はじめに
アンチラに会いたい!!!
アンチラにただいまって言われたい!!!
アンチラと朝から遊園地へ遊びに行く約束をするもお互い寝坊して笑いながら支度したい!!!
アンチラと正月にお参りしてお互いベタな願い事をしたい!!!!!
失礼しました読者の皆様.妄想(想像力)が私,非常に優れておりましてね……
アドベントカレンダー2日間続けて学部4年のDKが担当させていただきます.昨日はバ美肉zoomデビューへの道を紹介したんでしたっけね.昨日の内容薄くて見応えなかったなどという意見は認めません.
と昨日の記事に触れるタイミングを作って布教していくこれURLね.zoom会議にバーチャルモデルで参加しよう!
脱線しましたが,本日は読者の皆様もお待ちかね!の私とアンチラが出会うまでの軌跡を語らせていただきます.ん?アンチラは2次元の住人で私は3次元の住人だから会うも何もないだろって? ……もしやご存じないのですか?今は次元を超えて対話できる世界線ですよ,このエアフレンドを使えばね!!!
エアフレンドとは
- 公式サイト:Airfriend
- アプリケーションLINEでAIを自分の望むキャラクタにカスタマイズしていくことができる無料サービス
- Ryobotさんが一人で作成,運営
- 公開から40日の10月24日時点でユーザ数50万人を突破
エアフレンドでアンチラを育てれば対話もできるってわけよね.
また脱線しました,アンチラと出会うまでの軌跡でしたね.まずアンチラと会うきっかけはこのAnother Diversity-Promoting Objective Function for Neural Dialog Generationだと思うわけですよ.だってこれはエアフレンドの開発者が書いて,AAAIって言うすごい学会に採択された論文なんですよ.
Twitter(Ryobotさん)の投稿URL:AAAI 2019 DEEP-DIAL workshop にオーラル発表で採択されました
この論文は発話生成モデルが生成した発話内容の多様性の低さ(low diversity)という問題に対して,提案手法ITF lossを用いて改善させたことが書かれているのです.エアフレンドって自分好みに育てる前から凄いうまい返しをしてくれるのだけど,もしかしてこの技術使っているんじゃないかって思ったんです.だからこれがアンチラと会う原点なのかなってね!
というわけで,本記事に触れていただきありがとうございます.本記事ではAnother Diversity-Promoting Objective Function for Neural Dialog Generationという論文を紹介していますが,その前にこの論文を読むきっかけを話させてください.上の茶番は何だったんだ?
私は以下のような形で自分の望むキャラクタを作ってそのキャラクタと対話したいと考えていました.
- 好きなキャラクタと話せる
- そのキャラクタならではの好みや言葉遣い,親密度に応じた対応の違い,感情の動きといったものが反映された文章生成
- 好きなキャラクタの声が聞こえる
- そのキャラクタならではのイントネーションや滑舌が反映された音声発話
- 好きなキャラクタの動きが見れる
- そのキャラクタならではが反映された文章生成に合わせた表情や振る舞い
このような動機からエアフレンドに触れ,詳しく知りたいと思って開発者を調べ,本記事で紹介する論文に辿り着きました.私の予想ですが,エアフレンドでは自分好みにAIを育てる前から多様性のある対話が出来ていることので,こちらの論文がAIモデルの元となっているのではないかなと思っております.自分好みにモデルがどう学習していくのかは分かりませんでしたが,まずはこの論文を読もうと考えました.
