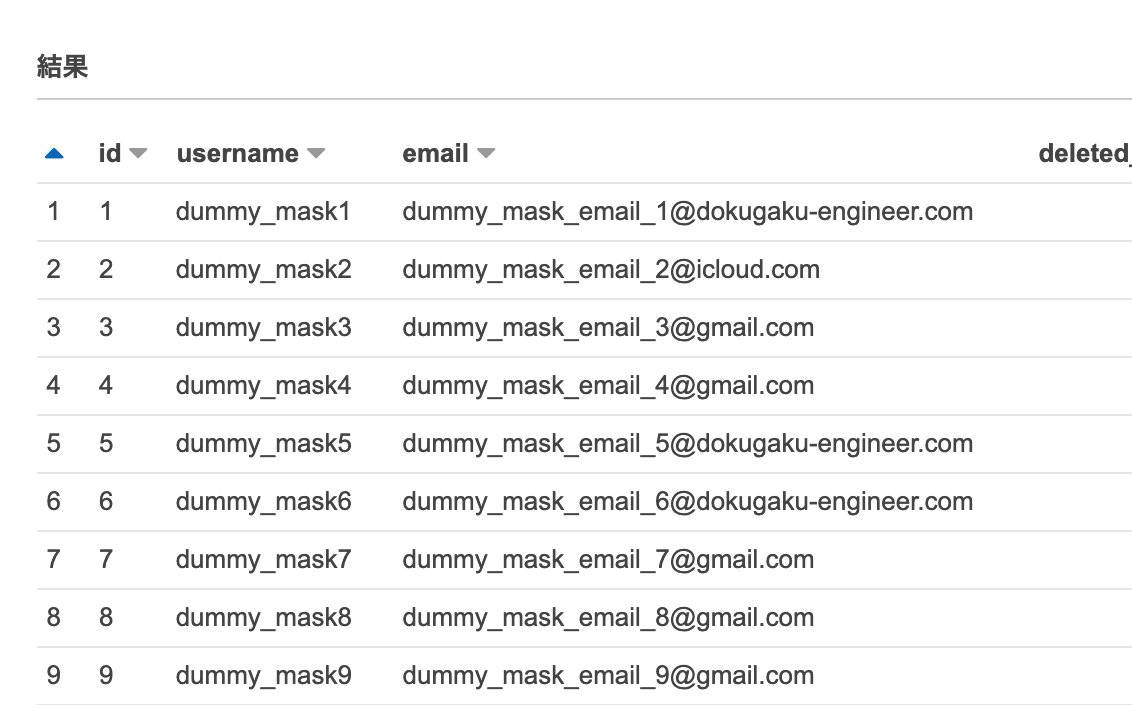
こうして無事に個人情報の流出を防ぐ仕組みを作ることができました。
しかし、ここで作業終了ではありません。マスキング処理も定期実行の処理に含めなければならないので7-5.定期実行編で作成したシェルスクリプトをアップデートしていきます。
アップデートした箇所はおおきく2つです。
1.マスキングRDSの作成と削除
2.マスキング処理の追加(masking.sqlディレクトリに格納)
重複している箇所も多いので追加したコードにだけコメントをつけてます。
#!/bin/bash -l
SCRIPT_DIR=[絶対パス]
echo ${SCRIPT_DIR}
${SCRIPT_DIR} s3 rm s3://[S3バケット名]/[S3ファイル名] --recursive
db_instance=dokugaku-engineer
SNAPSHOT_NAME=$(${SCRIPT_DIR} rds describe-db-snapshots \
--db-instance-identifier ${db_instance} \
--query 'reverse(sort_by(DBSnapshots,&SnapshotCreateTime))[0].DBSnapshotArn' --output text)
echo ${SNAPSHOT_NAME}
#変数に格納
db_new_instance=[作成したいデータベース識別子の名前]
instance_class=db.t2.micro
subnet_group=[指定したいサブネットグループ名]
security_group_id=[セキュリティグループID]
parameter_group_name=[パラメーターグループ名]
region=[指定したければリージョン名(任意)]
snapshot=SNAPSHOT_NAME
#MasterRDSからマスキングRDSをリストア
リストア
${SCRIPT_DIR} rds restore-db-instance-from-db-snapshot \
--db-instance-identifier ${db_new_instance} \
--db-snapshot-identifier ${SNAPSHOT_NAME} \
--db-instance-class ${instance_class} \
--db-subnet-group-name ${subnet_group} \
--vpc-security-group-ids ${security_group_id} \
--db-parameter-group-name ${parameter_group_name} \
--availability-zone ${region} \
--no-multi-az \
#リストアしたマスキングRDS使用可能になるまで待機
${SCRIPT_DIR} rds wait db-instance-available --db-instance-identifier ${db_new_instance} --region ap-northeast-1
#マスキング処理
mysql --defaults-extra-file=/var/tmp/mysql.conf \
-h dokugaku-masking.c4ntgclabrz3.ap-northeast-1.rds.amazonaws.com -u de_master \
