これまで何回かの記事で、MQTTを使ってDynamoDBにデータを集めてきました。
今回はいよいよそれらを可視化したいと思います。
可視化には、AWS QuickSightを使います。
AWS QuickSightへの入力ソースとして、S3とAWS Athenaのどちらでもできるのですが、まずは単純にS3から直接読み出します。(AWS Athenaを使う方法は、年末年始のばたばたが落ち着いたら追記しようと思います)
使うAWSツールは以下の通りです。
- DynamoDB
- Lambda
- S3
- QuickSight
- CloudWatch
- (Athena)
流れとしては以下の通りです。Athenaを介さない場合です。
① Lambdaを使ってDynamoDBのデータをCSVに変換しS3に格納します。起動のトリガはCloudWatchを使います。
② AWS QuickSightでS3のデータを可視化します。
ちなみに、Athenaを介する場合は以下の通りです。
① Lambdaを使ってDynamoDBのデータをCSVに変換しS3に格納します。起動のトリガはCloudWatchを使います。
② S3に格納したデータをAthenaで扱えるようにします。
③ AWS QuickSightでAthenaのデータを可視化します。
事前の準備であるDynamoDBへのデータ格納は以下をご参照ください。
AWS IoTにMosquittoをブリッジとしてつなぐ
Xiaomi Mijia 温湿度計 をIoTデバイスとして使う
Qiitaの閲覧数をMQTTで記録する
今回は、Xiaomi Mijia 温湿度計の温度と湿度をグラフ化します。
DynamoDBのデータ構造
DyanmoDBに格納されたデータの構造は以下の通りです。
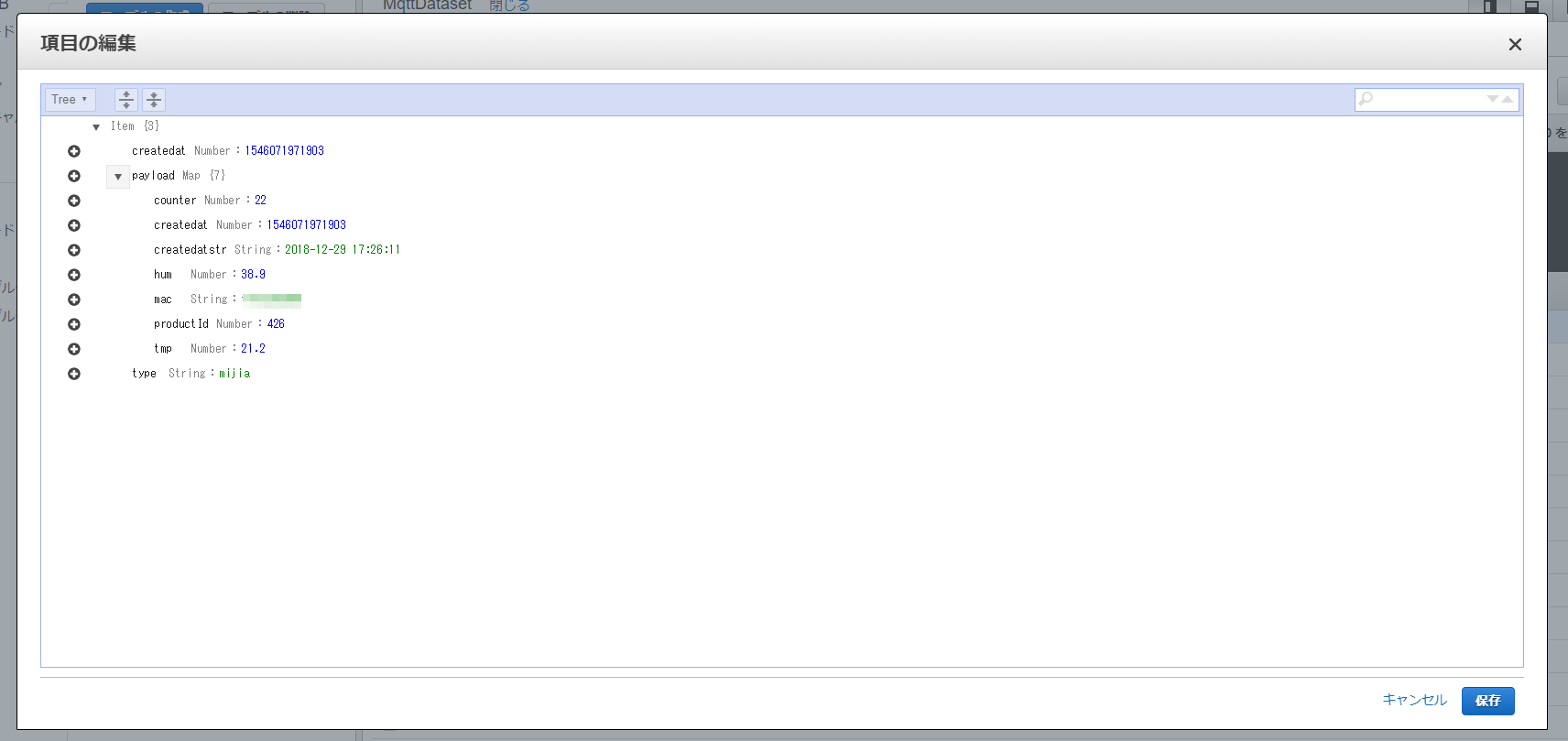
AWS IoTのルールで指定したハッシュキーとレンジキーがありますが、それ以外のデータはpayloadにあるのがわかります。
今回使う項目は、このうち以下の通りです。
- createat
- createdatstr
- hum
- tmp
- type
LambdaでS3にCSVファイルで格納する
Lambdaを使って、DynamoDBにあるデータの前日1日分をCSVファイルにします。
'use strict'
const AWS = require('aws-sdk');
AWS.config.update({ region: 'ap-northeast-1' });
