この記事について
ディープラーニングモデルをエッジデバイスで推論する際に用いられるモデル圧縮技術の概要についてまとめます。
背景
モデル圧縮の必要性について
DNNの学習効率化やエッジシステムへの適用のために、精度を維持したまま高速化できる手法確立の重要性が増加
-
学習の効率化
- 学習時間の短縮
- 学習済みモデルの配布
- 分散学習時のモデル分配
-
エッジシステムへの適用
- 記憶容量の削減
- メモリ削減
- 演算量削減
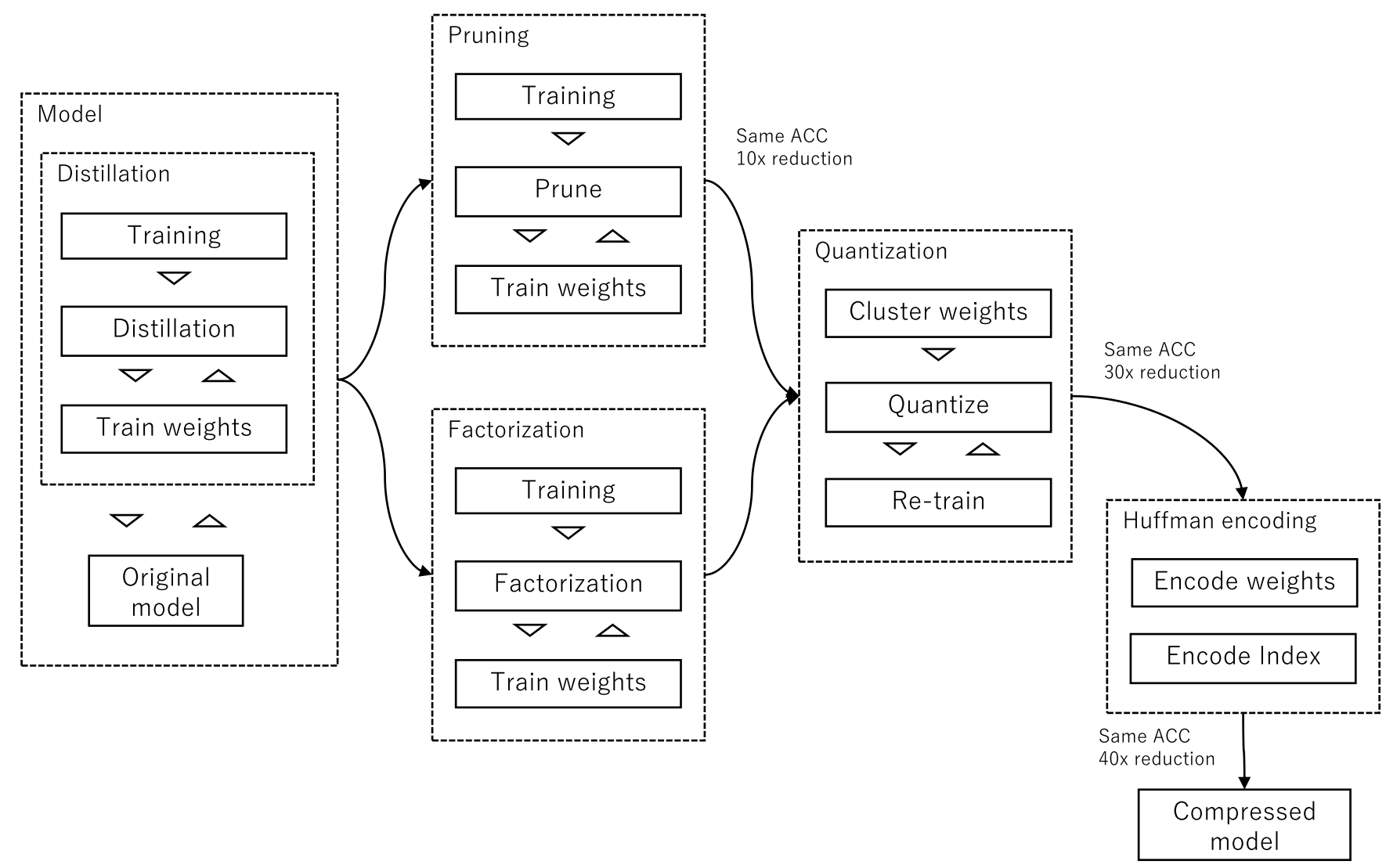
圧縮手法にはトレンドがあり、大きくPruning/Sharing, Factorization, Compact convolutional filters, distillationの4つに分類可能
-
Parameter pruning / sharing
- 影響度の小さいパラメータの削除 / パラメータの共有
-
Low-rank factorization
- 行列、テンソルの分解(CP分解,Trucker分解)によるパラメータ削減
- CPU/GPUで容易に実装可能(FC層はFWの変更も不要)
-
Transferred/compact convolutional filters
- 畳み込み層のフィルタを小さなカーネルに置換
-
Knowledge distillation
- 蒸留(distillation)を利用して小さなモデルに再学習
