Pythonコードは単純な工夫で高速化できる

はじめに
これまで株式銘柄のテクニカル選抜のバックテストを行う中で、処理速度の遅さに課題を感じていました。特に複数銘柄を対象としたループ処理では、毎回 yfinance を通じて株価データを取得していたため、同じ銘柄でも日付ごとに都度ダウンロードが発生し、非常に非効率でした。
例えば、テクニカルスクリーニングの全パターンを一通り回すだけで、実行に丸一日、解析を含めると次の方針が決まるのに3日近くかかる状況も珍しくありませんでした。
この課題に対処するため、
前回は以下のような軽量なローカルデータセットを構築したことを紹介しました。
- 対象:東証プライム全銘柄(約1,600銘柄)
- 期間:2010年〜2025年
- 項目:OHLCV(Open, High, Low, Close, Volume)
- 形式:Parquet形式(銘柄ごとに保存)
多くのテクニカル指標はこの OHLCV から算出可能であり、ローカルやGoogle Driveにあらかじめ保存しておけば、毎回APIから取得することなく瞬時に読み込める―
そう考えて、「これで高速化できるはずだ」と期待していました。
しかし、本当にこのデータセットを使いさえすれば高速化が実現できるのでしょうか?
今回はこの問いに答えるべく、
yfinanceベースの旧来コード(V1)と、Parquet形式のローカルデータセットを用いた新バージョン(V2)両者を用いて、同じ条件のバックテストを実行し、処理速度を比較しました。
Python×株式投資:月利3〜5%を狙う自動スクリーニング戦略
自動スクリーニングによる銘柄選抜ロジックを構築・検証し、安定した月利3〜5%を目指した戦略の実践記事です。 この記事のコードをベースに、今回、速度検証をしています。
Python×株式投資:都度DLはやめた─yfinanceで爆速テクニカル分析を回したい
yfinanceからの都度DLをやめ、Parquetデータセットを構築した話です。
使用データと検証設計
処理内容は、基本的に以前の記事と変わりありません。
-
対象銘柄: 東証プライム約1600銘柄のうち、財務スクリーニングを通過した約200銘柄
-
スクリーニング評価日・対象期間:
以前の記事と同様 -
スクリーニング条件(パターン):
8パターン(前回は16通りでしたが、今回は処理時間の比較に重点を置くため、省略)
また、処理時間の測定方法は以下の通りです。
- 各バージョンのコード冒頭に
global_start_time = time.time()を記述 - 処理の末尾に
global_end_time = time.time()を記述 - 実行時間を
global_end_time - global_start_timeで計測(単位:秒)
この方法で、全体のバックテスト処理にかかる時間を比較しています。
コード構成
| 項目 | V1:yfinanceベース | V2:ローカルParquetベース |
|---|---|---|
| 銘柄の読み込み | 毎回 yfinance からダウンロード | ローカル .parquet ファイルを読み込み |
| 読み込み位置 | ループ内で毎回APIを呼び出す | ループ内で毎回ファイルを開く |
| 使用データ形式 | yfinance → pandas DataFrame | parquet → pandas DataFrame |
| テクニカル計算 | 各銘柄のデータ取得後に都度実行 | 各銘柄の読み込み後に都度実行 |
| スクリーニング | 日付・銘柄・条件ごとに実行 | 日付・銘柄・条件ごとに実行 |
サンプルコードは本記事の最後に載せています。いずれのバージョンも選抜結果は同じでした。
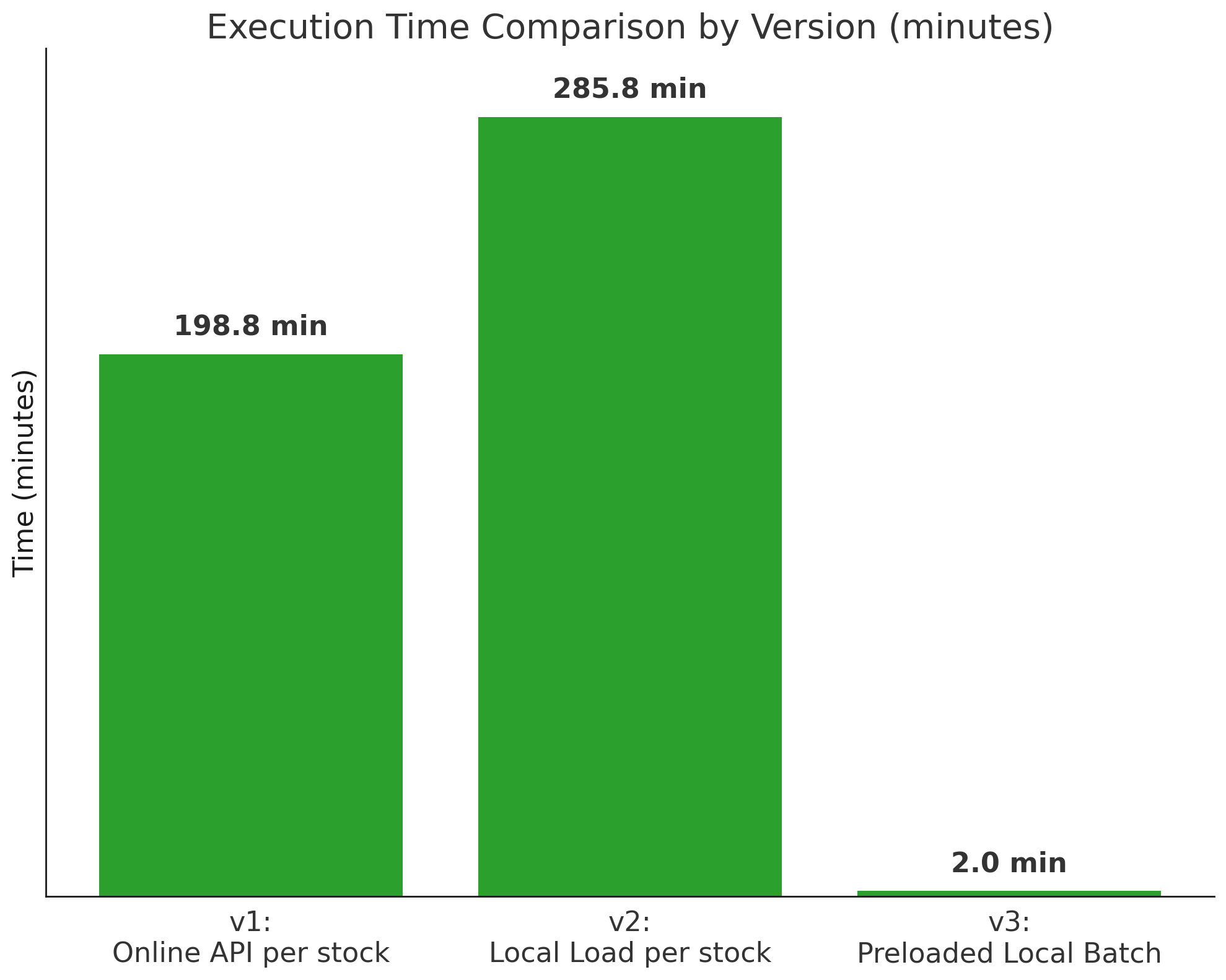
V1とV2の処理時間
- V1:11,926.90 秒(約198.8分)
- V2:17,146.69 秒(約285.8分)
一見すると、ローカルファイルを使ったV2の方が高速になると想定されがちですが、結果は逆でした。 Parquetファイルの読み込みがループ内で毎回発生する構成により、処理時間はむしろV1よりも長くなるという予想外の展開となりました。
わざわざローカルにデータベースを構築し、ネットワーク負荷を減らしたにもかかわらず、むしろ悪化したのです。
高速化のための対策案
1. Python のループは遅い
@ShigemoriMasato(重盛 雅人)氏の人気記事「[入門] Pythonを10倍高速化する実践テクニック集」では、次のように述べられています:
“Python の forループは遅い。NumPy を使ってまとめて処理(ベクトル化)すれば何倍も速くなる。”
例えば以下の2つのコードでは、NumPyによるベクトル処理の方が圧倒的に高速だと述べられていました。
# 遅い(純Python)
def slow_sum(n):
total = 0
for i in range(n):
total += i
return total
# 速い(NumPy)
def fast_sum(n):
return np.arange(n).sum()
2. V2の問題点:ループの中で再計算
これまでのコード(V2)では、ループの中で、銘柄ごとにParquetファイルを読み込み、その中で毎回テクニカル指標を再計算していました。
#コードのイメージ
# ① 評価処理だけループ(判定&記録のみ)
for day in days:
for pattern in patterns:
for ticker in tickers:
# ② データ読み込み
df = pd.read_parquet(f"data/{ticker}.parquet")
# ③ 毎回テクニカル指標を再計算
df["MA25"] = df["Close"].rolling(25).mean()
delta = df["Close"].diff()
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=df.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=df.index).rolling(14).mean()
df["RSI"] = 100 - (100 / (1 + avg_gain / (avg_loss + 1e-10)))
# その他の指標もここで毎回再計算
evaluate_conditions(df, pattern, day)
# 条件判定・リターン計算
# →判定 →保存
問題点
- Parquetの読み込みが銘柄数×条件数×日付数分繰り返されていた
- pandas/NumPyの高速な処理(例:rolling平均、対数変換など)であっても、ループ内で毎回呼び出せば非効率
一言で言えば、本来高速な処理を、遅いループの中で何度も無駄に繰り返していたのです。
3. 解決策(V3):データ読込みとテクニカル計算をループ外に出す
では、どうすればいいのか?
答えはシンプルです。同じ処理は最初に1回だけやればいい。
今回のV3では、コード全体で使い回すテクニカル指標の計算をすべてループの外に出し、一括処理する構成に変更しました。
#コードのイメージ
# ① 全銘柄データを一括で読み込み
df = pd.read_parquet("all_tickers.parquet")
# ② テクニカル指標を事前に一括計算(銘柄単位で2-3年分)
df_list = []
for ticker, df_group in df.groupby("Ticker"):
df_group["MA25"] = df_group["Close"].rolling(25).mean()
delta = df_group["Close"].diff()
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=df_group.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=df_group.index).rolling(14).mean()
df_group["RSI"] = 100 - (100 / (1 + avg_gain / (avg_loss + 1e-10)))
# その他の指標もここで計算
df_list.append(df_group)
df = pd.concat(df_list)# まとめてdfに乗っけておく
# ③ 評価処理だけループ(判定&記録のみ)
for day in days:
for pattern in patterns:
for ticker, group in df.groupby("Ticker"):
df_day = group[group["Date"] <= day].copy() #未来データは使っちゃダメ!
evaluate_conditions(df_day, pattern, day)
# 条件判定・リターン計算
# →判定 →保存
V3に施した改善
| 改善点 | 内容 |
|---|---|
| 📁 I/O回数削減 | ファイル読み込みを一括で実施(1600回 → 1回) |
| 🔄 冗長な計算削減 | テクニカル指標の再計算をループ外に移動(毎回 → 一度だけ) |
| 🔁 軽量ループ化 | 銘柄ごとの条件評価だけをループで処理(最小限の繰り返し) |
V3の処理速度はどうなったか?ー約100倍高速化された
V1と比べて、97.4倍、V2よりは140.0倍、高速化がされました。
ここで重要なのは、ローカルのParquetデータセットだけを使えば速くなるわけではないということ。Pythonの特性に合わせて、データ構造だけでなく処理アルゴリズム(ループの構造や計算タイミング)を見直すことが、パフォーマンス改善の鍵になると学びました。
実行時間(合計)
| バージョン | 処理構成 | 実行時間 |
|---|---|---|
| V1 | yfinance都度取得 | 11926.90秒(約198.8分) |
| V2 | Parquet使用(ループ内処理) | 17146.69秒(約285.8分) |
| V3 | Parquet一括読み込み+一括計算 | 122.42秒(約2.0分) |
V1実行時の様子 20倍速

V2実行時の様子 20倍速

V3実行時の様子 20倍速

1番下の青い進捗バーがスクリーニング1日分の進み具合を示す。
V3が遥かに高速なことがわかる。
高速化によって「期待できること」と「まだ改善が必要なこと」
以下のようなことが実行可能になると思われます。:
-
スクリーニング精度向上に向けた検証サイクルの高速化
これまで丸1日かかっていた処理が、数分で完了。
