株価や新型コロナウイルス陽性患者数など、細かく数値が上下するデータの大まかな傾向を掴むには、ある時点の前後の数値を含めた平均を取ります。このような操作を行う Pandas の関数である rolling についてメモします。
普通の使い方
import pandas as pd
まず rolling の基本動作を確認するために、10 個の 1 が並んだ Series を作り ones と名付けます。
ones = pd.Series([1] * 10)
ones
0 1
1 1
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
dtype: int64
rolling を使って ones を4つずつ足してゆきます。1 の数値を 4 つずつ足してゆくだけなので当然結果は 4 の列になります。ただ、最初にデータが 4 つ揃わない部分の結果は NaN になります。元の列と比較するために、ones と足した結果の sum-4 を並べてみました。
このように window で集計するデータの個数 (window の幅) を指定します。4 つの窓が最初から最後まで移動しながら集計してゆくイメージです。集計結果は window の最後に記録されるので、sum-4 の最初の 3 つの値は NaN になっています。
pd.DataFrame({
'ones': ones,
'sum-4': ones.rolling(window=4).sum(),
})
| ones | sum-4 | |
|---|---|---|
| 0 | 1 | NaN |
| 1 | 1 | NaN |
| 2 | 1 | NaN |
| 3 | 1 | 4.0 |
| 4 | 1 | 4.0 |
| 5 | 1 | 4.0 |
| 6 | 1 | 4.0 |
| 7 | 1 | 4.0 |
| 8 | 1 | 4.0 |
| 9 | 1 | 4.0 |
center=True を指定すると、集計結果を window の最後に記録する代わりに真ん中に記録する事も出来ます。これを sum-center として並べてみます。window が偶数の時は中心の後ろに記録します。今度は最後の要素が NaN になりました。
pd.DataFrame({
'ones': ones,
'sum-4': ones.rolling(window=4).sum(),
'sum-center': ones.rolling(window=4, center=True).sum(),
})
| ones | sum-4 | sum-center | |
|---|---|---|---|
| 0 | 1 | NaN | NaN |
| 1 | 1 | NaN | NaN |
| 2 | 1 | NaN | 4.0 |
| 3 | 1 | 4.0 | 4.0 |
| 4 | 1 | 4.0 | 4.0 |
| 5 | 1 | 4.0 | 4.0 |
| 6 | 1 | 4.0 | 4.0 |
| 7 | 1 | 4.0 | 4.0 |
| 8 | 1 | 4.0 | 4.0 |
| 9 | 1 | 4.0 | NaN |
デフォルトではデータの端っこの window の幅が足りない部分の集計は行いません。しかし min_periods を指定すると、最低限 min_periods の分があれば集計します。この例では、min_period=2 を指定していますので2つ目の行から結果が現れます。
pd.DataFrame({
'ones': ones,
'sum-4': ones.rolling(4).sum(),
'min-periods': ones.rolling(window=4, min_periods=2).sum(),
})
| ones | sum-4 | min-periods | |
|---|---|---|---|
| 0 | 1 | NaN | NaN |
| 1 | 1 | NaN | 2.0 |
| 2 | 1 | NaN | 3.0 |
| 3 | 1 | 4.0 | 4.0 |
| 4 | 1 | 4.0 | 4.0 |
| 5 | 1 | 4.0 | 4.0 |
| 6 | 1 | 4.0 | 4.0 |
| 7 | 1 | 4.0 | 4.0 |
| 8 | 1 | 4.0 | 4.0 |
| 9 | 1 | 4.0 | 4.0 |
ここまでは window にかかった部分の要素を全て使って集計していましたが、win_type を使うと集計する値の重みを変えられるそうです。scipy のインストールが必要。
pd.DataFrame({
'ones': ones,
'sum-4': ones.rolling(4).sum(),
'win_type': ones.rolling(window=4, win_type='nuttall').sum(),
})
| ones | sum-4 | win_type | |
|---|---|---|---|
| 0 | 1 | NaN | NaN |
| 1 | 1 | NaN | NaN |
| 2 | 1 | NaN | NaN |
| 3 | 1 | 4.0 | 1.059185 |
| 4 | 1 | 4.0 | 1.059185 |
| 5 | 1 | 4.0 | 1.059185 |
| 6 | 1 | 4.0 | 1.059185 |
| 7 | 1 | 4.0 | 1.059185 |
| 8 | 1 | 4.0 | 1.059185 |
| 9 | 1 | 4.0 | 1.059185 |
インデックスに日付を使う
ここまでは window に要素の個数を指定しました。ここで Series の index が日付や時刻の時だけ時間や日数などの期間を window に指定する事が出来ます。早速サンプルのデータを作ってみます。
date_ones = pd.Series(
index=[
pd.Timestamp('2020-01-01'),
pd.Timestamp('2020-01-02'),
pd.Timestamp('2020-01-07'),
pd.Timestamp('2020-01-08'),
pd.Timestamp('2020-01-09'),
pd.Timestamp('2020-01-16'),
],
data=[1,1,1,1,1,1]
)
date_ones
2020-01-01 1
2020-01-02 1
2020-01-07 1
2020-01-08 1
2020-01-09 1
2020-01-16 1
dtype: int64
ここで window='7d' のように指定すると、7日前までの要素を使って集計します。
pd.DataFrame({
'ones': date_ones,
'rolling-7d': date_ones.rolling('7D').sum(),
})
| ones | rolling-7d | |
|---|---|---|
| 2020-01-01 | 1 | 1.0 |
| 2020-01-02 | 1 | 2.0 |
