はじめに(Headless CMSとは)
Headless CMSを一言で説明すると「コンテンツを表示する機能を持たず、APIでコンテンツの配信を行うCMS」になります。従来のCMSはコンテンツを管理するバックエンドの機能とコンテンツを表示するフロントエンドの機能が一体となっていますが、Headless CMSでは画面テンプレートのようなフロントエンドの機能を持っていません。従来のCMSをCoupled(一体型) CMSと呼ぶのに対して、Headless CMSをDecoupled(分離型) CMSと呼ぶ場合もあります。
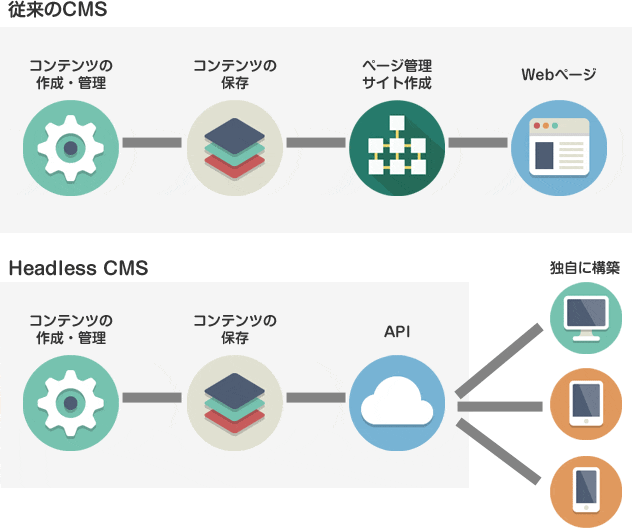
従来のCMSはサイトの枠組みが出来上がった状態から構築を行うことができるため誰でも素早く簡単にサイトを立ち上げることができます。一方でCMSの枠組みに縛られるため自由自在にサイトを構築するという訳にはいきません。
一方、Headless CMSはサイトを構築するための機能はありませんが、様々な形態のコンテンツをAPIを介して簡単に配信することができるため、フロントエンドを自由自在に作ることができます。一つのコンテンツを複数のチャネルに配信することもできますし、フロントエンドとバックエンドが切り離されているためセキュリティを確保しやすいといったメリットもあります。
そこで、今回はHeadless CMSの一つであるStrapiを使って静的サイトを構築してみたいと思います。
Strapiとは
StrapiはNode.js製のオープンソースHealess CMS(MITライセンス)で、2015年から開発が進められています。
https://strapi.io/
https://github.com/strapi/strapi
安定版の1.6.x系とは別に次期バージョンの3.0.0系の開発が進められており、月に1~2回のペースで継続的にリリースが行われています。
ではStrapiの仕組みを簡単に見てみましょう。
インストール&プロジェクトの作成
ここでは次期バージョンの3.0.0(アルファ版)を使用します。インストール前に以下の環境を準備しておいてください。
- Node.js v9.0.0以上
- npm v5.0.0以上
- mongoDB v3.4以上
最初に以下のコマンドでstrapiをインストールします。
npm install strapi@alpha -g
次にstrapiのCLIツールを使ってプロジェクトを作成します。
strapi new <project name>
そうすると対話式でプロジェクトの設定が行われますので、デフォルトの設定で問題ない場合はそのままEnterを押して進めて行きます。
Choose your main database:
? MongoDB (highly recommended)
Postgres
MySQL
Sqlite3
Redis
プロジェクトの作成が終わったらプロジェクトフォルダに移動してサーバを起動します。
cd <project name>
strapi start
サーバのhostはデフォルトでlocalhostになっています。VagrantのゲストOSで起動させる場合は設定ファイルのhostを0.0.0.0に変更してホストOSからアクセスできるようにしてください。
{
"host": "0.0.0.0",
"port": 1337,
"autoReload": {
"enabled": true
},
"cron": {
"enabled": false
}
}
サーバを起動したら以下のURLにアクセスします。
そうすると管理者アカウントの登録画面にリダイレクトされますので、アカウントの登録を行います。

アカウントの登録を行うと管理画面が表示されます。
APIを作成する
早速APIを作成してみましょう。デフォルトでContent Type Builderというプラグインがインストールされており、画面から作成することができます。左のメニューから「Content Type Builder」を選択します。
既に4つのコンテンツタイプが登録されていますが、「Add Content Type」から登録画面を開きコンテンツタイプの名前を入力して保存します。
まだこの状態だとフィールドがありませんので、フィールドを追加していきます。「Add New Field」をクリックすると追加するフィールドのタイプを選択する画面が開きます。
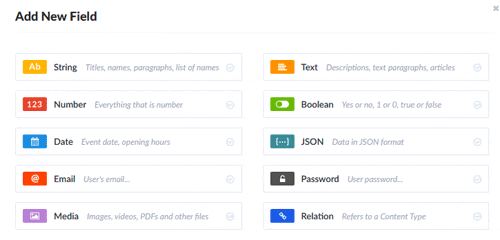
用意されているタイプは以下の10種類になります。
- String
- Text
- Number
- Boolean
- Date
- JSON
- Password
- Media(画像、動画など)
- Relation(コンテンツタイプ間の参照)
適当にフィールドを追加して保存します。
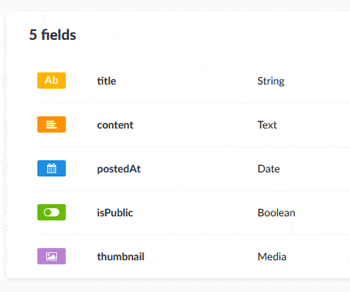
そうすると左メニューに追加したコンテンツタイプが表示されますので、コンテンツタイプを選択してください。登録データの一覧画面が表示されます。
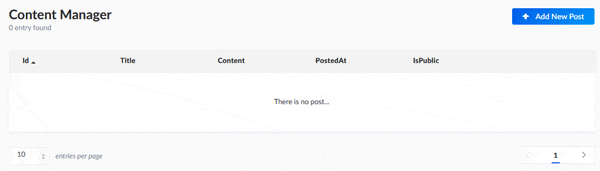
まだデータはありませんので、追加ボタンをクリックして登録画面を開きます。そうするとフィールドのタイプに合わせて入力フィールドが表示されますので適当に入力して登録します。
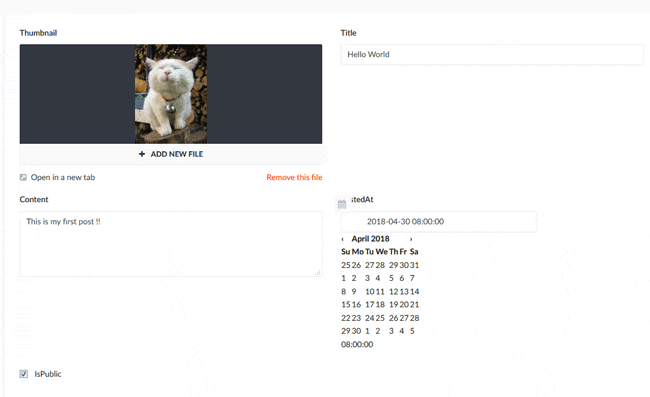
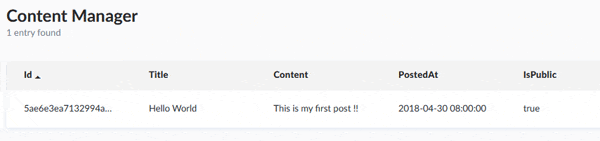
せっかくなのでDBの中身を確認してみます。作成したコンテンツタイプの名前がそのままコレクション名となり、追加したデータが登録されていることが確認できました。ただ、画像のフィールドが見当たりません。
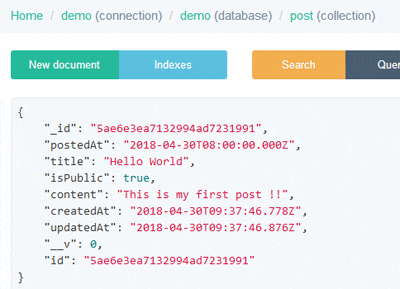
画像はupload_fileというコレクションに保存されており、大元のデータとリレーションが張られていることが確認できます。

画像の実ファイルはプロジェクトフォルダ内のpublic/uploads配下に保存されています。
ではAPIを介して登録したデータを取得してみたいと思います。APIはデフォルトでインストールされているRoles & Permissionsというプラグインによってアクセスを制限されています。左メニューの「Roles & Permissions」を選択すると既に登録されているロールが3つありますので、ログインしていないユーザーのロールを表す「Public」を選択します。

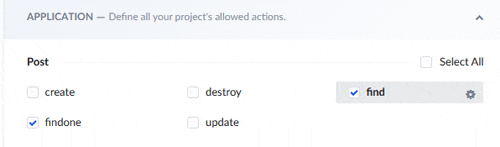
ロールの編集画面でAPPLICATIONの欄にコンテンツタイプとCRUDアクションが表示されていますので、許可したいアクションにチェックを付けて保存します。
これでAPIをコールする準備が整いました。以下のエンドポイントにGETメソッドでリクエストを投げてみます。
そうすると以下のようにJSON形式でデータが返って来ました。画像とそれ以外のデータは別々のコレクションに保存されていましたが、ちゃんとリレーションを解決して結果が返ってきていることが分かります。
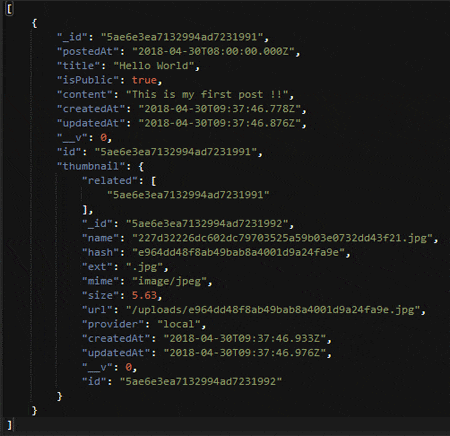
Strapiの基本的な仕組み
GUI操作でAPIを作成する流れを説明しましたが、もう少しStrapiの中身を見てみたいと思います。StrapiはContent Management Frameworkと謳っているようにコントローラ、サービス、モデルの3層に分かれたフレームワークがベースとなり、そこに管理画面が付属しているような形になります。フォルダ構成は以下のようになっています。
