この記事は JSL (日本システム技研) Advent Calendar 2019 - Qiita , 12月11日の記事です。
(昨年のカレンダー)
新入社員の@qtatsunishiuraです。よろしくお願いします。
前書き
- learning_curveに関しての解説記事は多く存在しています。しかし、実際の(いわゆる"汚い")データを用いたモデルの学習を例とした記事は少ないと思っています。
- 筆者も初心者ではありますが、自分がデータを集めた際の記録を公開することで、他の入門者の方にとって少しでも参考になればと思い執筆致しました。
- 筆者も初心者ですので、誤りや間違った理解が含まれているかもしれません。お気づきになられたら、ご指摘いただけると幸いです。
- 本記事では実際のデータを用い、learning_curveで評価しながらfeatureの考察や選択、集めるべきデータ数の議論をしていきたいと思います。
learning_curveの基本的な使い方
-
overfitting/underfittingの概念の解説については解説記事が多数存在するのでここでは述べません。以下の記事などを参考にしてください。
-
scikit-learnを用いたlearning curveの書き方の公式ドキュメントです。ここから抜粋して簡単に説明します。
余談: varidation curve
- scikit-learn公式ドキュメント
- 最適なRegularization parameterを求める為に書く。しかし、scikit-learnではGridSearchが用意されているので、こちらを利用することでパラメータを決めることができる。そのためvaridation curve自体を書くことは特に無いと思う(間違ってたらご指摘お願いします)。またパラメータのチューニング自体、データの質やfeatureの選択に比べると重要度は下がる(と思う...)。
問題: twitterで絵師がアップする画像を、「イラスト」と「写真」で分類したい
twitterとイラスト
- twitter はSNSの一種で、ツイートと呼ばれる投稿をすることで交流できます。フォロー機能があり、自分が興味を持った人物のツイートを見ることができます。
- twitterにおいてイラスト投稿を行なっているいる人は多く、一種のコミュニティを形成しています。pixiv(ピクシブ)などのイラスト投稿サイトと比較するとイラスト投稿のハードルが低い傾向があり、途中経過をアップする人も多いです。またハッシュタグを用いて、特定の題に沿った絵を投稿するような文化も存在しています。(例:わんどろ(
#深夜の真剣お絵かき60分一本勝負) -> @1draw_nightなど) - その為、twitterでしか見ることのできないイラストが存在します。
イラスト投稿におけるtwitterの問題点
- twitterは個人プロフィールの"メディア"という項目から、アップロードされた画像だけを見ることができます。
