はじめに
こちらの記事は、Dataiku AcademyのAdvanced Prepare Recipe Usageをやってみました。(前編) の続きになります。前編をご覧になっていない方は、是非そちらもご覧ください。より、Prepareレシピに関する理解が深まると思います。
※前回の記事では、次回の後編で完結すると述べましたが、今回の記事を中編とし、次回の後編で完結する、全3部に変更させていただきます。
本記事で扱う内容
Dataiku Academy - Advanced Prepare Recipe Usageに関する内容です。
今回はそのうち、下記の2つをご紹介します。
・Enriching Web Logs - ログの解析に関するお話
・Applying Prepare Steps to Multiple Columns - 複数のカラムにステップを追加するお話
Enriching Web Logs
ログを解析するのは手間がかかりますよね。(こう思っているのは私だけ…?![]() )
)
Dataikuのいくつかのプロセッサは、数回のクリックだけでログの解析を簡単にしてくれるようです。
チュートリアルでは、ウェブログデータを素早く解析する方法が紹介されています。
Importing the Data
サンプルデータとして、おもちゃ情報に関するアクセスログのデータセットが用意されていますので、これをDataikuにインポートします。
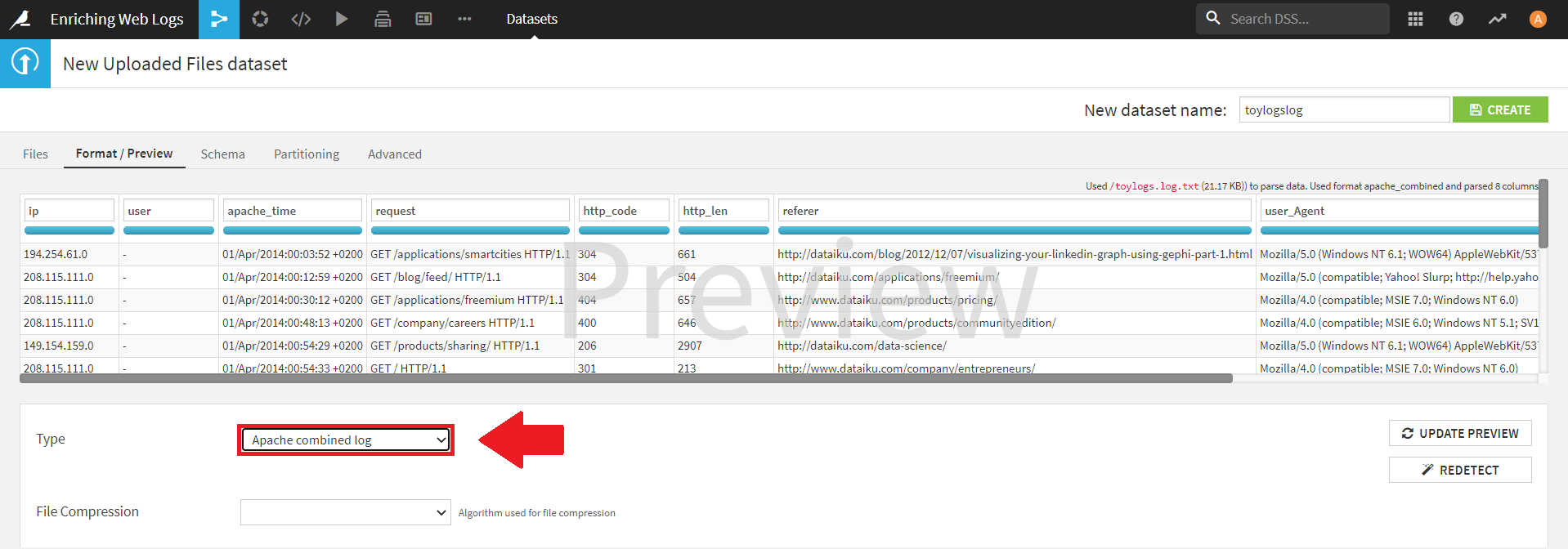
インポートすると、データセットのプレビュータブで、下図のように、「Apache combined log」というデータフォーマットを自動で検出してくれます。
そのまま、右上の [CREATE] をクリックし、データセットを作成しましょう。
これで、データセットの準備ができました。
GeoIP Enrichment
作成したデータセットを使い、ラボでビジュアル分析を行ったり、Prepare レシピを作成したりすることができます。
(今回は、チュートリアルに示されている、ラボでの分析を行ってみます。)
まずは、IP アドレスから地理情報を抽出してみます。
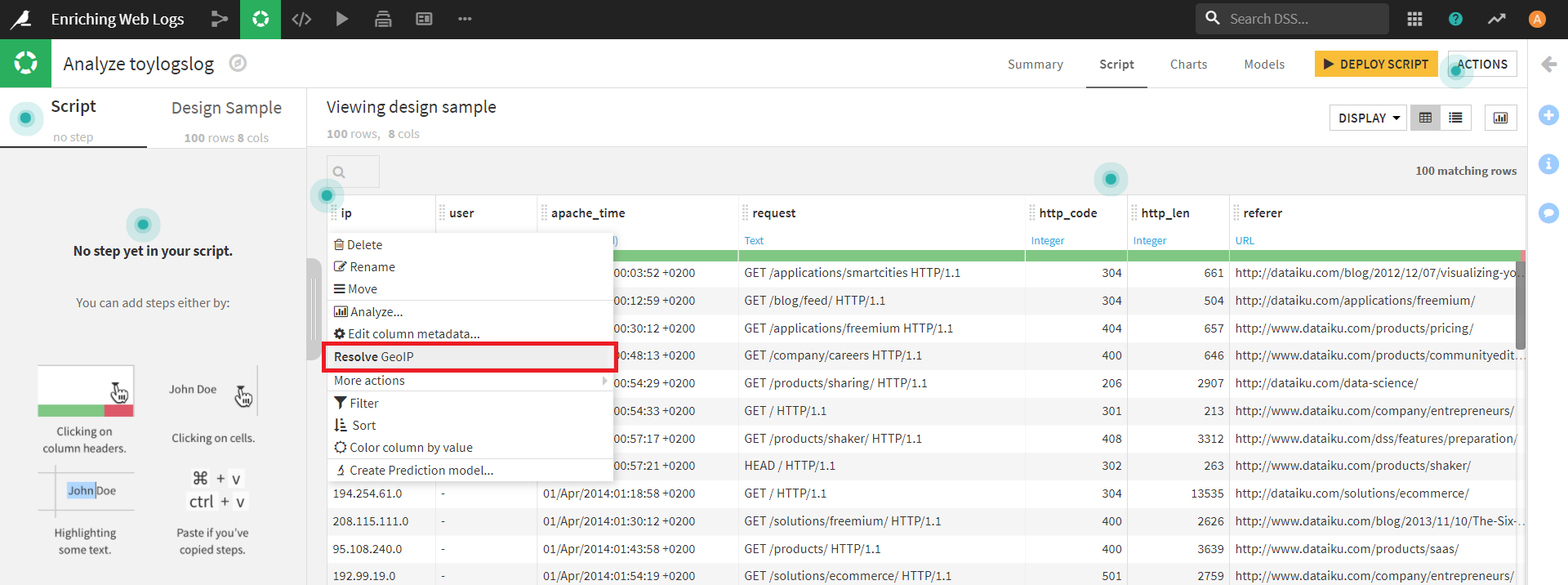
ラボで「ip」カラムをクリックすると、下図のようにタブが表示されます。
ここでは、タブの中央付近にある [Resolve GeoIP](GeoIPに関する問題を解決する) を選択します。
すると、下図のように、新たなカラム(背景色が青のところ)が追加されます。
追加されたカラムを見ると、先ほどの操作では、ipカラムから様々な地理情報を抽出しているようです。
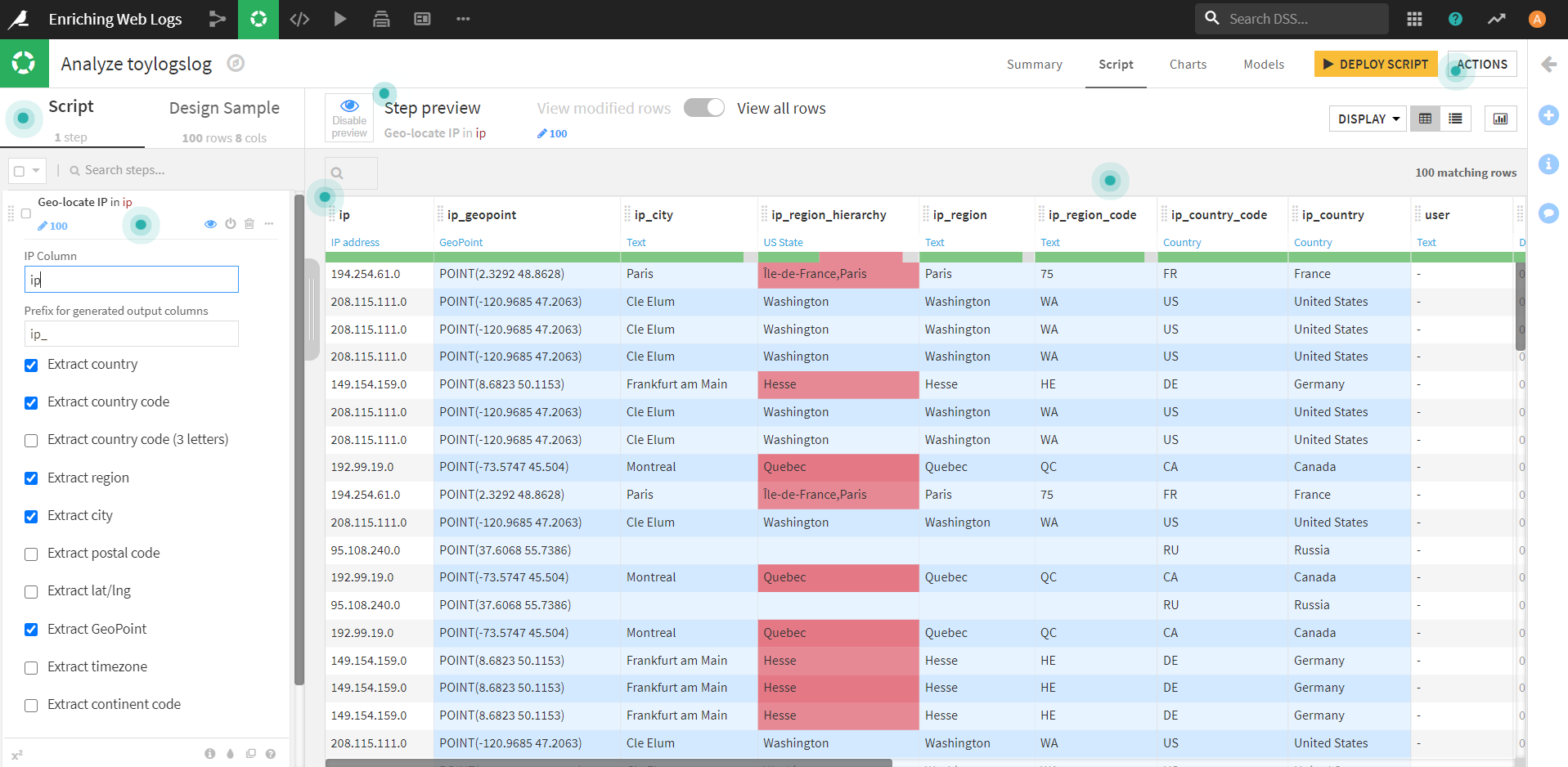
上記で7つの新しいカラムが作成されましたが、今回は、国とGeoPoint(地点情報)のみを抽出します。
それに合わせて、左端の「Geo-locate IP in ip」欄のチェックを、 「Extract country」「Extract GeoPoint」 の二つに変更します。
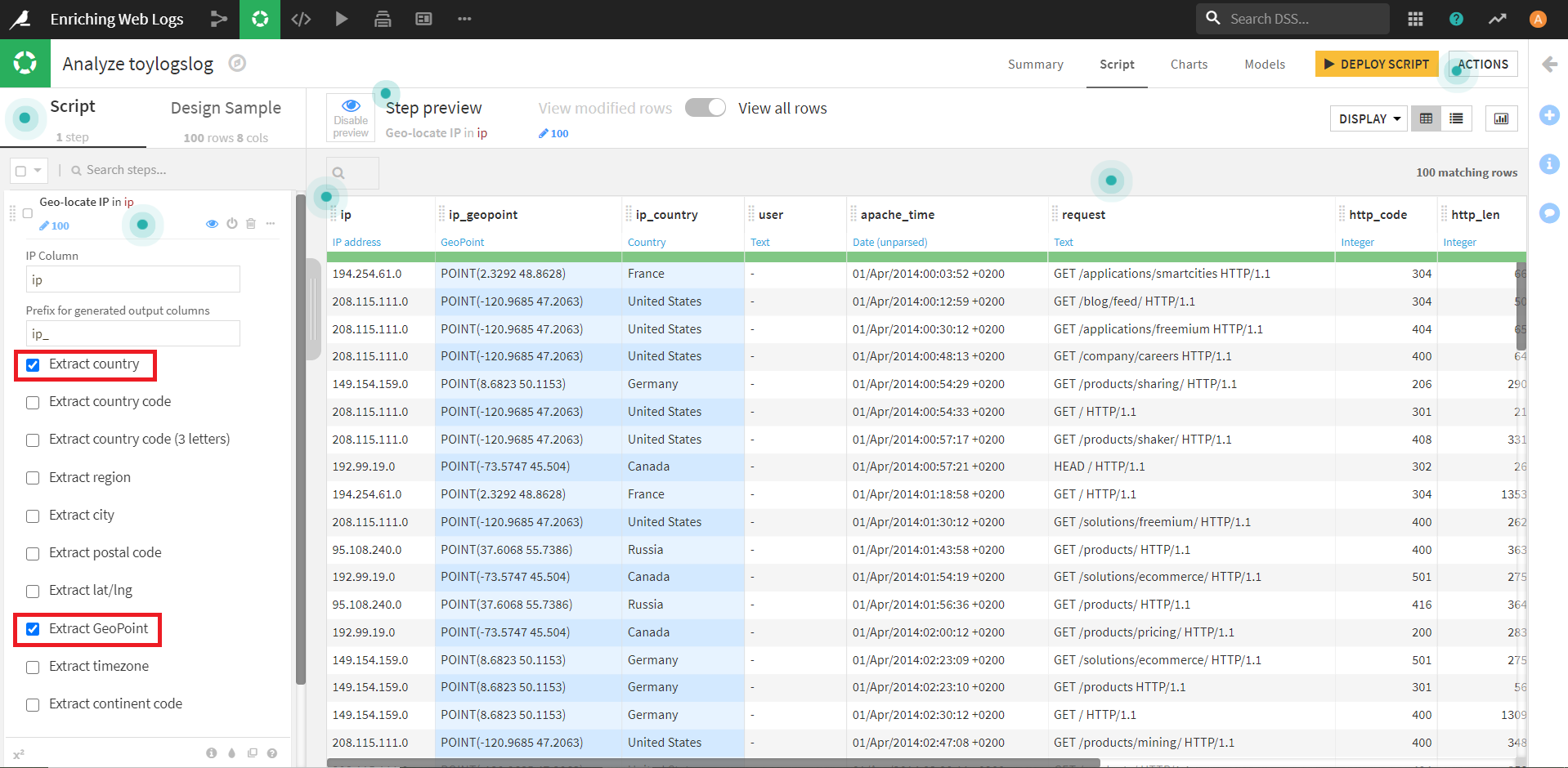
チェックを外したカラムは自動で削除されます。
ここまでで、国と位置情報を取得することができました。
次に、取得した国の情報を活用して簡単な分析を行ってみましょう!
