「Yahoo Finance US から株価をダウンロードしてみた」では、2019年1月以降、API経由で無料取得できるデータとして紹介してきました。これは拙著「Python3ではじめるシステムトレード」でYahoo Finance(米国版)のデータを利用してきたためです。もっとも、Yahoo Finance US(米国版)からのデータ取得手段は、仕様変更等により安定して提供されるとは限らず、停止・再開を繰り返してきました。
そのため第2版(2023年)では、取得手段として yfinance の利用、またはWebサイトからCSVを手動でダウンロードする方法を推奨しました。
しかし現在、私の環境では yfinance や stooq からの取得がうまくいかず、Yahoo Finance(米国版)の有料購読も日本から契約できない状況です。以上より、現時点では Financial Modeling Prep(FMP)のAPIを利用する方法が有力な選択肢と考えます。API_KEYをFMP(https://site.financialmodelingprep.com/)
から取得する必要があります。取得方法は付録を参照してください。また、すべての株価が無料というわけではなく、たとえばETFの株価は取得できませんし、インデックスも取得できません。これらは有料版で取得できるようです。以下にサンプルコードを示します(※APIキーは環境変数で管理してください)。
このコードではまずFMPからデータをダウンロードして、それをYahoo Financeのデータフォマットに変換しています。また、FMPでは一度に5年分しかデータをダウンロードできないので、取得期間が長期にわたる場合には、期間を5年ごとに切り分けてループをつかって、指定期間のデータをダウンロードしています。そのため、ダウンロードの回数は複数回にカウントされます。FMPでは無料版では一日のダウンロード数は250に制限されていますので、気を付けてください。
16122025 67909
import time
import requests
import pandas as pd
from datetime import date
from pathlib import Path
BASE = "https://financialmodelingprep.com"
def safe_date_str(s: str) -> str:
# "1980-12-12" -> "19801212"
return str(s).replace("-", "")
def fetch_fmp_window(endpoint: str, symbol: str, apikey: str, start: str, end: str) -> pd.DataFrame:
url = f"{BASE}{endpoint}"
params = {"symbol": symbol, "apikey": apikey, "from": start, "to": end}
r = requests.get(url, params=params, timeout=30)
r.raise_for_status()
df = pd.DataFrame(r.json())
if df.empty:
return df
df["date"] = pd.to_datetime(df["date"])
