
猫の正面顔写真集……ではありません。
全てDCGANによって創造された画像です。
以下はHow AI can learn to generate pictures of catsの日本語訳です。
How AI can learn to generate pictures of cats
2014年、Ian J. Goodfellowらによって発表されたGenerative Adversarial Nets論文は、モデル生成の分野において画期的なものでした。
ライバル会社の有力な研究者Yann Lecunも、この研究を「この20年で最もクールなアイデアだ」と認めました。
本日は、この素晴らしいアーキテクチャを使って、猫のフォトリアルな写真を生成するAIを構築していきます。
これはなんと幸福なことでしょう。
全てのコードはGithubで公開されています。
Python、ディープラーニング、Tensorflow、CNN(Convolutional neural network)の経験があるならすぐにわかると思います。
ディープラーニングを初めて学習する場合は、以下の優れた記事を読むとよいでしょう。
What is DCGAN?
Deep Convolutional Generative Adverserial Networks、略してDCGANとは、学習データと似たようなデータを出力するディープラーニングのアーキテクチャです。
このモデルは、GANモデルの全結合層をconvolutionレイヤと置き替えます。
DCGANの仕組みを説明するために、鑑定士と贋作者の喩えを使ってみましょう。
偽造者(generator)は、ゴッホの画像の贋作を作成し、それを売り払おうとします。

他方、鑑定士(discriminator)は、本物のゴッホの画像の知識を使って贋作を見極めようとします。

時間が経つにつれ、鑑定士の目利きレベルは上昇し、贋作者の偽造レベルも上昇します。

DCGANは、互いに競合するふたつのニューラルネットワークで構成されています。
・generatorは、本物っぽいデータを作ろうとする贋作者です。
本物のデータがどのようなものかは知りませんが、discriminatorからのフィードバックを元に学習することができます。
・discriminatorは、本物のデータと比較することによって入力が贋作であるかどうかを判断する鑑定士です。
本物のデータには誤検出を起こさないよう(false positive)に調整されています。
出力はgeneratorに逆伝播します。
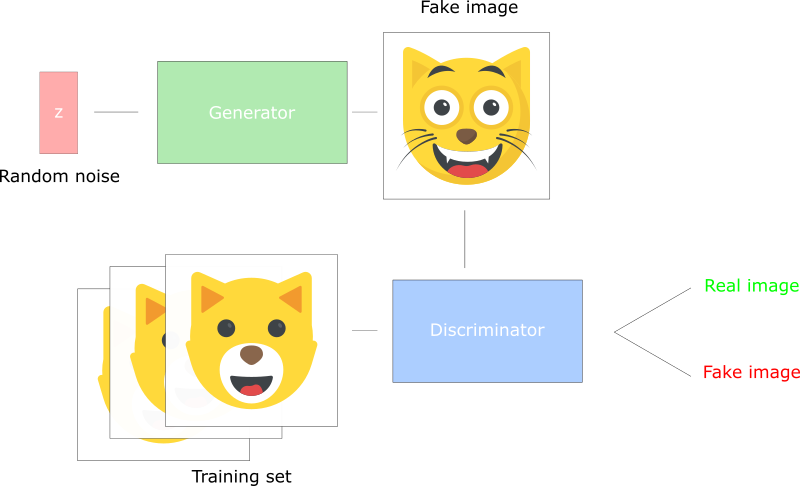
・generatorはランダムノイズから画像を生成してdiscriminatorに送る。
・discriminatorは画像を本物の画像と比較する。
・discriminatorは0(完全に偽物)から1(本物)の間の数値をgeneratorに返す。
Let’s create a DCGAN!
