第15章 アーキテクチャとは?
著者見解
ソフトウェアアーキテクチャとは、システムを構成するコンポーネントを適切に分割して配置し、それらの相互通信を定義することで生まれる「形」です。その目的は単にプログラムを正しく動かすことではなく、開発・デプロイ・運用・保守というライフサイクル全体をできるだけスムーズにすることにあります。つまり「動くこと」は前提であり、本当に重視すべきは「長期にわたり多くの選択肢を残すこと」です。
チームの規模や構成はアーキテクチャに直接影響します。数人程度の小規模チームであれば、モノリシックな構成でもコミュニケーションで補いながら開発を進められることが多いです。しかし数十人規模で複数チームが並行開発するなら、明確なコンポーネント分割と安定したインターフェイスが不可欠になります。チーム間の境界を設けることで、作業の干渉を減らし並行性を高められます。
デプロイ可能性も重要な観点です。理想は「単一アクションでデプロイできる」ことですが、マイクロサービス化は開発を容易にしても設定や起動順序の管理が複雑化し、デプロイコストが跳ね上がる場合があります。アーキテクトはデプロイの手間を見据え、必要以上に複雑化させない判断を求められます。
運用面では、アーキテクチャは運用チームに「何を、どう動かせばよいか」を明確に伝える役割を持ちます。ユースケースや非機能要件(スループット、可用性、監視要件など)が設計に反映されていれば、運用は適切なリソース配分や障害対応を行いやすくなります。保守性についても、問題の多くは既存コードの探索(いわゆる洞窟探検)と変更リスクの管理に起因します。コンポーネントを独立させ、安定したインターフェイスを維持することで、変更箇所の特定やテスト・デプロイが局所化され、新たなバグの発生を抑えられます。
本質的には、ソフトウェアの価値は「方針(ビジネスルールや戦略)」にあります。データベースやUI、通信プロトコルなどは方針を支える「詳細」にすぎません。優れたアーキテクトは方針を中心に据え、詳細への依存を逆転させることで、詳細の選択(DB製品、Webサーバ、DIフレームワークなど)を可能な限り先送りし、最適なタイミングで決定できるようにします。
歴史的な例として、1960年代の「IOデバイス非依存」の設計は、方針と詳細を切り離すことの効果を示しています。レコード書式(方針)と物理デバイス(詳細)を分けることで、ハードウェアが変わってもアプリケーションを修正せずに済むようになりました。これはオープン・クローズド原則(OCP)の原点ともいえます。まとめると、優れたアーキテクトは方針を明示する形状を作り、詳細の決定を遅延させることで最善の選択肢を残し、結果としてシステムのライフタイムコストを最小化しプログラマの生産性を最大化します。これが「ソフトウェアをソフトのまま保つ」ためのアーキテクチャ的アプローチです。
筆者所感
ソフトウェアアーキテクチャの本質は、「時間が経っても柔軟に変化に耐えられる形を作ること」だと考えています。価値の核は著者の言うとおり、方針(ビジネスルールや戦略)にあり、これが根本的に変わるなら新規に作り直す選択肢を検討すべきです。それに対してUIやフレームワーク、データベースなどの技術的詳細は頻繁に変わるので、これらに強く結びついた設計は早晩足かせになります。したがって、依存関係を逆転させたり抽象化して詳細を置き換えやすくすることで、少ないコストで技術選定の変更に対応できるようにするのが良いアーキテクトの仕事です。要は「方針は中心に据え、詳細は差し替え可能にする」――この設計方針がシステムを長く健全に保ちます。
第16章 独立性
著者見解
優れたアーキテクチャは、ユースケースの実現・運用の安定化(性能・スケーラビリティ)・開発時のチーム間干渉の回避・即時かつ小さな単位でのデプロイという、システムライフサイクルに関わる四つの活動を同時にサポートします。これらを両立させるための基本方針は、変更される理由が異なる要素を切り離し、同じ理由で変更される要素をまとめることにあります。
まず、ユースケース(システムの振る舞い)をトップレベルで見える化し分離することが重要です。具体的には、UIの変更とビジネスルールの変更は理由が異なるためUI層とドメイン層を明確に分け、ドメイン内部でもアプリケーション特有のルールと共通ドメインルールを分離します。設計は縦方向のユースケース単位のスライスと、横方向のレイヤー単位のスライスを組み合わせて行います。
次に、運用ニーズを抽象化して技術的詳細を選択肢として残しておくことで、後からスレッド・プロセス・サービスといった実行モデルへ移行しやすくなります。境界や通信プロトコルを固定しすぎなければ、高スループットや低レイテンシが求められる状況に応じて柔軟に対応できます。
開発体制に合わせてチーム間の干渉を防ぐ設計も欠かせません。Conwayの法則を念頭に置き、組織構造に対応した独立したコンポーネント群を用意することで、各チームの担当範囲を明確にし、あるチームの変更が他チームのコンパイルやテストに波及しないようにします。
さらに、デプロイ単位の柔軟性を確保することも重要です。理想はビルド直後に即デプロイできることであり、そのためには構成スクリプトや手作業を最小化し、必要であればレイヤーやユースケース単位でホットスワップできるようにします。
切り離しのレベルは時間とともに変化します。ソースコードレベルではモジュール間の依存を管理して再コンパイル範囲を最小化し、デプロイレベルではバイナリ単位で再ビルドや再配布の影響を局所化し、サービスレベルではネットワーク越しのインターフェイスで完全独立を実現します。実際には「モノリシック → デプロイ可能ユニット → サービス(マイクロサービス)」と段階的に成長させ、必要なら逆向きに再結合できる柔軟性を残すのが望ましいです。
要するに、システム要素を「異なる理由で変わるもの」に切り離し「同じ理由で変わるもの」をまとめることが、アーキテクチャの独立性を生み出す原則です。これによりユースケース追加や運用要件の変更、チーム構成やデプロイ戦略の見直しといったライフサイクル上の課題に対して、持続的に対応できるシステムが実現します。
