背景
昨今、ChatGPT の出現から、AIやブロックチェーン技術の利活用が加速しています。
SoftBankの孫正義氏は、
「人類の叡智の総和の 10倍 のAIが、10年以内 に達成される」と発言しています。参考動画
関連ワードとして、「第四次産業革命」や「Web3.0」という単語を耳にした人が
いるかもしれません。
そんな中でにわかに盛り上がっているのが、暗号通貨(暗号資産) です。
Bitcoin なんかが代表的な暗号資産ですね。
米ドルや円じゃなくて、暗号資産の時代がくる、なんて言っている人もいます。
そんな情勢の中で、ならばAIを用いてBitcoinの 価格予測 ができないのか、
というのに挑戦したのがこの記事になります。
※2024/03/07 現在での内容です。
※この記事に含まれる内容は、私見が含まれます。
目次
1. データセットの取得
2. データセットの前処理
3. 特徴量の作成
4. 訓練データとテストデータの分割
5. LightGBM モデルを適用,予測の実行
6. モデルの評価
7. まとめ
8. 考察
開発環境
Windows 11
Google Colaboratory
1.データセットの取得
- Bitcoin/米ドルの価格(BTC_data)
- 日経平均株価 (NI225_data)
- NYダウ(NYdow_data)
- ドル円相場(UJ_data)
いずれも2014-09-17~2024-02-27の日ごとの高値のデータを使用します。
下記3つはいずれも説明変数として設定しました。
(使用データの期間に意図はないため、期間を変えることで精度の改善に繋がる可能性が考えられます。)
データセットは、Yahoo Finance US から取得することができました。
まずは、必要なライブラリをインポート。
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import yfinance as yf
import seaborn as sns
from sklearn import metrics
import lightgbm as lgb
from sklearn.model_selection import train_test_split
その後データセットを取得し、日米間のタイムゾーン を統一します。
また、それぞれの高値のデータのみ取り出します。
#BTC-USD(目的変数)、日経平均株価、NYダウ、ドル円相場(説明変数)のデータセットを読み込み、整型
btc_chart = yf.Ticker("BTC-USD")
btc_chart = btc_chart.history(start="2014-09-17", end="2024-02-27")
btc_chart.index = btc_chart.index.tz_convert('UTC')
btc_chart_h = btc_chart.iloc[:, 1].to_frame()
NI225_chart = yf.Ticker("^N225")
NI225_chart = NI225_chart.history(start="2014-09-17", end="2024-02-27")
NI225_data = NI225_chart.rename(columns={'High': 'NI225_High'})
NI225_data_h =NI225_data.iloc[:,1]
NI225_data_h.index= NI225_data_h.index.tz_convert('UTC')
NYdow_chart = yf.Ticker("^DJI")
NYdow_chart = NYdow_chart.history(start="2014-09-17", end="2024-02-27")
NYdow_data = NYdow_chart.rename(columns={'High': 'NYdow_High'})