まずは、Reverse Geocoding / Admin maps プラグインをインストールします。
このプラグインは、インストール後にDataikuを再起動する必要があります。
再起動後、プラグインのインストールに成功しているか確認します。
プラグインのインストールが確認できたら、ラボの画面に戻り、Chartsタブから、グラフの作成を行います。
グラフの種類は、「Maps」(地球のアイコン)の「Administrative Map」「Filled」を選択します。
カラムの設定は下記のようにします。
・Show(Geo フィールド): ip_geopoint
・Details(カラードロップフィールド):Count of Records
すると、下図のような、塗分け地図が作成されます。
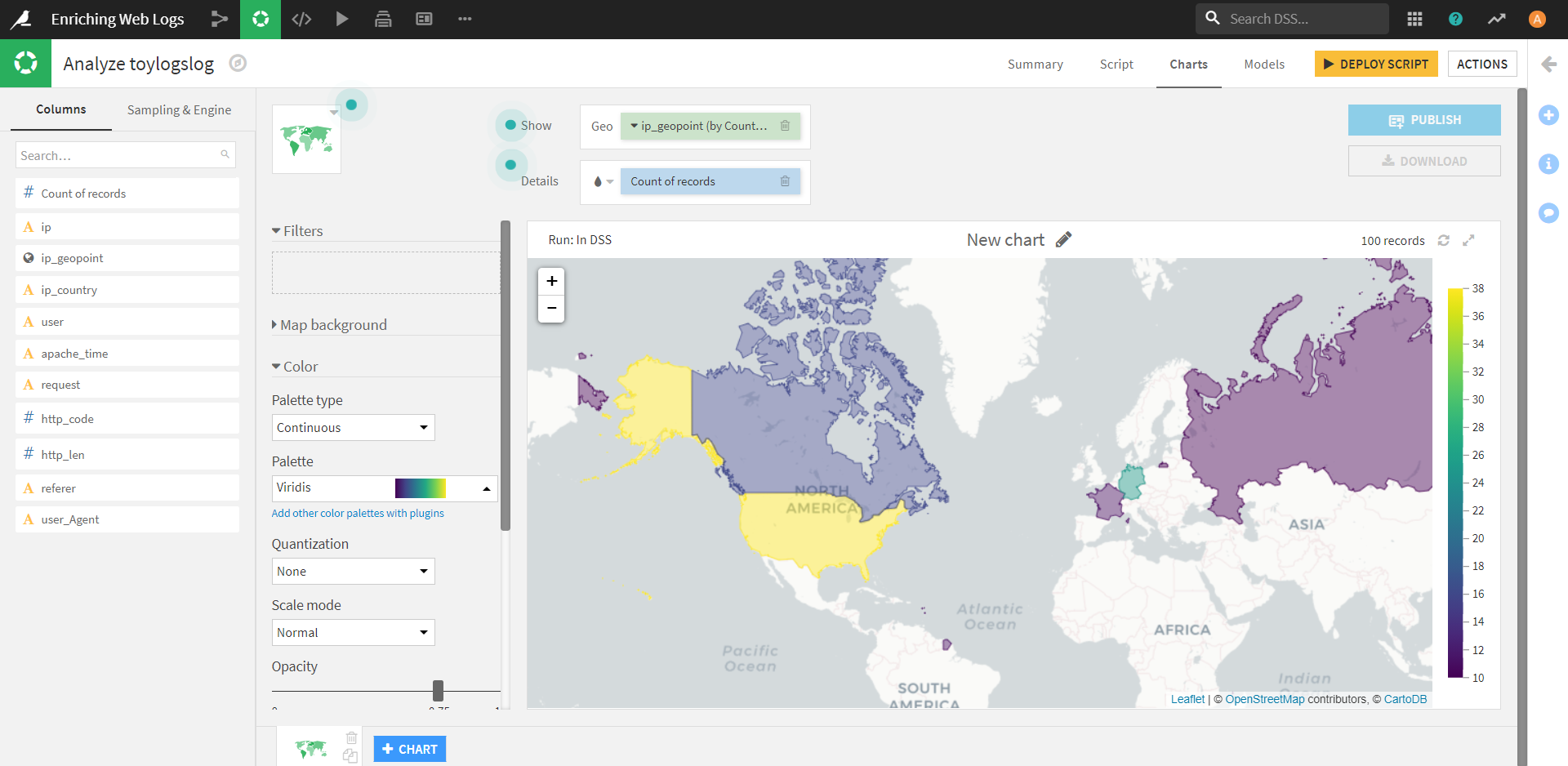
描画した図を使うと、カラーバーとマップからデータの分布が簡単に把握でき、地域性を見つけるヒントになりそうです。
今回の例では、アメリカにレコード数が多く、次いでドイツが多いですね。
個人的には南アメリカ大陸に一つだけ色付けされている地域が気になっていたのですが、ここはどうやらフランス領のギアナという地域のようです。
(画面には映っていないところでも、ぽつぽつと島国に色付けされていたのですが、すべてフランスの領土でした。私は知らなかったのですが、国情報に基づく場合、Dataikuでは本土以外にも今回の色付けのような操作が適用されるようです。)
今回の内容からは外れますが、Dataikuの地理空間データの操作に関するチュートリアルも用意されているようです。こちらをやってみると、上記で作成した塗分け地図のより良い活かし方が分かるかもしれません。
User-Agent Parsing
ユーザーエージェント情報が解析できると、以下のような問いにも答えられるのではないでしょうか。
・ユーザーはどのような端末を使用しているか?
・どのブラウザが最も使用されているか?
・どのブラウザが最も多くのエラーステータスを生成しているか?
・使用している端末と、販売の間に相関関係があるか?
Dataikuには、ユーザーエージェント情報を解析するための専用プロセッサが用意されているようです。
先ほどのデータに戻り、「user_Agent」カラムをクリックすると、タブが表示されます。
その中から、 [Classify User-Agent](ユーザーエージェントの分類)を選択します。
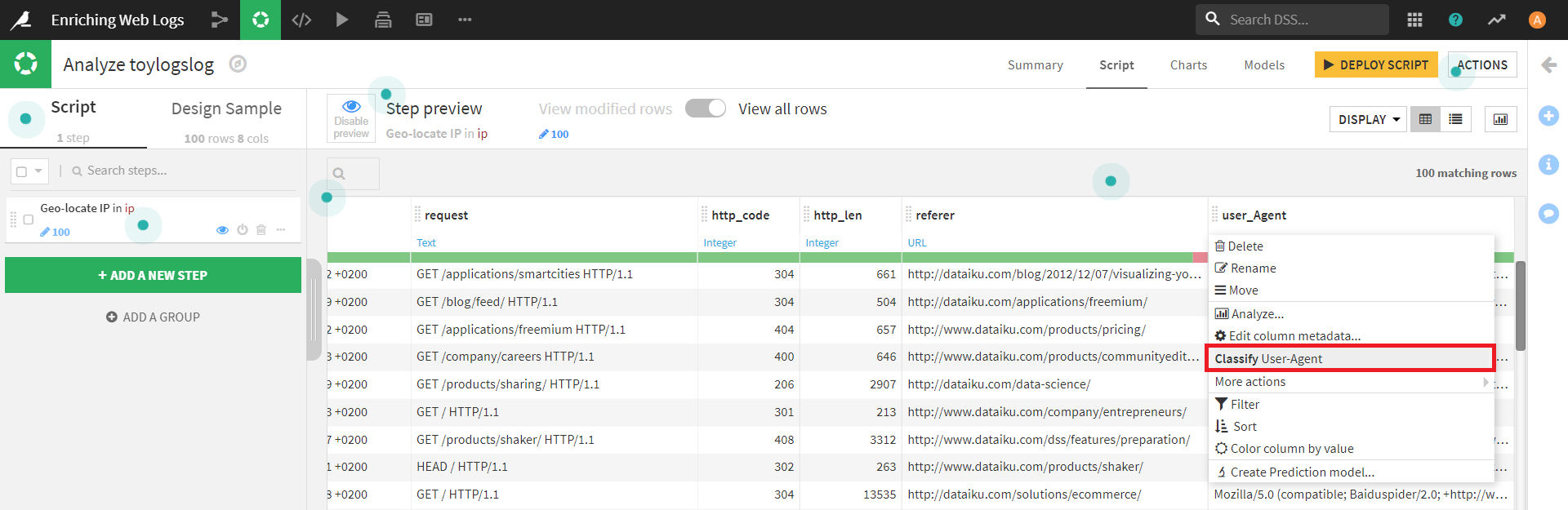
