この記事は自作している強化学習フレームワークの解説記事です。
※今回は解説のみで実装はありません。
・フレームワークの記事
・GitHub
はじめに
サンプル効率を高める手法としてWorldModelベースのDIAMOND、MCTSベースのEfficientZeroV2を書いてきました。
もう一つQ学習ベースでサンプル効率を高める手法が気になっていたので論文を読んでみました。
解説する論文は以下の3つです。
- SPR: 自己教師あり学習を導入し、学習しやすい状態を作ることで性能向上
- SR-SPR: リセット法を導入し、リプレイ率の大幅な向上を実現
- BBF: リセットとモデルのスケールの関係を調べ、さらに強くリセットする事で性能を向上
SPR(2020)
自己教師あり表現学習法(self-supervised representation learning methods)は、特にデータが少ない環境や半教師あり学習において、新しい視覚タスクや言語タスクの学習で成功を収めてきました。
この成功に着目し、状態を時間的に一貫性を持つように予測する事で、強化学習として優れた状態表現を獲得できるのではないかという疑問から生まれたのがSPRとなります。
性能は以下で、Arari 100k において従来のSoTAを更新した手法となります。
(横軸のScoreが1.0を超えると人間を超えるレベル)
(まだ人間レベルは超えておらず、この後に初めて人間レベルを超えた手法がEfficientZero)
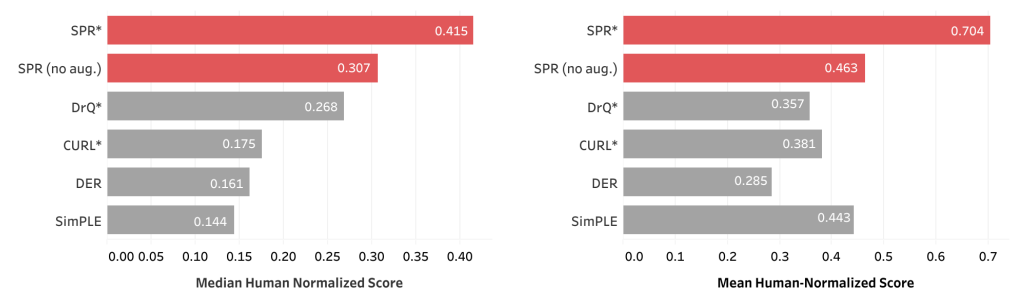
※Atari100kは従来のAtariベンチマークの200Mステップ(=200,000,000)を100kステップ(=100,000)に減らしたベンチマーク
論文とGitHubは以下です。
https://arxiv.org/abs/2007.05929
https://github.com/mila-iqia/spr
・自己教師あり表現学習法
これは、ラベルなしデータだけで特徴量(表現)を学習する手法です。
機械学習における「教師あり学習」と「教師なし学習」の中間に位置するアプローチとなります。
SPR(Self-Predictive Representations)
SPRはマルコフ決定過程を仮定し、一般的なQ学習(論文ではRainbow)をベースにしています。
考えとしては、自己教師あり学習を用いて状態を学習しやすい表現に変換する事で学習を効率化する手法となります。
将来の状態を予測するように状態を表現する事で、アルゴリズムのデータ効率が向上するのではないかという直感から考えられています。
具体的な方法は以下で、k-step後の状態を予測するように学習をします。
(図ではk-step後だけを学習しているように見えますが、実際は今の状態~k-step後の全ての状態で学習する)
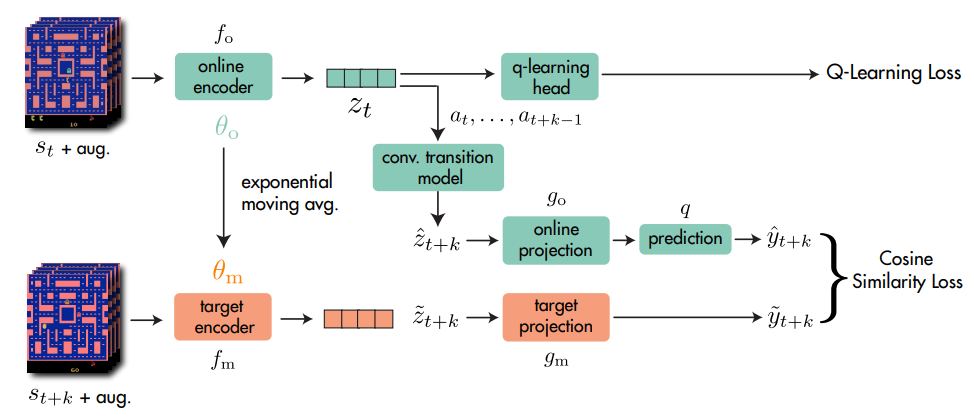
図は論文より
以下、画像の説明です。
Online/Target Encoder
エンコーダーは観測した状態 $s_t$ を潜在空間 $z_t$ に変換します。
今の状態はonlineエンコーダーで変換され、Q学習のlossや後述する未来の状態とのlossに使われます。
targetエンコーダーは未来の状態を変換しますが学習しません。
代わりにonlineエンコーダーからEMA(exponential moving average; 指数移動平均)でパラメータは更新されます。
EMAによる更新式は以下です。
$$
\theta_m \leftarrow \tau\theta_m + (1-\tau) \theta_o