- FC層、Conv層の両方に適用可能(モデルに依存しない)
-
Other
- Conv層演算のFFT/IFFT化
- Winogradアルゴリズムの適用(neon, cuDNN等で利用)
- Early termination
各手法は混合して利用可能
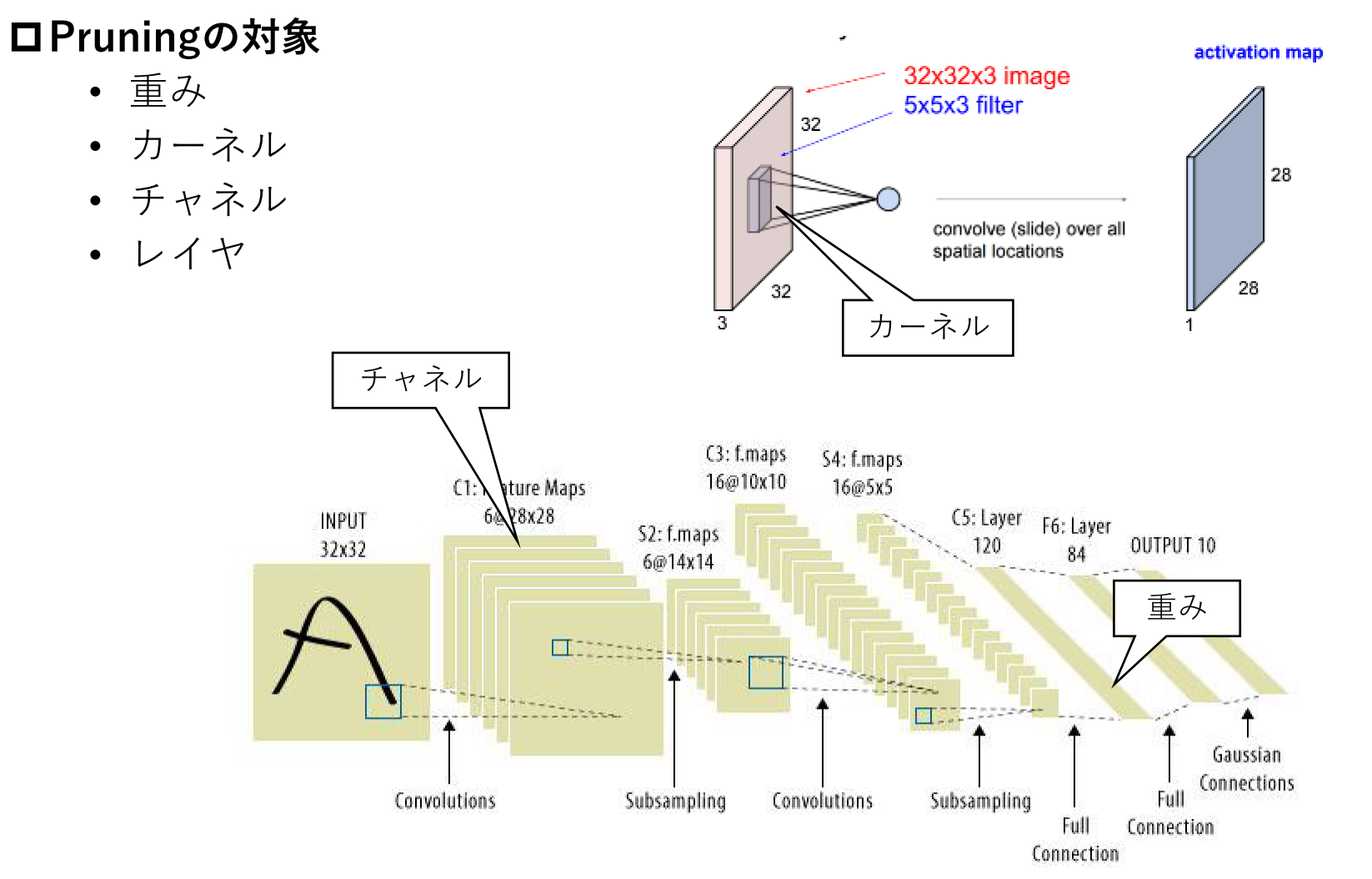
Parameter pruning / sharing
基本アイデア
訓練の結果、閾値以下となった重みを0として扱いFine-tuningを繰り返す
Pruning(枝刈り)は重み係数、カーネル、チャネル、レイヤ構造が対象。
代表的な手法
影響の少ないパラメータの消去や、パラメータ表現方法の工夫により削減するアプローチが多数提案されている
適用の際は、CPU/GPU、機械学習FWの対応状況の考慮が必要。
| 手法 | 概要 | 提案 | タイプ | メモリ | 演算 | 実装 | 備考 |
|---|---|---|---|---|---|---|---|
| Deep Compression | 絶対値が閾値以下の重みを削除 | 2015 | sparse | 削減 | 低減 | ○ | |
| Pruning Filters | L1ノルムが小さなフィルタを削除 | 2017 | sparse | 削減 | 低減 | ||
| Channel Pruning | Feature mapの復元の寄与率が低いチャネルを削除 | 2017 | sparse | 削減 | 低減 | ||
