はじめに
皆さんはTHE IDOLM@STER SHINY COLORSを知っていますか?
知らない人はとにかくシャニマスをプレイしてほしい.コミュとカードが素晴らしい.
youtubeでもプレイ動画が見られるのでとにかく見てほしい.
というのはさておいて,オリジナルデータでトレーニングするなら自分の好きなコンテンツでやりたいよね,ということでシャニマスのキャラクターで画像認識を試してみた記録.
用語は正しいか自信がない.
環境
学習用PC
- windows10
- RTX2080Super
一部作業はmacで行ったため,スクリーンショットも一部macで撮影している.
使用するソフトはすべてpython製なため,OS関係なく利用が可能である.
トレーニングの前に
どうにかしてDarknetを導入してほしい.
ここでは具体的なインストール方法は説明しない.
いつもの画像が出せたら準備完了.

動いたのを確認したら準備完了!
画像の収集
画像を判定させるには,まず画像の準備をしなければならない.
クローラーの準備,インストール
一枚一枚ダウンロードするのは非常に大変なため,今回はicrawlerというツールを使用する.
このツールは画像検索結果を自動的にダウンロードしてくれるので簡単に画像の準備ができる.
pythonはdarknetを入れている時点で入っているはずなので
pip install icrawler
でインストールが可能.
実行
画像収集のためにコードを書く.
シャニマスのアイドルを集めるために以下のようにする.
立ち絵が少ない印象だったので「キャラ名 コミュ」等も追加するといいかもしれない.
from icrawler.builtin import GoogleImageCrawler
google_crawler = GoogleImageCrawler(
feeder_threads = 1,
parser_threads = 2,
downloader_threads = 4,
storage = {'root_dir': 'shiny'}
)
filters = dict(
size = 'large'
)
words = ["アイドルマスターシャイニーカラーズ","シャニマス","櫻木真乃","風野灯織","八宮めぐる",
"月岡恋鐘","田中摩美々","三峰結華","白瀬咲耶", "幽谷霧子","大崎甜花","大崎甘奈","桑山千雪",
"小宮果穂","西城樹里","杜野凛世","園田智代子","有栖川夏葉","芹沢あさひ","和泉愛依", "黛冬優子",
"L’Antica","illumination STARS","ALSTROEMERIA シャニマス","Straylight","放課後クライマックスガールズ"]
max_num = 100 # 画像収集数 googleでは100が限界
# 浅倉透", "市川雛菜","樋口円香","福丸小糸", "ノクチル シャニマス" # 画像収集当時noctchillが発表翌日であったためコメントアウト
for i in range(len(words)):
google_crawler.crawl(keyword=words[i], filters=filters, max_num=max_num, file_idx_offset=i*max_num)
適当にpythonファイルとして保存し,実行する.
すると/shinyフォルダが作られ,取得した画像が保存される.

ファイルの手直し
今回ダウンロードしたファイルは拡張子がjpg以外にもpngやgifがある.
このままだと,学習に支障が出るためこれらのファイルは削除する.
拡張子を変換するという対処法もあるが面倒なので削除で対処した.
連番に穴ができるが,影響はないため気にしない.
また,今回はシャニマスのカードイラストも学習に使用した.
ダウンロード方法は説明しないが簡単に見つけられるだろう.
また,マルチバイト文字が混ざると面倒なので適当に変換をする.
大量のファイルを簡単に連番でリネームする方法(Windowsの標準機能)
アノテーション
画像の準備ができたらいよいよアノテーションである.2700枚(一部削除したので実際は2500枚程度だろう)の画像をアノテーションするので非常に大変である.
一気にやろうとせず,何日かに分けて行うといい.
アノテーションツールの準備
今回,labelimgを使用し,アノテーションを行った.
インストール
git clone https://github.com/tzutalin/labelImg.git
sudo apt install pyqt5-dev-tools
cd labelImg
make qt5py3
実行
python3 labelimg.py
で実行できる.
ファイルの準備
準備した画像ファイルを一旦labelimgのフォルダへ移動する.
また,クラスlabelimg/data の中にあるpredefined_class.txtを修正する.
そうすることでクラスの初期値が設定されるため,アノテーションが少し楽になる.
24人の名前を改行区切りで入力し,保存する.
Sakuragi Mano
Kazano Hiori
Hachimiya Meguru
Tanaka Mamimi
Yukoku Kiriko
Tsukioka Kogane
Mitsumine Yuika
Shirase Sakuya
Morino Rinze
Sonoda Chiyoko
Komiya Kaho
Saijo Juri
Arisugawa Natsuha
Osaki Amana
Osaki Tenka
Kuwayama Chiyuki
Serizawa Asahi
Mayuzumi Fuyuko
Izumi Mei
Ichikawa Hinana
Asakura Toru
Higuchi Madoka
Fukumaru Koito
Nanakusa Hazuki
アノテーションの実行
Open Dir で画像フォルダを開き,Change Save Dir で保存先を指定する.
今回は同じフォルダを指定する.