(どうやらDataikuは、このカラムをユーザーエージェントに関する情報であると推測しているため、このステップが出てくるようです。)
これを適用すると、新しいカラムが7つ生成されます。(図では一つ見切れてしまっていますが…)
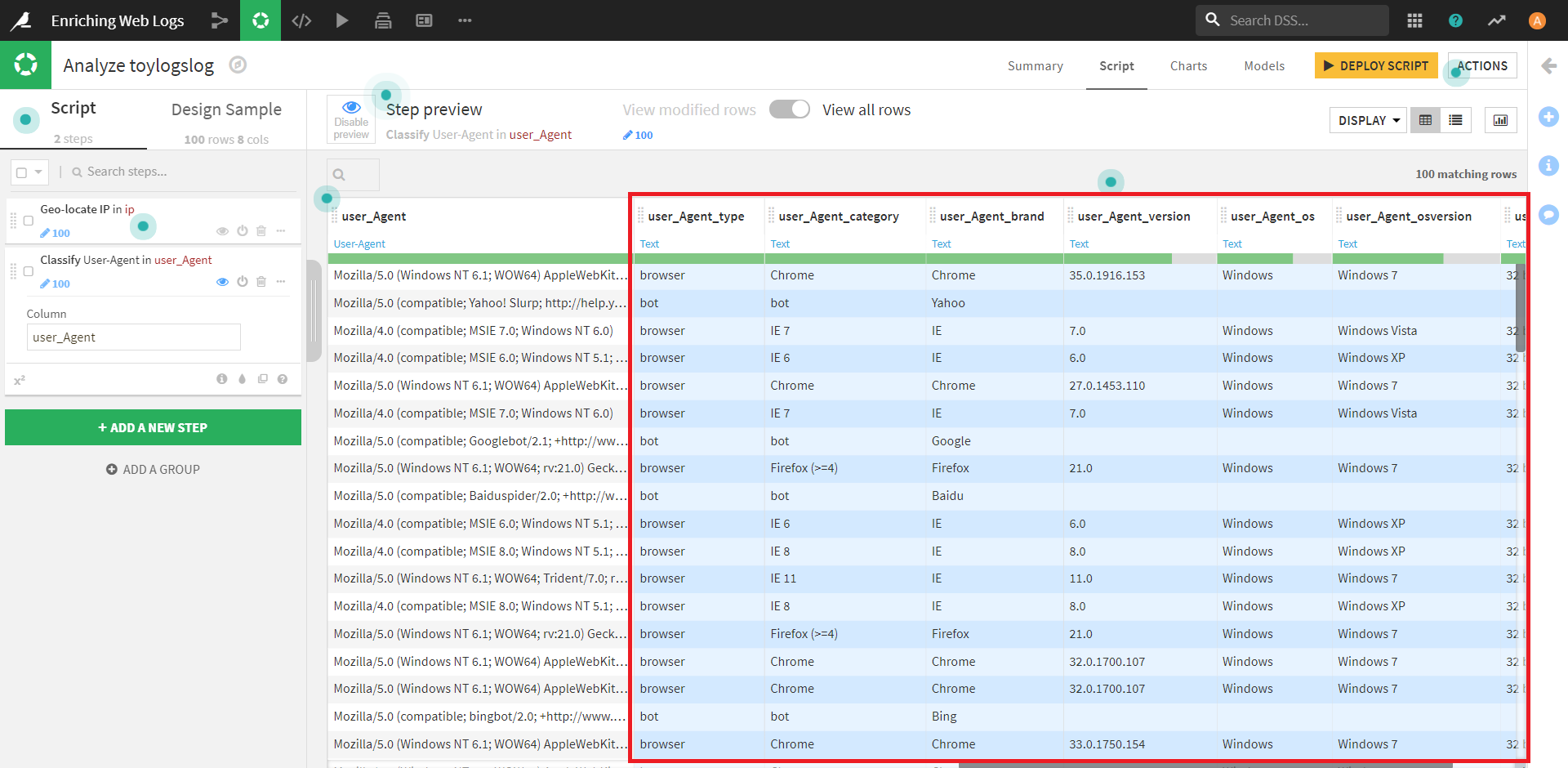
今回はこのうち「user_Agent_type」「user_Agent_brand」「user_Agent_os」のみを残し、他のカラムは削除します。
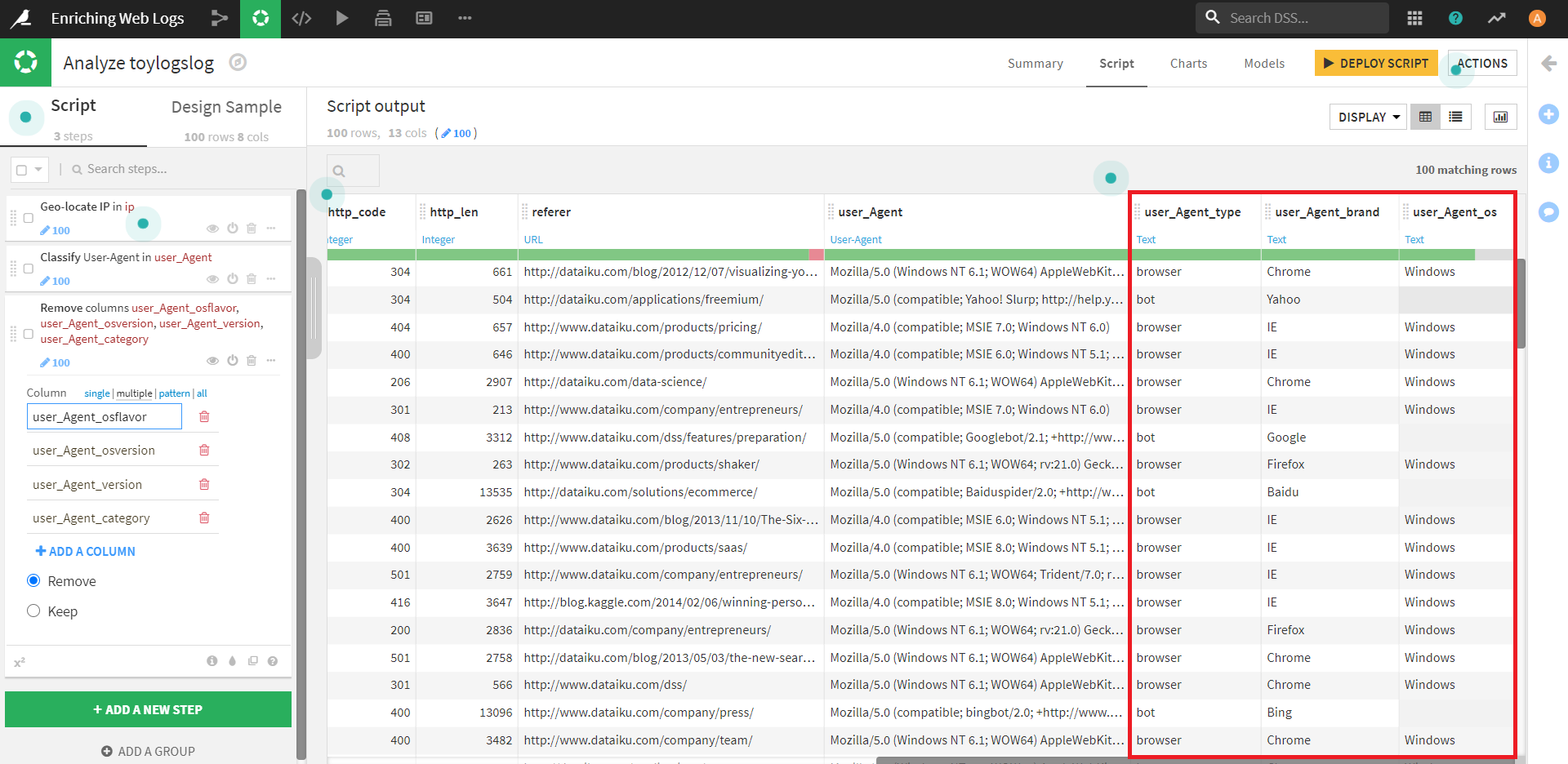
残ったカラムのうち、「user_Agent_type」カラムに注目してみます。
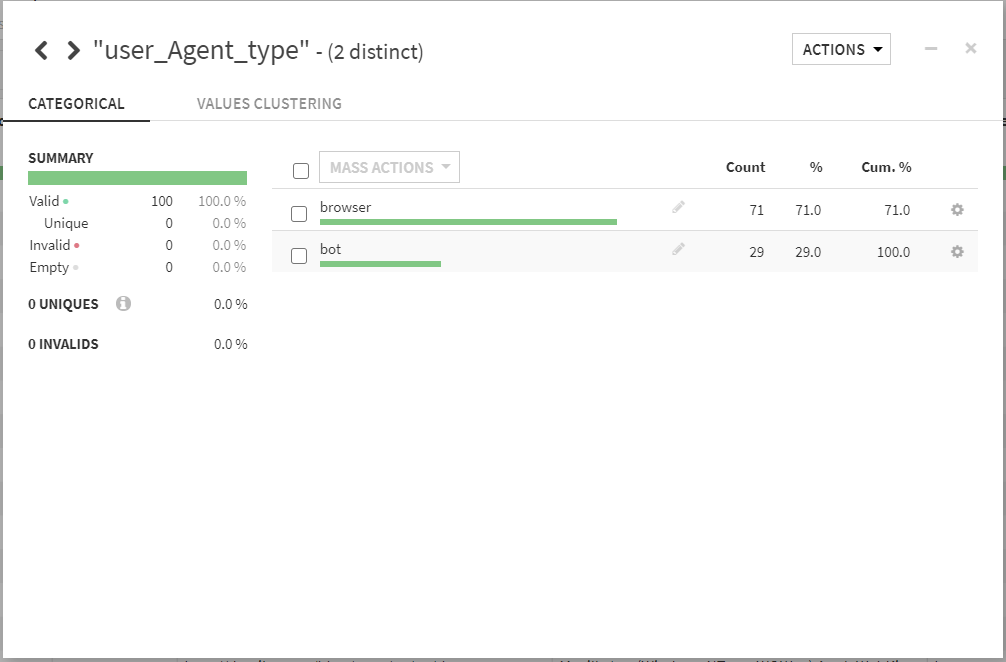
このカラムは、「bot」「browser」の二つの要素から構成されているようです。
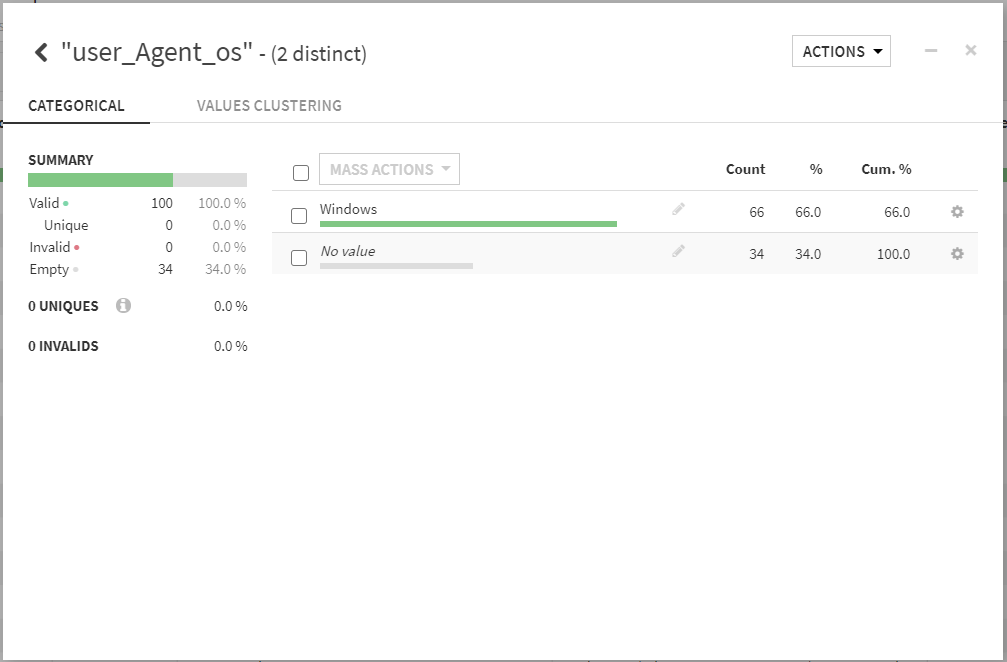
また、「user_Agent_os」カラムからは、その殆どがWindows経由であることが分かります。
Referer URL Parsing
次に、ユーザがどこから来ているのかを教えてくれるリファラに注目してみましょう。
「referer」カラムの構成を見てみると、1%だけ無効な値が含まれています。
このカラムの無効な値が何か調査するために、データセットをフィルタリングしてみましょう。
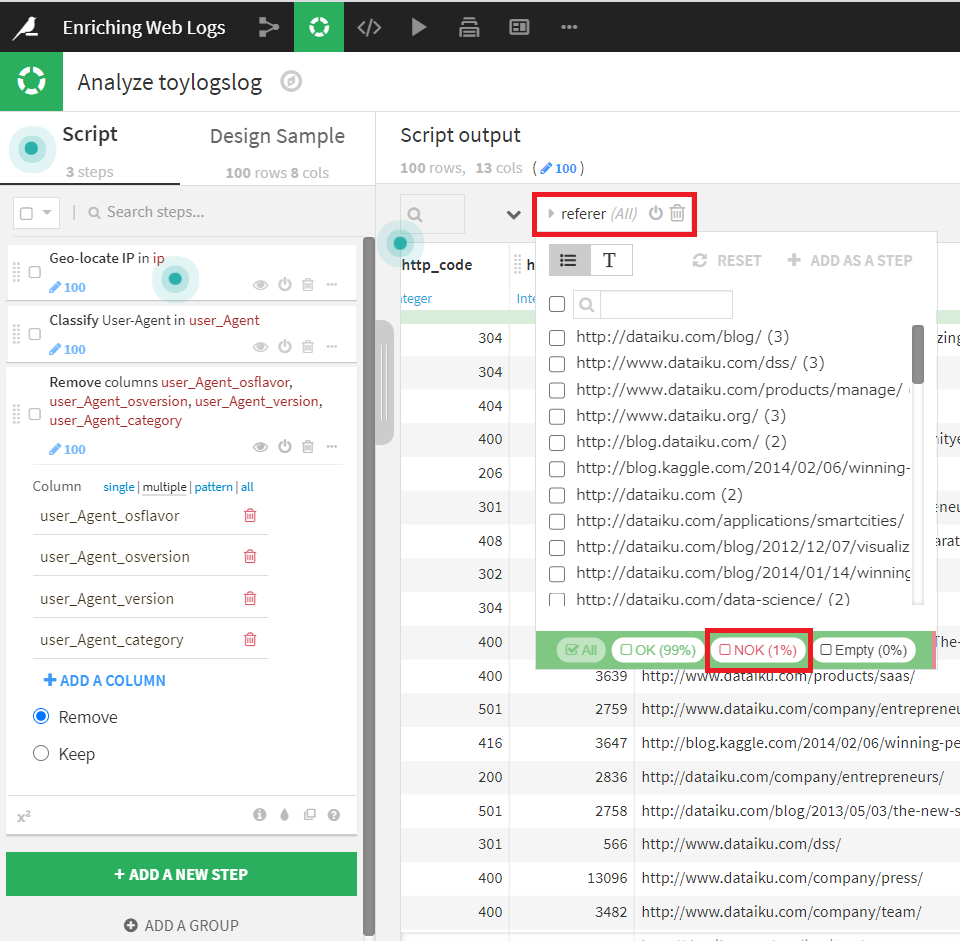
NOKの項目だけ見てみると、文字列値「-」が一つ含まれていることがわかります。
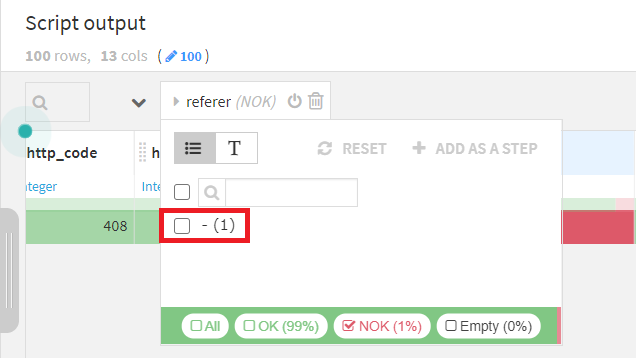
この値(カラム名ではなく値、背景色が赤になっているところ)をクリックすると、別のコンテキストメニューが表示され、 [Clear cells equal to -](「-」のセルをクリアする)という項目が表示されます。
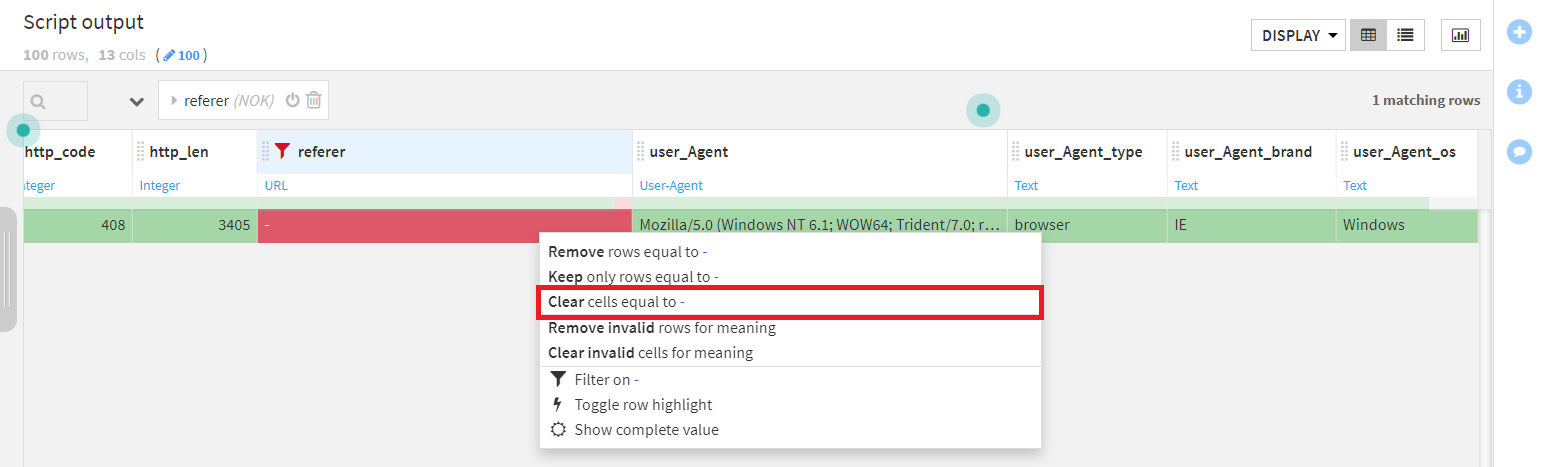
この操作を実行すると、ゲージの赤い部分が灰色になります。
今、ゲージが赤のカラムを参照していましたが、先ほどの操作でそれがなくなったことで、画面には何もない状態になりました。
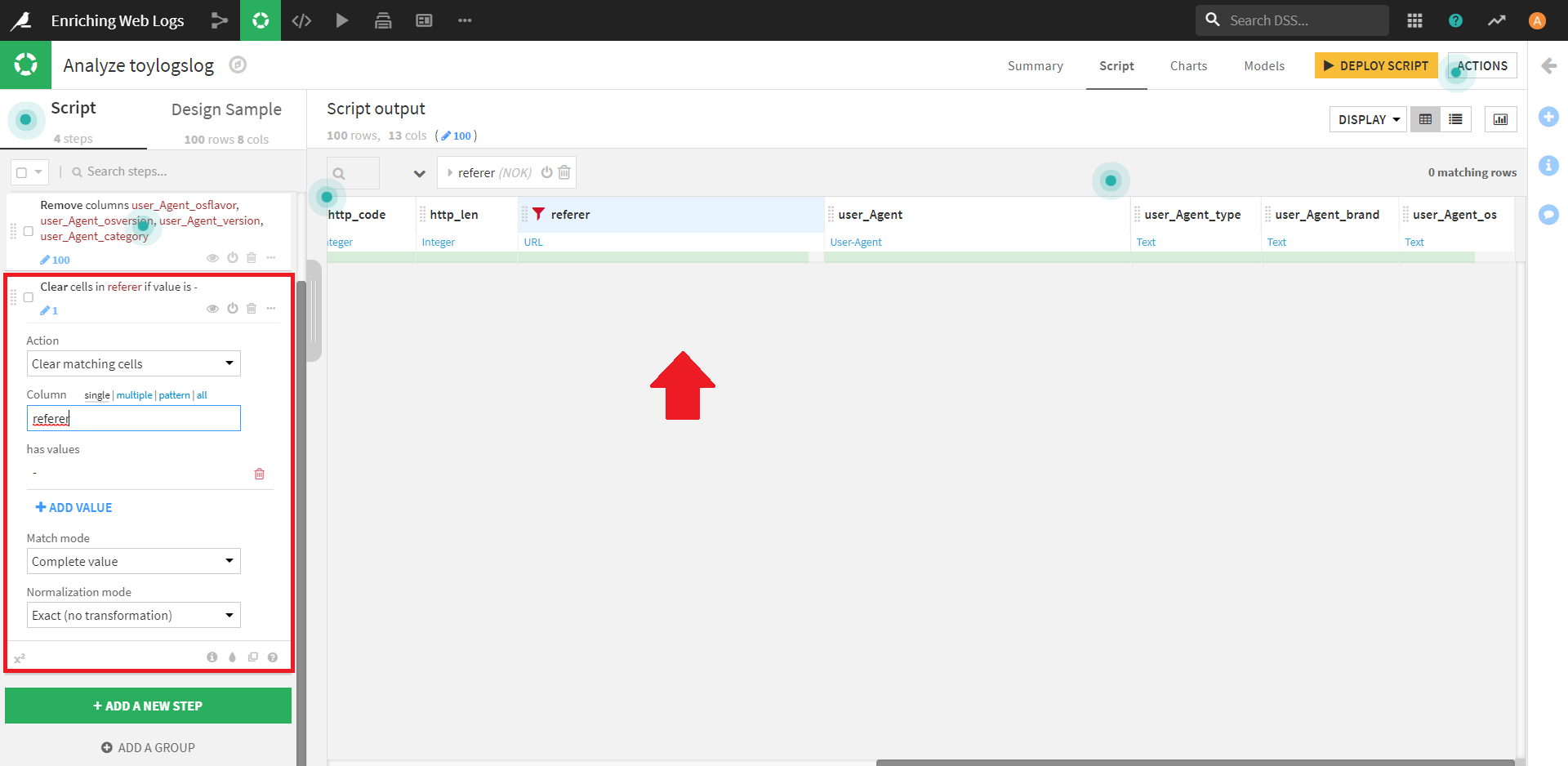
データを整えることができたので、参照元の「referer」カラムに戻り、タブを見ると [Split into host, port..](URLをホスト、ポートなどに分割する)があるので、これをクリックします。
(Dataikuはリファラ欄の意味をURLとして識別することができます。そのため、[Split URL into host, port..] が表示されています。)
