Abstract
white, inc の ソフトウェアエンジニア r2en です。
自社では新規事業を中心としたコンサルタント業務を行なっており、
普段エンジニアは、新規事業を開発する無料のクラウド型ツール を開発したり、
新規事業のコンサルティングからPoC開発まで携わります

今回は、機械学習の技術調査を行なったので記事で共有させていただきます
以下から文章が長くなりますので、口語で記述させていただきます
ヒストグラムベースのGradientBoostingTreeが追加されたので、系譜のLightGBMと比較した使用感を検証する。
今回はハイパーパラメータ探索のOptunaを使い、パラメータ探索時点から速度や精度を比較検証する。
最後にKaggleにSubmissionして、汎用性を確認する。
Introduction
scikit-learn v0.21 で追加された HistGradientBoosting*
ヒストグラムベースの勾配ブースティング木。LightGBMの系譜。
n_samples >= 10,000 のデータセットの場合、sklearn.ensemble.GradientBoostingClassifierよりもずっと高速に動く。
LightGBMと同じくbinning(整数で値を分割)しているので高速且つ、汎用性が高いものになっている。
Environment
検証環境
PC環境
OS: macOS HighSierra 10.13.6(Retina, Early 2015)
CPU: 3.1GHz Intel Core i7
MEM: 16GB 1867MHz DDR3
GPU: Intel Iris Graphics 6100 1536MB
開発環境
Python==3.6.8
jupyter notebook
import numpy as np
import pandas as pd
import lightgbm as lgbm
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
%reload_ext autoreload
%autoreload 2
HistGradientBoostingTree インストール
1.Scikit-learnを0.21.*以上にする必要性がある
!pip install -U scikit-learn==0.21.0
2.ライブラリをインポート
import sklearn
sklearn.__version__
'0.21.0'
3.現状では、from sklearn.experimental import enable_hist_gradient_boostingを一緒にインポートする必要性がある
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
速度計測
import time
from contextlib import contextmanager
@contextmanager
def timer(name):
t0 = time.time()
yield
print(f'[{name}] done in {time.time() - t0:.0f} s')
データ
Titanic: Machine Learning from Disaster
適度なデータ数、カーディナリティの少なさ、解釈しやすさ、皆に認識されてる3点から採用。
このコンペは、タイタニック号に乗船した、各乗客の購入したチケットのクラス(Pclass1, 2, 3の順で高いクラス)や、料金(Fare)、年齢(Age)、性別(Sex)、出港地(Embarked)、部屋番号(Cabin)、チケット番号(Tichket)、乗船していた兄弟または配偶者の数(SibSp)、乗船していた親または子供の数(Parch)など情報があり、そこからタイタニック号が氷山に衝突し沈没した際生存したかどうか(Survived)を予測する。
| 変数名 | 特徴 |
|---|---|
| PassengerId | 乗客識別ユニークID |
