BigQuery には Dry run と呼ばれる機能があり、実際にクエリを打たなくても、クエリによるデータスキャン量の見積もりや、クエリの文法チェックをすることができる。
※ Web UI ではお馴染みの、エディタ右上に出てくるこれも Dry run の結果

今回は、この Dry run を、CREATE 文などの DDL に対して実行したらどのような挙動になるかを検証していく。
なお、Dry run をはじめ、BigQuery の操作は Python スクリプトから行う。
参考にした公式ドキュメント
参考にさせていただいた記事
事前準備
Python 環境準備
pip で google-cloud-bigquery をインストールすればひとまず OK
pip install google-cloud-bigquery
まずはサンプルプログラムを実行
公式ドキュメントに書いてあるサンプルプログラムをとりあえず実行してみる。
from google.cloud import bigquery
# Construct a BigQuery client object.
client = bigquery.Client()
job_config = bigquery.QueryJobConfig(dry_run=True, use_query_cache=False)
# Start the query, passing in the extra configuration.
query_job = client.query(
(
"SELECT name, COUNT(*) as name_count "
"FROM `bigquery-public-data.usa_names.usa_1910_2013` "
"WHERE state = 'WA' "
"GROUP BY name"
),
job_config=job_config,
) # Make an API request.
# A dry run query completes immediately.
print("This query will process {} bytes.".format(query_job.total_bytes_processed))
実行結果は以下。
$ python dry_run_sample.py
This query will process 65935918 bytes.
課金されることなくクエリによるデータスキャン量を見積もることができた。
次に、エラーとなる以下のクエリ(存在しないテーブルを参照)を実行してみる。
from google.cloud import bigquery
client = bigquery.Client()
job_config = bigquery.QueryJobConfig(dry_run=True, use_query_cache=False)
query_job = client.query(
(
"SELECT name, COUNT(*) as name_count "
# 存在しないテーブルを指定
"FROM `bigquery-public-data.not_exist.table` "
"WHERE state = 'WA' "
"GROUP BY name"
),
job_config=job_config,
)
print("This query will process {} bytes.".format(query_job.total_bytes_processed))
実行結果は以下。
$ python dry_run_sample_fail.py
~略~
Access Denied: Table bigquery-public-data:not_exist.table: User does not have permission to query table bigquery-public-data:not_exist.table, or perhaps it does not exist.
~略~
BigQuery ジョブ自体がエラーとなった。
このように、クエリが正しく動作するかもチェックすることができるので、Dry run はクエリの文法チェック機能としても有用。
DDL に対して Dry run を実行
ここから本題。
Dry run を DDL に対して実行したらどのような挙動になるのかを見ていく。
CREATE 文に対する Dry run
以下のようなスクリプトを用意。
from google.cloud import bigquery
ddl = f"""
CREATE OR REPLACE TABLE `pokoyakazan.pokoyakazan_dataset.pokoyakazan_table1` AS (
SELECT 1 AS a
);
"""
ddl_dry_run = f"""
CREATE OR REPLACE TABLE `pokoyakazan.pokoyakazan_dataset.pokoyakazan_table2` AS (
SELECT 1 AS a
);
"""
client = bigquery.Client()
# 最初は dry_run を False に設定(デフォルトで False だが、わかりやすいように明示)
job_config = bigquery.QueryJobConfig(dry_run=False, use_query_cache=False)
query_job = client.query(
query=ddl,
job_config=job_config
)
print(f'Dry run: {query_job.dry_run}')
job_config.dry_run = True
query_job = client.query(
query=ddl_dry_run,
job_config=job_config
)
print(f'Dry run: {query_job.dry_run}')
pokoyakazan_table1 というテーブルを作成する CREATE 文を普通に実行し、
pokoyakazan_table2 というテーブルを作成する CREATE 文を Dry run で実行する。
※ pokoyakazan は私のハンドルネーム、特に意味はない
早速実行。
$ python dry_run_create.py
Dry run: False
Dry run: True
データセット配下のテーブルを見てみる。

結果、pokoyakazan_table1 は作成されたが、pokoyakazan_table2 は作成されなかった。
INSERT 文に対する Dry run
続いて、INSERT 文についても見てみる。
以下のスクリプトを用意。
from google.cloud import bigquery
ddl = f"""
INSERT `pokoyakazan.pokoyakazan_dataset.pokoyakazan_table1`
SELECT 100 AS a
"""
ddl_dry_run = f"""
INSERT `pokoyakazan.pokoyakazan_dataset.pokoyakazan_table1`
SELECT 200 AS a
"""
client = bigquery.Client()
# 最初は dry_run を False に設定(デフォルトで False だが、わかりやすいように明示)
job_config = bigquery.QueryJobConfig(dry_run=False, use_query_cache=False)
query_job = client.query(
query=ddl,
job_config=job_config
)
print(f'Dry run: {query_job.dry_run}')
job_config.dry_run = True
query_job = client.query(
query=ddl_dry_run,
job_config=job_config
)
print(f'Dry run: {query_job.dry_run}')
pokoyakazan_table1 の a カラムに対して100を挿入する INSERT 文を普通に実行し、
200を挿入する INSERT 文を Dry run で実行する。
$ python dry_run_insert.py
Dry run: False
Dry run: True
結果、100は挿入されたが、200は挿入されなかった。
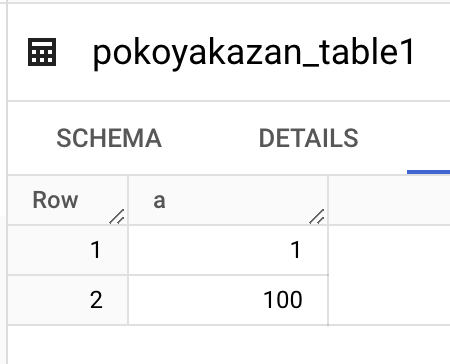
結論
DDL に対しても Dry run は使える。
DDL の文法チェックを Dry run で行う
最後に、DDL の文法が正しいかも Dry run でチェックできるか見ていく。
(特に意味はないが、CREATE FUNCTION 文で検証する)
以下のようなスクリプトを用意。
from google.cloud import bigquery
ddl_correct = f"""
CREATE FUNCTION `pokoyakazan.pokoyakazan_dataset.pokoyakazan_function_correct`(arg_string STRING) AS (
CONCAT(arg_string, 'hoge')
)
"""
ddl_fail = f"""
CREATE FUNCTION `pokoyakazan.pokoyakazan_dataset.pokoyakazan_function_fail`(arg_string STRING) AS (
arg_string / 100 # STRING を割ろうとしているのでエラー
)
"""
client = bigquery.Client()
job_config = bigquery.QueryJobConfig(dry_run=True, use_query_cache=False)
query_job = client.query(
query=ddl_correct,
job_config=job_config
)
print(f'Dry run status: {query_job.state}')
query_job = client.query(
query=ddl_fail,
job_config=job_config
)
print(f'Dry run status: {query_job.state}')
文法的に正しい ddl_correct の Dry run を実行した後に、
文法エラーとなる ddl_fail の Dry run を実行する。
実行結果は以下。
$ python dry_run_function.py
Dry run status: DONE
~略~
No matching signature for operator / for argument types: STRING, INT64. Supported signatures: FLOAT64 / FLOAT64; NUMERIC / NUMERIC; BIGNUMERIC / BIGNUMERIC; INTERVAL / INT64 at [3:3]
~略~
ddl_fail の文法エラーを検知することができた。
まとめ
BigQuery の Dry run 機能は DDL に対しても利用可能。
DDL の文法が間違っている場合でも Dry run によって検知可能。
めでたし!