筆者所感
アーキテクチャには CI/CD やデプロイ戦略も含まれるべきだと考えています。いくら設計がきれいでも、デプロイに数時間かかってしまっては開発効率が落ち、本来の仕事に時間を割けません。特にクリーンアーキテクチャのようにデプロイ単位が細かくなる場合は自動化や並列化を前提に設計し、迅速にリリースできる仕組みを整えることがアーキテクトの重要な責務です。
第17章 バウンダリー:境界線を引く
著者見解
ソフトウェアアーキテクチャの本質は、システム内に「境界線」を引くことにあります。重要なもの(たとえばビジネスルール)と重要でない技術的な詳細(UI、データベース、フレームワークなど)との間に明確な境界を設けることで、コアの振る舞いを保護しつつ開発・保守・拡張を容易にできます。具体的には、UIとビジネスルール、ビジネスルールとデータベースアクセスの間などに境界を置き、フレームワークやDIといった技術的詳細は外側のプラグインとして扱います。
こうした境界を引くことには複数の効果があります。データベース製品やWebサーバー、IOデバイスといった技術的決定を最後まで遅らせられるため、実装の選択肢を残すことができます。また、プラグイン→コアという一方向の依存を守れば、コアは詳細を知らずに済み、変更の波及を遮断する「ファイアウォール」として機能します。結果として、UIやDBを自由に差し替えられるプラグインアーキテクチャが実現し、たとえば Web/コンソール/クライアントサーバーの UI や、RDB/NoSQL/ファイルベースのデータストアを容易に入れ替えられるようになります。
非対称な依存関係の実例として、ReSharper(JetBrains)と Visual Studio(Microsoft)の関係が挙げられます。ReSharper は Visual Studio を参照して動作しますが、Visual Studio は ReSharper を意識しません。この一方向性こそが、コアを壊さずにプラグインを拡張・差し替え可能にする仕組みです。
境界を引く際には設計原則に従うことが有効です。依存関係逆転の原則(DIP)により高レイヤー(コア)は低レイヤー(プラグイン)の具象実装に依存せずインターフェイスに依存しますし、安定度・抽象度等価の原則(SAP)に従えば、多くの依存を集める安定なコンポーネントは抽象的に、詳細側のプラグインは具象的に設計されます。
最後に、境界を引くタイミングについては注意が必要です。プロジェクト初期にフレームワークやデータベースの選定を急がず、まずコアロジックを定義して周辺をプラグイン化する境界を明確にすることが重要です。詳細要件や技術スタックは境界の外側に置き、いつでも変更可能な状態を保つことで、ビジネスルールを中核に据えた柔軟で保守性の高いシステム構造が得られます。
筆者所感
私の小規模な PHP アプリ開発の例です。最初は PHPUnit、cs‑fixer、PHPStan だけを入れて、まずビジネスロジックを書くことに注力しました。依存性注入が必要になった段階で Laravel を導入しましたが、そのときも Eloquent や具体的な DB は未導入で、エンドポイントも作っていませんでした。結果として「詳細」に気を取られず、コアを先に固められたのが良かった点です。詳細は後から足す――この順序を守ると、本質を見失わずに設計を進められます。
第18章 境界の解剖学
著者見解
ソフトウェアアーキテクチャは、コンポーネントとそれらを隔てる「境界」によって形作られます。境界をどのように引き、越えるときのコストや依存関係をどう管理するかは設計の重要な課題です。本章では境界を四つのレベルに分け、それぞれの特徴と注意点を整理します。
まず同一アドレス空間内、いわゆるモノリス内部の境界です。この場合すべてが同一プロセス・同一アドレス空間で動作するため、境界を越えるのは単なる関数呼び出しやメモリ参照に過ぎず、オーバーヘッドは極めて小さいのが利点です。設計上はコンパイル時の依存と実行時の依存を同じ方向(詳細→コア)に揃えておくことで、コアを下位の詳細から独立させることができます。ただしデプロイは単一の実行ファイルとして扱われる点に注意が必要です。
次に動的リンクライブラリやバイナリ単位の境界(.NET の DLL、Java の JAR、UNIX の .so、Ruby の Gem など)があります。これらはコンパイルをやり直さずに差し替え可能で、デプロイ単位として部分的な配布や更新がしやすい一方で、内部通信は依然として高速な関数呼び出しで済むことが多い点が特徴です。war ファイルなどにまとめて配布する運用も一般的です。
三つ目はローカルプロセスの境界です。プロセスごとに独立したアドレス空間を持ち、ソケットやメッセージキュー、共有メモリ(保護付き)などで通信します。プロセス間通信にはシステムコールやデータのマーシャリング/アンマーシャリング、コンテキストスイッチといったオーバーヘッドが伴いますが、同一ホスト上での隔離やフォールトドメインの分離などの利点があります。動的ライブラリを複数プロセスで共有することも可能です。
最も強い境界はサービスの境界(リモートを含む)です。サービスは物理的な配置に依存せず、同一マシン内でもクラスタを跨いでも動作します。通信は HTTP/REST、gRPC、メッセージバスといったネットワーク越しの手段を使い、レイテンシはミリ秒から秒単位と大きくなるため、フォールトトレランスやリトライ設計が必要になります。いずれのケースでも呼び出し先の URI など物理情報をソースコードに直書きしない設計が望まれます。
これらをまとめると、境界越えのコストは「同一アドレス空間 < 動的ライブラリ < ローカルプロセス < サービス(ネットワーク)」の順に大きくなります。実際のシステムではこれらの境界を組み合わせ、性能・可用性・独立性・デプロイの柔軟性を釣り合わせることが求められます。
境界を適切に管理するためのポイントは次のとおりです。依存関係は常に下位(詳細)→上位(コア)の一方向に揃えること、境界越え通信のコストや信頼性(同期/非同期、トランザクション保証など)を設計段階で見積もること、ソースコードレベルとデプロイレベルの境界を明確にして変更時の再ビルド/再デプロイ範囲を限定すること、そして境界自体を「ファイアウォール」と見なして変更の波及を最小化することです。