| Survived | 生死 |
| Pclass | チケットクラス |
| Name | 乗客の名前 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | タイタニックに同乗している兄弟/配偶者の数 |
| Parch | タイタニックに同乗している親/子供の数 |
| Ticket | チケット番号 |
| Cabin | 客室番号 |
| Embarked | 出港地(タイタニックへ乗った港) |
前処理
前処理の方針としては、カテゴリ変数を数値型に変換し、欠損値をLightGBMで予測して埋める、のみ。
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# 欠損値を見ていくとAge, Cabin, Embarked, Fareがあることがわかる。
train.isnull().sum()
test.isnull().sum()
# Name, Sex, Ticket, Cabin, Embarkedのデータ型はObject型なのがわかる
# 機械学習モデルを適用するために、数値型に変換する
train.dtypes
test.dtypes
# Object型のName, Ticket, Cabinはカーディナリティが高く変換しづらいので削除
train = train.drop(['Name', 'Ticket', 'Cabin'], axis=1)
test = test.drop(['Name', 'Ticket', 'Cabin'], axis=1)
# Object型のEmbarked, Sexはカーディナリティが低く、変換しやすい数値データに変換
import category_encoders
object_columns = ['Embarked', 'Sex']
encode = category_encoders.OrdinalEncoder(cols=object_columns, handle_unknown='impute')
train = encode.fit_transform(train)
test = encode.fit_transform(test)
# NaNが4に割り振られているものを修正
# encode.category_mapping
# encoded_train['Embarked'].value_counts()
train['Embarked'].replace(4, np.nan, inplace=True)
# encoded_train.isnull().sum()
# Fare欠損値埋め
# 予測したいデータ
fare_null = test[test['Fare'].isnull()].drop(['Fare'], axis=1)
# トレーニングデータ
fare_X = test[~test['Fare'].isnull()].drop(['Fare'], axis=1)
fare_y = test[~test['Fare'].isnull()]['Fare']
params = {
'boosting_type': 'gbdt',
'objective': 'regression_l2',
'metric': 'l2',
'num_leaves': 40,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'lambda_l2': 2,
}
fare_pred = lgbm.LGBMRegressor(**params).fit(fare_X, fare_y).predict(fare_null)
test['Fare'].replace(np.nan, int(fare_pred), inplace=True)
# Age欠損値埋め
# 予測したいデータ
age_null = pd.concat([
train[train['Age'].isnull()],
test[test['Age'].isnull()]
