はじめに
推薦システムを開発していると、Embedding を2次元に圧縮して可視化しユーザーや商品の関係性を定性的に確認したくなる場面があります。
従来の課題
可視化をするために、ローカルで Jupyter セッションを立ち上げ、 BigQuery への認証を行い、データを取得してから Python で t-SNE を実行し、それを matplotlib で可視化、といった手順が必要でした。この過程では作業に時間がかかることやコンテキストスイッチが頻繁に発生してしまい作業前の面倒さの発生や集中が途切れたりすることが問題でした。
解決策:BigQuery Python UDFの活用
BigQuery Python UDF を使うことで、SQL の中で Python を使用し t-SNE を実行します。これにより可視化までの手順を簡素化します。
BigQuery Python UDFは2025年12月時点でプレビュー段階です。本番環境での利用は制限事項をご確認ください。
クエリの実行
以下のようなクエリを実行することで実現可能です。
- t-SNE(BigQuery Python UDF)の定義
- サンプルデータ作成 & t-SNE 実行
-- ===========================================
-- Phase 1: t-SNE UDFの定義
-- ===========================================
CREATE OR REPLACE FUNCTION `your_project.your_dataset`.tsne_reduce(
embeddings ARRAY<STRUCT<id STRING, embedding ARRAY<FLOAT64>>>,
perplexity FLOAT64
) RETURNS ARRAY<STRUCT<id STRING, tsne_x FLOAT64, tsne_y FLOAT64>>
LANGUAGE python
OPTIONS (
entry_point='run_tsne',
runtime_version='python-3.11',
packages=['scikit-learn==1.7.2'],
container_memory='4Gi',
container_cpu=1.0
)
AS r"""
import numpy as np
from sklearn.manifold import TSNE
def run_tsne(embeddings, perplexity):
ids = [e['id'] for e in embeddings]
X = np.array([e['embedding'] for e in embeddings])
tsne = TSNE(n_components=2, perplexity=min(perplexity, len(X) - 1),
random_state=42, learning_rate='auto', init='pca')
X_embedded = tsne.fit_transform(X)
return [{'id': ids[i], 'tsne_x': float(X_embedded[i, 0]),
'tsne_y': float(X_embedded[i, 1])} for i in range(len(ids))]
""";
-- ===========================================
-- Phase 2: サンプルデータ作成 & t-SNE実行