- /admin - 管理系のフロントエンドやバックエンドのロジックが入っている
- /api
- /**
- /config - ルーティングの設定情報が入っている
- /controllers - リクエストを受けるけるコントローラ
- /models - コレクションに対応するモデル
- /services - APIのロジックを実装するサービス
- /**
- /config - プロジェクトに関する各種設定ファイルが入っている
- /hooks - プロジェクトでカスタムフックを追加する場合はここに入れる
- /middlewares - プロジェクトでカスタムミドルウェアを追加する場合はここに入れる
- /plugins - プラグインがインストールされる場所
- /public - アップロードした画像など外部からアクセスできるリソースを格納する場所
コントローラやサービス、モデルは画面でコンテンツタイプを作成したタイミングで自動的に作成されます。APIの処理をカスタマイズしたい場合はこれらのプログラムを修正したり、カスタムのフックやミドルウェアを追加する形になります。
もう少し中身を詳しく見てみましょう。StrapiのHTTPレイヤーはWebフレームワークのKoaをベースに作られており、複数のミドルウェアを中継してリクエストがコントローラに渡り、レスポンスがクライアントに返却されます。

標準で用意されているミドルウェアは以下の通りです。
- boom - httpエラー処理
- cors - CORS(Cross-Origin Resource Sharing)の制御
- cron - スケジュールジョブの制御
- csp - Content Security Policyの制御
- csrf - CSRF攻撃の防御
- favicon - faviconの設定
- gzip - レスポンスのgzip圧縮
- hsts - HTTP Strict Transport Securityの制御
- ip - IPアドレスのホワイトリスト、ブラックリストによるアクセス制御
- language - 多言語対応
- logger - ロギング処理
- mask - Modelのマスキング処理(APIで取得できるフィールドを制限する)
- p3p - P3P(Platform for Privacy Preferences)の設定
- parser - フォームやJSON、テキストなどのリクエストbodyの解析
- public - 外部公開フォルダの設定
- responses - レスポンスの作成
- responseTime - レスポンスタイムの計測
- router - ルーティング処理
- session - セッションの制御
- xframe - X-Frame-Optionsの設定
- xss - XSS攻撃の防御
さらにデフォルトでインストールされているプラグインのミドルウェアがあります。
- users-permissions
これら全てのミドルウェアがサーバ起動時にロードされる訳ではなく、ミドルウェアのデフォルト設定ファイルdefault.jsonでenabledがtrueに設定されているものがロードされます。
{
"boom": {
"enabled": true
}
}
{
"csrf": {
"enabled": false,
"key": "_csrf",
"secret": "_csrfSecret"
}
}
ただし、プロジェクトのconfigフォルダ内にある環境ファイルによって有効・無効を上書きすることができます。
{
"csrf": {
"enabled": true,
"key": "_csrf",
"secret": "_csrfSecret"
}
}
ミドルウェアは非同期でロードされるため、ロード順序は保証されません。ただし、configフォルダ内にあるmiddleware.jsonによってロード順序を制御することができます。
例えば以下の10個のミドルウェアがロードされるとします。
- cors
- cron
- favicon
- gzip
- logger
- p3p
- parser
- response
- responseTime
- router
そして、middleware.jsonを以下のように設定します。
{
"timeout": 100,
"load": {
"before": [
"responseTime",
"logger",
"cors",
],
"order": [
"p3p",
"gzip"
],
"after": [
"parser",
"router"
]
}
}
そうするとミドルウェアがロードされる順序は以下のようになります。
- responseTime (beforeの1番目)
- logger (beforeの2番目)
- cors (beforeの3番目)
- favicon (beforeとafterの間、順序の保証はない)
- p3p(beforeとafterの間、gzipの前)
- cron (beforeとafterの間、順序の保証はない)
- gzip (beforeとafterの間、p3pの後)
- response (beforeとafterの間、順序の保証はない)
- parser (afterの1番目)
- router (afterの2番目)
次にコントローラやサービス、モデルについて簡単に見てみましょう。
コントローラのアクションはAPIのconfigディレクトリ内にあるroutes.jsonの設定に従って呼び出されます。
{
"routes": [
{
"method": "GET",
"path": "/post",
"handler": "Post.find",
"config": {
"policies": []
}
},
上記の設定だと/postにGETリクエストがあった場合にcontrollers/Post.jsのfindアクションが実行されます。
find: async (ctx) => {
return strapi.services.post.fetchAll(ctx.query);
},
コントローラから呼び出されるサービスは以下のようになっています。
fetchAll: (params) => {
const convertedParams = strapi.utils.models.convertParams('post', params);
return Post
.find()
.where(convertedParams.where)
.sort(convertedParams.sort)
.skip(convertedParams.start)
.limit(convertedParams.limit)
.populate(_.keys(_.groupBy(_.reject(strapi.models.post.associations, {autoPopulate: false}), 'alias')).join(' '));
},
サービスの実装は選択したデータストアによって変わってくるのですが、今回はMongoDBをデータストアにしているため、MongooseのModelインスタンスが上記のPostに入ります。
ModelにはCRUD操作の前後に処理を差し込むための拡張ポイントが設けられており、自動生成されたモデルにコメントアウトされた状態でメソッドが用意されていますので、それを利用して実装する形になります。
module.exports = {
// Before saving a value.