さらにSaveの下にあるPscalVOC を選択しYOLOに変更.
変更しないと泣きを見るので要注意!
画像が出てきたらアノテーションを行う.
「W」キーで範囲指定モードになるのでアイドルの顔を範囲選択する.
クラス名を選択する画面になるので正しいアイドルを選び,OKをクリック.

これを永遠と繰り返す.
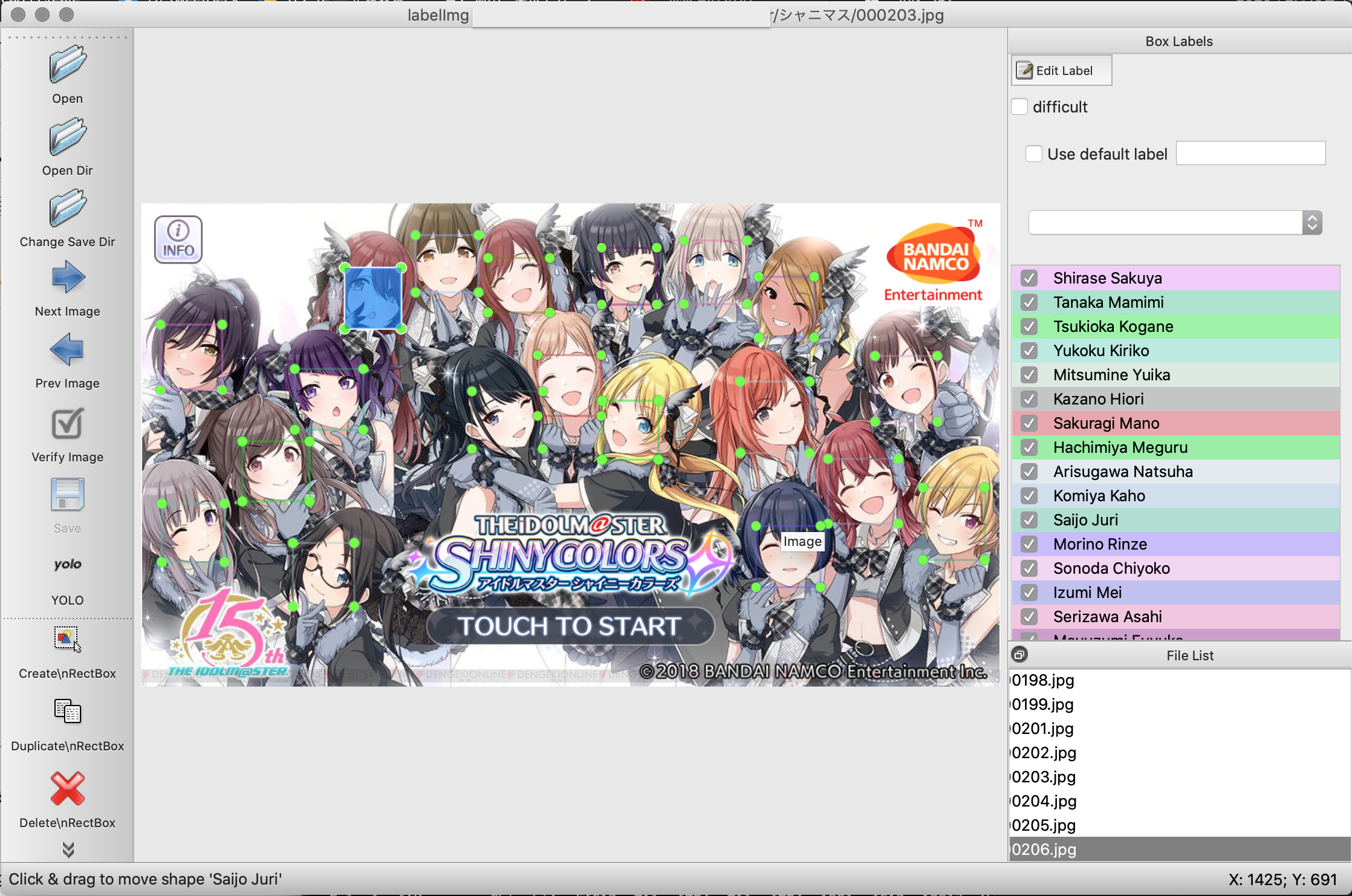
また,「View→Auto Save Mode」をオンにすることで自動的に保存してくれる様になる.
すると,殆どの作業がキー入力のみでできるため,
「W」→範囲指定→アイドル名の頭文字入力→矢印キーで選択→Enter→「D」で次の画像へ移動
といったことができる.
アノテーション時の注意点
2000枚以上のアノテーションを行うため,ときにはソフトが落ちてしまうことがある.
この際,画像フォルダ内にある「classes.txt」ファイルが破損する場合がある.
作業中メモ帳等で開いておくと破損してもすぐリカバリーが可能である.
また,入力ミスで新たなクラスを作ってしまった場合も同様の方法で修正が可能であるが,新たなクラスでラベリングしてしまったものは必ず削除すること.
また,画像収集の都合上,ラベリングが不能な画像も含まれる.その画像はそのまま飛ばせば良い.
 画像とテキストファイルが作成されたのを確認.
## データ分け
画像とテキストファイルが作成されたのを確認.
## データ分け
フォルダ内のデータを教師用データと学習用のデータに分ける.
これは
How to train YOLOv2 to detect custom objects
のプログラムを一部変更してデータを自動的に分けることにする.
import glob, os
# Current directory
current_dir = os.path.dirname(os.path.abspath(__file__))
# Directory where the data will reside, relative to 'darknet.exe'
path_data = 'data/obj/'
# Percentage of images to be used for the test set
percentage_test = 10
# Create and/or truncate train.txt and test.txt
file_train = open('train.txt', 'w')
file_test = open('test.txt', 'w')
# Populate train.txt and test.txt
counter = 1
index_test = round(100 / percentage_test)
texts = glob.glob(os.path.basename(os.path.join(current_dir, "*.txt")))
for pathAndFilename in glob.iglob(os.path.join(current_dir, "*.jpg")):
title, ext = os.path.splitext(os.path.basename(pathAndFilename))
if (title + ".txt") in texts:
if counter == index_test:
counter = 1
file_test.write(path_data + title + '.jpg' + "\n")
else:
file_train.write(path_data + title + '.jpg' + "\n")
counter = counter + 1
適当なファイル名をつけて画像と同じフォルダに保存し,実行.
これで,テキストファイルが存在する画像のみtrain.txtもしくはtest.txtファイルに追加される.
percentage_test = 10で教師用データの割合を決めているので適宜変更を.
これらが入ったフォルダを darknet/data/以下に移動(darknet/data/shinyになるように)
ファイルの準備
学習に必要なファイルの準備を行う.
weightsファイルの準備
事前トレーニングされたweightsファイルが公式にあるため,それを利用する.