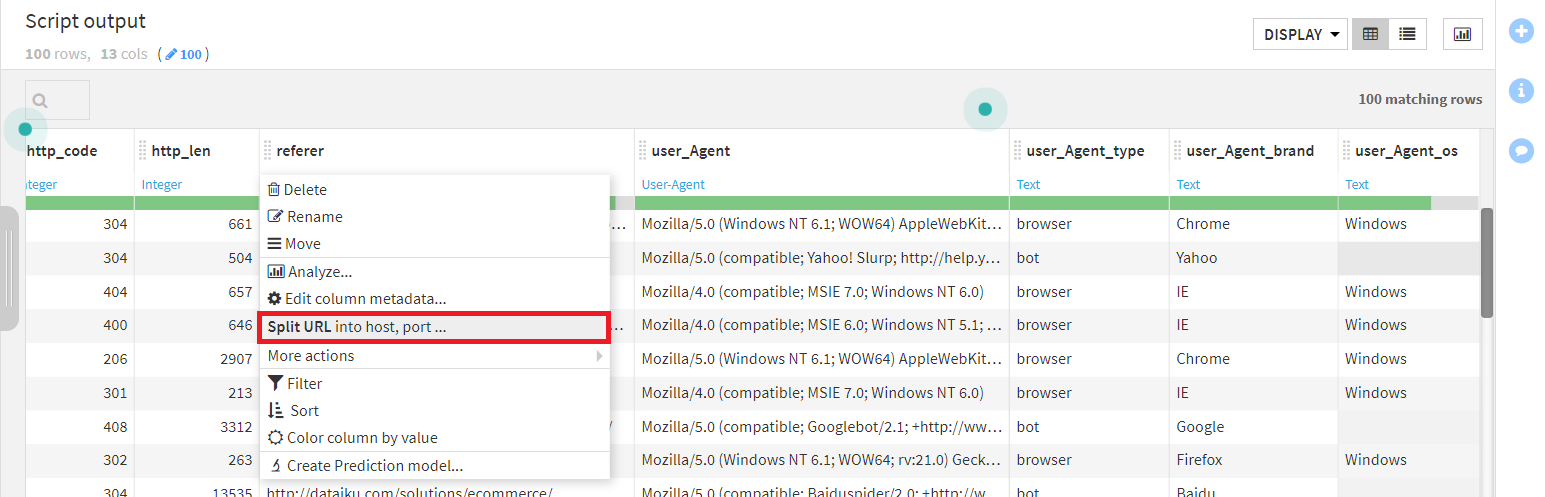
この操作により、新しいカラムが4つ生成されます。
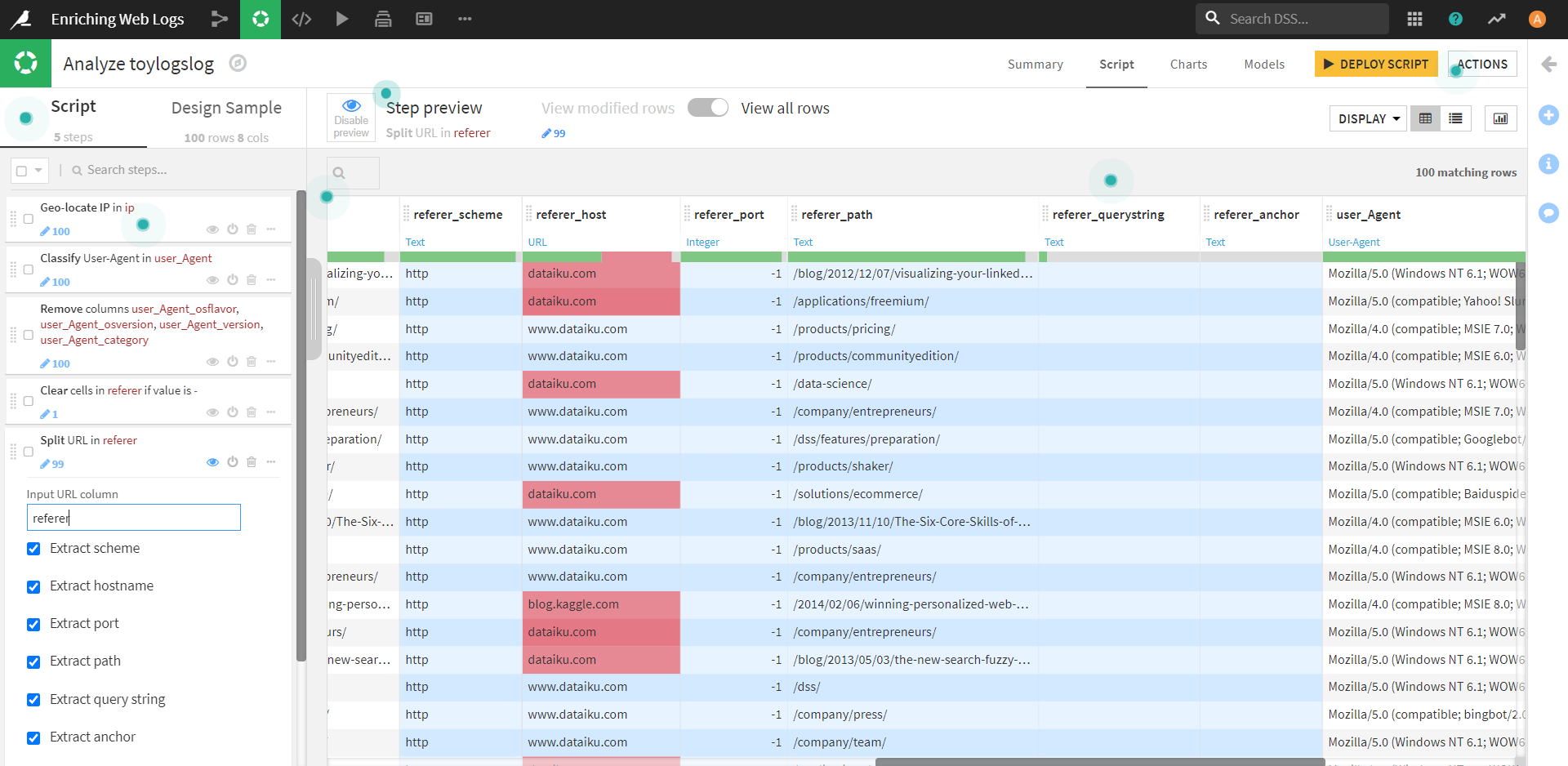
新しいカラムのうち、referer_path に着目し、ここをもう少し掘り下げていきましょう。
そのために、カラムを分割するステップを追加します。
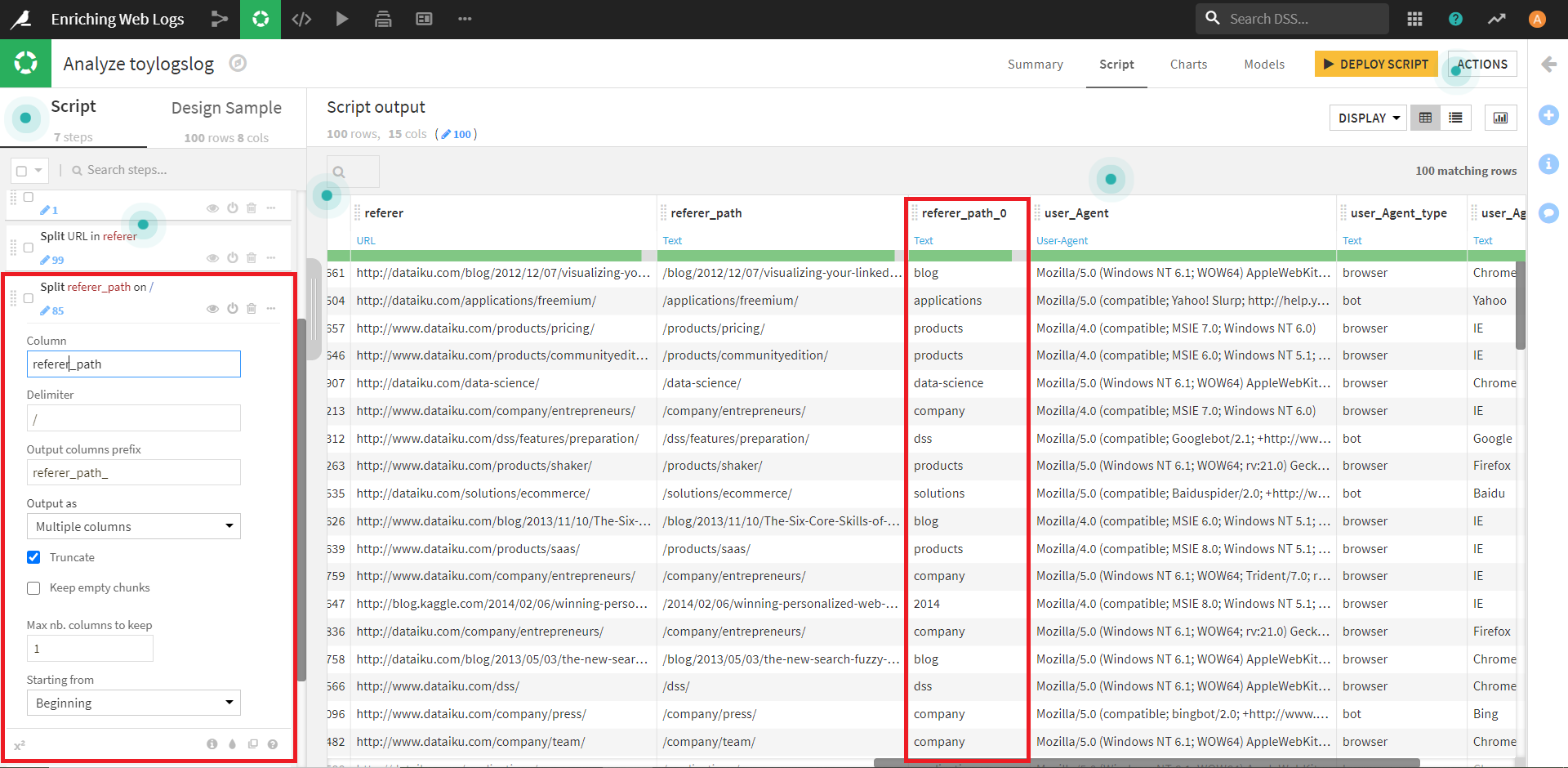
これで新たに分割されたカラム「referer_path_0」が作成されました。
ここには、アクセス情報のうち、何を経由しているかという内容が記載されているようです。
見てみると、そのほとんどのがウェブサイトの製品、ブログ、アプリケーションの部分から来ていることがわかります。
以上のようにして、Dataikuで手軽にアクセスログの分析を行えるようです。
Other Transformations
チュートリアルでは、ウェブログデータの内容が紹介されていましたが、他にも以下のようなユースケースでも使ってみてね!と紹介されています。
・ログの日付を解析して、コンポーネントを抽出する場面。
・HTTPクエリ文字列を利用した、ユーザーの動的データの調査。
このような場面でも、いつか試してみたいですね。![]()
Applying Prepare Steps to Multiple Columns
データを準備しているとき、複数の列に同じ操作を適用したい場合があると思います。
勿論、Dataikuでは、この操作が可能です。
しかも、ただ可能なだけではなく、操作の種類や手元のデータの種類に合わせた方法で、それを実現できます。
実際にそれらを確認してみましょう。
From the Columns view
まずはカラムビューを使用した方法です。
カラム ビューでは、複数のカラムを選択し、アクションメニューから操作を選択して、任意のカラムに操作を適用することができます。
たとえば、複数のカラムの名前を一度に変更するにはこの方法を適用します。
以下の例を見てみましょう。
顧客の自宅連絡先情報に関連する複数の列があるとします。
(これはサンプルプロジェクト「Cleaning Contacts」のデータです。)
このデータを仕事の連絡先情報と区別するために、カラムビューから必要なカラムを選択し、名前を変更して、選択したすべてのカラムの先頭に「home_」を追加したい、そんな場面を考えます。
一つ一つ変えていくのは手間なので、ここは賢いDataikuに頼って、一気にやってもらいましょう!