]).drop(['Survived', 'Age'], axis=1)
age_null_train = train[train['Age'].isnull()].drop(['Survived', 'Age'], axis=1)
age_null_test = test[test['Age'].isnull()].drop(['Age'], axis=1)
# トレーニングデータ
age_X = pd.concat([
train[~train['Age'].isnull()],
test[~test['Age'].isnull()]
]).drop(['Survived','Age'], axis=1)
age_y = pd.concat([
train[~train['Age'].isnull()],
test[~test['Age'].isnull()]
])['Age']
params = {
'boosting_type': 'gbdt',
'objective': 'regression_l2',
'metric': 'l2',
'num_leaves': 40,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'lambda_l2': 2,
}
age_pred_train = lgbm.LGBMRegressor(**params).fit(age_X, age_y).predict(age_null_train)
age_pred_test = lgbm.LGBMRegressor(**params).fit(age_X, age_y).predict(age_null_test)
# 欠損値
nan = np.zeros(age_pred_train.shape[0])
nan[:] = np.nan
train['Age'].replace(nan, age_pred_train.astype(np.float64), inplace=True)
nan = np.zeros(age_pred_test.shape[0])
nan[:] = np.nan
test['Age'].replace(nan, age_pred_test.astype(np.float64), inplace=True)
# Embarked欠損値埋め
# 予測したいデータ
embarked_null = train[train['Embarked'].isnull()].drop(['Survived', 'Embarked'], axis=1)
# トレーニングデータ
embarked_X = train[~train['Embarked'].isnull()].drop(['Survived', 'Embarked'], axis=1)
embarked_y = train[~train['Embarked'].isnull()]['Embarked']
params = {
'boosting_type': 'gbdt',
'objective': 'multiclass',
'num_class': 4,
'num_leaves': 40,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'lambda_l2': 2,
}
embarked_pred = lgbm.LGBMClassifier(**params).fit(embarked_X, embarked_y).predict(embarked_null)
nan = np.zeros(embarked_pred.shape[0])
nan[:] = np.nan
train['Embarked'].replace(nan, embarked_pred.astype(np.float64), inplace=True)
機械学習をさせるために、トレーニングデータを説明変数と目的変数に分離する
X = train.drop(['Survived'], axis=1)