wget https://pjreddie.com/media/files/darknet53.conv.74
でダウンロードが可能.
構成ファイルの準備
- .data
- .names
- .cfg
ファイルを作成する.
.dataファイルの作成
.dataファイルを作成する.
classes= 24
train = data/shiny/train.txt
valid = data/shiny/test.txt
names = cfg/obj_shiny.names
backup = backup/
obj_shiny.data と名前をつけ,cfg/に保存
同時にdarknet以下にbackupフォルダーを作成.
.namesファイルの作成
cfg / obj_shiny.names になるように obj_shiny.names ファイルを作成.
中身はclasses.txtと同じなので,classes.txtを名前をつけて新たに保存すればよい.
.cfgファイルの作成
cfg/yolov3-voc.cfgをコピーし,3箇所ある
- classesのクラス数を24に変更.
- classesの少し前にあるfiltersに, (classes + 5) * 3の値である87に設定する.
変更が完了したらcfg/yolov3_shiny.cfgとして保存する.
この部分のclassesとfiltersを変更する.
[convolutional]
size=1
stride=1
pad=1
filters=87
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=24
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
また,本格的にトレーニングを行う場合は,最初の[net]部分にある
- batch=1をbatch=64
- subdivisions=1をsubdivisions=8
に変更する.
GPUの性能によってはメモリエラーが出るため,batchを減らしたり,subdivisionsを大きくする.
トレーニング
darknet.exe detector train cfg/obj_shiny.data cfg/yolov3_shiny.cfg darknet53.conv.74
実行することでトレーニングが始まる.
グラフが出てこない場合はエラーが出ている可能性が高いので要確認.
実験結果
学習が終了したら
darknet.exe detector test cfg/obj_shiny.data cfg/yolov3_shiny.cfg backup/yolov3-obj_last.weights
で確認ができる.
 学習させたカードのイラストはもちろん判別ができている.
学習させたカードのイラストはもちろん判別ができている.
 浅倉透は10枚程度しか準備できなかったが,立ち絵ならば認識した.
浅倉透は10枚程度しか準備できなかったが,立ち絵ならば認識した.
 学習させていない新規イラストの芹沢あさひも認識し,判別ができた.
学習させていない新規イラストの芹沢あさひも認識し,判別ができた.

 横顔は認識できなかったが,学習ができているといえるだろう.
横顔は認識できなかったが,学習ができているといえるだろう.
終わりに
 今回学習させた過程のグラフだが,50000回では明らかに過学習になっていた.
結果を見ても5000~7000回が納得できる結果であった.
今回学習させた過程のグラフだが,50000回では明らかに過学習になっていた.
結果を見ても5000~7000回が納得できる結果であった.
また,今回,学習に使用した画像にすべてのシャニマスのイラストカードを利用した.
そのため,学習に利用した一枚目のような画像は当然認識するようになる.
本当に認識しているか確認するためには,より多くの実験用の画像も準備するべきだったと言える.
参考記事
How to train YOLOv2 to detect custom objects
ご注文はYOLOですか!?(Windows10でYOLOを学習して動かすまで)
ご注文はYOLOv3ですか!?~WindowsでYOLOv3を動かす~
icrawer部分での参考記事
pythonライブラリicrawlerを使い簡単に画像データを集める