まずは、画面右上の [Column View] をクリックし、データセットの表示形式を変更します。
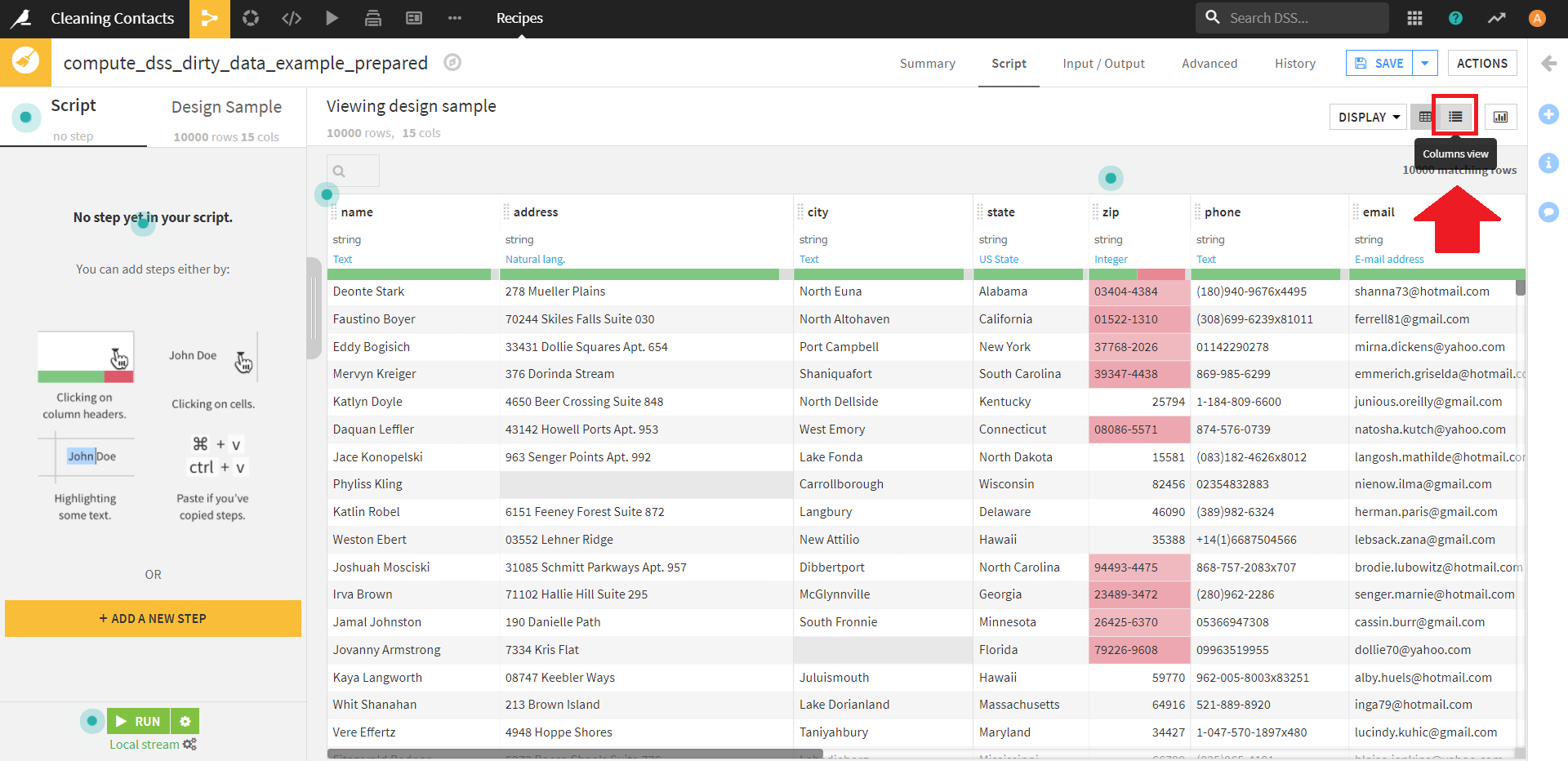
すると、このような画面になります。
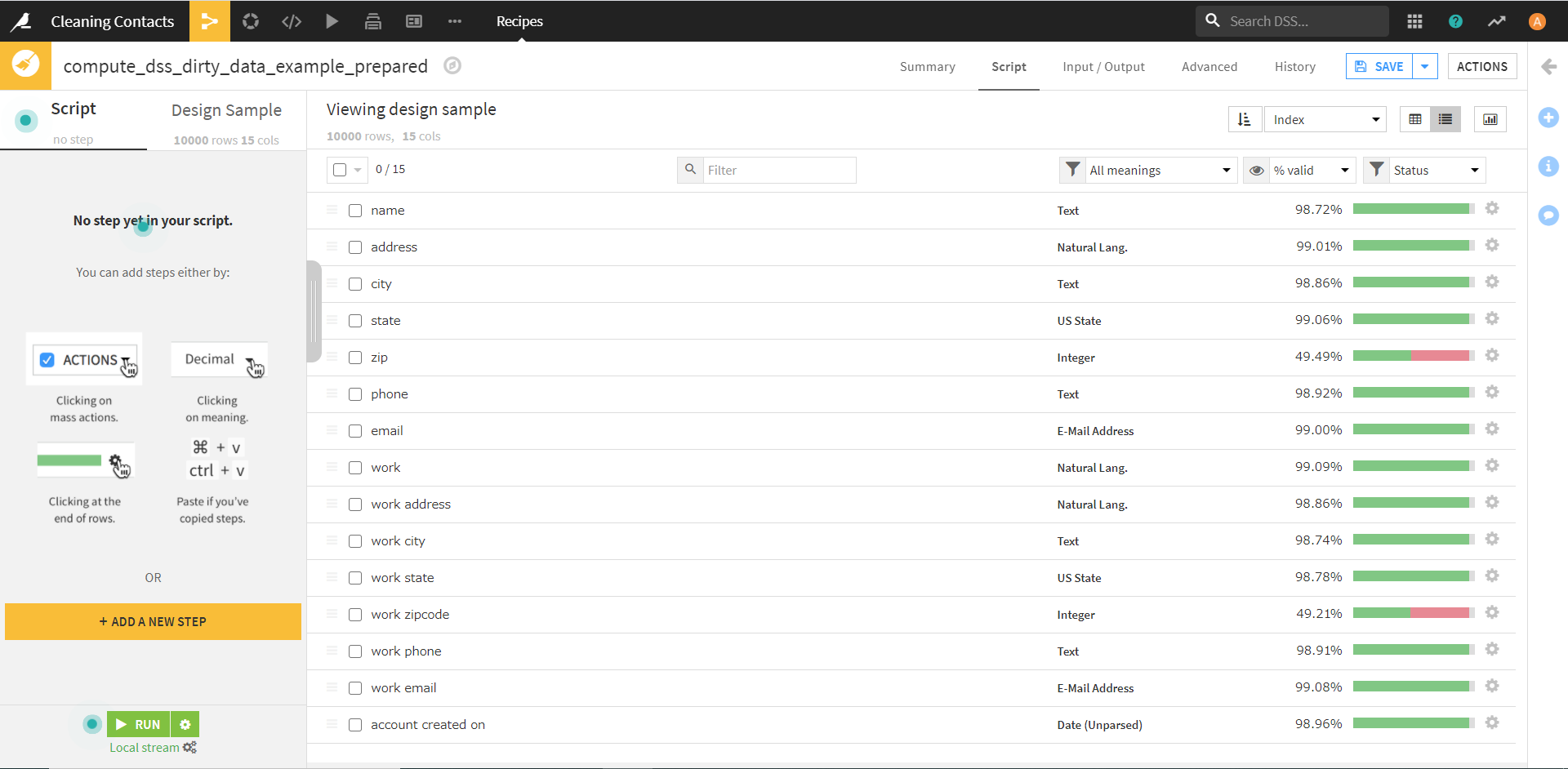
この画面で、「address」~「email」までのカラム名の左側にあるチェックをオンにします。
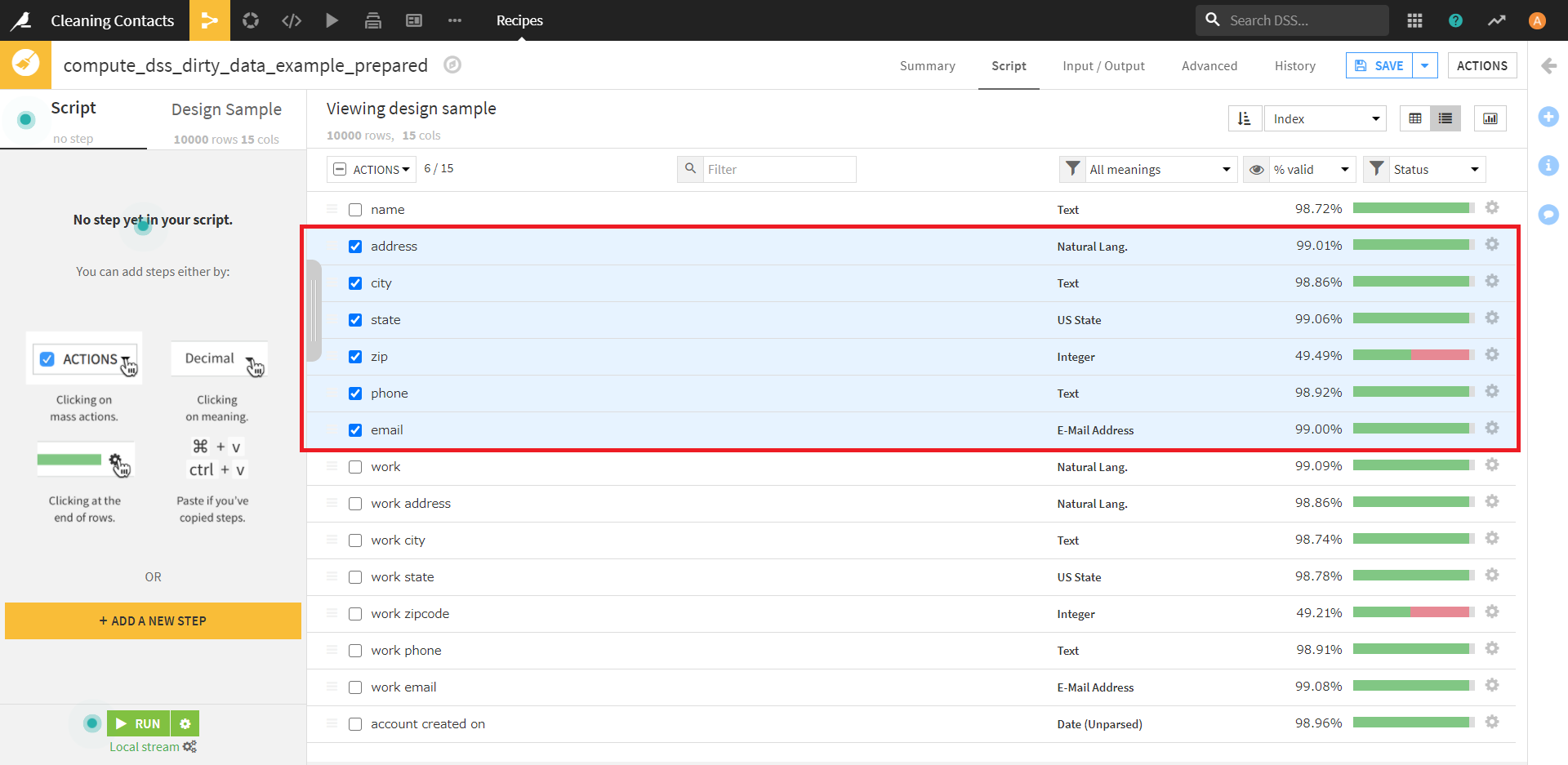
チェックをオンにした後、今度は画面左上の「Actions」の「Rename」を選択します。
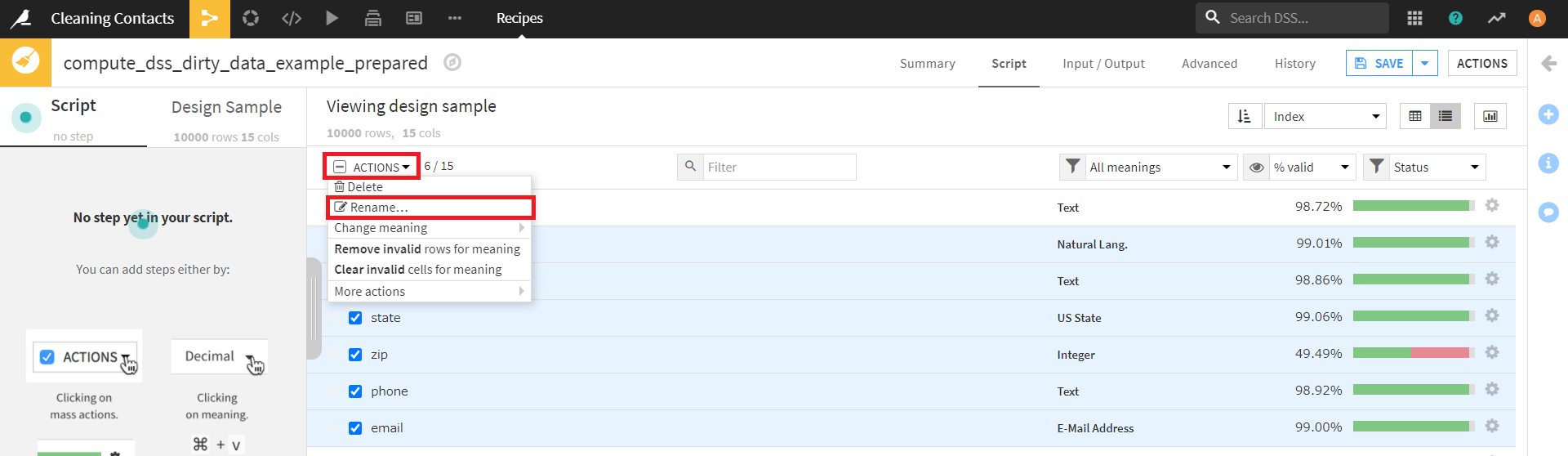
すると、下図のようなダイアログが現れます。
左側の選択項目はデフォルトの「Add a prefix」のまま、入力欄に「home_」を入力します。
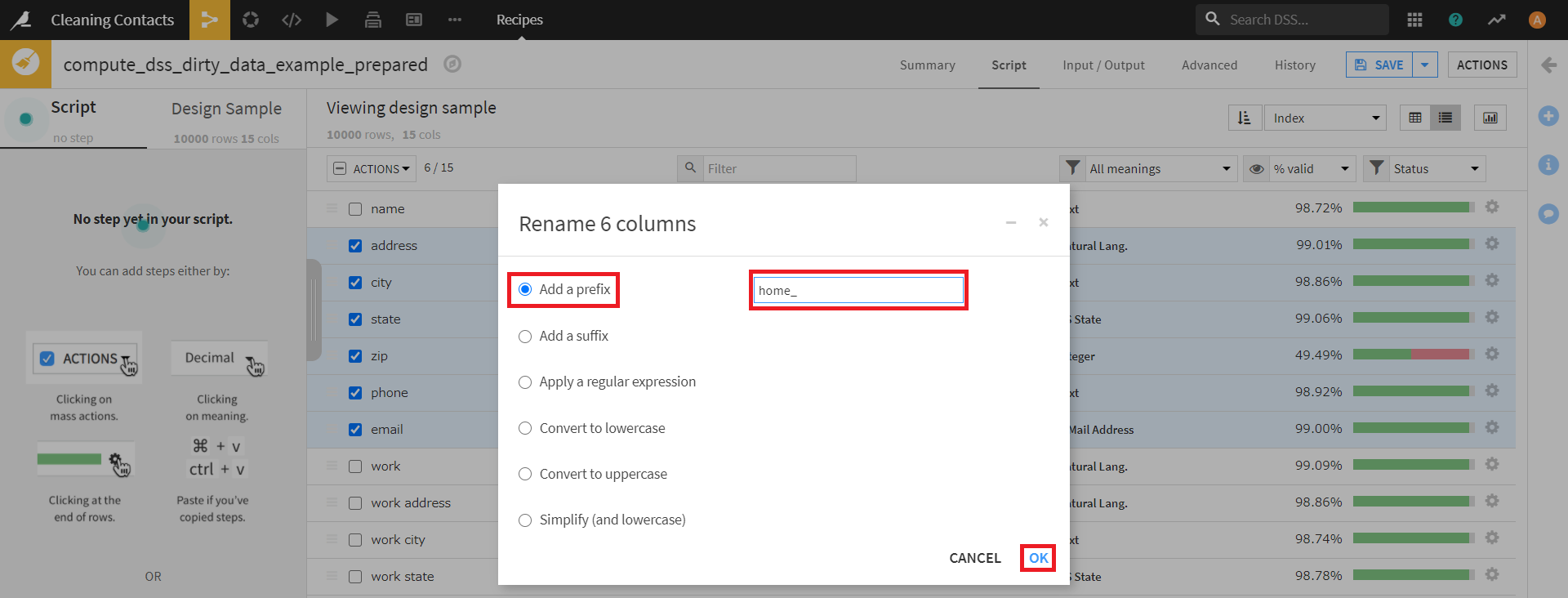
この操作を完了すると、このように選択したカラムの名前すべての先頭に「home_」が付けられました。
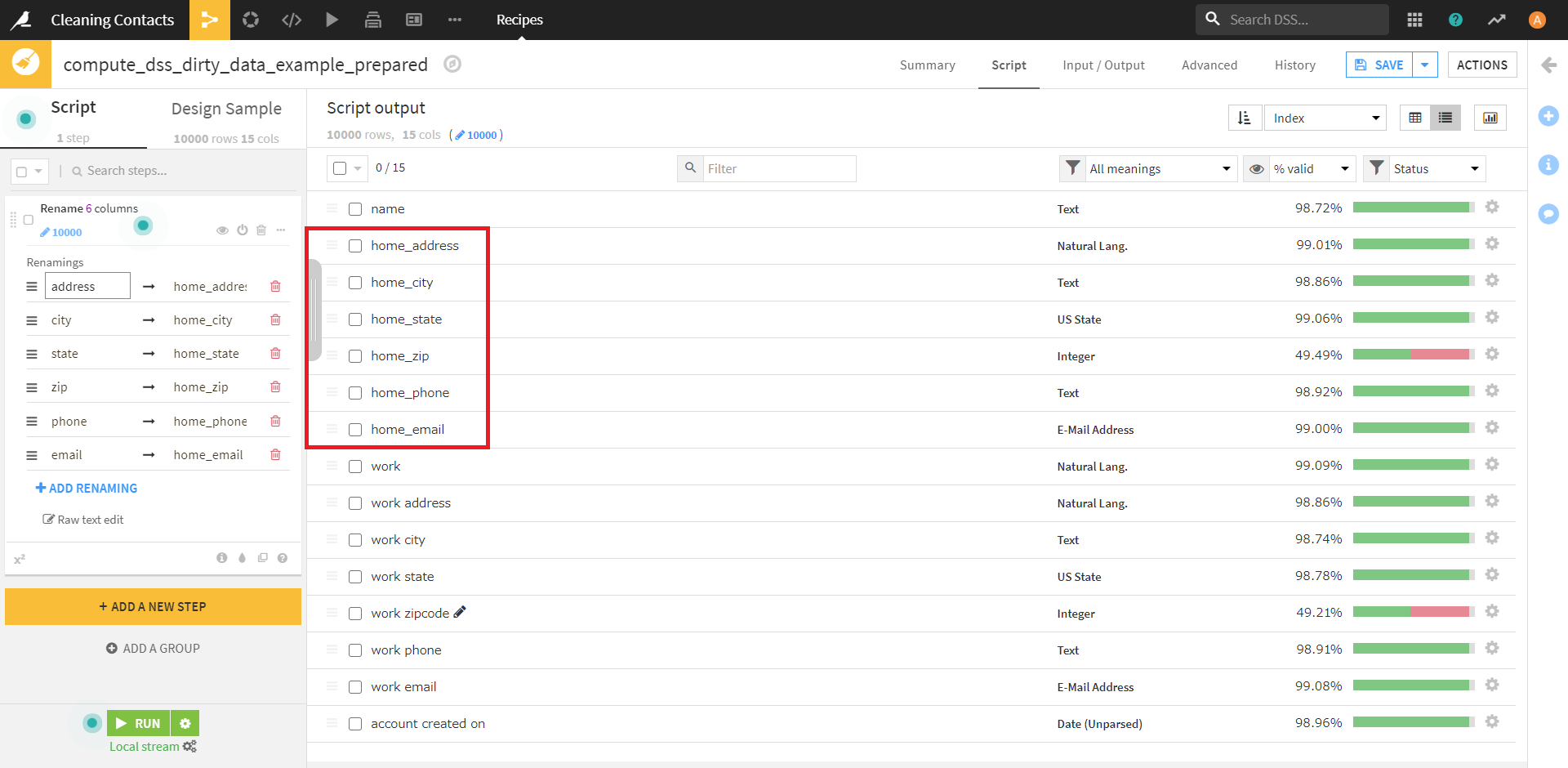
Table Viewに戻って確認してみても、しっかり操作が反映できています。
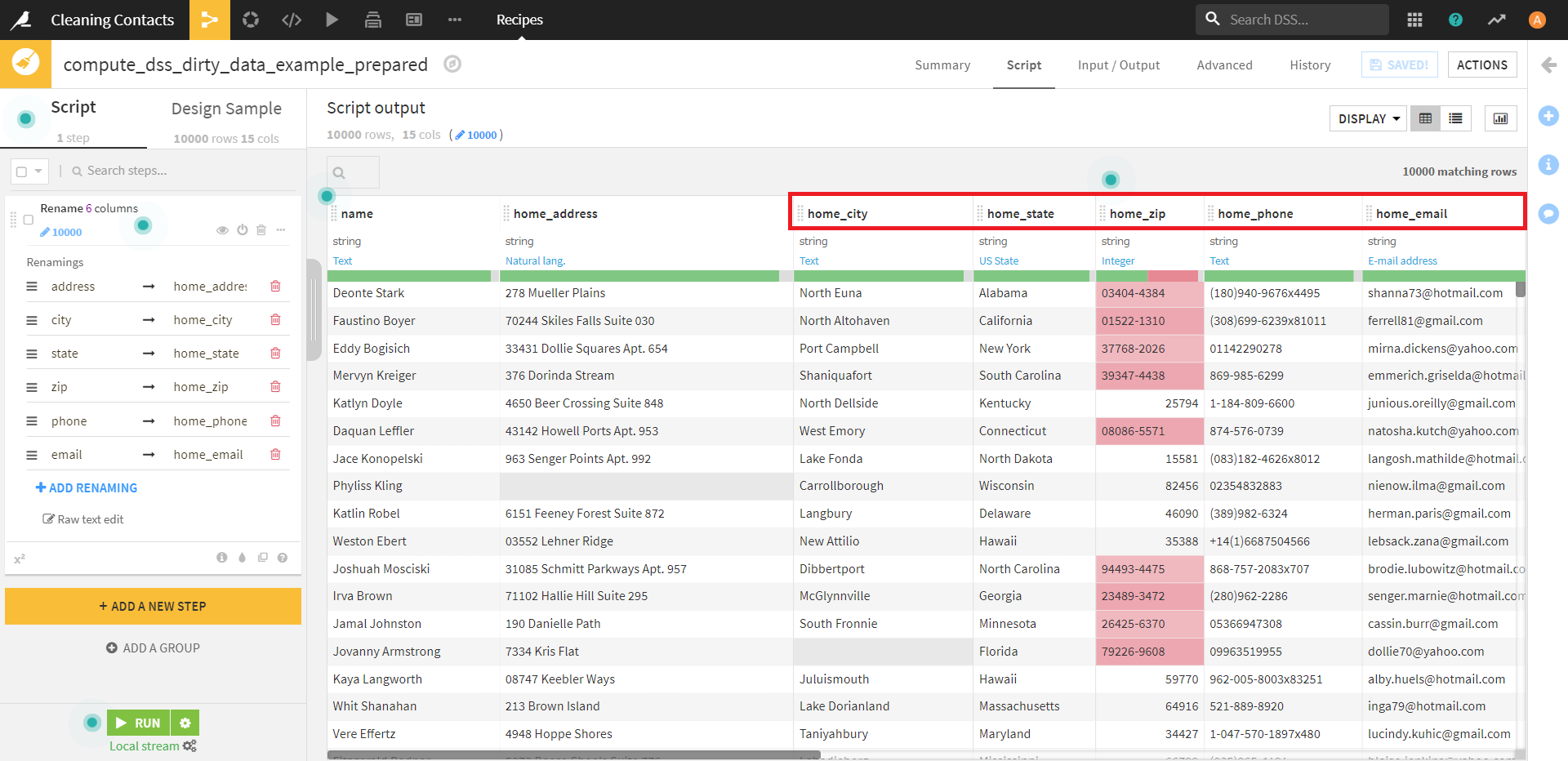
このような複数の列に適用できる処理は、選択した列のデータ型によって異なるようです。