y = train['Survived']
Method
import optuna
import lightgbm as lgbm
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_validate
from sklearn.metrics import accuracy_score, make_scorer
交差検証を5回、一度のイテレーションでoptunaの学習を100回試行させる
learning_rateとiterationは固定にする
SEED = 0
NFOLDS = 5
NTRIAL = 1000
LR = 0.1
ITER = 100
モデルのパラメータをoptunadeで設定
def tuning_parameter(trial, classifier):
if classifier == 'LightGBM':
params = {}
params['objective'] = 'binary'
params['random_state'] = SEED
params['metric'] = 'binary_logloss'
params['verbosity'] = -1
params['boosting_type'] = trial.suggest_categorical('boosting', ['gbdt', 'dart', 'goss'])
# モデル訓練のスピードを上げる
#params['bagging_freq'] = trial.suggest_int('max_bins', 0, 5)
params['save_binary'] = False
# 推測精度を向上させる
params['learning_rate'] = LR
params['num_iterations'] = ITER
params['num_leaves'] = trial.suggest_int('num_leaves', 5, 100)
params['max_bins'] = trial.suggest_int('max_bins', 2, 256)
# 過学習対策
# early stoppingは今回使わない。切り方によって、性能を高く見積もる可能性があるため。
# データ数が少ないため、早期に切り上げる必要性を感じないため。
#params['eary_stopping_round']
params['min_data_in_leaf'] = trial.suggest_int('min_data_in_leaf', 1, 100)
params['feature_fraction'] = trial.suggest_uniform('top_rate', 0.0, 1.0)
#params['bagging_fraction'] = trial.suggest_uniform('bagging_fraction', 0, 1.0)
params['min_child_weight'] = trial.suggest_int('min_child_weight', 0, 1e-3)
params['lambda_l1'] = trial.suggest_int('lambda_l1', 0, 500)
params['lambda_l2'] = trial.suggest_int('lambda_l2', 0, 500)
params['min_gain_to_split'] = 0
params['max_depth'] = trial.suggest_int('max_depth', 6, 10)
if params['boosting_type'] == 'dart':
params['drop_rate'] = trial.suggest_loguniform('drop_rate', 1e-8, 1.0)
params['skip_drop'] = trial.suggest_loguniform('skip_drop', 1e-8, 1.0)