dokugaku_engineer < ~/masking.sql
sleep 10
#スナップショットを取得
${SCRIPT_DIR} rds create-db-snapshot \
--db-instance-identifier ${db_new_instance} \
--db-snapshot-identifier [作成したいスナップショット識別子名]
#スナップショット取得開始まで少々時間がかかるので5分待機
sleep 5m
#マスキングRDSの最新のスナップショット名取得
SNAPSHOT_NAME=$(aws rds describe-db-snapshots \
--db-instance-identifier ${db_new_instance} \
--query 'reverse(sort_by(DBSnapshots,&SnapshotCreateTime))[0].DBSnapshotArn' --output text)
echo ${SNAPSHOT_NAME};
NOW_TIME=$(date "+%Y%m%d%H")
EXPORT_NAME="myexport-${NOW_TIME}"
echo ${NOW_TIME};
echo ${EXPORT_NAME};
ARN_NAME=[エクスポート先のS3バケットのarn名]
KMS_KEY_ID=[作成したkmsキーのID]
IAM_ROLE_ARN=使用したいIAMロールのArn
${SCRIPT_DIR} rds start-export-task \
--export-task-identifier ${EXPORT_NAME} \
--source-arn ${SNAPSHOT_NAME} \
--s3-bucket-name ${ARN_NAME} \
--kms-key-id ${KMS_KEY_ID}
sleep 1h
${SCRIPT_DIR} s3 mv s3://[ファイルが格納されているS3バケット名]/${EXPORT_NAME} s3://rds-for-s3/my-s3-export3 --recursive
${SCRIPT_DIR} rds delete-db-snapshot \
--db-snapshot-identifier ${SNAPSHOT_NAME}
# マスキングRDSの削除
${SCRIPT_DIR} rds delete-db-instance \
--db-instance-identifier \
--skip-final-snapshot ${db_new_instance}
(最終的なシェルスクリプト)
コードのアップグレードによって、定期更新、マスキング処理を行うことができるようになりました。
これにて7-6.マスキング処理編及び活動編が終了でございます!
7-5.定期実行編、7-6.マスキング処理編は、ただ作るだけではなく運用保守などを考慮して長い目でみて使えるものを作成しなければならないとうことが実感でき本当に自分の中で実務案件をこなさなければ出会えなかったであろう課題でした!初めてのことで大変なことも多々ありましたが本当に楽しかったです!
8.概算運用コスト
忘れてはいけない大事なお金の話。ということで月の概算運用コストも書いておきます。
運用を考えるとランニングコストも大事な部分なのでしっかりと要件定義で出された5000円前後に収めなければならないところです。

しっかり、5000円以内で収めることができました!