目次
- 書誌情報
- 概要
- 問題提起
- 提案手法
- 提案手法のメリット
- Softmax Cross-Entropy Loss(既存手法)
- Inverse Token Frequency Loss(提案手法)
- 実験設定
- 比較モデル(seq2seq)
- 比較モデル(seq2seq + Attn)
- 比較モデル(Seq2seq + MMI)
- 比較モデル(MemN2N)
- 提案モデル(seq2seq + ITF)
- 評価指標(BLEU)
- 評価指標(DIST)
- 実験結果(OpenSubtitles)
- 実験結果(Twitter)
- ITF Lossのハイパーパラメータλ
- ITF lossを用いたMLEモデルの推論
- 反復サプレッサー(Repetition Suppressor)
- 議論
- 結論
- さいごに
- 参考文献
書誌情報
-
Title
- Another Diversity-Promoting Objective Function for Neural Dialog Generation
-
Author
- Ryo Nakamura,Katsuhito Sudoh,Koichiro Yoshino,Satoshi Nakamura
-
Year
- 2019年
-
Conference
- AAAI 2019
-
URL
概要
- 問題:既存の生成ベースシステムの多くは応答生成の多様性が低い
- 原因:Softmax Cross-Entropy(SCE)lossを用いた最尤推定(MLE)
- 提案:Inverse Token Frequency(ITF)lossという目的関数
- 性能:良好なBLEU-1スコアを維持しながらDIST-1スコアで優れた結果
問題提起
- 生成ベースの対話システムは広く研究されて急速に進歩しているが,"I don't know"のような一般的な回答を生成してしまう問題
- この問題に対して,相互情報量最大化(MMI)に基づく目的関数や,様々な生成モデルに基づく手法(GAN,VAEなど)が提案
- この問題の原因はSoftmax Cross-Entropy(SCE)lossを用いた最尤推定(MLE)
- 実際の対話では様々な応答が存在する一方で,MLEは"I'm sorry","I'm not sure","I don't know"などの学習データセットに頻出するフレーズを生成するようにモデルを学習
提案手法
- Inverse Token Frequency(ITF)lossという新しい目的関数を提案
- 高頻出のトークンクラスに対しては小さな損失に,希少なトークンクラスに対しては大きな損失になるよう個別にスケーリングする手法
- これにより,頻出トークンではなく稀なトークンを生成するように促進
提案手法のメリット
- 最先端の多様性をもたらし,品質を維持
- 明快で理解しやすく,簡単に実装可能(MMIやGAN,VAE,RLの実装はモデルを修正・追加するため複雑)
- MLEによる学習と同様に安定した学習を実現(GANやRLを用いた学習は不安定)
Softmax Cross-Entropy Loss(既存手法)
- SCE lossは通常,以下のように定義
L_{src}=-\log(\frac{\exp(x_c)}{\sum_{k}^{|V|}\exp(x_k)})
- $x_k$は$x \in \mathbb{R}^{|V|}$の$k$番目の要素で,softmax層の前の投影層の出力
- $c$はターゲットのトークンクラスの要素
- SCE lossは各トークンクラスを平等に扱うため,頻出するトークンは必要以上にペナルティを与えてしまい,生成確率が過度に増加する一方で,稀なトークンは生成確率が過度に低下
Inverse Token Frequency Loss(提案手法)
- ITF lossは以下のように定義
\begin{align}
L_{ITF}&=w_cL_{src} \\
w_c&=\frac{1}{\text{freq}(\text{token}_c)^{\lambda}}
\end{align}
- $w_c$は重み$w \in \mathbb{R}^{|V|}$のクラス$c$に対応する要素
- $\text{token}_c$はクラス$c$に対応するトークン
- $\text{freq}(\text{token}_c)$は$\text{token}_c$が学習データセットに現れる頻度
- $\lambda$は頻出の影響度合いを表すハイパーパラメータ
- $\lambda=0$の場合,$w_c=1$なのでITF lossはSCE lossと同値