if params['boosting_type'] == 'goss':
params['top_rate'] = trial.suggest_uniform('top_rate', 0.0, 1.0)
params['other_rate'] = trial.suggest_uniform('other_rate', 0.0, 1.0 - params['top_rate'])
return params
if classifier == 'HistGradientBoostingClassifier':
params = {}
params['random_state'] = SEED
params['loss'] = 'binary_crossentropy'
params['verbose'] = -1
# モデル訓練のスピードを上げる
params['tol'] = trial.suggest_loguniform('tol', 1e-8, 1e-1)
# 推測精度を向上させる
params['learning_rate'] = LR
params['max_iter'] = ITER
params['max_leaf_nodes'] = trial.suggest_int('max_leaf_nodes', 5, 100)
params['max_bins'] = trial.suggest_int('max_bins', 2, 256)
params['min_samples_leaf'] = trial.suggest_int('min_samples_leaf', 1, 100)
# 過学習対策
#params['n_iter_no_change']
#iparams['scoring']
params['max_depth'] = trial.suggest_int('max_depth', 6, 10)
params['validation_fraction'] = 0.1 #trial.suggest_uniform('top_rate', 0.0, 1.0)
params['l2_regularization'] = trial.suggest_int('l2_regularization', 0, 500)
return params
def estimator(classifier, params):
if classifier == 'LightGBM': return lgbm.LGBMClassifier(**params)
if classifier == 'HistGradientBoostingClassifier': return HistGradientBoostingClassifier(**params)
def evaluate_score():
return {
'accuracy': make_scorer(accuracy_score)
}
class Objective(object):
def __init__(self, dataset):
self.X, self.y = dataset['training'], dataset['answer']
def __call__(self, trial):
classifier = dataset['classifier'] if 'classifier' in dataset else trial.suggest_categorical('classifier', ['LightGBM', 'HistGradientBoostingClassifier'])
params = tuning_parameter(trial, classifier)
clf = estimator(classifier, params)
score = evaluate_score()
kf = StratifiedKFold(n_splits=NFOLDS, shuffle=True, random_state=SEED)