return df
def fetch_fmp_long(endpoint: str, symbol: str, apikey: str,
start_date: str, end_date: str,
years_per_chunk: int = 5,
sleep_sec: float = 0.25) -> pd.DataFrame:
start = pd.to_datetime(start_date).date()
end = pd.to_datetime(end_date).date()
chunks = []
cur = start
while cur <= end:
nxt = date(min(cur.year + years_per_chunk, end.year + 1), cur.month, cur.day)
chunk_end = min(end, (pd.to_datetime(nxt) - pd.Timedelta(days=1)).date())
df = fetch_fmp_window(endpoint, symbol, apikey,
start=str(cur), end=str(chunk_end))
if not df.empty:
chunks.append(df)
cur = chunk_end + pd.Timedelta(days=1)
time.sleep(sleep_sec)
if not chunks:
return pd.DataFrame()
out = pd.concat(chunks, ignore_index=True)
out = out.drop_duplicates(subset=["date"]).sort_values("date")
return out
def make_yahoo_csv(symbol: str, apikey: str,
start_date: str = "1980-12-12",
end_date: str | None = None,
out_csv: str | None = None) -> pd.DataFrame:
if end_date is None:
end_date = str(date.today())
full = fetch_fmp_long("/stable/historical-price-eod/full", symbol, apikey, start_date, end_date)
if full.empty:
raise ValueError("full が空です(キー/プラン/エンドポイント/期間を確認してください)")
divadj = fetch_fmp_long("/stable/historical-price-eod/dividend-adjusted", symbol, apikey, start_date, end_date)
# dividend-adjusted 側の終値列名ゆれ対応(通常は close のはず)
adj_col = "adjClose" if "adjClose" in divadj.columns else ("close" if "close" in divadj.columns else None)
m = full.copy()
