はじめに
この記事は、42Tokyo Advent Calendar 2025の15日目の記事です。
最近は42内でもデータサイエンスといった文脈が多く登場するようになった(はずな)ので、最適化、特にスパースモデリングについて書きます。
前提知識と本記事の範囲
本記事は、線形代数(ベクトル・行列演算、ノルム)と微分(勾配)の基礎を前提とします。
凸解析については、定義や性質を必要に応じて示しますが、理論的な詳細には踏み込みません。凸解析は数学的に美しい理論体系であり、最適化の分野において「線形/非線形」から「凸/非凸」という問題の大別へのパラダイムシフトをもたらしました。本記事で登場する近接写像(proximal operator)などの概念も凸解析に基づいていますが、ここではツールとして利用するに留めます。
0. なぜ今スパースモデリングか
0.1 最新研究との接点
近年、大規模言語モデル(LLM)の内部構造を理解しようとする「解釈性研究」が活発化しています。その中で注目されているのがスパース構造です。ニューラルネットワークの重みや活性化パターンがスパース(疎)であれば、「どのニューロンが何を担当しているか」を特定しやすくなります。
例えば、Weight-sparse Transformerに関する最近の研究 (2025-12-15現在)では、モデルの重みをスパースにすることで解釈性を高める試みが報告されています。ただし、これには精度とのトレードオフがあり、スパース性を強めると推論性能が低下する傾向があります。解釈性と精度のバランスは、今なお活発に研究されている領域です。
0.2 本記事の立場
本記事では、このような最新のトピックとは少し距離を置き、より古典的かつ数理的な観点からスパースモデリングを解説します。
既存の日本語記事の多くは、「$\ell_1$ 正則化(LASSO)を使えばスパースな解が得られる」というトップダウンの説明になっています。しかし、これでは「なぜ $\ell_1$ なのか」という本質的な疑問に答えられません。
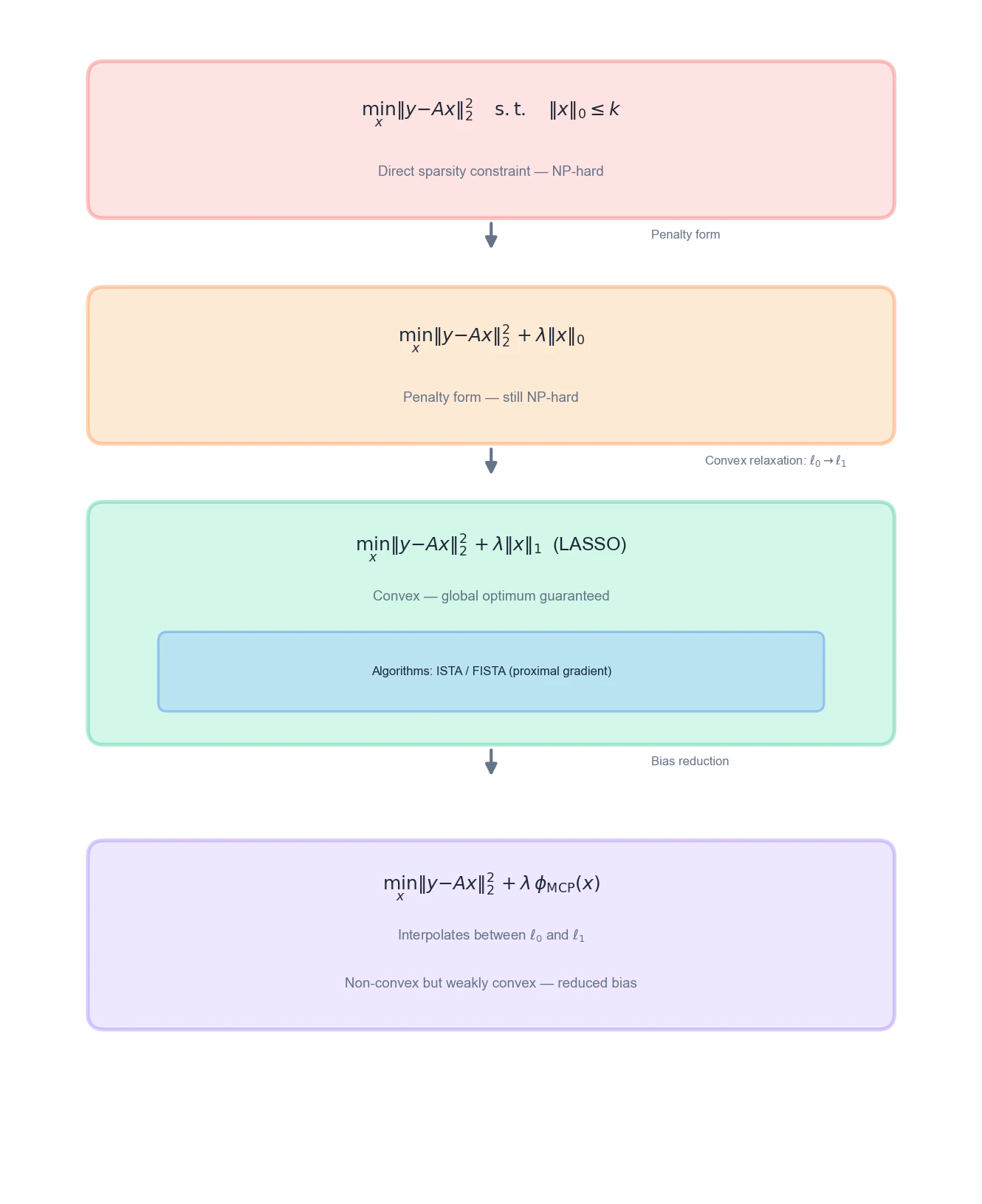
本記事の方針はボトムアップです。スパース性を直接的に表現する $\ell_0$ ノルムから出発し、なぜそれが計算困難なのか、なぜ $\ell_1$ への緩和が有効なのかを、論理的に導いていきます。最後にやや発展的ではありますが、$\ell_1$の弱点であるバイアス問題を解決するMCPに触れます。(巷で話題のModel Context Protcolではなく、Minimax Concave Penaltyというものです。)
本記事で辿る道筋を下図に示します。
1. スパース性とは何か
1.1 定義
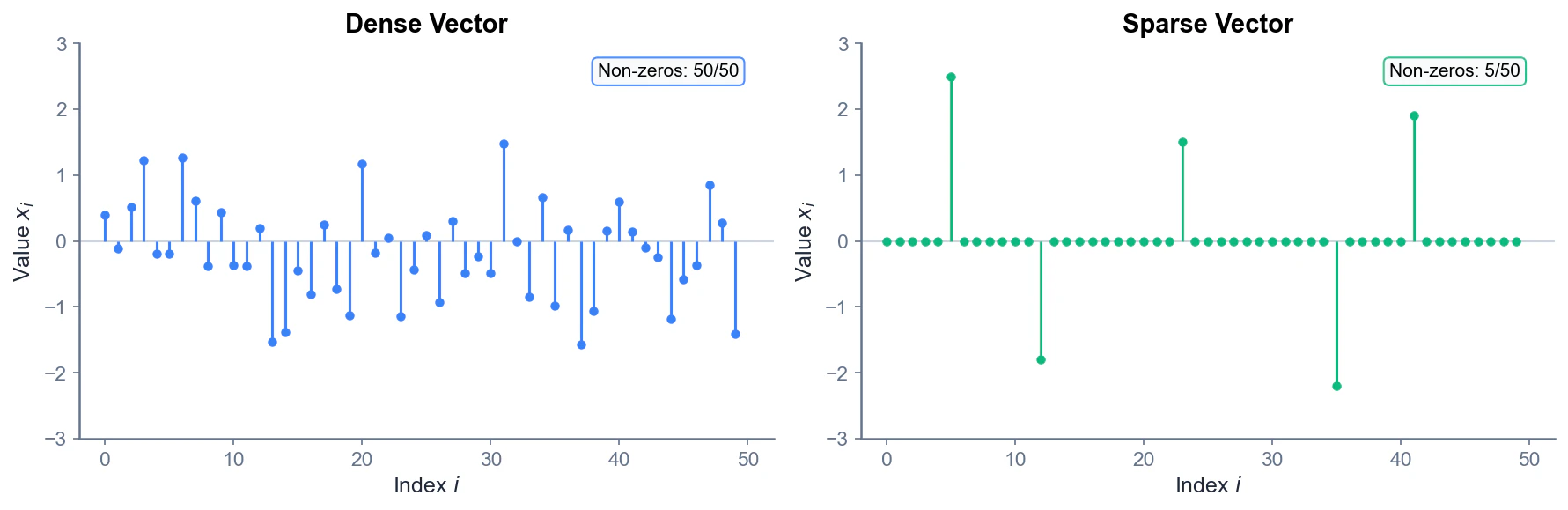
スパース(sparse) とは「疎」を意味し、スパースベクトルとは非ゼロ要素が少ないベクトルのことです。
例えば、10次元のベクトル
$$
x = (0, 0, 2.5, 0, 0, 0, -1.3, 0, 0, 0)
$$
は、10個の成分のうち2個だけが非ゼロなので「スパース」です。このようなベクトルを $k$-スパース と呼び、上の例は2-スパースです。
反対に、ほとんどの成分が非ゼロのベクトルはDense(密) と呼ばれます。
1.2 スパース性は「仮定」である
重要な点として、スパース性はデータの性質として仮定するものです。
自然界の多くの信号は、適切な基底(表現方法)を選ぶとスパースになることが知られています。
- 画像: ウェーブレット基底で表現すると、大部分の係数がほぼゼロになる
- 音声: フーリエ基底で表現すると、特定の周波数成分だけが大きい
- 遺伝子発現: 数万の遺伝子のうち、特定の条件で発現するのは少数