NYdow_data_h =NYdow_data.iloc[:,1]
NYdow_data_h.index= NYdow_data_h.index.tz_convert('UTC')
UJ_chart = yf.Ticker("JPY=X")
UJ_chart = UJ_chart.history(start="2014-09-17", end="2024-02-27")
UJ_data = UJ_chart.rename(columns={'High': 'UJ_High'})
UJ_data_h = UJ_data.iloc[:,1]
UJ_data_h.index= UJ_data_h.index.tz_convert('UTC')
2.データの前処理
説明変数3つをDataFrame型にします。
ここで、株式市場と暗号通貨市場の違いに悩まされました。
というのも、暗号通貨市場には休みがないため全てのデータが取れるのです。
一方、株式市場は土日祝が休みなため、データの欠損が出てきます。
(しかも、ニューヨークと日本では祝日も異なるため、一つのデータに結合するのに苦労しました…。)
調べていくうちに、pandas.merge.asofメソッドを使うと、一番近い値をキーにして結合してくれるというのが見つかったので、これを使用しました。
結合した後は、欠損値の処理を行います。
#DataFrame型に変更
NI225_data_h = NI225_data_h.to_frame()
NYdow_data_h = NYdow_data_h.to_frame()
UJ_data_h = UJ_data_h.to_frame()
#日付のリスト作成
dt_list = pd.date_range(start="2014-09-17", end="2024-02-26", freq='D')
dt_list = dt_list.to_frame(name='date')
#説明変数の結合、欠損値の処理
df_merged = pd.merge_asof(NYdow_data_h, UJ_data_h,left_index=True, right_index=True,direction='nearest')
df_merged = pd.merge_asof(df_merged, NI225_data_h, left_index=True, right_index=True, direction='nearest')
df_merged = pd.merge_asof(df_merged, btc_chart_h, left_index=True, right_index=True, direction='nearest')
df_merged.index = df_merged.index.date
df_all = pd.merge(dt_list, df_merged, left_index=True, right_index=True, how='outer').fillna(method='ffill')
df_all.index = df_all.index.date
df_all = df_all.rename(columns={'High':'BTC_High'})
3.特徴量の作成
正解データとして、今回は詳細な値動きを予測するのは難しいと考え、
翌日の高値が当日の高値を上回っていた場合は1、そうでない場合は0として変換しました。
#正解データとして、翌日の高値が当日の高値を上回っていた場合は1、そうでない場合は0とする。
btc_score = ((btc_chart["High"] - btc_chart["High"].shift(-1)) < 0)*1
btc_score.index= btc_score.index.tz_convert('UTC')
btc_score.index = btc_score.index.date
btc_score = btc_score.to_frame()