- しかし、相当数の絵師がイラスト以外にも、夕食のカツ丼やラーメン、もしくは家で飼っているインコや猫の画像を大量にアップロードしている為に、肝心のイラストが他の画像に埋もれてしまうという問題点があります。
- twitterはタグづけ機能が弱いです。モーメントという機能が存在し、イラストのみまとめることができますが、この機能でイラストをまとめるくらいマメな人はそもそもpixivに「twitterまとめ」と題した投稿を行います。
- 以上から、特定のユーザが投稿している画像一覧から、イラストのみを抽出する機能を作成すればtwitterライフがはかどると考えました。
文脈の設定
- 「あらゆる写真とイラストを区別する」ことを実現するのは、本問題(絵師の投稿したイラストを、ラーメンとインコの中から抽出)にとってはやりすぎなので諦めます。
- twitterで絵師が投稿する写真やイラストには傾向があります。ラーメンやインコがアップされることはあっても、サバンナの画像がアップされることは希だと思います。
- そこで、画像の収集自体をtwitterから行い、自分でラベルをつけて学習させることにしました。
- 言い換えると、「twitterにおいて絵師がアップする画像」以外は分類できなくてもよしとします。
小規模実験で方向性を決める
1. 少しだけデータを集める
- いきなり大量にデータを集めたりラベルを振ると、作業が無駄になってしまう可能性があります。そこで、小規模にデータを集めて実験することにしました。
- まずは画像を50件ほどtwitterから集めます。控えたurlから、(100×100)の要素からなる画像を生成しました。
- 結果として得られた画像データは、ある一枚の画像について
- 白黒画像にした(理由は、人間が白黒でもイラストと写真を見分けられるからという安直なもの)
- 100×100 = 10000個のドットからなるイラストのような状態。(下図参照)。
- それぞれの要素は0 ~ 255の間の値である。-> 白黒画像の濃淡です。
- ⬇︎がデータを表示した際のイメージです。ちなみにこの解像度は適当に決めました(とくに決めるための指標を持っていなかったため)。
# 100×100 のドットからなる画像を表示する
>>> data
array([[128, 255, 255, ..., 255, 255, 255]], dtype=uint8)
>>> plt.imshow(data.reshape((100,100)), cmap='gray')
>>> plt.show()
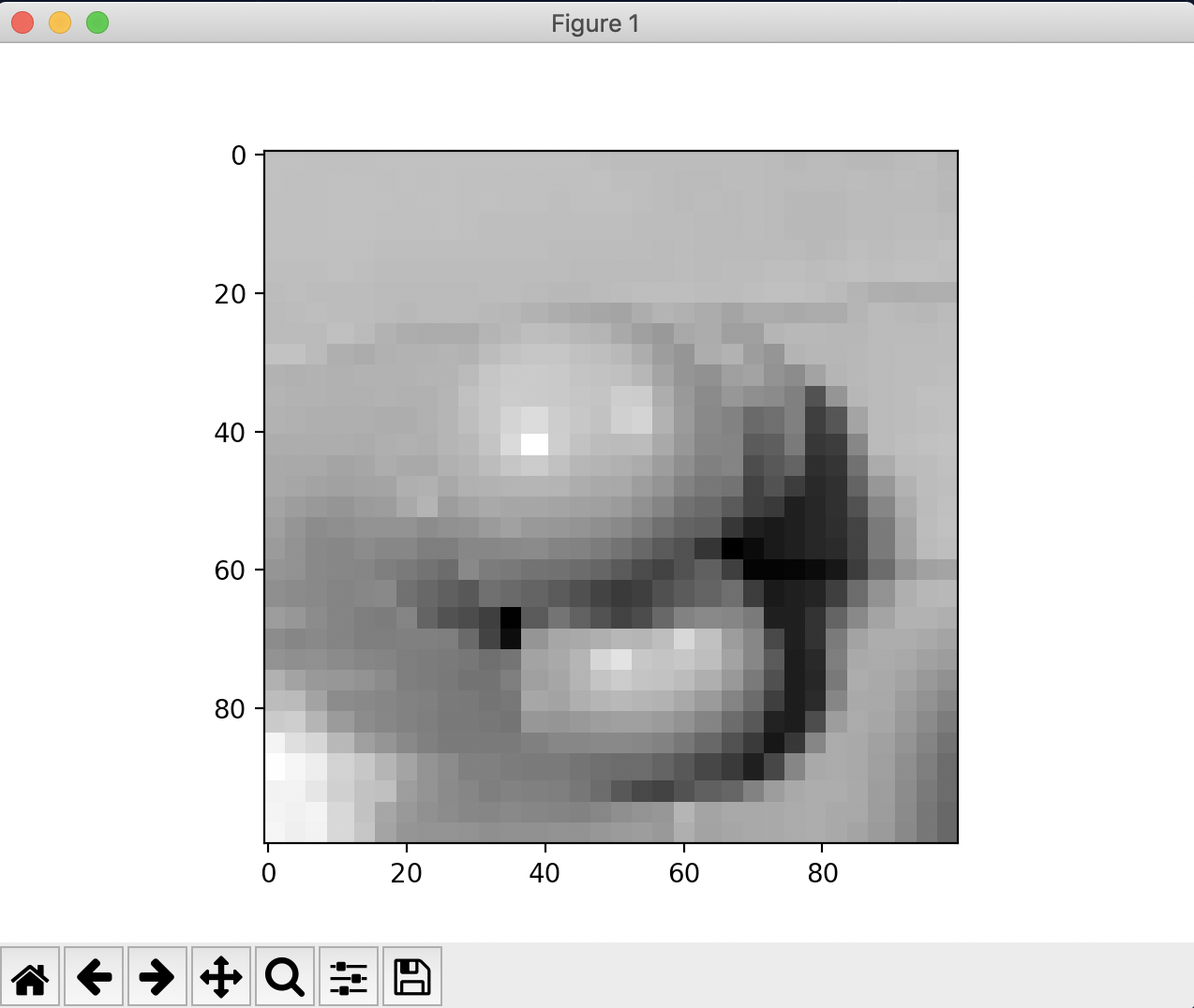
- 画像は僕の持っているジャグリングボール(写真)です。
2. 失敗してみる
- まずは失敗してみます
- これは前職(?)の考え方です。初回に一通り手を動かして失敗することで、そのトラブルシューティングという形で方向性を決めるという方法論(というほどのものでも無い...)です。
- まずは得られた10000個のドットをそのままfeatureとして学習させてみます。(うまくいくはずがありませんが...)