AIを作成する準備が整いました。
このパートでは主要な要素のみ話します。
詳細なコードを知りたい場合はこちらを参照してください。
Inputs
ここでは入力モデルを作成します。
inputs_realはdiscriminator用、inputs_zはgenerator用です。
2個の学習率を使うことに注意してください。
ひとつはdiscriminator用で、もうひとつはgenerator用です。
DCGANはハイパーパラメータにとてもに敏感で、適切にチューニングすることが非常に重要です。
def model_inputs(real_dim, z_dim):
"""
Create the model inputs
:param real_dim: tuple containing width, height and channels
:param z_dim: The dimension of Z
:return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D)
"""
# inputs_real for Discriminator
inputs_real = tf.placeholder(tf.float32, (None, *real_dim), name='inputs_real')
# inputs_z for Generator
inputs_z = tf.placeholder(tf.float32, (None, z_dim), name="input_z")
# Two different learning rate : one for the generator, one for the discriminator
learning_rate_G = tf.placeholder(tf.float32, name="learning_rate_G")
learning_rate_D = tf.placeholder(tf.float32, name="learning_rate_D")
return inputs_real, inputs_z, learning_rate_G, learning_rate_D
The discriminator and the generator
ふたつの理由でtf.variable_scopeを使用しています。
まず、全ての変数名がgeneratorかdiscriminatorで始まるようにできます。
これは後でAIのトレーニングをする際に役立ちます。
次に、これらのネットワークを別の入力で再利用したいと考えています。
・generatorはトレーニングを行いますが、トレーニング後に偽物の画像を出力する必要があります。
・discriminatorは偽物と本物の画像でパラメータを共有する必要があります。

さてdiscriminatorを作成しましょう。
discriminatorは、本物もしくは偽物の画像をインプットし、その点数を出力します。
・各Convolution Layerでフィルタの数を倍にします。
・downsamplingは推奨されません。かわりにConvolution LayerをStrideします。
・各レイヤでバッチ正規化を使用します。詳細についてはこちらを参照してください。
・勾配消失を避けるため、活性化関数としてLeaky ReLUを使用します。
def discriminator(x, is_reuse=False, alpha = 0.2):
''' Build the discriminator network.
Arguments
---------
x : Input tensor for the discriminator
n_units: Number of units in hidden layer
reuse : Reuse the variables with tf.variable_scope
alpha : leak parameter for leaky ReLU
Returns
-------
out, logits:
'''
with tf.variable_scope("discriminator", reuse = is_reuse):
# Input layer 128*128*3 --> 64x64x64
# Conv --> BatchNorm --> LeakyReLU
conv1 = tf.layers.conv2d(inputs = x,
filters = 64,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv1')
batch_norm1 = tf.layers.batch_normalization(conv1,
training = True,
epsilon = 1e-5,
name = 'batch_norm1')
conv1_out = tf.nn.leaky_relu(batch_norm1, alpha=alpha, name="conv1_out")
# 64x64x64--> 32x32x128
# Conv --> BatchNorm --> LeakyReLU
conv2 = tf.layers.conv2d(inputs = conv1_out,
filters = 128,
kernel_size = [5, 5],
strides = [2, 2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv2')
batch_norm2 = tf.layers.batch_normalization(conv2,
training = True,
epsilon = 1e-5,
name = 'batch_norm2')
conv2_out = tf.nn.leaky_relu(batch_norm2, alpha=alpha, name="conv2_out")
# 32x32x128 --> 16x16x256
# Conv --> BatchNorm --> LeakyReLU
conv3 = tf.layers.conv2d(inputs = conv2_out,
filters = 256,
kernel_size = [5, 5],
strides = [2, 2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv3')
batch_norm3 = tf.layers.batch_normalization(conv3,
training = True,
epsilon = 1e-5,
name = 'batch_norm3')
conv3_out = tf.nn.leaky_relu(batch_norm3, alpha=alpha, name="conv3_out")
# 16x16x256 --> 16x16x512
# Conv --> BatchNorm --> LeakyReLU
conv4 = tf.layers.conv2d(inputs = conv3_out,
filters = 512,
kernel_size = [5, 5],
strides = [1, 1],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv4')
batch_norm4 = tf.layers.batch_normalization(conv4,
training = True,
epsilon = 1e-5,
name = 'batch_norm4')
conv4_out = tf.nn.leaky_relu(batch_norm4, alpha=alpha, name="conv4_out")