| 2020-01-07 | 1 | 3.0 |
| 2020-01-08 | 1 | 3.0 |
| 2020-01-09 | 1 | 3.0 |
| 2020-01-16 | 1 | 1.0 |
この例では
- 2020-01-01: 前に何もないので 1
- 2020-01-02: 7日前以内に一つ有るので 2
- 2020-01-07: 7日前以内には 2020-01-01, 2020-01-02, 2020-01-07 があるので 3
- 2020-01-08: 7日前以内には 2020-01-02, 2020-01-07, 2020-01-08 があるので 3
- 2020-01-16: 7日前以内には何もないので 1
となります。
この '7D' のような指定方法を offset と呼びます。Offset aliases に説明があります。
window に offset を使うとデータが少なくとも集計が行われるので勝手に NaN が記録される事はありません。逆に min_periods を指定すると、指定した offset 期間に指定した以上のデータが無いと NaN になります。
pd.DataFrame({
'ones': date_ones,
'rolling-7d': date_ones.rolling('7D').sum(),
'rolling-min-periods': date_ones.rolling('7D', min_periods=3).sum(),
})
| ones | rolling-7d | rolling-min-periods | |
|---|---|---|---|
| 2020-01-01 | 1 | 1.0 | NaN |
| 2020-01-02 | 1 | 2.0 | NaN |
| 2020-01-07 | 1 | 3.0 | 3.0 |
| 2020-01-08 | 1 | 3.0 | 3.0 |
| 2020-01-09 | 1 | 3.0 | 3.0 |
| 2020-01-16 | 1 | 1.0 | NaN |
移動平均の例
さて、ここまでの知識を使って東京都の新型コロナウイルス感染者数の移動平均グラフを描いてみます。
データは 東京都 新型コロナウイルス陽性患者発表詳細 から拝借します。
covid_src = pd.read_csv('https://stopcovid19.metro.tokyo.lg.jp/data/130001_tokyo_covid19_patients.csv', parse_dates=['公表_年月日'])
covid_src
| No | 全国地方公共団体コード | 都道府県名 | 市区町村名 | 公表_年月日 | 曜日 | 発症_年月日 | 患者_居住地 | 患者_年代 | 患者_性別 | 患者_属性 | 患者_状態 | 患者_症状 | 患者_渡航歴の有無フラグ | 備考 | 退院済フラグ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 130001 | 東京都 | NaN | 2020-01-24 | 金 | NaN | 湖北省武漢市 | 40代 | 男性 | NaN | NaN | NaN | NaN | NaN | 1.0 |
| 1 | 2 | 130001 | 東京都 | NaN | 2020-01-25 | 土 | NaN | 湖北省武漢市 | 30代 | 女性 | NaN | NaN | NaN | NaN | NaN | 1.0 |
| 2 | 3 | 130001 | 東京都 | NaN | 2020-01-30 | 木 | NaN | 湖南省長沙市 | 30代 | 女性 | NaN | NaN | NaN | NaN | NaN | 1.0 |
| 3 | 4 | 130001 | 東京都 | NaN | 2020-02-13 | 木 | NaN | 都内 | 70代 | 男性 | NaN | NaN | NaN | NaN | NaN | 1.0 |
| 4 | 5 | 130001 | 東京都 | NaN | 2020-02-14 | 金 | NaN | 都内 | 50代 | 女性 | NaN | NaN | NaN | NaN | NaN | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 28131 | 28031 | 130001 | 東京都 | NaN | 2020-10-14 | 水 | NaN | NaN | 10歳未満 | 男性 | NaN | NaN | NaN | NaN | NaN | NaN |
| 28132 | 28032 | 130001 | 東京都 | NaN | 2020-10-14 | 水 | NaN | NaN | 20代 | 男性 | NaN | NaN | NaN | NaN | NaN | NaN |
| 28133 | 28033 | 130001 | 東京都 | NaN | 2020-10-14 | 水 | NaN | NaN | 70代 | 男性 | NaN | NaN | NaN | NaN | NaN | NaN |
| 28134 | 28034 | 130001 | 東京都 | NaN | 2020-10-14 | 水 | NaN | NaN | 20代 | 女性 | NaN | NaN | NaN | NaN | NaN | NaN |
| 28135 | 28035 | 130001 | 東京都 | NaN | 2020-10-14 | 水 | NaN | NaN | 40代 | 女性 | NaN | NaN | NaN | NaN | NaN | NaN |
28136 rows × 16 columns
必要なのは人数だけなので、groupby と size で日付ごとの件数を出します。
covid_daily = covid_src.groupby("公表_年月日").size()
covid_daily.index.name = 'date'
covid_daily
date
2020-01-24 1
2020-01-25 1
2020-01-30 1
2020-02-13 1
2020-02-14 2
...
2020-10-10 249
2020-10-11 146
2020-10-12 78
2020-10-13 166
2020-10-14 177
Length: 239, dtype: int64
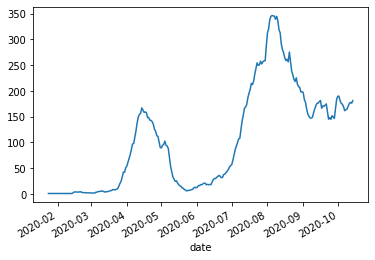
単に日付ごとの件数をグラフに描くとこのようにジグザグになります。
covid_daily.plot()
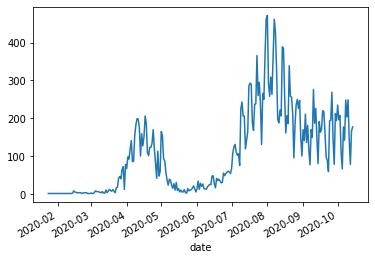
一週間の window を設定して陽性患者の傾向を掴みます。ここで、今までの sum() の代わりに mean() を使うと移動平均になります。
covid_daily.rolling(window='7D').mean().plot()