-- ===========================================
WITH sample_data AS (
SELECT 'item_1' AS id, 1 AS cluster_id, [0.1, 0.2, 0.1, 0.2, 0.15, 0.18, 0.12, 0.22] AS embedding UNION ALL
SELECT 'item_2', 1, [0.12, 0.18, 0.13, 0.21, 0.14, 0.19, 0.11, 0.23] UNION ALL
SELECT 'item_3', 1, [0.08, 0.22, 0.09, 0.19, 0.16, 0.17, 0.13, 0.21] UNION ALL
SELECT 'item_4', 1, [0.11, 0.19, 0.12, 0.2, 0.13, 0.2, 0.1, 0.24] UNION ALL
SELECT 'item_5', 1, [0.09, 0.21, 0.1, 0.18, 0.17, 0.16, 0.14, 0.2] UNION ALL
SELECT 'item_6', 1, [0.13, 0.17, 0.14, 0.22, 0.12, 0.21, 0.09, 0.25] UNION ALL
SELECT 'item_7', 2, [0.5, 0.5, 0.48, 0.52, 0.49, 0.51, 0.47, 0.53] UNION ALL
SELECT 'item_8', 2, [0.48, 0.52, 0.5, 0.5, 0.51, 0.49, 0.49, 0.51] UNION ALL
SELECT 'item_9', 2, [0.52, 0.48, 0.49, 0.51, 0.48, 0.52, 0.5, 0.5] UNION ALL
SELECT 'item_10', 2, [0.49, 0.51, 0.47, 0.53, 0.5, 0.5, 0.48, 0.52] UNION ALL
SELECT 'item_11', 2, [0.51, 0.49, 0.52, 0.48, 0.47, 0.53, 0.51, 0.49] UNION ALL
SELECT 'item_12', 2, [0.47, 0.53, 0.51, 0.49, 0.52, 0.48, 0.46, 0.54] UNION ALL
SELECT 'item_13', 3, [0.8, 0.1, 0.82, 0.08, 0.79, 0.11, 0.81, 0.09] UNION ALL
SELECT 'item_14', 3, [0.82, 0.08, 0.8, 0.1, 0.81, 0.09, 0.79, 0.11] UNION ALL
SELECT 'item_15', 3, [0.78, 0.12, 0.81, 0.09, 0.8, 0.1, 0.82, 0.08] UNION ALL
SELECT 'item_16', 3, [0.81, 0.09, 0.79, 0.11, 0.78, 0.12, 0.8, 0.1] UNION ALL
SELECT 'item_17', 3, [0.79, 0.11, 0.83, 0.07, 0.82, 0.08, 0.78, 0.12] UNION ALL
SELECT 'item_18', 3, [0.83, 0.07, 0.78, 0.12, 0.77, 0.13, 0.83, 0.07] UNION ALL
SELECT 'item_19', 4, [0.2, 0.8, 0.18, 0.82, 0.21, 0.79, 0.19, 0.81] UNION ALL