「この条件で精度はどれくらい出るのか?」という問いに対し、即座に答えを得ることができるようになりました。トライアンドエラーのスピードが大幅に向上し、精度の高いスクリーニングロジックへの距離が近づくと思われます。
-
スクリーニングパターンの大量展開と試験反復数の爆増
パターン数が8でも16でも32でも、処理時間はほぼ変わらず。
条件の細分化や最適パターン探索が現実的になり、再現性と信頼性の高い戦略検証が可能になります。これまで5回程度だった検証回数も、数十回単位で回せるようになり、より頑健なアルゴリズム構築が期待できます。
一方で、このアプローチにはまだ制約も残っています:
-
“最新データ”への対応が難しい
今回の構成は、あくまで「過去データ(Parquet)を用いた一括処理」に特化しています。
そのため、当日や直近の地合いに合わせて銘柄をスクリーニングするようなリアルタイム運用には不向きです。毎日の自動スクリーニングには、さらなる構成の工夫が必要になります。
-
指標が増えた際のスケーラビリティは未検証
現状は、RSIと移動平均などの軽量なテクニカル指標のみを対象にしています。
今後、パラボリックSAR、ボリンジャーバンド、ADXなどより複雑な指標群を導入した場合、再び処理時間がボトルネックになる可能性も否定できません。
この課題に対しては、現在「最新のデータをAPI(例:yfinance)から即時取得し、その場でデータセット化してスクリーニングに活用する」という、V4的なハイブリッド構成の開発を進めています。
「バックテストはローカルで爆速処理、日々の運用はAPIで軽量更新」という、リアルな運用に対応した仕組みを構築することが、次の目標です。
また、現在とは異なるテクニカル指標を導入した際に、どの程度スクリーニング精度が変化するのかについても合わせて検証を進めていく予定です。
おわりに
これまでのテクニカルスクリーニングは、「時間との戦い」でもありました。
処理が遅くて検証を断念し、検証できないから精度が上がらない─
そんな悪循環を、今回の高速化は少しずつ断ち切ってくれそうです。
もちろん、これですべての課題が解決するわけではありません。
それでも、「Pythonの遅さというボトルネックを改善する方法がある」という視点にたどり着けたことは、大きな前進でした。
今後は、指標の追加やリアルタイム運用への対応など、さらに実践的な課題に取り組んでいく予定です。 この試行錯誤の過程が、やがて“使える戦略”として育つことを信じて、これからも改善を続けていきます。
サンプルコード
実行環境
サービス: Google Colab Pro
ランタイム設定: CPU
RAM: 13.61 GB
主要ライブラリ:
pandas: 2.2.2
numpy: 2.0.2
tqdm: 4.67.1
yfinance: 0.2.63
curl-cffi: 0.11.3
実行日: (2025年6月20日)
*今までyfinaceのアクセスエラーを防止するため、ループ毎にtimesleepで0.5秒ほど遅延をさせていましたが、このバージョンyfinaceになってから、安定しているので、この操作は取り入れてません。今回の検証も、遅延0秒で実行してます。
V1のサンプルコード
# -----------------------------
# 2nd Screening V1
# -----------------------------
import time
global_start_time = time.time()
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
import numpy as np
import os
from tqdm.notebook import tqdm
import yfinance as yf
from curl_cffi import requests
# --------------------------------------------------
# ヘルパー関数定義セクション
# --------------------------------------------------
def calculate_market_sentiment_yfinance(session, ticker="1306.T", start="2021-01-01", end="2025-05-13"):
"""
【地合い用】yfinanceからデータを取得し、地合いスコアを計算する。
"""
print(f"\n--- 事前準備: 地合いスコア計算のため {ticker} のデータをダウンロードします ---")
df = yf.download(ticker, start=start, end=end, session=session, progress=False, timeout=10, auto_adjust=False)
if df.empty:
print(f"⚠️ {ticker} のデータ取得に失敗しました。")
return pd.Series(dtype=float)
if isinstance(df.columns, pd.MultiIndex):
df.columns = df.columns.get_level_values(0)
# 地合いスコア用の指標計算
df["MA25_diff"] = (df["Close"] - df["Close"].rolling(25).mean()) / df["Close"].rolling(25).mean()
df["5d_return"] = df["Close"].pct_change(5)
delta = df['Close'].diff()
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=df.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=df.index).rolling(14).mean()
rs = avg_gain / (avg_loss + 1e-10)
df['RSI'] = 100 - (100 / (1 + rs))
# スコアリング
df['score'] = 0
df['score'] += (df['5d_return'] > 0.01).astype(int)
df['score'] += (df['MA25_diff'] > 0).astype(int)
df['score'] += (df['RSI'] > 55).astype(int)
df['score'] -= (df['RSI'] < 45).astype(int)
df['score'] -= (df['5d_return'] < -0.01).astype(int)
df['score'] -= (df['MA25_diff'] < 0).astype(int)
print("✅ 地合いスコアの計算が完了しました。")
return df['score'].sort_index()
def fetch_and_calculate_indicators_yfinance(ticker, cond, session):
"""
【個別銘柄用】yfinanceで都度ダウンロードし、指標を計算する。
"""
try:
# yfinanceのダウンロード期間は固定(毎回全期間取得)
df = yf.download(ticker, start="2021-01-01", end="2025-05-13", session=session, progress=False, timeout=10)
time.sleep(0.00) # APIへの負荷を考慮
if df.empty or len(df) < 75:
return None
if isinstance(df.columns, pd.MultiIndex):
df.columns = df.columns.get_level_values(0)
# テクニカル指標の計算
df["MA_5"] = df["Close"].rolling(window=5).mean()
df["MA_25"] = df["Close"].rolling(window=25).mean()
df["MA_75"] = df["Close"].rolling(window=75).mean()
delta = df["Close"].diff()
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=df.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=df.index).rolling(14).mean()
df["RSI"] = 100 - (100 / (1 + (avg_gain / (avg_loss + 1e-10))))
df["MA_5_slope"] = df["MA_5"].diff(cond["slope_period"]) / cond["slope_period"]
return df
except Exception:
return None
def get_daily_sentiment_score(today, market_scores_by_date):
"""
日付を指定して、準備済みの地合いスコアから関連情報を取得する。(共通関数)
"""
try:
score_date = today
if score_date not in market_scores_by_date.index:
temp_idx = market_scores_by_date.index.get_indexer([score_date], method="nearest")[0]
temp_date = market_scores_by_date.index[temp_idx]
score_date = temp_date if temp_date <= score_date else (market_scores_by_date.index[temp_idx - 1] if temp_idx > 0 else None)
if score_date:
score_today_val = market_scores_by_date.loc[score_date]
score_window = market_scores_by_date.loc[market_scores_by_date.index <= score_date].tail(10)
return score_today_val, score_window.mean(), score_window.std(), score_window.diff().mean()