// Fired before an `insert` or `update` query.
// beforeSave: async (model) => {},
// After saving a value.
// Fired after an `insert` or `update` query.
// afterSave: async (model, result) => {},
ほんの一部分の紹介でしたが、以上がStrapiの基本的な仕組みになります。このように自動生成したAPIを柔軟にカスタマイズできるのがStrapiの大きな特徴になります。
Gatsbyとは
GatsbyはReactを使って静的サイトを作ることができるフレームワークです。Reactの公式サイトもこのGatsbyで作られています。
https://www.gatsbyjs.org/
https://github.com/gatsbyjs/gatsby
データソースとビューの間をGraphQLが仲介することにより、CMSやデータベース、ファイルなどデータソースの差異を意識することなくビューを作ることができます。

(image source:https://www.gatsbyjs.org/)
ではGatsbyの仕組みを簡単に見てみましょう。
インストール&サイトの作成
最初に以下のコマンドでGatsbyのCLIをインストールします。
npm install gatsby-cli -g
次にGatsbyのCLIツールを使ってサイトを作成します。
gatsby new <site directory>
もしくはスターターを指定して作成することもできます。
gatsby new <site directory> <url of starter github repo>
スターターには公式が提供するものとコミュニティが提供するものがあり、一覧は以下のURLから確認できます。
利用するスターターによってフォルダ・ファイル構成は多少異なりますが、基本的な構成は以下のような形になります。
- gatsby-browser.js - Gatsby Browser APIを使ったカスタマイズ処理を記述する(カスタマイズしないのであればファイル不要)
- gatsby-config.js - サイトの設定やプラグインの設定などを定義する
- gatsby-node.js - Gatsby Node APIを使ったカスタマイズ処理を記述する
- gatsby-ssr.js - Gatsby Server Rendering APIを使ったカスタマイズ処理を記述する(カスタマイズしないのであればファイル不要)
- src
- components - コンポーネントを格納する
- xxxx.js
- layouts - レイアウトファイルを格納する
- index.js、index.css
- pages - ページファイルを格納する
- xxxx.js
- templates - ページのテンプレートファイルを格納する
- xxxx.js
- components - コンポーネントを格納する
- static - モジュールシステムの管理外のアセットを格納する
- xxxx.ico、robots.txt、...etc
Gatsbyの基本的な仕組み
ライフサイクルと3つのAPI
Gatsbyには3つのフェーズがあります。

始めにデータソースやsrc配下に置いたリソースファイルをもとにサイトストラクチャが構成されます。そして、その情報をもとに静的ファイルへのレンダリングを行います。そして、デプロイ後にクライアント側のブラウザでReactコンポーネントとしてレンダリングされます。
もう少し詳しく見てみましょう。まず、Gatsbyのビルドコマンドを実行すると以下のように様々なプロセスを経てサイトストラクチャが構成されます。
- 設定ファイル(gatsby-config.js)のロード
- プラグインのロード
- .cacheフォルダのリセット
- GraphQLスキーマの作成
- レイアウトデータの作成
- ページデータの作成
- GraphQLのクエリ実行
- .cacheフォルダにページなどのファイルを出力
Gatsbyでは上記プロセスにおいて変化するサイトストラクチャ(state)の管理をReduxを使って行っています。stateは以下のようなオブジェクトツリーになっています。
{
program: {......},
nodes: {......},
nodesTouched: {......},
lastAction: {......},
plugins: {......},
flattenedPlugins: {......},
apiToPlugins: {......},
config: {......},
pages: {......},
layouts: {......},
schema: {......},
status: {......},
componentDataDependencies: {......},
components: {......},
jobs: {......},
redirects: {......},
}
このstateの更新はプラグインを介して行います。例えば、自動ロードされるプラグインの一つにcomponent-page-creatorというものがありますが、これはsrc/pages配下にあるファイルを読み込んでstateの中のpagesを更新します。internal-data-bridgeという自動ロードされるプラグインはpagesをもとにnodesを作成します。
自動ロードされるプラグインの一つにdefault-site-pluginというものがありますが、これはサイトのルートフォルダ直下(srcフォルダと同じ階層)にあるgatsby-xxxx.jsのことを表します。例えばsrc/pages以外のデータソースからページを作成したい場合があるでしょう。このような場合は、gatsby-node.jsに処理を記述します。
前述したように様々なプロセスを経てstateは更新されるため、好き勝手にstateを更新していては整合性が取れなくなってしまいます。そこで用意されているのがGatsby Node APIです。
gatsby-node.jsに必要なAPIを定義して、その中に処理を記述します。
exports.createPages = () => {
// ページを追加する処理をここに記述する
};
exports.onCreateNode = () => {
// 他のプラグインによって作成されたノードに対する処理をここに記述する
};
そうするとstateのflattenedPluginsのnodeAPIsにgatsby-node.jsで定義したAPIが登録されます。flattenedPluginsにはdefault-site-plugin以外に読み込まれた全てのプラグインが展開されます。
{
resolve: '/my_site/node_modules/gatsby/dist/internal-plugins/component-page-creator',
name: 'component-page-creator',
nodeAPIs: [ 'createPagesStatefully' ],
....