SELECT 'item_20', 4, [0.18, 0.82, 0.2, 0.8, 0.19, 0.81, 0.21, 0.79] UNION ALL
SELECT 'item_21', 4, [0.22, 0.78, 0.19, 0.81, 0.2, 0.8, 0.18, 0.82] UNION ALL
SELECT 'item_22', 4, [0.19, 0.81, 0.21, 0.79, 0.22, 0.78, 0.2, 0.8] UNION ALL
SELECT 'item_23', 4, [0.21, 0.79, 0.17, 0.83, 0.18, 0.82, 0.22, 0.78] UNION ALL
SELECT 'item_24', 4, [0.17, 0.83, 0.22, 0.78, 0.23, 0.77, 0.17, 0.83] UNION ALL
SELECT 'item_25', 5, [0.9, 0.9, 0.88, 0.92, 0.89, 0.91, 0.87, 0.93] UNION ALL
SELECT 'item_26', 5, [0.88, 0.92, 0.9, 0.9, 0.91, 0.89, 0.89, 0.91] UNION ALL
SELECT 'item_27', 5, [0.92, 0.88, 0.89, 0.91, 0.88, 0.92, 0.9, 0.9] UNION ALL
SELECT 'item_28', 5, [0.89, 0.91, 0.87, 0.93, 0.9, 0.9, 0.88, 0.92] UNION ALL
SELECT 'item_29', 5, [0.91, 0.89, 0.92, 0.88, 0.87, 0.93, 0.91, 0.89] UNION ALL
SELECT 'item_30', 5, [0.87, 0.93, 0.91, 0.89, 0.92, 0.88, 0.86, 0.94]
),
aggregated AS (
SELECT ARRAY_AGG(STRUCT(id, embedding)) AS data
FROM sample_data
)
SELECT
r.id,
r.tsne_x,
r.tsne_y,
s.cluster_id
FROM aggregated,
UNNEST(`your_project.your_dataset`.tsne_reduce(data, 5.0)) AS r
JOIN sample_data s ON r.id = s.id;
可視化
出力されたテーブルを Looker Studio で開き、散布図(X軸: tsne_x、Y軸: tsne_y)を作成するだけで可視化できます。
▼ 結果テーブルを Looker Studio で開く BigQuery の操作画面

▼ Looker Studio 散布図での可視化
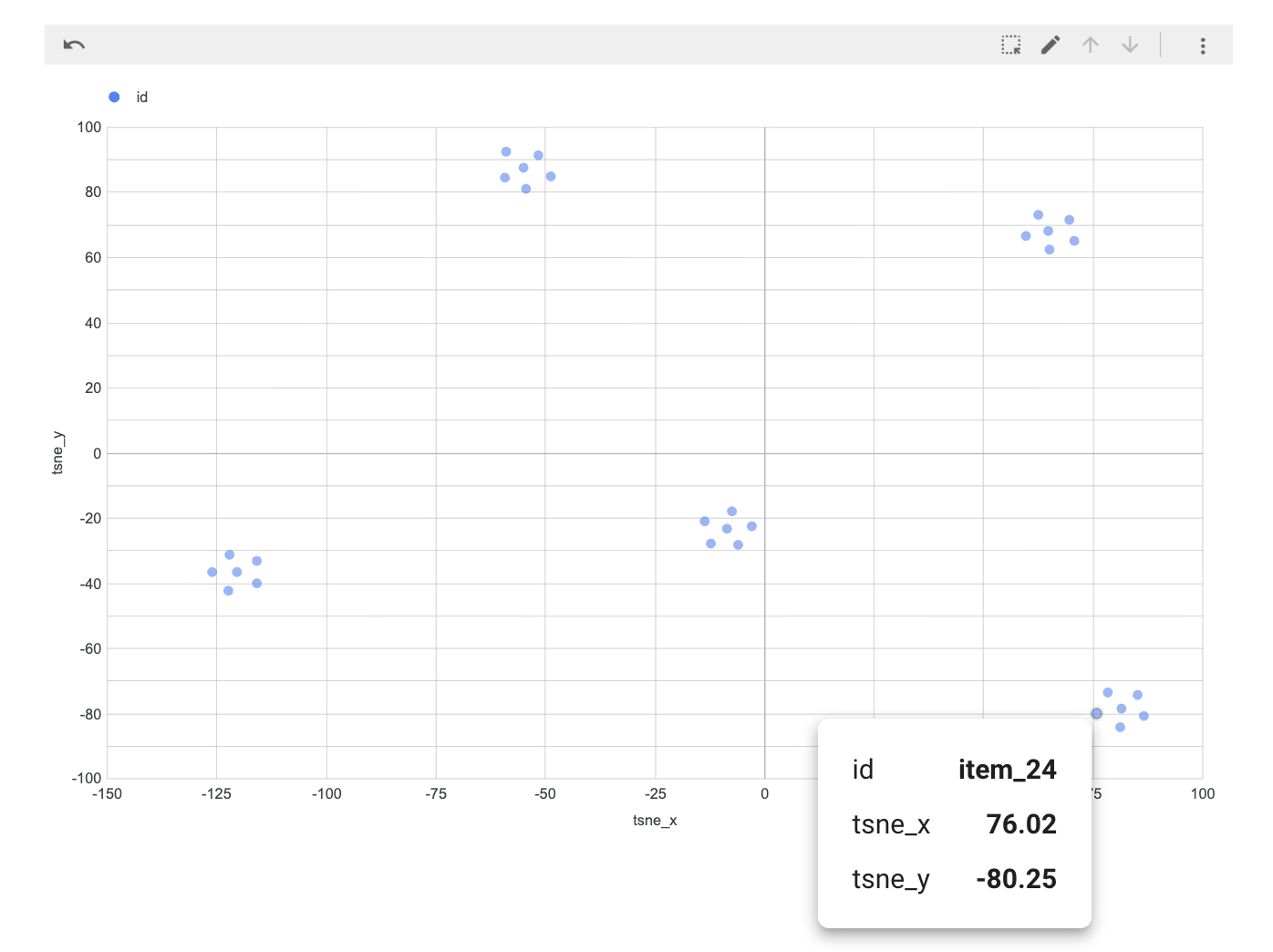
結果
肌感覚ですが、今回の改善によって作業時間とコンテキストスイッチの回数を以下のように削減しました。
| 項目 | Before | After |
|---|---|---|
| 作業時間 | 約30分 | 約5分 |
| コンテキストスイッチ | 4回以上 | 1回 |
おわりに
BigQuery Python UDF は、もちろん t-SNE 以外の用途でも使用可能です。さらに SQLベースなのでチームメンバーにクエリを共有するだけで誰でも手元に Python 環境を必要とせず実行可能な点もメリットです。