const docClient = new AWS.DynamoDB.DocumentClient();
const s3 = new AWS.S3();
const BUCKET_NAME = process.env.BUCKET_NAME || 【S3バケット名】;
const DB_TABLE_NAME = process.env.DB_TABLE_NAME || 【DBテーブル名】;
exports.handler = function (event, context, callback) {
console.log('type=' + event.type);
console.log('colums=' + event.colums);
console.log('header=' + event.header);
var now = new Date();
var base_jpn = new Date(now);
base_jpn.setDate(now.getDate() - 1);
base_jpn.setHours(now.getHours() + 9);
var yesterday = new Date(base_jpn.getFullYear(), base_jpn.getMonth(), base_jpn.getDate(), -9 );
var today = new Date(base_jpn.getFullYear(), base_jpn.getMonth(), base_jpn.getDate() + 1, -9 );
let params = {
TableName: DB_TABLE_NAME,
KeyConditionExpression: "#type = :type and #createdat between :start and :end",
ExpressionAttributeNames: {
"#type": "type",
"#createdat": "createdat"
},
ExpressionAttributeValues: {
":type" : event.type,
":start" : yesterday.getTime(),
":end": today.getTime() - 1
}
};
docClient.query(params).promise().then(data => {
console.log('dataNum=' + data.Items.length);