},
{
resolve: '/my_site',
name: 'default-site-plugin',
nodeAPIs: [ 'createPages', 'onCreateNode' ],
....
}
そして、特定のAPIが実行されるタイミングが来たらプラグインのnodeAPIsを走査して、該当するプラグインを順次実行します。これにより整合性を崩すことなくstateを更新することができます。
stateを更新する際はAction CreatorのコレクションであるBound Action Creatorsを使用します。
exports.onCreateNode = ({ node, getNode, boundActionCreators }) => {
const { createNodeField } = boundActionCreators;
// ノードを拡張して独自のフィールドを追加する
createNodeField({
node,
name: `xxxx`,
value: `xxxx`,
});
};
Gatsby Node APIについて簡単に紹介しましたが、この他にGatsby SSR APIとGatsby Browser APIがあります。
https://www.gatsbyjs.org/docs/ssr-apis/
https://www.gatsbyjs.org/docs/browser-apis/
Gatsby SSR APIはサーバ側でのレンダリング時の処理をカスタマイズするためのものです。gatsby-ssr.jsにAPIを定義します。
// 例:ボディコンポーネントの後にスクリプトを追加する
exports.onRenderBody = ({ setPostBodyComponents }) => {
return setPostBodyComponents([
<script
key={`xxxxxxxxxx`}
dangerouslySetInnerHTML={{
__html: `
(function(d) {
xxxxxxxxx
})(document);`
}}
/>
]);
};
共通のmetaタグを追加したり、scriptを追加するといった単純なカスタマイズであれば、srcフォルダ直下にhtml.jsを設置する方法もあります。.cacheフォルダの中にdefault-html.jsというファイルがありますので、それをコピーして編集してください。
module.exports = class HTML extends React.Component {
render() {
let css
if (process.env.NODE_ENV === `production`) {
css = (
<style
id="gatsby-inlined-css"
dangerouslySetInnerHTML={{ __html: stylesStr }}
/>
)
}
return (
<html {...this.props.htmlAttributes}>
<head>
<meta charSet="utf-8" />
<meta httpEquiv="x-ua-compatible" content="ie=edge" />
<meta
name="viewport"
content="width=device-width, initial-scale=1, shrink-to-fit=no"
/>
{this.props.headComponents}
{css}
</head>
<body {...this.props.bodyAttributes}>
{this.props.preBodyComponents}
<div
key={`body`}
id="___gatsby"
dangerouslySetInnerHTML={{ __html: this.props.body }}
/>
{this.props.postBodyComponents}
</body>
</html>
)
}
}
レンダリングされ静的ファイルに出力されたページはブラウザ側でReactコンポーネントとしてレンダリングされます。ブラウザ側での動作をカスタマイズするために用意されているのがGatsby Browser APIです。gatsby-browser.jsにAPIを定義します。
// 例:ルートが更新されたらGoogle Analyticsにページビューイベントを送信する
exports.onRouteUpdate = function({ location }) {
ga('set', 'page', location ? location.pathname : undefined);
ga('send', 'pageview');
};
GraphQL
CMSやデータベース、ファイルなど様々なデータソースから取得したデータはGraphQLを介して参照することができます。以下はStrapiから取得した投稿データの一覧ページの実装例です。
const BlogPage = ({ data }) => {
const posts = data.allStrapiPost.edges.map(edge =>
<article key={edge.node.id}>
<h2><a href={`/blog/${edge.node.slug}/`}>{edge.node.title}</a></h2>
<div>posted at {edge.node.createdAt}</div>
<p>{edge.node.description}</p>
</article>
);
return (
<section>{posts}</section>
);
};
export default BlogPage;
export const query = graphql`
query BlogQuery {
allStrapiPost(
sort: { fields: [createdAt], order: DESC }
) {
edges {
node {
id
title
description
slug
createdAt(formatString: "DD MMMM YYYY")
}
}
}
}
`;
queryという定数にGraphQLのクエリが記述されています。このクエリの結果がBlogPageというReactエレメントに渡されます。ただし、GraphQLのクエリが実行されるタイミングでStrapiのAPIがコールされる訳ではありません。もう少し詳しく見てみましょう。
GatsbyからStrapiのデータを参照するにはgatsby-source-strapiというプラグインを使用します。gatsby-config.jsに以下のようにプラグインを設定します。
module.exports = {
plugins: [
{
resolve: `gatsby-source-strapi`,
options: {
apiURL: `http://localhost:1337`,
contentTypes: [
`post`,
],
},
},
],
};
ライフサイクルの説明で少し触れましたが、ビルドを行うとまずプラグインがロードされます。このタイミングでgatsby-source-strapiはcontentTypesに指定されたデータセットをAPIから取得します。そして、Gatsby Node APIを使用してstateのnodeにデータセットを追加します。これはファイルなど他のデータソースから取得した場合も同様にstateのnodeにデータセットが追加されます。
そして、データソースから取得したデータが全てnodeに反映されると、nodeからGraphQLのスキーマが作成されます。その後query-runnerというプラグインがsrc/pages配下にあるjsファイルをパースしてGraphQLのクエリを抽出します。そして、クエリの実行結果を.cache/json配下にJSONファイルとして保存します。
保存されたJSONファイルはレンダリング時に読み込まれ、サンプルソースで示したReactエレメントに渡される形になります。つまり、データソースからのデータ取得は最初に行われ、GraphQLはそのデータから必要なものだけを抽出しているということになります。ブラウザ実行時にサーバから取得するといったものではありません。
GraphQLの書き方などについては公式サイトを参考にしてください。
サイトを作ってみる
StrapiとGatsbyの仕組みを説明しましたので、実際に簡単なブログサイトを作ってみたいと思います。

データソースとしてstrapiから投稿メタデータやタグを取得し、投稿データはQiitaからダウンロードしたマークダウンファイルを使用します。そして、Gatsbyで静的サイトに変換しNetlifyにデプロイします。
実際にNetlifyにデプロイしたサイトは以下のURLからご覧いただけます。
https://silly-panini-98e601.netlify.com/
では、StrapiでのAPI作成、Gatsbyでのサイト作成、Netlifyへのデプロイを順を追って見てみましょう。
StrapiでAPIを作成する
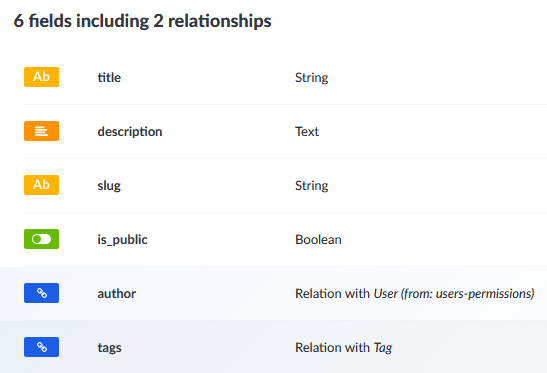
まずはContent Type Builderから投稿メタデータとタグのコンテンツタイプを作成します。投稿メタデータはタイトル、概要、スラッグ、公開フラグ、投稿者、タグの6つのフィールドを定義します。
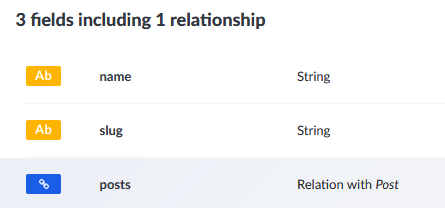
タグは名前、スラッグ、投稿の3つのフィールドを定義します。
これで定義は完了です。タグを以下のように適当に登録してみます。

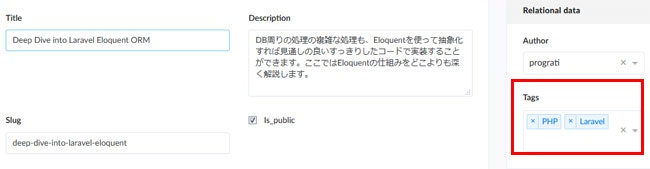
投稿画面は以下のような感じになっています。タグとMany-to-manyのリレーションを張っているので登録したタグが複数選択できるようになっています。