if (not divadj.empty) and (adj_col is not None):
m = m.merge(divadj[["date", adj_col]], on="date", how="left")
adj_series = m[adj_col]
else:
# 取得できない場合は暫定で Close を使う(=配当調整なし)
adj_series = m["close"]
yahoo = pd.DataFrame({
"Date": m["date"].dt.strftime("%Y-%m-%d"),
"Open": m["open"],
"High": m["high"],
"Low": m["low"],
"Close": m["close"],
"Adj Close": adj_series,
"Volume": m["volume"],
}).sort_values("Date", ascending=False)
if out_csv is None:
start_tag = safe_date_str(start_date)
end_tag = safe_date_str(end_date) if end_date is not None else "today"
out_csv = f"{symbol}_yahoo_{start_tag}_to_{end_tag}.csv"
yahoo.to_csv(out_csv, index=False, encoding="utf-8-sig")
yahoo["Date"] = pd.to_datetime(yahoo["Date"])
yahoo = yahoo.sort_values("Date").set_index("Date") # DateをIndexに
return yahoo
US yahoo! financeのデータ構成
- Open:始値
- High:高値
- Low:安値
- Close:終値 - 分割調整後
- Volume:出来高
- Adj Close:配当込み分割調整後株価
株価データの可視化
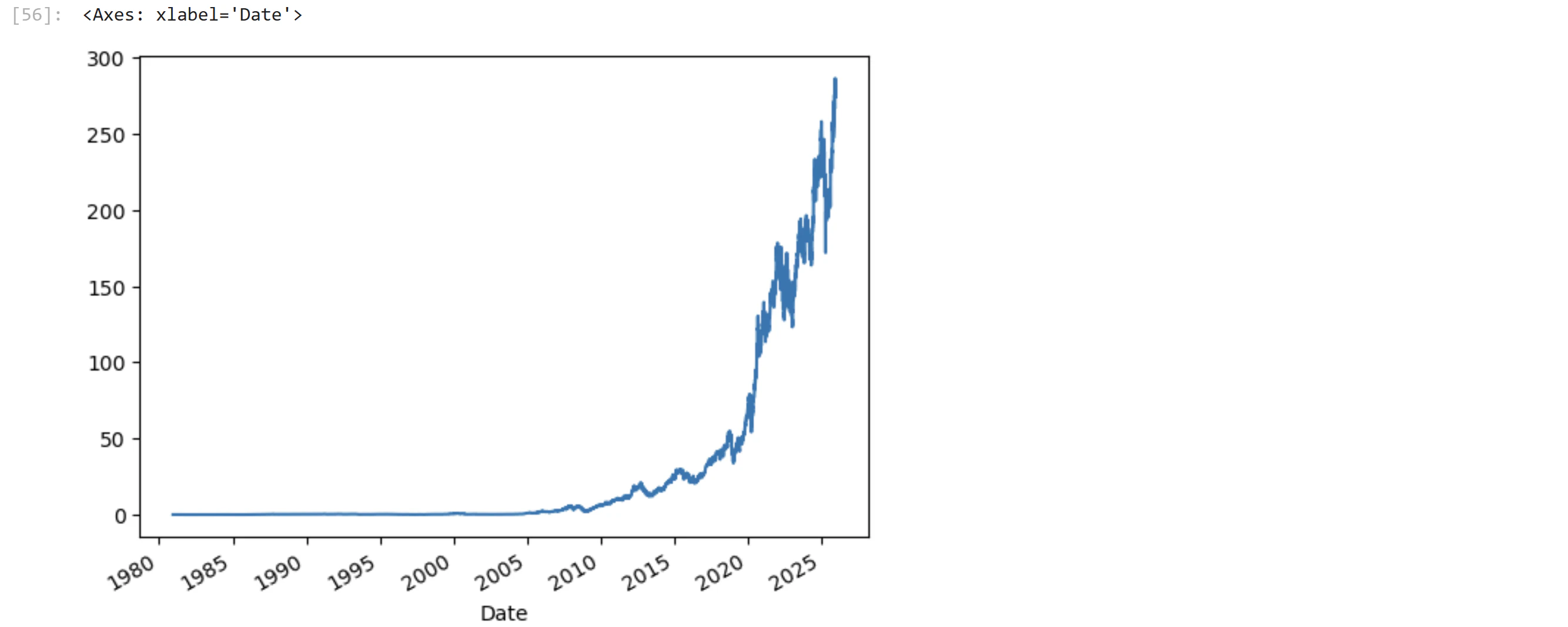
代表的な米国株 アップル
アップルは代表的な米国株です。銘柄コードはAAPLです。
では実際にダウンロードしてみましょう。
API_KEY = "あなたのキー"
df_y = make_yahoo_csv("AAPL", API_KEY, start_date="1999-1-22")
AAPL.plot()
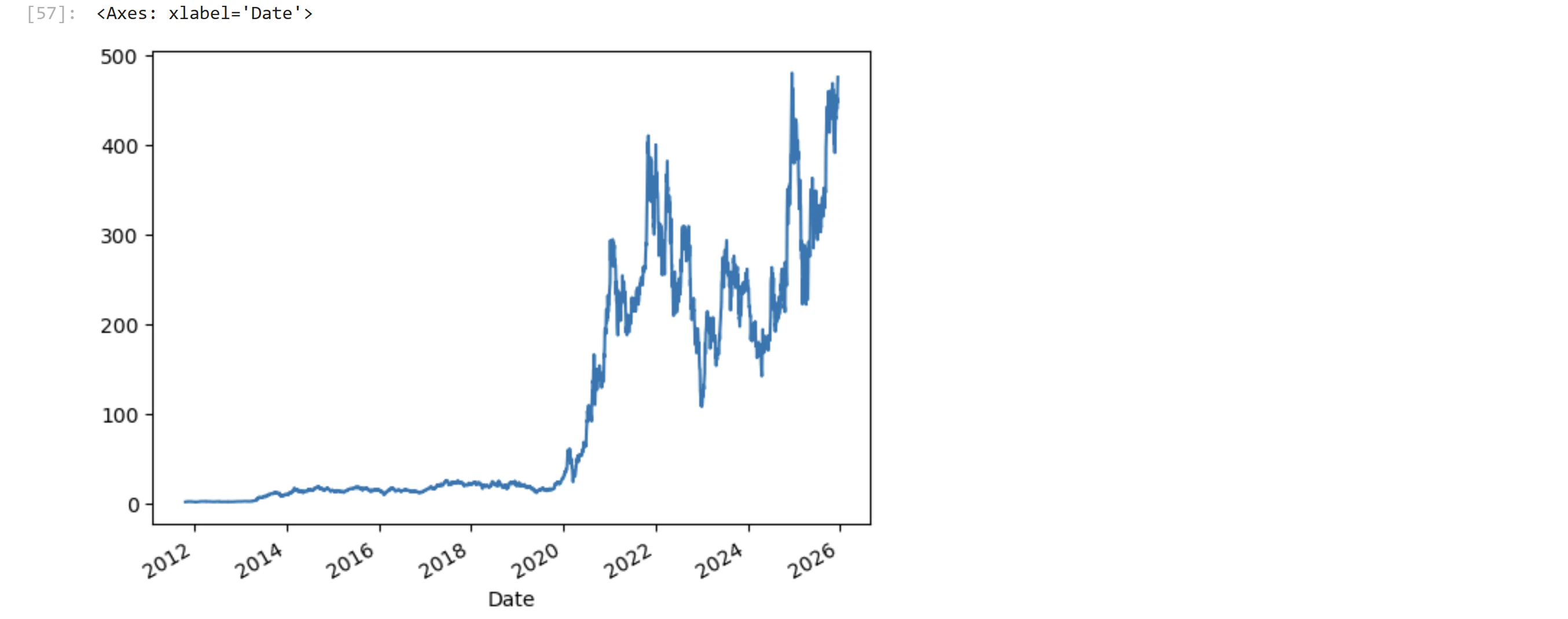
代表的な米国株 テスラ
ticker = 'TSLA'
df_y = make_yahoo_csv(ticker, API_KEY, start_date="2010-6-29")
df_y.plot()
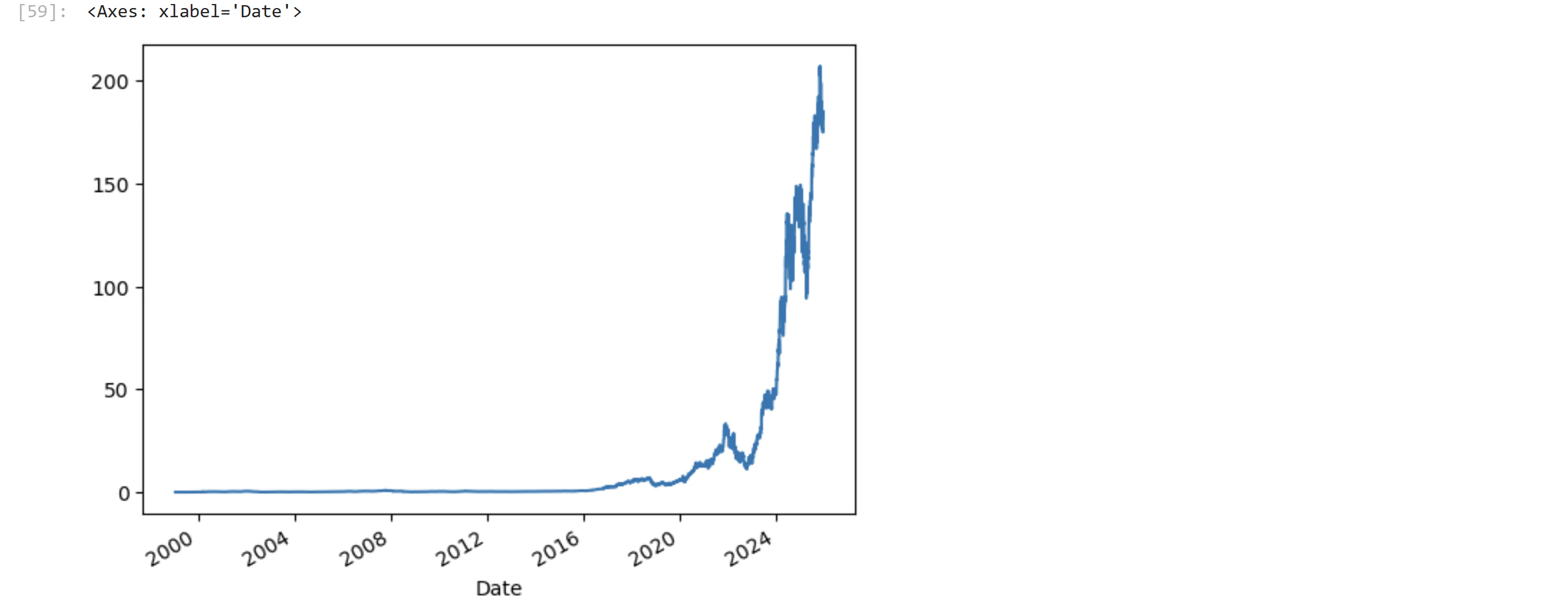
代表的な米国株 エヌビディア
ticker = 'NDVA'
df_y = make_yahoo_csv(ticker, API_KEY, start_date="1999-1-22")
df_y.plot()
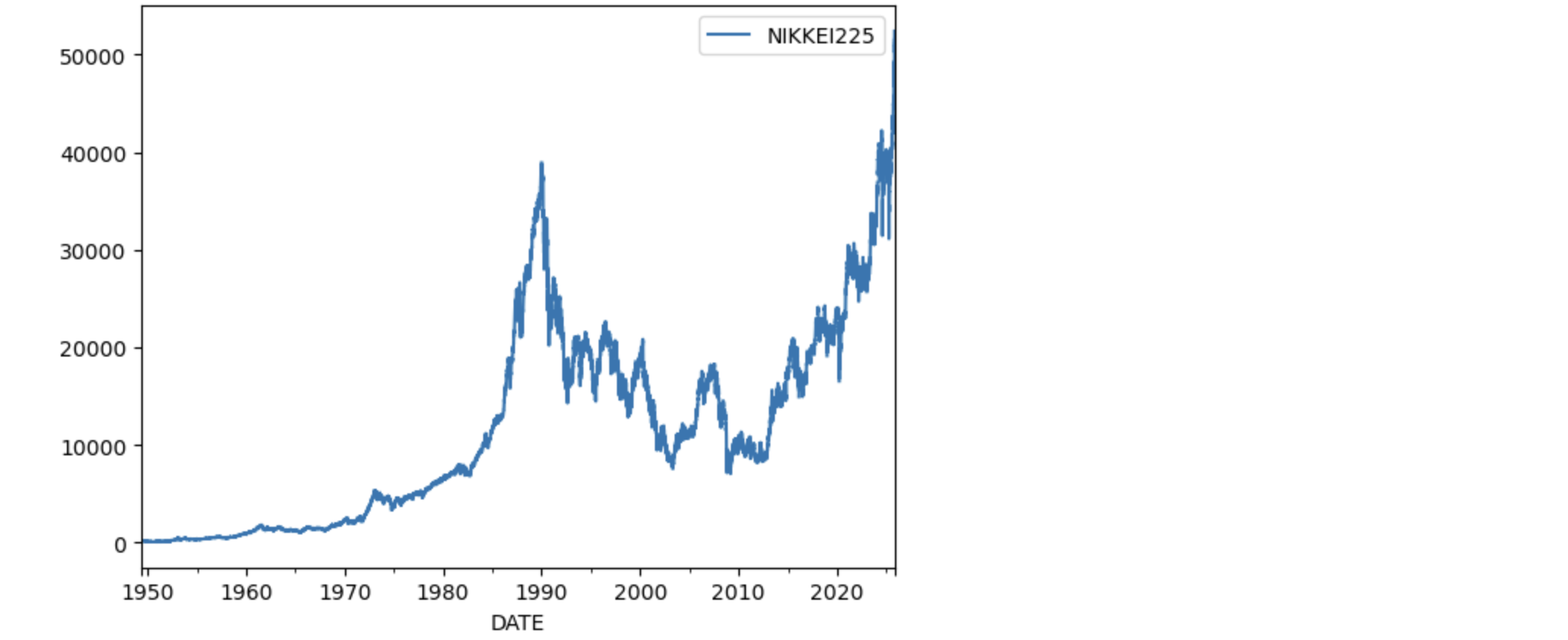
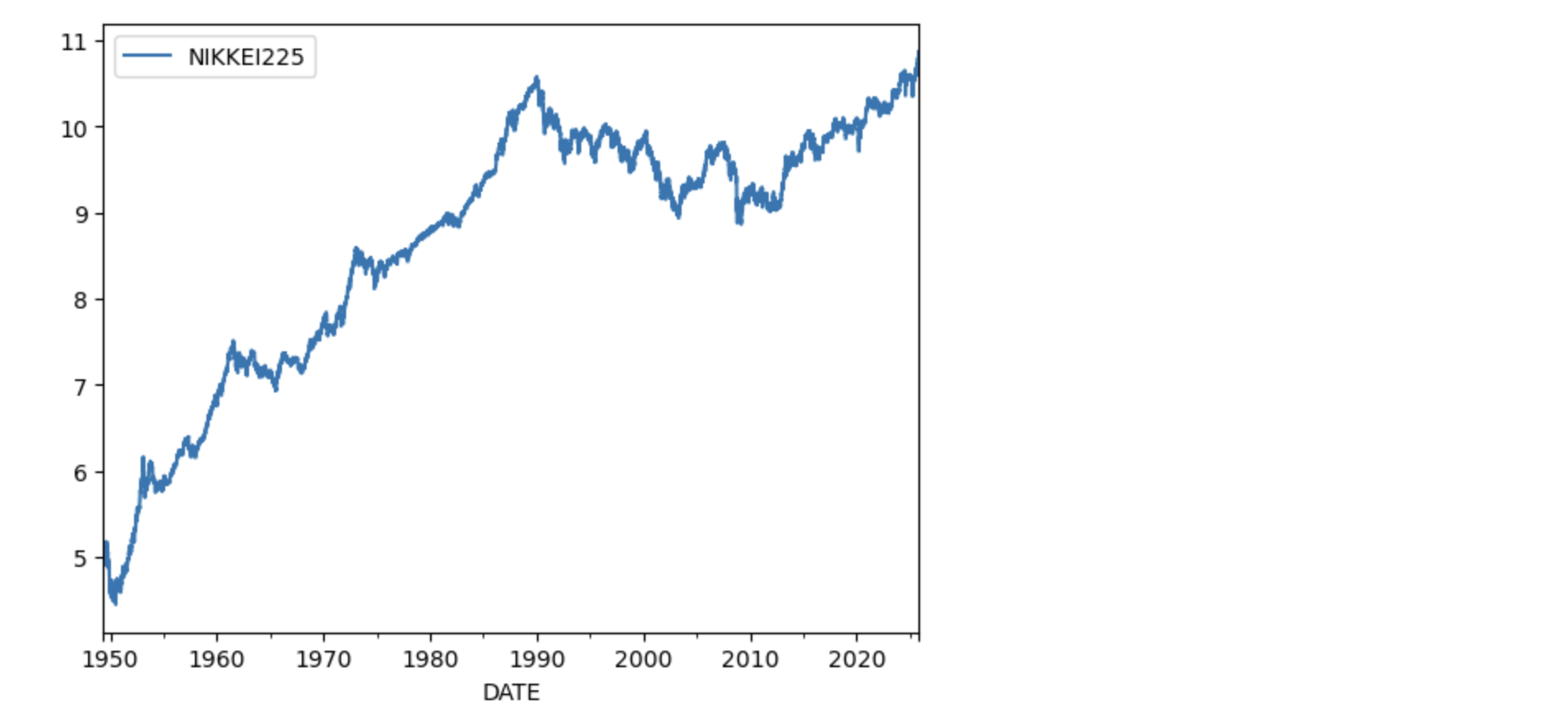