if( data.Items.length > 0 ){
console.log('datasample=', data.Items[0]);
}
let array = [];
if( event.header ){
var header = 'type, createdat';
for( var i = 0 ; i < event.colums.length ; i++ ){
header += ', ' + event.colums[i];
}
array.push(header);
}
for( var j = 0 ; j < data.Items.length ; j++ ){
var element = data.Items[j];
var str = element.type + ', ' + element.createdat;
for( var i = 0 ; i < event.colums.length ; i++ ){
str += ', ' + element.payload[event.colums[i]];
}
array.push(str);
}
// console.log(array);
var fname = 'mqttdataset/' + event.type + '/' + event.type + '_' + base_jpn.toLocaleDateString() + '.csv';
console.log('fname=' + fname );
let s3Params = {
Bucket: BUCKET_NAME,
Key: fname,
Body: new Buffer(array.join('\n'), 'utf8')
}
return s3.putObject(s3Params).promise();
}).then(data => {
console.log(data);
})
.catch(err => {
console.log(err);
});
};
環境に合わせて以下を変更してください。
【DBテーブル名】
【S3バケット名】
DBテーブル名は、前回の記事の通りですと、「MqttDataset」になります。
格納先のS3のフォルダは以下の通りです。
mqttdataset/【タイプ】/【タイプ】_【エクスポート対象日付】.csv
タイプは、今回は「mijia」です。MQTTでアップするデータには複数の種類を用意する予定なので、タイプで区別しています。また毎日1回S3に集約するので、ファイル名に日付を含めるようにしています。