(すべてテキスト列で選択すると、Dataikuは文字列変換の適用を提案しますが、すべて数値列で選択すると、数値範囲でのフィルタリングを提案することがあるようです。)
また、さまざまなデータ型を混在させて選択すると、無効な行を削除したり、意味に基づいて無効なセルをクリアしたりすることがあるようですので、ここは少し注意が必要ですね。
From the step editor
ステップを複数の列に適用する別の方法として、ステップエディタを使用する方法があります。
例えば、列の空のセルをUnknownのような固定値で埋めたい場合があるとします。
これについて、先ほどと同じデータで見ていきましょう。
「home_zip」カラムをクリックすると、タブに [Clear invalid cells for integer](int型でないセルをクリア)という項目がありますので、それを適用します。
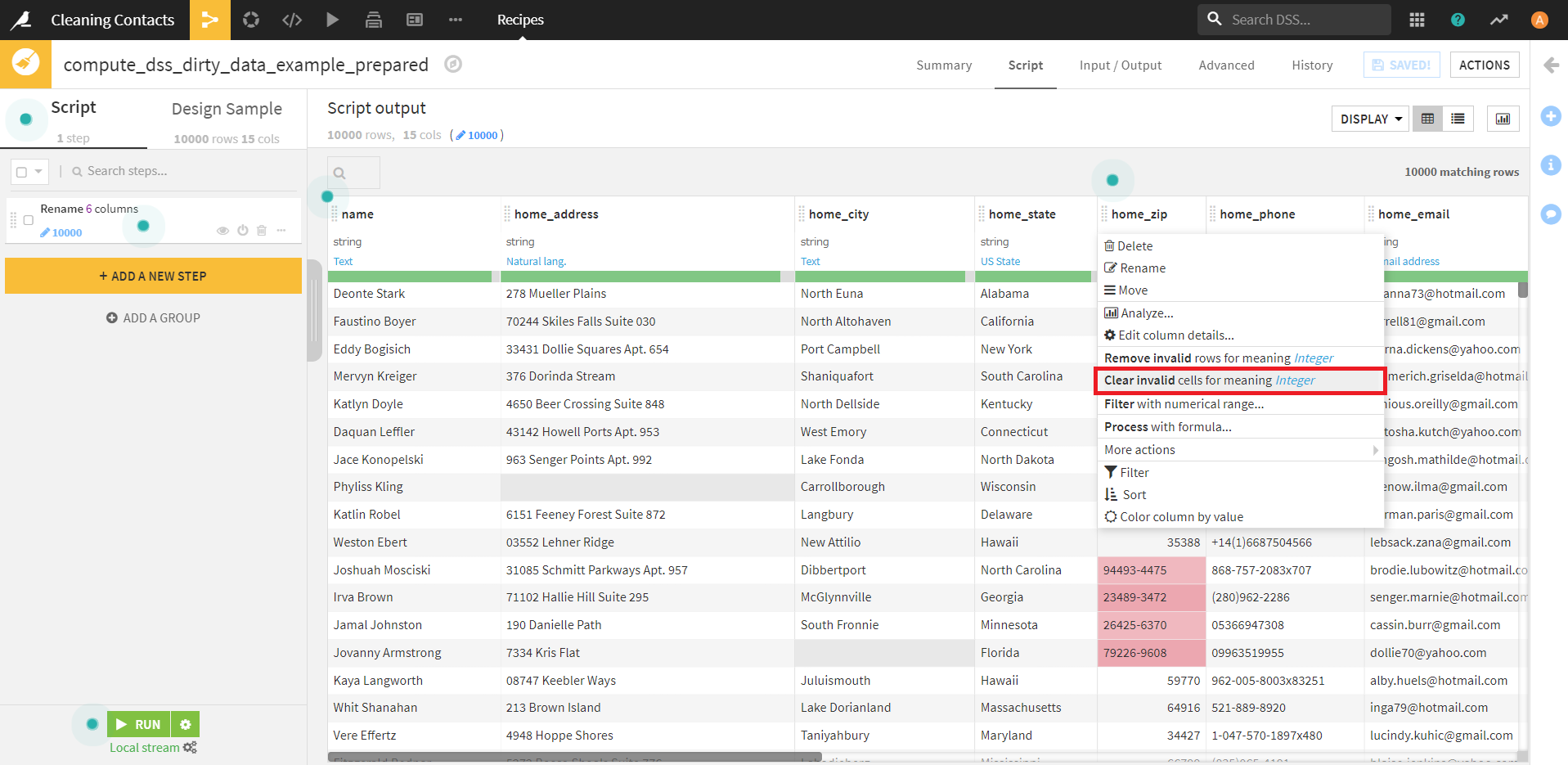
すると、背景色が赤のエラー項目がすべて空になりました。
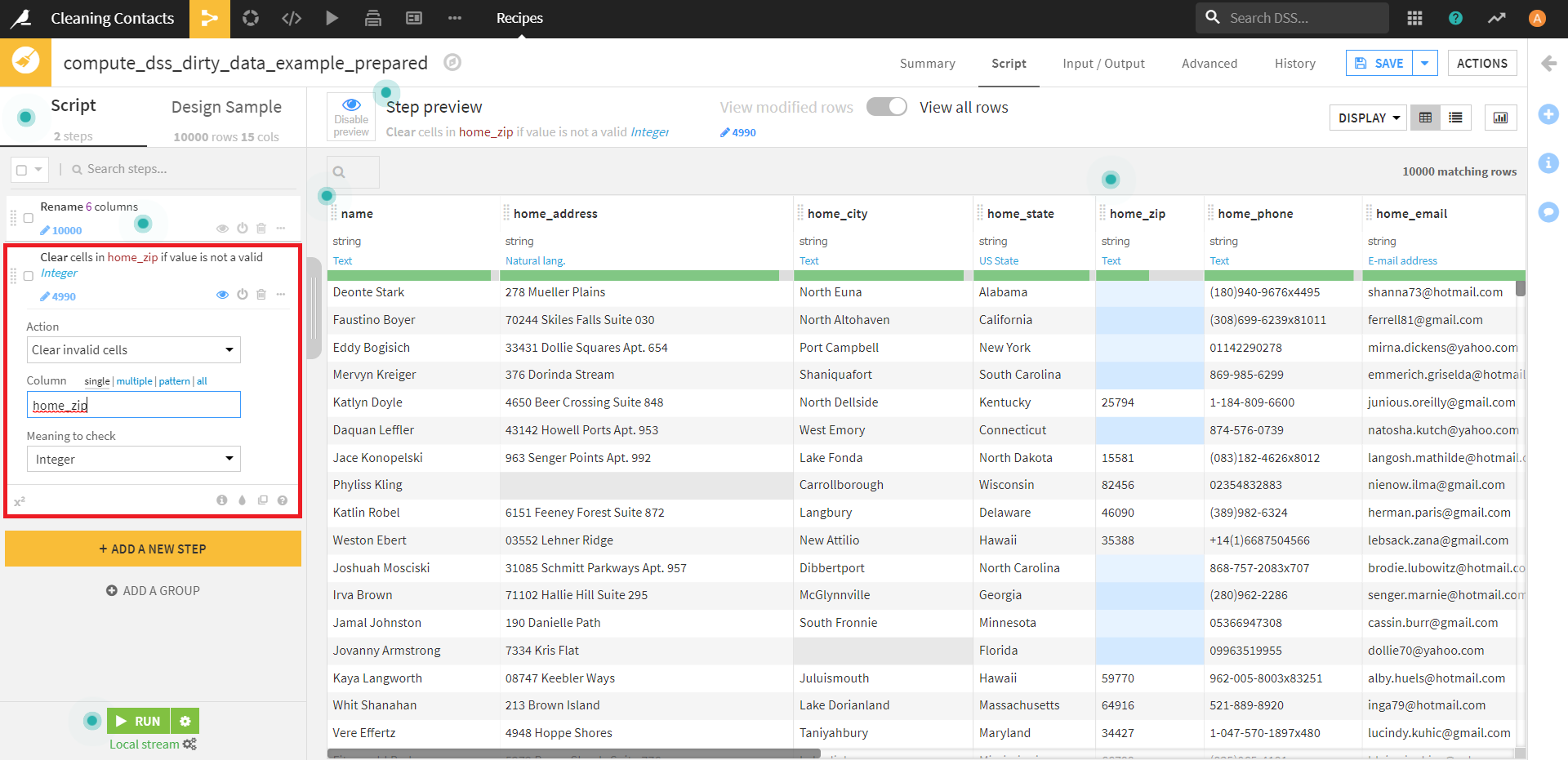
この状態になったところで、後ほどの操作のために、「home_zip」カラムのデータの意味をIntegerからTextに変更しておきます。
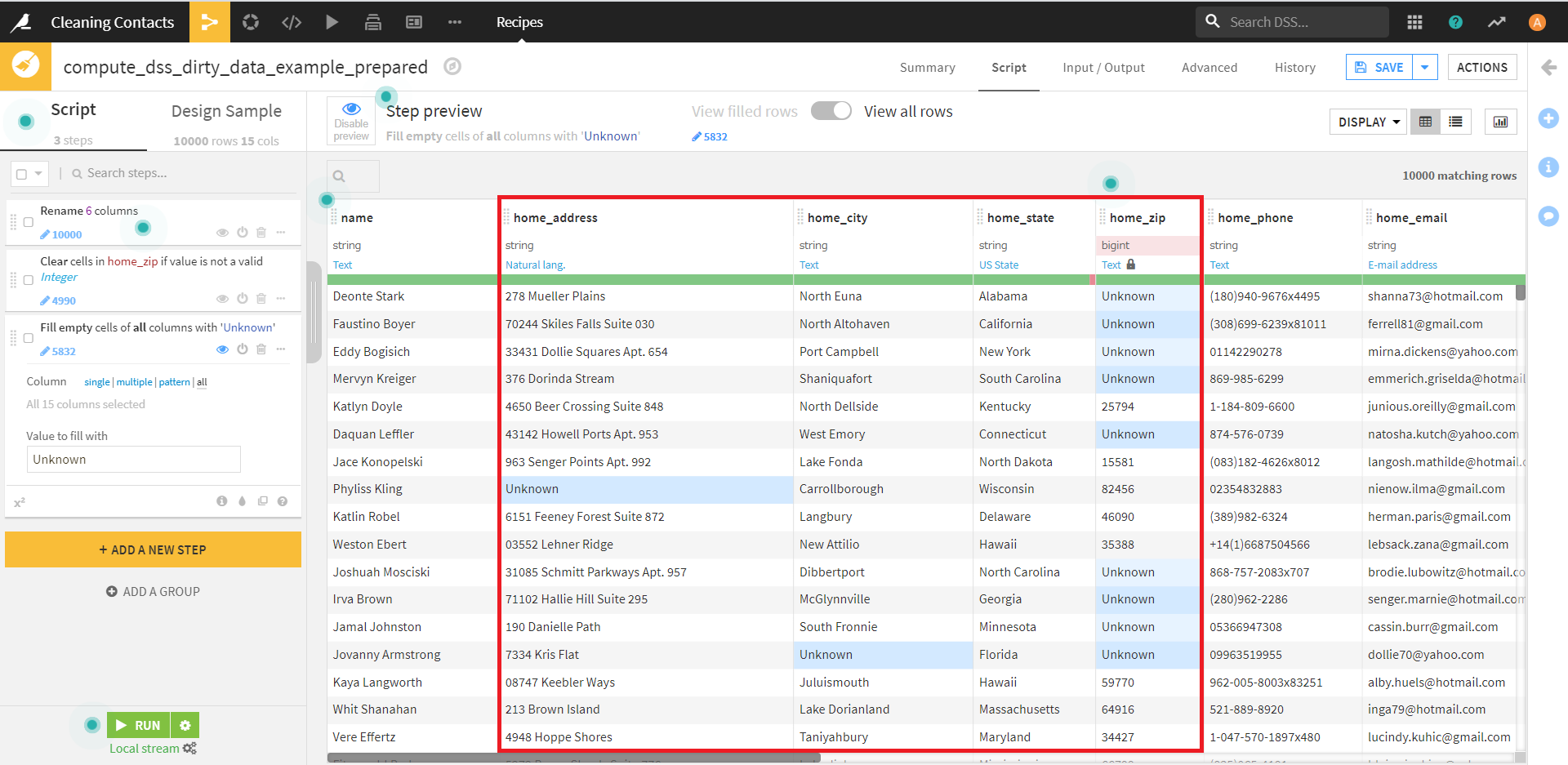