日経平均株価
日本の代表的な株価指数である日経平均株価(日経225)もダウンロード可能です。しかし、FMPからはダウンロードできないので、FREDからダウンロードします。
ticker = 'NIKKEI225'
n225 = web.DataReader(ticker, "fred","1949/5/16")
n225.plot()
plt.show()
np.log(n225).plot()
plt.show()
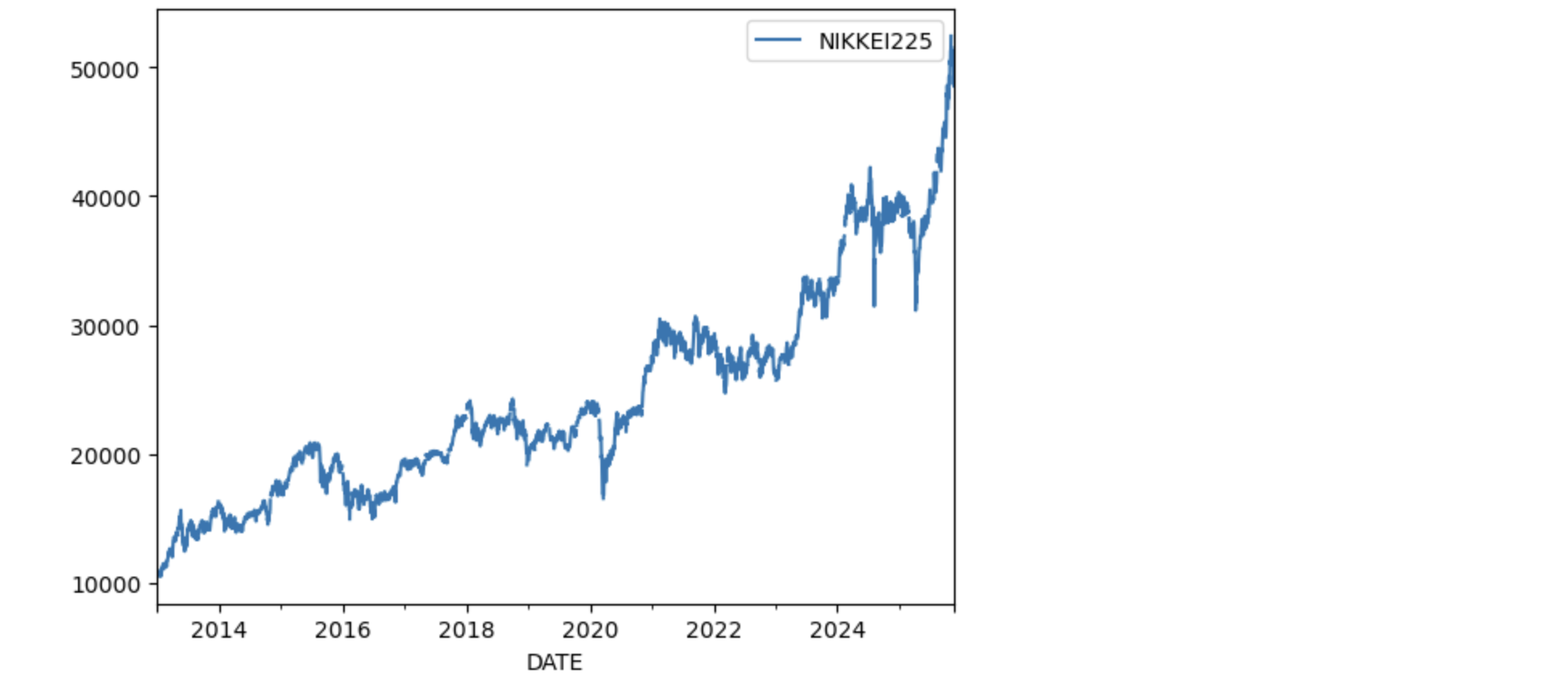
アベノミクス(2013年)以降の指数をダウンロードしてみましょう。
n225.loc['2013':].plot()
plt.show()
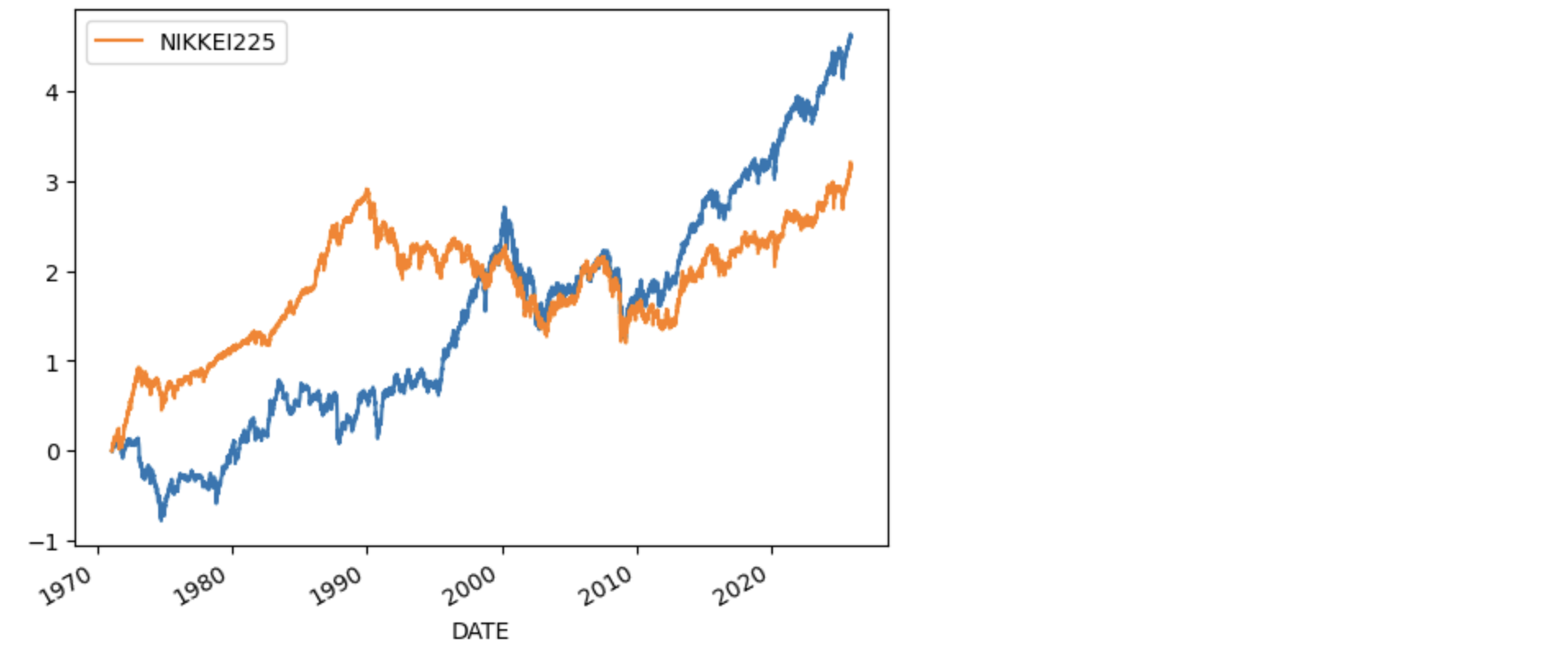
米国株投資の日本円でリターン
最近、日本株が安定した値上がりを示しているために、米国株とのパフォーマンスの比較が出ます。多くは日経225の日本円でのリターンと米国株のドル建てのリターンを比べています。ここでは米国株投資を日本円のリターンに直して示してみます。
ナスダック
日経平均とNASDAQに投資した際の円建てのリターンを為替リスクのヘッジなしで比べたときの結果を示します。
# FRED から USD/JPY のデータを取得
start_date = "1971/2/5"
end_date = datetime.datetime.now()
jpy = web.DataReader("DEXJPUS", "fred", start_date, end_date)
# NaNを削除(必要なら)
jpy = jpy.dropna()
# jpy.index も pd.Timestamp 型に変換
jpy.index = pd.to_datetime(jpy.index)
ndx = web.DataReader("NASDAQCOM", "fred", start_date, end_date)
# データをフィルタリング
jpy = jpy[jpy.index >= pd.Timestamp(start_date)]
ndx = ndx[ndx.index >= pd.Timestamp("1971-02-05")]
# データフレームを作成して結合
df = pd.DataFrame({'NDX_USD': ndx.NASDAQCOM, 'DEXJPUS': jpy.DEXJPUS}).dropna()
# ndxの価格を日本円に換算
df['NDX_JPY']= (df['NDX_USD'] * df['DEXJPUS'])
df=df.dropna()
# 正規化して対数スケールでプロット
ax=np.log(df.NDX_JPY/df.NDX_JPY.loc[start_date]).plot()
np.log(n225.loc[start_date:] / n225.loc[start_date]).plot(ax=ax)
plt.show()
主な株価指数の構成銘柄
代表的なナスダック100指数を構成する銘柄
アメリカ経済を牽引する銘柄群です。
NDX=pd.read_csv("nasdaq.csv",header=None)
NDX.head()

for x in NDX.iloc[:,0]:
ticker = yf.Ticker(x)
tsd = ticker.history(period="1y")
len(NDX)
100
nasdaq.csvは自分で作ることができます。https://en.wikipedia.org/wiki/Nasdaq-100
にナスダック100のリストがありますから、それをエクセルにペーストして、株価コードだけをcsvファイルとして落とせば完了です。1年に一度、見直しがあるので、入れ替えは頻繁に起こると思ってください。
代表的なダウ平均株価指数採用銘柄
「ダウ平均」、「ニューヨーク・ダウ」、「ニューヨーク平均株価」などとして親しまれている当指数は、チャールズ・ダウにより考え出され、1884年から算出されています。発表当初は鉄道株が中心でした。19世紀末には変わりゆく経済の姿を受け、1896年から新たなダウ工業株平均の算出が始まりました。その後ダウ工業株30種平均株価を構成する銘柄は時代の流れに合わせて入れ替えが行われています。今現在もっとも古くから採用されている銘柄はエクソンモービルで1928年から採用されています。
現在の構成銘柄は、
DJIA=pd.read_csv("djia.csv",header=None)
DJIA.head()

djia.csvは自分で作ることができます。https://en.wikipedia.org/wiki/Dow_Jones_Industrial_Average
にDJIAのリストがありますから、それをエクセルにペーストして、株価コードだけをcsvファイルとして落とせば完了です。入れ替えは頻繁に起こると思ってください。
US Yahoo Financeからダウンロードできるその他の主な株価、指数、暗号通貨
代表的な世界の株価指数
index=["^DJI","^DJT","^DJU","^BANK","^IXCO","^NDX","^NBI",
"^NDXT","^INDS","^INSR","^OFIN","^IXTC","^TRAN","^NYY","^NYI","^NY",
"^NYL","^XMI","^OEX","^GSPC","^HSI","^FCHI","^BVSP","^N225","^RUA","^XAX"]
| ^DJI | Dow Jones Industrial Average |
| ^DJT | Dow Jones Trnsport |
| ^DJU | Dow Jones Utility Average |
| ^BANK | NASDAQ Bank |
| ^IXCO | NASDAQ Computer |
| ^NDX | NASDAQ-100 |
| ^NBI | NASDAQ Biotechnology |
| ^NDXT | NASDAQ 100 Technology |
| ^INDS | NASDAQ Industrial |
| ^INSR | NASDAQ Insurance |
| ^OFIN | NASDAQ Other Finance |
| ^IXTC | NASDAQ Telecommunications |
| ^TRAN | NASDAQ Transportation |
| ^NYY | NYSE TMT INDEX |
| ^NYI | NYSE INTL 100 INDEX |
| ^NY | NYSE US 100 INDEX |