このような「適切な空間ではスパースになる」という事前知識があるからこそ、スパースモデリングは強力なツールになります。
1.3 スパース性が活きる場面
スパースな解を求めることには、いくつかの重要な応用があります。
モデルの解釈性
スパース性の最も直接的な恩恵は解釈性です。非ゼロの成分だけが「意味のある」変数なので、何が重要かが一目瞭然になります。
導入で触れたWeight-sparse Transformerはその一例です。ニューラルネットワークの重みをスパースにすることで、「どのニューロンが何を担当しているか」を特定しやすくなります。
もう一つの例はSINDy (Sparse Identification of Nonlinear Dynamics) です。これは、観測データから微分方程式を発見する手法で、候補となる項($x$, $x^2$, $\sin x$, ...)の中からスパースな組み合わせを選ぶことで、シンプルかつ解釈可能な支配方程式を同定します。
データだけから生成元の微分方程式を同定するというのはなかなかインパクトがあります。アルゴリズムは以下に公開されています。
線形逆問題
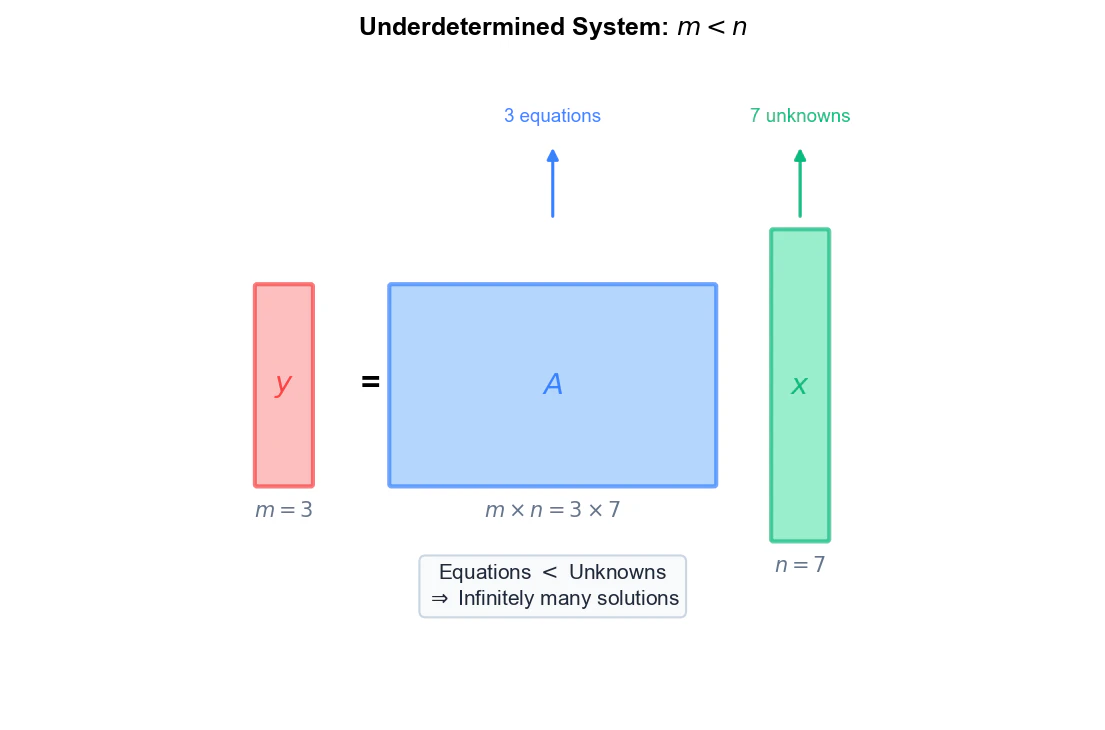
スパースモデリングのもう一つの重要な舞台は線形逆問題です。
$$
y = Ax + \varepsilon
$$
ここで、
- $y \in \mathbb{R}^m$ : 観測ベクトル
- $A \in \mathbb{R}^{m \times n}$ : 設計行列
- $x \in \mathbb{R}^n$ : 推定したい未知ベクトル
- $\varepsilon \in \mathbb{R}$ : ノイズ
$m < n$(観測数 < 未知数)の劣決定系では、方程式を満たす解が無限に存在します。しかし「$x$ はスパースである」という仮定を導入すると、無限にある解の中から「最もスパースなもの」を選ぶことで、解を一意に特定できる可能性が生まれます。
これはオッカムの剃刀の数学的表現とも言えます。応用例としては
- MRI画像の高速撮影(少ないサンプルから画像を再構成)
- 遺伝子発現解析(サンプル数 << 遺伝子数)
- レコメンドシステム(観測された評価 << 全ユーザー×全アイテム)
その他の利点
- 計算効率: 非ゼロ要素だけを扱えばよいので、ストレージも計算時間も削減できる
- 過学習の-抑制: 使う変数を少なくすることで、モデルの複雑さを制限し、汎化性能を高める
1.4 本記事の焦点
以降は線形逆問題を舞台に、スパース最適化の数理を展開します。
2. スパース最適化の定式化
2.1 l0 制約付き最小化
「スパースな解を求める」という目標を最も直接的に表現すると、次の最適化問題になります。
\min_{x} \|y - Ax\|_2^2 \quad \text{subject to} \quad \|x\|_0 \leq k
ここで $|x|_0$ は $\ell_0$ ノルムで、ベクトル $x$ の非ゼロ要素の個数を表します。
\|x\|_0 := |\{i : x_i \neq 0\}|
つまり、この問題は「データへの当てはまり $||y - Ax||_2^2$ を最小化しつつ、非ゼロ要素は $k$ 個以下に抑える」という意味です。これこそがスパース推定の本質的な定式化です。
「$\ell_0$ ノルム」と呼ばれますが、ノルムの公理における正斉次性を満たさないため、厳密にはノルムではなく擬似ノルム(pseudo-norm)です。
2.2 なぜ l0 制約付き最小化は難しいか
$\ell_0$ 制約付き最小化は、NP-hard であることが知られています。つまり、問題サイズが大きくなると、厳密に解くことが実質的に不可能になります。
NP-hardとは?
