はじめに
最近BERT等の事前学習モデルを採用した自然言語処理が人気ですね。
私もBERTを利用して日本語のチャットボットやQAシステムを作りたいなと考えているのですが、
大量のQAデータセットを持っているわけではないのでSQuADのような学習はできません。
「大量というほどはないが少数のQAデータセットは手元にある。なんとかこれを使いたい」
という場合は多いと思います。
このような場合は、入力クエリがデータセットのQまたはAのどれに当てはまるか
という分類問題を解くことで、QAシステムっぽいものを作れるんじゃないかと思います。
例えば、スーパーの売り場を案内するQAサイトを作成することを考えます。
「乳製品売り場はどこですか?」
という入力クエリが与えられた場合に、手元にあるデータセットに
「乳製品が置いてある場所を教えて下さい」
という質問があり、これと同じものと判定することができれば適切な答えを返すことができそうです。
このような言い換えを学習するためのデータセットとしてGoogleからPAWSが公開されました。
PAWSは英語のみのデータセットで、日本語を含めた多言語版はPAWS-Xといいます。
https://github.com/google-research-datasets/paws
本当にやりたいことは日本語の言い換え理解なのですが、とりあえずPAWSがどういうものか試してみました。
ソースコードは以下に公開しています。
https://github.com/kyoto-bt-lab/QQP-PAWS
本投稿の内容は下記の論文の再現実験になります。
PAWS: Paraphrase Adversaries from Word Scrambling
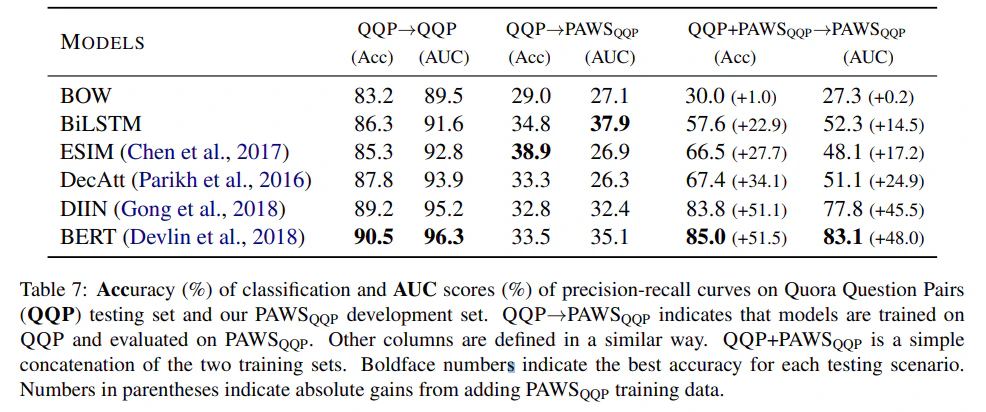
QQP→QQP
PAWSはGLUEのタスクの一つであるQQP(Quora Question Pairs)のデータセットを言い換えたものになります。
QQPは2つの質問文が与えられたときに、それが同一か否かを0/1で判定するタスクです。
そこで、まずは素のQQPを学習してみます。
GLUEのタスクを学習するにはHaggingfaceが公開しているtransformersを使うと簡単です。
![]()
以下のようにしてtransformersのexampleにあるrun_glue.pyを動かします。
python ./transformers/examples/run_glue.py \
--data_dir=./data_glue/QQP/ \
--model_type=bert \
--model_name_or_path="bert-base-uncased" \
--do_lower_case \
--task_name=qqp \
--do_train \
--do_eval \
--output_dir=./result/qqp_qqp \
--overwrite_output_dir \
--num_train_epochs=3 \
--per_gpu_train_batch_size=64 \
--per_gpu_eval_batch_size=64 \
--save_steps=5000 \
BERTの学習済みモデルは複数公開されていますが、とりあえずbaseモデルかつ小文字正規化を適用している
"bert-base-uncased"を指定しています。
また、save_steps=5000することでイテレーションが5000回ごとにcheckpointが作成されます。
今回は5000、10000、15000でcheckpointが作成されました。1つのcheckpointは約1.2GBほどあります。
また、Epoch数は3にしました。Google Colaboratoryで実行すると1Epoch 140分ぐらいかかりました。
evalが終わるとoutput_dirにeval_results.txtが作成されます。
結果はaccuracy = 0.910でした。Haggingfaceが公開している結果は0.884だったのでいい感じに学習できています。
https://huggingface.co/transformers/examples.html#glue
QQP→PAWSQQP
次に、QQPで学習したモデルを使って言い換え文(PAWSQQP)のテストをしてみます。
PAWSのデータセットを用意したりなどはGoogleが手順を公開してくれているのでそれに従います。
面倒なのでシェルスクリプトにまとめておいたのでご興味がある方はご確認ください。
https://github.com/kyoto-bt-lab/QQP-PAWS/blob/master/setup.bash
残念ながらPAWSデータセットはGLUEデータセットとフォーマットが若干違うためtransformersで読み込むにはもうひと工夫必要です。
(GLUEデータセットは5列で、PAWSデータセットは3列といった単純な違いです)
そこで、PAWSデータセット読み込み用のPawsQqpProcessorとこれを使ったload_and_cache_examples関数を定義しました。
全部掲載すると長くなるので詳細はgithubをご確認ください。
load_and_cache_examplesはtsvファイルを読み込んだあとトークナイズやembeddingの処理をして、
キャッシュファイルを保存するという役割があります。もしキャッシュファイルが存在すればそちらを読み込みます。
