はじめに
近年急速に進化しているGANの中でも、特に有名な物の一つであるStyleGANについて改めて勉強したいと思い、今回のテーマにしました。
前半は論文紹介として、StyleGANの構造や特徴について勉強した事をまとめます。
後半は、実際に学習済みのStyleGANを使って画像生成を試してみたので、その結果を書いていきます。
論文紹介
StyleGAN (v1)
StyleGANは2018年に発表されました。(論文リンク)
以下はStyleGANで生成された画像例の引用ですが、本物の写真と見分けがつかないような高品質の画像が生成されていると思います。

以下、StyleGANの特徴を説明していきます。
generatorの構造
StyleGANの特徴は、主にgeneratorの構造にあると言っていいかと思います。
論文中の以下の図について、左側が従来のGAN(ここではPGGAN)のgenerator、右側がStyleGANのgeneratorの構造です。
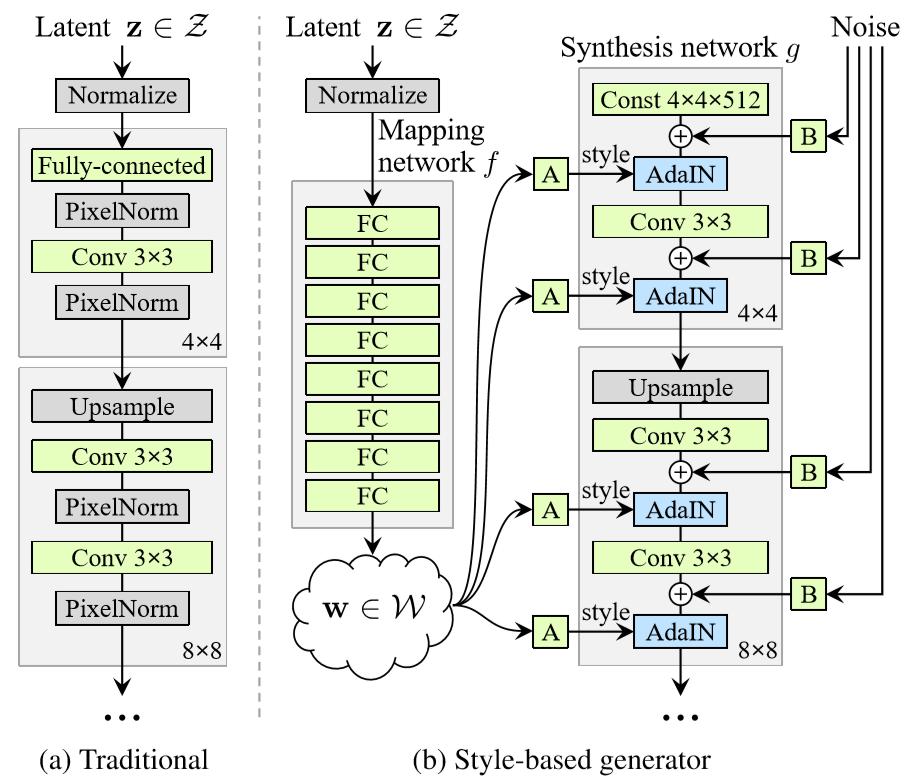
従来のGANでは潜在変数(latent z)をランダムに生成してgeneratorの最初のレイヤから入力しています。対して、StyleGANの場合はgeneratorの最初の入力は固定値とし、latent zはまずMapping networkを通して変換された後、generator途中の各所でAdaINを使って入力されます。
さらにgenerator各層に対し、ランダムに生成したノイズも加えています。
※AdaINについて
AdaIN(Adaptive Instance Normalization)は、スタイル変換の研究で提案された正規化手法です。以下式のように、変換元の特徴マップxの平均・分散を、適用するスタイル画像の特徴マップyの平均・分散に合わせる操作です。

StyleGANでは、zをMapping networkにより変換した結果がスタイルにあたります。
Style Mixing
generator各層に入力するスタイル情報は全て同一である必要はなく、複数を組み合わせる事ができます。
例えば、ある画像A・Bを生成するような潜在変数z1・z2があるとして、generatorのある層まではz1由来のスタイルを、その後からz2由来のスタイルを入力することで、A・Bの特徴を混ぜたような画像を生成することができます。(Style mixing)
この時、前段の方でz1→z2に切り替えるとBの大きな特徴(顔の向きや形状)が反映されますが、後段の方で切り替えると細かな特徴(髪の色など)しか反映されないことがわかっています。
※詳細と具体的な画像例は論文のFigure 3を参照してください。
Progressive Growing
これはPGGAN(Progressive-Growing GAN)で提案された学習方法です。※StyleGANはPGGANをベースラインとしている。
学習時にgenerator・discriminatorの層を段階的に追加することで生成画像の解像度を上げていく方法で、1024x1024といった高解像度の画像を安定して生成できることが報告されています。
ただ、Progressive Growingにはデメリットもあるようです。以下のStyleGAN2では、その辺りについても検討されています。