実装上では、前日一日分をDynamoDBから抽出するために、ちょっと手間がかかっています。日本時間とUTCで時差があるためです。(momentを使えばもっとスマートになるかも。。。)
★それから、忘れずに、このLambdaの実行者のロールに、DynamoDBとS3へのアクセス権を与えておきましょう。★
前回の記事でも述べていますが、アップするデータは今後いろんな種類が増える可能性があり、データ(payload部)のフォーマットは異なります。
そこで、データのどの項目をCSV出力するのかをLambda呼び出し時の入力引数"colums"で指定するようにしました。
以下の通りです。
{
"header": true,
"type": "mijia",
"colums": [
"createdatstr",
"hum",
"tmp"
]
}
"header"は、CSVファイルに項目名を示すヘッダを付けるかどうかを示しています。
AWS Athenaを介する場合はヘッダは不要なので、falseとしてください。
これを、Lambdaのテストイベントに設定します。
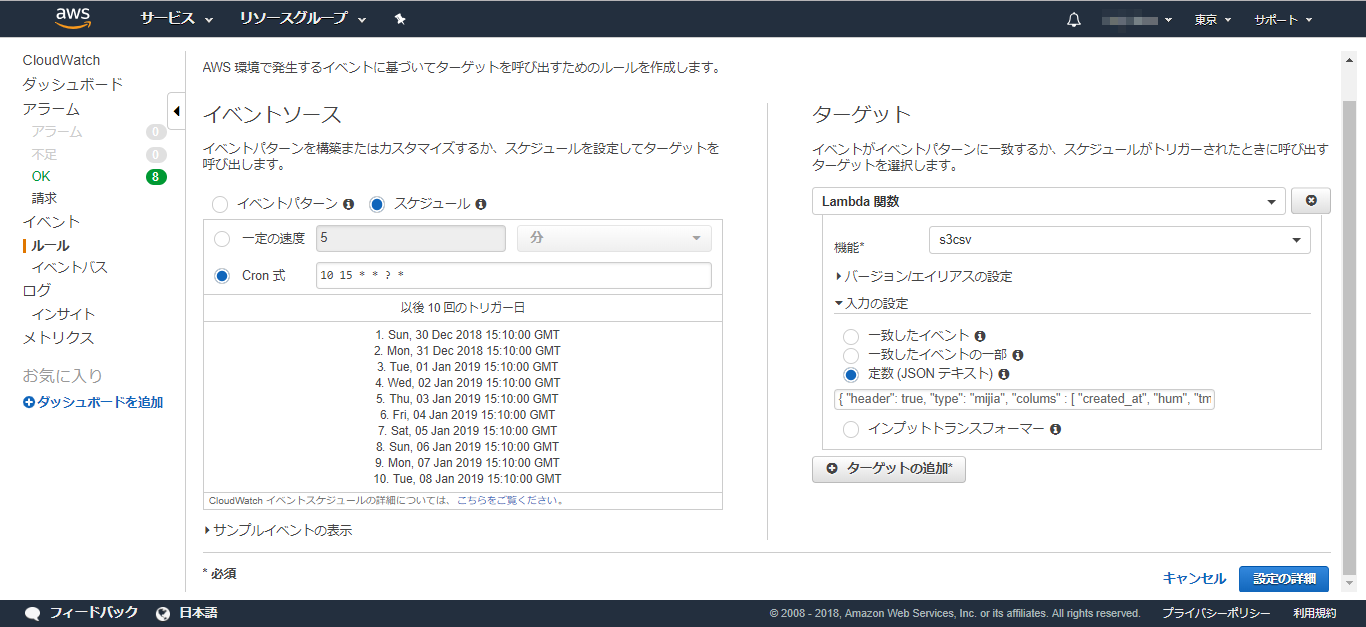
Lambdaコンソールから、「テスト」ボタンを押下して実行すると、「Execution Result」にconsole.logの内容が出力され、実行が成功しているのがわかります。
また、S3コンソールを見ると、ファイルが増えているのがわかります。ダウンロードして中身を確認しましょう。
確認が終わったら、いったんこのファイルは削除しておきましょう。
CloudWatchで1日に1回Lamdaを起動する
定期起動には、CloudWatchのルールを使うのが楽ちんです。
「ルールの作成」ボタンを押下します。
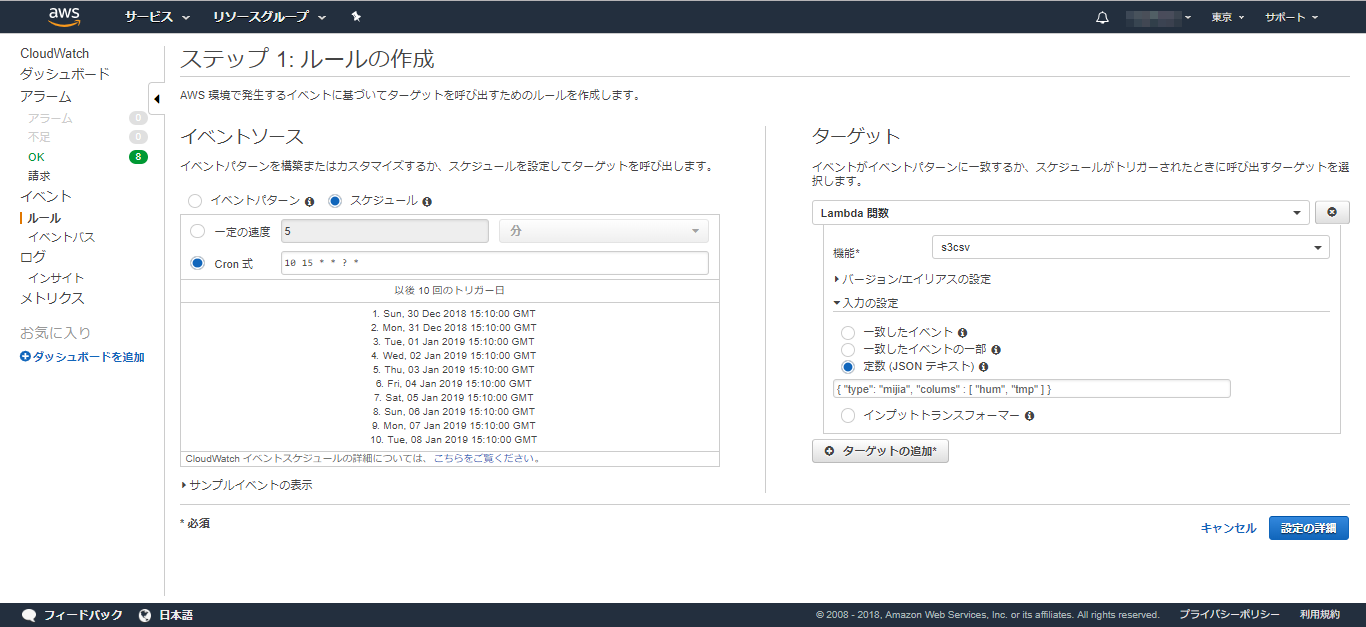
イベントソースは「スケジュール」を選択し、Cron式には以下を指定します。
10 15 * * ? *
毎日、15時10分に起動する指定です。なぜ15時かというと、日本とUTCには時差が9時間あるためです。日本での深夜0時10分は、UTCでいうと前日の15時10分です。
ターゲットとして、先ほど作成したLambda関数名を指定します。
入力の設定には、Lambdaコンソールで指定したテストイベントと同じJSONを指定します。
あとは、深夜0時10分を待つのみです。
無事に、S3にまたCSVファイルが出力されましたでしょうか?