これらを意識して境界設計を行えば、同一プロセス内の軽量なモジュール連携から、クラウド上の分散サービス連携に至るまで、一貫性のある柔軟で保守しやすいシステムを構築できます。
筆者所感
個人開発ではモノリスで十分なことが多いですが、将来の拡張を見越して依存関係はきちんと管理しておくべきだと考えています。たとえ今は同一プロセス内で動いていても、あるドメインの変更が別のドメインに波及すると分離が難しくなります。だからこそ初期からドメインごとの境界を意識し、将来的に動的ライブラリやサービスに切り出せるように設計しておくと安心です。
第19章 方針とレベル
著者見解
ソフトウェアシステムは、「入力を出力に変換する方針」の集積体です。大きなシステムでは、ビジネスルールの計算方法、レポートフォーマット、入力データの検証など、さまざまな方針が混在します。優れたアーキテクチャは、それらの方針を「同じ理由やタイミングで変更されるもの」は同一コンポーネントにまとめ、「異なる理由やタイミングで変更されるもの」は別々のコンポーネントに分離することで、影響範囲を明確化します。こうしておくと、ある方針を修正しても他の方針に波及せず、部分的なテストや再デプロイが容易になります。
ここでいう「レベル」とは、方針がシステムの入力・出力からどれだけ離れているかで測る階層です。入力や出力に直接関わる方針は最下位レベル、そこから距離が遠い暗号化や変換、ビジネスロジックは上位レベルに位置づけられます。重要なのは依存関係の一方向性で、下位レベルのインターフェイスを上位レベルのコンポーネントが利用する形で依存を統一することです。たとえば、encrypt 関数は直接 readChar や writeChar を呼ぶのではなく、入出力用のインターフェイス経由で呼び出すようにします。こうすることで、入出力実装を変更しても暗号化ロジックを改修する必要がなくなります。
この方針分割とレベル配置を支える設計原則としては、単一責任の原則(SRP)や閉鎖性共通の原則(CCP)で変更理由ごとにコンポーネントを分離し、オープン・クローズド原則(OCP)によって既存コードを変更せずに拡張可能にします。さらに依存関係逆転の原則(DIP)を適用して高レイヤーが低レイヤーの抽象(インターフェイス)に依存し、安定依存の原則(SDP)/安定度・抽象度等価の原則(SAP)で「変更しにくい部分は抽象化して上位に配置」することで、全体を有向非循環グラフ(DAG)として構築できます。結果として、変更に強く保守性の高いアーキテクチャが実現し、部分的なビルドやデプロイ、テストがスムーズに行えるようになります。
筆者所感
アーキテクチャを学び始めたときに最も違和感があったのは、データの流れと依存関係の向きが逆になる点です。たとえばデータは readChar → encrypt → writeChar と流れるのに、依存関係は readChar → encrypt ← writeChar のように表現されることがあります。慣れると自然ですが、本質は「変更頻度の高い詳細(I/Oなど)に、安定した方針(この場合は暗号化)が依存してはいけない」ということです。重要なロジックが入出力の変更に左右されないよう、抽象(インターフェイス)を噛ませて依存の向きを設計することが大切だと感じています。
第20章 ビジネスルール
著者見解
ソフトウェアは本質的に「方針」を実現するための道具であり、その中でも特に重要なのがビジネスルールです。ビジネスルールとは、収益を生み出したりコストを削減したりする手続きや計算のことで、システムの価値はここにあります。こうしたルールを設計するときは、役割や変更理由に応じて責務を分け、影響範囲を最小化することが重要です。
まず「エンティティ」と呼ばれるオブジェクト群があり、ここには最重要ビジネスデータ(例:貸付残高、金利、返済スケジュール)と、それらを操作する核となるビジネスルールがまとめられます。エンティティはビジネスそのものであり、データベースやユーザーインターフェイス、外部フレームワークといった技術的詳細には依存してはいけません。エンティティの公開インターフェイスはビジネス上の操作を表すメソッド群だけで構成し、外部技術を知らないまま安定して動くことが求められます。
一方で「ユースケース」は、ユーザーや他のシステムが自動化されたプロセスをどのように利用するかを定めるアプリケーション固有のルールです。ユースケースは「いつ・どの順序で・どのエンティティのルールを呼ぶか」を定義し、入力(リクエスト)と出力(レスポンス)を扱いますが、表示の仕方やデータベースの問い合わせの詳細といった低レイヤーの実装には触れてはなりません。ユースケースはあくまで簡潔な入出力モデルを受け取り、エンティティへの参照を通じてビジネス処理を進めます。
重要な設計ルールは依存関係の方向です。ユースケース(下位)はエンティティ(上位)に依存してよいが、エンティティがユースケースやUI、DBに依存してはいけません。この一方向の依存により、ビジネスロジックはテストしやすく再利用可能になり、UIやDBの変更がコアのルールに波及することを防げます。
まとめると、ビジネスルール層はシステムの中で最も独立性が高くあるべきで、エンティティとユースケースに責務を分離することで、変更に強く保守しやすい設計が実現します。
筆者所感
DDD の「エンティティ」とクリーンアーキテクチャの「エンティティ」は指す範囲が異なる点に注意が必要です。クリーンアーキテクチャでは「エンティティ」は DDD のエンティティに加えて Value Object やドメインサービス的な役割まで含めた広い概念として扱われることが多く、またユースケースは DDD ではアプリケーション層に相当します。同じ用語でも文脈によって意味が変わるため、現場で混同しないように事前に用語の定義を揃えておくことが重要です。
第21章 叫ぶアーキテクチャ
著者見解