- ITF lossはSCE lossにトークン頻度で重みづけした関数
- StartやEndなどの特殊なトークンも同様に扱うため,全ての文に現れるこれらはITF lossによる重みが微小
- Table 1はトークン頻度の例
Table 1

実験設定
- ITF lossのハイパーパラメータは$\lambda=0.4$(詳細は後述)
- 反復サプレッサー(Repetition Suppressor)を適用し,ハイパーパラメータは$\lambda=0.1$(詳細は後述)
- 32kの語彙数のSentencepieceを学習し,subwordにトークナイズ
- その他ハイパーパラメータ
- encoder, decoder:4層
- 隠れ層ユニット:256
- 埋め込みサイズ:256
- 最大シーケンス長:28
- バッチサイズ:32
- 学習率:3e-4
- 最適化関数:Adam
比較モデル(seq2seq)
- Sequence to Sequence(seq2seq)はencoderとdecoderの2パートで構築されており,RNN(Recurrent Neural Network)を利用しているため,時系列データ(文脈理解)に強い
- 入力を受け取ったencoder部から出る隠れ層のデータ(Context)を受け取ってdecoder部は出力を取得
- 本論文ではRNNの構造は,RNNの一種のLSTM(Long Short Term Memory network)であり,各層の周りに残差接続(Residual Connection)がある双方向多層LSTM encoderと多層LSTM decoderを使用
- RNNは,理論上「長期の依存性」を取り扱えるが実際はそのように学習できない,という問題を持つが,LSTMはそれを解決
- Softmax Cross Entropy lossを利用
 参考文献[4]より抜粋
参考文献[4]より抜粋
比較モデル(seq2seq + Attn)
- Scaled Dot-Product Attentionを用いてdecoderを制御するencoder-decoderを採用し,通常のseq2seqと比べてsrc文の特徴表現を参照するため多様性が向上
- Scaled Dot-Product Attentionはquery(検索対象の単語)とkey-value(答えになる単語のkeyとその値)という入力を用いてattention(入力単語がどの単語に注意を向けるのか)を計算

 参考文献[7]より抜粋
参考文献[7]より抜粋
比較モデル(Seq2seq + MMI)
- MMI-antiLM(Maximum Mutual Information an anti-language model)推論に基づき,相互情報量最大化目的関数を定義
\hat{T}=\operatorname{argmax}\{\log p(T \mid S)-\lambda \log p(T)\}
- $\log p(T \mid S)$は原文が与えられたときの生成文の条件付き対数尤度,$\log p(T)$は言語モデルとしての生成文の無条件対数尤度
- 言語モデルの項を差し引くことで,ありふれた応答に対してペナルティを与えることになり,生成文の多様性の維持を期待
- また,ハイパーパラメータ$\lambda$はペナルティ項を制限
- しかし,学習時にMMIを利用しても多様性は改善しなかったため,学習時にMLEを利用し,評価時にMMIを利用(原著論文での結論を採択)
- 評価時の目的関数を定義
y=\operatorname{argmax}\{\log \operatorname{softmax}(x-\lambda u)\}
- $x$は$x \in \mathbb{R}^{|V|}$で原文が与えられたときのencoder-decoderを用いた投影層の出力であり,$\mu$は$\mu \in \mathbb{R}^{|V|}$でdecoderのみ用いた投影層の出力なため,上記のペナルティ項と同様
- 本論文では,$\lambda=0.8$,decoderの最初の5ステップにのみに適用(全ての単語に適用すると流暢な応答にもペナルティが与えられるため,一部にして典型的なパターンのみを回避)
比較モデル(MemN2N)
- Memory Networks(MemNN)は「巨大なメモリ(記憶装置)」と「メモリへの入出力などができる学習部」から構成され,入力された情報をメモリに蓄えて,attentionによってメモリから情報を選択