さて、次はいよい「クライアントに最終提出です。なんていわれるんだろうかとこのときの私は蛇に睨まれたカエルのようにプルプルとふるえておりました...」
9.最終提出
さっそくですが、最終提出したものがおおきく2つで、こちら
AthenaでSQLクエリの実行結果(マスキング処理済み)
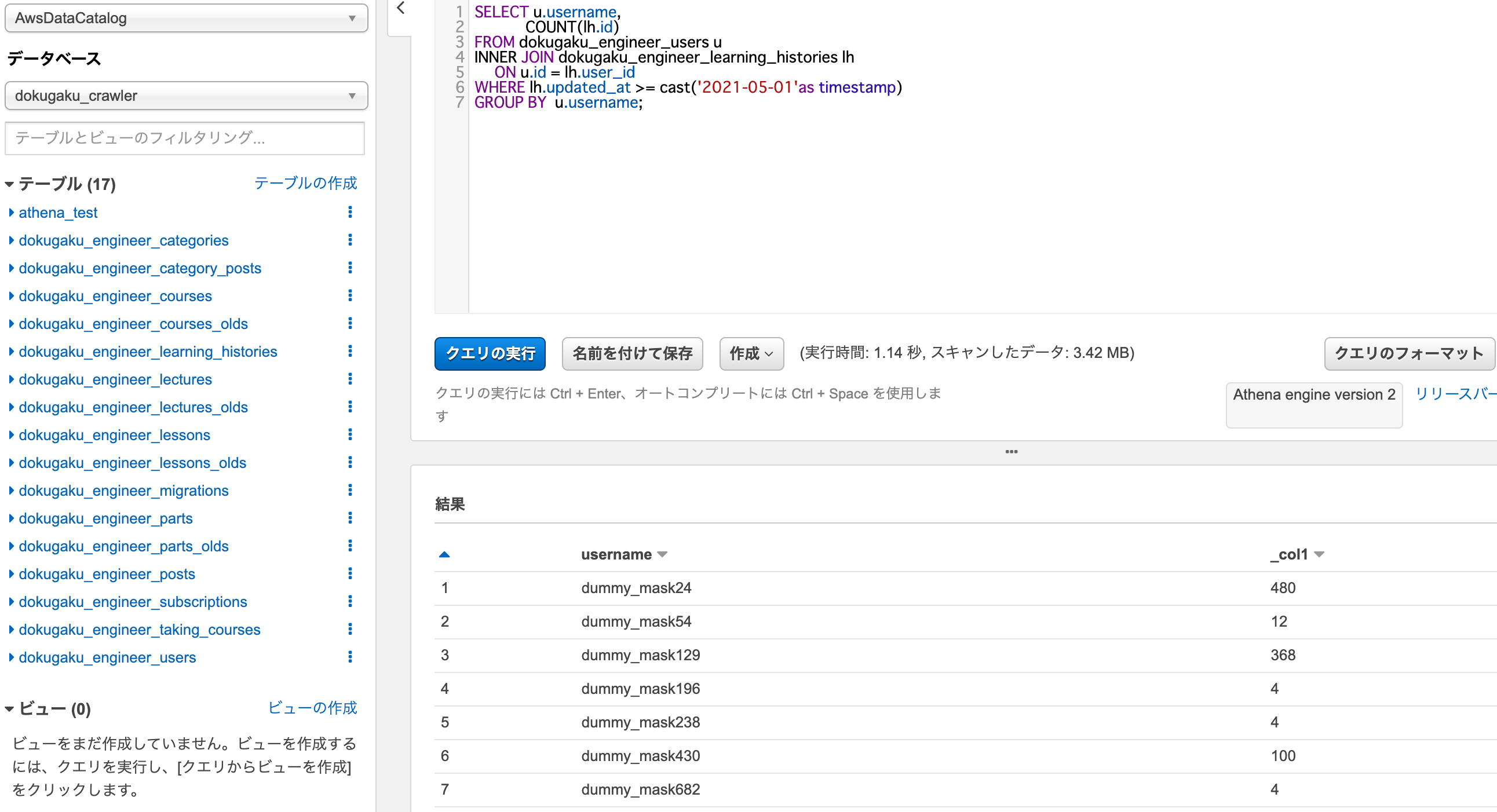
クライアントから事前に頂いていたSQL文を実行後、提出して了承をいただきました。
QuickSightでデータの可視化(マスキング処理済み)
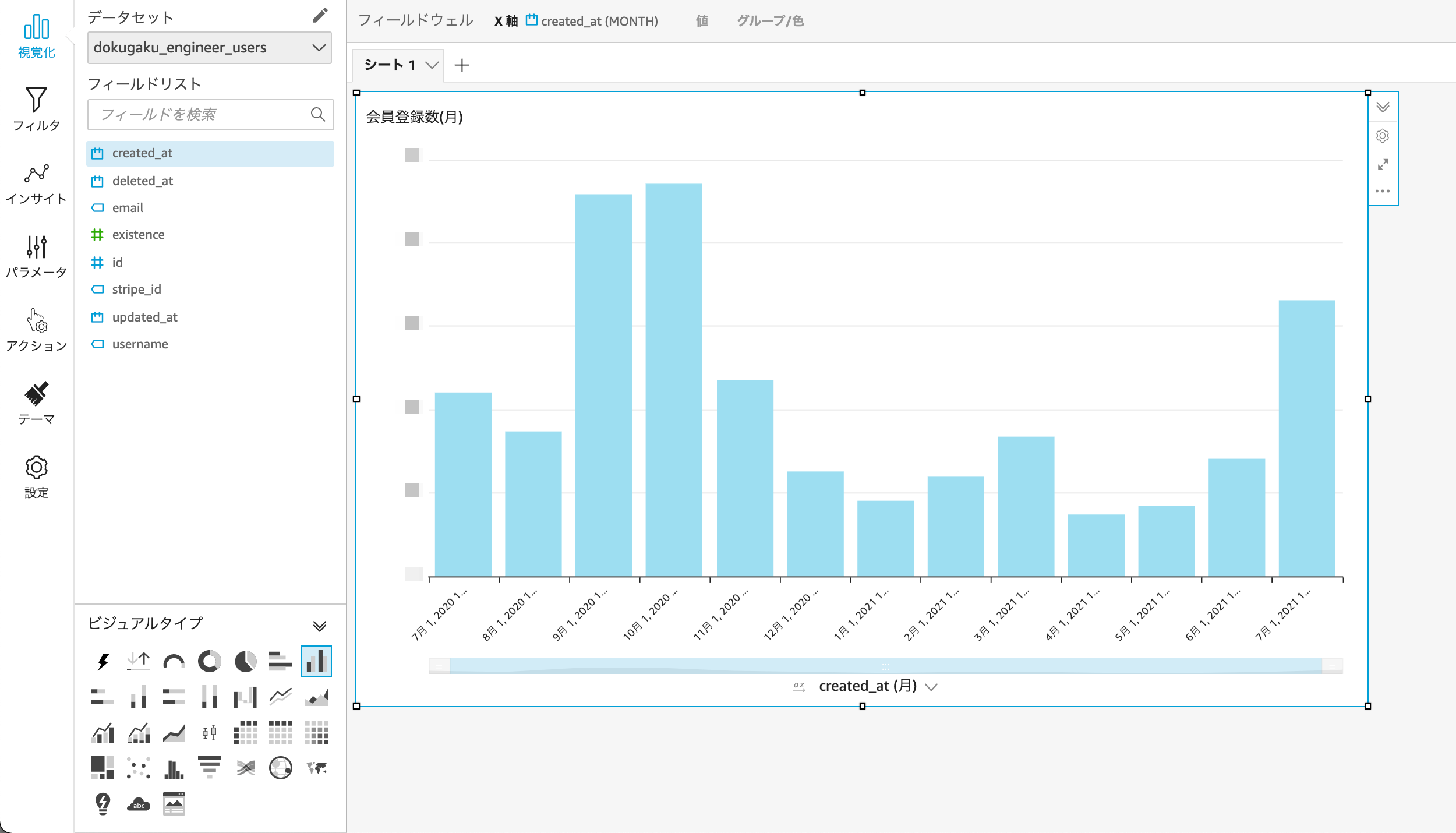
Athenaでのクエリ結果も無事可視化できました。1回データセットを登録すれば次回以降は自動で最新のデータに更新されます。こちらもクライアントから了承をいただきました。
そして、クライアントからいただいたお言葉は
![]() 「おー素晴らしいです!お疲れ様でしたー!!」
「おー素晴らしいです!お疲れ様でしたー!!」
銭湯あがりにコーヒー牛乳を一気飲みする気持ちよさ。一言で言うなら「昇天」
こうして課題に課題を重ねつつもなんとか提出することができました。
皆様、ここまでほんっとーに!長かったですね...ここまで読んでくださった皆様、途中で離脱したみなさまも本当にありがとうございました!
あと1つ、1つだけ23年しか生きていない私ですが実務案件をとおして「エンジニアとして働くということの価値観が180度変わった」そんなお話を最後にきいていっていただけると嬉しいです!では最後のセクションいってみましょう!