ソフトウェアのアーキテクチャは、設計図を見ただけで「何のためのシステムか」が直感的にわかるべきです。家の間取り図を見れば「これは一戸建てだ」と分かるように、ソースの最上位ディレクトリ構成やパッケージ名は「ヘルスケアシステム」「会計システム」「在庫管理」といった業務の意図を示していなければなりません。逆に「Rails」「Spring」「ASP」といったフレームワーク名で叫んでいるようでは、本来のアーキテクチャの役割を果たしていません。
Ivar Jacobson の言葉を借りれば、アーキテクチャはシステムのユースケースを支える構造です。優れたアーキテクチャはユースケースを中心に据え、フレームワークやデータベース、提供形態(Web など)といった「詳細」は後回しにできるように設計されます。これにより、フレームワークの採用を遅延させたり、別の技術へ置き換えたりする余地を残すことができます。
注意したいのは、フレームワークは強力な道具である一方、使い方を誤るとフレームワークにアーキテクチャを支配されてしまう点です。アーキテクチャがフレームワークに基づいてしまうと、ユースケース中心の設計が損なわれます。真にユースケース中心の設計であれば、各ユースケースのユニットテストはフレームワークや Web サーバー、データベースを立ち上げずに実行できるはずです。
結論として、アーキテクチャは「システムそのもの」を語るものであり、フレームワークや提供手段はあくまで実装の詳細にすぎません。設計段階で業務のユースケースを明確にし、それを叫ぶような構造を作ることが、柔軟で長持ちするシステムをつくる第一歩です。
筆者所感
私はプロジェクトのルートを2〜3階層ほど見ただけで「何をするアプリか」が直感的に分かるようにフォルダ構成や命名を工夫することが大事だと考えています。例えば src/Wiki や src/Wiki/Group といった構成なら、一目でこのシステムには「Wiki 機能」があって、なんらかの「グループ」に特化しているものだと分かります。トップレベルの構造が業務ドメインやサブドメインを語ることは、コード理解の速さやオンボーディングの容易さに直結するので重要だと考えています。
第22章 クリーンアーキテクチャ
著者見解
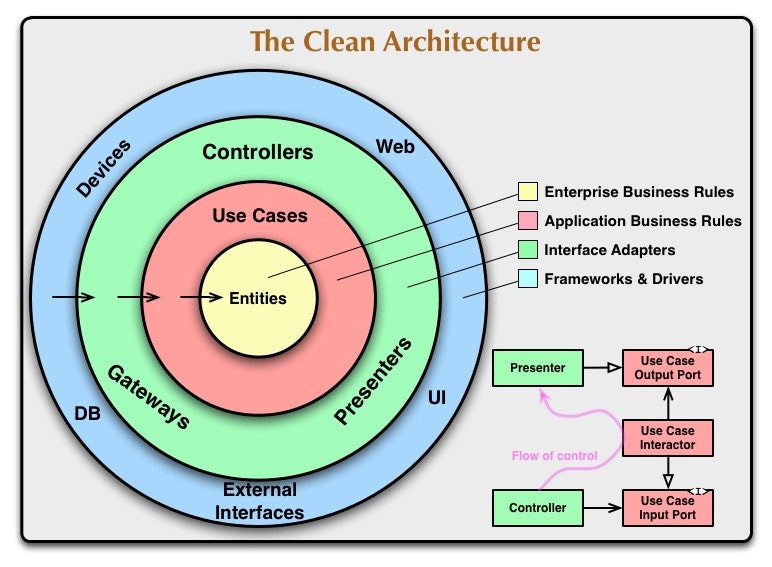
画像保存元:https://blog.tai2.net/the_clean_architecture.html
クリーンアーキテクチャは、ヘキサゴナルやDCI、BCE といった既存の考え方が目指してきた「関心事の分離」を同心円状のレイヤー構造として統合したものです。中心に近いほどビジネスの方針や抽象度が高く、外側ほど具体的な技術やツールになります。最も重要なルールは依存性の向きで、コードの依存は常に外側から内側へ向けるべきであり、内側のレイヤーは外側の詳細を知らないように設計します。
中心に位置するのがエンティティで、ここには企業やドメイン全体で意味を持つ最重要のビジネスルールとデータがカプセル化されます。エンティティは外部のUIやデータベース、フレームワークの変更に左右されるべきではなく、再利用性と安定性が求められます。その外側にあるユースケース層は、アプリケーション固有の振る舞いを実装し、エンティティを組み合わせて具体的な業務フローを達成します。ユースケースはエンティティに依存しますが、同時に外部の詳細には依存しないように設計されます。
さらに外側にはインターフェイスアダプター層があり、ユースケースやエンティティが扱いやすい内部フォーマットと、データベースやWeb、外部サービスが要求する外部フォーマットとの変換を担います。コントローラ、プレゼンター、リポジトリ実装、シリアライザなどのコードはこの層に置き、SQL や永続化の詳細もここに閉じます。最外層にはフレームワークやドライバ、ライブラリといった具体的な技術が位置し、ここには「接着(グルー)コード」程度しか置かないのが原則です。
境界をまたぐ際には設計上の注意が必要です。制御の流れが外側→内側であっても、ソースコードの依存方向は内側へ向けなければならないことがあり、これを解決するために依存関係逆転の原則(DIP)を用います。具体的にはユースケース側にインターフェイスを定義し、外側のプレゼンターやインフラがそのインターフェイスを実装する形で、制御と依存の矛盾を解消します。
また、境界を越えて渡すデータは単純で独立したデータ構造(DTO)に限るべきです。エンティティオブジェクトやデータベースの行表現をそのまま越境させてはいけません。例えば、データベースの行表現をそのまま越境させると、内側が外側の詳細に依存してしまい、ルール違反となります。外部形式と内部形式の変換はインターフェイスアダプターに任せ、内側が扱いやすい形でデータを受け渡すことが重要です。
要するに、クリーンアーキテクチャは「方針と詳細の分離」「依存は外側→内側」「境界越えは変換して単純なデータで行う」という原則に基づき、テスト可能でフレームワーク非依存、UI/DB の差し替えが容易なソフトウェア構造を実現します。これにより長期的な保守性や柔軟性が高まり、技術的な変化にも強い設計が可能になります。
筆者所感
プロジェクトで遭遇した具体例を紹介します。古い実装の一部で Eloquent モデル(Laravelフレームワークで提供されるORM)をそのままレスポンスに返していたため、別チームがテーブルスキーマを変更した際に返却オブジェクトの構造が変わり、フロント側は OpenAPI から生成した Zod スキーマで型チェックしていたため大量の ZodError が発生しました。原因は「永続化の詳細(Eloquent)」がそのまま外側に漏れていたことです。これはまさに「詳細に汚されている」典型例で、リポジトリ層で必要なフィールドだけを DTO に詰めて渡していれば防げたはずです。今回はフロントで表面化しましたが、同様の問題がビジネスロジック側に影響を与えていた可能性もあります。
第23章 プレゼンターとHumble Object
著者見解