StyleGAN2
StyleGANの改良版として、StyleGAN2が2019年に発表されました。(論文リンク)
以下はStyleGAN2で生成された画像例です。
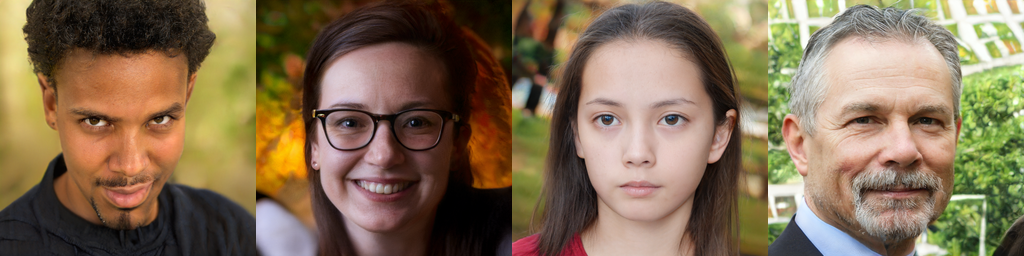
見た感じだとStyleGANとの品質の差はわかりにくいですが、StyleGANで発生する特徴的な水滴状パターンが解消され、画像品質の指標であるFID等のスコアも大きく向上した事が報告されています。
具体的な改良点としては、主に以下の点が挙げられます。
- AdaINに相当する処理を単一のConv層で実現 (Weight demodulation)
- 正則化の改善 (Path length regularization, Lazy regularization)
- ネットワーク構造を改良し、Progressive Growingを不要に
以下、各項目について記載します。
AdaINに相当する処理を単一のConv層で実現
StyleGANではAdaINの正規化処理により水滴状のパターン(water droplet-like artifacts)が引き起こされることが判明したため、StyleGAN2ではこれの改善が行われています。
以下、generatorの構造を論文中から引用します。
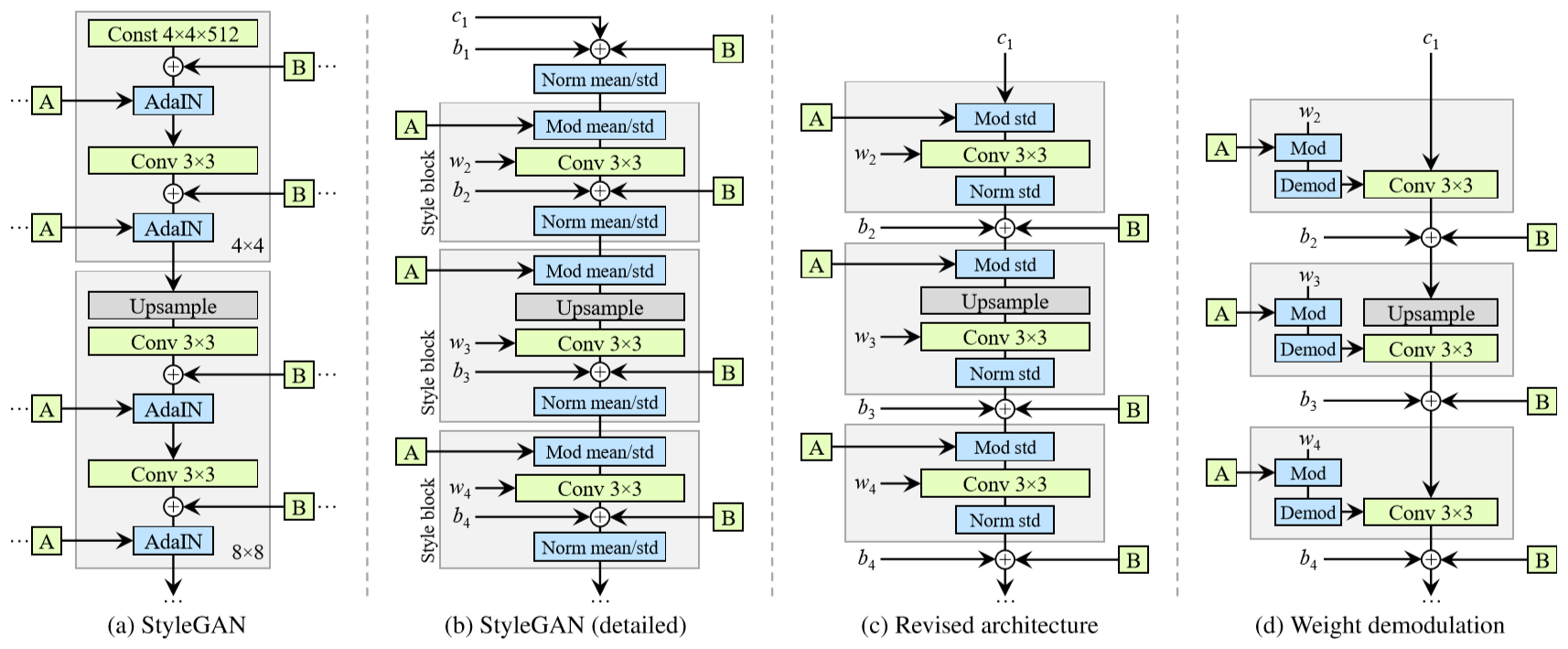
左側(a)(b)が元のStyleGAN、一番右(d)がAdaINを使わない形に変更された結果です。
AdaINによる正規化と同等の操作を、Weight demodulationという操作(Conv層の重みを標準偏差で割ること)で実現しています。
※論文ではより丁寧に、段階的に説明されています。
ポイントは、実際の入力データの統計量を使わず、分布の仮定に基づいてWeight demodulationを行っているという点で、これにより水滴状パターンの問題が解消されたと報告されています。
正則化の改善
潜在空間が知覚的に滑らかであるかを示すPerceptual Path Lengthが生成画像の品質向上において重要ということで、これを正則化項に加えています。(Path length regularization)
この辺りの理解が曖昧ですが、潜在空間内で距離が近いzに対しては、知覚的に似ている画像が生成されるべき(そうなるよう学習させるべき)ということでしょうか。。
また、メインの損失項に対して、正則化項の更新は頻度を下げてもスコアに悪影響がなかったと報告されています。(正則化項の更新頻度を下げる事を"Lazy regularization"と呼んでいます)
これにより計算コストとメモリ使用量が削減でき、学習時間の短縮にも寄与しています。
ネットワーク構造を改良し、Progressive Growingを不要に
Progressive Growingは高解像度の画像生成を安定して学習できるメリットがありますが、
目や歯といった局所的な部分が、全体的な動き(顔の向き)に追従しないという問題があります。
一例としては以下の図があります。顔の向きが変わっても、歯の並びが動いていないのがわかります。
2,3年前のGANと比べれば、こんな細かい箇所について議論していること自体がすごい気がしますが…。
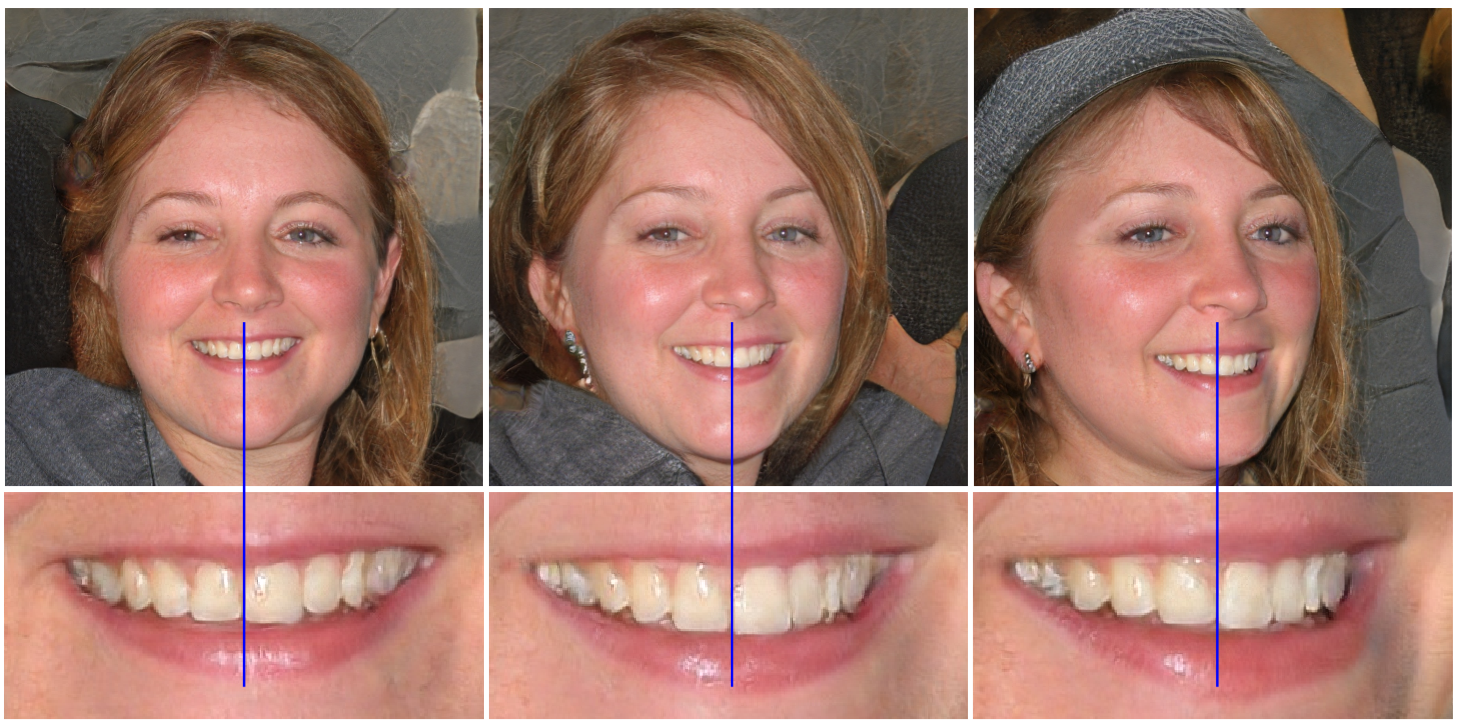