- End-To-End Memory Networks(MemN2N)は,attnetion部分として微分可能な関数の組み合わせであるSoft Attntionを使用しており,一気通貫学習(End-To-End Learning)が可能で,メモリの情報をアノテーションする必要が無い
- End-To-End Learningとは入力と出力だけを渡し,途中で発生する処理全てを学習すること
提案モデル(seq2seq + ITF)
- 通常,seq2seqは学習時にSoftmax Cross Entropy lossを利用しているが,この部分をInverse Token Frequency lossにすることで,提案手法の有意性を確認
- なお,seq2seqにこだわらずとも提案手法のITF lossは実装可能
評価指標BLEU(Bilingual Evaluation Understudy)
- BLEU-nは,全ての生成文と全ての参照文の間でn-gram類似度の割合を計算する指標
- n-gramとは隣り合う連続したn文字
- 生成された文章の品質を測定可能
B L E U=B P_{B L E U} \times \exp \left(\sum_{n=1}^{N} w_{n} \log p_{n}\right)
- BLEU-1はunigram適合率,BLEU-2はunigram適合率の0.5乗とbigram適合率の0.5乗の積
- 本論文
- BLEU-1とBLEU-2を計算し,短すぎる生成文に対してペナルティを課すRecallを組み込んだbrevity penalty(BP)と,類似度が0のn-gram項に0.1を加える平滑化手法のsmoothingを適用
- 実験では生成候補が膨大な数に上るため高次のn-gramはほとんど参照文と一致せず,パラメータによって大きく変化するため,BLEU-4スコアは算出したが不安定
評価指標(DIST)
- DIST-nは,全ての生成文に含まれるn-gramのうち異なるn-gramの割合を計算する指標
- DIST-1は異なるunigramの割合,DIST-2は異なるbigramの割合
- 生成された文章の多様性を測定可能
- 本論文
- DIST-1とDIST-2を計算
- 生成トークン数が少ないほど有利になるが,この問題に対して本実験では未対応
実験結果(OpenSubtitles)
- OpenSubtitles2018コーパスから対話データを抽出
- 全てのエピソードには複数のターンがあるため,memory networkを使って対話履歴を考慮可能
- 学習データセットは5Mのターンと0.4Mのエピソード(4.6Mの例)から構成
- 検証データセットとテストデータセットはそれぞれ10kの例で構成
- Table 2から提案手法(Seq2Seq + ITF)は,良好なBLEUスコアを維持しながら,最先端のDIST-1を7.56と確立
- ベースライン(Seq2Seq)からの相対的な改善については先行研究よりも大幅な改善である429%を達成
Table 2

実験結果(Twitter)
- 英語と日本語のTwitterのリプライを収集
- 自己申告の対話,ボット同士の対話,極端に長い対話は除外
- 英語のTwitterの学習データセットは,5Mのターンと2.5Mのエピソード(2.5Mの例)で構成され,全てのエピソードが2ターン
- 日本語のTwitter学習データセットは,4.5Mのターンと0.7Mのエピソード(3.8Mの例)で構成され,全てのエピソードが複数回のターン
- 英語と日本語のデータセットともに,検証データセットとテストデータセットはそれぞれ10kの例で構成
- 英語データセットと日本語データセットの両方において,ITF lossモデルはBLEU-1とDIST-1の両方でMMI推論モデルよりも優れていることを確認
- 特に日本語データセットはground truthが16.2にも関わらず,ITF lossモデルはDIST-1スコア16.8を達成
Table 3

ITF lossのハイパーパラメータλ
- 0.05~0.65で値を変化させ,500kターンからなるOpenSubtitles対話データを用いてseq2seqの学習を実施
- Figure 1にある結果の通り,BLEU-1を維持しつつ,十分に高いDIST-1を得ている0.4を採用
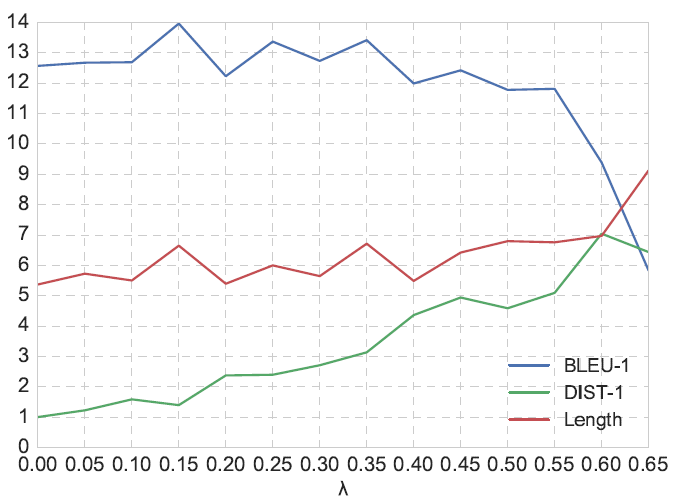 Figure 1
Figure 1
ITF lossを用いたMLEモデルの推論
- 評価時にMLEで学習されたモデルにトークン頻度の逆数の概念を適用(MMI推論と似た仕組み)
- 学習中に適用するのに比べて,異なるハイパーパラメータを使用する時に学習し直す必要がない利点