except Exception:
pass
return np.nan, np.nan, np.nan, np.nan
# --------------------------------------------------
# 設定・定義セクション
# --------------------------------------------------
# --- パス設定 ---
input_base_dir = "/content/drive/MyDrive/stock_prediction/ver.1/results/Qiita/1st/J-Quants/Prime/selected_ajt_type2"
output_base_dir = "/content/drive/MyDrive/stock_prediction/ver.1/results/Qiita/2nd/Speed_test/yfinance_loop_Autoadjust" # 出力先を明示的に変更
os.makedirs(output_base_dir, exist_ok=True)
# --- 日付リスト ---
date_list = [
'2022-01-13', '2022-01-24', '2022-01-28', '2022-02-01', '2022-04-20',
'2022-05-17', '2022-05-27', '2022-06-21', '2022-07-21', '2022-09-05',
'2022-09-09', '2022-11-28', '2022-12-01', '2022-12-21', '2023-02-17',
'2023-03-28', '2023-04-24', '2023-07-14', '2023-08-04', '2023-09-21',
'2023-10-05', '2023-11-09', '2023-11-29', '2023-12-04', '2023-12-21',
'2023-12-22', '2024-03-05', '2024-03-13', '2024-03-26', '2024-04-11',
'2024-06-06', '2024-06-07', '2024-07-22', '2024-07-26', '2024-09-12'
]
# --- スクリーニング条件定義 ---
screening_conditions = [
{"name": "pattern1", "rsi_range": (25, 50), "ma_eps": 0.02, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern2", "rsi_range": (25, 50), "ma_eps": 0.04, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern3", "rsi_range": (25, 50), "ma_eps": 0.06, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern4", "rsi_range": (25, 50), "ma_eps": 0.08, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern5", "rsi_range": (30, 60), "ma_eps": 0.02, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern6", "rsi_range": (30, 60), "ma_eps": 0.04, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern7", "rsi_range": (30, 60), "ma_eps": 0.06, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern8", "rsi_range": (30, 60), "ma_eps": 0.08, "slope_period": 5, "slope_thresh": 0.04}
]
# ------------------------------------------------------------------------------
# メイン処理
# ------------------------------------------------------------------------------
# 1. 事前準備(地合いスコアの一括計算)
session = requests.Session(impersonate="safari15_5")
market_scores_by_date = calculate_market_sentiment_yfinance(session=session)
if market_scores_by_date.empty:
print("地合いスコアが取得できなかったため、処理を中断します。")
exit()
# 2. 日付ごとのバックテスト実行
for today_str in tqdm(date_list, desc="全体進捗 (日付別)"):
today_process_start_time = time.time()
today = pd.Timestamp(today_str)
input_csv_path = os.path.join(input_base_dir, f'1st_filtered_{today_str}.csv')
try:
df_list = pd.read_csv(input_csv_path)
except FileNotFoundError:
print(f"ファイルが見つかりません: {input_csv_path}")
continue
output_dir = os.path.join(output_base_dir, f'2nd_16pts_slope5_{today_str}')
os.makedirs(output_dir, exist_ok=True)
score_today_val, score_mean, score_std, score_trend = get_daily_sentiment_score(today, market_scores_by_date)
summary = []
for cond in tqdm(screening_conditions, desc=f" ↳ 日付 {today_str} のパターン処理", leave=False):
result = []
for _, row in df_list.iterrows():
ticker_yf = f"{str(row['LocalCode'])[0:4]}.T"
# ★変更点: 関数を呼び出してデータ取得&計算
df = fetch_and_calculate_indicators_yfinance(ticker_yf, cond, session)
if df is None:
continue
# スクリーニング対象日を特定
screening_date = today
if screening_date not in df.index:
temp_idx = df.index.get_indexer([screening_date], method="nearest")[0]
temp_date = df.index[temp_idx]
screening_date = temp_date if temp_date <= screening_date else (df.index[temp_idx - 1] if temp_idx > 0 else None)
if not screening_date or pd.isna(df.loc[screening_date]).any():
continue
# 条件判定
last_row = df.loc[screening_date]
close_last = last_row["Close"]
epsilon = close_last * cond["ma_eps"]
trend_flag = (abs(last_row["MA_5"] - last_row["MA_25"]) < epsilon and abs(last_row["MA_25"] - last_row["MA_75"]) < epsilon and last_row["MA_5_slope"] > cond["slope_thresh"])
rsi_flag = (cond["rsi_range"][0] < last_row["RSI"] < cond["rsi_range"][1])
if trend_flag and rsi_flag:
screening_idx = df.index.get_loc(screening_date)
returns = {}
for days in [14, 30, 60, 90]:
future_idx = screening_idx + days
if future_idx < len(df):
ret = (df["Close"].iloc[future_idx] - close_last) / close_last * 100
returns[f"Return({days}d)%"] = ret
else:
returns[f"Return({days}d)%"] = np.nan
result.append({"Ticker": ticker_yf.replace(".T",""), "Name": row.get("Name", "NoName"), **returns})
df_result = pd.DataFrame(result)
df_result.to_csv(f"{output_dir}/result_{cond['name']}_{today_str}.csv", index=False)
# サマリー作成ロジック
mean_return14, win_rate14 = (df_result["Return(14d)%"].mean(), (df_result["Return(14d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
mean_return30, win_rate30 = (df_result["Return(30d)%"].mean(), (df_result["Return(30d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