scores = cross_validate(estimator=clf, X=self.X, y=self.y, cv=kf, scoring=score, n_jobs=-1)
return 1.0 - scores['test_accuracy'].mean()
デフォルトで、枝刈りのoptuna.pruners.MedianPrunerが設定されているが、5step(n_warmup_steps)で枝刈りをどんどんしてしまうというものなので、これの影響で100イテレーションでも最初の10回程度でパラメータ探索を終わらせてしまう。なので、Successive Halvingというハイパーパラメータ最適化を多腕バンデット問題の最適腕識別問題として考えられた手法を使う。やっていることとしては、複数個のパラメータの候補を途中まで学習して、その段階で設定した閾値より評価が悪いものの探索をやめて、良いパラメータに対して多くの学習時間を割り当てるというもの。
def bayesian_optimize_parameter(dataset):
objective = Objective(dataset)
study = optuna.create_study(
pruner=optuna.pruners.SuccessiveHalvingPruner(min_resource = 1, reduction_factor = 4, min_early_stopping_rate = 0)
#, direction='maximize')
)
study.optimize(objective, n_trials=NTRIAL)
return study.trials_dataframe(), study.best_params, study.best_value
Result
HistGradientBoostingTree
性能を見るために、下記コードを5回イテレートする
dataset = {'classifier': 'HistGradientBoostingClassifier', 'training': X, 'answer': y}
with timer('HistGradientBoostingClassifier'):
dataframe, params, value = bayesian_optimize_parameter(dataset)
dataframe.drop(['number', 'datetime_start', 'datetime_complete'], axis=1).sort_values(['value'], ascending=True)[:20]
print(f'[params]: \n{params}')
print(f'[value]: {value}')
LightGBM
性能を見るために、下記コードを5回イテレートする
dataset = {'classifier': 'LightGBM', 'training': X, 'answer': y}
with timer('LightGBM'):
dataframe, params, value = bayesian_optimize_parameter(dataset)
dataframe.drop(['number', 'datetime_start', 'datetime_complete'], axis=1).sort_values(['value'], ascending=True)[:20]
print(f'[params]: \n{params}')
print(f'[value]: {value}')
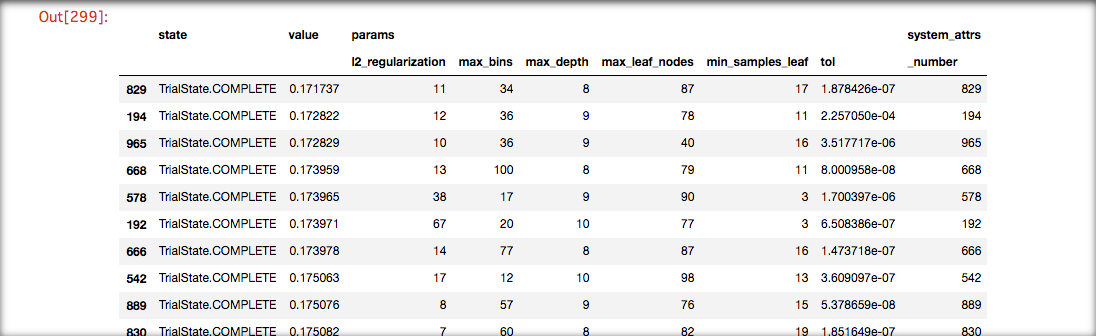
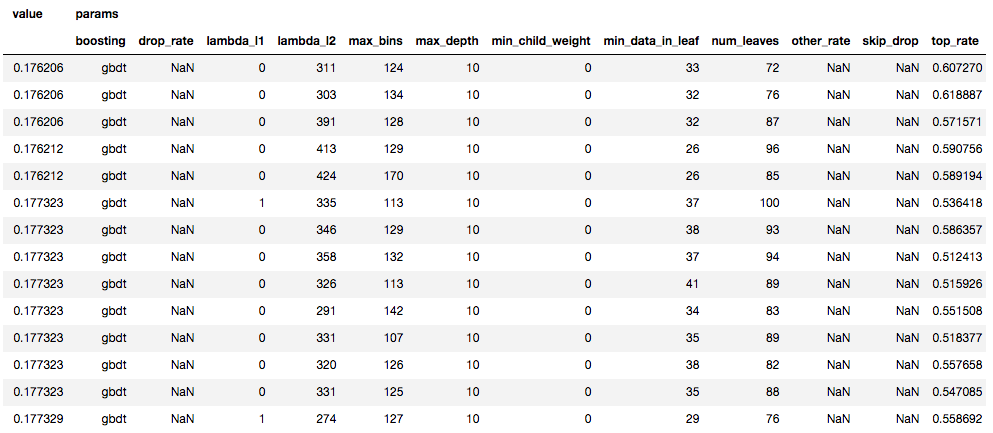
ハイパーパラメータ探索結果
2モデルをOptunaで各5回イテレートした場合の上位10件たちのパラメータと値
HistGradientBoostingTree
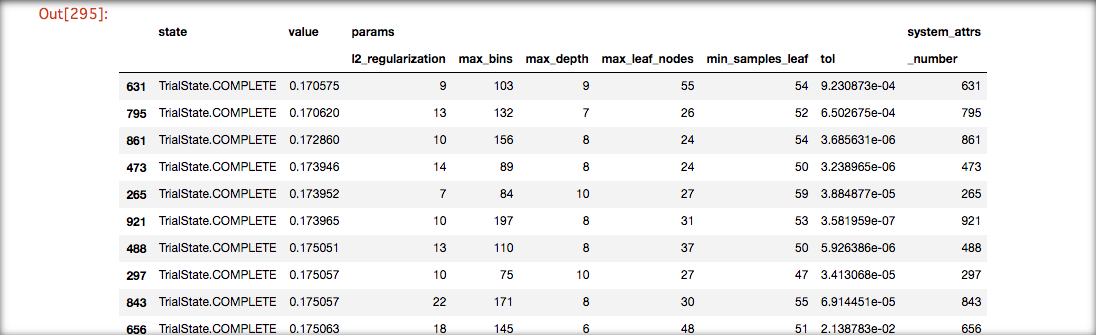