QuickSightでグラフを表示する
QuickSightコンソールを開きます。
(最初にアカウント作成が要求されると思います。)
さきに、QuickSightから、S3やAthenaにアクセスできるように、ロール権限を与える必要があります。
右上のリージョンの選択から、「US East(N.Virginia)」を選択します。そして、右上のアカウントアイコンから、「Manage QuickSight」を選択します。
表示されたページから「Account Setting」を選択します。
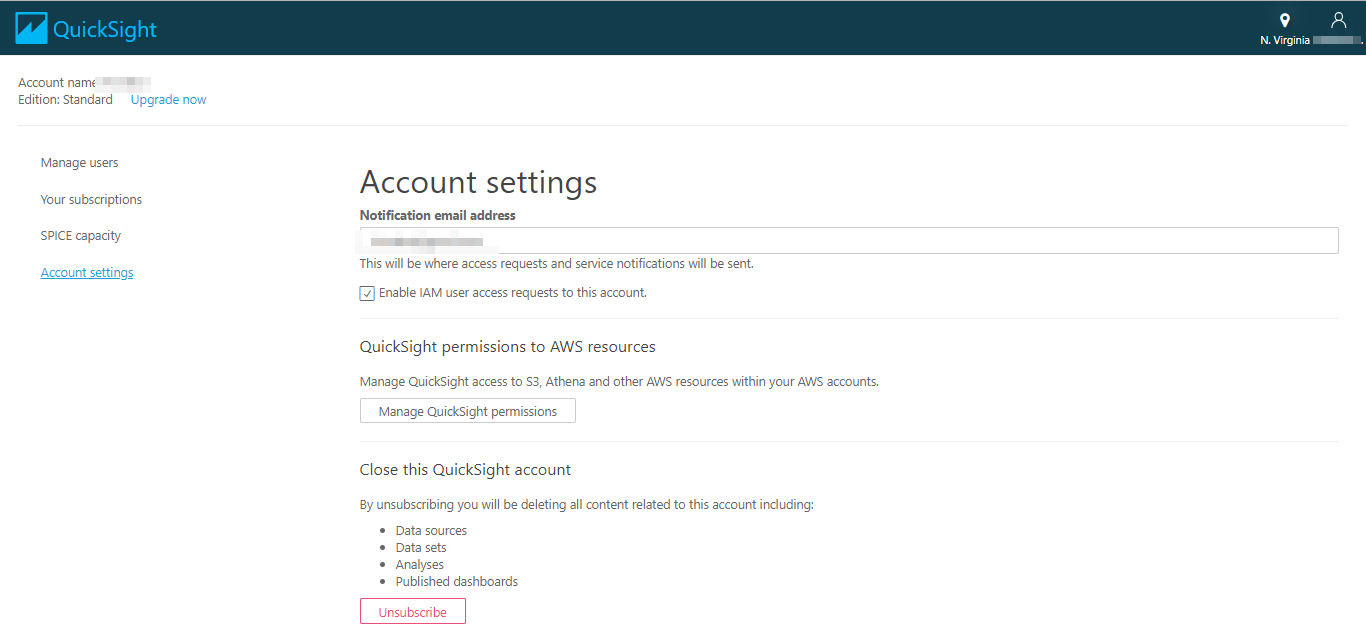
Manage QuickSight permissionsボタンを押下します。以下の画面が表示されます。場合によってはエラーが表示されている場合があります。すでにロールが存在しているからのようで、対象のロールをIAMから削除して、もう一度進めてみてください。