# 16x16x512 --> 8x8x1024
# Conv --> BatchNorm --> LeakyReLU
conv5 = tf.layers.conv2d(inputs = conv4_out,
filters = 1024,
kernel_size = [5, 5],
strides = [2, 2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name='conv5')
batch_norm5 = tf.layers.batch_normalization(conv5,
training = True,
epsilon = 1e-5,
name = 'batch_norm5')
conv5_out = tf.nn.leaky_relu(batch_norm5, alpha=alpha, name="conv5_out")
# Flatten it
flatten = tf.reshape(conv5_out, (-1, 8*8*1024))
# Logits
logits = tf.layers.dense(inputs = flatten,
units = 1,
activation = None)
out = tf.sigmoid(logits)
return out, logits

次にgeneratorを作成します。
generatorは、ランダムなノイズベクトルを受け取り、transposed convolution layerを通して偽物の画像を出力します。
そのアイデアは、各レイヤでフィルタサイズを半分にし、画像のサイズを倍にするというものです。
generatorの活性化関数としてはtanhを使うのがベストだとされています。
def generator(z, output_channel_dim, is_train=True):
''' Build the generator network.
Arguments
---------
z : Input tensor for the generator
output_channel_dim : Shape of the generator output
n_units : Number of units in hidden layer
reuse : Reuse the variables with tf.variable_scope
alpha : leak parameter for leaky ReLU
Returns
-------
out:
'''
with tf.variable_scope("generator", reuse= not is_train):
# First FC layer --> 8x8x1024
fc1 = tf.layers.dense(z, 8*8*1024)
# Reshape it
fc1 = tf.reshape(fc1, (-1, 8, 8, 1024))
# Leaky ReLU
fc1 = tf.nn.leaky_relu(fc1, alpha=alpha)
# Transposed conv 1 --> BatchNorm --> LeakyReLU
# 8x8x1024 --> 16x16x512
trans_conv1 = tf.layers.conv2d_transpose(inputs = fc1,
filters = 512,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv1")
batch_trans_conv1 = tf.layers.batch_normalization(inputs = trans_conv1, training=is_train, epsilon=1e-5, name="batch_trans_conv1")
trans_conv1_out = tf.nn.leaky_relu(batch_trans_conv1, alpha=alpha, name="trans_conv1_out")
# Transposed conv 2 --> BatchNorm --> LeakyReLU
# 16x16x512 --> 32x32x256
trans_conv2 = tf.layers.conv2d_transpose(inputs = trans_conv1_out,
filters = 256,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv2")
batch_trans_conv2 = tf.layers.batch_normalization(inputs = trans_conv2, training=is_train, epsilon=1e-5, name="batch_trans_conv2")
trans_conv2_out = tf.nn.leaky_relu(batch_trans_conv2, alpha=alpha, name="trans_conv2_out")
# Transposed conv 3 --> BatchNorm --> LeakyReLU
# 32x32x256 --> 64x64x128
trans_conv3 = tf.layers.conv2d_transpose(inputs = trans_conv2_out,
filters = 128,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv3")
batch_trans_conv3 = tf.layers.batch_normalization(inputs = trans_conv3, training=is_train, epsilon=1e-5, name="batch_trans_conv3")
trans_conv3_out = tf.nn.leaky_relu(batch_trans_conv3, alpha=alpha, name="trans_conv3_out")
# Transposed conv 4 --> BatchNorm --> LeakyReLU
# 64x64x128 --> 128x128x64
trans_conv4 = tf.layers.conv2d_transpose(inputs = trans_conv3_out,
filters = 64,
kernel_size = [5,5],
strides = [2,2],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="trans_conv4")
batch_trans_conv4 = tf.layers.batch_normalization(inputs = trans_conv4, training=is_train, epsilon=1e-5, name="batch_trans_conv4")
trans_conv4_out = tf.nn.leaky_relu(batch_trans_conv4, alpha=alpha, name="trans_conv4_out")
# Transposed conv 5 --> tanh
# 128x128x64 --> 128x128x3
logits = tf.layers.conv2d_transpose(inputs = trans_conv4_out,
filters = 3,
kernel_size = [5,5],
strides = [1,1],
padding = "SAME",
kernel_initializer=tf.truncated_normal_initializer(stddev=0.02),
name="logits")
out = tf.tanh(logits, name="out")
return out