計算量理論における問題の難しさの分類で、NP-complete以上に難しい問題群を指します。$P \neq NP$ 予想の下では、多項式時間で解くアルゴリズムが存在しないとされています。
計算量の観点から見ると、非ゼロ成分をどの $k$ 個にするかを決める問題は、$n$ 個から $k$ 個を選ぶ組合せです。その場合の数は
$$
\binom{n}{k} = \frac{n!}{k!\ (n-k)!}
$$
例えば $n = 1000$, $k = 10$ の場合、約 $2.6 \times 10^{23}$ 通りの組合せがあります。全探索は現実的ではありません。
最適化の観点から見ると、制約集合 ${x : ||x||_0 \leq k}$ が非凸です。非凸集合上の最適化では、局所解に陥るリスクがあり、勾配法のような標準的なアルゴリズムが使えません。
さらに、$\ell_0$ ノルムは原点以外で微分が定義できない(不連続)ため、勾配ベースの最適化が根本的に適用できません。
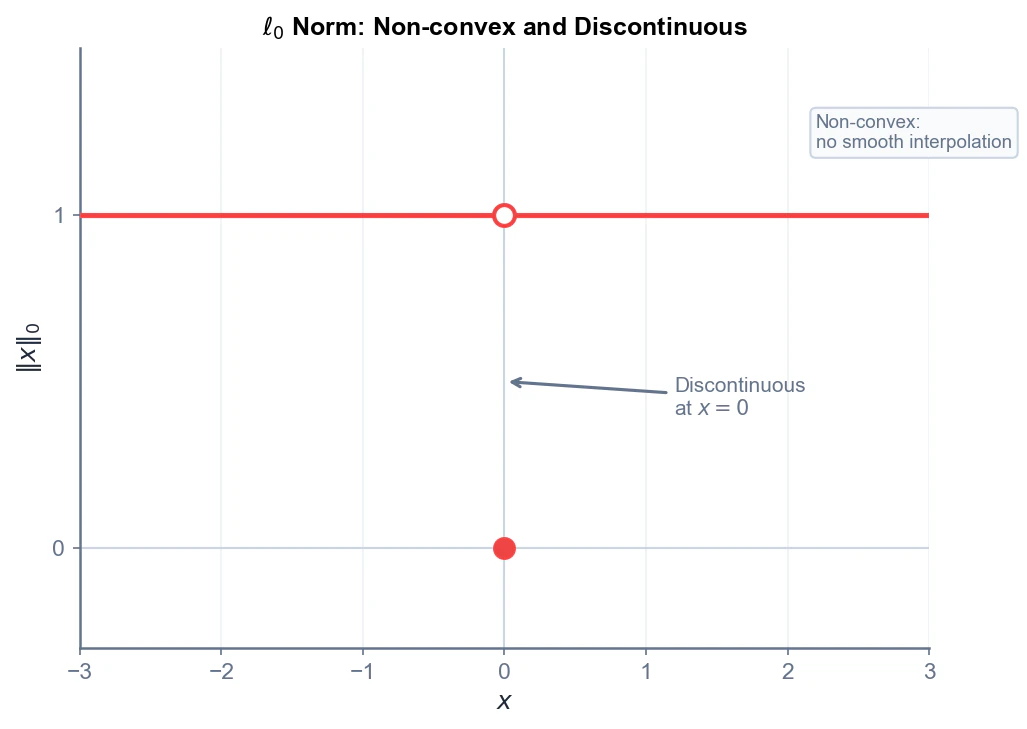
3. 制約から正則化へ
3.1 l0 正則化
$\ell_0$ 制約付き最小化の制約を、目的関数に組み込む方法があります。
\min_{x} \|y - Ax\|_2^2 + \lambda \|x\|_0
制約 $||x||_0 \leq k$ の代わりに、$||x||_0$ を「ペナルティ」として目的関数(コスト関数)に加えています。
$\lambda > 0$ は正則化パラメータで、スパース性の強さを制御します。
- $\lambda$ が大きい → スパース性を強く要求(非ゼロ要素が少ない解)
- $\lambda$ が小さい → データへの当てはまりを重視(非ゼロ要素が多い解)
3.2 依然としてNP-hard
正則化形式に変換しても、$\ell_0$ の非凸性・離散性は残ったままです。
目的関数の損失項 $||y - Ax||_2^2$ は凸ですが、正則化項 $||x||_0$ は非凸なので、全体としては非凸最適化問題のままです。解を求めるのは依然としてNP-hardです。
ここで発想の転換が必要です。
$\ell_0$ そのものを扱うのではなく、$\ell_0$ に「近い」が「扱いやすい」ものに置き換える。
これが凸緩和のアイデアです。
4. 凸緩和:l1 ノルムの登場
4.1 LASSO
ここでついに $\ell_1$ ノルムが登場します。
\min_{x} \|y - Ax\|_2^2 + \lambda \|x\|_1
ここで
\|x\|_1 := \sum_{i=1}^{n} |x_i|
です。この問題は LASSO (Least Absolute Shrinkage and Selection Operator) と呼ばれる有名な問題です。
4.2 なぜ l1 が「最良の」凸緩和か
$\ell_1$ が $\ell_0$ の代わりに使われる理由は、$\ell_1$ が $\ell_0$ の最もtightな凸緩和だからです。これは幾何学的に理解できます。
凸包としての $\ell_1$