上記の問題は、Progressive Growingで段階的に解像度を上げる事で頻出の特徴が生成されやすくなるのが原因であるとし、これを使わずに学習を成功させられるようネットワーク構造が見直されています。
実験の結果、generatorとdiscriminator双方にスキップ構造を導入する事が有効であることが示され、Progressive Growing無しでも高品質の画像生成に成功しています。(→ 歯や目が顔の向きに追従しない件も解決)
※GとDではスキップ構造の入れ方が異なります。詳細は論文のFigure7, Table2を参照してください。
...勉強は以上として、ここからはStyleGANによる画像生成を実際に試してみます。
学習済みモデルによる実験
画像生成の実験を行うにあたり、以下に公開されているStyleGAN実装を使わせて頂きました。
(GitHub) stylegans-pytorch
公式のStyleGANはTensorFlowですが、上記はPyTorchで再現実装されています。環境準備から学習済み重みの変換手順まで丁寧に説明されていて、とても助かりました。
StyleGAN1,2の両方に対応されていますが、今回はStyleGAN1の方で試してみました。(使える重みの種類が多そうだったので)
準備・動作確認
環境としては以下の通りです。ゲーム用PCにUbuntuとCUDA等を入れて作った環境です。
OS : Ubuntu 18.04.4 LTS
GPU : GeForce RTX 2060 SUPER x1
準備はREADMEの手順に沿って特に問題なくできました。
変換した重みを使って実際に生成した画像が以下です。

本家と同じ画像が生成できていることから、重みの変換とgenerotorによる生成処理が正しくできていることが確認できました。
また、二次元キャラクター生成用の学習済みモデルにも対応されていたので、これも試しました。
[face_v1_1]

[portrait_v1]

interpolation実験
ここまででStyleGANによる画像生成を試すことができましたが、せっかくなのでGANの動画などでよく見る潜在変数zのinterpolationを試してみることにしました。
元のwaifu/run_pt_stylegan.pyを参考に、アニメキャラの学習済みモデルでzのinterpolationを行って結果をgifとして保存する処理を書きました。
import argparse
from pathlib import Path
import pickle
import numpy as np
import cv2
import torch
from tqdm import tqdm
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, default='face_v1_1',
choices=['face_v1_1','face_v1_2','portrait_v1','portrait_v2'])
parser.add_argument('--weight_dir', type=str, default='../../data')
args = parser.parse_args()
return args
def prepare_generator(args):