$$
$\tau$ は更新の割合を決めるパラメータです。(データ拡張を使用しない場合、$\tau=0.99$)
Transition Model
遷移モデルは潜在空間上で次の状態を予測するモデルです。
具体的にはエンコード後の潜在表現(7,7,64)に対して直接CNNを適用します。
コードで表すと以下です。
trans_layers = [
Conv2d(64,filter=3,kernel=1)
Conv2d(64,filter=3,kernel=1)
BatchNorm()
ReLU()
] × 2
Projection Heads
潜在空間はProjectionネットワークを通してより小さな潜在空間に投影した後に学習されます。
online側はBYOLの論文より追加の予測ヘッド(prediction)を追加して投影します。
target側のパラメータはエンコーダーと同じく学習されず、online側からEMAで更新されます。
Prediction Loss
最後にSPRの損失ですが、損失は時間ステップ$t+k$($1\leqq k\leqq K$)における予測表現(online側)と観測表現(target側)のコサイン類似度を最小化します。
(コサイン類似度はBYOLのL2正規化損失と線形関係にあります)
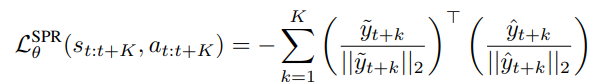
実際にはこれにQ学習側の損失も含まれるので以下となります。
$$
L_{\theta}^{total} = L_{\theta}^{RL} + \lambda L_{\theta}^{SPR}
$$
論文だと$\lambda=2$です。
SR-SPR(2023)
環境が1ステップ進む間に学習する回数をリプレイ率(replay ratio)と定義します。(厳密な言い回しは論文参照)
例えば1ステップに対して1回学習すればリプレイ率は1になり、DQNのAtariはフレームスキップを用いているので4ステップに1回学習=リプレイ率0.25になります。
リプレイ率が高いほど環境とのやりとりが少なくなるのでサンプル効率が高くなると言えます。
リプレイ率ですが、パラメータを適切に調整するとある程度上げられることが知られています。
(離散制御で8、連続制御でも最大20を達成している論文があるとのこと)
しかし、ハイパーパラメータの調整は容易ではなく、リプレイ率を効果的に高めるのは依然として困難です。
また最近の研究で、学習されたニューラルネットワークは新しい情報から学習・一般化する能力を失う傾向がある事が分かってきました。1
深層強化学習では動的なデータセットを処理しており、トレーニングの過程でデータセットが変化していきます。
ほとんどの強化学習手法は新しい情報に対する対策が講じられていないため、リプレイ率の向上に対して大きな障害となっていると考えました。
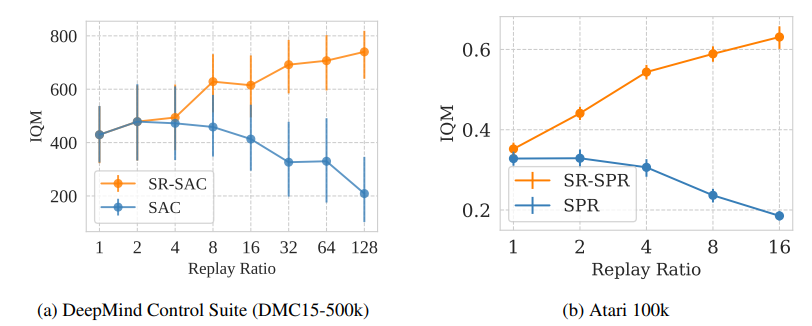
SR-SPR(Scaled-by-Resetting SPR)はパラメータリセット法によりリプレイ率の大幅な向上に成功した手法となります。
図は論文より、リプレイ率を上昇させても性能が劣化しないどころか向上していることが分かります。
(横軸がリプレイ率)
・論文
https://openreview.net/forum?id=OpC-9aBBVJe
深層強化学習における学習能力と汎化能力の喪失
ニューラルネットは学習中に汎化能力を失うことを示唆する証拠が増えています。
この現象は固定されたデータを使う教師あり学習などでは明確には見えませんが、データ分布が変化する強化学習では見え始めます。