2次元で考えます。$\ell_0$ の unit ball ${x : ||x||_0 \leq 1}$ は、座標軸上の点の集合、すなわち十字の形状です(ちょうど1成分だけが非ゼロ、または原点)。
この十字型集合の 凸包(convex hull) を取ると、正方形になります。これがまさに $\ell_1$ の unit ball ${x : ||x||_1 \leq 1}$ です。
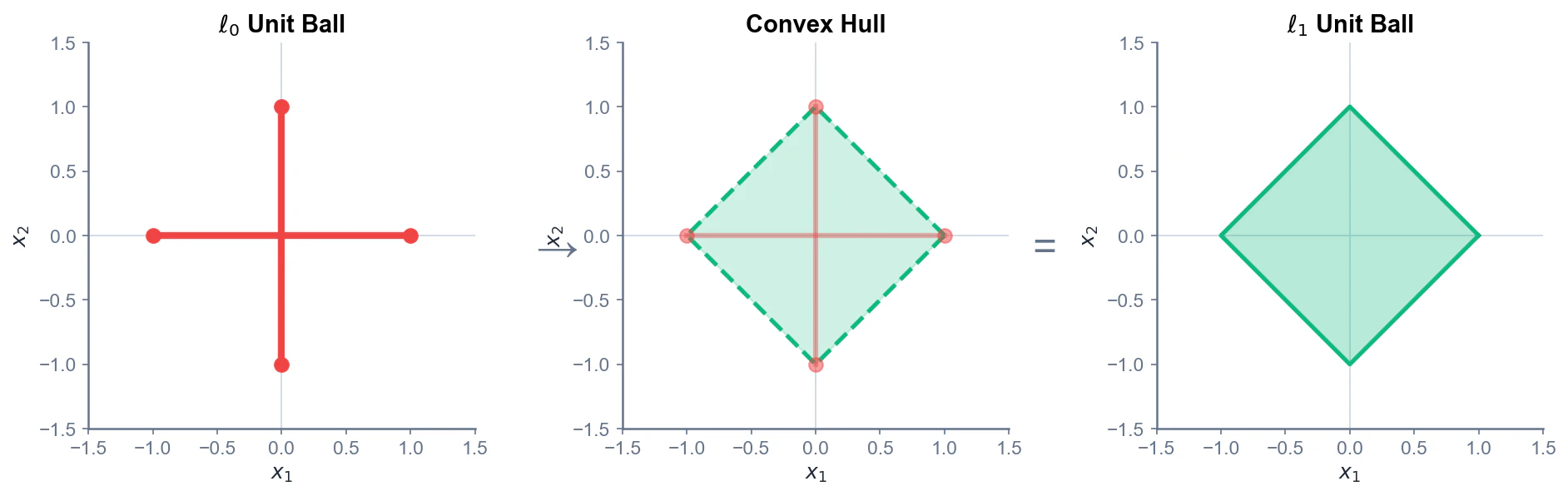
つまり、$\ell_1$ は $\ell_0$ を凸集合で近似するとき、最もギッチギチに近似するものなのです。
等高線との接触(直感的な理解)
LASSOの幾何学的解釈も直感を与えてくれます。制約形式で書くと、
\min_{x} \|y - Ax\|_2^2 \quad \text{subject to} \quad \|x\|_1 \leq t
損失関数 $||y - Ax||_2^2$ の等高線と、$\ell_1$ ball ${x : ||x||_1 \leq t}$ の交点が解になります。
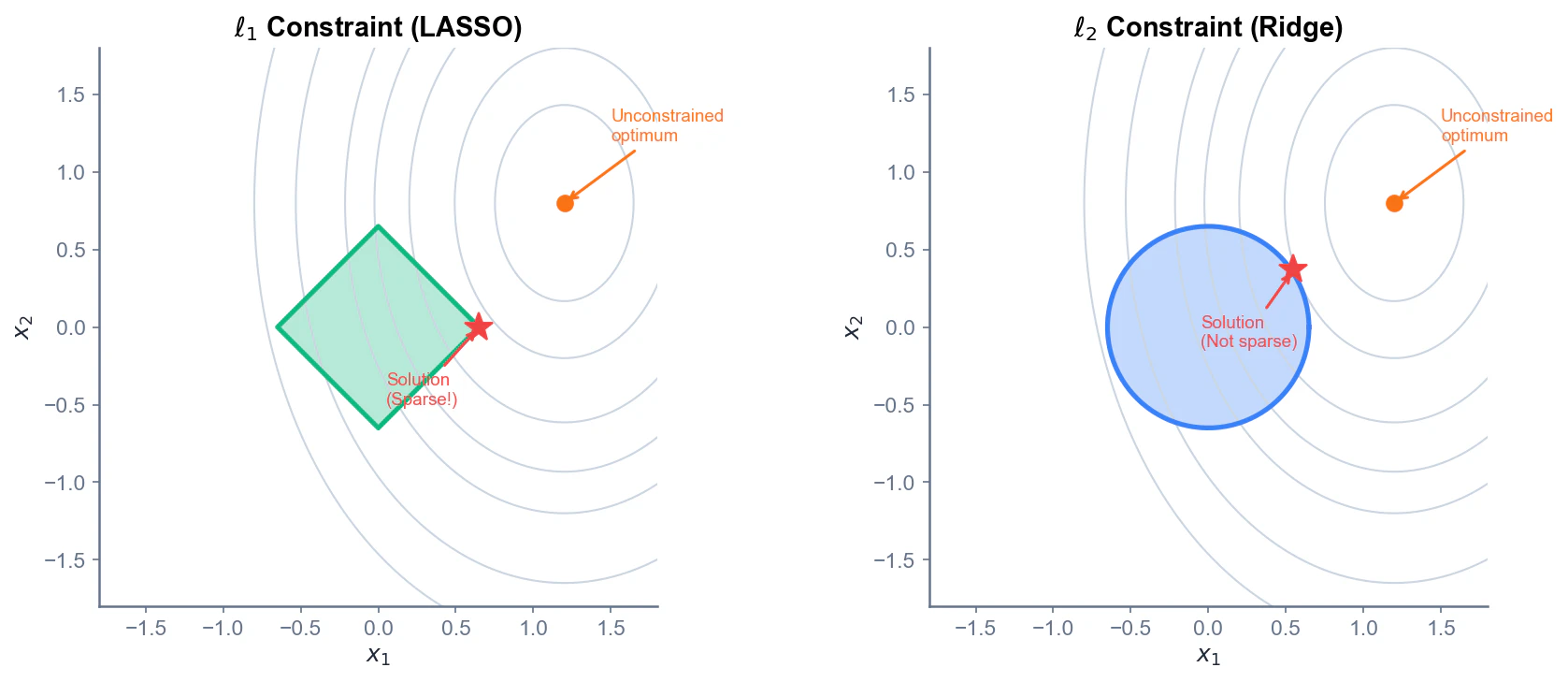
$\ell_1$ ball はひし形なので、等高線との接点は高確率で角(座標軸上)になります。角は少なくとも1つの成分が0であることを意味するので、スパースな解が得られます。
これが $\ell_2$ 正則化(Ridge回帰)との決定的な違いです。$\ell_2$ ball は円なので、等高線との接点は一般に座標軸上にはなく、スパースな解は得られません。
ただし、これはあくまで直感的な説明です。スパース促進の本質的なメカニズムは、次章で説明する近接写像にあります。
4.3 凸性の恩恵
LASSOの目的関数 $||y - Ax||_2^2 + \lambda ||x||_1$ を見ると、
- $||y - Ax||_2^2$:$x$ について凸(2次関数)
- $||x||_1$:$x$ について凸(ノルム)
- 凸関数の和は凸(凸性の保存)
なので、全体として凸最適化問題になります。
凸最適化の素晴らしい性質は、局所最適解が大域最適解に一致することです。どこから探索を始めても、正しく収束すれば最適解に到達できます。初期値依存性がなく、アルゴリズムの設計が大幅に簡単になります。
$\ell_1$ 緩和がうまくいく条件について、理論的な研究が進んでいます。特に有名なのが RIP (Restricted Isometry Property) です。
RIPは、行列 $A$ が「スパースベクトルの長さをあまり変えない」という性質を定量化したものです。$A$ がRIPを満たすとき、$\ell_1$ 最小化によって真のスパース解を正確に復元できることが証明されています。
これが圧縮センシング (Compressed Sensing) の理論的基盤です。
5. LASSOの解法とスパース促進の本質
5.1 非平滑凸関数最適化としてのLASSO
LASSOを効率的に解くために、問題の構造を分析します。目的関数を2つの部分に分解します。