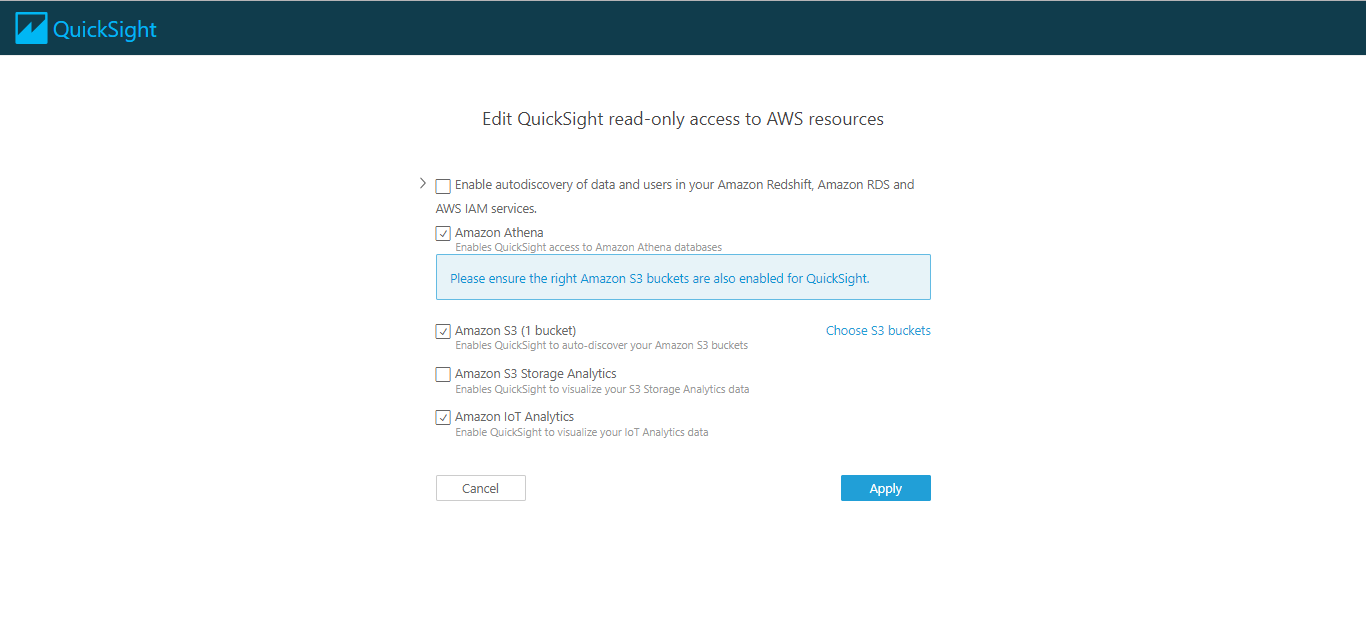
(参考)
https://docs.aws.amazon.com/ja_jp/quicksight/latest/user/troubleshoot-connect-athena.html
ここで、入力予定のデータソースの候補をチェックボックスで選んで「Apply」ボタンを押下します。
右上のリージョン選択から「Asia Pacific (Tokyo)」を選択して東京に戻しておきます。
左上の「New analysis」ボタンを押下します。
次に、左上の「New data set」ボタンを押下します。
S3を選択します。
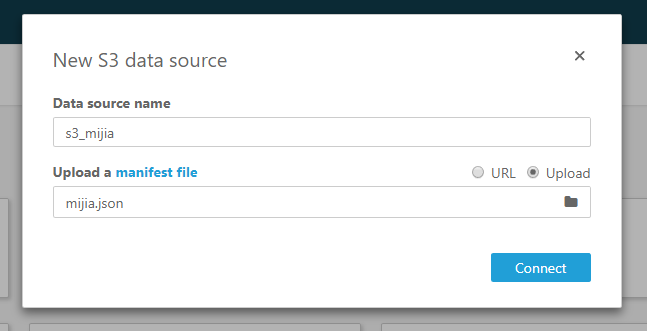
Data source nameには適当な名前を付けます。例えば、「s3_mijia」とします。
Upload a manifest fileには、「Upload」を選択したのち、以下のJSONファイルをアップロードします。