| ^NYL | NYSE NY World Leader Index |
| ^XMI | NYSE ACRA Major Market Index |
| ^OEX | S&P 100 Index |
| ^GSPC | S&P 500 Index |
| ^HSI | Hang Seng Index |
| ^FCHI | CAC 40 |
| ^BVSP | IBOVESPA |
| ^N225 | Nikkei 225 |
| ^RUA | Russel 3000 |
| ^XAX | NY AMEX Composit Index |
| ^SOX | PHLX Semiconductor Index |
SOX指数はフィラデルフィア連銀による半導体株指数。半導体株の動向に大きな影響がある。
代表的なS&P株
現在の構成銘柄は、wikiのページから銘柄リストをエクセルにペーストしてティッカーの部分だけを残してsp500.csvファイルとして保存します。
SP500=pd.read_csv("sp500.csv",header=None)
SP500.head()

for x in SP500.iloc[:,0]:
ticker = yf.Ticker(x)
tsd = ticker.history(period="1mo")
len(SP500)

代表的な米国ETF
ETF=['DIA','SPY','QQQ','IBB','XLV','IWM','EEM','EFA','XLP','XLY','ITB','XLU','XLF',
'VGT','VT','FDN','IWO','IWN','IYF','XLK','XOP','USMV','BAB','GLD',
'VNQ','SCHH','IYR','XLRE','AGG','BND','LQD','VCSH','VCIT','JNK']
代表的なバイオ・ヘルス株
代表的なバイオ・ヘルス株の銘柄を得るために代表的なバイオ株へ投資しているETFを参考に銘柄を絞り込みます。まず、IBBを参考にします。IBBのホームページに行きます。
https://www.ishares.com/us/products/239699/ishares-biotechnology-etf
つぎにholdingをクリックすると、投資銘柄リストをダウンロードできるボタンがあります。
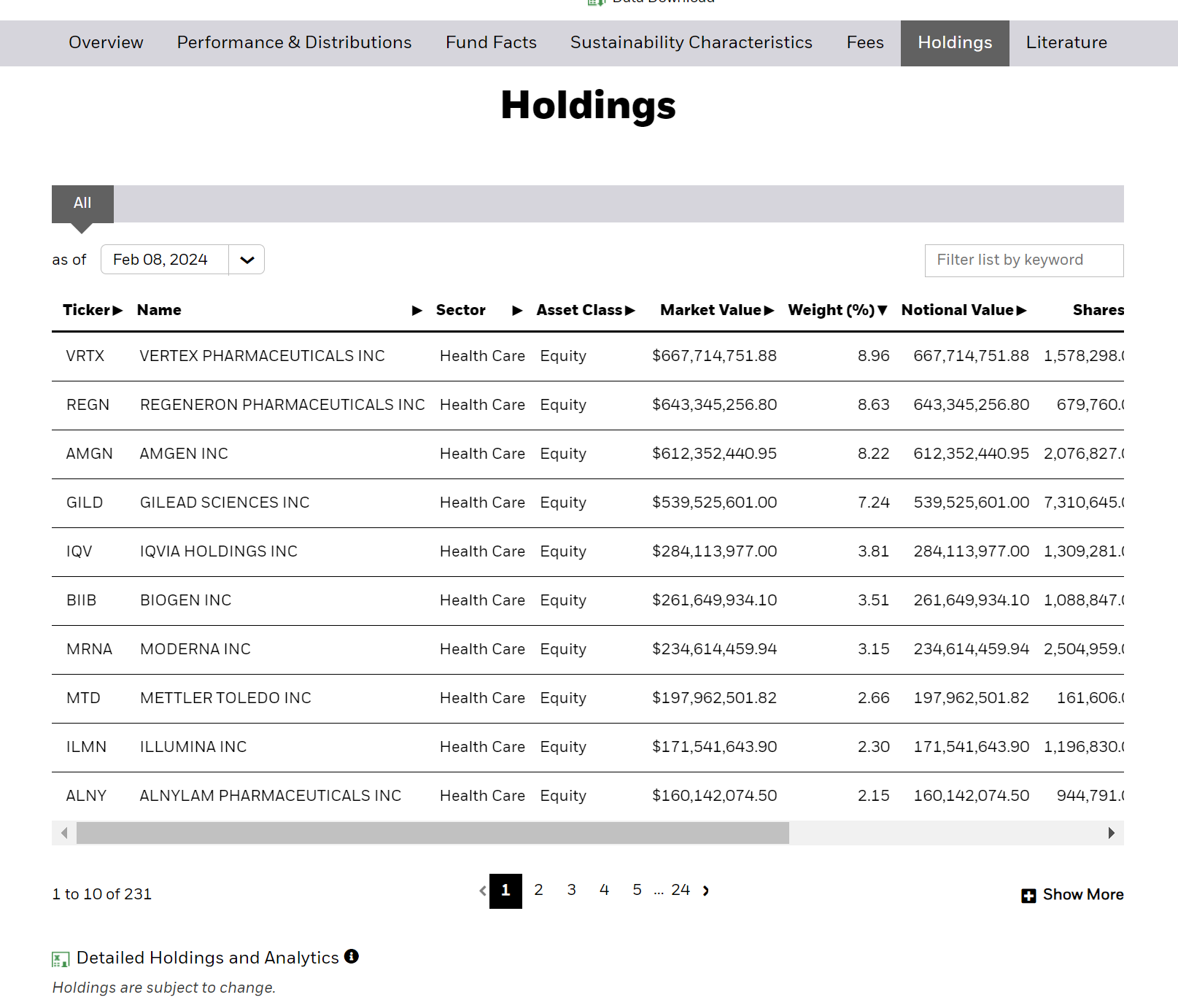
左下のDetailed Holdings and Analyticsのボタンを押すと関連ファイルがダウンロードホルダーにダウンロードできます。
IBB_holdings.csv
エクセルでファイルを開いてティカーコードだけを残して、IBB.csvとして保存します。
IBB=pd.read_csv("IBB.csv",header=None)
IBB.head()

for x in IBB.iloc[:,0]:
ticker = yf.Ticker(x)
tsd = ticker.history(period="1mo")
len(IBB)

代表的な暗号通貨
ccurrency=["BTC-USD","XRP-USD","ETH-USD","LTC-USD","BCH-USD","BNB-USD",