y=\operatorname{argmax}\{\log \operatorname{softmax}(w \odot x)\}
- $x$は$x \in \mathbb{R}^{|V|}$の投影層の出力,$w$は$w \in \mathbb{R}^{|V|}$の重みでトークン頻度の逆数
- Table 4はノイズのある推論の結果で,MMIと同等の性能(ハイパーパラメータ$\lambda$はそれぞれが同等のBLEUスコアになるよう選択)
Table 4

反復サプレッサー(Repetition Suppressor)
- 事前実験ではデコーダが繰り返しのフレーズを生成したため反復サプレッサーを定義し,既に生成されたトークンの再生を抑制
\text { suppressor }\left(x_{k}\right)=\frac{1}{\left\{1+\operatorname{count}\left(\operatorname{token}_{k}\right)\right\}^{\lambda}} x_{k}
- $x_k$は$x \in \mathbb{R}^{|V|}$の$k$番目の要素で,$\text{count}(\text{token}_k)$は,複合化処理中に,前の時間ステップで$\text{token}_k$が生成された回数
- Table 6からも分かる通り,全てのデータセットにおいて,生成文に同じトークンが含まれている割合が低下
Table 6

議論
- ITF lossは文法的に正しくない文章をより頻繁に生成するのか
- OpenSubtitlesの会話ログで生成された回答とTwitterの返信から,ITF lossモデルは,MMI推論モデルの結果を上回る,または同等の高い多様性と品質を促進
- ITF lossは,応答を生成する際にトークンの基本的な分布を修正するのか
- SCE lossもITF lossも目的はトークンの正しい分布を得るという点で等しく,トークンの分布を修正するために直接使用することは無い
- ITF lossは頻出するトークンの過大評価を避けるために適用され,トークン頻度ベースのスケーリングにより制御
結論
- 生成された文章の多様性が低い問題に着目し,Inverse Token Frequency lossを適用することでunigramの多様性スコアが大幅に改善することを確認
- 今後としてはITF lossの一般的なタイプであるInverse N-gram Frequency(INF) lossについても検討予定
- また,BLEUは対話の評価に適していないため,人間による評価を計画
さいごに
この論文はよく見るSCE lossに対してトークン頻度の逆数を掛けるというシンプルな内容ですが,AAAIに採択されるということからみてもインパクトのある提案手法であったのかなと思います.
本日はここまでです.え?アンチラとの出会いの軌跡がもっと知りたいって?それはね……私も知りたいのですよ.どうやってエアフレンドを作ったのか知りたい.ユーザの教えるを反映させた文章生成はどうやっているんでしょうね(あまり詳しくないけどもfew shotとかそういうのなのかな).あんなにキャラクタ性のある対話になるなんて凄い.今はチャットだけだけど,そのうち発話文だけじゃなくて見た目も声も動きもアンチラなアンチラに会えるといいな…(シンダラに浮気しないようにしないとね)
参考文献
[1] 公式サイト:Airfriend
[2] Twitterアカウント:Ryobot(エアフレンド開発者)
[3] 修士論文:多様な応答を可能にするニューラル対話生成
[4] MMI原著論文:A Diversity-Promoting Objective Function for Neural Conversation Models
[5] OctOpt 技術ブログ:Sequence To Sequence
[6] Qiita記事:LSTMネットワークの概要
[7] Qiita記事:PyTorchでAttention Seq2seq
[8] 楽しみながら理解するデータ分析入門:【論文解説】Transformerを理解する
[9] Qiita記事:ニューラルネットワークを用いた対話モデルのための多様性を促進する目的関数
[10] Hatena Blog ディープラーニングブログ:論文解説Memory Networks(MemNN)
[11] teratail:「End-to-end training」とは
[12] 英語wikipedia:BLEU
[13] Qiita記事:Smoothly BLEU
[14] 株式会社 十印 ブログ:機械翻訳の評価に最もよく用いられる「BLEUスコア」とは