from run_pt_stylegan import ops_dict, setting
if 'v1' in args.model:
from stylegan1 import Generator, name_trans_dict
else:
from stylegan2 import Generator, name_trans_dict
generator = Generator()
cfg = setting[args.model]
with (Path(args.weight_dir)/cfg['src_weight']).open('rb') as f:
src_dict = pickle.load(f)
new_dict = {k : ops_dict[v[0]](src_dict[v[1]]) \
for k,v in name_trans_dict.items() if v[1] in src_dict}
generator.load_state_dict(new_dict)
return generator
def make_latents_seq():
n_latent_point = 3
interpolation_step = 13
n_image = 3
latent_dim = 512
#起点となるlatentsをランダムに生成
points = np.random.randn(n_latent_point, n_image, latent_dim)
results = []
for i in range(n_latent_point):
s = points[i]
e = points[i+1] if i+1 < n_latent_point else points[0]
latents_ = np.linspace(s, e, interpolation_step, endpoint=False) #線形補間
results.append(latents_)
return np.concatenate(results)
def generate_image(generator, latents, device):
img_size = 320
latents = torch.from_numpy(latents.astype(np.float32))
with torch.no_grad():
N, _ = latents.shape
generator.to(device)
images = np.empty((N, img_size, img_size, 3), dtype=np.uint8)
for i in range(N):
z = latents[i].unsqueeze(0).to(device)
img = generator(z)
normalized = (img.clamp(-1, 1) + 1) / 2 * 255
np_img = normalized.permute(0, 2, 3, 1).squeeze().cpu().numpy().astype(np.uint8)
images[i] = cv2.resize(np_img, (img_size, img_size),
interpolation=cv2.INTER_CUBIC)
def make_table(imgs):