mean_return60, win_rate60 = (df_result["Return(60d)%"].mean(), (df_result["Return(60d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
mean_return90, win_rate90 = (df_result["Return(90d)%"].mean(), (df_result["Return(90d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
summary.append({"Pattern": cond["name"], "銘柄数": len(df_result), "平均リターン(2週間)%": round(mean_return14, 2), "勝率(2週間後にプラス)%": round(win_rate14, 2), "平均リターン(30日)%": round(mean_return30, 2), "勝率(30日後にプラス)%": round(win_rate30, 2), "平均リターン(60日)%": round(mean_return60, 2), "勝率(60日後にプラス)%": round(win_rate60, 2), "平均リターン(90日)%": round(mean_return90, 2), "勝率(90日後にプラス)%": round(win_rate90, 2), "地合いスコア(当日)": int(score_today_val) if pd.notna(score_today_val) else np.nan, "地合いスコア平均": round(score_mean, 2), "地合いスコア標準偏差": round(score_std, 2), "地合いスコア傾向": round(score_trend, 3)})
df_summary = pd.DataFrame(summary)
today_process_end_time = time.time()
df_summary["この日の処理時間(秒)"] = today_process_end_time - today_process_start_time
df_summary.to_csv(f"{output_dir}/summary_16pts_slope5_{today_str}.csv", index=False)
global_end_time = time.time()
print(f"\n全日付 完了!! 合計処理時間: {global_end_time - global_start_time:.2f} 秒")
V2のサンプルコード
# -----------------------------
# 2nd Screening V2
# -----------------------------
import time
global_start_time = time.time()
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
import numpy as np
import os
from tqdm.notebook import tqdm
import yfinance as yf # ★地合い計算のために必要
from curl_cffi import requests # ★地合い計算のために必要
# --------------------------------------------------
# ヘルパー関数定義セクション
# --------------------------------------------------
def calculate_market_sentiment_yfinance(session, ticker="1306.T", start="2021-01-01", end="2025-05-13"):
"""
【地合い用】yfinanceからデータを取得し、地合いスコアを計算する。
"""
print(f"\n--- 事前準備: 地合いスコア計算のため {ticker} のデータをyfinanceからダウンロードします ---")
df = yf.download(ticker, start=start, end=end, session=session, progress=False, timeout=10, auto_adjust=False)
if df.empty:
print(f"⚠️ {ticker} のデータ取得に失敗しました。")
return pd.Series(dtype=float)
if isinstance(df.columns, pd.MultiIndex):
df.columns = df.columns.get_level_values(0)
# 地合いスコア用の指標計算
df["MA25_diff"] = (df["Close"] - df["Close"].rolling(25).mean()) / df["Close"].rolling(25).mean()
df["5d_return"] = df["Close"].pct_change(5)
delta = df['Close'].diff()
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=df.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=df.index).rolling(14).mean()
rs = avg_gain / (avg_loss + 1e-10)
df['RSI'] = 100 - (100 / (1 + rs))
# スコアリング
df['score'] = 0
df['score'] += (df['5d_return'] > 0.01).astype(int)
df['score'] += (df['MA25_diff'] > 0).astype(int)
df['score'] += (df['RSI'] > 55).astype(int)
df['score'] -= (df['RSI'] < 45).astype(int)
df['score'] -= (df['5d_return'] < -0.01).astype(int)
df['score'] -= (df['MA25_diff'] < 0).astype(int)
print("✅ 地合いスコアの計算が完了しました。")
return df['score'].sort_index()
def fetch_and_calculate_indicators_parquet(ticker, today, parquet_path, cond):
"""
【個別銘柄用】Parquetから都度データを読み込み、指標を計算する。
"""
try:
lookback_days = 250
lookahead_days = 90
start_date = today - pd.Timedelta(days=lookback_days)
end_date = today + pd.Timedelta(days=lookahead_days)
df = pd.read_parquet(
parquet_path,
filters=[('Ticker', '==', ticker), ('Date', '>=', start_date), ('Date', '<=', end_date)],
columns=['Date', 'Open', 'High', 'Low', 'Close', 'Volume']
)
if df.empty or len(df) < 75: return None
df["Date"] = pd.to_datetime(df["Date"])
df = df.set_index("Date").sort_index()
df["MA_5"] = df["Close"].rolling(window=5).mean()
df["MA_25"] = df["Close"].rolling(window=25).mean()
df["MA_75"] = df["Close"].rolling(window=75).mean()
delta = df["Close"].diff()
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=df.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=df.index).rolling(14).mean()
df["RSI"] = 100 - (100 / (1 + (avg_gain / (avg_loss + 1e-10))))
df["MA_5_slope"] = df["MA_5"].diff(cond["slope_period"]) / cond["slope_period"]
return df
except Exception:
return None
def get_daily_sentiment_score(today, market_scores_by_date):
"""
日付を指定して、準備済みの地合いスコアから関連情報を取得する。(共通関数)
"""
try:
score_date = today
if score_date not in market_scores_by_date.index:
temp_idx = market_scores_by_date.index.get_indexer([score_date], method="nearest")[0]
temp_date = market_scores_by_date.index[temp_idx]
score_date = temp_date if temp_date <= score_date else (market_scores_by_date.index[temp_idx - 1] if temp_idx > 0 else None)
if score_date:
score_today_val = market_scores_by_date.loc[score_date]
score_window = market_scores_by_date.loc[market_scores_by_date.index <= score_date].tail(10)
return score_today_val, score_window.mean(), score_window.std(), score_window.diff().mean()