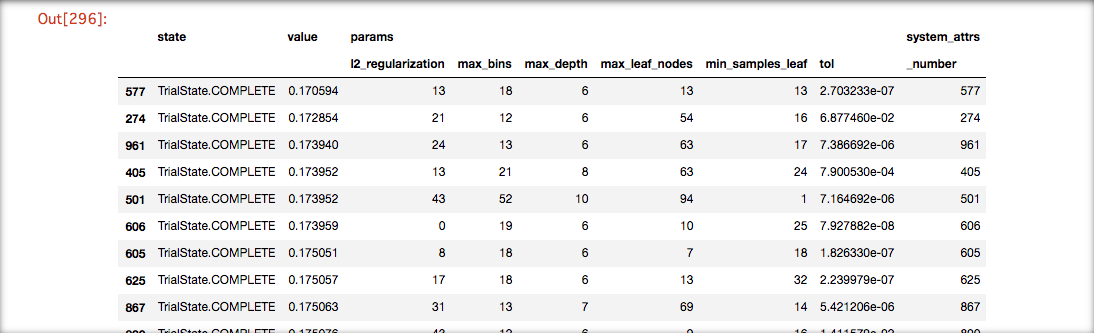
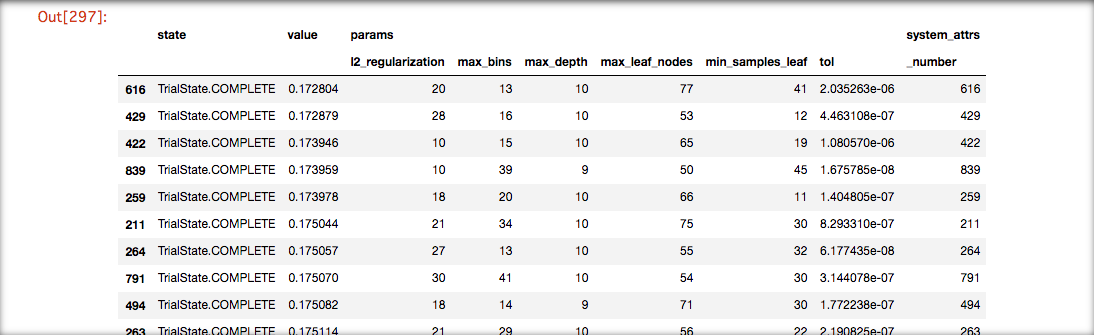
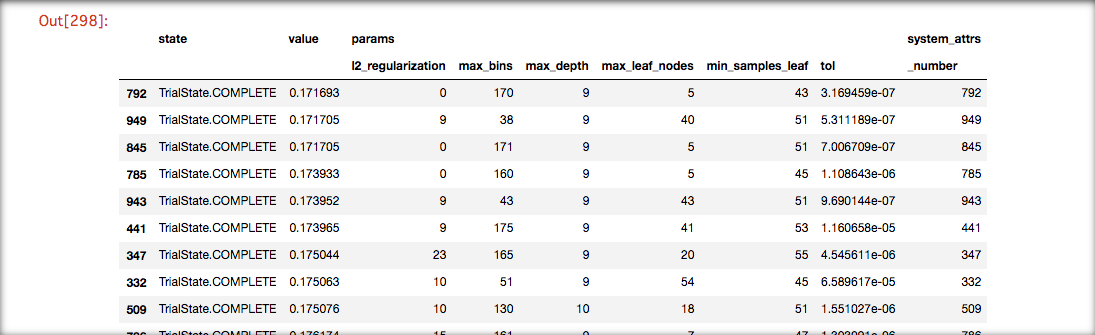
LightGBM
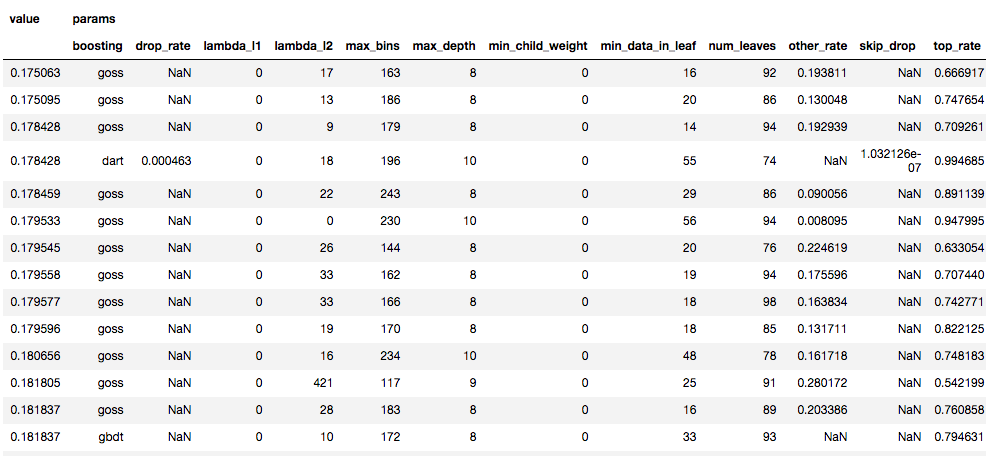
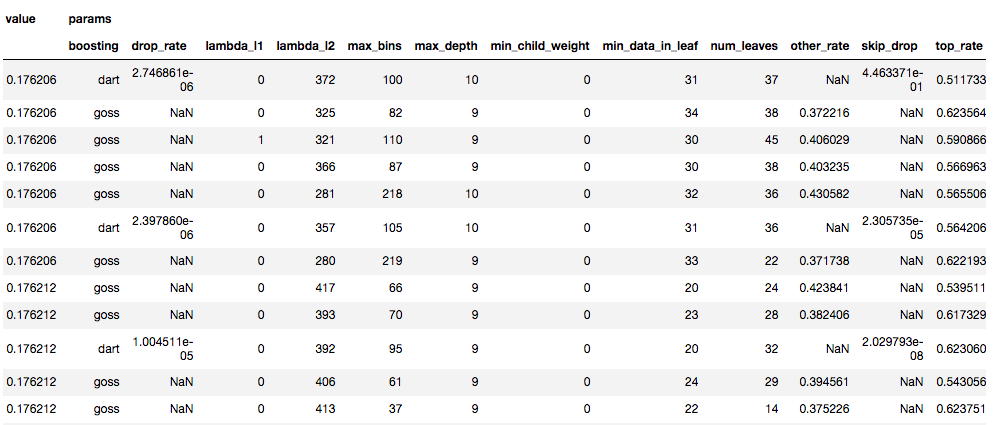
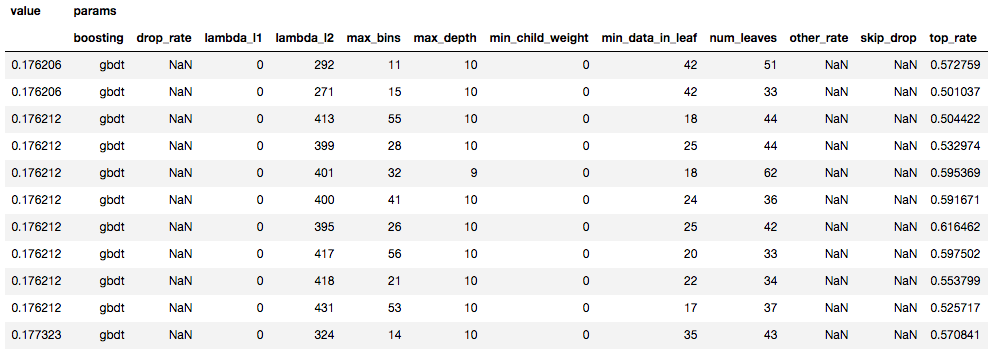
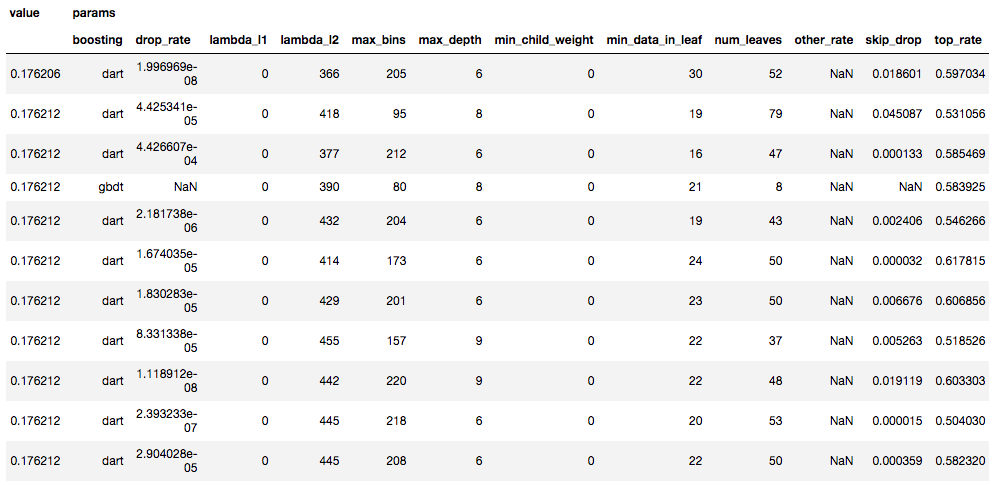
精度と速度
5回の交差検証と、1000回のoptunaでのパラメータ探索、それらを5セットずつ行い、最高精度と最良パラメータを抽出した
| 精度 | モデル1 | モデル2 | モデル3 | モデル4 | モデル5 | 平均 | 最良 | 最低 |
|---|---|---|---|---|---|---|---|---|
| HGB | 0.82942 | 0.82940 | 0.82719 | 0.82830 | 0.82826 | 0.82851 | 0.82942 | 0.82719 |
| LGBM | 0.823794 | 0.824937 | 0.823794 | 0.823794 | 0.823794 | 0.82402 | 0.824937 | 0.823794 |
pd.Series(dataframe['datetime_complete'] - dataframe['datetime_start']).sum()
| 学習時間 | モデル1 | モデル2 | モデル3 | モデル4 | モデル5 | 平均 | 最良 | 最低 |
|---|---|---|---|---|---|---|---|---|
| HGB | 00:13:34 | 00:14:41 | 00:14:54 | 00:13:49 | 00:18:34 | 00:15:11 | 00:13:34 | 00:18:34 |
| LGBM | 00:06:62 | 00:11 | 00:11:39 | 00:10:53 | 00:11:42 | 00:09:19 | 00:06:62 | 00:11:42 |
精度は、若干HGBの方が高い値を出しているが誤差の範囲内。平均、最良、最悪の精度ともにHGBに一応軍配があがる。
速度は、大分LGBMの方が高い値を出している。平均、最速、最遅の速度ともにLGBMに軍配があがる
パラメータ
精度向上
learning_rate: 0.1(初期値0.1) 固定
max_iter: 100(初期値100) 固定
max_leaf_nodes: 50(初期値31)
min_samples_leaf: 35(初期値20)
過学習対策
max_bins: 30 or 100(初期値255)
tol: 0.000005421206(初期値1e-7=0.0000001)
l2_regularization: 0~40(初期値0)
全体: 上位パラメータはだいたい上のような形になっていて、初期値に割と近い値になっている。l2やtol、max_binsなど過学習対策のものに強めにパラメータがふってある。上記を使う場合は、今回は、learning_rateやmax_iterを固定にしたため、もしより高精度なモデルを作りたいと思った場合は、learning_rateをこれ以上低めに設定し、max_iterの回数を多めにすると良い
再学習
optunaで各々算出されたパラメータから、KaggleにSubmissionし、汎用性のあるモデルなのかどうかを検証する。
性能を見るために、下記コードを5回ずつイテレートする
HistGradientBoostingTree
params = {'tol': 0.0009230872993162462, 'max_leaf_nodes': 55, 'max_bins': 103, 'min_samples_leaf': 54, 'max_depth': 9, 'l2_regularization': 9}
