やりたいこと
あるキーワードでGoogle検索した上位10サイトのタイトルの特徴を知りたい。
ライブラリ
- BeautifulSoup4
- requests
- pandas
- janome
- sklearn
前提
今回はJupyter notebookで書いていきますので、インストール済みであること。
実装
実際のコードを書いていきますが、いかんせん経験が浅いので効率の悪い書き方をしているかもしれません。ご了承ください。
ライブラリのインポート
今回はこれだけのライブラリを使用しますので、冒頭でインポートしておきます。
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
from math import log
from janome.tokenizer import Tokenizer
from janome.analyzer import Analyzer
from janome.tokenfilter import POSStopFilter
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
検索結果のタイトルを取得
BeautifulSoupを使用してGoogle検索結果をスクレイピングしていきます。
# リクエストヘッダー
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"}
list_keywd = ['キーワード1','キーワード2']
input_num = 10
url = 'https://www.google.co.jp/search?num={}&q='.format(input_num) + ' '.join(list_keywd)
# 接続
response = requests.get(url, headers=headers)
# HTTPステータスコードをチェック(200以外は例外処理)
response.raise_for_status()
# 取得したHTMLをパース
soup = bs(response.content, 'html.parser')
# 検索結果のタイトルとリンクを取得
ret_link = soup.select('.r > a')
# パン屑を取らないために
ret_link2 = soup.select('.r > a > h3')
title_list = []
url_list = []
leng = len(ret_link)
r_list = []
cols = ['title','url']
for i in range(len(ret_link)):
#タイトルのテキスト部分を取得
title_txt = ret_link2[i].get_text()
#リンクのみを取得し、余計な部分を削除する
url_txt = ret_link[i].get('href').replace('/url?q=','')
title_list.append(title_txt)
url_list.append(url_txt)
tmp = []
tmp = [title_txt,url_txt]
r_list.append(tmp)
# 検索結果を表示
df = pd.DataFrame(r_list,columns=cols)
df
あるキーワードでのGoogle検索結果の上位10サイトはこんな結果でした。

タイトルを形態素解析~分かち書き
上位10サイトのタイトルが取得できたので、形態素解析から分かち書きまで行います。
形態素解析はJanomeを使用しました。
# 各ブログの名詞を分かち書きして登録
tokenizer = Tokenizer()
token_filters = [POSStopFilter(['記号','助詞','助動詞','動詞'])]
a = Analyzer(tokenizer=tokenizer, token_filters=token_filters)
work = []
WAKATI = []
for i in BLOG.keys():
texts_flat = "".join(BLOG[i]["title"])
tokens = a.analyze(texts_flat)
work.append(' '.join([t.surface for t in tokens]))
WAKATI.append(work[i].lower().split())
# 確認
for i in BLOG.keys():
print("■WAKATI[{}]: {}".format(i,WAKATI[i]))
# scikit-learnで単語の出現頻度を計算
vectorizer = CountVectorizer()
# Bow計算
X = vectorizer.fit_transform([work[i] for i in range(len(work))])
WORDS = vectorizer.get_feature_names()
WORDS.sort()
print('=========================================')
print('全単語')
print('=========================================')
print(WORDS)
こんな形に解析されました。