この問題に関する先行研究の内容をまとめたものが以下です。(論文の表3を意訳したもの)
| 表現 | 定義 | 文献 |
|---|---|---|
| Warm-Startingによるダメージ | Warm-start(事前学習)されたネットワークは、ランダム初期化されたネットワークよりもテストサンプルで性能が劣る | Ash & Adams (2020) |
| 非定常性(Non-Stationarity)によるダメージ | 非定常性とは入力データ自体の分布の変化です。一時的なデータ分布の変化に過剰に反応し、ニューラルネットの重要な内部表現が更新される事で性能が劣化する可能性がある | Igl et al. (2021) |
| キャパシティの喪失(Capacity Loss) | 学習が進むと学習内容が固定化し、新しいタスクを学習する空間(パラメータの自由度)が足りなくなり、新しい知識の学習能力が低下する | Lyle et al. (2022b), Lyle et al. (2022a) |
| 可塑性の喪失(Loss of Plasticity) | 長時間の学習により内部表現が固定化し、(キャパシティがあっても)新しいことを学習する能力そのものを失うこと | Berariu et al. (2021), Dohare et al. (2022) |
| 初期バイアス(Primacy Bias) | 学習初期の経験に過剰適合し、それ以降の学習がうまく行えなくなる偏り | Nikishin et al. (2022) |
リプレイ率のスケーリング
環境の1stepあたりのエージェントの更新回数をリプレイ率(replay ratio)とし、この比率を向上させることをサンプル率のスケーリングとして明確に定義します。
-
リプレイ率のスケーリング(Replay Ratio Scaling)
同じ回数だけ環境とやり取りした場合に、更新回数を増やした場合のエージェントの性能の変化
原文:Change in an agent’s performance caused by doing more updates for a fixed number of environment interactions.
リプレイ率を阻害する原因は何でしょうか?
主な要因はニューラルネットワークの学習能力と汎化能力の漸進的な低下であると考えられます。
最近の研究では、たとえタスクがスムーズに切り替わる場合でも、以前のタスクでより多くのトレーニングが行われれば行われるほど、新しいタスクでの最終的なパフォーマンスが低下することが示されています。
強化学習は異なるタスクが連なった長いシーケンスと見ることができ、この悪影響が大きいと考えられます。
リプレイ率が高いほどトレーニング量が増えるため、新しいタスクへの学習/汎化能力が低下し、学習の限界がある事を自然に説明できます。
リセットによるリプレイ率のスケーリング
学習能力と汎化能力は回復可能です。
例えば Nikishin et al. (2022) はネットワークのパラメータを定期的にリセットする事でこれを実現しました。
SR-SPRのリプレイ率のスケーリングの鍵は、ネットワークの学習能力と汎化能力を定期的に回復することであり、パラメータの部分リセットと完全リセットにより実現しています。
オフライン学習の頻度に関する考察
高いリプレイ率の学習はオフライン強化学習に似たものになり、リプレイ率の上昇はオフライン学習の割合を増やすことに相当します。
ではオフライン学習中の更新回数はリプレイ率を決める上で重要な変数となるでしょうか?