"EOS-USD","USDT-USD","LINK-USD","TRX-USD","ADA-USD",
"XLM-USD","XMR-USD","DASH-USD","NEO-USD","IOT-USD",
"VEN-USD","ETC-USD","XEM-USD","ZEC-USD","XRB-USD","QTUM-USD",
"BTG-USD","BAT-USD","DOGE-USD"]
| Bitcoin USD | BTC-USD |
| Ripple USD | XRP-USD |
| Ethereum USD | ETH-USD |
| Litecoin USD | LTC-USD |
| Bitcoin Cash / BCCUSD | BCH-USD |
| Binance Coin USD | BNB-USD |
| EOS USD | EOS-USD |
| Tether USD | USDT-USD |
| ChainLink USD | LINK-USD |
| Tronix USD | TRX-USD |
| Cardano USD | ADA-USD |
| Stellar USD | XLM-USD |
| Monero USD | XMR-USD |
| DigitalCash USD | DASH-USD |
| NEO USD | NEO-USD |
| IOTA USD | IOT-USD |
| Vechain USD | VEN-USD |
| Ethereum Classic USD | ETC-USD |
| NEM USD | XEM-USD |
| ZCash USD | ZEC-USD |
| Nano USD | XRB-USD |
| QTUM USD | QTUM-USD |
| Bitcoin Gold USD | BTG-USD |
| Basic Attention Token USD | BAT-USD |
| Dogecoin USD | DOGE-USD |
さて、重要なことをまだ説明していません。それはデータを分析することで何が得られるのかという点です。多くの人は何か理論的な確証を得て効果的で効率の良い投資ができるのではと考えていませんか?実はそのような理論も事実もありません。あるのは株価の過去の動きのパターンを知ることができるということだけです。ではなぜパターンが大事なのでしょうか?それはあなた自身のリスク許容能力をつかむためです。株式を売らずに持ち続けることは簡単なことではありません。株価が下落すれば、すぐに売りたくなってしまいます。でもそれでは効率的な投資にはなりません。そこであなたがどの程度の下落に「どきどき」しないで耐えられるのかをまずつかむ必要があります。そしてそのレベルを、パターンを収益率/リスクで測ろうとしているのです。そして、それがつかめたら、同じパターンをもつ株をまず探して、そのリストから分散投資するための銘柄を選べばいいのです。そのために統計分析が必要なのです。決して、理論的な背景を探して、それをよりどころに投資をするからではありません。「知的ゲーム」は危険な「遊び」です。
真理の追求