関数定義
今回はtf値、idf値、tf-idf値を求める関数を書きました。
# 関数定義
def tf(t, d):
return d.count(t)/len(d)
def idf(t):
df = 0
for wak in WAKATI:
df += t in wak
#return log(N/df) + 1
return log(N/np.array(df)) + 1
def tfidf(t,d):
return tf(t,d) * idf(t)
def highlight_negative(val):
if val > 0:
return 'color: {0}; font-weight: bold'.format('red')
else:
return 'color: {0}'.format('black')
# 関数定義 おわり
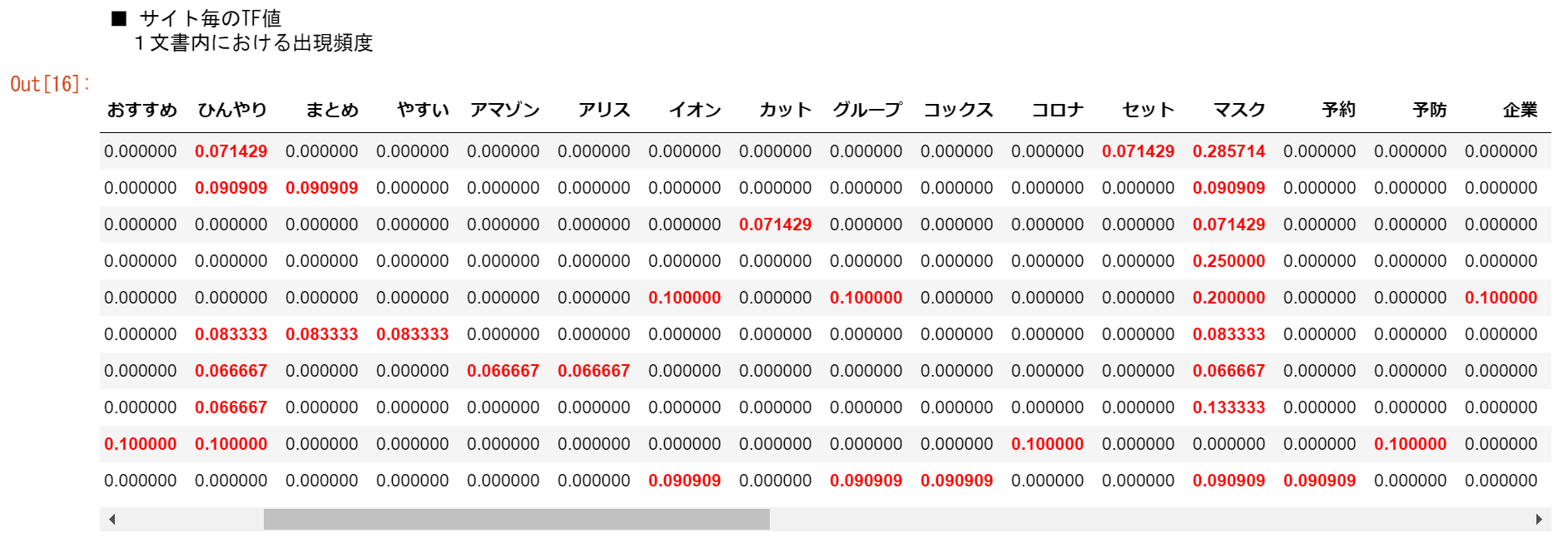
tf値を見てみます
まずは、tf値を見ていきます。
# tf計算
print('■ サイト毎のTF値')
print(' 1文書内における出現頻度')
ret = []
for i in range(N):
ret.append([])
d = WAKATI[i]
for j in range(len(WORDS)):
t = WORDS[j]
if len(d) > 0:
ret[-1].append(tf(t,d))
tf_ = pd.DataFrame(ret, columns=WORDS)
tf_.style.applymap(highlight_negative)
下図のとおり、tf値が取得できました。
使用されている品詞を赤字表記にしています。
「マスク」と「ひんやり」は多くの割合でタイトルに使用されていますね。
tf値だけで、なんとなく検索ワードが分かるかもしれませんね。
idf値を見てみます
idf値が大きいほど、他のタイトルには出現していないことになり、希少性のあるワードになります。
逆に値が小さいほどよく使われているってことになります。
# idf計算
ret = []
for i in range(len(WORDS)):
t = WORDS[i]
ret.append(idf(t))
idf_ = pd.DataFrame(ret, index=WORDS, columns=["IDF"])
idf_s = idf_.sort_values('IDF')
idf_s.style.applymap(highlight_negative)

tf値のほうで、よく出現していた「マスク」や「ひんやり」は当然のごとくidf値が小さいですね。
この結果では、値が2.609438は2サイトで出現、値が3.302585は1サイトでのみ出現となっています。
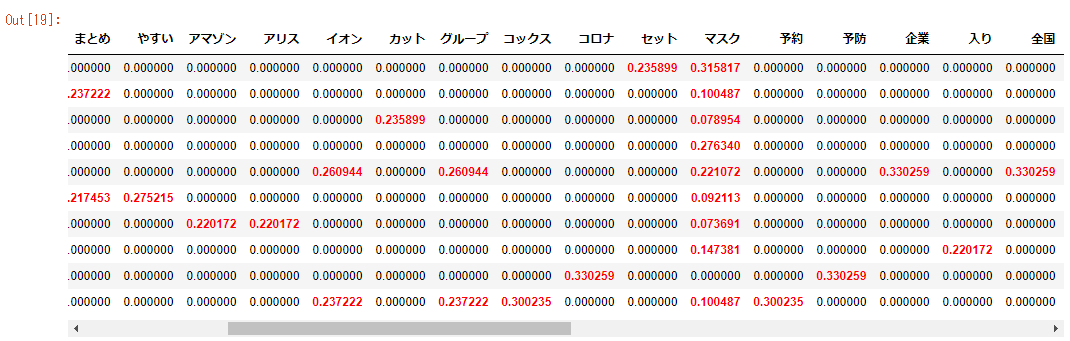
tf-idf値を見てみます
tf-idf値が大きいほど、そのワードはそのタイトル内で重要な役割を持つってことになります。
ret = []
for i in range(N):
ret.append([])
d = WAKATI[i]
for j in range(len(WORDS)):
t = WORDS[j]
if len(d) > 0:
ret[-1].append(tfidf(t,d))
tfidf_ = pd.DataFrame(ret,columns=WORDS)
tfidf_.style.applymap(highlight_negative)
結果はこんな感じになりました。
行がサイトで、列は全単語が出ています。
サイト内に出現していないワードの値は「0」です。
サイト毎に見た時に、値の大きいワードがそのサイトタイトル内で大きな役割を持っていると言えるかもしれません。
まとめ
こんな感じで特徴を調べることができます。
サイトのタイトルは何にしようかなーとか、入れておくべきワードを見つける時とかの参考になるかもしれません。