これに答えるために反復オフライン強化学習という方法を考えます。
これは、純粋なオフライン学習とデータ収集を交互に行う手法です。
反復オフライン強化学習では、固定データセットに対して非常に多くの更新を適用すると、前よりも良いポリシーが得られなくなる劣化したポリシーが学習されるリスクが高まります。
(劣化したポリシーは劣化した経験を収集する)
ポリシーの劣化を止める仕組みがない場合、この悪循環を止める方法は新しいデータを収集するしかありません。
既存アルゴリズム(SACなど)ではこのような場合を打開する方法はオンラインな学習しかありません。
(既存のオフライン強化学習アルゴリズムでどうなるかは今後の研究課題との事)
並行学習実験(Tandem Setting)
リプレイ率が高い場合、エージェントの学習はオフライン強化学習に近いものになります。
なので学習するデータセットはほとんどが現ポリシーとは関係ないポリシーで収集されたデータセットです。
では少しだけある現ポリシーで収集されたデータ(オンラインインタラクション; online interaction)はどれほど重要なのでしょうか?
これに答えるために以下の実験をします。
同じアルゴリズム(SR-SAC)の2つのエージェントを用意します。
- Activeエージェント: 環境とやり取りし、データをリプレイバッファに保存
- Passiveエージェント: Activeエージェントのリプレイバッファのデータのみで学習(環境とやりとりなし)
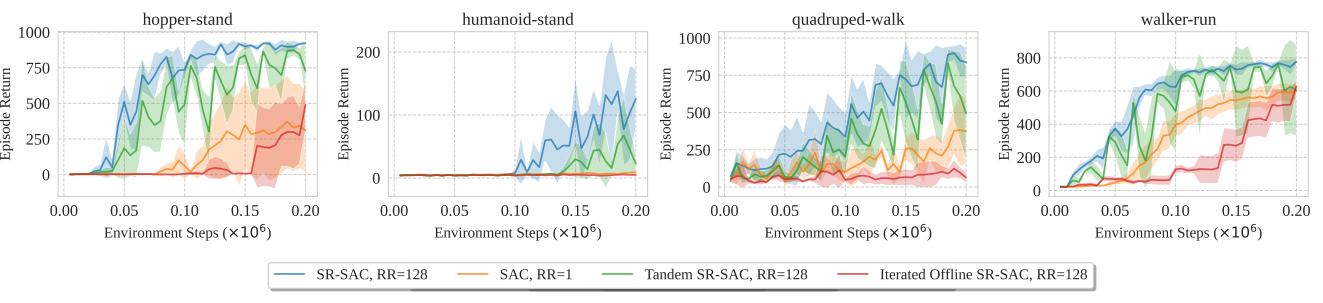
図は論文より
図は4つのタスクに対しての学習結果で、横軸が学習のステップ数、縦軸が報酬です。
特に"hopper-stand"(左の図)で顕著ですが、Activeエージェント(青)とPassiveエージェント(緑)で以下の挙動の特徴があります。
- リセット(下がった)直後、大幅に上昇する
- 学習後半のリセット後の挙動
- Activeエージェント: 安定
- Passiveエージェント: 性能が一時的に下がる
この実験はオンラインインタラクションが暗黙的な正則化機構として動いている事を示しています。
※論文ではもう少し詳しく&更に細かい内容についてもリプレイ率について議論が書かれているので興味がある人は原文をどうぞ
パラメータの初期化方法
リセットの方法については論文で語られておらず、参照先の論文「On Warm-Starting Neural Network Training(論文リンク)」に書かれています。
方法は以下で、Shrink;縮小 + Perturb;摂動 +(Repeat;再訓練)で初期化します。
$$
\theta^t = \lambda\theta^{t-1} + p^t
$$
- $\theta$:パラメータ