- この際、学習に伴うスコアの上昇をみる為にlearnig_curveを使います。
# svm.SVCを使ってみますが、これも大した理由はありません。
>>> train_sizes, train_scores, test_scores = learning_curve(estimator=svm.SVC(kernel='rbf'), X=X, y=y)
# データをn通りに区切って(defaultは3)それぞれに対してスコアを出してくれます。今回は平均だけ使います。
>>> train_scores_mean = np.mean(train_scores, axis=1)
>>> test_scores_mean = np.mean(test_scores, axis=1)
# 画
>>> plt.figure()
>>> plt.grid()
>>> plt.plot(train_sizes, train_scores_mean, 'r-')
>>> plt.plot(train_sizes, test_scores_mean, 'b--')

- 縦軸はaccuracyで、高いほど正解していると考えてください。
- 当然ですが、overfittingとなりました。コードを見てもらうとわかりますが、赤色がtrainingのスコアで、青色がtestのスコアです。
- 赤色のtrainingのデータは完璧にあっている一方、スコアが実際に上がって欲しい青色のtestスコアは全く上がる気配がありません。
ここまでの失敗からわかることと改善, 得られたもの
- overfittingなので、featureの数がサンプルに対してあまりに多すぎるということがまず言えます。
- (当たり前ですが)100x100要素をそのままfeatureとして使うのは無謀でした。classifierを変更する検討は、する必要も無いと思います。
- 平均など、全要素の情報を代表するようなfeatureを使ってみることにします。
- 以下のようにして、平均と分散を利用することにしました。featureはこの2つだけ、となります。
>>> X_mean = np.mean(X, axis=1)
>>> X_variance = np.var(X, axis=1)
>>> X_mean = X_mean.reshape((50, 1))
>>> X_variance = X_variance.reshape((50,1))
>>> X_mean_var = np.concatenate((X_mean, X_variance), axis=1)
- 先ほどと同様にlearning_curveを描くと、以下のようになりました。
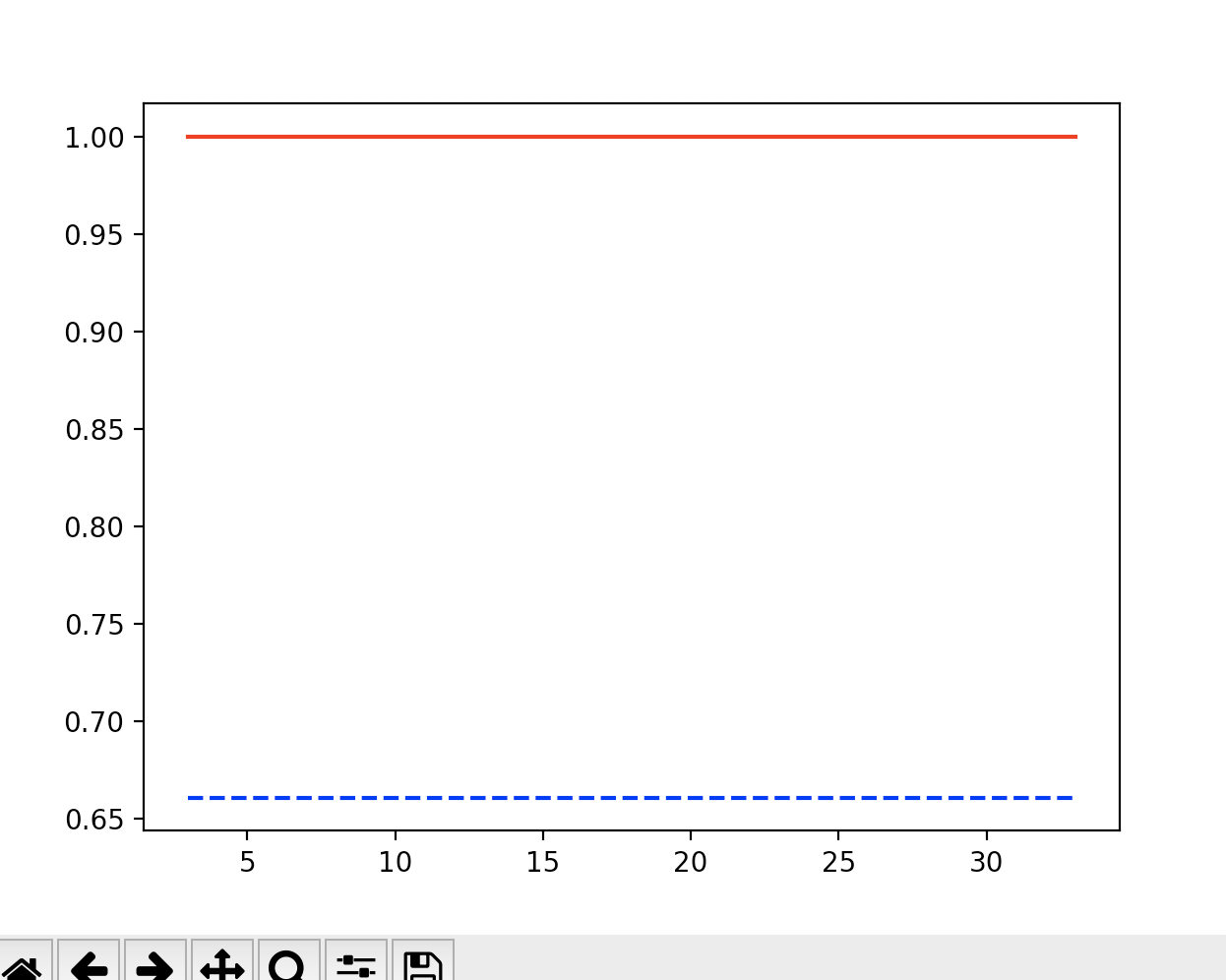
- ご覧の通り、全くダメです。
改善: scaling
- 平均と分散を使うというアイディアはそこまで悪くなかったように思います。featureを減らしていますが、画像のドットの濃さという情報は残しています。しかし全く改善しません。