prediction = HistGradientBoostingClassifier(**params).fit(X, y).predict(test)
PassengerId = pd.read_csv('test.csv')['PassengerId']
HistGradientBoostingSubmission = pd.DataFrame({
'PassengerId': PassengerId,
'Survived': prediction
})
HistGradientBoostingSubmission.to_csv('HistGradientBoosting.csv', index=False)
LightGBM
params = {'boosting': 'gbdt', 'num_leaves': 76, 'max_bins': 134, 'min_data_in_leaf': 32, 'top_rate': 0.6188874459282185, 'min_child_weight': 0, 'lambda_l1': 0, 'lambda_l2': 303, 'max_depth': 10}
prediction = lgbm.LGBMClassifier(**params).fit(X, y).predict(test)
PassengerId = pd.read_csv('test.csv')['PassengerId']
LightGBMSubmission = pd.DataFrame({
'PassengerId': PassengerId,
'Survived': prediction
})
LightGBMSubmission.to_csv('LightGBM.csv', index=False)
Kaggleの本番テストデータで検証
| モデル1 | モデル2 | モデル3 | モデル4 | モデル5 | 平均 | 最良 | 最低 | |
|---|---|---|---|---|---|---|---|---|
| HGB | 0.73684 | 0.76076 | 0.75119 | 0.76555 | 0.74641 | 0.75215 | 0.76555 | 0.73684 |
| LGBM | 0.77033 | 0.77033 | 0.77033 | 0.76076 | 0.76076 | 0.76650 | 0.77033 | 0.76076 |
HGB、LGBMともにOptuna検証時から5~6%ほど正解率が落ちている。若干LSTMのほうが良い精度を出している。有意差はあまり感じられない。
discussion
- Scikit-learnの決定木(Decision Tree)などとパラメータが似ているので触りやすい
- 最低限のパラメータで作られている、feature_importanceでの可視化や、callbackでroundごとの学習率が見れないのは不便
- 今回のデータに対しては、Early Stoppingが正しくないと思ったのでしなかったが、LightGBMと比較すると少し遅い
- 本来LightGBM系譜の純正sklearnということで精度そこそこ速度高速というのでGBT系のベンチマーク(optunaで回してデータに適合する共通のパラメタ探索用)として使えるかも!と思って触ったため、optunaで検証してみたがそんなことはない
- 他のGBT系のXGBoostやCatBoostと比較検証するのも良さそう
- 大規模なデータセット(n_samples >= 10,000)に対しての精度と速度の検証をする必要性がありFeature Workとする
- モデル作成時間に関しては、どちらもHGBもLGBMもデータセットが軽く1秒以内に作成できたため非掲載
Referances
sklearn.ensemble.HistGradientBoostingClassifier¶
LightGBM’s documentation¶