{
"fileLocations": [
{"URIPrefixes":
[
"https://s3-ap-northeast-1.amazonaws.com/【S3バケット名】/mqttdataset/mijia/",
]
}
],
"globalUploadSettings": {
"format": "CSV",
"textqualifier": "\"",
"delimiter": ","
}
}
【S3バケット名】の部分を環境に合わせて変更してください。
(参考)
https://docs.aws.amazon.com/ja_jp/quicksight/latest/user/supported-manifest-file-format.html
最後にConnectボタンを押下します。
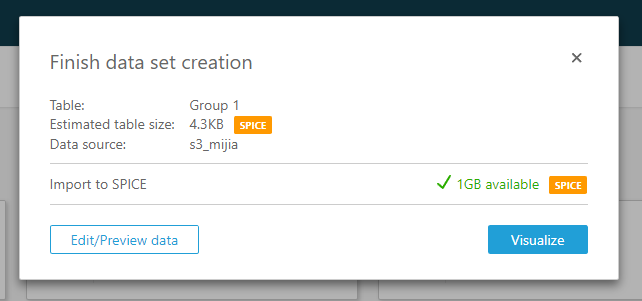
データが取り込まれました。
(QuickSightに取り込まれたようです。1GBが無料の上限のようです。取り込まれずS3から直接アクセスできるAthena経由の方がいいのかな???)
「Visualize」ボタンを押下します。
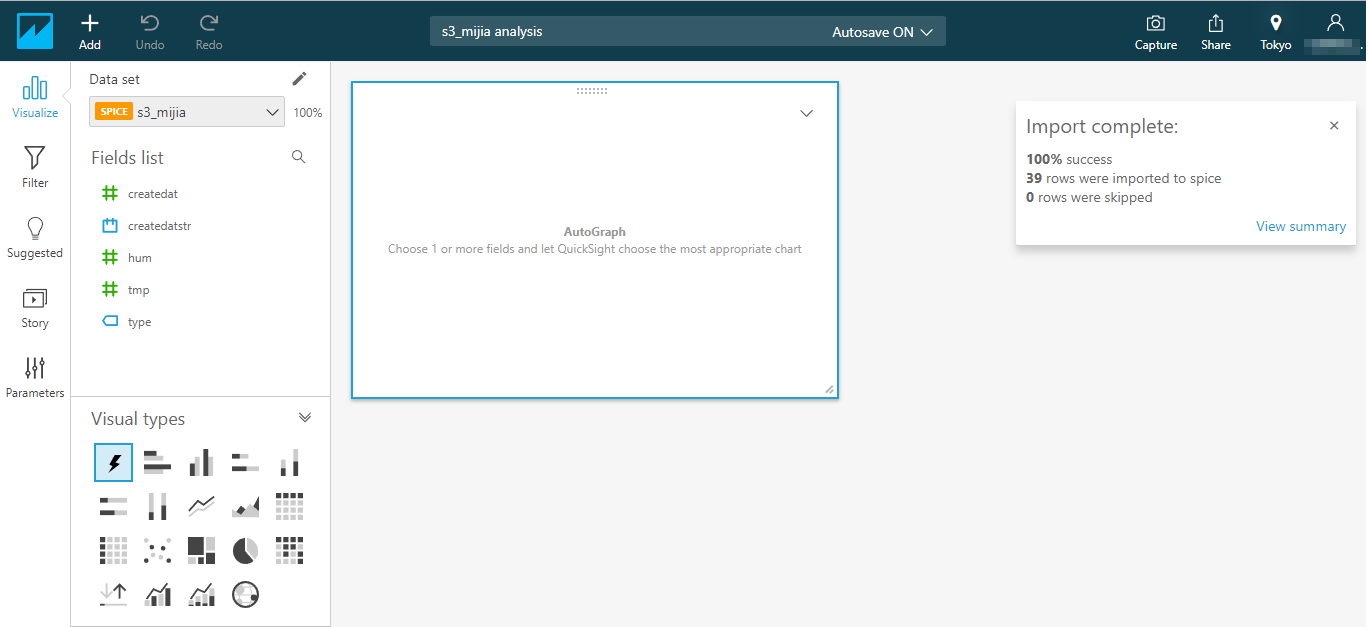
可視化のための設定をすると以下のようになります。(もちろん取得したデータが場所によって違いますので、それぞれカーブの形は違います)
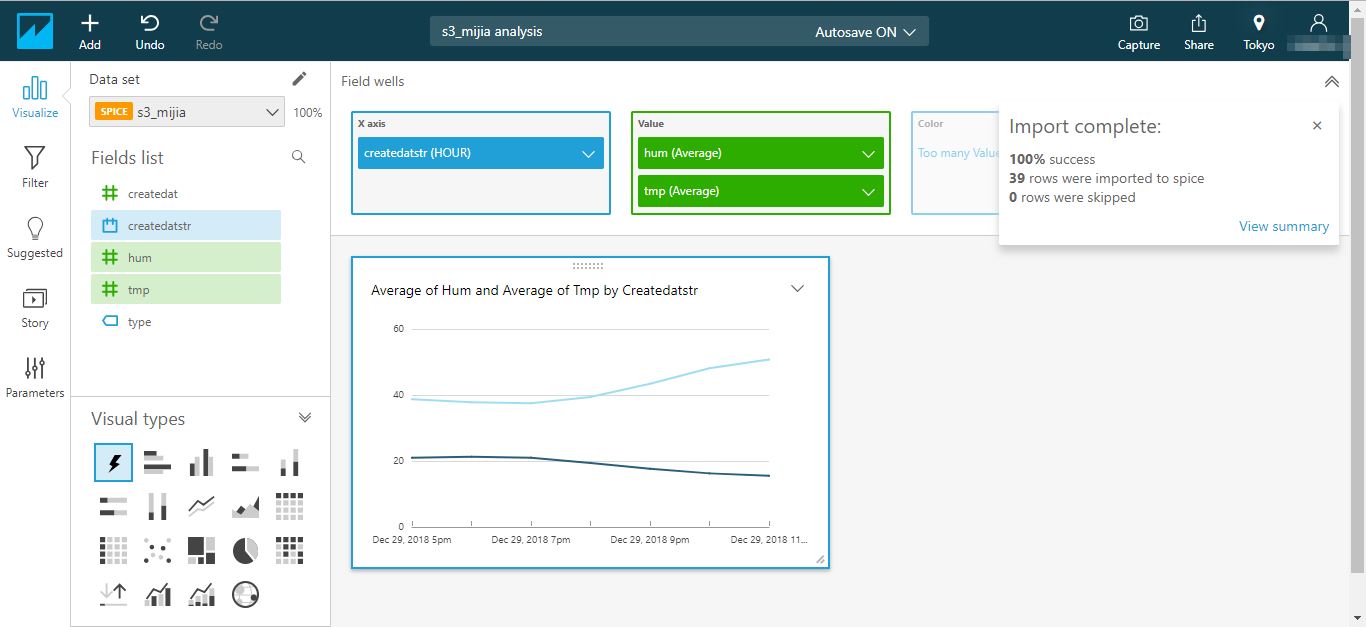
横軸(X axis)は、createdatstr とし、HOUR単位としました。
縦軸(Value)は、humとtmpとし、Average(平均)としました。
所感
このやり方に落ち着くまでに、たくさん試行錯誤しました。また、グラフ表示されましたが、まだ使いこなせていないので、QuickSightの有用性は未知です。
結構めんどうだった。。。
Athenaを介した方法もありますが、また今度加筆しようと思います。
以上です。