10.「価値観が変わった」お話
ここまでは楽しく読めるように書いてきたつもりですが、最後のこのセクションだけはすこし真面目な話に付き合っていただけると幸いです。
最初にも述べたとおり、この実務案件を通してエンジニアとして働くことに関する価値観が180度変わりました。
私の中で大きな価値観の変化がおきたと思うポイントは2つあります。
1つ目がコードを書くことだけがエンジニアの仕事ではないということです。これだけだとそんなセリフよく目にするよ!でも結局はコードを書けるかどうかが全てだろ?っていうような声がきこえてくるきがしますし、私自身も実務案件を行うまではそう思っていました。
実務案件を通してこの言葉の真意を自分なりにおきかえてみるとこうなりました。エンジニアとはIT技術をつかって課題解決をするのが仕事で、その1つの選択肢としてプログラミングがあるです。
実務案件を行う前だとこれをみたら何いってんだ?と私自身なっていたと思うのですが、すぐにコードを書き始める前に、その課題を解決するのに本当にコードを書く必要があるのかと考えることも重要だと思いました。
具体的には今回の実務案件では募集要項として「php,Rubyで開発経験がある人」という項目があったこともあって実務案件に参加してすぐはphpでどうやって解決しよう、どんなふうにコードを書けば解決できるだろうという思考になっていましたが、実際に書いたコードは100行以下だと思います。
多少はコードを書きましたが実際には自分の知らなかったツールを駆使することで実務案件の課題を解決することができました。今回の案件を1からコードでかいていると間違いなく今の私では課題を解決することはできなかったと思います。コードを書く前にもっと広い視野をもってこの課題解決に適したツールで、より簡単に解決する方法はないのかという広い視野を持つことができました。
このような実体験からコードを書くことだけがエンジニアの仕事ではない。エンジニアとはIT技術をつかって課題解決をするのが仕事で、その1つの選択肢としてプログラミングがあるということに気づくことができました。
2つ目が自分理想のソリューション=クライアントにとって最適なソリューションではないということです。これも当たり前のことのように感じますが実務案件をおこなう前の自分にはなかった考えでした。これはシンプルにいうとクライアントにとって重要なことを意識することが大事ということです。
今回特に意識したのは「納期」「シンプルさ」です。
まず「納期」ですが、これはどんなによいソリューションであったとしても納期に間に合わないのであれば価値は0ということです。自分の理想ばかりをかかげているソリューションを考えるのではなくクライアントの課題解決を1番に考えて納期に間に合う現実的なソリューションを考えることが重要です。
次に「シンプルさ」ですが、自分にしかわからない複雑なものを作るよりクライアントにもしっかりと理解してもらえるシンプルなソリューションをかんがえるのが重要ということです。実際に案件にとりくんでいると、これつかってこんな事もできるのか絶対あったほうがいいなと自分自身は思ってしまうのですが、実際には求められていないということもありました。クライアントにとって無駄なものを足していくより、よりシンプルに課題解決する方法はないかと考えることが重要です。
例えば、
a 「高度な技術と機能がもりもりのエンジニアのロマンが詰まったソリューション」
b 「シンプルでかつ自分の課題が解決できるソリューション」
極端に言えばこんな感じで、自分がクライアントならどちらを使いたいでしょうか?
これは機能数を極端に減らばいいという話ではなくて「まずはクライアントの課題をシンプルに解決するその上でこんなのもあったらどうですかと自分から提案してみる」これが理想の形であると思いました。
これは机上の空論ではなく私自身今回提出したソリューションの前に「納期」「シンプルさ」をまったく意識せずに今流行の技術もりもりのソリューションを提案してしまいその失敗から学びました。
以上のことから自分理想のソリューション=クライアントにとって最適なソリューションではないということに気づく事ができました。
最後にはなりますが、実務案件をとして自分のポートフォリオ作りだけでは決して気づくことのないことに沢山気づく事ができました。「IT技術を駆使して課題を解決するのがエンジニアの仕事」「クライアントにとって最適なソリューションを考える」など文字にすれば当たり前のように感じることですがなかなか実行できていなかったことで、これらを実際に実行してみて沢山の壁にぶつかったことで自分の経験として学ぶことができました。
以上「小さな駆け出しエンジニアのエンジニアとして働くことに関する価値観が180度変わるそんな物語」でした。
ここまで読んでいただきありがとうございました!
2022/01/04 追記:新たな実務案件記事
別の実務案件も記事にしましたのでよろしければ覗いてみてください!
( PHP, Laravel, Chart.js, Dokcer, Circle CI AWS(EC2, RDS, Cloud Formation)などを使ってます )