except Exception:
pass
return np.nan, np.nan, np.nan, np.nan
# --------------------------------------------------
# 設定・定義セクション
# --------------------------------------------------
# --- パス設定 ---
input_base_dir = "/content/drive/MyDrive/stock_prediction/ver.1/results/Qiita/1st/J-Quants/Prime/selected_ajt_type2"
output_base_dir = "/content/drive/MyDrive/stock_prediction/ver.1/results/Qiita/2nd/Speed_test/hybrid_loop" # 出力先を明示的に変更
os.makedirs(output_base_dir, exist_ok=True)
# --- データソース設定 ---
PARQUET_PATH_FOR_PREDICTION = "/content/drive/MyDrive/stock_prediction/ver.1/Database/OHLCV/プライム/total_with_date/batch_size/ticker_combined_append_batch_PER.parquet"
# --- 日付リスト ---
date_list = [
'2022-01-13', '2022-01-24', '2022-01-28', '2022-02-01', '2022-04-20',
'2022-05-17', '2022-05-27', '2022-06-21', '2022-07-21', '2022-09-05',
'2022-09-09', '2022-11-28', '2022-12-01', '2022-12-21', '2023-02-17',
'2023-03-28', '2023-04-24', '2023-07-14', '2023-08-04', '2023-09-21',
'2023-10-05', '2023-11-09', '2023-11-29', '2023-12-04', '2023-12-21',
'2023-12-22', '2024-03-05', '2024-03-13', '2024-03-26', '2024-04-11',
'2024-06-06', '2024-06-07', '2024-07-22', '2024-07-26', '2024-09-12'
]
# --- スクリーニング条件定義 ---
screening_conditions = [
{"name": "pattern1", "rsi_range": (25, 50), "ma_eps": 0.02, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern2", "rsi_range": (25, 50), "ma_eps": 0.04, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern3", "rsi_range": (25, 50), "ma_eps": 0.06, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern4", "rsi_range": (25, 50), "ma_eps": 0.08, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern5", "rsi_range": (30, 60), "ma_eps": 0.02, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern6", "rsi_range": (30, 60), "ma_eps": 0.04, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern7", "rsi_range": (30, 60), "ma_eps": 0.06, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern8", "rsi_range": (30, 60), "ma_eps": 0.08, "slope_period": 5, "slope_thresh": 0.04}
]
# ------------------------------------------------------------------------------
# メイン処理
# ------------------------------------------------------------------------------
# 1. 事前準備(地合いスコアをyfinanceで計算)
session = requests.Session(impersonate="safari15_5")
market_scores_by_date = calculate_market_sentiment_yfinance(session=session)
if market_scores_by_date.empty:
print("地合いスコアが取得できなかったため、処理を中断します。")
exit()
# 2. 日付ごとのバックテスト実行
for today_str in tqdm(date_list, desc="全体進捗 (日付別)"):
today_process_start_time = time.time()
today = pd.Timestamp(today_str)
input_csv_path = os.path.join(input_base_dir, f'1st_filtered_{today_str}.csv')
try:
df_list = pd.read_csv(input_csv_path)
except FileNotFoundError:
print(f"ファイルが見つかりません: {input_csv_path}")
continue
output_dir = os.path.join(output_base_dir, f'2nd_16pts_slope5_{today_str}')
os.makedirs(output_dir, exist_ok=True)
score_today_val, score_mean, score_std, score_trend = get_daily_sentiment_score(today, market_scores_by_date)
summary = []
for cond in tqdm(screening_conditions, desc=f" ↳ 日付 {today_str} のパターン処理", leave=False):
result = []
for _, row in df_list.iterrows():
ticker = f"{str(row['LocalCode'])[0:4]}.T"
# ★変更点: 個別銘柄のデータはParquetから取得
df = fetch_and_calculate_indicators_parquet(ticker, today, PARQUET_PATH_FOR_PREDICTION, cond)
if df is None:
continue
# スクリーニング対象日を特定
screening_date = today
if screening_date not in df.index:
temp_idx = df.index.get_indexer([screening_date], method="nearest")[0]
temp_date = df.index[temp_idx]
screening_date = temp_date if temp_date <= screening_date else (df.index[temp_idx - 1] if temp_idx > 0 else None)
if not screening_date or pd.isna(df.loc[screening_date]).any():
continue
# 条件判定
last_row = df.loc[screening_date]
close_last = last_row["Close"]
epsilon = close_last * cond["ma_eps"]
trend_flag = (abs(last_row["MA_5"] - last_row["MA_25"]) < epsilon and abs(last_row["MA_25"] - last_row["MA_75"]) < epsilon and last_row["MA_5_slope"] > cond["slope_thresh"])
rsi_flag = (cond["rsi_range"][0] < last_row["RSI"] < cond["rsi_range"][1])
if trend_flag and rsi_flag:
screening_idx = df.index.get_loc(screening_date)
returns = {}
for days in [14, 30, 60, 90]:
future_idx = screening_idx + days
if future_idx < len(df):
ret = (df["Close"].iloc[future_idx] - close_last) / close_last * 100
returns[f"Return({days}d)%"] = ret
else:
returns[f"Return({days}d)%"] = np.nan
result.append({"Ticker": ticker.replace(".T", ""), "Name": row.get("Name", "NoName"), **returns})
df_result = pd.DataFrame(result)
df_result.to_csv(f"{output_dir}/result_{cond['name']}_{today_str}.csv", index=False)
# サマリー作成ロジック
mean_return14, win_rate14 = (df_result["Return(14d)%"].mean(), (df_result["Return(14d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