- ここで一つ、scalingの問題が考えられます。svmを利用している(kernel='rbf')いますし、この方法では平均と比べて分散が非常に大きな値になってしまいます。こちらを解決してみます。
- scikit-learnには
StandardScalerというクラスがあり、標準正規分布(平均が0, 分散が1)になるよう特徴量を割返してくれます(手動でもできますが)。そちらを試してみましょう。- 注意: testサンプルを評価する際には、trainingデータだけでscaler.fit()を行うようにしてください。testを含んでscalerをセットすると本来より高いスコアが出てしまいます(未知のデータに対してfitしたことになってしまう)
# (100x100の白黒ドット)平均, 分散です。
>>> X_mean_var
array([[ 215.6588 , 6625.93098256],
[ 123.0937 , 6075.77512031],
[ 94.9236 , 4254.99676304],
[ 182.425 , 3538.924375 ],............
>>> from sklearn.preprocessing import StandardScaler
>>> scaler = StandardScaler()
>>> scaler.fit(X_mean_var)
>>> X_mean_var_scaling = scaler.transform(X_mean_var)
>>> X_mean_var_scaling
array([[ 1.19576016, 0.70434395],
[-0.98625618, 0.50540125],
[-1.65030362, -0.15301319],
[ 0.41234725, -0.41195322],..............
- こちらを使って描いたlearnig_curveは以下のようになりました。

- 同じく赤色がtrainingスコアで、青色点線がtestスコアです。どうやら改善の兆しが見えたようです。
- trainingスコアも最初の方が少し低すぎる気がしますが、こういうものなのでしょうか...(?)
3. 方向性を考えてみる
これまでにわかったこと
- これまでの実験は、50サンプルほどの少ないデータを用いて行ってきましたが、それでも色々なことを知ることができました。
- URLから画像取得~変換のコード
- 解説からは省いていますが、そもそも画像をデータに変換するためのscriptをここで得ています。PILやrequestsライブラリを使う練習になりました。
- 画像のドットについて、平均や分散をとった値がfeatureとして使える可能性が高い
- たとえば線を抽出するなどの、高度な処理が必要な可能性もありましたが、単純な濃度の分布だけでもtwitterのイラストと写真を区別することができる可能性を示唆していると思います。
- scalingが重要
- svm(kernel='rbf')は使えそう
- 画像50件は一つの単位として考えられるスケールである(50件内の学習で多少なりとも進捗がみられる)
- URLから画像取得~変換のコード
この次にやるべきことは?