Discriminator and generator losses
generatorとdiscriminatorを同時にトレーニングするので、両方の損失を算出する必要があります。
discriminatorには、画像が本物であるときには1を、完全に偽物であるときは0を出力してほしいので、それを反映するために損失を設定する必要があります。
discriminatorの損失は、実画像の損失と偽画像の損失の合計です。
d_loss = d_loss_real + d_loss_fake
d_loss_realは、実際は本物の画像であるのに、discriminatorが偽物であると判定してしまったときの損失です。
これは以下のように算出されます。
・d_logits_realのラベルは全て1である。
・discriminatorのをよりよくするため、labels = tf.ones_like(tensor) * (1 - smooth)を適用する。
d_loss_fakeは、実際は偽物の画像であるのに、discriminatorが本物であると判定してしまったときの損失です。
これは以下のように算出されます。
・d_logits_fakeandのラベルは全て0である。
generatorはdiscriminatorのd_loss_fakeを再度利用します。
今度のラベルは全て1で、これはgeneratorがdiscriminatorを騙したいからです。
def model_loss(input_real, input_z, output_channel_dim, alpha):
"""
Get the loss for the discriminator and generator
:param input_real: Images from the real dataset
:param input_z: Z input
:param out_channel_dim: The number of channels in the output image
:return: A tuple of (discriminator loss, generator loss)
"""
# Generator network here
g_model = generator(input_z, output_channel_dim)
# g_model is the generator output
# Discriminator network here
d_model_real, d_logits_real = discriminator(input_real, alpha=alpha)
d_model_fake, d_logits_fake = discriminator(g_model,is_reuse=True, alpha=alpha)
# Calculate losses
d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,
labels=tf.ones_like(d_model_real)))
d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.zeros_like(d_model_fake)))
d_loss = d_loss_real + d_loss_fake
g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.ones_like(d_model_fake)))
return d_loss, g_loss
Optimizers
損失の計算後、generatorとdiscriminatorをそれぞれアップデートします。
そのためにtf.trainable_variables()を使って変数を取得します。
これは使用した全ての変数を返します。
def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1):
"""
Get optimization operations
:param d_loss: Discriminator loss Tensor
:param g_loss: Generator loss Tensor
:param learning_rate: Learning Rate Placeholder
:param beta1: The exponential decay rate for the 1st moment in the optimizer
:return: A tuple of (discriminator training operation, generator training operation)
"""
# Get the trainable_variables, split into G and D parts
t_vars = tf.trainable_variables()
g_vars = [var for var in t_vars if var.name.startswith("generator")]
d_vars = [var for var in t_vars if var.name.startswith("discriminator")]
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
# Generator update
gen_updates = [op for op in update_ops if op.name.startswith('generator')]
# Optimizers
with tf.control_dependencies(gen_updates):
d_train_opt = tf.train.AdamOptimizer(learning_rate=lr_D, beta1=beta1).minimize(d_loss, var_list=d_vars)
g_train_opt = tf.train.AdamOptimizer(learning_rate=lr_G, beta1=beta1).minimize(g_loss, var_list=g_vars)
return d_train_opt, g_train_opt
Training
ここではトレーニング機能を実装します。
構造は比較的単純です。
・epoch_count5回ごとにモデルを更新する。
・トレーニング10回毎に画像を保存する。
・Jupyter notebookは大量の画像を出力するとバグるため、g_lossとd_lossと画像をepoch_count15回毎に画面出力する。
・予め20時間トレーニングしたモデルを読み込んで画像出力することもできる。
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha):
"""
Train the GAN
:param epoch_count: Number of epochs
:param batch_size: Batch Size
:param z_dim: Z dimension
:param learning_rate: Learning Rate
:param beta1: The exponential decay rate for the 1st moment in the optimizer
:param get_batches: Function to get batches
:param data_shape: Shape of the data
:param data_image_mode: The image mode to use for images ("RGB" or "L")
"""