あとは、投稿を登録していけば完了です。と言いたい所ですが、このまま投稿を保存しても投稿に紐づくタグのデータは保存されません。保存して投稿を開き直してもタグがリセットされて空の状態になってしまいます。
コンテンツタイプを作成した時点でコントローラやサービス、モデルが自動的に作成されることは前述しましたが、モデルの定義もjsonファイルとして作成されます。以下は投稿モデルの定義です。
{
"connection": "default",
"collectionName": "post",
"info": {
"name": "post",
"description": ""
},
"options": {
"timestamps": true
},
"attributes": {
"title": {
"multiple": false,
"type": "string"
},
"description": {
"multiple": false,
"type": "text"
},
"slug": {
"multiple": false,
"type": "string"
},
"is_public": {
"multiple": false,
"type": "boolean"
},
"author": {
"model": "user",
"via": "posts",
"plugin": "users-permissions"
},
"tags": {
"collection": "tag",
"via": "posts",
"dominant": true
}
}
}
ここで、tagsの部分に"dominant": trueという設定があります。これは画面からではなくエディタで直接追加したものです。この設定によって、投稿データがタグとのリレーションの情報を保持することができるようになります。リレーションというとモデル同士がキーを持ってリレーションを張っているイメージがしますが、実際は片方のモデルがリレーションのためのキーを保持する形になります。上記の設定だと投稿にタグを2つ付けて保存すると投稿データにタグのキーが2つ登録されることになります。
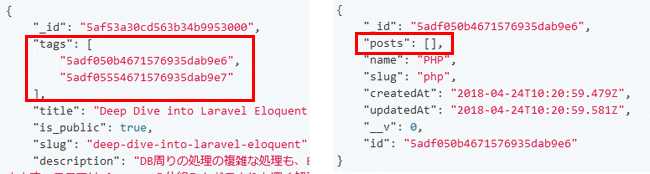
これで準備は完了です。APIから投稿データを取得してみるとタグのデータも一緒に展開されて取得することができます。
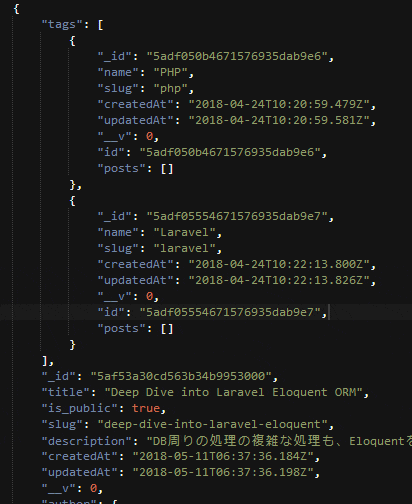
せっかくなのでAPIを少しカスタマイズしてみます。投稿データには公開フラグというものを定義しました。GatsbyのGraphQL側で公開フラグをもとにデータを絞っても良いのですが、公開フラグがtrueのデータのみAPIから取得できるようにしたいと思います。
APIに条件を追加するためにサービスを修正します。修正前のソースが以下のようになっています。
fetchAll: (params) => {
const convertedParams = strapi.utils.models.convertParams('post', params);
return Post
.find()
.where(convertedParams.where)
.sort(convertedParams.sort)
.skip(convertedParams.start)
.limit(convertedParams.limit)
.populate(_.keys(_.groupBy(_.reject(strapi.models.post.associations, {autoPopulate: false}), 'alias')).join(' '));
},
これにwhere条件を1行追加して以下のようにします。
fetchAll: (params) => {
const convertedParams = strapi.utils.models.convertParams('post', params);
return Post
.find()
.where(convertedParams.where)
.where('is_public').eq(true)
.sort(convertedParams.sort)
.skip(convertedParams.start)
.limit(convertedParams.limit)
.populate(_.keys(_.groupBy(_.reject(strapi.models.post.associations, {autoPopulate: false}), 'alias')).join(' '));
},
これでAPIで取得できるデータを公開フラグがtrueのデータのみに制限できるようになりました。
Gatsbyでサイトを構築する
トップページおよびタグページに記事一覧を表示し、そこから各記事ページに遷移するというような簡単なサイト構成で作ってみましょう。今回はプロジェクトのフォルダ構成を以下のようにしました。
- src
- components - ページを構成する各種Reactコンポーネント
- images - サイト内で使用する画像
- layouts - レイアウトファイル
- pages - ページファイル
- styles - サイト全体に適用するCSS
- templates - テンプレートファイル
- static
- icon - アイコン
- content
- posts
- yyyy-mm-dd-(記事のスラッグ) - マークダウンファイルや画像
- posts
Qiitaからダウンロードしたマークダウンファイルおよび画像ファイルはcontentフォルダの中に2018-06-01-xxxxxxxのような形式で記事ごとに日付+スラッグ名のフォルダを作り、その中に保存します。(今回はpage-1.md、page-2.mdのように一つの記事を複数ページに分けています)
ここからは主要なファイルの中身について簡単に説明していきます。
gatsby-config.js
gatsby-config.jsは主にプラグインの設定が中心になります。
const config = require("./src/web-config");
module.exports = {
siteMetadata: {
title: config.siteTitle,
description: config.siteDescription,
},
plugins: [
'gatsby-plugin-react-helmet',
'gatsby-plugin-sass',
{
resolve: 'gatsby-source-filesystem',
options: {
path: `${__dirname}/content/posts/`,
name: 'posts'
}
},
{
resolve: 'gatsby-transformer-remark',
options: {
plugins: [
{
resolve: 'gatsby-remark-copy-linked-files',
options: {
destinationDir: 'static',
ignoreFileExtensions: [],
}
},
'gatsby-remark-prismjs',
'gatsby-remark-emoji'
]
}
},
'gatsby-plugin-sharp',
'gatsby-transformer-sharp',
{
resolve: 'gatsby-source-strapi',
options: {
apiURL: 'http://localhost:1337',
contentTypes: [
'post',
'tag',
],
},
},
{
resolve: 'gatsby-plugin-manifest',
options: {
name: config.manifestName,
short_name: config.manifestShortName,
start_url: config.manifestStartUrl,
background_color: config.manifestBackgroundColor,
theme_color: config.manifestThemeColor,
display: config.manifestDisplay,
icons: [
{
src: "/icon/icon-192x192.png",
sizes: "192x192",
type: "image/png"
}
]
}
},
'gatsby-plugin-offline',
],
}
使用するプラグインについて一部抜粋してご説明します。gatsby-source-filesystemプラグインはファイルをデータソースとして扱うためのプラグインです。ファイルを読み込みFileノードを作成します。今回はcontentフォルダの配下にマークダウンファイルや画像を配置しましたので、pathを指定してファイルを読み込んでいます。
そして、Fileノードに追加されたマークダウンファイルを処理するのがgatsby-transformer-remarkプラグインです。このプラグインによってマークダウンがHTMLに変換されます。このままでもHTMLとしてページを表示することはできますが、画像が表示されないなど調整が必要なためプラグインをオプションで追加しています。
今回、マークダウンファイルの中の画像パスは以下のように手元にダウンロードした画像への相対パスに書き換えています。

contentフォルダにある画像への相対パスなので、このままHTML化しても画像を参照することは出来ません。そこでマークダウン内の画像を処理するプラグインを利用します。プラグインにはgatsby-remark-imagesというものがあり、マークダウンが参照している画像をレスポンシブ画像(srcset)に変換してリンクも置換してくれます(ただし、png、jpg、bmp、tiffには対応していますがgifには対応していません)。
今回はレスポンシブ画像ではなく元の解像度のまま画像を利用したいのでgatsby-remark-copy-linked-filesというプラグインを使用しています。こちらはファイルをpublicフォルダにコピーして、そのファイルへのリンクに置換してくれます。