btc_score = btc_score.rename(columns={'High': 'BTC_score'})
df_h_all = pd.merge(df_all, btc_score, left_index=True,right_index=True)
4.訓練データとテストデータの分割
必要なデータが一つに結合されたため、説明変数と目的変数を設定し、
データを分割していきます。
#説明変数と目的変数の設定
X_df = df_h_all.drop(['date','BTC_High',"BTC_score"], axis=1)
y_df = df_h_all['BTC_score']
#訓練データとテストデータを分割
X_train, X_test, y_train, y_test = train_test_split(X_df, y_df, test_size=0.2, shuffle=False)
5.LightGBM モデルを適用,予測の実行
ここからは、モデルの実装になります。
今回使用した LightGBM は、勾配ブースティングを実装するため Microsoft 社が開発した
強力な高性能機械学習ライブラリです。
機械学習の世界コンペ(Kaggleなど)でランキング上位を独占しており、信頼性が高い上に動作も軽いため人気を集めています。
#XGBoostで学習するためのデータ形式に変換
dtrain = lgb.Dataset(X_train, y_train)
dvalid = lgb.Dataset(X_test, y_test)
#モデルパラメータの設定
callbacks=[
lgb.early_stopping(stopping_rounds=100, verbose=True),
lgb.log_evaluation(5),
]
params = {'objective': 'binary',
'metric': 'auc',
"boosting_type": "gbdt",}
model = lgb.train(params,dtrain,valid_sets=dvalid, num_boost_round=1000, callbacks=callbacks)
#テストデータに対し予測を実施
y_pred = model.predict(X_test)
パラメータは、0か1のバイナリに設定します。
また、early_stoppingも設定し、過学習を防ぎ、計算時間を短縮します。(下図)
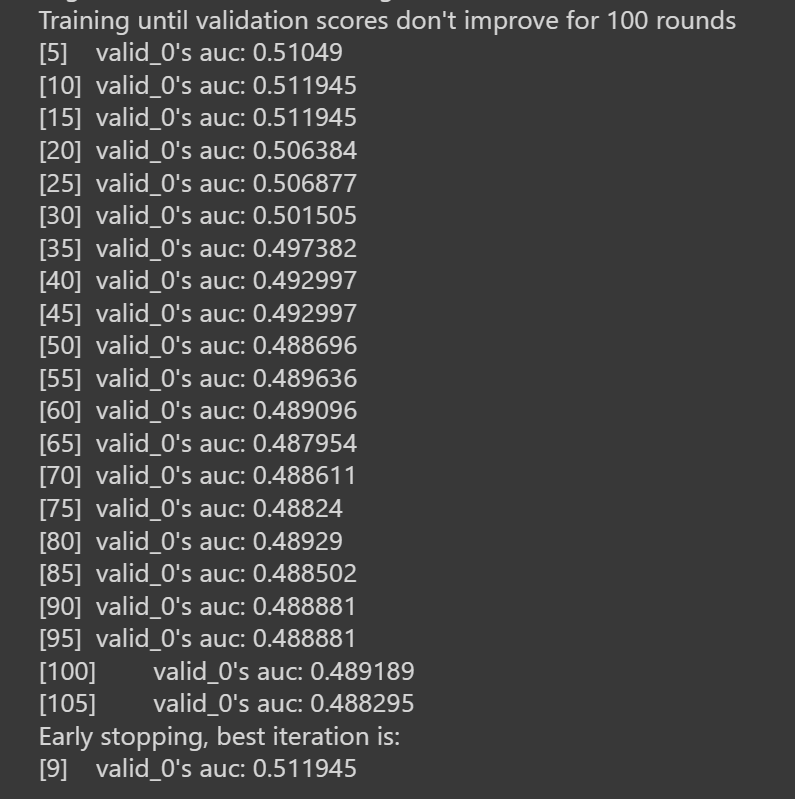
6.モデルの評価
ここまでで、モデル構築が完了したので、精度を評価していきます。
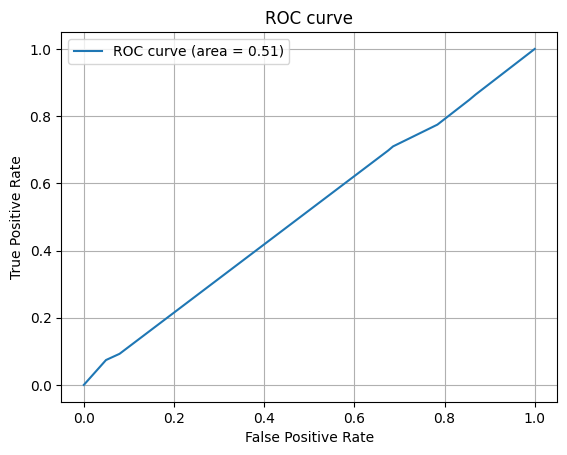
今回は、精度の指標として、ROC曲線と混同行列を用います。
ついでに、どの説明変数が一番寄与していたかをプロットします。
# AUCを計算
fpr, tpr, thresholds = metrics.roc_curve(np.asarray(y_test), y_pred)
auc = metrics.auc(fpr, tpr)
print("AUC", auc)
# ROC曲線をプロット
plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc)
plt.legend()
plt.title('ROC curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.grid(True)
plt.show()
# accuracy, precisionを計算
acc = metrics.accuracy_score(np.asarray(y_test), np.round(y_pred))
precision = metrics.precision_score(np.asarray(y_test), np.round(y_pred))