mean_return30, win_rate30 = (df_result["Return(30d)%"].mean(), (df_result["Return(30d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
mean_return60, win_rate60 = (df_result["Return(60d)%"].mean(), (df_result["Return(60d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
mean_return90, win_rate90 = (df_result["Return(90d)%"].mean(), (df_result["Return(90d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
summary.append({"Pattern": cond["name"], "銘柄数": len(df_result), "平均リターン(2週間)%": round(mean_return14, 2), "勝率(2週間後にプラス)%": round(win_rate14, 2), "平均リターン(30日)%": round(mean_return30, 2), "勝率(30日後にプラス)%": round(win_rate30, 2), "平均リターン(60日)%": round(mean_return60, 2), "勝率(60日後にプラス)%": round(win_rate60, 2), "平均リターン(90日)%": round(mean_return90, 2), "勝率(90日後にプラス)%": round(win_rate90, 2), "地合いスコア(当日)": int(score_today_val) if pd.notna(score_today_val) else np.nan, "地合いスコア平均": round(score_mean, 2), "地合いスコア標準偏差": round(score_std, 2), "地合いスコア傾向": round(score_trend, 3)})
df_summary = pd.DataFrame(summary)
today_process_end_time = time.time()
df_summary["この日の処理時間(秒)"] = today_process_end_time - today_process_start_time
df_summary.to_csv(f"{output_dir}/summary_16pts_slope5_{today_str}.csv", index=False)
global_end_time = time.time()
print(f"\n全日付 完了!! 合計処理時間: {global_end_time - global_start_time:.2f} 秒")
V3のサンプルコード
# -----------------------------
# 2nd screening V3
# -----------------------------
import time
global_start_time = time.time()
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
import numpy as np
import os
from tqdm.notebook import tqdm
import yfinance as yf
from curl_cffi import requests
session = requests.Session(impersonate="safari15_5")
# --------------------------------------------------
# ヘルパー関数定義セクション
# --------------------------------------------------
def calculate_market_sentiment_score(ticker_symbol: str, start_date: str, end_date: str, session) -> pd.DataFrame:
"""
指定されたティッカーシンボル(TOPIX連動ETFなど)のデータに基づき、地合いスコアを計算する。
"""
print(f"🌀 地合いスコア計算のため、{ticker_symbol} のデータをダウンロード中...")
start_str = pd.Timestamp(start_date).strftime('%Y-%m-%d')
end_str = pd.Timestamp(end_date).strftime('%Y-%m-%d')
market_data = yf.download(ticker_symbol, start=start_str, end=end_str, interval="1d", session=session)
if market_data.empty:
print(f"⚠️ {ticker_symbol} のデータが見つかりません。地合いスコア計算をスキップします。")
return pd.DataFrame()
if isinstance(market_data.columns, pd.MultiIndex):
market_data.columns = market_data.columns.get_level_values(0)
market_data["LogReturn"] = np.log(market_data["Close"] / market_data["Close"].shift(1))
market_data["MA25"] = market_data["Close"].rolling(25).mean()
market_data["MA25_diff"] = (market_data["Close"] - market_data["MA25"]) / market_data["MA25"]
delta = market_data["Close"].diff()
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=market_data.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=market_data.index).rolling(14).mean()
rs = avg_gain / (avg_loss + 1e-10)
market_data["RSI_14"] = 100 - (100 / (1 + rs))
market_data["score_today"] = 0
market_data["score_today"] += (market_data["LogReturn"].rolling(5).sum() > 0.01).astype(int)
market_data["score_today"] += (market_data["MA25_diff"] > 0).astype(int)
market_data["score_today"] += (market_data["RSI_14"] > 55).astype(int)
market_data["score_today"] -= (market_data["RSI_14"] < 45).astype(int)
market_data["score_today"] -= (market_data["LogReturn"].rolling(5).sum() < -0.01).astype(int)
market_data["score_today"] -= (market_data["MA25_diff"] < 0).astype(int)
market_data["score_mean"] = market_data["score_today"].rolling(10).mean()
market_data["score_std"] = market_data["score_today"].rolling(10).std()
market_data["score_trend"] = market_data["score_today"].diff().rolling(10).mean()
ema12 = market_data["Close"].ewm(span=12, adjust=False).mean()
ema26 = market_data["Close"].ewm(span=26, adjust=False).mean()
market_data["MACD"] = ema12 - ema26
market_data["Signal"] = market_data["MACD"].ewm(span=9, adjust=False).mean()
market_data["MACD_Hist"] = market_data["MACD"] - market_data["Signal"]
market_data.index.name = 'Date'
market_df = market_data.dropna().copy()
print(f"✅ 地合いスコア計算完了 ({ticker_symbol})。")
return market_df
def calculate_technical_indicators(df_group):
"""
個別銘柄のデータフレームを受け取り、テクニカル指標を計算して返す。
"""
if df_group.empty or len(df_group) < 75:
return df_group
df_group["MA_5"] = df_group["Close"].rolling(window=5).mean()
df_group["MA_25"] = df_group["Close"].rolling(window=25).mean()
df_group["MA_75"] = df_group["Close"].rolling(window=75).mean()
delta = df_group["Close"].diff()
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=df_group.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=df_group.index).rolling(14).mean()