destinationDirに出力先のディレクトリとしてstaticを指定しているのでpublicフォルダ内にstaticフォルダを作成して、そこに画像がコピーされます。imgタグの画像の参照パスも以下のように置換されます。
<!-- プラグイン使用前 -->
<img src="./c4f6508e-9381-9d63-47bd-689d88f2d9bf.png"/>
<!-- プラグイン使用後 -->
<img src="/static/c4f6508e-9381-9d63-47bd-689d88f2d9bf.png"/>
これで画像を表示することはできるようになりましたが、さらに見た目を調整するために2つプラグインを指定しています。gatsby-remark-prismjsプラグインはコードブロックにシンタックスハイライトを当てるためのプラグインです。gatsby-remark-emojiはマークダウンに埋め込まれたemojiをbase64形式のデータに変換してimgタグとして埋め込んでくれるプラグインになります。
gatsby-node.js
gatsby-node.jsでは記事ページやタグページの作成を行っています。通常の固定ページはsrcのpages配下にjsファイルを作成しますが、今回は記事毎にjsファイルを作るのではなく、テンプレートファイルを作ってそこに読み込んだマークダウンを流し込む形になります。また、タグページもタグ毎にページを作るのではなくテンプレートファイルから動的に作成します。
exports.createPages = async ({ graphql, boundActionCreators }) => {
const { createPage } = boundActionCreators;
const postTemplate = path.resolve(`src/templates/post.js`);
const tagTemplate = path.resolve(`src/templates/tag.js`);
const posts = await graphql(
`
{
allStrapiPost {
edges {
node {
slug
fields {
pageCount
}
}
}
}
}
`
);
if (posts.errors) {
console.error(posts.errors);
throw Error(posts.errors);
}
posts.data.allStrapiPost.edges.map(({ node }) => {
const pageCount = node.fields.pageCount;
for (i = 1; i <= pageCount; i++) {
createPage({
path: i == 1 ? `/blog/${node.slug}/` : `/blog/${node.slug}/${i}/`,
component: slash(postTemplate),
context: {
slug: node.slug,
page: i
}
});
}
});
const tags = await graphql(
`
{
allStrapiTag {
edges {
node {
slug
}
}
}
}
`
);
if (tags.errors) {
console.error(tags.errors);
throw Error(tags.errors);
}
tags.data.allStrapiTag.edges.map(({ node }) => {
createPage({
path: `/tag/${node.slug}/`,
component: slash(tagTemplate),
context: {
slug: node.slug
}
});
});
};
まず最初に全ての記事のスラッグを取得し、スラッグベースのURLで記事ページを作成しています。テンプレートにはtemplatesディレクトリ配下のpost.jsを利用し、テンプレートにスラッグとページ番号を渡しています。次に全てのタグのスラッグを取得し、こちらも記事と同じようにスラッグベースのURLでタグページを作成しています。
また、gatsby-node.jsではページの作成に加えてノードフィールドの追加を行っています。
const BLOG_POST_FILENAME_REGEX = /([0-9]+)\-([0-9]+)\-([0-9]+)\-(.+)\/page\-([0-9]+)\.md$/;
const BLOG_THUMBNAIL_REGEX = /.+\/content\/posts\/[0-9]+\-[0-9]+\-[0-9]+\-(.+)\/thumbnail\.png.+/;
exports.onCreateNode = ({ node, getNode, boundActionCreators }) => {
const { createNodeField } = boundActionCreators;
let slug, match;
switch (node.internal.type) {
case 'MarkdownRemark':
const { relativePath } = getNode(node.parent);
match = BLOG_POST_FILENAME_REGEX.exec(relativePath);
const year = match[1];
const month = match[2];
const day = match[3];
const filename = match[4];
const pageNo = match[5];
slug = filename;
createNodeField({
node,
name: 'slug',
value: slug,
});
const date = new Date(year, month - 1, day);
createNodeField({
node,
name: 'postedAt',
value: date.toJSON(),
});
createNodeField({
node,
name: 'pageNo',
value: parseInt(pageNo, 10),
});
break;
case 'ImageSharp':
match = BLOG_THUMBNAIL_REGEX.exec(node.id);
if (match !== null) {
slug = match[1];
createNodeField({
node,
name: 'slug',
value: slug,
});
}
break;
case 'StrapiPost':
slug = node.slug;
const nodes = Object.values(store.getState().nodes).filter(node => node.internal.type === 'MarkdownRemark' && node.fields.slug == slug);
if (nodes.length > 0) {
createNodeField({
node,
name: 'postedAt',
value: nodes[0].fields.postedAt,
});
createNodeField({
node,
name: 'pageCount',
value: nodes.length,
});
}
break;
}
};
MarkdownRemarkはgatsby-transformer-remarkプラグインによって作成されたマークダウンのノードです。記事データはcontentフォルダの配下にyyyy-mm-dd-(記事のスラッグ)という形式でフォルダを作って配置しましたので、そのフォルダ名を利用してマークダウンノードにスラッグと投稿日を追加しています。
ImageSharpはgatsby-transformer-sharpプラグインによって作成された画像ファイルのノードです。今回記事の画像ファイルとは別にアイキャッチ用のサムネイル画像をthumbnail.pngという名前で配置しています。そのサムネイル画像を扱うために画像ファイルのノードにスラッグを追加しています。
StrapiPostはgatsby-source-strapiプラグインによって作成された記事データのノードです。ここではマークダウンのノードを利用して投稿日やページ数をノードに追加しています。
トップページ
トップページは記事の一覧を表示します。それに関わるファイルをいくつか見てみましょう。まずはレイアウトファイルです。
import React from 'react';
import Sidebar from '../components/Sidebar';
import './index.scss';
const Layout = ({ children }) => (
<div className="container">
<div className="columns is-gapless">
<div className="column is-9 colLeft">
{children()}
</div>
<div className="column colRight">
<Sidebar/>
</div>
</div>
</div>
);
export default Layout;
このファイルが全てのページのレイアウトのベースとなります。
次はトップページファイルです。レイアウトファイルの{children()}の部分に渡されるのがこのファイルです。
import React from 'react';
import Link from 'gatsby-link';
import Helmet from 'react-helmet';
import Posts from '../components/Posts';