- 3つ考えられました。
- データを増やす
- 現状、スコアが上昇しているのでこのままデータを増やして行けばうまくいきそうです。
- 原点に立ち返り、集めるデータを検討する
- featureをさらに増やす
- 平均, 分散以外にも、四分位数(中央値が上から数えて50%とすると、75%や25%の値のこと。)も簡単に算出できますし、これまでの経緯を考えると有効に思えました。
- データを増やす
-
このうち、最も大変なのは1です。twitterから画像を集めなければなりませんし、それに対してラベル(写真なら1, イラストなら0を振る)を振るのはかなり面倒です。
- 仮に、1000件ほど集めたところでスコアの伸びが著しく悪くなり、「画像収集アプリ作成」が必要となったときその1000件を手動で集めたことは無駄になってしまいます。集める件数を見積もれないうちにはやりたく無いです。
- また、この平均と分散をfeatureにした評価方法は、どう考えてもイラストや写真の種類にかなり依存すると予想されます。つまり、後半に行くほどスコア改善の伸びは期待できなくなると思います。
- よって1は保留しました。
-
2は今の時点では、根拠のある方法を思いつきません。
-
3は簡単にできます。やってみました。
>>> qs = np.percentile(X, [75, 50, 25], axis=1)
- learnig_curveは以下のようになりました。赤色がtraining, 青色がtestです。
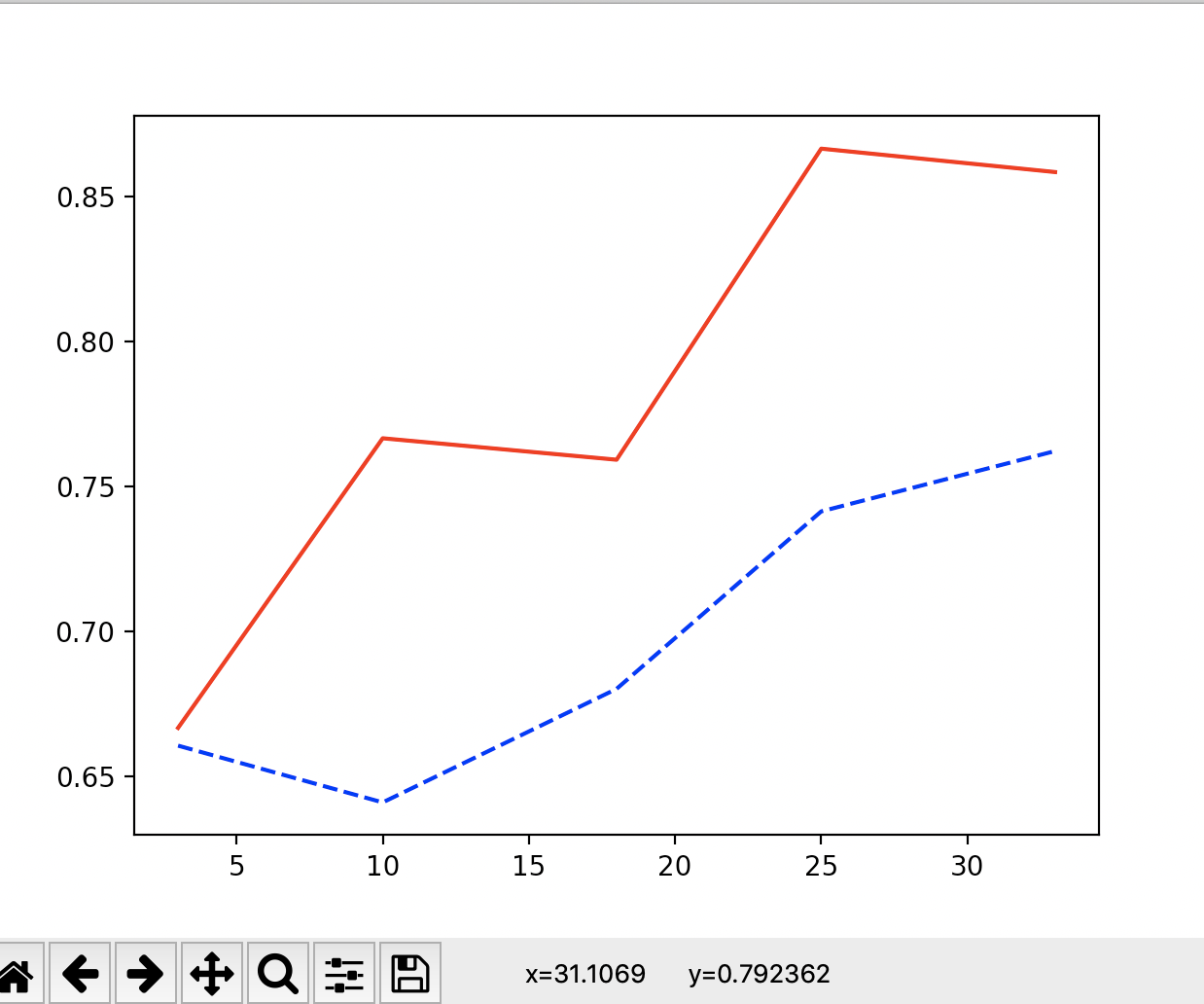
- 大して改善しませんでした。分散に含まれる情報と大差ないのでしょうか。
色の情報を利用する
-
このままデータを集めてもよかったのですが、上述の通り不安がありました。改善できる点は今のうちに改善し、データを集めるのは最後に回したいです。
-
そこで、カラーで情報を取得することにしました。白黒ではなく、RGBを区別して取得します。
- 根拠として、平均と分散が割と分類に役立つfeatureだとわかったことが挙げられます。単純に、RGBを区別することでそれぞれの平均値と分散を出すことができ、featureを増やすことができます。
- また、視覚的にも100×100の白黒画像では、写真とイラストが判別できないものが多かったことも挙げられました。カラーだと、この解像度でもほとんど写真とイラストを区別可能です。人間が区別できるものは機械学習でも区別できるらしいので(courseraで聞いた)、RGBで画像を取得します。