rs = avg_gain / (avg_loss + 1e-10)
df_group["RSI"] = 100 - (100 / (1 + rs))
df_group["MA_5_slope"] = df_group["MA_5"].diff(5) / 5
return df_group
# --------------------------------------------------
# 設定・定義セクション
# --------------------------------------------------
# --- パス設定 ---
input_base_dir = "/content/drive/MyDrive/stock_prediction/ver.1/results/Qiita/1st/J-Quants/Prime/selected_ajt_type2"
output_base_dir = "/content/drive/MyDrive/stock_prediction/ver.1/results/Qiita/2nd/Speed _test/mydataset/morerapid"
os.makedirs(output_base_dir, exist_ok=True)
# --- データソース設定 ---
PARQUET_PATH_FOR_PREDICTION = "/content/drive/MyDrive/stock_prediction/ver.1/Database/OHLCV/プライム/total_with_date/batch_size/ticker_combined_append_batch_PER.parquet"
MARKET_INDEX_TICKER = '1306.T' # 地合い計算に使うTOPIX連動ETFなど
# --- 日付リスト ---
date_list = [
'2022-01-13', '2022-01-24', '2022-01-28', '2022-02-01', '2022-04-20',
'2022-05-17', '2022-05-27', '2022-06-21', '2022-07-21', '2022-09-05',
'2022-09-09', '2022-11-28', '2022-12-01', '2022-12-21', '2023-02-17',
'2023-03-28', '2023-04-24', '2023-07-14', '2023-08-04', '2023-09-21',
'2023-10-05', '2023-11-09', '2023-11-29', '2023-12-04', '2023-12-21',
'2023-12-22', '2024-03-05', '2024-03-13', '2024-03-26', '2024-04-11',
'2024-06-06', '2024-06-07', '2024-07-22', '2024-07-26', '2024-09-12'
]
# --- スクリーニング条件定義 ---
screening_conditions = [
{"name": "pattern1", "rsi_range": (25, 50), "ma_eps": 0.02, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern2", "rsi_range": (25, 50), "ma_eps": 0.04, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern3", "rsi_range": (25, 50), "ma_eps": 0.06, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern4", "rsi_range": (25, 50), "ma_eps": 0.08, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern5", "rsi_range": (30, 60), "ma_eps": 0.02, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern6", "rsi_range": (30, 60), "ma_eps": 0.04, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern7", "rsi_range": (30, 60), "ma_eps": 0.06, "slope_period": 5, "slope_thresh": 0.04},
{"name": "pattern8", "rsi_range": (30, 60), "ma_eps": 0.08, "slope_period": 5, "slope_thresh": 0.04}
]
# ------------------------------------------------------------------------------
# メイン処理
# ------------------------------------------------------------------------------
# -----------------------------
# 1. データ準備(一括読み込みと事前計算)
# -----------------------------
print("\n--- 全データセットの読み込みとテクニカル指標の事前計算を開始します ---")
global_data_load_start_time = time.time()
# 分析期間を決定
earliest_screening_date = pd.Timestamp(date_list[0])
latest_screening_date = pd.Timestamp(date_list[-1])
max_lookback_days = 250
max_lookahead_days = 90
global_data_start_date = earliest_screening_date - pd.Timedelta(days=max_lookback_days)
global_data_end_date = latest_screening_date + pd.Timedelta(days=max_lookahead_days)
print(f"分析対象期間: {global_data_start_date.strftime('%Y-%m-%d')} から {global_data_end_date.strftime('%Y-%m-%d')}")
# 地合いスコアを動的に計算
try:
df_market_sentiment = calculate_market_sentiment_score(
ticker_symbol=MARKET_INDEX_TICKER,
start_date=global_data_start_date,
end_date=global_data_end_date,
session=session
)
sentiment_cols = ['score_today', 'score_mean', 'score_std', 'score_trend']
df_market_sentiment_to_merge = df_market_sentiment[sentiment_cols].copy()
except Exception as e:
print(f"致命的エラー: 地合いスコアの計算に失敗しました: {e}")
df_market_sentiment = pd.DataFrame() # ループ内で参照するため空で定義
df_market_sentiment_to_merge = pd.DataFrame(columns=['score_today', 'score_mean', 'score_std', 'score_trend'])
# ParquetファイルからOHLCVデータを読み込む
try:
df_all_data = pd.read_parquet(
PARQUET_PATH_FOR_PREDICTION,
columns=['Date', 'Ticker', 'Open', 'High', 'Low', 'Close', 'Volume'],
filters=[('Date', '>=', pd.Timestamp(global_data_start_date)), ('Date', '<=', pd.Timestamp(global_data_end_date))]
)
df_all_data["Date"] = pd.to_datetime(df_all_data["Date"])
df_all_data["Ticker"] = df_all_data["Ticker"].str.replace(".T", "", regex=False)
except Exception as e:
print(f"致命的エラー: 全データセットの読み込みに失敗しました: {e}")
exit()
# 銘柄データに地合いスコアを日付キーでマージ
if not df_market_sentiment_to_merge.empty:
print("🌀 銘柄データに地合いスコアを結合中...")
df_all_data_processed = pd.merge(df_all_data, df_market_sentiment_to_merge.reset_index(), on='Date', how='left')
df_all_data_processed = df_all_data_processed.set_index(["Date", "Ticker"]).sort_index()
else:
print("⚠️ 地合いスコアが利用できないため、スコア関連の列はNaNになります。")
df_all_data_processed = df_all_data.set_index(["Date", "Ticker"]).sort_index()
for col in ['score_today', 'score_mean', 'score_std', 'score_trend']:
df_all_data_processed[col] = np.nan
# 全銘柄のテクニカル指標を計算 (★ここで、冒頭で定義した関数を呼び出す)
print("🌀 全銘柄のテクニカル指標を計算中...")
