はじめに
以前、Unity SentisでWhisperのtinyモデルの推論を行うという以下のような記事を作成しました。
前回の記事でも軽く触れましたが、Unity公式からもUnity SentisのデモがGitHub上に公開されています。今回はそのデモの一部を紹介したいと思います。
なお、Unity Sentisの公式ページは以下になります。
導入
以下のリポジトリをローカルの適当な場所にクローンします。なお、git lfs のインストールが必要になると思います。
このプロジェクトには
-
Blaze Face/Hand/Pose Detection
Google社のBlaze系モデルを用いた 顔/手/ポーズ の検知 -
Digit Recognition
MNISTを学習させたモデルを用いた脱出ゲーム -
Board-game AI
ニューラルモデルで盤面から着手ごとの勝率を推論するオセロAI -
Depth Estimation
カメラ画像からリアルタイムで震度推定を行うARデモ -
Protein Folding
タンパク質の折り畳みをリアルタイム3Dでレンダリング・可視化 -
Star Simulation
Unity SentisによるGPU上の運動方程式計算と星の動きのリアルタイムシミュレーション
という6種類のデモが同梱されています。
今回の記事では、上の3つ(Blaze Face/Hand/Pose Detection, Digit Recognition, Board-game AI)について紹介したいと思います。
※追記
Board-game AI については、元のコードに(修正は少ないけど割と重大な)バグがあり、そのままだと適切に動作しなかったのと、コードの説明が少し長くなりそうなので別記事に分けたいと思います。
リポジトリをクローンした後は、Unity Hubを開き、Add > Add project from diskから該当のプロジェクトを開けばよいです。なお、プロジェクトごとに当時のEditor Versionのインストールが要求されると思います。最新のEditorであれば大丈夫であると思いますが、念のため推奨されたEditor Versionをインストールすることをお勧めします。
デモを使ってみる
Blaze Detection Model in Sentis (Hand Detection)
概要
Googleの Blaze Face/Hand/Pose を用いて、Unity上で顔/手/ポーズ の検知を行うデモです。Unity Sentisを用いることで、バックエンド上で GPU による非同期推論を可能にしています。
このBlazeによる検知についてはFace、Hand、Pose用の計3種類が用意されていましたが、今回はHand用のデモを試したいと思います。
公式のドキュメントは以下になります。
実行
まずプロジェクトを開き、HandDetectionという名前のシーンを開きます。その後、エディタ上部の再生ボタンを押すなどして実行してみるとあらかじめ用意されていた手の画像に対して推論が行われ、手の骨格が適切に検知されることが確認できると思います。
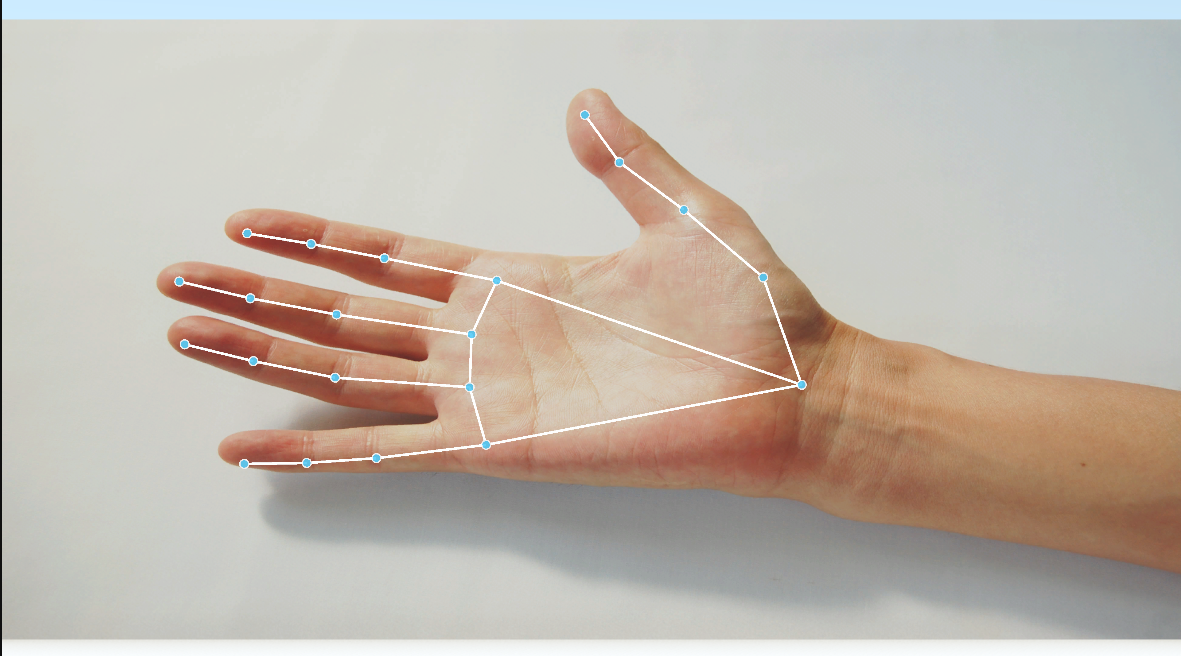
なお、私はせっかくなのでプロジェクト内にある画像から別の手の画像に差し替え、検知されるかを試してみした。画像はこちらのものを拝借させていただきました。
実際の実行結果が下の画像です。画像を変えてもきちんと検知が行われ、キーポイントが適切に配置されています。
コード
主要部分のコード(Scripts/HandDetection.csのStart(), Detect())について簡単に説明します。一部、日本語でコメントを追加しています。
Start()
public async void Start()
{
// アンカーボックスの読み込み
m_Anchors = BlazeUtils.LoadAnchors(anchorsCSV.text, k_NumAnchors);
// モデルのロード
var handDetectorModel = ModelLoader.Load(handDetector);
// モデルの後処理を行い、スコアをフィルタリングして ArgMax により最も信頼性の高い手を選択する
var graph = new FunctionalGraph();
var input = graph.AddInput(handDetectorModel, 0);
var outputs = Functional.Forward(handDetectorModel, input);
var boxes = outputs[0]; // (1, 2016, 18)
var scores = outputs[1]; // (1, 2016, 1)
var idx_scores_boxes = BlazeUtils.ArgMaxFiltering(boxes, scores);
handDetectorModel = graph.Compile(idx_scores_boxes.Item1, idx_scores_boxes.Item2, idx_scores_boxes.Item3);
// モデルを GPU で実行するためのWorkerを作成