画面左下の [+ ADD A NEW STEP]より、 [Fill empty cells with fixed value] を選択し、実行します。
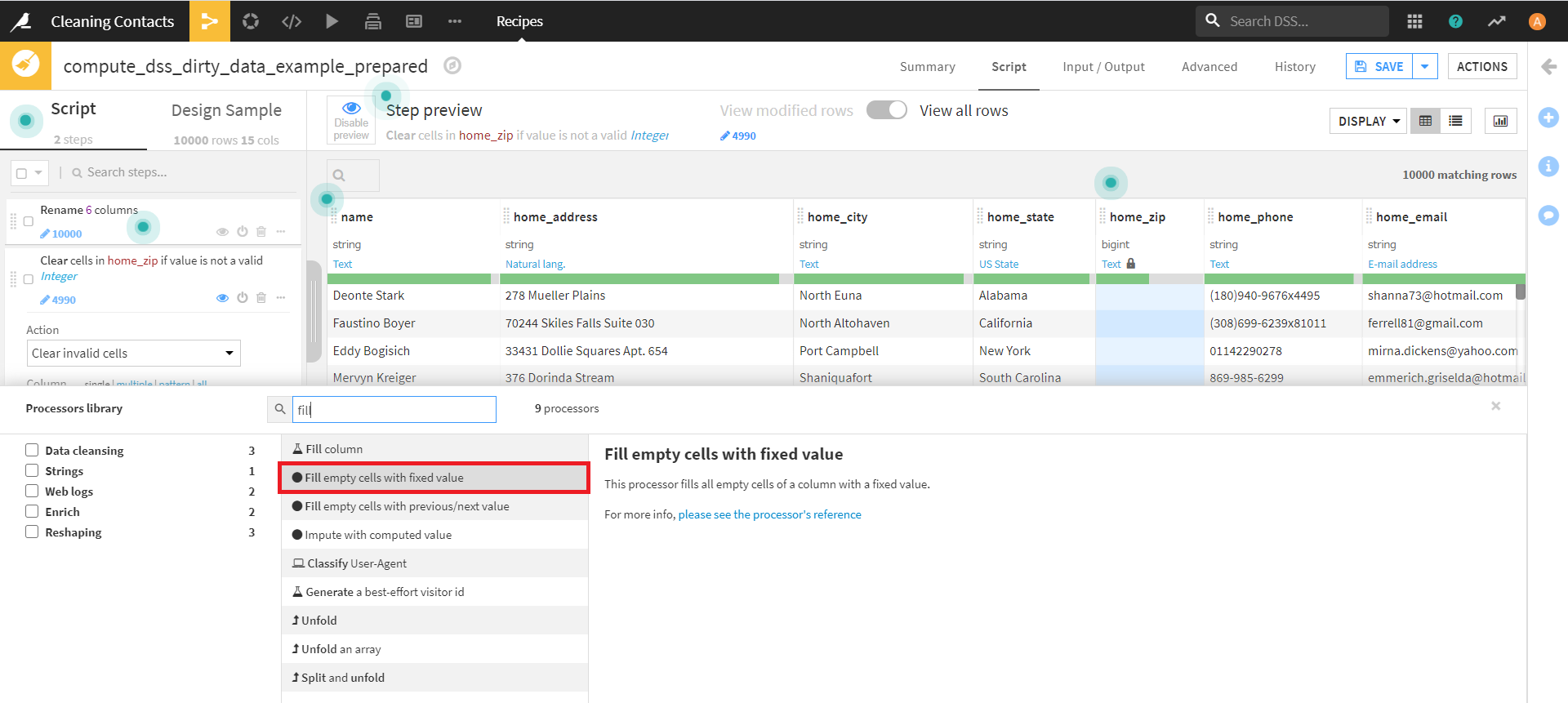
それぞれ、下記のように設定します。
・Column:home_zip
・Value to fill with:Unknown
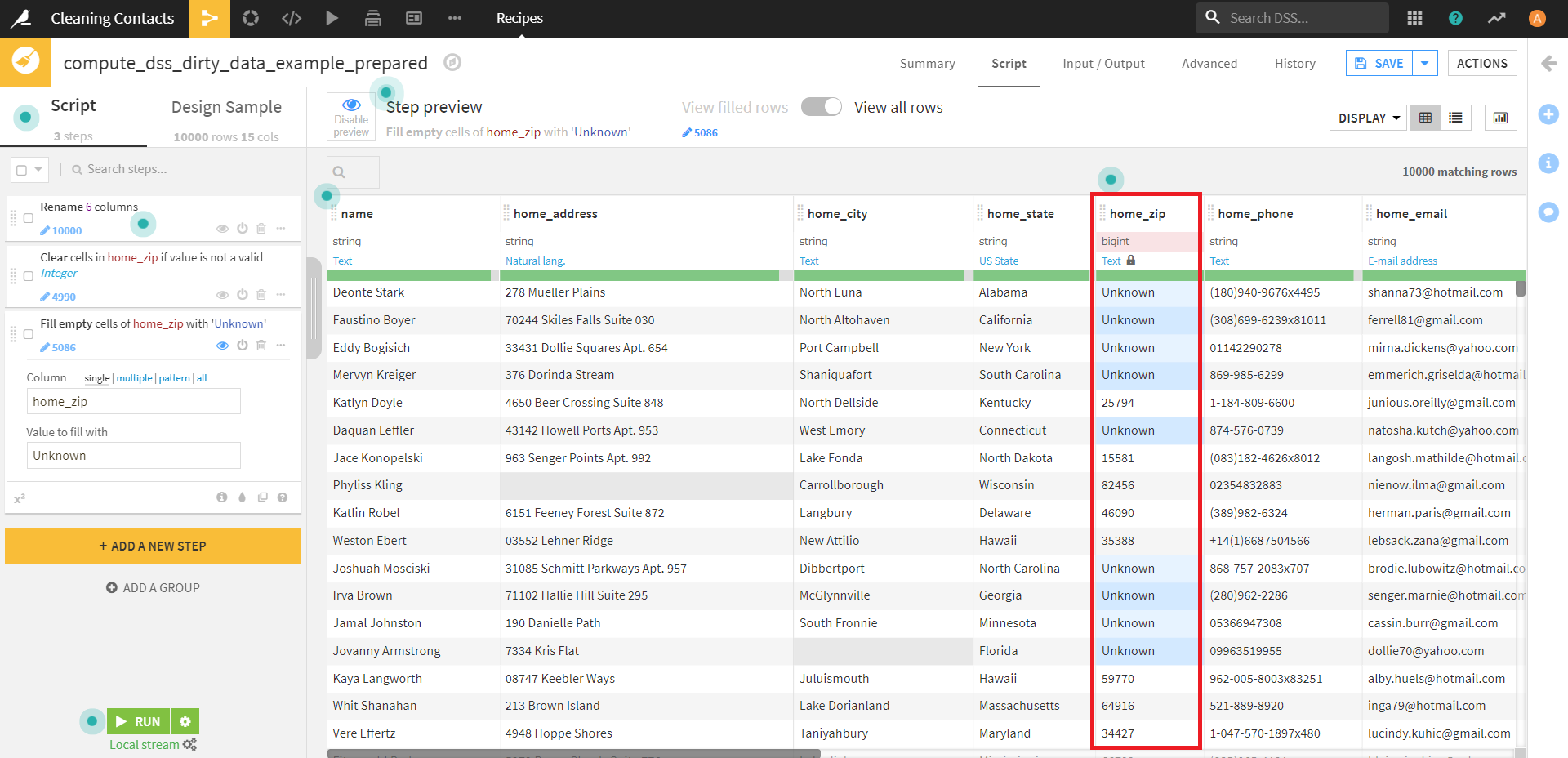
実行すると、空のセルがUnknownで埋められました。
(ここでUnknownでセルを埋めるために、先ほどデータの意味を変更しました。)
今は適用範囲がsingleになっていますが、multipleにすると、
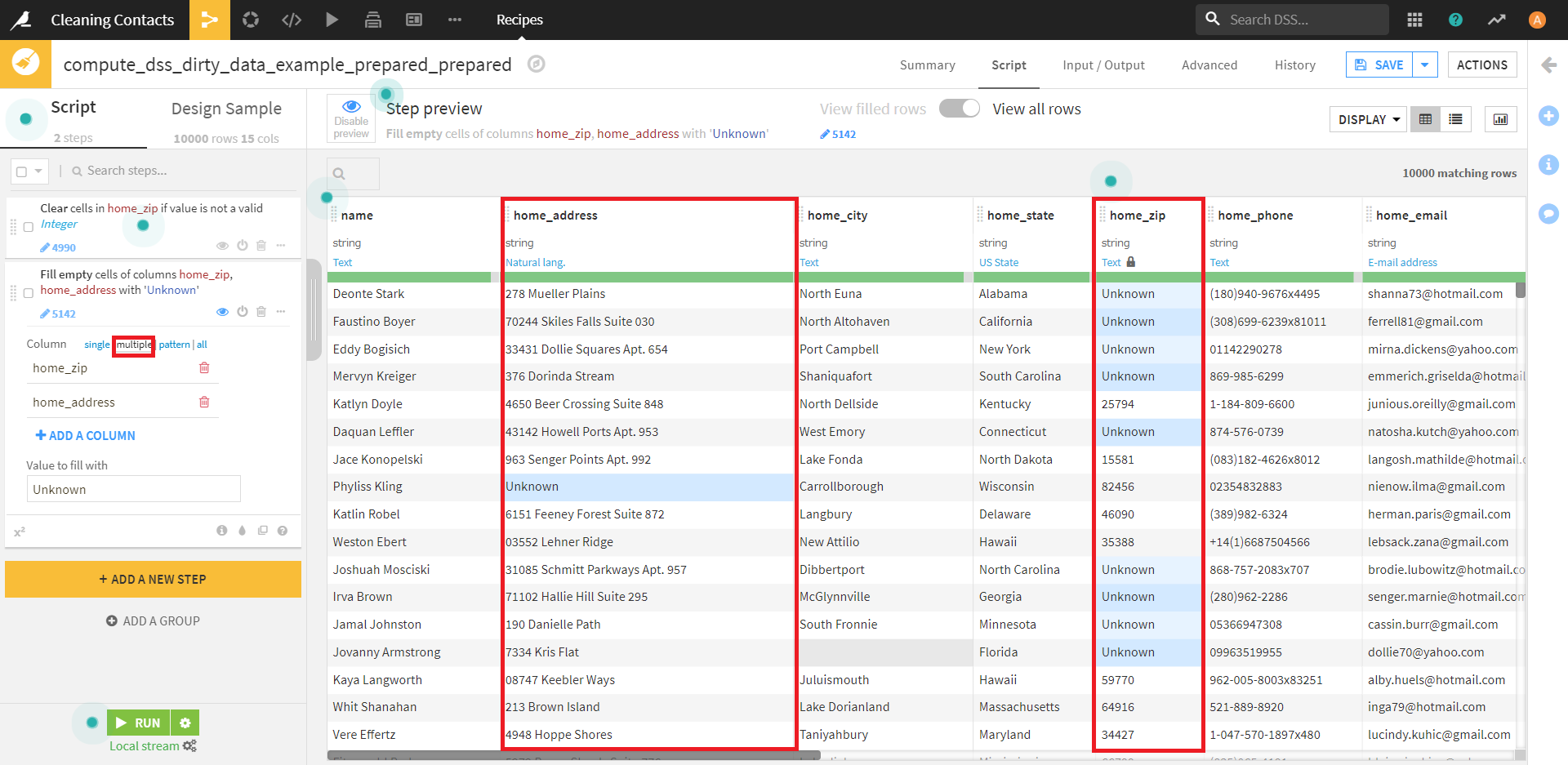
このように、複数のカラムに適用でき、allにすると、すべてのカラムに適用できます。
Within a Python function
Pythonの関数を使って複数のカラムを処理することも可能です。
実際に確認してみましょう。
今回は、サンプルプロジェクト「Customer Lifetime Value」のデータを使用します。
(チュートリアルで上記を使用していただけですので、データは何でも結構です。)
画面左側の [+ ADD A NEW STEP] より、 [Python function] を選択します。
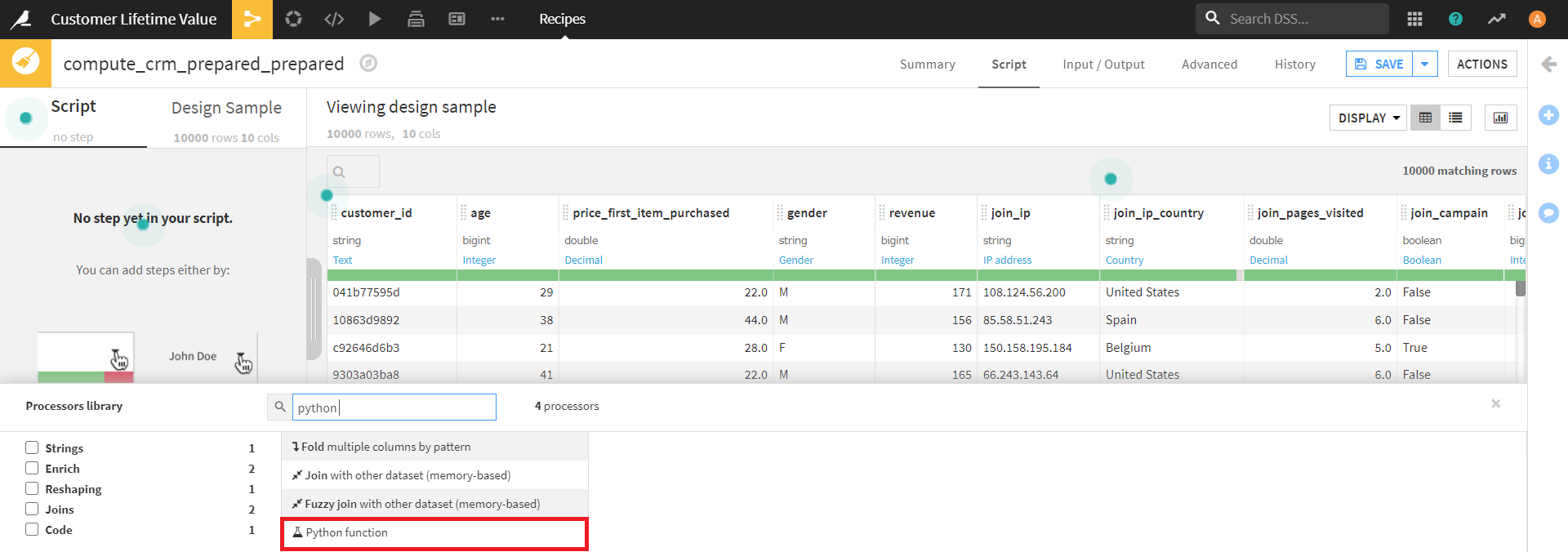