プレゼンターは「Humble Object(控えめなオブジェクト)」パターンの典型例であり、アーキテクチャの境界を明確にして保護する役割を果たします。Humble Object パターンの肝は「テストしにくい振る舞い」と「テストしやすい振る舞い」を分離することです。振る舞いを二つのモジュール(またはクラス)に分け、テスト困難な部分はなるべくシンプルで振る舞いを持たない“控えめ”なオブジェクトに残し、実際のロジックや整形処理はテストしやすい別のオブジェクトに移します。
GUI の例でいうと、View(画面表示)は Humble Object に相当します。View の責務は画面要素にデータを移すことだけにし、その内部でデータを加工したり判断したりしないようにします。一方、Presenter はテスト可能なオブジェクトとして、アプリケーションから受け取ったデータをプレゼンテーション用にフォーマットし、View が受け取れるシンプルな ViewModel(文字列や真偽値、列挙型などからなるデータ構造)に詰めて渡します。こうすれば View の自動テストは最小限の確認で済み、Presenter のロジックはユニットテストで十分に検証できます。
同様の考え方はデータベースやサービスの境界にも適用されます。ユースケース(インタラクター)とデータベースの間には「データベースゲートウェイ」が置かれ、CRUD 操作を隠蔽するポリモーフィックなインターフェイスを提供します。ゲートウェイの実装側は Humble Object とみなせるため、テスト時にはスタブやテストダブルに差し替えてユースケースを容易に検証できます。逆にユースケース自体はアプリケーション固有のビジネスルールを担うため Humble ではありません。
ORM(たとえば Hibernate)の位置づけについては、ORM を「オブジェクト」と見なすのは誤解を招きます。外部から見ればオブジェクトは操作の集合であってデータ構造ではないため、RDB の行を単純にオブジェクトとして渡すのは適切ではありません。ORM はむしろ「データマッパー」であり、データベース層に属するのが自然です。データベースから取得した生データをアプリケーションが扱いやすい形式に詰める役割を担い、境界を越える際の変換はゲートウェイやアダプターで行うべきです。
サービス連携時も同様で、アプリケーションは外部サービスと通信する際にシンプルなデータ構造にデータを詰め、境界を越えて渡します。受け側ではリスナーやアダプターが外部フォーマットを受け取り、アプリケーション内部で使える単純なデータ構造に変換します。こうした設計により、境界を越えるデータは常に独立で単純な DTO(Data Transfer Object)になり、内外の結合が緩やかになります。
まとめると、Humble Object パターンはアーキテクチャの境界の近くに現れやすく、境界ごとに「テストしにくい部分」をシンプルに抑え、「テストしやすいロジック」を内側に残すことでシステム全体のテスト容易性と保守性を大幅に向上させます。
筆者所感
今のプロジェクトではフロントが Vue.js(多くがOptions API)で書かれており、this に依存した methods やライフサイクルでロジックがコンポーネントに入り込んでいるため、ユニットテストが非常に書きにくくなっており、現状、フロントのテストはないに等しい状況です。そこで Composition API への移行を進めつつ、 Composableや純粋関数に段階的に移行して、UI(テンプレート/描画)とロジック(状態・振る舞い)を明確に分離するリファクタリングが進んでいます。これにより UI は「Humble Object」として薄く保ち、ロジックはテスト可能な単位でカバーできるようになります。
第24章 部分的な境界
著者見解
本格的なアーキテクチャ境界は有益である一方、導入と維持にかなりのコストがかかります。双方向のポリモーフィックなインターフェイス、入出力用のデータ構造、両側を独立にコンパイル/デプロイできるようにするための依存関係管理──これらを用意しておく必要があるためです。そのため優れたアーキテクトの判断としては、「境界は重要だが、あらゆる箇所に完全な境界を作るのはコストに見合わない」ことが多く、必要になったら拡張できる余地だけ残しておく、という折衷を取ることがあります。こうした予備設計はアジャイルのYAGNI(You Aren’t Gonna Need It)批判を受けることもありますが、実務では「部分的な境界」を導入することがよくあります。
部分的な境界の一つのやり方は、インターフェイスや入出力データ定義などはあらかじめ用意しておきつつ、実際のコンパイルやデプロイは単一のコンポーネントとして行う方法です。外形的には完全な境界と同等の設計(インターフェイス、DTO、スタブ化の余地など)を用意するものの、運用上は管理するコンポーネント数を増やさずに済みます。これによりバージョン管理やリリース管理の負荷を抑えつつ、将来的に分離が必要になれば比較的スムーズに独立させられる可能性を残せます。ただし、片側の実装が他方の実装に依存するようになってしまうと、後から分離する手戻りが大きくなる点には注意が必要です。
「将来の分離」を意図して片側だけインターフェイス化する手法としては Strategy パターンが使えます。クライアント側は ServiceBoundary のようなインターフェイスへ依存し、現在はそのインターフェイスを ServiceImpl が実装している構造です。これにより将来 client と ServiceImpl を分割したくなったときに、依存関係逆転の形が既にできているため分離が容易になります。ただしインターフェイス経由で利用することを守らせるのは開発者やアーキテクトの規律に依存するため、実際にはガバナンスが必要です。
さらに手軽な折衷案として Facade パターンを用いる方法があります。Facade は境界を単一のクラスとしてまとめ、クライアントはこのファサードのメソッドだけを呼び出します。実装の詳細はファサードの裏側に隠れますが、ファサード自身が内部の複数サービスに逐次的に依存しているため、静的型付け言語ではファサードの背後にあるクラスを変更するとクライアントも再コンパイルが必要になるなど、隠ぺいによるトランジティブな依存が残ります。つまり Facade はコストも低く導入は容易ですが、真の独立性や将来の分離を強く保証するものではありません。
