はじめに
こちらは「ゼロつく3DeepLearning_cp3」の記事の続きです。
「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」についてのまとめを数回に分けて行いたいと思います。
YOUTUBEでのおすすめチャンネルは以下の通り
何をまとめるのか
さて、このまとめではpythonのコードを動かしたり、何か実装するということは行いません。
ちなみに、書籍のソースコードはこちらにまとめられています。
なので1章はとばし、2章からのスタートになります。
今回は4章をまとめます。実装ベースの部分が多いので、少し割愛した形にはなりますが、
引き続き個人的に重要だと思うポイントを記載したいと思います。
4章 ニューラルネットワークの学習
機械学習では、訓練データとテストデータを分けて用います。
訓練データのみを使って学習を行い、テストデータを使って訓練したモデルを評価します。教師あり学習だと、訓練データを用いて正解を教え込み、テストデータでそのモデルの精度を評価する形です。
モデルの精度は、ニューラルネットワークの重みを調整することによって高まります。
前章で、ニューラルネットワークは適切な重みを自動で学習できるということをお伝えしたかと思いますが、どのようにして適切な重みを決めるのでしょうか?
実は、ある関数の値を小さくすることによって決められます。最適な重みを計算する関数を損失関数と言います。
損失関数
損失関数は、さまざまな関数がありますが、本に出ている2乗和誤差と交差エントロピー誤差を紹介します。
どちらも出力と正解の誤差を計算しています。
2乗和誤差
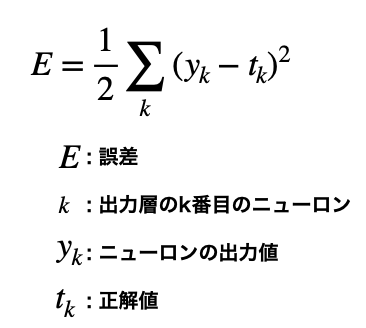
各ニューロン出力値と正解値の差を2乘した値の総和をとったものを二乗和誤差とよびます。
1/2はこの関数を微分すると$2*1/2Σ_k(y_k-t_k)$となり、整数部分を打ち消すことができるためついています。
交差エントロピー誤差
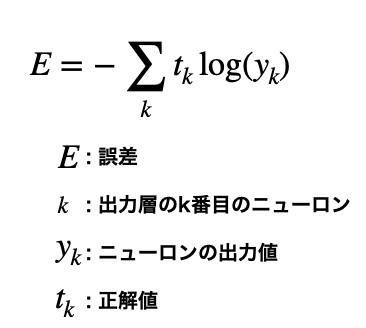
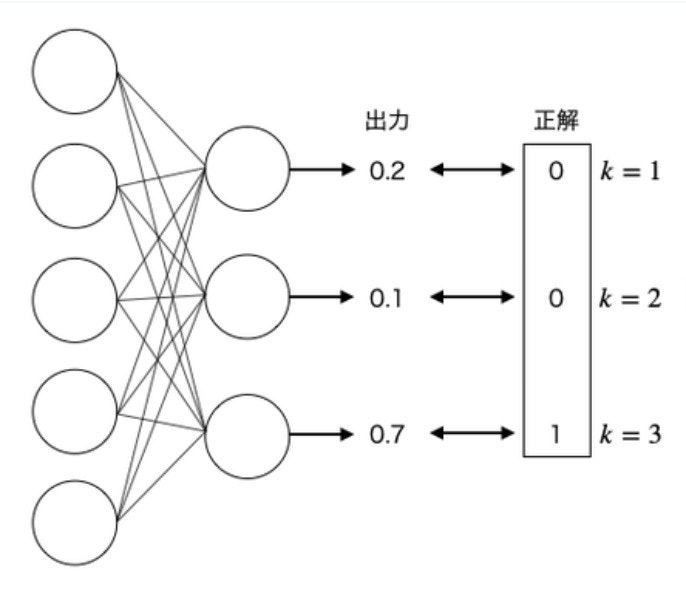
例えば、以下のような層を考えます。
Eは日本語では誤差ですが、Errorの略です。
正解は$k=3$なので、出力層の3番目のニューロンについて考えたいと思います。(1,2番目は正解の値が0なので、式に当てはめると$E=0$になります。)
上記の式に代入すると以下の通りです。
$$E=-1*log(0.7)$$
$$E=0.36$$
では、$k=3$の出力が0.2だった際はどうでしょうか?
うまく学習できていない場合の出力です。交差エントロピー誤差の値は以下のようになります。
$$E=-1*log(0.2)$$
$$E=1.61$$
うまく学習できていない場合の方が交差エントロピー誤差の値が大きいことがわかります。
ニューラルネットワークの学習は、この誤差の値をより小さくなるように計算し重みを更新することを言います。
勾配法
ニューラルネットワークの学習は、この誤差の値をより小さくなるように計算し重みを更新すると先ほど述べました。つまり、誤差の最小値を見つけると最適な重みとして更新できるようになります。
どうやって最小値、もしくは最小値に近い値を見つけるかというと、勾配(傾き)を利用します。
イメージとしては以下のような形です。
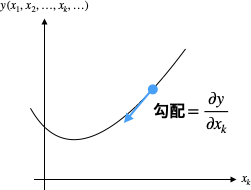

学習率の値は0.01や0.001など、前もって値を決める必要があります。この値は大きすぎても小さすぎてもいけません。
ニューラルネットワークの学習においては、学習率の値を変更しながら正しく学習できているか確認を行うのが一般的です。
ニューラルネットワークの学習の手順
学習の手順を確認すると以下のような順序になります。
[前提]
ニューラルネットワークは適応可能な重みとバイアスがあり、この重みとバイアスを訓練データに適応するように調整することを「学習」と呼ぶ
1. ミニバッチ
訓練データの中からランダムに一部のデータを選び出す。その選ばれたデータをミニバッチといい、そのミニバッチの損失関数の値を減らすことを目的とする。
2. 勾配の算出
ミニバッチの損失関数を減らすために、各重みの勾配を求める。勾配は損失関数の値を最も減らす方向を示す。
3. パラメータの更新
重みを勾配方向に少しだけ更新する。
4. 繰り返す
1.2.3を繰り返す
実際の処理の際に気を付けること
- 学習させる際は学習データとテストデータに分けて行います。
- ミニバッチといって、全部のデータを学習させるのではなく、データの一部を学習させます。これは計算時間の短縮を目的としています。
- 微分によって重みパラメータの勾配を求めることができます。しかし、入力から順番に微分を計算していくと時間がかかります。
一方で、5章で紹介する誤差逆伝播法は高速に勾配を求めることができます。
参考文献