\min_{x} \underbrace{\|y - Ax\|_2^2}_{=:f(x)} + \underbrace{\lambda \|x\|_1}_{=:g(x)}
- $f(x) := ||y - Ax||_2^2$:平滑(微分可能)で凸
- $g(x) := \lambda ||x||_1$:非平滑($x_i = 0$ で微分不可能)だが凸
このような「滑らかな凸関数 + 非滑らかな凸関数」の形は、機械学習や信号処理で頻繁に現れます。この問題には 近接勾配法 (proximal gradient method) という標準的な解法が存在します。
5.2 なぜ通常の勾配法が使えないか
$f(x)$ だけなら、通常の勾配降下法が使えます。
$$
x^{(k+1)} = x^{(k)} - \eta \nabla f(x^{(k)})
$$
しかし、$g(x) = \lambda ||x||_1$ は $x_i = 0$ で微分が定義されません。絶対値関数 $|x_i|$ の微分を考えると、
\frac{d|x_i|}{dx_i} = \begin{cases} 1 & (x_i > 0) \\ -1 & (x_i < 0) \\ \text{undefined} & (x_i = 0) \end{cases}
となり、原点で不連続です。
5.3 近接写像 (Proximal Operator)
ここで登場するのが 近接写像(proximal operator) です。関数 $g$ に対する近接写像は、
\mathrm{prox}_{\eta g}(v) := \mathrm{argmin}_{x} \left\{ g(x) + \frac{1}{2\eta}\|x - v\|_2^2 \right\}
と定義されます。これは「$g(x)$ を小さくしつつ、$v$ の近くにいる」点を返す写像です。
近接写像は凸解析の理論で非平滑関数を扱うための強力なツールです。
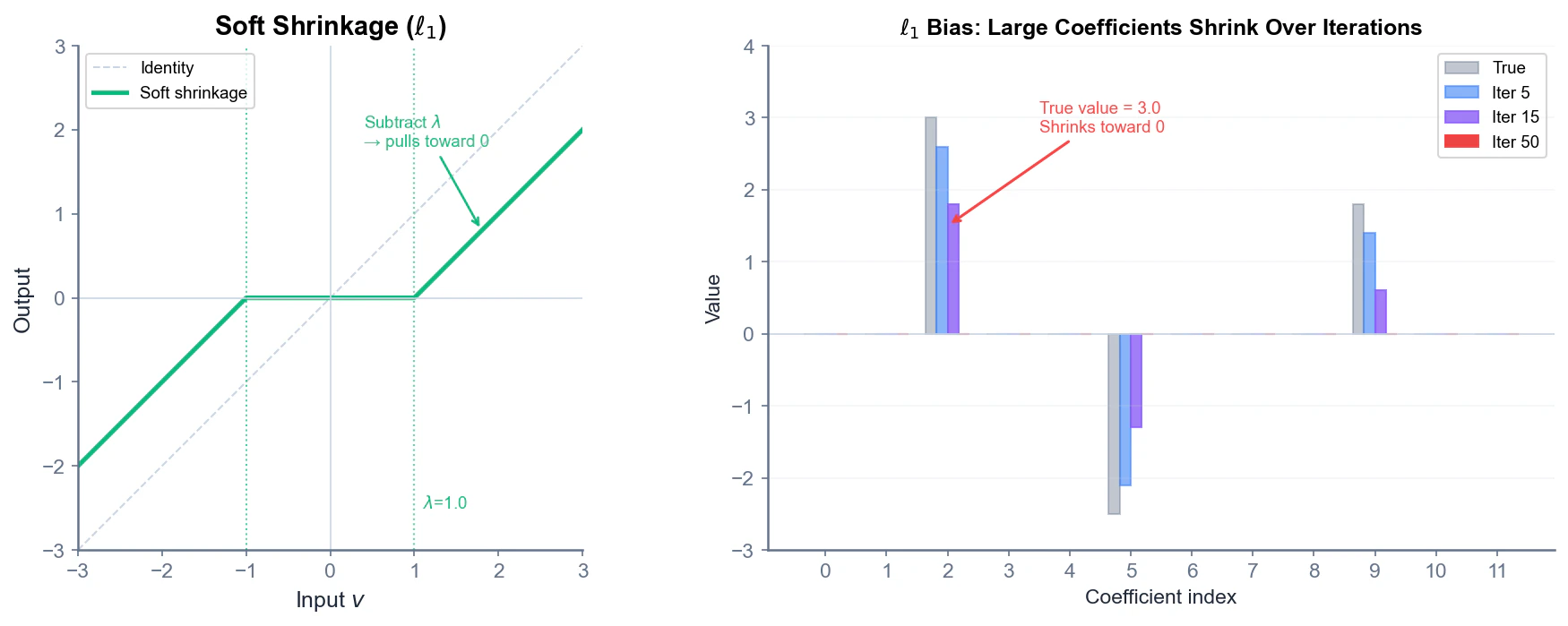
5.4 l1 の近接写像: Soft Shrinkage (スパース促進の本質)
$\ell_1$ ノルムの近接写像は、成分ごとに分解でき、以下のように計算できます。
\left[\mathrm{prox}_{\eta \lambda \|\cdot\|_1}(v)\right]_i = \mathrm{sign}(v_i) \cdot \max(|v_i| - \eta\lambda, 0)
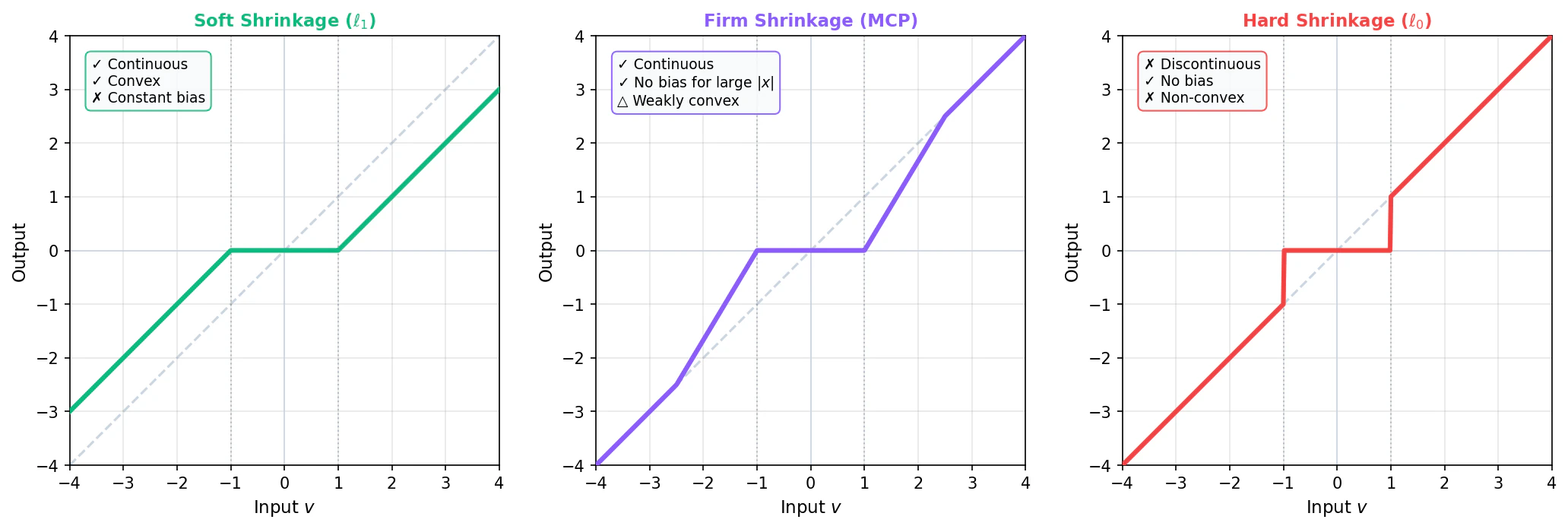
これは Soft Shrinkage と呼ばれる演算です。
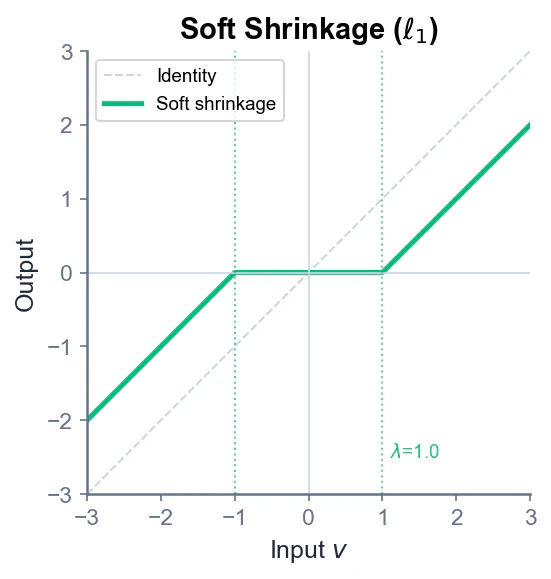
Soft Shrinkageの動作は:
- $|v_i| < \eta\lambda$ のとき → 出力は0(小さな値は完全に潰す)
- $|v_i| \geq \eta\lambda$ のとき → 出力は $v_i$ を $\eta\lambda$ だけ原点に近づけた値