これらのアプローチはそれぞれトレードオフを持ち、状況に応じて使い分けるのが現実的です。初期コストや運用負荷を重視するなら部分的境界やファサードで始め、分離の必要性が増した段階で段階的に完全な境界へ移行する――という段階的進化はよく採られるパターンです。重要なのは「境界をまったく考慮しない」ことではなく、コストと将来性のバランスを見据えた上で、部分的な境界を設計的に取り入れる判断をすることです。
筆者所感
DIフレームワークが充実している現代では、境界は可能な限りインターフェイス越しに渡す設計が現実的で安全だと考えています。Controllerがビジネスユースケースの具象クラスに直接依存すること自体は依存関係のルール違反ではありませんが、詳細を知りすぎたり、使わないメソッドに依存したりしやすくなるため、コンストラクタ注入でインターフェイスを受け取る形にしておけば将来的な分離や差し替えが容易になります。
第25章 レイヤーと境界
著者見解
ソフトウェアを単純に「UI」「ビジネスルール」「データベース」の三つに分けて考えるのは分かりやすい一方で、実際のシステムではもっと多くのコンポーネントと境界が存在します。1972年のテキストゲーム「Hunt the Wumpus」を例に取ると、単純なテキストUIとゲームルールを分離し、さらに永続化や言語/配信方法などの関心ごとを別のコンポーネントに切り出すことで、各部分を独立して置き換えられる設計が可能になります。
具体的には、UI と GameRules(ゲームのルール)は言語に依存しない API でやり取りし、UI 側は API の結果を適切な言語に翻訳して表示します。同様に、GameRules が状態を保存するための DataStorage とは別の API を用意しておけば、保存先が RAM、フラッシュ、クラウドなどに変わっても GameRules 側は影響を受けません。重要なのは、こうした境界のインターフェイスは上流のコンポーネントが定義・所有するという点です。例として Language の API を上流が所有し、English や Spanish がその具象実装となる構成が示されます。
情報の流れは典型的に次のようになります。ユーザー入力は TextDelivery(配信層)から入り、Language(翻訳層)でコマンドに変換されて GameRules に渡される。GameRules は処理結果を DataStorage に送り、出力は再び Language → TextDelivery を経てユーザーに返されます。オンラインプレイのようにネットワーク要素が加われば、情報の流れが増え、必要な境界も増えていきます。さらに、ゲームの内部でも地図管理(MoveManagement)とプレイヤー状態管理(PlayerManagement)のように別々の方針が存在し、それらを別プロセスやサービスに分離することが合理的な場合もあります。
ここから学べるのは、境界はあらゆるところに潜んでおり、いつどこで必要になるかをアーキテクトが見極める必要があるということです。ただし完全な境界を最初からすべて構築するのはコストが高く、無用な分離は開発や運用の負担になるため、どこまで実装するかはトレードオフになります。重要なのは「境界をまったく考慮しない」ことでも「無差別に全部作る」ことでもなく、コストと便益を見比べて段階的に判断することです。
実践的には、設計段階で潜在的な境界を意識しつつ、システム進化の中で摩擦(変更が難しい、テストしにくい、リリースが大変など)の兆候を監視します。境界を作るコストと、境界を作らないことによる将来的なコスト(手戻り・統合困難・運用負荷など)を定期的に比較し、無視コストが実装コストを上回る時点で境界を実装する――この反復的な判断が望ましいアーキテクチャ運用です。
筆者所感
レイヤーごとに境界は引けますが、実務ではフォルダ構成をレイヤー単位にするかどうかはチームの好みや事情によります。私は可読性の観点からレイヤー別フォルダを推しますが、「GameRules」など既にドメインが明示されている場合に、さらに「Domain」フォルダを作るのは冗長だという意見も理解できます。肝心なのはどちらが正解かを議論することではなく、チームで方針を決めて一貫して運用することです。
第26章 メインコンポーネント
著者見解
Mainコンポーネントはシステムの最も外側に位置する「究極の詳細」です。通常は実行のエントリポイント(main関数)として動作し、オペレーティングシステム以外からは依存されません。Mainの役割は、FactoryやStrategyなどのグローバルな要素や外部リソースを初期化し、依存性注入(DI)を含めた初期設定を行ったのち、システムの上位レベルへ制御を渡すことにあります。
実装上のポイントとしては、MainでDIフレームワークを使って必要な依存関係を注入し終えたら、その先はフレームワークに依存しない通常のコード構造で動かすのが望ましいということです。Mainは「最も汚れた仕事」を引き受ける場所なので、詳細な設定や環境差の処理はFacadeや別のモジュールに委ね、Main自体はできるだけ薄く保つとよいでしょう。こうしておけば、Facade側の変更があってもMainを再コンパイル/再デプロイする必要を減らせます。
また、Mainはアプリケーションのプラグインのように扱えます。開発・テスト・本番用や国別・顧客別など、設定ごとに複数のMainコンポーネントを用意して切り替えることが可能です。要するに、Mainは初期状態や構成を決め、外部資源を集め、上位層の方針に制御を渡す「起動と橋渡し」の役割を持つコンポーネントだと考えてください。
筆者所感