num_H, num_W = 1, 3 #並べる画像数 (縦, 横)
H = W = img_size
num_total = num_H * num_W
canvas = np.zeros((H*num_H, W*num_W, 3), dtype=np.uint8)
for i, p in enumerate(imgs[:num_total]):
h, w = i//num_W, i%num_W
canvas[H*h:H*-~h, W*w:W*-~w, :] = p[:, :, ::-1]
return canvas
return make_table(images)
def save_gif(images, save_path, fps=10):
from moviepy.editor import ImageSequenceClip
images = [cv2.cvtColor(img, cv2.COLOR_BGR2RGB) for img in images]
clip = ImageSequenceClip(images, fps=fps)
clip.write_gif(save_path)
if __name__ == '__main__':
args = parse_args()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
generator = prepare_generator(args).to(device)
latents_seq = make_latents_seq()
print('generate images ...')
frames = []
for latents in tqdm(latents_seq):
img = generate_image(generator, latents, device)
frames.append(img)
save_gif(frames, f'{args.model}_interpolation.gif')
make_latents_seq()の中で、3点のlatent zを起点として線形補間を行い、シーケンスとしてのzを生成しています。
※本家論文ではSlerp(球面線形補間)が使われますが、ここでは単に線形補間しています。
結果は以下の通りです。
[face_v1_1]

[portrait_v1]

期待通り、キャラの顔が連続的に変化する動画が得られました。学習時のデータによるのでしょうが、色々な作画スタイルが混在していて面白いと思います。(なんとなく見覚えがあるような顔もちらほらと...)
頭の周囲や肩より下部分はかなり無秩序に変化しているようですが、顔部分については、interpolationのどの瞬間を見てもちゃんと顔になっていることがわかります。これが、潜在空間が知覚的に滑らかにつながっているという事なんでしょうか。
あとgifのファイルサイズを気にしなければ、interpolation_stepをもっと上げることで更に滑らかなアニメーションになります。
おわり
StyleGANについて、論文の紹介と学習済みモデルによる実験を行いました。もし論文の解釈などで間違っている部分があったらご指摘頂けると幸いです。
自宅のマシンではだいぶ時間かかりそうですが、学習についてもいつか自分で試してみたいと思います。