m_HandDetectorWorker = new Worker(handDetectorModel, BackendType.GPUCompute);
// Landmark用のモデル読み込み・Worker作成
var handLandmarkerModel = ModelLoader.Load(handLandmarker);
m_HandLandmarkerWorker = new Worker(handLandmarkerModel, BackendType.GPUCompute);
m_DetectorInput = new Tensor<float>(new TensorShape(1, detectorInputSize, detectorInputSize, 3));
m_LandmarkerInput = new Tensor<float>(new TensorShape(1, landmarkerInputSize, landmarkerInputSize, 3));
while (true)
{
try
{
m_DetectAwaitable = Detect(imageTexture);
await m_DetectAwaitable;
}
catch (OperationCanceledException)
{
break;
}
}
m_HandDetectorWorker.Dispose();
m_HandLandmarkerWorker.Dispose();
m_DetectorInput.Dispose();
m_LandmarkerInput.Dispose();
}
Start()では最初にアンカーボックス(※)の読み込み、モデルの読み込みと後処理、Worker(推論エンジン)の起動を行い、その後
Detect()を非同期で繰り返し呼び出します。画像中の手の領域検知用(HandDetector)とランドマーク推定用(HandLandmarker)にそれぞれモデル・Workerが用意されていることに注意してください。
※アンカーボックスとは
アンカーボックス画像内にあらかじめ配置された基準の矩形(バウンディングボックス)のことを言います。
モデルはこのアンカーを基に、物体の正確な位置や大きさを推定します。
以下の記事を参考にすると理解しやすいと思います。
Detect()
async Awaitable Detect(Texture texture)
{
// 画像情報を設定
m_TextureWidth = texture.width;
m_TextureHeight = texture.height;
imagePreview.SetTexture(texture);
var size = Mathf.Max(texture.width, texture.height);
// テンソル座標系から画像座標系に変換するためのアフィン変換行列
var scale = size / (float)detectorInputSize;
var M = BlazeUtils.mul(BlazeUtils.TranslationMatrix(0.5f * (new Vector2(texture.width, texture.height) + new Vector2(-size, size))), BlazeUtils.ScaleMatrix(new Vector2(scale, -scale)));
BlazeUtils.SampleImageAffine(texture, m_DetectorInput, M);
// HandDetectorの実行
m_HandDetectorWorker.Schedule(m_DetectorInput);
var outputIdxAwaitable = (m_HandDetectorWorker.PeekOutput(0) as Tensor<int>).ReadbackAndCloneAsync();
var outputScoreAwaitable = (m_HandDetectorWorker.PeekOutput(1) as Tensor<float>).ReadbackAndCloneAsync();
var outputBoxAwaitable = (m_HandDetectorWorker.PeekOutput(2) as Tensor<float>).ReadbackAndCloneAsync();
using var outputIdx = await outputIdxAwaitable;
using var outputScore = await outputScoreAwaitable;
using var outputBox = await outputBoxAwaitable;
// 一定値を超えたらプレビュー
var scorePassesThreshold = outputScore[0] >= scoreThreshold;
handPreview.SetActive(scorePassesThreshold);
if (!scorePassesThreshold)
return;
// バウンディングボックスの計算・調整
var idx = outputIdx[0];