| Variational Dropout | Bayesian Dropoutのドロップ率を最大化 | 2017 | sparse | 削減 | 低減 | ||
| weight sharing | 係数共通化による情報削減 | 2015 | sparse | 削減 (可逆) | 低減 | × (GPU未対応) | |
| sparse matrix | タプル表現による行列の情報削減 | 2015 | sparse | 削減 (可逆) | 低減 | × (GPU未対応) | |
| Adaptive Fastfood transform | 全結合層の再パラメータ化 | 2015 | structural matrix | 削減 | 低減 | ○ | |
| float16, int8 | 量子化数低減による情報削減 | quantization | 削減 | 低減 | △ (FW未対応) | 推論時に単純置き換え可能 | |
| haffman coding | ハフマン符号化による情報削減 | 2015 | quantization | 削減 (可逆) | 低減 | × (CPU/GPU未対応) | |
| XNOR-Net | パラメータ、アクティベーションの演算を2値化 | binarized | 削減 | 低減 | FPGA(演算器削減) | ||
| Ternary weight Networks | パラメータを3値化しスケーリング係数 | binarized | 削減 | 低減 | FPGA(演算器削減) |
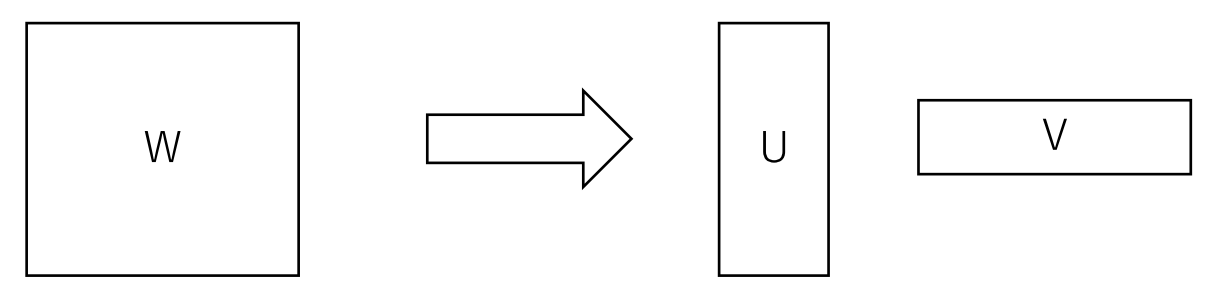
Factorization
基本アイデア
行列(テンソル)の低ランク性を仮定して近似することで計算量を削減
- Low Rank Matrix Factorization
- FC層を2つに分解して実現
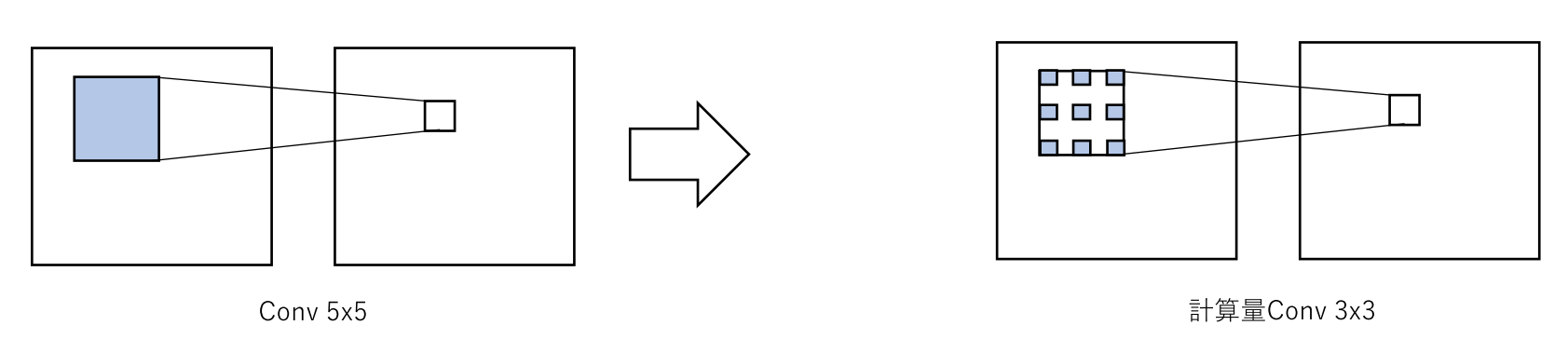
Transferred/compact convolutional filters
基本アイデア
CNNのConv層を圧縮
- 畳み込みカーネルのFactorization
- 理論上で計算量を9:6に圧縮
- エッジデバイスに畳み込み演算のアクセラレータがある場合、遅くなる可能性あり

Dilated Convolution
カーネルの重みに規則的な0を挿入して、パラメータ数、計算量を小さいカーネルと同じに保ったままカーネルサイズを拡張
- 例:Dilated = 2
- 小さいサイズで同等の受容野(receptive field)を維持
- Feature mapの解像度を高く保つ効果がある
Quantization
基本アイデア
量子化数低減は特に推論時の演算効率を重視。エンコーディング系は伸長のための演算コストが増加するため伝送時の利用などを想定。