- 平均と分散はRGBそれぞれで計算し、別のfeatureとして使います。それ以外の処理は同じです。
-
以下がlearning_curveの様子です。利用している画像データは先程までと同じものです。(カラーで取得しただけ.)

- testスコアの伸びがかなり改善していると思います。**testスコア(青色)**が、初めて8割を超えました。
- このことから、カラー画像のRGBそれぞれの平均, 分散を利用することは、白黒と同じデータを用いていてもtestスコアの改善につながっているのではないかと考えました。
4. データを集める
- データは50件程度しかありませんが、最後に示したlearning_curveはtestスコアが8割を超えただけでなく、まだまだ伸びそうに見えます。
- ここから先はデータを増やしてみても良いと判断しました。
その後
-
(一応)完成したのがこちらです: このユーザの画像は分類できなかったとか、フィードバックもらえるとうれしいです。
- 漫画やアニメ的なハッキリした絵柄のイラストと、日常の風景(食べ物やペット)はそこそこ分類されると思います。Fスコアは0.9程度ありました。
- 反面、厚塗りのイラストはtwitterから集めたサンプルが少なく、6割り程度しか分類できない印象です。
- また、人物の自撮りを加工したものも若干分類が苦手です。
- そもそも、僕のフォローしているユーザーリストから画像を集めているため、そこに存在していないタイプの画像は分類しづらいということに由来しています。
- その他やった検討: データ収集のほか、パラメータのチューニングはGridSearchを利用して行いました。precision_recall_fscore_supportでスコアの判定をしながら、他の学習モデルも試すなどしました。
5. まとめ
- これから機械学習を勉強される方へ: 機械学習のことをあまり知らなくても、とりあえずlearning curveを書くことで問題点を一つ一つ見つけていき、改善していくことでそれっぽいものを作ることができる....ということが伝われば幸いです。進んでいる方向が正しいのかをlearning curveは教えてくれると思います。
- 機械学習できる方へ: 「そのやりかたはまずい」など、教えていただけると幸いです。
- これからまた頑張りたいと思います(何ヶ月もサボっていて、numpyの操作すらおぼつかなくなっていた)