var anchorPosition = detectorInputSize * new float2(m_Anchors[idx, 0], m_Anchors[idx, 1]);
var boxCentre_TensorSpace = anchorPosition + new float2(outputBox[0, 0, 0], outputBox[0, 0, 1]);
var boxSize_TensorSpace = math.max(outputBox[0, 0, 2], outputBox[0, 0, 3]);
var kp0_TensorSpace = anchorPosition + new float2(outputBox[0, 0, 4 + 2 * 0 + 0], outputBox[0, 0, 4 + 2 * 0 + 1]);
var kp2_TensorSpace = anchorPosition + new float2(outputBox[0, 0, 4 + 2 * 2 + 0], outputBox[0, 0, 4 + 2 * 2 + 1]);
var delta_TensorSpace = kp2_TensorSpace - kp0_TensorSpace;
var up_TensorSpace = delta_TensorSpace / math.length(delta_TensorSpace);
var theta = math.atan2(delta_TensorSpace.y, delta_TensorSpace.x);
var rotation = 0.5f * Mathf.PI - theta;
boxCentre_TensorSpace += 0.5f * boxSize_TensorSpace * up_TensorSpace;
boxSize_TensorSpace *= 2.6f;
// 手のバウンディングボックスを基にしたアフィン変換行列を計算
var origin2 = new float2(0.5f * landmarkerInputSize, 0.5f * landmarkerInputSize);
var scale2 = boxSize_TensorSpace / landmarkerInputSize;
var M2 = BlazeUtils.mul(M, BlazeUtils.mul(BlazeUtils.mul(BlazeUtils.mul(BlazeUtils.TranslationMatrix(boxCentre_TensorSpace), BlazeUtils.ScaleMatrix(new float2(scale2, -scale2))), BlazeUtils.RotationMatrix(rotation)), BlazeUtils.TranslationMatrix(-origin2)));
BlazeUtils.SampleImageAffine(texture, m_LandmarkerInput, M2);
// HandLandmarkerの実行
m_HandLandmarkerWorker.Schedule(m_LandmarkerInput);
var landmarksAwaitable = (m_HandLandmarkerWorker.PeekOutput("Identity") as Tensor<float>).ReadbackAndCloneAsync();
using var landmarks = await landmarksAwaitable;
// 可視化
for (var i = 0; i < k_NumKeypoints; i++)
{
var position_ImageSpace = BlazeUtils.mul(M2, new float2(landmarks[3 * i + 0], landmarks[3 * i + 1]));
Vector3 position_WorldSpace = ImageToWorld(position_ImageSpace) + new Vector3(0, 0, landmarks[3 * i + 2] / m_TextureHeight);
handPreview.SetKeypoint(i, true, position_WorldSpace);
}
}
Detect()では、手の領域検出(HandDetector)およびランドマーク検出(HandLandmarker)のモデルが実際に実行されます。
HandDetectorの実行後は、まずモデルの出力
- outputIdx : 最もスカが高い手のインデックス
- outputScore : 信頼スコア
- outputBox : バウンディングボックス情報
を取得します。ただし、一定値を下回る場合はプレビューされません。
その後、バウンディングボックスを計算・調整し、ランドマーク推定モデルの実行に移ります。そして、実行によって得られたランドマーク情報(キーポイントの位置を表すデータ)プレビューします。
Digit Recognition
概要
パスコードを手書き入力する脱出ゲームのデモです。MNISTと呼ばれる手書きの10進数のデータセットを学習させたモデルを用いて、文字認識を行っています。
公式のドキュメントは以下になります。
実行