# Create our input placeholders
input_images, input_z, lr_G, lr_D = model_inputs(data_shape[1:], z_dim)
# Losses
d_loss, g_loss = model_loss(input_images, input_z, data_shape[3], alpha)
# Optimizers
d_opt, g_opt = model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1)
i = 0
version = "firstTrain"
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# Saver
saver = tf.train.Saver()
num_epoch = 0
if from_checkpoint == True:
saver.restore(sess, "./models/model.ckpt")
show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, True, False)
else:
for epoch_i in range(epoch_count):
num_epoch += 1
if num_epoch % 5 == 0:
# Save model every 5 epochs
#if not os.path.exists("models/" + version):
# os.makedirs("models/" + version)
save_path = saver.save(sess, "./models/model.ckpt")
print("Model saved")
for batch_images in get_batches(batch_size):
# Random noise
batch_z = np.random.uniform(-1, 1, size=(batch_size, z_dim))
i += 1
# Run optimizers
_ = sess.run(d_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_D: learning_rate_D})
_ = sess.run(g_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_G: learning_rate_G})
if i % 10 == 0:
train_loss_d = d_loss.eval({input_z: batch_z, input_images: batch_images})
train_loss_g = g_loss.eval({input_z: batch_z})
# Save it
image_name = str(i) + ".jpg"
image_path = "./images/" + image_name
show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, True, False)
# Print every 5 epochs (for stability overwize the jupyter notebook will bug)
if i % 1500 == 0:
image_name = str(i) + ".jpg"
image_path = "./images/" + image_name
print("Epoch {}/{}...".format(epoch_i+1, epochs),
"Discriminator Loss: {:.4f}...".format(train_loss_d),
"Generator Loss: {:.4f}".format(train_loss_g))
show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, False, True)
return losses, samples
How to run it
GPUファームを揃えるか10年待つか、何れかを選ばないかぎり手元のPCで動作させるのは非現実的です。
かわりに、AWSやFloydHubといったクラウドGPUサービスを使用する必要があります。
学習データは、Microsoft AzureのDeep Learning Virtual Machineを20時間回して作成しました。
注意:私はAzureの利害関係はありません。素晴らしいサービスだと考えているだけです。
仮想マシンでの動作に問題がある場合、こちらの記事を参照してください。
このチュートリアルが役に立つことを祈っています。
モデルを改善したら遠慮無くプルリクを送ってください。

アイデアやコメントなどがありましたらhello@simoninithomas.comにメールするか、@ThomasSimoniniにツイートしてください。
この記事が気に入ったら拍手ください。あとフォローもください。
試してみた
GithubのほうのGetting Startedに手順が書いてあったので、実際に試してみた。
Download the dataset here : https://www.kaggle.com/crawford/cat-dataset
猫画像のデータセットをダウンロードした。
既に目の位置などのメタデータが入っているので、顔の切り出しとかそのあたりを考えなくてよくなる。
Download the model checkpoint : https://drive.google.com/drive/folders/1zdZZ91fjOUiOsIdAQKZkUTATXzqy7hiz?usp=sharing
リンク先にあった4ファイルをダウンロードした。
これが予め20時間ほどトレーニング済みの学習データであるようだ。
Type sh start.sh it will handle extract, remove outliers, normalization and face centering
start.shを実行してデータセットを整形しろと書かれているが、手元はWindows環境なのでそのままでは動かなかった。
中身は単にファイルを解凍して異常値を削除してpreprocess_cat_dataset.pyを実行しているだけなので、そのあたりを手動で行った。
だがpreprocess_cat_dataset.pyが置いてなくて、探してみたら元ネタらしきところを見付けたのだが、よく見るとそっちのstart.sh的なものとは色々差異があったりしてて何が正解なのかよくわからん。
なおpreprocess_cat_dataset.pyはメタデータを元に画像から顔部分の切り出しを行うだけで、特にAI的なことはしていない。
Launch Jupyter Notebook jupyter notebook --no-browser
Anaconda Navigatorからjupyter notebookを起動した。
Anaconda Navigatorでno-browserの指定方法がわからないので気にせず起動。
初期ディレクトリがUsers\ユーザ名で、シンボリックリンクを追ってくれないので色々と不便。
Launch CatDCGAN
GithubのプロジェクトをダウンロードしてUsers\ユーザ名\AnacondaProjects以下に配置。
checkpointのファイルはmodel以下に配置、
images、resized_dataディレクトリをcats_bigger_than_128x128と同じ場所に作っておく。
notebookでCat DCGAN.ipynbを選択するとプロジェクトが開く。
Change do_preprocess = True !!! important!
