はじめに
PythonとKerasを使ってAlphaZero AIを自作するという記事があったので、おもしろそうだからAlphaZeroのコードを動かしてみました。
見つけた記事のタイトル通りにkerasが使われていますが、kerasの使い方がわからなくてもAlphaZeroのコードは動かせるようになっています。
この記事では見つけた記事を参考にしつつ、記事では書かれていない以下の2つをやってみます。
- 三目並べを学習させる
- 学習モデルを使ってtkinterで実装された三目並べでAIと対戦する
AlphaZeroって何?
DeepMindが開発したプログラムでAlphaGoとは違って囲碁だけでなく、オセロ、将棋、チェスなどのゲームを学習することができます。
AlphaZeroを作る
この記事に書かれている手順で進めるだけです。
まずは、ここのRepositoryを自分のパソコンにcloneもしくはDownloadします。
この時点でディレクトリの中身は以下のようになっています。
学習を開始するにはrun.ipynbの上2つのセルを実行します。実行するとgame.pyに書かれたゲームの学習を開始します。
game.pyを書き換える
Downloadしたgame.pyにはコネクトフォーのゲームのルールについて書かれています。
このコードを以下の三目並べのゲームのルールに書き換えます。
import numpy as np
import logging
class Game:
def __init__(self):
self.currentPlayer = 1
self.gameState = GameState(np.array([0]*9, dtype=np.int), 1)
self.actionSpace = np.array([0]*9, dtype=np.int)
self.pieces = {'-1': 'X', '0': '-', '1': 'O'}
self.grid_shape = (3, 3)
self.input_shape = (2, 3, 3)
self.name = "三目並べ"
self.state_size = len(self.gameState.binary)
self.action_size = len(self.actionSpace)
def reset(self):
self.gameState = GameState(np.array([0]*9, dtype=np.int), 1)
self.currentPlayer = 1
return self.gameState
def step(self, action):
next_state, value, done = self.gameState.takeAction(action)
self.gameState = next_state
self.currentPlayer = -self.currentPlayer
info = None
return ((next_state, value, done, info))
def identities(self, state, actionValues):
identities = [(state, actionValues)]
currentBoard = state.board
currentAV = actionValues
currentBoard = np.array([
currentBoard[2], currentBoard[1], currentBoard[0],
currentBoard[5], currentBoard[4], currentBoard[3],
currentBoard[8], currentBoard[7], currentBoard[6]
])
currentAV = np.array([
currentAV[2], currentAV[1], currentAV[0],
currentAV[5], currentAV[4], currentAV[3],
currentAV[8], currentAV[7], currentAV[6]
])
identities.append((GameState(currentBoard, state.playerTurn), currentAV))
return identities
class GameState:
def __init__(self, board, playerTurn):
self.board = board
self.pieces = {'-1': 'X', '0': '-', '1': 'O'}
self.winners = [[0,1,2], [3,4,5], [6,7,8], [0,3,6], [1,4,7], [2,5,8], [0,4,8], [2,4,6]]
self.playerTurn = playerTurn
self.binary = self._binary()
self.id = self._convertStateToId()
self.allowedActions = self._allowedActions()
self.isEndGame = self._checkForEndGame()
self.value = self._getValue()
self.score = self._getScore()
def _allowedActions(self):
return np.where(self.board == 0)[0]
def _binary(self):
currentplayer_position = np.zeros(len(self.board), dtype=np.int)
currentplayer_position[self.board == self.playerTurn] = 1
other_position = np.zeros(len(self.board), dtype=np.int)
other_position[self.board == -self.playerTurn] = 1
position = np.append(currentplayer_position, other_position)
return (position)
def _convertStateToId(self):
player1_position = np.zeros(len(self.board), dtype=np.int)
player1_position[self.board == 1] = 1
other_position = np.zeros(len(self.board), dtype=np.int)
other_position[self.board == -1] = 1
position = np.append(player1_position, other_position)
return "".join(map(str, position))
def _checkForEndGame(self):
return self._check()
def _check(self):
for i in range(len(self.winners)):