| 手法 | 概要 | タイプ | メモリ削減 | 演算削減 | 実装容易性 | 備考 |
|---|---|---|---|---|---|---|
| FP16, INT8 | 量子化数低減による情報削減 | quantization | ✓ | ✓ | △ | 推論時に単純置換可 |
| haffman coding | ハフマン符号化による情報削減 | quantization | ✓ | × | CPU,GPU未対応 | |
| XNOR-Net | ハフマン符号化による情報削減 | binarized | ✓ | ✓ | 〇(FPGA) | 2015年提案 |
| Ternary weight Networks | パラメータを3値化しスケーリング係数化 | binarized | ✓ | ✓ | 〇(FPGA) |
Distillation (蒸留)
基本アイデア
アンサンブル学習器や巨大モデルを教師モデルとして、精度を保ちながら小さなモデル(生徒モデル)に再学習させる手法
- 教師モデルの出力を利用して生徒モデルを学習
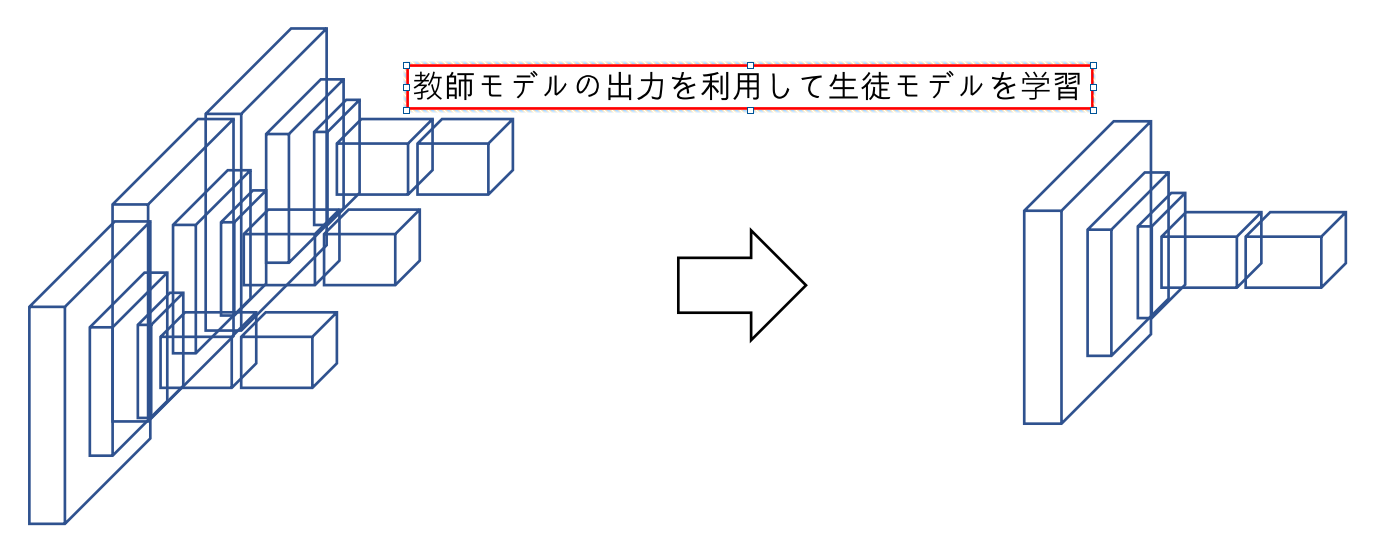
- モデル構成例
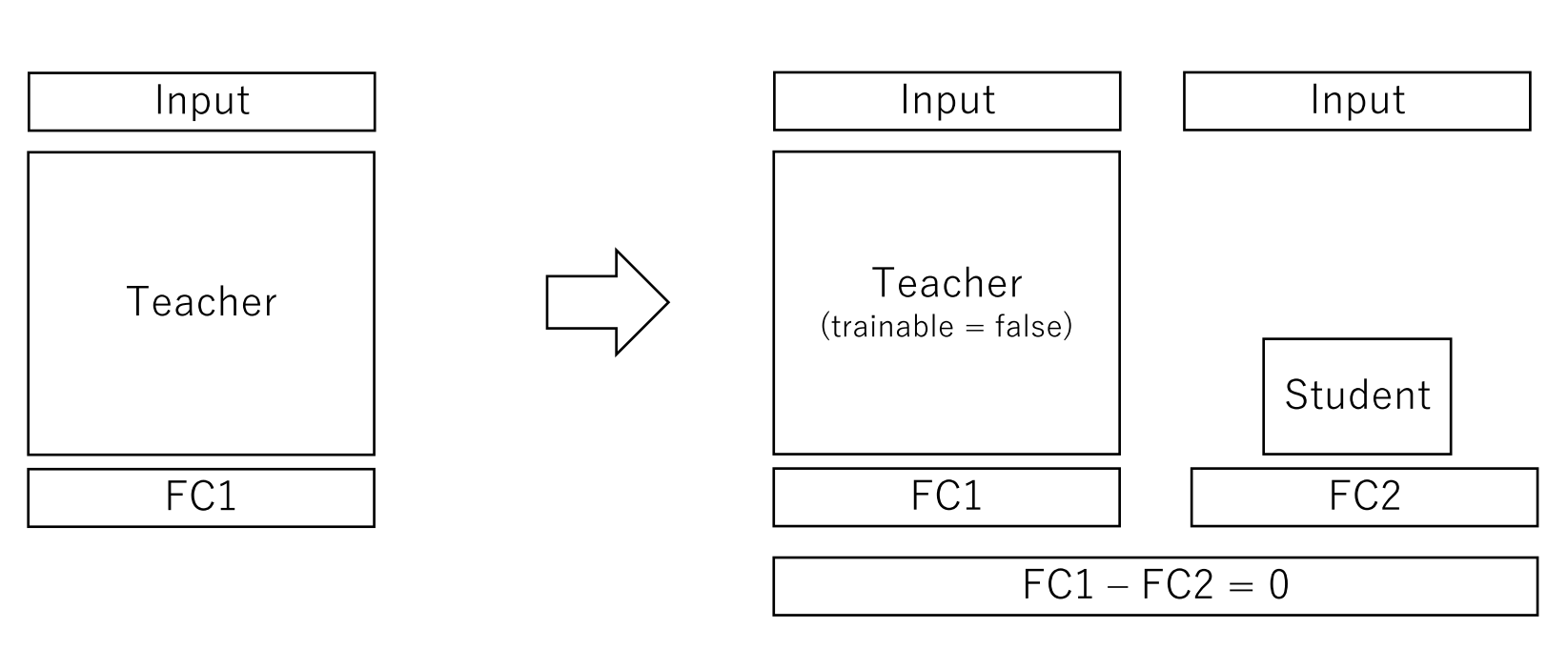
reference
A Survey of Model Compression and Acceleration for Deep Neural Networks (2017)