今回はこの仕様を逆手にとり、load_and_cache_examplesでキャッシュファイルを先に作成してしまいます。
こうすることで、その他の処理はrun_glue.pyのまま使いまわせるので簡潔に書くことができます。
from transformers import BertConfig, BertForSequenceClassification, BertTokenizer
from transformers import glue_output_modes as output_modes
import argparse
import torch
import sys
sys.path.append("./transformers/examples")
from run_glue import evaluate
config_class, model_class, tokenizer_class = BertConfig, BertForSequenceClassification, BertTokenizer
tokenizer = tokenizer_class.from_pretrained("./result/qqp_qqp/", do_lower_case=True)
model = model_class.from_pretrained("./result/qqp_qqp/")
args = argparse.Namespace(
output_dir="./result/qqp_pawsqqp",
task_name="qqp",
model_type="bert",
data_dir="./data_paws/paws_qqp/output",
model_name_or_path="bert-base-uncased",
overwrite_cache=False,
local_rank=-1,
max_seq_length=128,
per_gpu_eval_batch_size=64,
n_gpu=1,
)
args.output_mode = output_modes["qqp"]
args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(args.device)
model.eval()
with torch.no_grad():
load_and_cache_examples(args, args.task_name, tokenizer, evaluate=True)
result = evaluate(args, model, tokenizer)
print("\n", result)
結果はaccuracy = 0.374でした。論文通り、言い換えにはほとんど対応できていません。
QQP+PAWSQQP→PAWSQQP
最後に、PAWSQQPのtrainデータでファインチューニングしてからテストしてみます。
from run_glue import train
# add default parameters
args.max_steps = -1
args.gradient_accumulation_steps = 1
args.learning_rate = 5e-05
args.adam_epsilon = 1e-08
args.warmup_steps = 0
args.weight_decay = 0.0
args.max_grad_norm = 1.0
args.logging_steps = 500
args.fp16 = False
args.seed = 42
args.evaluate_during_training = False
# Fine-tuning
args.output_dir = "./result/pawsqqp_pawsqqp"
args.num_train_epochs = 3
args.per_gpu_train_batch_size = 64
args.save_steps = 5000
model.train()
train_dataset = load_and_cache_examples(args, args.task_name, tokenizer, evaluate=False)
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
print("\n", "global_step = %s, average loss = %s"%(global_step, tr_loss))
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
model.eval()
with torch.no_grad():
result = evaluate(args, model, tokenizer)
print("\n", result)
Epoch数はQQPと同様に3にしました。Google Colaboratoryで実行すると1Epoch 5分ぐらいかかりました。
結果はaccuracy = 0.826でした。言い換えにもだいたい対応できるようになりました。
まとめ
特に新しいことをしたわけではありませんが、Haggingfaceのtransformersを使ってPAWSがどういうものか試してみました。
次はPAWS-Xを使って日本語の言い換えにも挑戦しようと思います。