if self.board[self.winners[i][0]]==self.board[self.winners[i][1]]==self.board[self.winners[i][2]]==1:
return 1
if self.board[self.winners[i][0]]==self.board[self.winners[i][1]]==self.board[self.winners[i][2]]==-1:
return 1
return 2 if np.count_nonzero(self.board) == 9 else 0
def _getValue(self):
result = self._check()
if result == 2:
# Draw
return (0, 1, 1)
elif result == 1:
# Win
if self.playerTurn == 1:
# player1
return (1, 1, -1)
else:
# player2
return (-1, -1, 1)
else:
return (0, 0, 0)
def _getScore(self):
tmp = self.value
return (tmp[1], tmp[2])
def takeAction(self, action):
newBoard = np.array(self.board)
newBoard[action] = self.playerTurn
newState = GameState(newBoard, -self.playerTurn)
value = 0
done = 0
if newState.isEndGame:
value = newState.value[0]
done = 1
return (newState, value, done)
def render(self, logger):
for r in range(3):
logger.info([self.pieces[str(x)] for x in self.board[3*r : (3*r+3)]])
logger.info('--------------')
Graphviz
Graphvizが必要なのでインストールしていない方はインストールしましょう。インストールしたらパスを通します。
学習させる
コードの用意ができたらJupyter Notebookからrun.ipynbを開いて上2つのセルを実行すると学習が開始します。学習が進んでいくとrunフォルダ内のmodelsフォルダに学習モデルが保存されます。学習モデルができるまでけっこう時間がかかります。私のパソコンの場合5時間くらいかかりました。
# -*- coding: utf-8 -*-
# %matplotlib inline
%load_ext autoreload
%autoreload 2
import numpy as np
np.set_printoptions(suppress=True)
from shutil import copyfile
import random
from importlib import reload
from keras.utils import plot_model
from game import Game, GameState
from agent import Agent
from memory import Memory
from model import Residual_CNN
from funcs import playMatches, playMatchesBetweenVersions
import loggers as lg
from settings import run_folder, run_archive_folder
import initialise
import pickle
lg.logger_main.info('=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*')
lg.logger_main.info('=*=*=*=*=*=. NEW LOG =*=*=*=*=*')
lg.logger_main.info('=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*')
env = Game()
# If loading an existing neural network, copy the config file to root
if initialise.INITIAL_RUN_NUMBER != None:
copyfile(run_archive_folder + env.name + '/run' + str(initialise.INITIAL_RUN_NUMBER).zfill(4) + '/config.py', './config.py')
import config
######## LOAD MEMORIES IF NECESSARY ########
if initialise.INITIAL_MEMORY_VERSION == None:
memory = Memory(config.MEMORY_SIZE)
else:
print('LOADING MEMORY VERSION ' + str(initialise.INITIAL_MEMORY_VERSION) + '...')
memory = pickle.load( open( run_archive_folder + env.name + '/run' + str(initialise.INITIAL_RUN_NUMBER).zfill(4) + "/memory/memory" + str(initialise.INITIAL_MEMORY_VERSION).zfill(4) + ".p", "rb" ) )
######## LOAD MODEL IF NECESSARY ########
# create an untrained neural network objects from the config file
current_NN = Residual_CNN(config.REG_CONST, config.LEARNING_RATE, (2,) + env.grid_shape, env.action_size, config.HIDDEN_CNN_LAYERS)
best_NN = Residual_CNN(config.REG_CONST, config.LEARNING_RATE, (2,) + env.grid_shape, env.action_size, config.HIDDEN_CNN_LAYERS)
# If loading an existing neural netwrok, set the weights from that model
if initialise.INITIAL_MODEL_VERSION != None:
best_player_version = initialise.INITIAL_MODEL_VERSION
print('LOADING MODEL VERSION ' + str(initialise.INITIAL_MODEL_VERSION) + '...')