- $t$:各学習ラウンド(元論文は強化学習ではなく画像系の教師あり学習の論文)
- $\lambda$:縮小率($0<\lambda<1$)
- $p^t \sim \mathcal{N}(0, \sigma^2)$:正規分布ノイズ
その他の話
SR-SPRはアクション選択にターゲットネットワークを使用します。
これは方策の揺らぎ(Policy Churn)に対応したためとの事です。
方策の揺らぎとは、最新の方策が頻繁に変更されると行動の一貫性が失われて安定しなくなる問題です。
方策の揺らぎの大きさは、外部ノイズがない場合などは適度に増やして探索を促したほうがいいのですが、この変化が大きすぎると似た状況でも一貫した行動がとれず、性能が落ちる事が確認されているようです。
リプレイ率が高いと方策の揺らぎが大きくなるのでSR-SPRではターゲットネットワークを使用する事でこの揺らぎを抑えています。
Bigger, Better, Faster(2023)
BBF(Bigger, Better, Faster)はSR-SPRを調整し、Atari100kにて人間レベルを超えた性能を達成した手法となります。
またSPR,SR-SPR,BBFは筆頭著者が同じ人(Max Schwarzer氏)らしいです。
性能は以下で、SR-SPRより5倍の性能を実現しています。
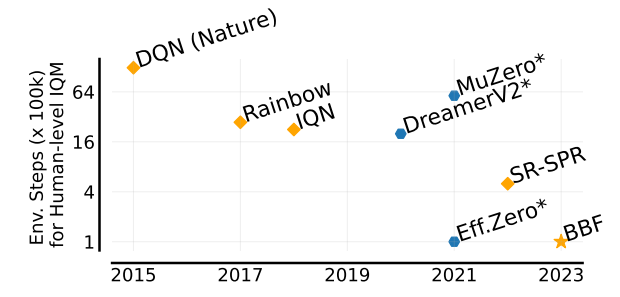
・論文
https://arxiv.org/abs/2305.19452
改善内容
Harder resets
リセットの割合ですが、SR-SPRではCNN層に対して20%リセット、後続層を完全リセットにしていました。
しかし、これをより強くCNN層を50%リセットにしたらより強い摂動(perturbation)が働き性能が向上したとの事です。
これは大規模なネットワークでは損失が速く減少するので、より強い正則化が必要になるためと考えられます。
Receding update horizon
update horizon (n-step)(n-step multilearningの事、これのちゃんとした名称ってなんですかね)ですが、最大10ステップから3ステップへ徐々に減少させます。
これによりRainbowのN=3やSR-SPRのN=10に比べて性能がかなり向上したとの事です。
n-stepスケジュールはnが大きいほど収束が早くなりますが、誤差が大きくなります。
なのでnをアニーリングする事でこの問題に対応しています。
Larger network
ネットワークのスケーリングはBBFの動機の1つとの事です。
(最近の深層学習のトレンドですね)
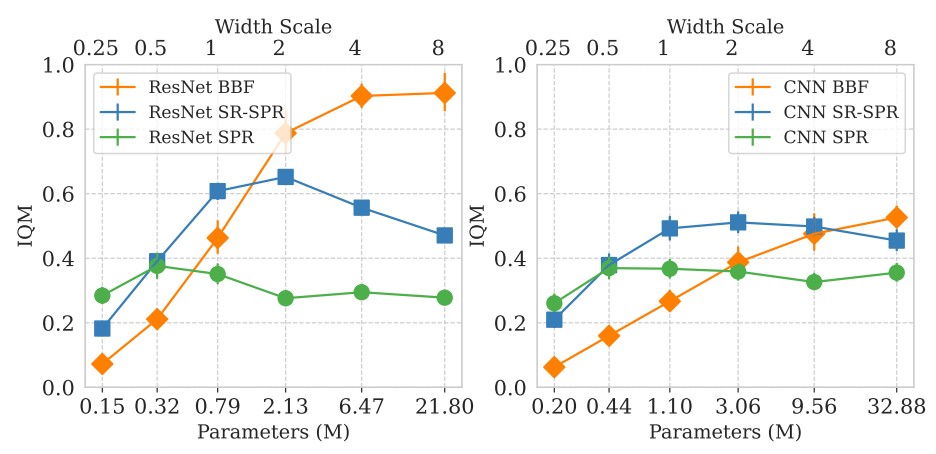
図は論文より、左がResNet、右がCNNを用いた場合のネットワークのスケーリングの関係です。