print("accuracy", acc)
print("precision", precision)
# 混同行列をプロット
y_pred = np.round(y_pred)
cm = metrics.confusion_matrix(np.asarray(y_test), np.where(y_pred < 0.5, 0, 1))
cmp = metrics.ConfusionMatrixDisplay(cm, display_labels=[0,1])
cmp.plot(cmap=plt.cm.Blues)
# 性能向上に寄与する度合いで重要度をプロット
lgb.plot_importance(model, height = 0.5, figsize = (4,8))
plt.show()
7.結果
精度の出力結果は、以下となります。
全体的な結果としては、かなり良いとまでは言えない感じです。
(人による精度がどれくらいか、どこまでの数字が基準なのかによりますが…)
| Score | Value |
|---|---|
| AUC | 0.5119451190717128 |
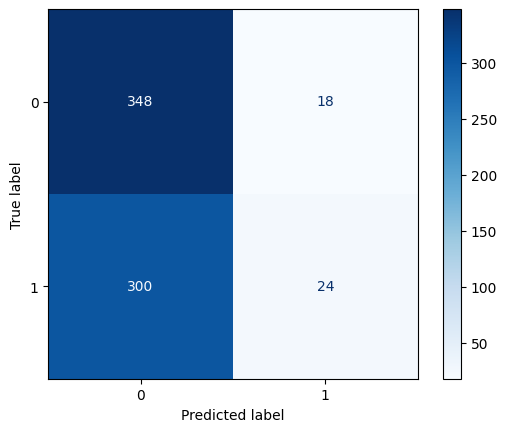
| accuracy | 0.5391304347826087 |
| precision | 0.5714285714285714 |
ROC曲線を作成した時に、グラフの下の部分の面積をAUC(Area Under the Curve) と呼びます。AUCは0から1までの値をとり、値が1に近いほど判別能が高いことを示します。
また、混同行列を見ることで、どの予測がどれくらい正しかった(あるいは間違っていた)
のかが視覚的に理解できます。
正解率(accuracy) も適合率(precision) もここから算出できます。
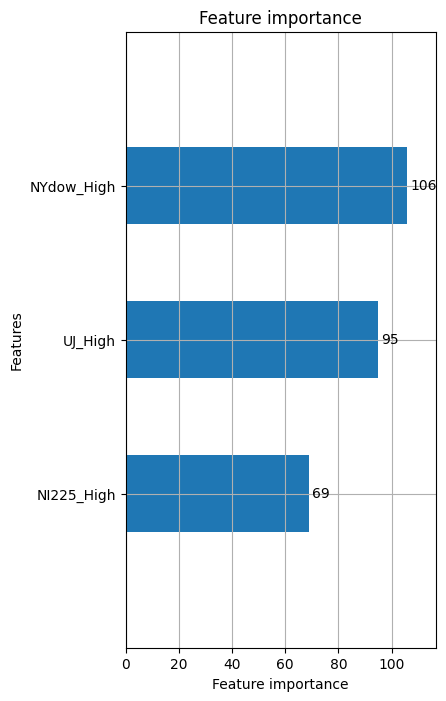
さらに、今回はどの説明変数が一番寄与していたか。グラフで表しました。
結果として、NYダウの高値が一番寄与していたという事になりますね。
Bitcoinの大半がアメリカにあることを考えると、妥当ではないかと思います。
8.考察
予測精度が芳しくなかった理由としては、
- 不適当なモデルの選択
- データの前処理の仕方
- 不適切な説明変数(3つという数、選んだ変数の妥当性)
が考えられます。
今回は時系列データですので、もっと正確に予測したいのであれば、
時事データや周期性なども考慮すべきかもしれません。
今回は、LightGBMモデルを用いましたが、
SARIMAXモデルやLASSOモデルでも予測は可能とのことなので、
予測精度の上昇のために、モデルを正しく使い分ける必要があると痛感しました。
また、今回の分析では、欠損データ等によるデータの前処理にかなり時間を割きました。
実務面でもここに一番時間をかけるという風に聞いていたため、
実際にこの予測を行うことでその苦労を実感しました。
ただもっと経験を積んでゆけば、時間短縮できるとも思いますので、
ここは精進あるのみですね。
今回は以上です!何かの参考になれば幸いです。
最後までお読みいただき、ありがとうございました!
参考文献
- Forecasting Bitcoin Prices with Time Series
- Yahoo Finance USから株価をダウンロードしてみた
- Twitter感情分析を用いて、FXのドル円予測をPythonでやってみた
- Intro to Time Series Forecast
- 【pandas】最も近い値でマージするmerge_asof関数
- Python初心者による時系列解析〜SARIMAモデルの実装〜
- 年利30%超え!!!!!LightGBMを用いたトヨタ株自動売買シミュレーション
- 時系列データを機械学習で予測(LightGBM By Python)
- コピペで動くLightGBM |Pythonで最強予測モデルの実装