m_tmp = best_NN.read(env.name, initialise.INITIAL_RUN_NUMBER, best_player_version)
current_NN.model.set_weights(m_tmp.get_weights())
best_NN.model.set_weights(m_tmp.get_weights())
# otherwise just ensure the weights on the two players are the same
else:
best_player_version = 0
best_NN.model.set_weights(current_NN.model.get_weights())
# copy the config file to the run folder
copyfile('./config.py', run_folder + 'config.py')
plot_model(current_NN.model, to_file=run_folder + 'models/model.png', show_shapes = True)
print('\n')
######## CREATE THE PLAYERS ########
current_player = Agent('current_player', env.state_size, env.action_size, config.MCTS_SIMS, config.CPUCT, current_NN)
best_player = Agent('best_player', env.state_size, env.action_size, config.MCTS_SIMS, config.CPUCT, best_NN)
# user_player = User('player1', env.state_size, env.action_size)
iteration = 0
while 1:
iteration += 1
reload(lg)
reload(config)
print('ITERATION NUMBER ' + str(iteration))
lg.logger_main.info('BEST PLAYER VERSION: %d', best_player_version)
print('BEST PLAYER VERSION ' + str(best_player_version))
######## SELF PLAY ########
print('SELF PLAYING ' + str(config.EPISODES) + ' EPISODES...')
_, memory, _, _ = playMatches(best_player, best_player, config.EPISODES, lg.logger_main, turns_until_tau0 = config.TURNS_UNTIL_TAU0, memory = memory)
print('\n')
memory.clear_stmemory()
if len(memory.ltmemory) >= config.MEMORY_SIZE:
######## RETRAINING ########
print('RETRAINING...')
current_player.replay(memory.ltmemory)
print('')
if iteration % 5 == 0:
pickle.dump( memory, open( run_folder + "memory/memory" + str(iteration).zfill(4) + ".p", "wb" ) )
lg.logger_memory.info('====================')
lg.logger_memory.info('NEW MEMORIES')
lg.logger_memory.info('====================')
memory_samp = random.sample(memory.ltmemory, min(1000, len(memory.ltmemory)))
for s in memory_samp:
current_value, current_probs, _ = current_player.get_preds(s['state'])
best_value, best_probs, _ = best_player.get_preds(s['state'])
lg.logger_memory.info('MCTS VALUE FOR %s: %f', s['playerTurn'], s['value'])
lg.logger_memory.info('CUR PRED VALUE FOR %s: %f', s['playerTurn'], current_value)
lg.logger_memory.info('BES PRED VALUE FOR %s: %f', s['playerTurn'], best_value)
lg.logger_memory.info('THE MCTS ACTION VALUES: %s', ['%.2f' % elem for elem in s['AV']] )
lg.logger_memory.info('CUR PRED ACTION VALUES: %s', ['%.2f' % elem for elem in current_probs])
lg.logger_memory.info('BES PRED ACTION VALUES: %s', ['%.2f' % elem for elem in best_probs])
lg.logger_memory.info('ID: %s', s['state'].id)
lg.logger_memory.info('INPUT TO MODEL: %s', current_player.model.convertToModelInput(s['state']))
s['state'].render(lg.logger_memory)
######## TOURNAMENT ########
print('TOURNAMENT...')
scores, _, points, sp_scores = playMatches(best_player, current_player, config.EVAL_EPISODES, lg.logger_tourney, turns_until_tau0 = 0, memory = None)
print('\nSCORES')
print(scores)
print('\nSTARTING PLAYER / NON-STARTING PLAYER SCORES')
print(sp_scores)
#print(points)
print('\n\n')
if scores['current_player'] > scores['best_player'] * config.SCORING_THRESHOLD:
best_player_version = best_player_version + 1
best_NN.model.set_weights(current_NN.model.get_weights())