const config = require("../web-config");
const IndexPage = ({ data }) => (
<div>
<Helmet>
<title>{data.site.siteMetadata.title}</title>
<meta name="description" content={data.site.siteMetadata.description} />
</Helmet>
<Posts data={data} />
</div>
);
export default IndexPage;
export const query = graphql`
query IndexQuery {
site {
siteMetadata {
title
description
}
}
posts: allStrapiPost(
sort: { fields: [fields___postedAt], order: DESC }
) {
edges {
node {
id
title
description
slug
tags {
id
name
slug
}
fields {
postedAt(formatString: "DD MMMM YYYY")
}
}
}
}
thumbnails: allImageSharp(
filter: { fields: { slug: { ne: null } } }
) {
edges {
node {
resolutions(width: 100, height: 100) {
src
}
fields {
slug
}
}
}
}
}
`;
ここではGraphQLから取得したデータを記事一覧を表示するコンポーネントに渡す処理をしています。GraphQLでは記事とサムネイル画像の2つのデータを取得しています。記事データは投稿日の降順でソートし、投稿日の日付書式を変更しています。サムネイル画像にはgatsby-node.jsでスラッグを追加しましたので、全画像データの中からスラッグがnullでないものだけを抽出しています。また、画像はresolutions(width: 100, height: 100)とし100×100のサイズにリサイズしています。このリサイズの処理にはgatsby-plugin-sharpプラグインが必要になります。
そして最後が記事一覧を表示するコンポーネントです。
import React from 'react';
import Link from 'gatsby-link';
import PropTypes from "prop-types";
import { chunk } from 'lodash';
import Tag from './Tag.js';
import styles from './styles.module.scss';
class Posts extends React.Component {
render () {
const { data } = this.props;
let posts = data.posts.edges;
let thumbnails = [];
data.thumbnails.edges.forEach(thumbnail => thumbnails[thumbnail.node.fields.slug] = thumbnail);
// タグが指定されている場合は記事データをタグで絞り込む
if (data.tag) {
const ids = data.tag.posts.map(post => post.id);
posts = posts.filter(post => ids.includes(post.node.id));
}
const columns = posts.map(post =>
<article className="column is-one-third" key={post.node.id}>
<div className={styles.thumbnail}><Link to={`/blog/${post.node.slug}/`} title={post.node.title}><img src={thumbnails[post.node.slug].node.resolutions.src} alt={post.node.title} /></Link></div>
<div className={styles.postedAt}>
<span>{post.node.fields.postedAt}</span>
</div>
<h1><Link to={`/blog/${post.node.slug}/`}>{post.node.title}</Link></h1>
<Tag tags={post.node.tags} />
<p><Link to={`/blog/${post.node.slug}/`} title={post.node.title}>{post.node.description}</Link></p>
</article>
);
const chunkOfColumns = chunk(columns, 3);
const rows = chunkOfColumns.map((chunkOfColumn, index) =>
<div className="columns" key={index}>
{chunkOfColumn}
</div>
);
return (
<main className={styles.posts}>
{rows}
</main>
);
}
}
Posts.propTypes = {
data: PropTypes.object.isRequired
};
export default Posts;
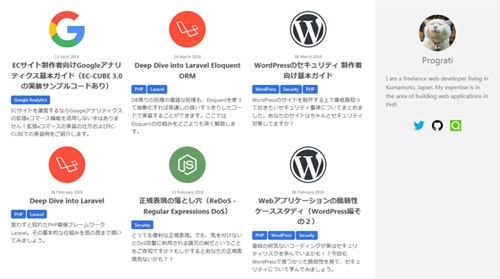
トップページのGraphQLで抽出した記事データを表示しています。最終的には以下のような表示になります。
タグページ
タグページはタグ毎の記事一覧を表示します。レイアウトファイルはトップページで使用したレイアウトファイルを同じです。ページはgatsby-node.jsでテンプレートをもとに作成しましたのでテンプレートファイルを見てみましょう。
import React from 'react';
import Link from 'gatsby-link';
import Helmet from 'react-helmet';
import NavigationHome from '../components/Navigation/Home';
import Posts from '../components/Posts';
const config = require("../web-config");
const TagPage = ({ data }) => (
<div>
<Helmet>
<title>{`${data.tag.name} | ${data.site.siteMetadata.title}`}</title>
<meta name="description" content={`${data.tag.name}に関する投稿の一覧ページです。`} />
</Helmet>
<NavigationHome />
<Posts data={data} />
</div>
);
export default TagPage;
export const query = graphql`
query TaggedPostsQuery($slug: String!) {
site: site {
siteMetadata {
title
}
}
tag: strapiTag(slug: { eq: $slug }) {
name
slug
posts {
id
}
}
posts: allStrapiPost(
sort: { fields: [fields___postedAt], order: DESC }
) {
edges {
node {
id
title
description
slug
tags {
id
name
slug
}
fields {
postedAt(formatString: "DD MMMM YYYY")
}
}
}
}
thumbnails: allImageSharp(
filter: { fields: { slug: { ne: null } } }
) {
edges {
node {
resolutions(width: 100, height: 100) {
src
}
fields {
slug
}
}
}
}
}
`;
トップページとほとんど同じですが、GraphQLの部分でスラッグを条件にしてタグのデータを取得しています。タグデータはそのタグが付いた記事のIDを持っていますので、一覧では全記事の中から該当のIDだけ表示するようにしています。
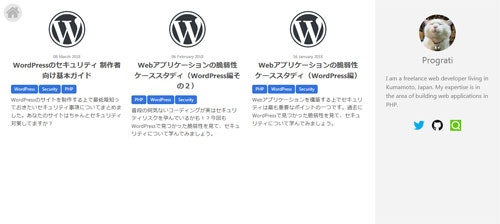
記事ページ
レイアウトファイルはトップページで使用したレイアウトファイルを同じです。ページはgatsby-node.jsでテンプレートをもとに作成しましたのでテンプレートファイルを見てみましょう。
import React from 'react';
import Link from 'gatsby-link';
import Helmet from 'react-helmet';
import '../styles/highligh.css';
import NavigationHome from '../components/Navigation/Home';
import Post from '../components/Post';
const config = require("../web-config");
const PostPage = ({ data }) => (
<div>
<Helmet>
<title>{`${data.post.title} | ${data.site.siteMetadata.title}`}</title>