この「閾値以下を0にする」性質が、スパース性を生む本質的なメカニズムです。等高線の幾何学的説明は直感を与えてくれますが、実際にスパースな解を生成するのはこのSoft Shrinkageです。
5.5 参考:l0 の近接写像: Hard Shrinkage
比較のため、$\ell_0$ ノルムの近接写像も見てみます。
\left[\mathrm{prox}_{\eta \lambda \|\cdot\|_0}(v)\right]_i = \begin{cases} v_i & (|v_i| > \sqrt{2\eta\lambda}) \\ 0 & (|v_i| \leq \sqrt{2\eta\lambda}) \end{cases}
これは Hard Shrinkage と呼ばれます。閾値以下を0にし、閾値以上はそのまま保持します(縮小しない)。
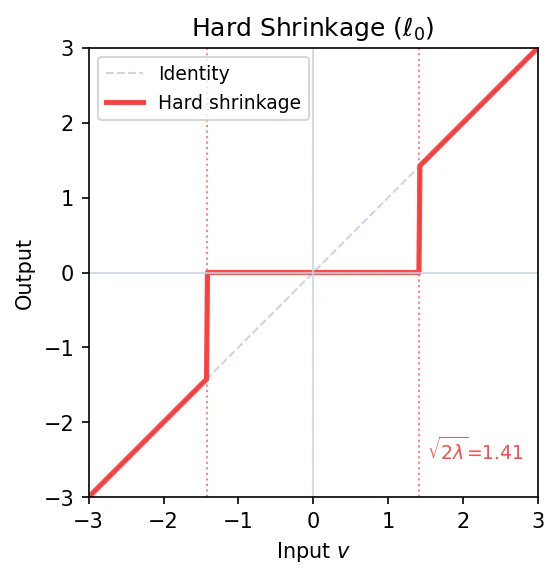
| Soft ($\ell_1$) | Hard ($\ell_0$) | |
|---|---|---|
| 閾値以下 | 0 | 0 |
| 閾値以上 | 縮小 | そのまま |
| 連続性 | 連続 | 不連続 |
Soft Shrinkageは連続なので勾配法と組み合わせやすく、これが $\ell_1$ を使う実用上の大きな利点です。
6. ISTA と FISTA
6.1 近接勾配法
非平滑凸関数の最小化に対する 近接勾配法 (Proximal Gradient Descent) は、以下の更新則を繰り返します。
x^{(k+1)} = \mathrm{prox}_{\eta g}\left( x^{(k)} - \eta \nabla f(x^{(k)}) \right)
直感的には:
- 勾配ステップ: $f$ を小さくする方向に進む
- 近接ステップ: $g$ を考慮して調整する
この2つを交互に繰り返すことで、$f + g$ 全体を最小化します。凸関数の場合、 大域最適解への収束が保証 されています。
6.2 ISTA
LASSOに近接勾配法を適用したものが ISTA (Iterative Shrinkage-Thresholding Algorithm) です。
x^{(k+1)} = \mathrm{prox}_{\frac{\lambda}{L} \|\cdot\|_1}\left( x^{(k)} - \frac{1}{L}\nabla f(x^{(k)}) \right)
$f(x) = ||y - Ax||_2^2$ の場合、$\nabla f(x) = 2A^T(Ax - y)$ なので、
def ista_step(x, A, y, lam, L):
"""One iteration of ISTA."""
z = x - (2/L) * A.T @ (A @ x - y) # gradient step
return soft_shrinkage(z, lam/L) # proximal step
def soft_shrinkage(z, threshold):
"""Soft shrinkage operator."""