DigitRecognitionSampleというプロジェクトを開きます。シーンを開き、実行すれば早速脱出ゲームをプレイできます。
部屋の中に、正解となる3桁の番号が隠されているので発見し、扉の隣にあるパネルに入力すれば次の部屋に進むことができます。パネルの隣にある水色の数字は、書いた文字がどのように認識されているかを表しています。
操作については、ざっくり書くと
-
WASDで移動可能, Shiftを押していると走れる
-
スペースキーを押すことでカーソルが消えたりついたり
-
消えていると、マウスで視点操作が可能に
-
ついていると、扉の隣にある装置で文字入力可能
-
不正解だと警報を鳴らされ、再入力が必要(パスワードが変わる)
といったようになっていました。

プレイしてみた感想としましては、認識精度・速度は十分で結構ゲームとして有用そうだと思いました。自分の書いた字がちゃんとゲーム内にインタラクションされるのでデモながら面白かったです。他の学習データ(KMNISTとかChinise-MNISTとか)を使ったモデルでもやってみたいです。
コード
Scripts/MNISTEngine.cs中でモデルの推論および出力結果の取得・利用が行われています。
Start()
void Start()
{
// モデルのロード
Model model = ModelLoader.Load(mnistONNX);
// ニューラルネットワークの計算グラフを構築
var graph = new FunctionalGraph();
inputTensor = new Tensor<float>(new TensorShape(1, 1, imageWidth, imageWidth));
var input = graph.AddInput(DataType.Float, new TensorShape(1, 1, imageWidth, imageWidth));
var outputs = Functional.Forward(model, input);
var result = outputs[0];
// Softmaxを用いてモデルの出力を確率に変換、確率が最大となるインデックス取得
var probabilities = Functional.Softmax(result);
var indexOfMaxProba = Functional.ArgMax(probabilities, -1, false);
model = graph.Compile(probabilities, indexOfMaxProba);
// 推論エンジンの作成
engine = new Worker(model, backendType);
// カメラ設定
lookCamera = Camera.main;
}
コメントに記載された通りの処理を行います。Blaze系モデルによる検知の時とは異なり必要な処理が少ないのでわかりやすいと思います。
GetMostLikelyDigitProbability()
// 画像をニューラルネットワークモデルに送信し、その画像が各数字である確率を返す
public (float, int) GetMostLikelyDigitProbability(Texture2D drawableTexture)
{
// テクスチャをテンソルに変換 (width=W、height=W、channnels=1)
TextureConverter.ToTensor(drawableTexture, inputTensor, new TextureTransform());
// 推論の実行
engine.Schedule(inputTensor);
// ニューラルネットワークの出力への参照を取得
// 結果をGPUからCPUで読み取れる形式に変換
using var probabilities = (engine.PeekOutput(0) as Tensor<float>).ReadbackAndClone();
using var indexOfMaxProba = (engine.PeekOutput(1) as Tensor<int>).ReadbackAndClone();
var predictedNumber = indexOfMaxProba[0];
var probability = probabilities[predictedNumber];
return (probability, predictedNumber);
}
名前の通り、書いた手書き文字(数字)がそれぞれ10進数のどれに該当するかの確率を取得する関数。ここで、ニューラルモデルによる推論を行っています。
まとめ
Unity Sentisを通じた、Blaze Detection や Digit Recognition のデモを体験してみました。Blaze Detection の方は今回は静止画のみに対して検知を行いましたが、少しコードをいじればカメラからリアルタイムで検知を行うことができるのでよりゲームに対して応用が利くように思います。Digit Recognition のデモはすでに簡単なゲームになっており、新しい操作体験を生み出せているように感じました。某脳を鍛えるゲームの計算のやつとかに使えそう。
Board-game AI の方の記事は近日中に公開する予定です。
※追記
投稿しました。