<meta name="description" content={data.post.description} />
</Helmet>
<NavigationHome />
<Post data={data} />
</div>
);
export default PostPage;
export const query = graphql`
query PostQuery($slug: String!, $page: Int!) {
site: site {
siteMetadata {
title
}
}
post: strapiPost(slug: { eq: $slug }) {
title
description
slug
tags {
name
slug
}
fields {
postedAt(formatString: "DD MMMM YYYY")
pageCount
}
}
markdown: markdownRemark(fields: { slug: { eq: $slug }, pageNo: {eq: $page} }){
html
fields {
pageNo
}
}
}
`;
ここでは記事データとマークダウンをスラッグを条件にして抽出し、記事を表示するコンポーネントに渡す処理をしています。
記事を表示するコンポーネントは以下のようになります。
import React from 'react';
import PropTypes from "prop-types";
import PostShare from './Share.js';
import Pagination from './Pagination.js';
import styles from './styles.module.scss';
class Post extends React.Component {
render () {
const { data } = this.props;
return (
<main className={styles.post}>
<article>
<h1>{data.post.title}</h1>
<div dangerouslySetInnerHTML={{ __html: data.markdown.html }} />
<Pagination slug={data.post.slug} pageCount={data.post.fields.pageCount} pageNo={data.markdown.fields.pageNo} />
<PostShare post={data.post} />
</article>
</main>
);
}
}
Post.propTypes = {
data: PropTypes.object.isRequired
};
export default Post;
コンポーネントでは渡されたデータを表示しています。最終的には以下のような表示になります。
せっかくなので少し記事ページをカスタマイズして画像のLazy Loadingに対応させてみたいと思います。gatsby-transformer-remarkに対応したプラグインが見つからなかったので簡易的なプラグインを自作します。ルートディレクトリにpluginsフォルダを作成して、その中にプラグインを配置すればgatsby-config.jsで読み込むことができます。
フォルダ構成は以下のような形です。
- plugins
- gatsby-remark-lazy-load
- index.js
- package.json
- gatsby-remark-lazy-load
gatsby-transformer-remarkのオプションにプラグインを追加します。
{
resolve: 'gatsby-transformer-remark',
options: {
plugins: [
{
resolve: 'gatsby-remark-copy-linked-files',
options: {
destinationDir: 'static',
ignoreFileExtensions: [],
}
},
'gatsby-remark-prismjs',
'gatsby-remark-emoji',
'gatsby-remark-lazy-load'
]
}
},
プラグインではgatsby-transformer-remarkによって作成されたマークダウンのAST(Abstract Syntax Tree)でimageノードをhtmlノードに置換しています。
const visit = require('unist-util-visit');
module.exports = ({markdownAST}) => {
visit(markdownAST, 'image', node => {
node.type = 'html';
node.value = `<img class="lazyload" src="placeholder.png" data-src="${node.url}" alt="${node.alt}" />`;
});
};
そして、記事を表示するコンポーネントを以下のように修正し、コンポーネントマウント後にIntersectionObserverで記事内のimgタグの交差を監視するようにします。
import React from 'react';
import PropTypes from "prop-types";
import PostShare from './Share.js';
import Pagination from './Pagination.js';
import styles from './styles.module.scss';
class Post extends React.Component {
componentDidMount() {
let observer = new IntersectionObserver((entries, self) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
entry.target.src = entry.target.dataset.src;
self.unobserve(entry.target);
}
})
}, {
root: null,
rootMargin: '300px 0px',
threshold: 0
});
const images = document.querySelectorAll('.lazyload');
images.forEach(image => observer.observe(image));
}
render () {
const { data } = this.props;
return (
<main className={styles.post}>
<article>
<h1>{data.post.title}</h1>
<div dangerouslySetInnerHTML={{ __html: data.markdown.html }} />
<Pagination slug={data.post.slug} pageCount={data.post.fields.pageCount} pageNo={data.markdown.fields.pageNo} />
<PostShare post={data.post} />
</article>
</main>
);
}
}
Post.propTypes = {
data: PropTypes.object.isRequired
};
export default Post;
ビルド・デプロイする
一通りページの説明を行いましたので最後にビルド・デプロイを行ってみます。毎回ビルドしてデプロイは手間がかかるので、開発中はwebpack-dev-serverを使って確認します。サーバを起動するには以下のコマンドを実行します。
gatsby develop
Vagrantを使用していてサーバを0.0.0.0で起動する必要がある場合はオプションを指定します。
gatsby develop -H 0.0.0.0
サーバを起動したら以下のURLからページを確認することができます。
また、以下のURLからGraphiQLというGraphQLのためのIDEにアクセスすることができ、クエリを実行して結果を確認することができます。

最後に以下のコマンドでビルドを行います。publicフォルダに全てのファイルが出力されますので、それらのファイルをまとめてWebサーバにアップすれば完了です。
gatsby build
今回はWebサーバにNetlifyを使用し、手動でデプロイします。githubと連携して自動デプロイすることもできるのですが、ローカルにStrapiのAPIサーバがあるため手動にしています。
まずCLIツールをインストールします。
npm install netlify-cli -g
次に以下のコマンドを実行してデプロイします。
netlify deploy
初回デプロイ時はフォルダのパスなどを対話形式で入力する必要がありますが、2回目以降はコマンドを実行するだけでデプロイできるようになります。
デプロイしたサイトは以下のURLからご確認頂けます。
https://silly-panini-98e601.netlify.com/
最後に
今回作成したサイトのソースコードを以下に公開しています。Gatsby側のコードしかありませんのでStrapiはご自身でご用意ください。
今回のような単一のサイトを作るのであればWordPressを使った方がずっと簡単で効率的だと思います。しかし、Content Is King, Distribution Is Queenと言う人もいるように、コンテンツは作れば良しではなく、ディストリビューションも含めて包括的に考える必要があります。
まだまだ発展途上の分野ですがGraphCMSのように興味深いプロダクトもいろいろ出ていますし、海外での事例も増えているようです。皆さんもHeadless CMSを使った新しいソリューションを考えてみては如何でしょうか?