return np.sign(z) * np.maximum(np.abs(z) - threshold, 0)
これは非常にシンプルなアルゴリズムで、行列-ベクトル積とSoft Shrinkageだけで実装できます。
ここで $L$ は $\nabla f$ のリプシッツ定数で、$f(x) = ||y - Ax||_2^2$ の場合 $L = 2|A^T A|$($A^T A$ の最大固有値の2倍)です。こういう定数を使うとうまくいくと思っていただいて大丈夫です。
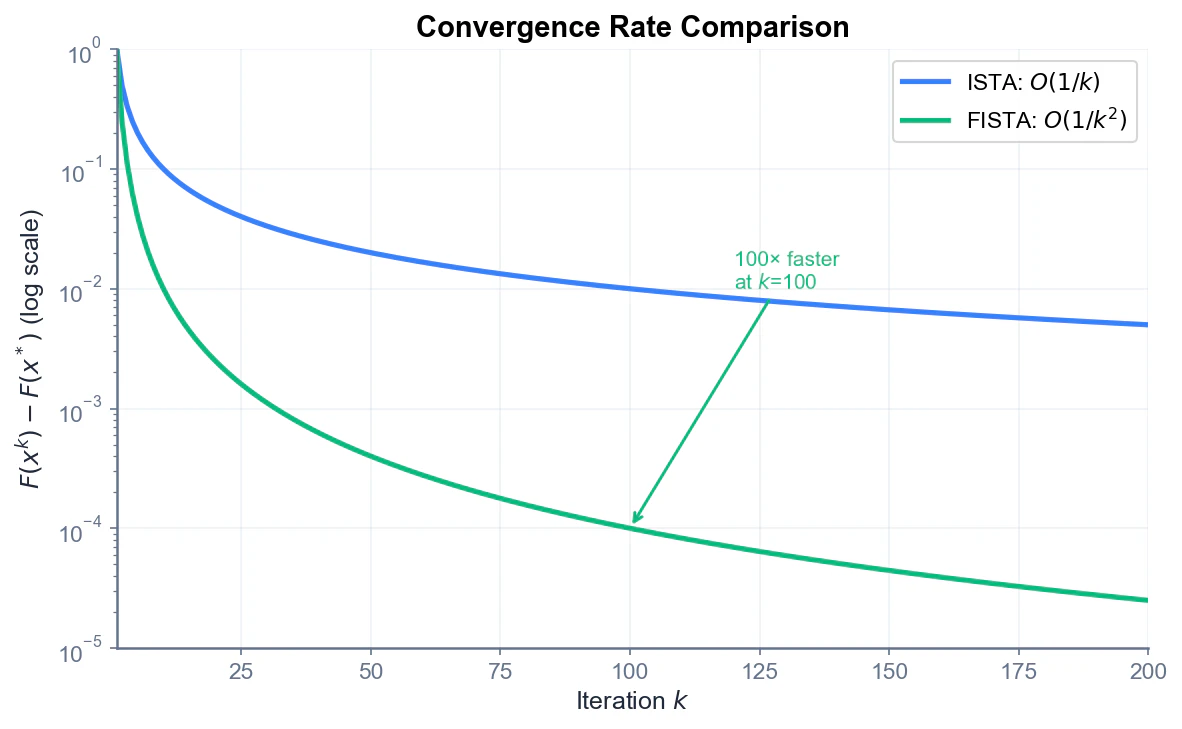
ISTAの収束速度は $O(1/k)$ です。つまり、$k$ 回反復後の目的関数値と最適値の差は $O(1/k)$ で減少します。
6.3 FISTA:momentumによる加速
ISTAの $O(1/k)$ 収束は、高精度な解が必要な場合には遅いことがあります。
FISTA (Fast ISTA) は、Nesterovの加速勾配法のアイデアを取り入れ、 momentum(慣性) を導入することで収束を高速化します。過去の更新方向を「慣性」として利用し、より効率的に最適解に向かいます。
FISTAの収束レートは $O(1/k^2)$ であり、ISTAと比べて劇的な改善ができます。
| 精度 | ISTA | FISTA |
|---|---|---|
| 1% | 100回 | 10回 |
| 0.01% | 10,000回 | 100回 |
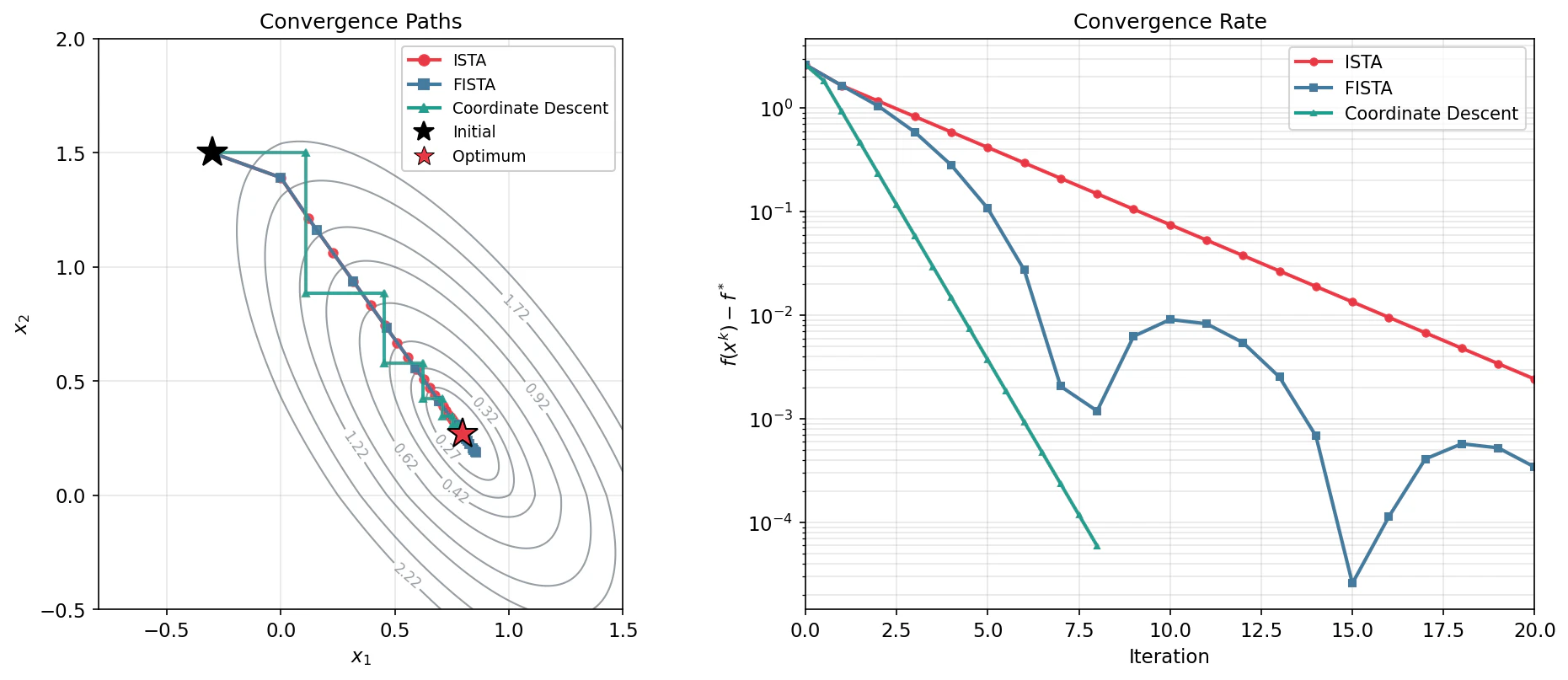
実装について:座標降下法
本記事ではISTAを通じてスパース最適化の本質を解説しましたが、scikit-learnなどの実用ライブラリでは 座標降下法(Coordinate Descent) が採用されています。
座標降下法は1変数ずつ最適化を行う手法です。LASSOの場合、各変数 $x_j$ の更新も閉形式で与えられ、ISTAと同じSoft Shrinkageが現れます。
「1変数ずつ」は遅そうに見えますが、実際には以下の理由で非常に高速であることが知られています。
- 各座標で反復なしに最適値へ直接更新可能
- ゼロの座標をスキップできること(Active Set)
- Warm Start($\lambda$ を変えながら解く際に前の解を初期値として利用)
scikit-learnの実装
scikit-learnでは、LASSOはElastic Netの特殊な場合(l1_ratio=1)として実装されています。
- Python API:
sklearn/linear_model/_coordinate_descent.py - Cython実装:
sklearn/linear_model/_cd_fast.pyx
一方、ISTAは理論的に明快であるため、Group LASSO (説明記事)などへの拡張に向いています。
参考として、ISTA/FISTA/Coordinate Descentの収束の様子を以下に示します。
7. 【発展編】l1 のバイアスと MCP
7.1 l1 のバイアス問題
$\ell_1$ 正則化には重要な弱点があります。バイアス問題です。
Soft Shrinkageは、閾値 $\lambda$ 以下の成分を0に潰し、閾値を超える成分を $\lambda$ だけ縮小します。これは小さな成分をスパースにするには有効ですが、大きな係数も毎イテレーション $\lambda/L$ ずつ縮小されてしまいます。
例えば、真の係数が $x^* = 3.0$ のとき、収束後の推定値は真値より小さくなります。これが $\ell_1$ 正則化に固有のバイアス問題です。
7.2 MCP (Minimax Concave Penalty)
理想的には、小さな係数には強いペナルティ(0に潰したい)、大きな係数には弱いペナルティ(バイアスを避けたい)を与えたいです。$\ell_0$ はまさにこの性質を持ちますが、非凸で扱えません。
MCP (Minimax Concave Penalty) は、Zhang (2010) によって提案された非凸関数のペナルティで、$\ell_0$ と $\ell_1$ の間を補間します。
\phi_{\text{MC}}(x; \lambda, \gamma) := \begin{cases}
\lambda |x| - \frac{x^2}{2\gamma} & (|x| \leq \gamma\lambda) \\
\frac{\gamma \lambda^2}{2} & (|x| > \gamma\lambda)
\end{cases}
パラメータ $\gamma > 1$ により:
- $\gamma \to \infty$: $\ell_1$ に近づく
- $\gamma \to 1$: $\ell_0$ に近づく
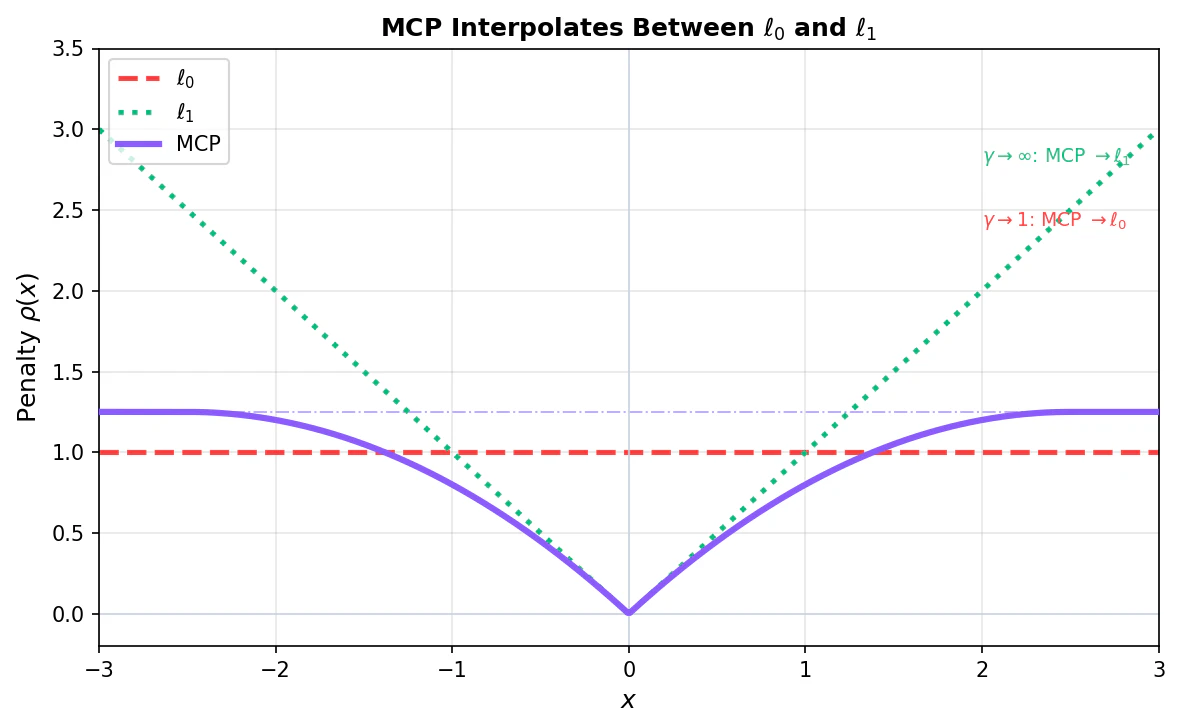