インターネットの普及によって一攫千金の可能性やマネーゲーム的な要素を持つ株式市場は、多くの人々のギャンブル性向を掻き立ててきた。暴落が発生したときなどには、市場の破壊力と予測不可能な性質は、恐れおののく投資家に市場に対しての畏敬と恐れを思い抱かせる。実際、暴落によって人々がパニックに陥った話や自殺する投資家の話が伝説的に語り継がれている。それでもなお株式市場の持つ様々なパターンは、有益な投資戦略を用いることで市場に打ち勝つことができるのではないかという思いを人々にいだかせる。しかしながら、株式市場は遊び好きな、あるいは愚かなギャンブラー達のカジノではない。
基本的な考え方は、複雑系や臨界現象といった周囲に存在する驚くべきシステムがどのように生起するかからはじめて、市場の暴落の予測といった結論を得ることだ。そしてその中心は、自己組織化システムだ。暴落は、自己組織化システムに「特異現象」が自然発生する事象そのものだ。
投資の基本はリスク管理だ!リスクの多い世界を扱い、それに対処するための重要なアイデアを得るには、市場の暴落を知ることはその出発点だ。
絶えず移り変わる世界は、不確実性と変化というキーワードを用いて表現することができる。私達の住む世界は動的で不安定であり、安定や均衡といったものは幻想である。このような世界において、均衡や恒常性を追究しても必ず失敗に終わる。大切なのは、深刻な金融危機のような「特異現象の組織化」と「崩壊」の役割を認識することだ。特異現象が社会に及ぼす明らかな影響だけでなく、安定状態から危機や大災害への瞬間的な遷移もまた、システムのダイナミクスの最も劇的な特徴の1つである。
私達の住む地球や社会は常に安定な状態、つまり「均衡」と呼ばれている状態にあるのではなく、不連続なダイナミクスによって成り立っている。ゆえに、崩壊の重要性やインパクトを複合的に認識することが必要なのだ。
時間の矢は、不確実な未来を容赦なく追い立てる。未来を予測することは人々の想像力を掻きたてる最大の挑戦でもある。歴史的に見ても、ひとびとは預言者たちの描く未来のビジョンに恐れ、奮い立たされてきた。
基本的な問題は:
-
金融市場の暴落とは何か?どのようにして発生するのか?なぜ発生するのか?いつ発生するのか?
-
株式市場、および株価がある瞬間から次の瞬間にどのように変化するのか?
-
大規模な金融市場の暴落は外れ値か?
-
投資家間における正のフィードバックが投機的なバブルを加速させ、暴落を引き起こす不安定状態を形成するか?
-
投機的なバブルと暴落の合理的なモデル:暴落のハザード率が市場価格を動かすと仮定したモデルか?それとも価格変化が暴落の危険性を高めるモデルか?
-
大暴落の前に現れる前兆のパターンに含まれる情報は、"一般的なフラクタルの概念や自己相似性の概念、複雑な次元を持つフラクタルの考え方、そして、このフラクタルに関連した離散的自己相似性、さらに、これらの驚くべき幾何学的・数学的な概念"によって、体系化できるのか?
-
暴落前に前兆が現れるか?
-
市場間に強い相関関係が働くことはあるか?
-
市場の暴落や他の大事件は予測できるのか?
-
期待される予測の正確さと見通せる範囲はわかるのか?
-
「アンチバブル(反バブル)」の顕著な実例は何か?
参考:why stock markets crash by Sornette
参考
Python3ではじめるシステムトレード【第2版】環境構築と売買戦略

「画像をクリックしていただくとpanrollingのホームページから書籍を購入していただけます。

「画像をクリックしていただくとpanrollingのホームページから書籍を購入していただけます。」