best_NN.write(env.name, best_player_version)
else:
print('MEMORY SIZE: ' + str(len(memory.ltmemory)))
ファイル容量が気になる場合
学習を進めていくとrunフォルダ内のlogフォルダに学習の記録が保存されていきます。学習が進むにつれてファイル容量がかなり大きくなるので気になる方はログの記録をオフにしましょう。
Downloadしたディレクトリにあるloggers.pyの内容をFalseからTrueにするだけです。
LOGGER_DISABLED = {
'main': True
, 'memory': True
, 'tourney': True
, 'mcts': True
, 'model': True}
AlphaZeroと対戦
tkinterで作られた三目並べを使って対戦してみます。
以下のコードをコピペしてapp.pyという名前でDownloadしたディレクトリ直下においてください。作り方については以前私のブログに記事を書きました。(※興味がある方はこちら。)ブログに書いたプログラムをAlphaZero用に少し改良しています
import threading
import time
import random
import tkinter as tk
import config
import numpy as np
import tensorflow as tf
from agent import Agent, User
from game import Game, GameState
from keras.models import load_model
from model import Residual_CNN
class Thread(threading.Thread):
def __init__(self):
super(Thread, self).__init__()
self.is_running = True
self.thlock = 1
self.keylock = 0
self.parent = None
self.start()
def __call__(self):
self.keylock = 1
self.unlock()
def set_parent(self, parent):
self.parent = parent
def lock(self):
self.thlock = 1
def unlock(self):
self.thlock = 0
def is_lock(self):
return self.thlock
def random_choice(self):
i = random.choice([i for i, v in enumerate(self.parent.board2info) if v == 0])
tag = self.parent.alpstr[i]
flag = self.parent.update_board(tag)
if flag:
self.lock()
return
self.parent.playerTurn = 1
self.lock()
self.keylock = 0
def alpha_zero(self):
action, _, _, _ = self.parent.cpu.act(self.parent.state, 0)
tag = self.parent.alpstr[action]
# Do the action
done = self.parent.update_board(action, tag)
self.lock()
if done:
return
self.keylock = 0
def run(self):
while self.is_running:
if self.is_lock():
continue
#self.random_choice()
self.alpha_zero()
table = """
Turn {}
|{:^3s}|{:^3s}|{:^3s}|
-------------
|{:^3s}|{:^3s}|{:^3s}|
-------------
|{:^3s}|{:^3s}|{:^3s}|
"""
table_r = """
結果: {}
|{:^3s}|{:^3s}|{:^3s}|
-------------
|{:^3s}|{:^3s}|{:^3s}|
-------------
|{:^3s}|{:^3s}|{:^3s}|
"""
def check(board):
wins = [[0,1,2], [3,4,5], [6,7,8], [0,3,6], [1,4,7], [2,5,8], [0,4,8], [2,4,6]]
for i in range(len(wins)):
if board[wins[i][0]]==board[wins[i][1]]==board[wins[i][2]]==1:
return 1
elif board[wins[i][0]]==board[wins[i][1]]==board[wins[i][2]]==-1:
return 1
return [2, 0][0 in board]
class App(tk.Tk):
def __init__(self):
super(App, self).__init__()
# Window
self.title("三目並べ")
self.geometry("{}x{}+{}+{}".format(360, 400, 450, 100))
# Set up some variables
self.set_variables()
# Set up game board
self.set_board()
# Set up some buttons
self.set_button()
# Set up env
self.settings()
# Set threading
self.thread = Thread()
self.thread.set_parent(self)
def set_variables(self):
self.board2info = [0] * 9
self.symbol = " ox"
self.alpstr = "abcdefghi"
self.winner = ["", "あなた", "引き分け", "CPU"]
def set_board(self):
self.board = tk.Canvas(self, bg="white", width=340, height=340)
self.tag2pos = {}
position = [(20, 20, 120, 120), (120, 20, 220, 120), (220, 20, 320, 120),
(20, 120, 120, 220), (120, 120, 220, 220), (220, 120, 320, 220),
(20, 220, 120, 320), (120, 220, 220, 320), (220, 220, 320, 320)]
for tag, pos in zip(self.alpstr, position):
self.tag2pos[tag] = pos[:2]