MCPの特徴は、$|x| > \gamma\lambda$ でペナルティが飽和することです。大きな係数に対するペナルティが一定になるため、$\ell_1$ のようなバイアスが生じません。
MCPの近接写像は Firm Shrinkage と呼ばれ、Soft と Hard の中間的な動作をします。
\mathrm{firm}_{\lambda, \gamma}(v) := \begin{cases}
0 & (|v| \leq \lambda) \\
\displaystyle \frac{\gamma}{\gamma - 1}(v - \mathrm{sign}(v)\lambda) & (\lambda < |v| \leq \gamma\lambda) \\
v & (|v| > \gamma\lambda)
\end{cases}
- 小さい値($|v| \leq \lambda$):0に潰す(Softと同様)
- 中程度の値($\lambda < |v| \leq \gamma\lambda$):滑らかに縮小
- 大きい値($|v| > \gamma\lambda$):そのまま保持(Hardと同様、バイアスなし)
7.3 弱凸性と収束保証
MCPは非凸ですが、 弱凸(weakly convex) という性質を持ちます。関数 $h$ が $\rho$-弱凸とは、$h(x) + \frac{\rho}{2}||x||_2^2$ が凸であることを意味します。
MCPは $1/\gamma$-弱凸であり、損失項 $||y - Ax||_2^2$ の凸性が十分強ければ、全体の目的関数の凸性を保つことができます。この場合、近接勾配法による収束保証が得られます。
8. まとめ
1. スパース性の本質は $\ell_0$ にある
$\ell_1$ 正則化は「手段」であり、「本質」ではありません。スパース性を最も直接的に表現するのは $\ell_0$ ノルムです。しかし $\ell_0$ はNP-hardなため、$\ell_1$ という凸緩和を使います。
2. $\ell_1$ が優れている理由
$\ell_1$ は $\ell_0$ の凸包として「最もtightな凸緩和」です。凸性により大域最適解が保証され、効率的なアルゴリズムが使えます。
3. 近接写像(prox)がスパース性を生む
$\ell_1$ の近接写像であるSoft Shrinkageは、閾値以下の成分を0にする操作です。これがスパース性を生む本質的なメカニズムです。LASSOは非平滑凸関数最小化問題のインスタンスであり、ISTAはこの操作を反復適用するアルゴリズムです。
4. 非凸正則化でさらに改善可能
$\ell_1$ にはバイアス問題があります。MCPなどの非凸正則化は、$\ell_0$ と $\ell_1$ の間を補間し、バイアスを軽減します。弱凸性により、一定の条件下で収束保証を持たせることができます。
8.3 参考になる資料
この辺りの最適化が体系的にまとまっている神資料があります。
興味があればこちらも参照してみてください。
8.4 参考文献
- Natarajan, B.K. (1995). Sparse Approximate Solutions to Linear Systems. SIAM J. Comput., 24(2), 227–234.
- Tibshirani, R. (1996). Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B, 58(1), 267–288.
- Candès, E.J. & Tao, T. (2005). Decoding by Linear Programming. IEEE Trans. Inf. Theory, 51(12), 4203–4215.
- Beck, A. & Teboulle, M. (2009). A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sci., 2(1), 183–202.
- Zhang, C.-H. (2010). Nearly Unbiased Variable Selection under Minimax Concave Penalty. Ann. Statist., 38(2), 894–942.
- Parikh, N. & Boyd, S. (2014). Proximal Algorithms. Found. Trends Optim., 1(3), 127–239.
- Bauschke, H.H. & Combettes, P.L. (2011). Convex Analysis and Monotone Operator Theory in Hilbert Spaces. Springer.
- Friedman, J., Hastie, T. & Tibshirani, R. (2010). Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw., 33(1), 1–22.