リプレイ率は2で統一されています。
BBF以外はパラメータを増やしても性能が必ず上がるわけではないですが、BBF(オレンジ)だけはパラメータのスケールに合わせて性能が上がっていますね。
Increasing discount factor
学習中に割引率を増加させるとパフォーマンスが向上するという知見をもとに増加させます。
具体的には $\gamma 1=0.97$(Atariで使用される典型的な値より低い値)から $\gamma 2=0.997$(MuzeroやEfficientZeroで使用されている値)を採用しています。
Weight decay
高いリプレイ率は過学習をする可能性が高いので、統計的な過学習を抑制するために、エージェントに重み減衰を組み込みます。
具体的には重み減衰値を0.1にしたAdamWを使用します。
Removing noisy nets
SPR/SR-SPRで用いられているNoisyNetは性能向上に寄与しないことが分かりました。
これは学習中にノイズが追加されることで方策揺らぎの増加につながり、また学習時の分散の増加によりNoisyNetの過剰探索につながる可能性があります。
詳細については今後の課題となりますが、NoisyNetの削除により計算量とメモリ使用量が大幅に削減されました。
各性能比較
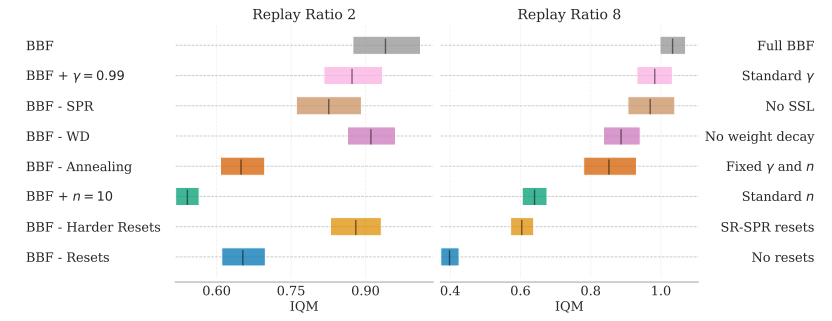
図は論文より、上記の要素をリプレイ率2(左)とリプレイ率8(右)で見てみた結果です。
影響が大きいのはネットワークのリセットとn=10stepの固定でしょうか(まあ10stepも先を見ているとretraceを入れないと厳しいのはなんとなく分かる)
ハードリセットはリプレイ率が低いとあまり影響はないですが、リプレイ率が高いとかなり影響しますね。
終わりに
名前の割に関連がバラバラですね。
SPRとSR-SPRはあまり関連がないですが、SR-SPRとBBFは似た手法です。
個人的にはリプレイ率を踏まえて、オフライン強化学習の意味にまで踏み込んでいるのは興味深かったです。
オフライン強化学習から見るとオンライン強化学習は単なる正則化の役割でしかない点は衝撃でした。
オンライン強化学習が楽観的に学習する傾向が強いのはこの正則化があるからでしょう。
逆にオフライン強化学習が悲観的に学習するのは正則化がないので自前で調整しないといけないからですかね。
もしオフライン強化学習で、別の正則化機構を用意すればオンライン強化学習が不要になるかも?(言いすぎかな)
-
Chaudhry et al., 2018; Ash & Adams, 2020; Berariu et al., 2021; Igl et al., 2021; Dohare et al., 2022; Lyle et al., 2022a;b; Nikishin et al., 2022 ↩