self.board.create_rectangle(*pos, fill='green yellow', outline='green yellow', tags=tag)
self.board.tag_bind(tag, "<ButtonPress-1>", self.pressed)
# Vertical line
for x in range(120, 320, 100):
self.board.create_line(x, 20, x, 320)
# Horizontal line
for y in range(120, 320, 100):
self.board.create_line(20, y, 320, y)
self.board.place(x=10, y=0)
def set_button(self):
self.reset = tk.Button(self, text="reset", relief="groove", command=self.clear)
self.reset.place(x=170, y=360)
self.quit_program = tk.Button(self, text="quit", relief="groove", command=self.close)
self.quit_program.place(x=320, y=360)
def settings(self):
graph = tf.get_default_graph()
env = Game()
state = env.reset()
player_NN = Residual_CNN(
config.REG_CONST,
config.LEARNING_RATE,
env.input_shape,
env.action_size,
config.HIDDEN_CNN_LAYERS
)
net = player_NN.load()
player_NN.model.set_weights(net.get_weights())
cpu = Agent(
"Agent",
env.state_size,
env.action_size,
config.MCTS_SIMS,
config.CPUCT,
player_NN,
graph
)
cpu.mcts = None
self.cpu = cpu
self.env = env
self.state = state
def clear(self):
self.board.delete("all")
self.set_variables()
self.set_board()
self.thread.keylock = 0
self.state = self.env.reset()
def draw_symbol(self, tag):
symbol = self.symbol[self.env.currentPlayer]
x, y = self.tag2pos[tag]
self.board.create_text(x+50, y+50,
font=("Helvetica", 60),
text=symbol)
def pressed(self, event):
if self.thread.keylock:
return
item_id = self.board.find_closest(event.x, event.y)
tag = self.board.gettags(item_id[0])[0]
action = self.alpstr.index(tag)
state = self.board2info[action]
if state in [-1, 1]:
return
if self.update_board(action, tag):
self.thread.keylock = 1
return
self.thread()
def update_board(self, action, tag):
self.board2info[action] = self.env.currentPlayer
self.draw_symbol(tag)
self.check_result()
self.state, _, done, _ = self.env.step(action)
return done
def check_result(self):
result = check(self.board2info)
winner = "Turn {}".format("?")
if result:
winner = self.winner[result] if result == 2 else self.winner[self.env.currentPlayer]
print(table_r.format(winner, *[[" ", "o", "x"][i] for i in self.board2info]))
else:
print(table.format("?", *[[" ", "o", "x"][i] for i in self.board2info]))
def close(self):
self.thread.is_running = 0
self.quit()
def run(self):
self.mainloop()
if __name__ == "__main__":
app = App()
app.run()
さらに、ちょっときたないやり方かもしれませんが同じくディレクトリ直下にあるmodel.pyのクラスGen_Modelに次のメソッドを追加します。
def load(self):
return load_model('run/models/version0022.h5',
custom_objects={'softmax_cross_entropy_with_logits': softmax_cross_entropy_with_logits})
version0022.h5は学習モデルです。モデル名については学習状況によって各自で変えてみてください。
これでAIと対戦できる準備が整ったので対戦してみます。
Downloadしたディレクトリに移動してpython app.pyでアプリケーションが起動します。
起動するまで時間が少しかかります。
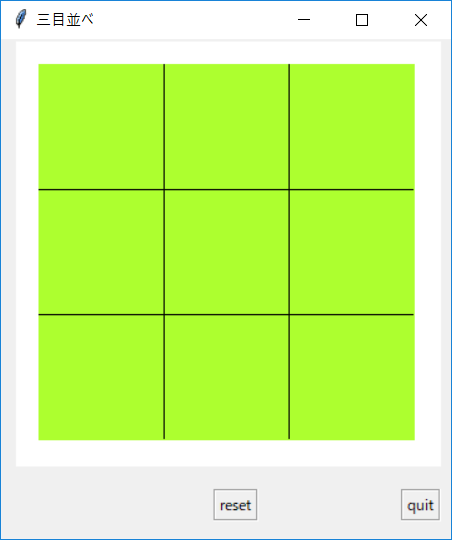
アプリケーションの概要
アプリケーションが起動したらすでにゲームができる状態になっており、空いているマスをクリックすると〇が書き込まれます。
下にあるresetボタンを押せばゲームを最初からやり直せます。quitボタンを押すとアプリケーションが終了します。
対戦の制約
tkinterで作られた三目並べですが、いくつかの制約があります。
- ユーザvsAIの対戦しかできない。
- ユーザは〇、AIは✖を書き込む
- ユーザは先手、AIは後手
おわりに
ここまで簡単に三目並べをAlphaZeroで学習させる方法を書いてみました。
game.pyに書かれているAPIに従えば、ほかのゲーム(オセロや将棋)なども与えられたルールに基づき、自己対戦によってAlphaZeroは学習できるようです。
さらに、紹介したRepositoryには強化学習やモンテカルロ法についてのコードがあるので勉強したい方は参考になると思います。
私のTwitterアカウントでは主にQiitaやブログ記事に関する情報を投稿しています。
->@pytry3g