Python functionの操作では、Modeを [row:return a row for each row] とし、 [EDIT PYTHON SOURCE CODE] をクリックします。
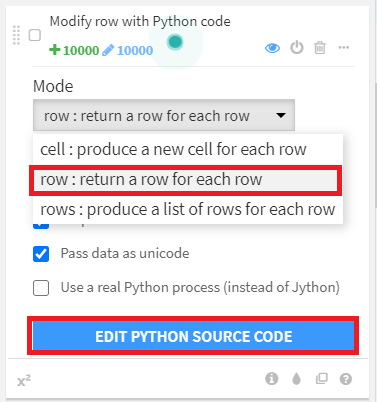
すると、下図のように、画面上段に「Step」が作成されます。
ここでスクリプトを入力して、カラムに対への操作を加えることができます。
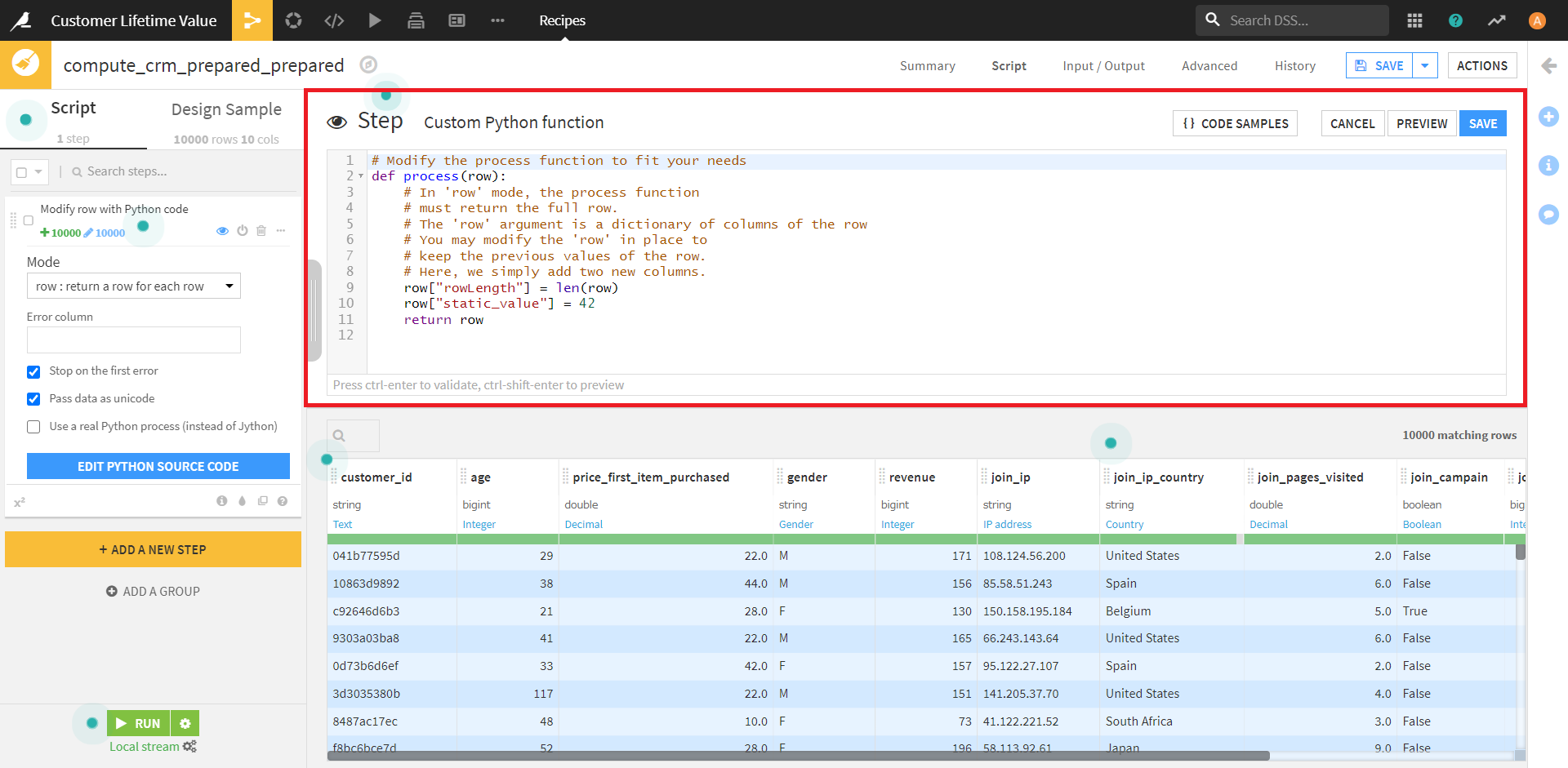
今回は、下記のスクリプトで、「age」カラムすべてに+5してみたいと思います。
import ast
def process(row):
for i in row.keys():
try:
isint = type(ast.literal_eval(row[i])) is int
except:
isint = False
if isint:
row[i] = int(row[i]) + 5
return row
スクリプトを書き終えたら、画面右上の「SAVE」(STEP欄にある、背景色が青のところ)をクリックします。
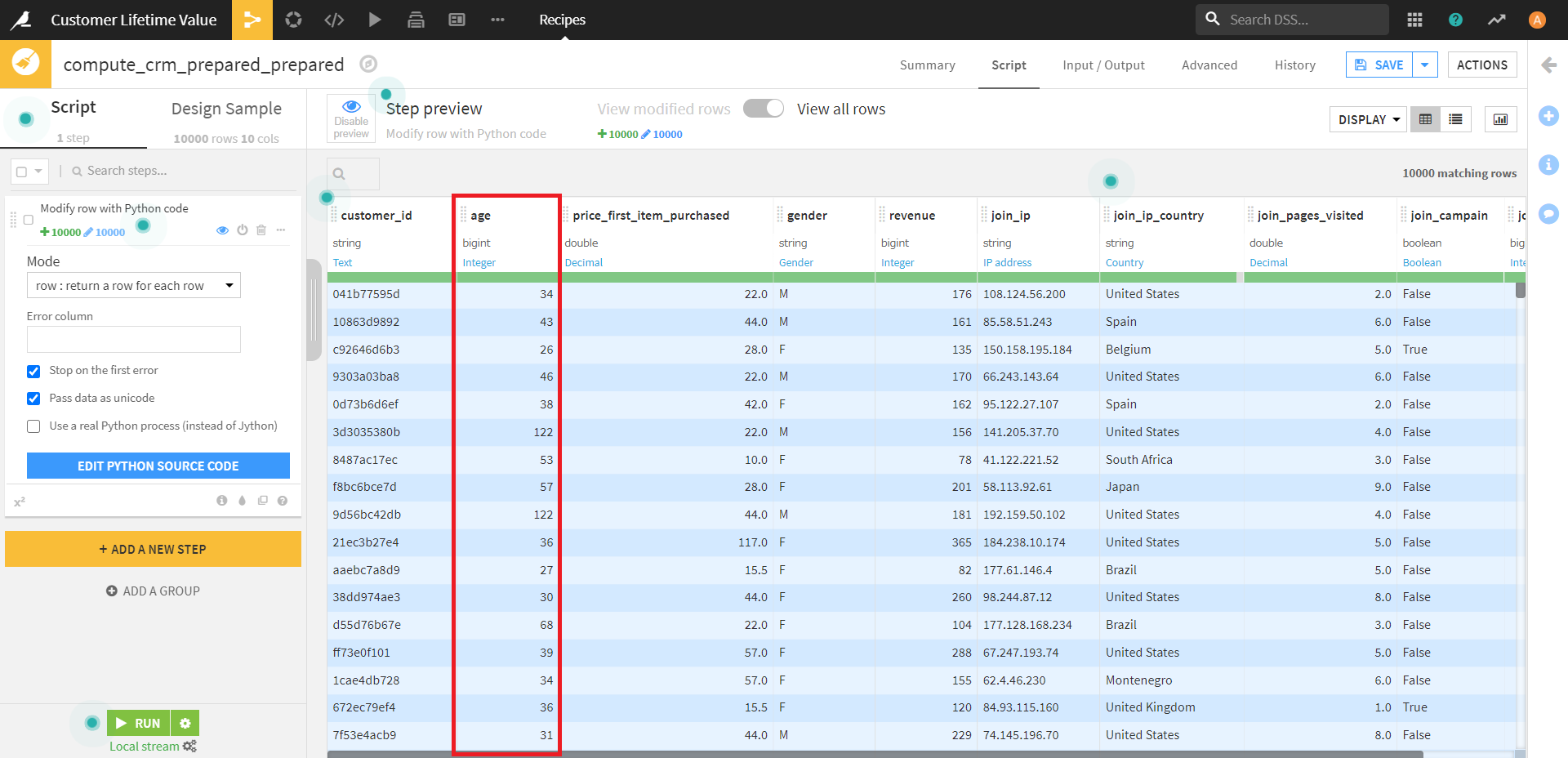
操作が完了するまで数秒時間がかかりますが、下記のように「age」カラムすべてに +5 することができました。
今回はここまでです。
次回もお楽しみに。