Main コンポーネントに限らず、どこでフレームワークを使い、どこを純粋なコードに保つかをチームで明確にすることが重要だと思います。私の現プロジェクトでは、ドメインやユースケース、それらにデータを受け渡すDTO といったコア部分は純粋な PHP コードで実装し、Repository/Factory/Query の実装や Action クラスのリクエスト取り扱いなど外側の責務だけに Eloquent や Laravel の機能を使う方針にしています。こうしておけばフレームワーク依存がコアに漏れず、テストや移植性が確保されます。チーム内で「ここはフレームワークを使って良い/使ってはいけない」を合意してドキュメント化しておくことが肝要です。
第27章 サービス:あらゆる存在
著者見解
サービス指向やマイクロサービスは最近の流行ですが、「サービスを使えばそれがそのままアーキテクチャになる」という考えは誤りです。本章の要点を平易にまとめます。
まず、サービスは「実行単位(プロセス/プラットフォーム)の境界を越える関数呼び出し」に過ぎないことを押さえておきます。アーキテクチャとは、本当に重要な境界──上位の方針と下位の詳細を分離し、依存性のルール(どちらがどちらに依存するか)を守ることで定義されます。サービスを分割しただけで、必ずしもその分離が達成されるわけではありません。サービスにも「アーキテクチャ上重要なもの」と「単に振る舞いを分けただけのもの」がある、という点を理解しておく必要があります。
サービスの利点としてよく挙げられるのは、
- 実行・開発・デプロイを独立させやすく見えること、
- 担当チームをサービスごとに割り当てやすいこと(「チームがサービスを所有する」形)
といった点です。しかし実際には、サービス間で共有するデータや横断的関心事がある限り、サービス同士の結合は残ります。たとえばサービス間でやり取りするデータレコードに新しいフィールドが追加されれば、そのフィールドを扱うすべてのサービスを改修しなければならないことが多く、結果として密結合が発生します。さらに、サービスのインターフェイスは関数インターフェイスほど厳密に定義・管理されない場合があり、その点で思ったほど独立性が得られないこともあります。
実例として「タクシーに子猫宅配機能を追加する」ケースを考えると分かりやすいです。賛同する事業者もあれば賛同しない事業者もおり、運転手や乗客のアレルギー配慮など横断的なルールが絡みます。この種の横断的関心事は、サービスを分けただけでは解決せず、システム全体に影響を及ぼします。
では解決策はないのかというと、あります。重要なのは「サービス内部のコンポーネント設計」です。サービスを内部で SOLID などの原則に従ったコンポーネント群に分割しておけば、新しい機能は既存ロジックを広げるのではなく、抽象基底クラスを継承する新しいコンポーネントとして追加できることが多いです。例えば Java のサービスであれば、基本ロジックは抽象クラス群として jar にまとめ、新機能を別の jar として追加する形で動的に拡張できます(OCP に合致)。この場合、サービスの再デプロイを最小限に抑えつつ機能追加が可能になります。
結論としては次のとおりです。
- サービスそのものは便利な実行単位だが、それ自体がアーキテクチャのすべてを決めるわけではない。
- 真のアーキテクチャは「境界」と「依存性のルール」によって成り立つ。サービスは、その内側にあるコンポーネント構造に依存して初めて柔軟性を発揮する。
- サービス設計の際は、データ共有や横断的関心事が結合を生まないように内部アーキテクチャを慎重に設計する必要がある。
- 必要ならばサービスを分割して使うが、それはアーキテクトがコストと利点を評価した上で行うべき段階的判断である。
要するに、サービスは有力な手段の一つだが、正しいアーキテクチャを得るためには「サービスをどう内部で構成するか」「境界と依存をどう定めるか」がより重要だ、ということです。
筆者所感
この章はこれまでの議論を「サービス」の視点でまとめ直したものだと受け取っています。つまり、アーキテクチャは境界を定めて依存関係を管理することが本質であり、サービスは「大きな境界」の一つに過ぎず、境界はあらゆるレベル(コンポーネント内外)に存在します。サービス間のデータ共有があったりすると、見かけ上は分離していても密結合が残りやすくなります。サービス化はあくまで手段であり、サービス間・サービス内の境界設計と依存制御をきちんと行うことが、将来の保守性や柔軟性を左右します。
第28章 テスト境界
著者見解
テストもシステムの一部であり、依存関係のルールに従います。テストは常に被テストコードに依存する非常に具体的なコンポーネントであり、クリーンアーキテクチャの円で言えば最外側に置かれるべきものです。テストは運用には不要でユーザーに提供するものでもありませんが、開発を支える独立したコンポーネントとして設計・配置する価値があります。
問題になるのは、テストを設計から切り離したり極端に分離してしまったりすると、逆にテストが脆弱化してしまう点です。特に GUI を使った統合的なテストは、画面構造やナビゲーションの小さな変更で大量のテストが壊れるため、システムの変更を躊躇させる「硬直化」を招きます。こうした「脆弱なテスト」は開発速度を低下させる大きな原因です。
このため設計の第一原則は変わりません──変化しやすいものに依存しないこと。GUI に依存してビジネスルールを検証するのではなく、GUI を使わなくてもビジネスルールを直接検証できるようにシステムを設計する必要があります。具体的には、テスト用に使える API を用意して、セキュリティ制約を迂回したり高コストな外部リソースをバイパスしたりできる「スーパーパワー」をテスト側に与えることが有効です。このテスト API は、インタラクターやインターフェイスアダプターが提供する機能のスーパーセットとして位置づけられ、テストと本番ロジックを分離します。
注意すべきは「構造的結合」です。クラス単位・メソッド単位でテストを厳密に結びつけすぎると、プロダクションコードのリファクタリングがテストの大改修に直結し、テストと本番コードの進化を阻害します。テスト API はアプリケーションの内部構造を隠蔽し、プロダクションコードを自由に一般化・抽象化できるようにする役割を持ちます。逆にテストがアプリケーション構造に深く結びついていると、時間とともにテストは詳細化・個別化し、本番コードは抽象化・一般化するという進化の分離ができなくなります。