do_preprocess = Falseの行があったのでTrueに変更した。
これは画像の下準備を行うだけなので、一度実行してresized_dataディレクトリに画像が入ったら、以降はFalseに戻してよい。
If you want to train from scratch : change from_checkpoint = False
If you want to train from last model saved (you save 20 hours of training tada) : change from_checkpoint = True
学習を最初から行うならFalse、学習済みのモデルを使うならTrueにする。
先ほど学習済みモデルを入れたのでTrueにした。
実行
上から順に実行していたら色々エラーが出た。
・ImportError: No module named 'PIL'と言われた。
pip install Pillowで解決。
・ImportError: No module named 'scipy'と言われた。
pip install scipyで解決。
・ImportError: No module named 'matplotlib'と言われた。
pip install matplotlibで解決。
・UnboundLocalError: local variable 'image_path' referenced before assignmentと言われた。
train関数内でimage_pathという変数が使われているのだが、これが場合によっては未定義のまま使用される。
なにこれバグ?
直前にsaver.restore(sess, "./models/model.ckpt")というコードがあるので、おそらくimage_pathもここからリストアされるのだろう。
従って学習済みデータからの読み込みがうまくいってないと思われるのだが、中身のことなんてさっぱりわからないのでどうしようもなかった。
学習済みモデルを使わないようにfrom_checkpoint = Falseも試してみたのだが、そうするとtrainメソッドから帰ってこなくなった。
一回の学習に数分かかり、それが数万回とかループしてるので死ぬ。
実際GPUファームを揃えるか10年待つかAzureに170ドル払えって書いてあって、ローカルで試すのは無謀なようだ。
とりあえず100回学習してみた結果は以下のとおり。

最初の完全ランダム領域から全く抜け出せてない。
後半はなんとなくうすぼんやりと輪郭が見えてきたような気がしないでもないので、20時間ほど放置していたらそれっぽくなってくるかもしれない。
Cat DCGAN.ipynbの概要
Cat DCGAN.ipynbのコード全体をGitHub等から見ることはできないようだが、概ね上記のコードを順番に実行している。
コードをざっくり説明すると、
・上の準備編で作成したcats_bigger_than_128x128ディレクトリの画像を、128*128に揃えてresized_dataディレクトリに格納
・discriminatorやらgeneratorやらのモデル定義
・画像出力メソッドshow_generator_outputの定義
・学習メソッドtrainの定義
・学習に使うパラメータを設定
・resized_dataディレクトリの画像を読み出して学習実行
と全体的な流れはわかりやすい。
個別に何をやってるのかはさっぱりわからない。
感想
ディープラーニングもTensorFlowも、そもそもPythonもほぼ初心者なのでよくわからなかった。
DCGANってあれか、要するにアキネイターみたいなものか。
機械学習はとにかく時間かお金がかかることが問題だな。
誰か170ドル払って続きを頼んだ。