Part 01
Introduction
There are many data set for classification tasks. I think the Titanic data set on Kaggle is a great data set for the machine learning beginners.
Titanic wreck is one of the most famous shipwrecks in history. Titanic sank after crashing into an iceberg. There was a 2,224 total number of people inside the ship. Unfortunately, 1502 people died due to a lack of lifeboats. People need to have some luck to escape from that kind of tragic situation. But if we analyze the data bit deeply, we can recognize some group of people was more likely to survive than others.
First of all, we need to import several Python libraries such as numpy, pandas, sklearn, seaborn, etc.
import numpy as np
import pandas as pd
import pandas_profiling
from pprint import pprint
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, VotingClassifier
from sklearn.ensemble import AdaBoostClassifier, BaggingClassifier, ExtraTreesClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, log_loss
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score, StratifiedKFold, learning_curve
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn.tree import DecisionTreeClassifier
I'm using pandas_profiling to get a quick insight into the data. If you guys don't have pandas_profiling, you may need to install it using pip
Explorer the data
I loaded my datasets to pandas data frames.
train_data = pd.read_csv('./data/titanic_train.csv')
test_data = pd.read_csv('./data/titanic_test.csv')
train_data.head()

The next step is to inspect the dataset we have got. There are a few ways to get an initial look at the data. Here I use pandas_profiling. We can effortlessly get an overview of our variables, including missing values.
pandas_profiling.ProfileReport(train_data)

Here we have 12 variables, including our target which named Survived. So we have 11 features to use for the model. Some of those features can be very important and some of the features can be not much useful.
The following table will give us an explanation of our features.

We can see that there are 5 categorical features in our dataset.
1. Cabin
2. Embarked
3. Sex
4. Pclass
5. Survived
and also there are Numeric features,
1. PassengerId
2. SibSp
3. Parch
4. Age
5. Fare
and text variables.
- Ticket
- Name
We can further divide categorical features into Nominal and Ordinal.
- Nominal: Unordered categories that are mutually exclusive.
Ex: Sex (male, female) - Ordinal: Ordered categories that are mutually exclusive.
Ex: Pclass (1 = 1st, 2 = 2nd, 3 = 3rd)
This dataset is not much messy, but when you are dealing with NLP, messy data can be a tremendous headache. As we have a kind of idea about our data, next we should inspect the missing data.
Dealing with missing values
I created a simple function to get missing values os the features in our dataset.
def get_missing_values(df):
values = df.isnull().sum().sort_values()
data = pd.DataFrame(values, columns=['Total missing values'])
data = data[data.values.sum(axis=1) > 0]
return data
get_missing_values(train_data)
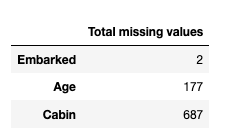
get_missing_values(test_data)

We can see that both our training and testing dataset have some amount of missing values. First, we need to think about a good strategy to fill those missing values. for example, we can take the mean and fill those values. Or we can think about a better way to fill those than the mean values.
From here, There are two ways to fill the elements.
- Consider the data set separately.
- Combine data set and deal with once.
Here, I selected the second method.
combined_df = train_data.append(test_data, ignore_index=True, sort=True)
get_missing_values(combined_df)
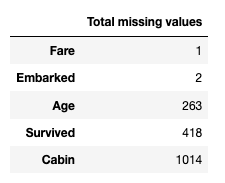
OK, now we can see all the missing values we have on our dataset. Let's begin with the Embarked.
Embarked Feature
def values(df, feature_name):
return pd.DataFrame(df[feature_name].value_counts(dropna=False))
values(combined_df, 'Embarked')

We can see that two missing values in the Embarked feature. Since its just two values, I am going to fill it based on the majority values. If there are significant values, we should come with a better strategy than the above method.
For example, There can be a relationship between Fare or passenger class.
Before filling those missing values, let's have look who is missing the Embarked feature.
combined_df[combined_df['Embarked'].isnull()]

Oh, it is very similar, they both survived, belong to ticket class 1, both are females, and ticket fare is the same. Since they share with the same ticket number, they should have some relationship.
combined_df['Embarked'].fillna('S', inplace=True)
Great, we just finished dealing with one missing feature. Let's move to the next feature Fare.
Fare Feature
combined_df[combined_df['Fare'].isnull()]

We have only one missing value. So, it can fill with the mean value of the fare. If we have more missing values, we can use the following approach.
combined_df.groupby(['Embarked', 'Pclass', 'Sex'])['Fare'].mean()

Our missing Fare value person is a male and Embarked from S and belongs to the passenger ticket class 3. So mean are of this group is 13.14
combined_df['Fare'].fillna(13.14, inplace=True)
The article became too long. So, I will continue this in next post.
Next
Table of contents
- Kaggle Titanic data set - Top 2% guide (Part 01)
- Kaggle Titanic data set - Top 2% guide (Part 02)
- Kaggle Titanic data set - Top 2% guide (Part 03)
- Kaggle Titanic data set - Top 2% guide (Part 04)
- Kaggle Titanic data set - Top 2% guide (Part 05)
*本記事は @qualitia_cdevの中の一人、@nuwanさんに作成していただきました。
*This article is written by @nuwan a member of @qualitia_cdev.