さらに、テスト API が持つ「スーパーパワー」は本番環境に置くと危険です。したがって、テスト専用の機能やその危険な実装は、本番とは別に独立してデプロイ可能なコンポーネントとして分離しておくべきです。
まとめると、テストはシステムの外側でも部外者でもなく、重要な構成要素です。テストを設計の一部として組み込み、テスト容易性を高めるための API やアダプターを用意し、構造的結合を避けてテストと本番コードの独立した進化を可能にすることが、高品質で変化に強いソフトウェアを保つために不可欠です。
筆者所感
現在のプロジェクトでは、ドメインやユースケース、DTO は適宜モックを利用してユニットテストを行い、Query/Repository/Factory の実装はテスト用 DB を使った統合テストでカバーしています。一方で Action クラスやフロントエンドはテストが未実装です。今後はフロントのロジックを Composition API の Composable に切り出してテスト可能にし(現在は大半がOptions APIのVueファイルに直接書かれている)、段階的にカバー範囲を広げる予定です。変化しやすい箇所はテストが脆くなりやすいため最初から網羅を目指さず、サービスの成長に合わせて「コストに見合う箇所だけを選んでテストする」方針が現実的だと考えています。実際、テスト用 DB を使った統合テストは最初から導入しておらず、サービスが成熟し、安定期に入ってきたことで、統合テストを書いても、頻繁に壊れない目処が立ってきたので、コストとメリットが逆転して統合テストの導入にいたりました。
第29章 クリーン組込みアーキテクチャ
著者見解
組込み開発においては、ソフトウェアとハードウェアの関係性を慎重に設計しないと、ソフトウェアが「ハードウェア化」してしまい長持ちしない、という問題がよく起きます。Doug Schmidt の指摘どおり、ファームウェアの寿命が短いのはそれが単に ROM に置かれているからではなく、何に依存しているか――ハードウェアの進化にどれだけ左右されるか――によって決まるのです。したがって組込みコードの構造は、ハードウェア依存部分を極力局所化し、それ以外をハードウェアから独立させる方向で考える必要があります。
Kent Beck が示したソフトウェア構築の三段階(まず動かす、次に正しくする=リファクタリング、最後に高速化)を念頭に置くと、組込みコードは「動かす」ことに偏りがちで、リファクタリングして長寿化する設計が後回しにされやすいことがわかります。組込み固有の制約(限られたメモリ、リアルタイム性、特殊な IO、特定のツールチェーンなど)があるとはいえ、クリーンアーキテクチャの原則――関心事の分離、インターフェイスに対するプログラミング、代替可能性――は組込みにも適用できます。むしろ、ターゲットハードウェアに依存した設計を避けることで、オフターゲットでのテストや将来の移植が容易になり、開発速度・保守性が向上します。
具体的な実践としては、ハードウェア依存コードをファームウェアや HAL(Hardware Abstraction Layer)に閉じ込めることが重要です。HAL は上位ソフトウェアが必要とする抽象化 API を提供し、フラッシュやレジスタといった低レベル操作の詳細を隠蔽します。アプリケーションは「名前と値のペア」などの高レベルな操作を HAL の API に対して行えばよく、どのような物理メディアに保存されるかを知る必要はありません。これにより、ハードウェアが変わっても上位コードはほとんど影響を受けません。
さらに、プロセッサ固有の拡張(ベンダー製コンパイラの特殊キーワードや直接レジスタ参照など)は、その利用箇所を極限まで限定し、可能なら独立したファームウェアモジュールに閉じ込めるべきです。ベンダー独自のヘッダ(例:acmetypes.h)を直接散在させると移植性は大きく損なわれるため、まずは標準的な stdint.h 等を使うか、自前でターゲット向けの互換ヘッダを用意して依存を局所化します。
OS を使う場合も同様の考え方が有効です。RTOS や組込み Linux に直接依存すると、将来の OS 変更やベンダー事情の変化で大きな手戻りが発生しがちです。そこで OS 抽象化層(OSAL: OS Abstraction Layer)を設け、スレッドやメッセージパッシングなどの基本機能をアプリケーション用の抽象 API にラップしておけば、新しい OS 向けの OSAL 実装を用意するだけで移植やテストが容易になります。OSAL にテスト用のフックを作っておけば、ターゲット OS がなくてもオフターゲットでアプリケーションロジックを検証できます。
また、条件付きコンパイルでターゲット差分を散らす手法には注意が必要です。多用すると DRY 原則に反し、同じロジックが複数箇所に複製・分散して管理が難しくなります。HAL/OSAL を使って差分を隠蔽し、リンカやランタイムバインディングで実装を切り替える方法のほうが、可読性・保守性・テスト性の点で優れています。
総じて、クリーン組込みアーキテクチャでは次の点を心がけます:ハードウェア寄りのコードは局所化してファームウェアに閉じ込める、上位ロジックは抽象 API に依存させてハード/OS の変化から守る、ベンダー固有の拡張は限定的に扱う、そしてオフターゲットでのテストが容易になるよう継ぎ目(seams)を設ける――これらを実施すれば組込みソフトウェアの移植性・テスト容易性・長期的な保守性が大きく向上します。
筆者所感
専門的なハードウェア知識は乏しいですが、本書を通じて気付いたのは「クリーンアーキテクチャのルーツはハードウェア依存の問題にある」ということです。昔はハードウェア仕様の変更で同じ振る舞いをするコードでも大幅な書き換えが必要になり、それを避けるために機能をプラグイン化して差し替え可能にする発想が生まれました。そこから依存関係の整理や抽象化の手法が発展し、結果的に現在のクリーンな設計思想へと結実した――そう理解しています。