tickers_to_process = df_all_data_processed.index.get_level_values('Ticker').unique()
processed_data_parts = []
for ticker_val in tqdm(tickers_to_process, desc="↳ 各銘柄のテクニカル指標計算"):
ticker_df_part = df_all_data_processed.loc[(slice(None), ticker_val), :].reset_index(level='Ticker', drop=True).copy()
processed_df_part = calculate_technical_indicators(ticker_df_part)
processed_df_part['Ticker'] = ticker_val
processed_df_part = processed_df_part.set_index('Ticker', append=True).swaplevel(0,1)
processed_data_parts.append(processed_df_part)
df_all_data_processed = pd.concat(processed_data_parts).sort_index()
global_data_load_end_time = time.time()
print(f"✅ 全データセットの読み込みとテクニカル指標の事前計算が完了しました。所要時間: {global_data_load_end_time - global_data_load_start_time:.2f} 秒")
# -----------------------------
# 2. 日付ごとのバックテスト実行
# -----------------------------
for today_str in tqdm(date_list, desc="全体進捗 (日付別)"):
today_process_start_time = time.time()
today = pd.Timestamp(today_str)
# 1stスクリーニング結果を読む
input_csv_path = os.path.join(input_base_dir, f'1st_filtered_{today_str}.csv')
try:
df_list = pd.read_csv(input_csv_path)
except FileNotFoundError:
print(f"エラー: 1stスクリーニング結果ファイルが見つかりません: {input_csv_path}")
continue
# 出力先を作成
output_dir = os.path.join(output_base_dir, f'2nd_16pts_slope5_{today_str}')
os.makedirs(output_dir, exist_ok=True)
# 地合いスコアの取得
score_today_val, score_mean, score_std, score_trend = np.nan, np.nan, np.nan, np.nan
try:
if not df_market_sentiment.empty:
if today in df_market_sentiment.index:
score_row = df_market_sentiment.loc[today]
else:
temp_idx = df_market_sentiment.index.get_indexer([today], method="nearest")[0]
temp_date = df_market_sentiment.index[temp_idx]
score_date = temp_date if temp_date <= today else (df_market_sentiment.index[temp_idx - 1] if temp_idx > 0 else None)
score_row = df_market_sentiment.loc[score_date] if score_date else None
if score_row is not None:
score_today_val, score_mean, score_std, score_trend = score_row['score_today'], score_row['score_mean'], score_row['score_std'], score_row['score_trend']
except Exception as e:
print(f"地合いスコア取得中にエラー: {e}")
# 条件別比較&バックテスト
summary = []
for cond in tqdm(screening_conditions, desc=f" ↳ 日付 {today_str} のパターン処理", leave=False):
result = []
for _, row in df_list.iterrows():
ticker = str(row["LocalCode"])[0:4]
try:
df = df_all_data_processed.loc[(ticker,slice(None)), :].reset_index(level='Ticker', drop=True).copy()
if df.empty: continue
screening_date = today
if screening_date not in df.index:
temp_idx = df.index.get_indexer([screening_date], method="nearest")[0]
temp_date = df.index[temp_idx]
screening_date = temp_date if temp_date <= screening_date else (df.index[temp_idx - 1] if temp_idx > 0 else None)
if not screening_date: continue
last_row = df.loc[screening_date]
ma5_last, ma25_last, ma75_last = last_row["MA_5"], last_row["MA_25"], last_row["MA_75"]
slope_last, rsi_last, close_last = last_row["MA_5_slope"], last_row["RSI"], last_row["Close"]
epsilon = close_last * cond["ma_eps"]
trend_flag = (abs(ma5_last - ma25_last) < epsilon and abs(ma25_last - ma75_last) < epsilon and slope_last > cond["slope_thresh"])
rsi_flag = (cond["rsi_range"][0] < rsi_last < cond["rsi_range"][1])
if trend_flag and rsi_flag:
df_trading_days = df.dropna(subset=['Close'])
if screening_date not in df_trading_days.index: continue
screening_idx_pos = df_trading_days.index.get_loc(screening_date)
returns = {}
for days in [14, 30, 60, 90]:
future_idx_pos = screening_idx_pos + days
returns[f"Return({days}d)%"] = ((df_trading_days["Close"].iloc[future_idx_pos] - close_last) / close_last * 100) if future_idx_pos < len(df_trading_days) else np.nan
result.append({"Ticker": ticker, "Name": row.get("Name", "NoName"), **returns})
except (KeyError, IndexError, TypeError):
continue
df_result = pd.DataFrame(result)
df_result.to_csv(f"{output_dir}/result_{cond['name']}_{today_str}.csv", index=False)
# summary への追加
mean_return14, win_rate14 = (df_result["Return(14d)%"].mean(), (df_result["Return(14d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
mean_return30, win_rate30 = (df_result["Return(30d)%"].mean(), (df_result["Return(30d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
mean_return60, win_rate60 = (df_result["Return(60d)%"].mean(), (df_result["Return(60d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
mean_return90, win_rate90 = (df_result["Return(90d)%"].mean(), (df_result["Return(90d)%"] > 0).mean() * 100) if not df_result.empty else (np.nan, np.nan)
summary.append({
"Pattern": cond["name"], "銘柄数": len(df_result),
"平均リターン(2週間)%": round(mean_return14, 2), "勝率(2週間後にプラス)%": round(win_rate14, 2),
"平均リターン(30日)%": round(mean_return30, 2), "勝率(30日後にプラス)%": round(win_rate30, 2),
"平均リターン(60日)%": round(mean_return60, 2), "勝率(60日後にプラス)%": round(win_rate60, 2),
"平均リターン(90日)%": round(mean_return90, 2), "勝率(90日後にプラス)%": round(win_rate90, 2),
"地合いスコア(当日)": int(score_today_val) if pd.notna(score_today_val) else np.nan,
"地合いスコア平均": round(score_mean, 2), "地合いスコア標準偏差": round(score_std, 2), "地合いスコア傾向": round(score_trend, 3)
})
# summaryの保存
df_summary = pd.DataFrame(summary)
today_process_end_time = time.time()
elapsed_time_today = today_process_end_time - today_process_start_time
df_summary["この日の処理時間(秒)"] = elapsed_time_today
df_summary.to_csv(f"{output_dir}/summary_16pts_slope5_{today_str}.csv", index=False)
global_end_time = time.time()
total_elapsed_time = global_end_time - global_start_time
print(f"\n全日付 完了!! 合計処理時間: {total_elapsed_time:.2f} 秒")
おすすめ記事
tqdm は Python のループ処理に「進捗バー(プログレスバー)」を簡単に追加できるライブラリです。
長丁場な処理をするときは、いつになったら終わるんなら!とカリカリしなくてもよくなるし、
待ち時間に、北海道行ってこよう!みたいなこともできます。
Jupyter / Colab で実行する場合は、 tqdm.notebookがおすすめです。見た目が良くて、かっこいい。やった感ある。
tqdm に関する参考記事まとめ
tqdmでプログレスバーを表示させる
tqdmを使ったプログレスバーの基本操作から、update()やset_description()によるカスタマイズまでを解説されてる。
Pythonでプログレスバーを表示【tqdm】
tqdmの導入方法、ループやPandasでの利用例、descやtotalなど主要引数の使い方がわかる。
Pythonで進捗可視化のためにtqdmを使う
よく動いている感じが良い
Pythonの進捗バーtqdmの使い方
postfix()による動的情報表示など、現場視点で便利な使いこなしをまとめた技術メモ。
高速化の参考記事
Pythonの実行を高速化する方法を一覧でまとめてみた - Qiita
Pythonを高速化するための手法を一覧形式で網羅的に解説した記事。
Numbaなど、用途別に整理されていて導入しやすい。
Numbaって大阪難波のことですか?バスターミナルになかなか到達できないですが、いいところd
Pythonを10倍高速化する実践テクニック集
勝手に尊敬させていただいてる重盛さんの記事。ベンチマーク付きで解説されてて、今回の改善にも非常に勉強になった。
2025年06月22日リンク修正しました。